
Partially Wildcarded Attribute-based Encryption and Its Efficient
Construction
Go Ohtake
1
, Yuki Hironaka
1
, Kenjiro Kai
1
, Yosuke Endo
1
, Goichiro Hanaoka
2
, Hajime Watanabe
2
,
Shota Yamada
∗2,3
, Kouhei Kasamatsu
2,4
, Takashi Yamakawa
2,3
and Hideki Imai
2,5
1
Science & Technology Research Laboratories, Japan Broadcasting Corporation,
1-10-11 Kinuta, Setagaya-ku, Tokyo 157-8510, Japan
2
Research Institute for Secure Systems (RISEC), National Institute of Advanced Industrial Science and Technology (AIST),
1-1-1 Umezono, Tsukuba-shi, Ibaraki 305-8568, Japan
3
Graduate School of Frontier Sciences, The University of Tokyo, 5-1-5 Kashiwanoha, Kashiwa-shi, Chiba 277-8561, Japan
4
Security Solution Business Department, NTT Software Corporation,
Teisan Kannai Bldg. 209, Yamashita-cho, Naka-ku, Yokohama-shi, Kanagawa 231-8551, Japan
5
Faculty of Science and Engineering, Chuo University 1-13-27 Kasuga, Bunkyo-ku, Tokyo 112-8551, Japan
Keywords:
Attribute-based Encryption, Ciphertext Policy, Wildcard.
Abstract:
Many kinds of ciphertext-policy attribute-based encryption (CP-ABE) schemes have been proposed. In CP-
ABE, the set of user attributes is associated with his/her secret key whereas a policy is associated with a
ciphertext so that only users whose attributes satisfy the policy can decrypt the ciphertext. CP-ABE may be
applied to a variety of services such as access control for file sharing systems and content distribution ser-
vices. However, CP-ABE costs more for encryption and decryption in comparison with conventional public
key encryption schemes since it can handle more flexible policies. In particular, wildcards, which mean that
certain attributes are not relevant to the ciphertext policy, are not essential for a certain service. In this paper,
we construct a partially wildcarded CP-ABE scheme with a lower decryption cost. In our scheme, the user’s
attributes are separated into those requiring wildcards and those not requiring wildcards. Our scheme hence
embodies a CP-ABE scheme with a wildcard functionality and an efficient CP-ABE scheme without wild-
card functionality. We compare our scheme with the conventional CP-ABE schemes and describe a content
distribution service as an application of our scheme.
1 INTRODUCTION
1.1 Background
In attribute-based encryption (ABE), the set of user
attributes is associated with a secret key or a cipher-
text so that only users whose attributes satisfy the
policy can decrypt the ciphertext. ABE may be ap-
plied to a variety of services, e.g., access control for
file sharing systems and content distribution services.
The first ABE scheme was proposed as an extension
of the identity-based encryption (IBE) scheme called
Fuzzy IBE (Sahai and Waters, 2005) and many kinds
of ABE schemes have been proposed. ABE scheme
∗
The seventh author is supported by a JSPS Research
Fellowship for Young Scientists.
is classified into two types: key-policy ABE (KP-
ABE) (Goyal et al., 2006; Ostrovsky et al., 2007) and
ciphertext-policy ABE (CP-ABE) (Bethencourt et al.,
2007; Cheung and Newport, 2007; Emura et al., 2009;
Katz et al., 2008; Lewko et al., 2010; Nishide et al.,
2008; Okamoto and Takashima, 2010; Waters, 2011).
In KP-ABE, ciphertexts are associated with attributes,
and users’ secret keys are associated with policies. If
the attributes satisfy the key policy, the user can de-
crypt the ciphertext successfully. On the other hand,
in CP-ABE, attributes are associated with secret keys
and policies are associated with ciphertexts. If the at-
tributes satisfy the ciphertext policy, the user can de-
crypt the ciphertext successfully. In this paper, we
focus on CP-ABE.
Bethencourt, Sahai, and Waters proposed the first
CP-ABE scheme (Bethencourt et al., 2007), where ci-
339
Ohtake G., Hironaka Y., Kai K., Endo Y., Hanaoka G., Watanabe H., Yamada S., Kasamatsu K., Yamakawa T. and Imai H..
Partially Wildcarded Attribute-based Encryption and Its Efficient Construction.
DOI: 10.5220/0004509303390346
In Proceedings of the 10th International Conference on Security and Cryptography (SECRYPT-2013), pages 339-346
ISBN: 978-989-8565-73-0
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

phertext policies are expressed by a tree structure in-
cluding AND-gates and OR-gates. This scheme al-
lows ciphertext policies to be very expressive, but it
has larger costs for encryption and decryption than
conventional public key encryption schemes. In con-
trast, Cheung and Newport proposed an efficient CP-
ABE scheme (Cheung and Newport, 2007), where ci-
phertext policies are compactly expressed by AND-
gates and three types of attribute values: positive, neg-
ative, and don’t care. This scheme has much lower
costs for encryption and decryption than the scheme
in (Bethencourt et al., 2007). However, the expres-
sion of ciphertext policies is rather restricted: the size
of possible values for each attribute is only one bit.
On the other hand, Nishide, Yoneyama, and Ohta pro-
posed a CP-ABE scheme (Nishide et al., 2008) where
ciphertext policies are expressed by AND-gates and
a subset of possible values for each attribute and the
corresponding policies are hidden for the purpose of
guaranteeing the recipient’s anonymity. Both (Che-
ung and Newport, 2007) and (Nishide et al., 2008)
construct an efficient CP-ABE scheme with limited
ciphertext policies by using only AND-gates. Fur-
thermore, in these schemes, encryptors can use wild-
cards to mean that certain attributes are not relevant
to the ciphertext policy. On the other hand, Emura,
Miyaji, Nomura, Omote, and Soshi proposed a CP-
ABE scheme (Emura et al., 2009) that is more effi-
cient than those of (Cheung and Newport, 2007) and
(Nishide et al., 2008) by removing the wildcard func-
tionality. In this scheme, ciphertext policies are ex-
pressed by AND-gates and one of the possible values
for each attribute. This scheme has much lower costs
for decryption compared with the scheme presented
in (Nishide et al., 2008).
CP-ABE schemes with a wildcard functional-
ity (Cheung and Newport, 2007; Nishide et al.,
2008) are effective for services where certain at-
tributes might not be relevant to the ciphertext pol-
icy. However, this scheme is functionally redundant
if all attributes are relevant. In contrast, the CP-ABE
scheme without the wildcard functionality (Emura
et al., 2009) has much lower costs for decryption.
However, this scheme cannot be applied to services
where certain attributes are not relevant to the cipher-
text policy.
In particular, the decryption costs of broadcasting
services must be as small as possible, since the de-
vices in the user terminals are usually lower in per-
formance than personal computers and it is possible
that the decryption process is performed on tamper-
resistant devices such as smart cards.
1.2 Our Contributions
In this paper, we propose a partially wildcarded CP-
ABE scheme to reduce the decryption cost. (Emura
et al., 2009) shows that the presence or absence of
wildcard functionality has an influence on the effi-
ciency of the CP-ABE scheme. In our scheme, an
user’s attribute list is separated into a list of attributes
which require wildcards and an list of attributes which
do not require wildcards. Our scheme embodies a CP-
ABE scheme with a wildcard functionality and an ef-
ficient CP-ABE scheme without a wildcard function-
ality. Our idea is to split the master secret key into
two shares by using 2-out-of-2 secret sharing and to
use the shares as master secret keys of each CP-ABE
scheme. We compare our scheme with conventional
CP-ABE schemes and describe a content distribution
service as an application of our scheme. For example,
if there is only one attribute that requires wildcards
among four attributes, our scheme can reduce the de-
cryption cost by 40% in comparison with the conven-
tional CP-ABE schemes.
2 PRELIMINARIES
2.1 Model
A CP-ABE scheme consists of the following four al-
gorithms (Nishide et al., 2008).
Setup(1
k
): This algorithm takes the security parame-
ter k as input and generates a public key PK and a
master key MK.
KeyGen(MK, L): This algorithm takes MK and an at-
tribute list L as input and generates a secret key
SK
L
associated with L.
Encrypt(PK, M, W): This algorithm takes PK, a mes-
sage M, and an ciphertext policy W as input and
generates a ciphertext CT.
Decrypt(CT, SK
L
): This algorithm takes CT and SK
L
associated with L as input. We use the no-
tation L |= W to mean that L satisfies W. If
L |= W, it returns the message M such that
Decrypt(Encrypt(PK,M,W), SK
L
) = M
2.2 Security Definition
We consider the following security game.
Init: The adversary A chooses the challenge cipher-
text policy W and gives it to the challenger B.
Setup: B runs Setup and gives PK to A .
SECRYPT2013-InternationalConferenceonSecurityandCryptography
340

Phase 1: A transmits an attribute list L for KeyGen
query to B . B returns SK
L
associated with L to A
iff L 6|= W.
Challenge: A transmits two messages M
0
and M
1
to
B. B chooses b ∈ {0,1} at random, generates a
ciphertext CT = Encrypt(PK,M
b
,W), and trans-
mits it to A.
Phase 2: Same as Phase 1.
Guess: A outputs a guess b
′
of b.
The security of the CP-ABE scheme is defined as
follows:
Definition 1. We say that a CP-ABE scheme is se-
lective IND-CPA secure if Adv
A
=
Pr[b
′
= b] −
1
2
is
negligible in the above game.
2.3 Bilinear Maps
Let G,G
T
be multiplicative cyclic groups of prime
order p and g be a generator of G. A bilinear map is
a map e : G × G → G
T
with the following properties:
Bilinear: e(g
a
,g
b
) = e(g,g)
ab
∀a,b ∈ Z
p
Non-degenerate: e(g,g) 6= 1
We say that G is a bilinear group if the group action
in G can be efficiently computed and there exists a
group G
T
and an efficiently computable bilinear map
e : G × G → G
T
, as above.
2.4 Decisional Bilinear Diffie-Hellman
(DBDH) Assumption
Let z
1
,z
2
,z
3
∈ Z
∗
p
be chosen at random and g ∈ G
be a generator. Also, let Z be a random element
in G
T
. The DBDH assumption is that no prob-
abilistic polynomial-time algorithm can distinguish
the tuple [g,g
z
1
,g
z
2
,g
z
3
,e(g,g)
z
1
z
2
z
3
] from the tuple
[g,g
z
1
,g
z
2
,g
z
3
,Z] with a non-negligible advantage.
3 CONVENTIONAL SCHEMES
Here, we describe the CP-ABE algorithm with a wild-
card functionality that was proposed in (Nishide et al.,
2008) and the algorithm without a wildcard function-
ality that was proposed in (Emura et al., 2009).
3.1 CP-ABE with Wildcard (Nishide
et al., 2008)
In (Cheung and Newport, 2007), each attribute can
take two values: 1 (positive) and 0 (negative), but in
(Nishide et al., 2008), each attribute can take two or
more values, and eachW
i
in a ciphertext policyW can
be any subset of possible values for each attribute A
i
.
In this paper, the user’s attribute list is simply repre-
sented by indices correspondingto the possible values
for each attribute. Let S
i
= {1, 2, ..., n
i
} be the set of
possible values for A
i
where n
i
is the number of pos-
sible values for A
i
. Then, let L = [L
1
,L
2
,...,L
n
] be the
attribute list where L
i
∈ S
i
and let W = [W
1
, W
2
, ...,
W
n
] be the ciphertext policy where W
i
⊆ S
i
. When the
encryptor specifies a wildcard for A
i
, it corresponds
to specifying W
i
= S
i
for A
i
. The attribute list L satis-
fies the ciphertext policy W; that is, L |= W iff L
i
∈ W
i
for all i ∈ [n].
Setup(1
k
): Choose multiplicative cyclic groups G
and G
T
of prime order p, a bilinear map e :
G × G → G
T
, and a random generator g ∈
G. Then, pick w, a
i,t
, b
i,t
∈ Z
∗
p
, A
i,t
∈
G at random for i ∈ [n], t ∈ [n
i
]. Compute
Y = e(g,g)
w
and output the public key PK =
hp,G,G
T
,e,g,Y, {{A
a
i,t
i,t
,A
b
i,t
i,t
}
t∈[n
i
]
}
i∈[n]
i and the
master key MK = hw,{{a
i,t
,b
i,t
}
t∈[n
i
]
}
i∈[n]
i.
KeyGen(MK, L): Let L = [L
1
,L
2
,...,L
n
] be the at-
tribute list for the user who will obtain the cor-
responding secret key. Pick random values s
i
∈
Z
∗
p
for i ∈ [n], set s =
∑
n
i=1
s
i
, and compute
D
0
= g
w−s
. Then, pick random values λ
i
∈ Z
∗
p
for i ∈ [n] and compute {D
i,0
,D
i,1
,D
i,2
} = {g
s
i
·
(A
i,L
i
)
a
i,L
i
b
i,L
i
λ
i
,g
a
i,L
i
λ
i
,g
b
i,L
i
λ
i
}. Output the secret
key SK
L
= h D
0
·
∏
n
i=1
D
i,0
, {D
i,1
,D
i,2
}
i∈[n]
i asso-
ciated with L.
Encrypt(PK, M, W): Let W = [W
1
,W
2
,...,W
n
] be a ci-
phertext policy and M ∈ G
T
be a message. Pick
a random value r ∈ Z
∗
p
and compute
˜
C = M ·Y
r
and C
0
= g
r
. Then, execute the following pro-
cess for all i ∈ [n]: pick random values r
i,t
∈ Z
∗
p
for t ∈ [n
i
]. If t ∈ W
i
, compute {C
i,t,1
,C
i,t,2
} =
{(A
b
i,t
i,t
)
r
i,t
,(A
a
i,t
i,t
)
r−r
i,t
}. If t 6∈ W
i
, let {C
i,t,1
,C
i,t,2
}
be random values in G. Output the ciphertext
CT = h
˜
C,C
0
,{{C
i,t,1
,C
i,t,2
}
t∈[n
i
]
}
i∈[n]
i.
Decrypt(CT, SK
L
): Check whether the attribute list L
for the user satisfies the ciphertext policy W. If
L |= W, output the message,
M =
˜
C·
∏
n
i=1
e(C
i,L
i
,1
,D
i,1
) · e(C
i,L
i
,2
,D
i,2
)
e(C
0
,D
0
·
∏
n
i=1
D
i,0
)
.
3.2 CP-ABE without Wildcard (Emura
et al., 2009)
In (Emura et al., 2009), each attribute can take two or
more values, and eachW
i
in a ciphertext policyW can
PartiallyWildcardedAttribute-basedEncryptionandItsEfficientConstruction
341

be any one of the possible values for attribute A
i
. As
a result, the encryptor cannot specify a wildcard.
In this paper, an user’s attribute list is simply rep-
resented by indices corresponding to possible values
for each attribute. Let S
i
= {1, 2, ..., n
i
} be a set of
possible values for A
i
where n
i
is the number of the
possible values for A
i
. Then, let L = [L
1
,L
2
,...,L
n
] be
the attribute list where L
i
∈ S
i
and let W = [W
1
, W
2
,
..., W
n
] be the ciphertext policy where W
i
∈ S
i
. The
attribute list L satisfies the ciphertext policy W, that
is, L |= W iff L
i
= W
i
for all i ∈ [n].
Setup(1
k
): Choose multiplicative cyclic groups G
and G
T
of prime order p, a bilinear map
e : G × G → G
T
, and random generators
g,h ∈ G. Then, pick y,t
i, j
∈ Z
p
at ran-
dom for i ∈ [n] and j ∈ [n
i
]. Compute Y =
e(g,h)
y
and T
i, j
= g
t
i, j
. Output the public key
PK = hp,G,G
T
,e,g,h,Y,{{T
i, j
}
j∈[n
i
]
}
i∈[n]
i and
the master key MK = hy,{{t
i, j
}
j∈[n
i
]
}
i∈[n]
i.
KeyGen(MK, L): Let L = [L
1
,L
2
,...,L
n
] be the at-
tribute list for the user who will obtain the cor-
responding secret key. Pick a random value
r ∈ Z
p
and output the secret key SK
L
= hh
y
·
(g
∑
i∈[n]
t
i,L
i
)
r
,g
r
i associated with L.
Encrypt(PK, M, W): LetW = [W
1
,W
2
,...,W
n
] be a ci-
phertext policy and M ∈ G
T
be a message. Pick a
random value s ∈ Z
p
and compute C
1
= M · Y
s
,
C
2
= g
s
, and C
3
= (
∏
i∈[n]
T
i,W
i
)
s
= (g
∑
i∈[n]
t
i,W
i
)
s
.
Output the ciphertext CT = hW,C
1
,C
2
,C
3
i.
Decrypt(CT, SK
L
): Check whether the attribute list L
for the user satisfies the ciphertext policy W. If
L |= W, output the message
M =
C
1
· e(C
3
,g
r
)
e(C
2
,h
y
· (g
∑
i∈[n]
t
i,L
i
)
r
)
.
4 PROPOSED SCHEME
We propose a partially wildcarded CP-ABE scheme
to reduce the decryption cost.
4.1 Overview of Proposed Scheme
In (Emura et al., 2009), it is found that a more ef-
ficient CP-ABE scheme than the scheme in (Nishide
et al., 2008) can be constructed by removing the wild-
card functionality. Hence, the presence or absence of
the wildcard functionality has an influence on the ef-
ficiency of the CP-ABE scheme. In our scheme, the
user’s attribute list is separated into a list of attributes
requiring wildcards and a list of attributes not requir-
ing wildcards. Our scheme thus embodies schemes
with and without the wildcard functionality. Gen-
erally, a CP-ABE scheme without a wildcard func-
tionality has a smaller cost than one with a wildcard
functionality. Therefore, the larger the number of at-
tributes not requiring a wildcard functionality is, the
smaller the total cost of the CP-ABE scheme will be.
However, combining two schemes with and with-
out the wildcard functionality is not trivial. When
the secret key corresponding to the attributes requir-
ing wildcards and the secret key corresponding to the
attributes not requiring wildcards are generated, they
are associated with each other by using a random
number in order to prevent collusion attacks. Further-
more, the ciphertext size is reduced by the encryption
algorithms sharing another random number.
In (Nishide et al., 2008), the authors achieve re-
cipient anonymity by hiding the subsetW
i
for each A
i
specified in the ciphertext policy of the AND-gate of
all the attributes. However, ciphertext policies must
be revealed in certain services. For example, in a
content distribution service, users must know what at-
tributes are required for playing content. In this paper,
we construct a modified CP-ABE scheme by remov-
ing recipient anonymity from the CP-ABE scheme in
(Nishide et al., 2008) and use the modified scheme
as a CP-ABE scheme with a wildcard functionality.
Moreover, we combine it with the CP-ABE scheme
without the wildcard functionality in (Emura et al.,
2009).
4.2 Proposed Scheme
Let ˆn be the number of attributes
ˆ
A
i
which re-
quire wildcards and ˇn be the number of attributes
ˇ
A
i
which do not require wildcards. Moreover, let
ˆ
S
i
= {1,2,..., ˆn
i
} be the set of possible values for at-
tribute
ˆ
A
i
and
ˇ
S
i
= {1,2,..., ˇn
i
} be the set of possi-
ble values for attribute
ˇ
A
i
. The user’s attribute list L
is separated into one list
ˆ
L = {
ˆ
L
1
,
ˆ
L
2
, ...,
ˆ
L
ˆn
} which
requires wildcards, where
ˆ
L
i
∈
ˆ
S
i
, and another list
ˇ
L
= {
ˇ
L
1
,
ˇ
L
2
, ...,
ˇ
L
ˇn
} which does not require wildcards,
where
ˇ
L
i
∈
ˇ
S
i
. Also, the ciphertext policy W is sepa-
rated into a ciphertext policy
ˆ
W = {
ˆ
W
1
,
ˆ
W
2
, ...,
ˆ
W
ˆn
}
which requires wildcards, where
ˆ
W
i
⊆
ˆ
S
i
, and a policy
ˇ
W = {
ˇ
W
1
,
ˇ
W
2
, ...,
ˇ
W
ˇn
} which does not require wild-
cards, where
ˇ
W
i
∈
ˇ
S
i
.
Setup(1
k
, ˆn, ˇn, { ˆn
i
}
i∈[ ˆn]
, { ˇn
i
}
i∈[ ˇn]
): Choose multi-
plicative cyclic groups G and G
T
of prime order
p, a bilinear map e : G × G → G
T
, and a random
generator g ∈ G. Then, pick a random value
w ∈ Z
∗
p
, and compute Y = e(g,g)
w
. Also, pick a
random value A
i, j
∈ G for all i ∈ [ ˆn] and j ∈ [ ˆn
i
],
and pick a random value T
i, j
∈ G for all i ∈ [ˇn]
and j ∈ [ ˇn
i
]. Output the public key PK = h p, G,
SECRYPT2013-InternationalConferenceonSecurityandCryptography
342

G
T
, e, g, Y, {{A
i, j
}
j∈[ ˆn
i
]
}
i∈[ ˆn]
, {{T
i, j
}
j∈[ ˇn
i
]
}
i∈[ ˇn]
i
and the master key MK = w.
KeyGen(PK, MK,
ˆ
L,
ˇ
L): Pick a random value ξ ∈ Z
∗
p
and a random value s
i
∈ Z
∗
p
for all i ∈ [ ˆn]. Set
s =
∑
ˆn
i=1
s
i
and compute D = g
w−s+ξ
. After that,
pick a random value λ
i
∈ Z
∗
p
for all i ∈ [ ˆn] and
compute {D
i,0
,D
i,1
} = {g
s
i
·A
λ
i
i,
ˆ
L
i
,g
λ
i
}. Also, pick
a random value u ∈ Z
∗
p
and compute {D
′
1
,D
′
2
} =
{g
−ξ
· (
∏
i∈[ ˇn]
T
i,
ˇ
L
i
)
u
,g
u
}. Output the secret key
SK
[
ˆ
L,
ˇ
L]
= h
ˆ
L,
ˇ
L, D·
∏
i∈[ ˆn]
D
i,0
· D
′
1
, {D
i,1
}
i∈[ ˆn]
, D
′
2
i associated with the user’s attribute list
ˆ
L and
ˇ
L.
Encrypt(PK, M,
ˆ
W,
ˇ
W): Pick a random value r ∈
Z
∗
p
and compute C
1
= M · Y
r
, C
2
= g
r
, C
3
=
(
∏
i∈[ ˇn]
T
i,
ˇ
W
i
)
r
. Then, compute C
i, j
= A
r
i, j
for all
i ∈ [ ˆn] and j ∈
ˆ
W
i
. Output the ciphertextC
[
ˆ
W,
ˇ
W]
=
h
ˆ
W,
ˇ
W, C
1
, C
2
, C
3
, {C
i, j
}
i∈[ ˆn], j∈
ˆ
W
i
i.
Decrypt(SK
[
ˆ
L,
ˇ
L]
, C
[
ˆ
W,
ˇ
W]
): If
ˆ
L |=
ˆ
W and
ˇ
L |=
ˇ
W, out-
put the message,
M = C
1
·
∏
i∈[ ˆn]
e(C
i,
ˆ
L
i
,D
i,1
) · e(C
3
,D
′
2
)
e(D·
∏
i∈[ ˆn]
D
i,0
· D
′
1
,C
2
)
.
4.3 Security Proof
Theorem 1. Our scheme is selective IND-CPA secure
if the DBDH assumption holds in G.
Proof. Let A be an adversary interested in thwarting
our scheme. We build an algorithm B that solves the
DBDH problem in G by using A. Pick random values
α,β,γ in Z
∗
p
and compute g
1
= g
α
, g
2
= g
β
, and g
3
=
g
γ
. Then, pick a random bit δ ∈ {0,1}. If δ = 1, set
R = e(g,g)
αβγ
. If δ = 0, let R be a random value in
G
T
. B takes as input hg,g
1
,g
2
,g
3
,Ri and proceeds as
follows:
Init: A chooses the challenge ciphertext policies
ˆ
W
∗
= (
ˆ
W
∗
1
,
ˆ
W
∗
2
,...,
ˆ
W
∗
ˆn
) and
ˇ
W
∗
= (
ˇ
W
∗
1
,
ˇ
W
∗
2
,...,
ˇ
W
∗
ˇn
)
and gives them to B.
Setup: B receives
ˆ
W
∗
and
ˇ
W
∗
. It computes the pub-
lic key as follows: B computes Y = e(g
1
,g
2
). After
that, it picks random values a
i, j
in Z
∗
p
for all i ∈ [ ˆn]
and j ∈ [ ˆn
i
]. If j ∈
ˆ
W
∗
i
, it computes A
i, j
= g
a
i, j
.
If j 6∈
ˆ
W
∗
i
, it computes A
i, j
= g
a
i, j
1
. Moreover, B
picks random values b
i, j
in Z
∗
p
for all i ∈ [ ˇn] and
j ∈ [ ˇn
i
]. If j =
ˇ
W
∗
i
, it computes T
i, j
= g
b
i, j
. If
j 6=
ˇ
W
∗
i
, it computes T
i, j
= g
b
i, j
1
. Finally, it returns
PK = hg,Y,{{A
i, j
}
j∈[ ˆn
i
]
}
i∈[ ˆn]
,{{T
i, j
}
j∈[ ˇn
i
]
}
i∈[ ˇn]
i to A.
Phase 1: When A transmits the attribute lists
ˆ
L =
(
ˆ
L
1
,
ˆ
L
2
,...,
ˆ
L
ˆn
) and
ˇ
L = (
ˇ
L
1
,
ˇ
L
2
,...,
ˇ
L
ˇn
) for the KeyGen
query to B, B returns the corresponding secret key as
follows: If (
ˆ
L |=
ˆ
W
∗
) ∧ (
ˇ
L |=
ˇ
W
∗
), B returns ⊥ to A .
Here, the query can be classified into three types. A
type 1 query satisfies (
ˆ
L 6|=
ˆ
W
∗
) ∧ (
ˇ
L 6|=
ˇ
W
∗
); a type
2 query satisfies (
ˆ
L |=
ˆ
W
∗
) ∧ (
ˇ
L 6|=
ˇ
W
∗
); and a type 3
query satisfies (
ˆ
L 6|=
ˆ
W
∗
) ∧ (
ˇ
L |=
ˇ
W
∗
).
• Type 1 or Type 2: B picks a random value ξ
′
in
Z
∗
p
. After that, it picks a random value s
i
in Z
∗
p
for all i ∈ [ ˆn]. It computes s =
∑
ˆn
i=1
s
i
and D =
g
s−ξ
′
. It then picks random values λ
i
in Z
∗
p
for all
i ∈ [ ˆn] and computes D
i,0
= g
s
i
· A
λ
i
i,
ˆ
L
i
and D
i,1
=
g
λ
i
. In Type 1 and Type 2,
ˇ
L 6|=
ˇ
W
∗
is satisfied.
Therefore, B can set
∑
i∈[ ˇn]
t
i,
ˇ
L
i
= T
1
+ T
2
α, where
T
2
6= 0 (The probability of T
2
= 0 is negligible and
it has no influence on the security proof, so we
will omit this case. See (Emura et al., 2009).). B
can compute T
1
and T
2
by using {b
i, j
}
i∈[ ˇn],j∈[ ˇn
i
]
.
It picks a random value u
′
in Z
∗
p
and computes
D
′
1
= g
ξ
′
· g
u
′
1
· g
T
1
u
′
T
2
· g
−
T
1
T
2
2
and D
′
2
= g
u
′
T
2
· g
−
1
T
2
2
.
• Type 3: B picks random values ξ and u in Z
∗
p
and
computes D
′
1
= g
−ξ
· (
∏
i∈[ ˇn]
T
i,
ˇ
L
i
)
u
and D
′
2
= g
u
.
In Type 3,
ˆ
L 6|=
ˆ
W
∗
is satisfied. Therefore, there
exists the index k such that
ˆ
L
k
6∈
ˆ
W
k
. B picks
random values s
i
in Z
∗
p
for all i ∈ [ ˆn]\k. Then,
it picks random values λ
i
in Z
∗
p
and computes
D
i,0
= g
s
i
· A
λ
i
i,
ˆ
L
i
and D
i,1
= g
λ
i
. It picks random
values s
′
k
and λ
′
k
in Z
∗
p
for the index k such
that
ˆ
L
k
6∈
ˆ
W
k
and computes D = g
−s
′
k
−
∑
i∈[ ˆn]\k
s
i
+ξ
,
D
k,0
= g
λ
′
k
1
· g
s
′
k
, and D
k,1
= g
λ
′
k
a
k,
ˆ
L
k
· g
1
a
k,
ˆ
L
k
2
.
Finally, B computes SK
[
ˆ
L,
ˇ
L]
= h
ˆ
L,
ˇ
L, D ·
∏
i∈[ ˆn]
D
i,0
·
D
′
1
, {D
i,1
}
i∈[ ˆn]
, D
′
2
i and returns SK
[
ˆ
L,
ˇ
L]
to A .
Lemma 1. SK
[
ˆ
L,
ˇ
L]
is distributed identically to that in
the real IND-CPA game.
We will prove Lemma 1 after showing the advantage
of B.
Challenge: A transmits two messages M
0
and M
1
to B . B picks a random bit η ∈ {0,1} and computes
C
1
= M
η
· R, C
2
= g
3
, and C
3
= g
∑
i∈[ ˇn]
b
i,
ˇ
W
∗
i
3
. It then
computes C
i, j
= g
a
i, j
3
for all i ∈ [ ˆn] and j ∈
ˆ
W
∗
i
. It
returns the challenge ciphertext C
ˆ
W
∗
,
ˇ
W
∗
= h
ˆ
W
∗
,
ˇ
W
∗
,
C
1
, C
2
, C
3
, {C
i, j
}
i∈[ ˆn], j∈
ˆ
W
∗
i
i to A.
PartiallyWildcardedAttribute-basedEncryptionandItsEfficientConstruction
343

Lemma 2. If R = e(g,g)
αβγ
, C
ˆ
W
∗
,
ˇ
W
∗
is distributed
identically to the challenge ciphertext in the real IND-
CPA game. Otherwise, A can obtain no information
about η.
this Lemma can be proved easily since A
i, j
= g
a
i, j
for
all i ∈ [ ˆn], j ∈
ˆ
W
∗
i
and T
i, j
= g
b
i, j
for all i ∈ [ ˇn] if j =
ˇ
W
∗
i
. Hence, we will omit the proof.
Phase 2: Same as Phase 1.
Guess: A outputs η
′
. B outputs δ
′
= 1 if η = η
′
.
Otherwise, B outputs δ
′
= 0.
B outputs δ
′
= 1 iff A can predict the value of η.
When R = e(g,g)
αβγ
, B completely simulates the
IND-CPA game for A . In contrast, when R is a ran-
dom element in G
T
, the value of η is information-
theoretically hidden, so the probability that A can pre-
dict the value of η is 1/2. Hence, Pr[δ
′
= 1|δ = 1] =
Adv
CPA
A
(k) +
1
2
and Pr[δ
′
= 1|δ = 0] =
1
2
. That is, the
advantage of B solving the DBDH problem is as fol-
lows:
Pr[δ
′
= 1|δ = 1] − Pr[δ
′
= 1|δ = 0]
= Adv
CPA
A
(k)
If Adv
CPA
A
(k) is non-negligible, B has non-negligible
advantage for the DBDH problem, which contradicts
the DBDH assumption. Therefore, in the selective
IND-CPA game for our scheme, the advantage of A
is negligible. Hence, Theorem 1 holds.
Proof. To prove Lemma 1, we show that SK
[
ˆ
L,
ˇ
L]
gen-
erated by B satisfies the following equations:
SK
[
ˆ
L,
ˇ
L]
= h
ˆ
L,
ˇ
L,D
′′
,{D
i,1
}
i∈[ ˆn]
,D
′
2
i (1)
where D = g
w−s+ξ
(2)
D
i,0
= g
s
i
· A
λ
i
i,
ˆ
L
i
for all i ∈ [ ˆn] (3)
D
i,1
= g
λ
i
for all i ∈ [ ˆn] (4)
D
′
1
= g
−ξ
· g
u·
∑
i∈[ ˆn]
t
i,
ˆ
L
i
(5)
D
′
2
= g
u
(6)
D
′′
= D·
∏
i∈[ ˆn]
D
i,0
· D
′
1
(7)
where s =
∑
ˆn
i=1
s
i
and w = αβ.
• Type 1 or Type 2: By setting −ξ
′
= αβ + ξ, it be-
comes obvious that D, D
i,0
, and D
′
1
respectively
satisfy equations (2), (3), and (4). These computa-
tions do not require g
αβ
, so B can easily compute
them. Next, D
′
1
and D
′
2
can be computed as fol-
lows by setting −ξ = αβ + ξ
′
and u
′
= β + uT
2
.
D
′
1
= g
ξ
′
· g
u
′
1
· g
T
1
u
′
T
2
· g
−
T
1
T
2
2
= g
ξ
′
· g
αu
′
· g
T
1
·
u
′
−β
T
2
= g
ξ
′
· g
α(β+uT
2
)
· g
uT
1
= g
(αβ+ξ
′
)
· g
u(T
1
+T
2
α)
= g
−ξ
· g
u·
∑
i∈[ ˆn]
t
i,
ˆ
L
i
D
′
2
= g
u
′
T
2
· g
−
1
T
2
2
= g
β+uT
2
T
2
· g
−
β
T
2
= g
u
where
∑
i∈[ ˇn]
t
i,
ˇ
L
i
= T
1
+ T
2
α from the conditions
of Type 1 and Type 2. ξ
′
and u
′
are uniformly and
randomly chosen, so ξ and u are also uniformly
and randomly distributed, and D
′
1
and D
′
2
satisfy
the above equations. Therefore, D
′
1
and D
′
2
sat-
isfy equations (5) and (6). Hence, SK
[
ˆ
L,
ˇ
L]
gen-
erated by B satisfies equation (1), and Lemma 1
holds.
• Type 3: It is obvious that D
′
1
and D
′
2
satisfy equa-
tions (5) and (6) since their computations are sim-
ilar to equations (5) and (6) without g
αβ
. As a
result, it is obvious that {D
i,0
,D
i,1
}
i∈[ ˆn]\k
, where
k is an index wherein
ˆ
L
k
6∈
ˆ
W
k
, satisfies equations
(3) and (4) since their computations are similar
to equations (3) and (4) without g
αβ
. D, D
k,0
,
and D
k,1
can be computed as follows by setting
−s
′
k
= αβ − s
k
, λ
′
k
= a
k,
ˆ
L
k
λ
k
− β.
D = g
−s
′
k
−
∑
i∈[ ˆn]\k
s
i
+ξ
= g
αβ−s
k
−
∑
i∈[ ˆn]\k
s
i
+ξ
= g
w−s+ξ
D
k,0
= g
λ
′
k
1
· g
s
′
k
= g
α(−β+a
k,
ˆ
L
k
λ
k
)
· g
s
′
k
= g
−αβ+s
′
k
· g
a
k,
ˆ
L
k
λ
k
1
= g
s
k
· A
λ
k
k,
ˆ
L
k
D
k,1
= g
λ
′
k
a
k,
ˆ
L
k
· g
1
a
k,
ˆ
L
k
2
= g
λ
′
k
+β
a
k,
ˆ
L
k
= g
λ
k
s
′
k
is uniformly and randomly chosen, so s
k
is
also uniformly and randomly distributed and D,
D
k,0
, and D
k,1
satisfy the above equations. There-
SECRYPT2013-InternationalConferenceonSecurityandCryptography
344
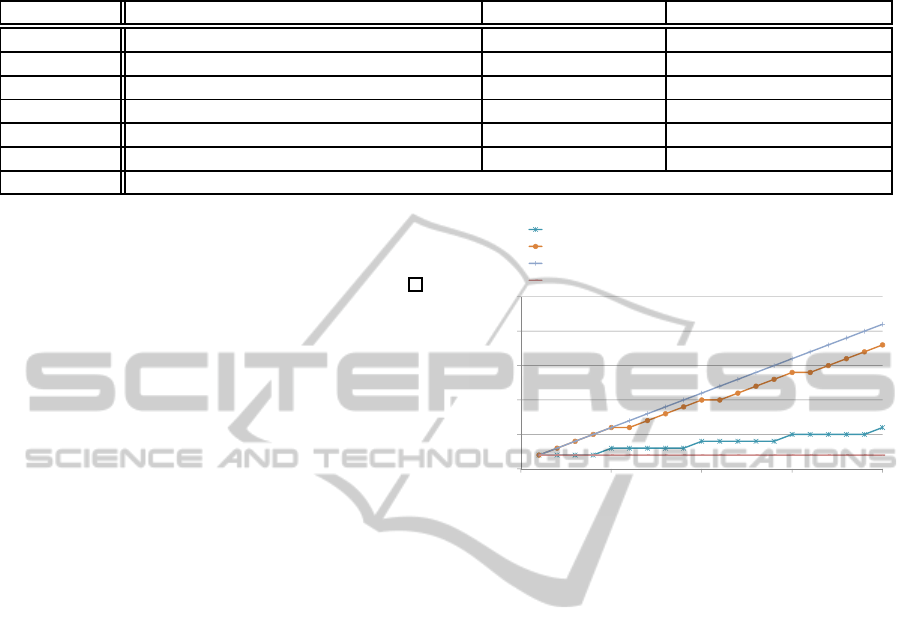
Table 1: Comparison of our scheme and conventional CP-ABE schemes. (See Section 5.1 for the notation.)
Modified scheme of (Nishide et al., 2008) (Emura et al., 2009) Our scheme
|PK| (n
s
+ 1)|G| + |G
T
| (n
s
+ 2)|G| + |G
T
| (n
s
+ 1)|G| + |G
T
|
|SK| (n+ 1)|G| 2|G| (θn+ 2)|G|
|CT| (m
s
+ 1)|G| + |G
T
| 2|G| + |G
T
| ( ˆm
s
+ 2)|G| + |G
T
|
Enc (m
s
+ 1)M
G
+ M
G
T
(n+ 1)M
G
+ M
G
T
(θn+ ˇm
s
+ 1)M
G
+ M
G
T
Dec (n+ 1)P 2P (θn+ 2)P
Wildcard yes (for all attributes) no yes (for partial attributes)
Assumption DBDH
fore, D, D
k,0
, and D
k,1
respectively satisfy equa-
tions (2), (3), and (4). Hence, SK
[
ˆ
L,
ˇ
L]
generated by
B satisfies equation (1), and Lemma 1 holds.
5 PERFORMANCE
5.1 Cost Comparison
Table 1 compares our schemes with the modified
scheme of (Nishide et al., 2008) and the scheme pre-
sented in (Emura et al., 2009). In this table, |PK| de-
notes the size of the public key, |SK| the size of the
secret key, |CT| the size of the ciphertext, Enc the en-
cryption cost, and Dec the decryption cost. |G| and
|G
T
| denote the size of the elements in G and G
T
,
respectively. n is the number of attributes A, ˆn the
number of attributes
ˆ
A that require wildcards, and ˇn
the number of attributes
ˇ
A that do not require wild-
cards. θ denotes the proportion of attributes which
require wildcards, and 0 ≤ θ ≤ 1. n
s
=
∑
n
i=1
n
i
, where
n
i
denotes the number of possible values for attribute
A
i
. ˆn
s
=
∑
ˆn
i=1
ˆn
i
, where ˆn
i
denotes the number of
possible values for attribute
ˆ
A
i
which require wild-
cards, and ˇn
s
=
∑
ˇn
i=1
ˇn
i
, where ˇn
i
is the number of
possible values for attribute
ˇ
A
i
which do not require
wildcards. m
s
=
∑
n
i=1
m
i
, where m
i
means the number
of attribute values in a policy W
i
such that m
i
≤ n
i
.
ˆm
s
=
∑
ˆn
i=1
ˆm
i
, where ˆm
i
denotes the number of at-
tribute values in a policy
ˆ
W
i
that require wildcards and
ˆm
i
≤ ˆn
i
. ˇm
s
=
∑
ˇn
i=1
ˇm
i
, where ˇm
i
denotes the number
of attribute values in a policy
ˇ
W
i
that do not require
wildcards and ˇm
i
≤ ˇn
i
. M
G
and M
G
T
denote modulo
exponentiation in G and G
T
, respectively. P denotes
a pairing computation on an elliptic curve.
Figure 1 compares the processing times for de-
cryption. The number of attributes is the horizontal
axis and the processing time for decryption is the ver-
tical axis. We assume that the processing time for
one pairing computation is 10 (msec) (Zhang et al.,
2008). The graphs for our scheme correspond to the
case of θ = 0.2 and that of θ = 0.8. Figure 1 clearly
is also
0
,
satisfy the above equations. Therefore,
respectively satisfy equations
generated by
Table 1 compares our schemes with the modified
scheme of (Nishide et al., 2008) and the scheme pre-
ϮϬϬ
ϮϱϬ
WƌŽĐĞƐƐŝŶŐƚŝŵĞĨŽƌĚĞĐƌLJƉƚŝŽŶ;ŵƐĞĐͿ
KƵƌƐĐŚĞŵĞ;ɽсϬ͘ϮͿ
KƵƌƐĐŚĞŵĞ;ɽсϬ͘ϴͿ
DŽĚŝĨŝĞĚƐĐŚĞŵĞŽĨ;EŝƐŚŝĚĞĞƚĂů͕͘ϮϬϬϴͿ
;ŵƵƌĂĞƚĂů͕͘ϮϬϬϵͿ
Ϭ
ϱϬ
ϭϬϬ
ϭϱϬ
Ϭ ϱ ϭϬ ϭϱ ϮϬ
WƌŽĐĞƐƐŝŶŐƚŝŵĞĨŽƌĚĞĐƌLJƉƚŝŽŶ;ŵƐĞĐͿ
EƵŵďĞƌŽĨĂƚƚƌŝďƵƚĞƐ
Figure 1: Processing time for decryption in CP-ABE
Figure 1: Processing time for decryption in CP-ABE
schemes.
shows that the processing time for decryption in our
scheme is short when the proportion of attributes re-
quiring wildcards is small.
5.2 Application
A content distribution service is a potential applica-
tion of our scheme. Let us assume that users have
four attributes: residence, membership, contract in-
formation, and gender. First, the user’s attributes are
classified according to the need of wildcards as fol-
lows:
(Attribute with wildcard)
ˆ
A
1
: residence
ˆ
S
1
= {1, 2,...,47} = {Hokkaido, Aomori, ..., Oki-
nawa}
(Attribute without wildcard)
ˇ
A
1
: membership
ˇ
S
1
= {1, 2} = {general, premium}
ˇ
A
2
: contract information
ˇ
S
2
= {1, 2} = {payer, non-payer}
ˇ
A
3
: gender
ˇ
S
3
= {1, 2} = {male, female}
PartiallyWildcardedAttribute-basedEncryptionandItsEfficientConstruction
345

Our scheme can realize a regionally restricted con-
tent distribution service. In Japan, there are 47 pre-
fectures, so we assign them to possible values for
ˆ
A
1
. We also allow two kinds of membership, general
and premium, as possible values for
ˇ
A
1
, two kinds
of contract information, payer and non-payer, as pos-
sible values for
ˇ
A
2
, and two genders, male and fe-
male, as possible values for
ˇ
A
3
. For example, when
a service provider encrypts a piece of content with
the policy
ˆ
W
1
= {Tokyo, Kanagawa, Saitama, Chiba,
Gunma, Tochigi, Ibaraki}, which means the Kanto
region, a user who has the attribute
ˆ
L
1
= Tokyo can
decrypt the content but a user who has the attribute
ˆ
L
1
= Osaka cannot decrypt the content. In this case,
n = 4 and θ = 0.25. Therefore, the decryption cost is
5P in the modified scheme of (Nishide et al., 2008)
and 3P in our scheme, respectively, which means that
our scheme can reduce the decryption cost by 40%
in comparison with the modified scheme of (Nishide
et al., 2008).
For attribute
ˇ
A
1
, a service provider must encrypt
content with either
ˇ
W
1
= general or
ˇ
W
1
= premium.
If the service provider allows both general members
and premium members to decrypt a content, they must
transmit two corresponding ciphertexts to users (For
the other attributes
ˇ
A
2
and
ˇ
A
3
, the service provider
must do the same as the above.). If the number of
possible values for an attribute is large, the wildcard
functionality is effective. On the other hand, if the
number of possible values for an attribute is small, the
service provider should employ such a trivial scheme
rather than use wildcards to reduce total costs. That
is, the service provider should transmit as many ci-
phertexts as possible attribute values to users.
Table 2 is a numerical comparison of the schemes
described in Table 1. Several parameters are set
according to the above content distribution service:
|G| = 176 (bits), |G
T
| = 1056 (bits), M
G
= 5 (msec),
M
G
T
= 8 (msec), P = 10 (msec), n = 4, ˆn = 1, ˇn = 3,
θ = 0.25, n
s
= 53, m
s
= 10, ˆn
s
= 47, ˆm
s
= 7, ˇn
s
= 6,
and ˇm
s
= 3. As shown in Table 2, our scheme is more
efficient than the modified scheme of (Nishide et al.,
2008).
6 CONCLUSIONS
We proposed a partially wildcarded CP-ABE scheme.
We compared our scheme with conventional CP-ABE
schemes and described a content distribution service
as an application of our scheme. The result showsthat
our scheme can reduce the decryption cost in compar-
ison with the conventional CP-ABE schemes.
Table 2: Numerical comparison of our scheme and conven-
tional CP-ABE schemes. M-NYO08 denotes the modified
scheme of (Nishide et al., 2008) and EMNOS09 denotes the
scheme in (Emura et al., 2009).
M-NYO08 EMNOS09 Ours
|PK| (bits) 10,560 10,736 10,560
|SK| (bits) 880 352 528
|CT| (bits) 2,992 1,408 2,640
Enc (msec) 63 33 33
Dec (msec) 50 20 30
REFERENCES
Bethencourt, J., Sahai, A., and Waters, B. (2007).
Ciphertext-policy attribute-based encryption. In IEEE
Symposium on Security and Privacy, pages 321–334.
Cheung, L. and Newport, C. (2007). Provably secure ci-
phertext policy abe. In ACMCCS’07, pages 456–465.
Emura, K., Miyaji, A., Nomura, A., Omote, K., and Soshi,
M. (2009). A ciphertext-policy attribute-based en-
cryption scheme with constant ciphertext length. In
ISPEC, pages 13–23.
Goyal, V., Pandey, O., Sahai, A., and Waters, B. (2006).
Attribute-based encryption for fine-grained access
control of encrypted data. In ACMCCS, pages 89–98.
Katz, J., Sahai, A., and Waters, B. (2008). Predicate encryp-
tion supporting disjunctions, polynomial equations,
and inner products. In Eurocrypt, pages 146–162.
Lewko, A., Okamoto, T., Sahai, A., Takashima, K., and
Waters, B. (2010). Fully secure functional encryp-
tion: Attribute-based encryption and (hierarchical) in-
ner product encryption. In Eurocrypt, pages 62–91.
Nishide, T., Yoneyama, K., and Ohta, K. (2008). Attribute-
based encryption with partially hidden encryptor-
specified access structures. In ACNS, pages 111–129.
Okamoto, T. and Takashima, K. (2010). Fully secure func-
tional encryption with general relations from the deci-
sional linear assumption. In Crypto, pages 191–208.
Ostrovsky, R., Sahai, A., and Waters, B. (2007). Attribute-
based encryption with non-monotonic access struc-
tures. In ACMCCS, pages 195–203.
Sahai, A. and Waters, B. (2005). Fuzzy identity-based en-
cryption. In Eurocrypt, pages 457–473.
Waters, B. (2011). Ciphertext-policy attribute-based en-
cryption: An expressive, efficient, and provably se-
cure realization. In PKC, pages 53–70.
Zhang, Y., Kanayama, N., and Okamoto, E. (2008). Java
implementation of pairing on elliptic curves over F
2
m
(in japanese). In CSS, pages D2–1.
SECRYPT2013-InternationalConferenceonSecurityandCryptography
346
