
Diagnostic Category Leakage in Helper Data Schemes for Biometric
Authentication
Joep de Groot
1
, Boris
ˇ
Skori´c
2
, Niels de Vreede
2
and Jean-Paul Linnartz
1
1
Signal Processing Systems, Eindhoven University of Technology, Eindhoven, The Netherlands
2
Security and Embedded Networked Systems, Eindhoven University of Technology, Eindhoven, The Netherlands
Keywords:
Biometrics, Secrecy Leakage, Privacy Leakage, Helper Data Scheme, Template Protection.
Abstract:
A helper data scheme (HDS) is a cryptographic primitive that extracts a high-entropy noise-free secret string
from noisy data, such as biometrics. A well-known problem is to ensure that the storage of a user-specific
helper data string in a database does not reveal any information about the secret. Although Zero Leakage
Systems (ZSL) have been proposed, an attacker with a priori knowledge about the enrolled user can still
exploit the helper data. In this paper we introduce diagnostic category leakage (DCL), which quantifies what
an attacker can infer from helper data about, for instance, a particular medical indication of the enrolled
user, her gender, etc. The DCL often is non-zero. Though small per dimension, it can be problematic in
high-dimensional biometric authentication systems. Furthermore, partial a priori knowledge on of medical
diagnosis of the prover can leak about the secret.
1 INTRODUCTION
Nowadays authentication and identification applica-
tions rely more and more on biometrics, since it
is considered a convenient solution and difficult to
forge. Contrary to passwords and tokens biometrics
cannot be forgotten or lost, but are inherently bound
to the user. They truly identify who someoneis, rather
than what somebody knows or possesses.
It will be difficult to keep biometrics strictly se-
cret. For example, a face or iris can be captured as a
photographic image unnoticed. Whereas a user’s fin-
gerprints can be found on many daily objects. How-
ever, in-the-clear storage of templates extracted from
the biometric is out of the question, since that will
make it very easy for an adversary to misuse them.
Roughly the problems introduced by storing bio-
metric features can be split into security and privacy
risks (Jain et al., 2005). The former include the repro-
duction of fake biometrics from the stored features,
e.g. rubber fingers (Matsumoto et al., 2002). These
fake biometrics can cause serve security issues, e.g.
to obtain unauthorized access to information or ser-
vices or to leave fake evidence at crime scenes. Such
actions are commonly known as identity theft.
On the other hand there are privacy risks bound to
the application of biometrics (Labatiet al., 2012). The
most sensitive are: (i) some biometrics might reveal
diseases and disorders of the user and (ii) unprotected
storage allows for cross-matching between databases.
Helper data schemes (HDS) (Juels and Watten-
berg, 1999; Linnartz and Tuyls, 2003; Dodis et al.,
2004; Juels and Sudan, 2006; Chen et al., 2007) have
been proposed to ensure that hashes of biometrics can
be stored, such that even during verification no in-
the-clear biometric templates can be retrieved from
a database. These schemes exploit a prover-specific
variable, called the helper data to ensure reliable ex-
act digital reproducibility of a biometric value.
Zero Secrecy Leakage (ZSL) helper data schemes
have been proposed (Verbitskiy et al., 2010; de Groot
and Linnartz, 2011; de Groot and Linnartz, 2012), to
ensure that the mutual information between the helper
data and the secret key is zero. However, it has been
recognized that this property does not fully ensure to-
tal protection of the prover’s privacy.
Ignatenko and Willems (Ignatenko and Willems,
2009) introduced the notion of privacy leakage, de-
fined as the mutual information between helper data
and the biometricvalue it self as opposedto the helper
data and the secret. Yet we are not aware of any paper
that confirms the severity of the theoretical privacy
leakage in terms of how much valuable information
the attacker actually gets about the prover. If for in-
stance the biometric is the length of a person, many
helper data schemes, such as (de Groot and Linnartz,
506
de Groot J., Skoric B., de Vreede N. and Linnartz J..
Diagnostic Category Leakage in Helper Data Schemes for Biometric Authentication.
DOI: 10.5220/0004524205060511
In Proceedings of the 10th International Conference on Security and Cryptography (SECRYPT-2013), pages 506-511
ISBN: 978-989-8565-73-0
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

2011), leak that the last decimals of the value, for in-
stance are 593, but give no clue about whether it is
an 1.63593 meter small person or 1.93593 meter tall
person. In this paper we address the question whether
such leakage is serious. For instance if we know from
the helper data of a cyclist that his heart rate is equal
to an unknown integer plus some known fraction, how
much does that tell us about the likelihood of an en-
larged EPO concentration in his blood. In this paper
we analyze such questions.
Another form of key or privacy leakage (de Groot
and Linnartz, 2011) can occur when the attacker has
a priori knowledge about the prover, or about any per-
son in the data base. For instance that the cyclist is a
28 year old female.
Our current paper has been motivated by an im-
plementation project that records data from epileptic
patients from body sensor networks, with biometric
configuration of the radio links. Here we encountered
the question of how severe such issues are for practi-
cal biometrics.
We perform a security analysis for three important
scenarios. (i) The case of a mismatch between the true
distribution of the features x and the distribution used
for creating helper data w. The attacker is assumed to
know the true distribution. (ii) An attacker who has
partial information about enrolled users, e.g. a medi-
cal indication or gender, and tries to learn something
about the stored secret. (iii) An attacker who tries to
learn something about the enrolled user’s characteris-
tics by exploiting the public helper data and some a
priori partial information about the user.
These scenarios lead to a mismatch between the
distribution as seen by the attacker and the distribu-
tion used to make w. The question is how much the
ZSL helper data w leaks under these circumstances,
in addition to the already existing leakage. We prove
an upper bound on this additional leakage.
2 ZERO SECRECY LEAKAGE
SCHEME
We consider a commonly accepted verification
scheme which consists of an enrollment and verifi-
cation phase. In the enrollment phase the prover pro-
vides his biometric data x = (x
0
,...,x
M− 1
). From this
data, the system extracts a secret s
= Q(x), which the
system stores safely in the hashed form (h(skz),w),
where w is the helper data, which is generated as
w
= g(x) and z is the salt. The salt is a system
and/or user specific random string to prevent cross-
matching between different databases. In the verifica-
tion phase the prover provides his correlated biomet-
ric data y
= (y
0
,...,y
M− 1
) to prove his identity. All
variables, except for the salt z, are length M vectors
extracted by some means of preprocessing, to ensure
that the components are (nearly) independent, but not
necessarily identically distributed. Independence can
be obtained by for example applying a principle com-
ponent analysis (PCA) to the raw data.
Analysis will be carried out per dimension since
we have assumed the features to be independent. In
this case the total leakage in a verification scheme will
be a summation of the leakage per dimension. For
clarity notation of the biometric feature x, secret s and
helper data w will be without subscript i.
Initially, leakage elimination has been studied
(Verbitskiy et al., 2010) for secret values that are
equiprobable (Fuzzy Extractor). Each interval be-
longing to a secret is then subdivided in equiproba-
ble intervals to define the helper data. The helper data
intervals are repeated for each interval of the secrets.
This construction yields helper data whose probabil-
ity is independent of the enrolled secret.
Meanwhile, it has been argued that verification
performance highly depends of effective quantiza-
tion of the analog (continuous valued) biometrics and
continuous-valued helper data within the quantiza-
tion intervals (Linnartz and Tuyls, 2003; Chen et al.,
2007). Also in this domain, leakage is a concern
(de Groot and Linnartz, 2011; de Groot and Linnartz,
2012). Instead of demanding equiprobable discrete
values as helper data, helper data w is defined as a
continuousvariable that indicates the relative position
of the enrollment feature x within a quantization in-
terval belonging to a secret s. To achieve ZSL the
scheme has to take into account the probability den-
sity of the features. ZSL is achieved in this case by
s = Q(x) = ⌊N · F
X
(x)⌋, (1)
w = g(x) = N · F
X
(x) − s (2)
in which N is the number of quantization intervals
and F
X
is the cumulative distribution function (CDF)
of feature x. The number of quantization intervals N
does not necessarily have to be a power of 2.
The above construction yields a continuous helper
data w that reveals no information about the enrolled
secret s. In fact one can only reconstruct N possible x
values, each in a different quantization interval. This
reconstruction is given by
x
s
(w) = F
−1
X
s+ w
N
(3)
In this work we will limit ourselves to a leakage
analysis on the continuous scheme only, since the dis-
crete scheme can be considered a special case of the
continuous version.
DiagnosticCategoryLeakageinHelperDataSchemesforBiometricAuthentication
507

3 LEAKAGE ANALYSIS
For the leakage analysis presented in this section we
will make a distinction between a priori leakage and
additional leakage due to the public helper data. The
former is solely due to the assumed improved under-
standing of the biometric features by the attacker and
assumes the attacker does not yet exploit the informa-
tion in the helper data. Whereas the latter is this pos-
sible “bonus” due to exploiting the combination of a
priori knowledge and public helper data.
3.1 Mismatch Between the Real and
Assumed Distribution
The distribution f
sys
(x) used by the authentication
system is not exactly equal to the real distribution f
X
of X. When the system is set up, the statistical knowl-
edge about X is based on a finite number of observa-
tions, from which f
sys
is derived. Due to finite size
effects a (small) mismatch between f
X
and f
sys
arises.
It is prudent to assume that attackers have full knowl-
edge of f
X
, e.g. due to scientific progress after the
system has been fixed. Given this mismatch, the prob-
abilities for S and W are derived as follows. First of
all we can derive the joint density of the helper data
and secret as
χ(s,w) =
1
N
f
X
(x
s
(w))
f
sys
(x
s
(w))
(4)
which follows from f
X
(x)dx = χ(s,w)dw and
dx = dw/[N f
sys
(x)] evaluated at x = x
s
(w). The prob-
ability of the secrets follows from integrating f
X
be-
tween the boundary points that correspond to S = s,
hence
χ(s) = P(S = s) = F
X
(x
s
(1)) − F
X
(x
s
(0)). (5)
Finally, the marginal
χ(w) =
1
N
N−1
∑
s=0
f
X
(x
s
(w))
f
sys
(x
s
(w))
(6)
follows from (4) by summing over s. These probabil-
ity functions can subsequently be used to determine
the leakage
I(S;W) =
∑
s
1
Z
0
χ(s,w)log
2
χ(s,w)
χ(s)χ(w)
dw, (7)
in which I stands for mutual information.
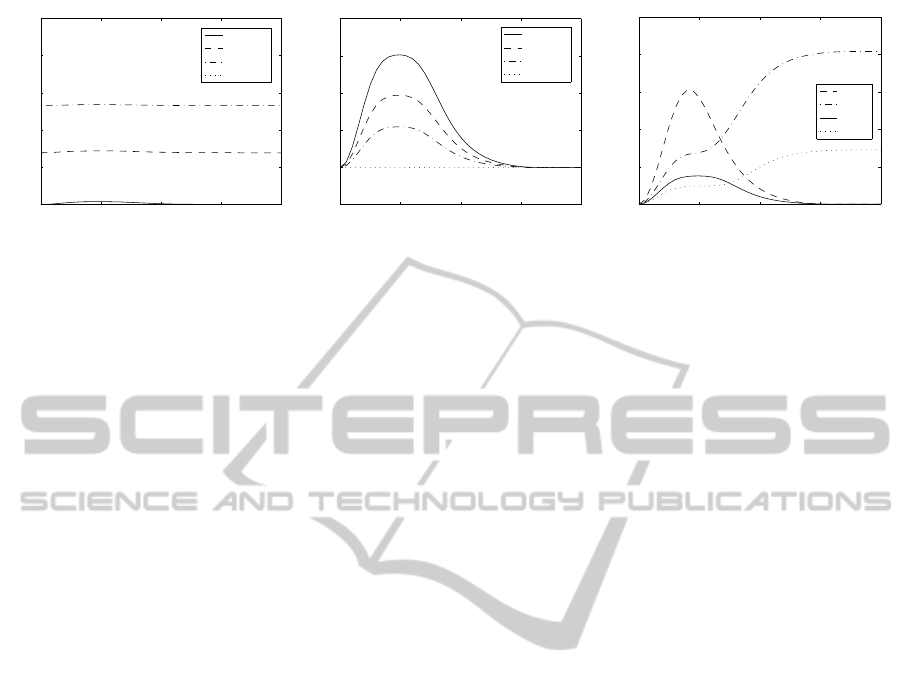
An example for such leakage is given in Figure 1.
This particular example assumes both distributions,
real and assumed, to be Gaussian and the number of
quantization intervals N = 4.
True distribution’s µ
True distribution’s σ
2
Leakage I(S; W|µ, σ
2
)
-2
-1
0
10
−2
10
−1
10
0
10
1
0
0.5
1
Figure 1: Additional leakage due to mismatch between real
distribution and assumed distribution for N = 4. Only for
(µ,σ
2
) = (0,1) the leakage is zero.
3.2 Related Property Known by
Attacker
There is another source of leakage. It may happen
that the statistics of the measured quantity x depend
on, e.g. the gender of the enrolled users, skin color,
medical diagnosis, or some other (discrete) property.
This idea has been motivated by results from a
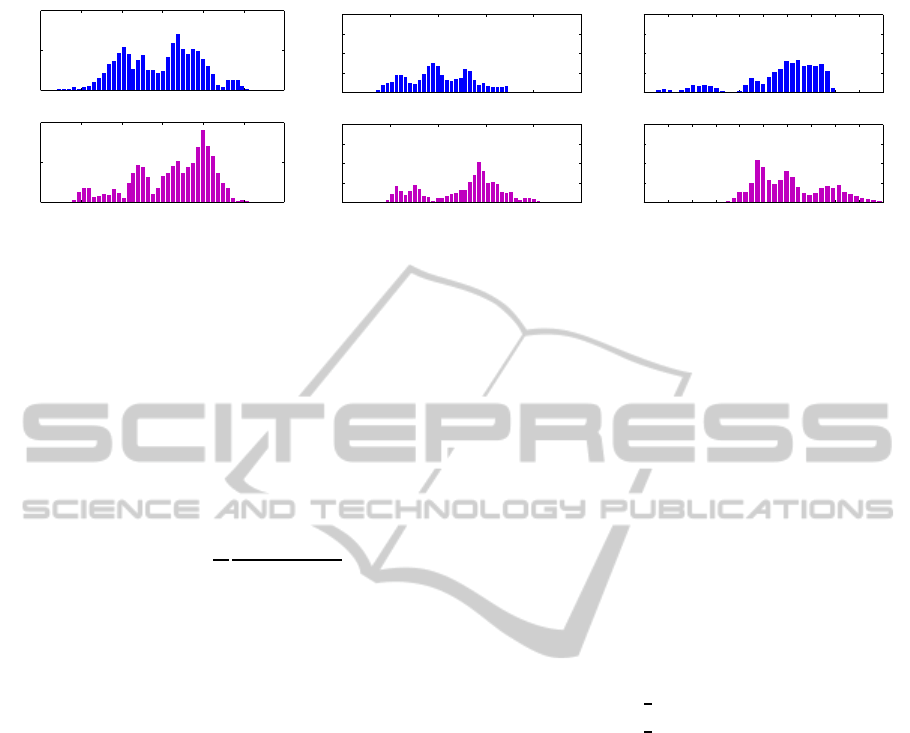
biometric verification experiment with ECG signals.
The extracted features showed a clear divergence
when sorted by gender. A few striking examples are
depicted in Figure 2. These features were obtained by
calculating autocorrelation (AC) on 1 minute epochs
and subsequently applying a discrete cosine transform
(DCT) (Agrafioti and Hatzinakos, 2008).
We will consider a general discrete category C ∈
C . We ask ourselves the question whether an attacker
can gain an advantage from some observation
˜
C ∈ C
which yields (partial) knowledge about the category
C. One can think of
˜
C as an estimate derived from an
observation for a specific person, e.g. gait or height,
or an observation of the whole enrolled population,
e.g. the percentage of men vs. women. For example
the observation could be a 1.9m tall person, which
might give rise to the assumption it is a man, since
men are usually taller than women. However, we
might be dealing with an exceptionally tall woman.
We will investigate two attack scenarios:
1. Secret Estimation
The attacker wants to leverage the side informa-
tion to derive a better guess for an enrolled per-
son’s secret S. In this scenario the mutual infor-
mation I(S;W,
˜
C) is the quantity of interest.
2. Category Estimation
Based on the side information, the attacker wants
to diagnose an enrolled person’s categoryC (med-
ical indication). In fact we generalize this to any
SECRYPT2013-InternationalConferenceonSecurityandCryptography
508
biometric feature x
probability
male
biometric feature x
probability
female
0 0.5
1
1.5
2 2.5
3
0
0.5 1
1.5
2
2.5 3
0
0.05
0.1
0
0.05
0.1
(a) DCT coefficient 2.
biometric feature x
probability
male
biometric feature x
probability
female
0
0.5
1 1.5
2
2.5
0 0.5
1
1.5
2 2.5
0
0.05
0.1
0.15
0.2
0
0.05
0.1
0.15
0.2
(b) DCT coefficient 4.
biometric feature x
probability
male
biometric feature x
probability
female
0.2 0.4
0.6
0.8
1 1.2
1.4
1.6
1.8 2
2.2
0.2
0.4 0.6
0.8
1
1.2 1.4
1.6
1.8
2 2.2
0
0.05
0.1
0.15
0.2
0
0.05
0.1
0.15
0.2
(c) DCT coefficient 5.
Figure 2: Examples of deviating distributions per gender in a ECG based verification experiment.
privacy sensitive category including gender, race,
etc. Here the quantity of interest is I(C;W,
˜
C).
For given c, we have to consider the f
X
(x) in (4)
to f
X|C
(x|c). The f
X
(x) remains unchanged, since the
enrollment is done without regard to categories. Note
that S andW have no additional dependence on C. By
using the joint probability Q
c˜c
of c and ˜c and the chain
rule χ(s,w,c, ˜c) = Q
c˜c
χ(s,w|C = c) we can write
χ(s,w,c, ˜c) = Q
c˜c
1
N
f
X|C
(x
s
(w)|c)
f
X
(x
s
(w))
. (8)
From (8) we can derive all the marginal distribu-
tions that are necessary for computing I(S;W,
˜
C) and
I(C;W,
˜
C). Some examples assuming Gaussian distri-
butions are depicted in Figure 3(a) and Figure 4(a).
3.2.1 Bound on the Secrecy Leakage
We will show that the total amount of information that
can be obtained is very limited. The expression of
the mutual information between enrolled secret s and
public data, i.e. helper data w and category estimate
˜c, can be split in two terms
I(S;W,
˜
C) = I(S;W) + I(S;
˜
C|W). (9)
Since the scheme is a zero leakage key extraction
scheme, i.e. I(S;W) = 0, it follows that
I(S;W,
˜
C) = I(S;
˜
C|W) ≤ H(
˜
C|W) ≤ H(
˜
C) (10)
where H stands for Shannon entropy and I for mu-
tual information. Therefore we can conclude that the
secrecy leakage satisfies
I(S;W,
˜
C) ≤ H(
˜
C). (11)
This bound, which limits the amount of informa-
tion about the secret that can be obtained in a ZSL
scheme, is limited by the entropy in the category esti-
mate and is independent of the public helper data and
the type of ZSL scheme. If an attacker for example
knows the gender of an enrolled user, he can never
learn more than 1 bit even if the secret is more than 1
bit.
4 TOY EXAMPLE: GAUSSIAN
DISTRIBUTIONS
4.1 Secret Estimation
In this section we study the situation that emerges
when an attacker knows
˜
C, i.e. an estimate of the
category C of the enrolled user. For this particular
example we construct the category as a single bit. For
example “0” is male and “1” is female. The estimate
is derived from the actual category with some error
p, which is modeled as a Binary Symmetric Channel
(BSC) with cross-over probability p. We assume that
a priori both categories are equiprobable, thus
Q
c˜c
=
(
1
2
(1− p) c = ˜c
1
2
p c 6= ˜c
. (12)
For the feature distribution we assume a Gaussian
Mixture Model (GMM) with two distributions, which
represent the two categories. The parameters for this
model are set to µ
0
= −µ, µ
1
= µ and σ
2
0
= σ
2
1
= 1.
This mean value parameter µ ≥ 0 will be varied to-
gether with error probability p to study the emerging
leakage in the system.
To calculate x
s
(w) in Eq. (8) we need to calculate
the inverse CDF of the Gaussian mixture as given by
Eq. (3). This has been solved by applying Newton’s
method to the given PDF and CDF of the Gaussian
mixture. For argumentssmaller than 1/2, µ
0
was used
as initial guess and for arguments larger than 1/2, µ
1
,
which ensured a rapid convergence and accurate re-
sults.
The inverse CDF allows us to calculate the joint
probability density function χ(s,w, ˜c) as a function of
w. This marginal is derived from Eq. (8). Subse-
quently we can calculate the secrecy leakage in terms
of mutual information as
DiagnosticCategoryLeakageinHelperDataSchemesforBiometricAuthentication
509

Category offset µ
Secrecy leakage I(S; W,
˜
C)
N = 4
p = 0.00
p = 0.10
p = 0.20
p = 0.30
0 1
2
3
4
0
0.2
0.4
0.6
0.8
1
(a) Leakage by category estimate ˜c and helper data
w.
Category offset µ
Conditional secrecy leakage I(S; W |
˜
C)
N = 4
p = 0.00
p = 0.10
p = 0.20
p = 0.30
0
1 2
3
4
0
0.01
0.02
0.03
0.04
0.05
(b) Component of the leakage due to helper data w
given ˜c.
Category offset µ
Secrecy leakage I(S; W |
˜
C)
p = 0.00
N = 2
N = 3
N = 4
N = 5
0
1
2 3
4
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
(c) Component of the leakage due to helper data w
given ˜c for different number of quantization inter-
vals N.
Figure 3: Leakage of secret S in secret estimation scenario.
I(S;W,
˜
C) =
∑
s, ˜c
1
Z
0
χ(s,w, ˜c)log
2
χ(s,w, ˜c)
χ(s)χ(w, ˜c)
dw.
(13)
At increasing value of µ we observe a clear satu-
ration for the total leakage I(S;W,
˜
C). Moreover, the
better the estimate (p → 0), the more information an
attacker obtains. However, even for µ ≫ 0 and p = 0,
i.e. a perfect category estimate, there is a maximum
leakage of 1 bit, which agrees with the bound found
in Section 3.2.1. The results of this calculation for
different values of p can be found in Figure 3(a).
A distinction can be made between leakage by
a priori knowledge of the category I(S;
˜
C) irrespec-
tive of the helper data and “bonus” leakage I(S;W|
˜
C)
caused by the category estimate ˜c combined with
knowledge of the helper data w. So
I(S;W,
˜
C) = I(S;
˜
C) + I(S;W|
˜
C) (14)
and by doing the numerics for
I(S;W|
˜
C) =
∑
s, ˜c
1
Z
0
χ(s,w, ˜c)log
2
χ( ˜c)χ(s,w, ˜c)
χ(s, ˜c)χ(w, ˜c)
dw
(15)
we can assess the amount of leakage actually caused
by the helper data scheme.
In the special case of symmetric distributions and
an even number of quantization intervals (as assumed
in Figure 3(b)), for µ ≫ 0 it holds that I(S;W|
˜
C) → 0.
This effect is caused by the fact that the two cate-
gory distributions become favorably located over the
quantization intervals. However, for more unfortu-
nate choices, e.g. odd N, this favorable effect is not
present, as can be seen in Figure 3(c).
We conclude that leakage can only be severe for
a pre-informed attacker who has specific a priori
knowledge. However, such a situation closely resem-
bles a situation in which an attacker possesses the bio-
metric feature x itself and not a single ZSL scheme
can protect against such well informed attackers, as
in the limiting case the attacker knows as much as the
verifier.
4.2 Category Estimation
For the scenario that an attacker tries to extract
privacy–sensitive information about a category (e.g
gender, race, epileptic indications, use of certain me-
diation or drugs) to which the prover belongs, we can
obtain similar results. The total information about C
can again be split in a part from the estimate
˜
C and a
part caused by the helper data W as follows
I(C;W,
˜
C) = I(C;
˜
C) + I(C;W|
˜
C). (16)
Most information about the category is obtained from
the category estimate
˜
C. Since we modeled this esti-
mate as a BSC this equals 1 − h(p). In this equation
h(p) is the binary entropy function. This effect can
also be seen in Figure 3(a). The contribution of the
helper data is only partial as confirmed by Figure 4(b).
Also the convergence to zero for µ ≫ 0 only applies
for even N as can be seen in Figure 4(c). In this ex-
ample we have set p = .5, which effectively removes
the a priori knowledge on
˜
C.
However, the leakage as show in Figure 4(b) and
Figure 4(c) might seem small, but this is a leakage per
dimension. An authentication scheme will in general
use more the one dimension and it is not unlikely that
the category under consideration will have influence
on more than a single dimension, as is also confirmed
in Figure 2. In case one wishes to determine a bi-
nary quantity, e.g. gender, with high probability this
could be possible by combining the information from
all available dimensions.
In fact, biometric secret extraction of 64 bits or
more may typically require several tens of dimen-
sions. Although such a system can be secure in terms
of key entropy, it may inadvertently reveal privacy-
sensitive information about the subject and even give
SECRYPT2013-InternationalConferenceonSecurityandCryptography
510
Category offset µ
Category leakage I(C; W,
˜
C)
N = 4
p = 0.50
p = 0.20
p = 0.10
p = 0.00
0 1
2
3
4
0
0.2
0.4
0.6
0.8
1
(a) Leakage by category estimate ˜c and helper data
w.
Category offset µ
Conditional category leakage I(C; W |
˜
C
)
N = 4
×10
−3
p = 0.50
p = 0.20
p = 0.10
p = 0.00
0 1
2
3
4
-5
0
5
10
15
20
(b) Component of the leakage due to helper data w
given ˜c.
Category offset µ
Category leakage I(C; W )
p = 0.50
N = 2
N = 3
N = 4
N = 5
0 1
2
3
4
0
0.02
0.04
0.06
0.08
0.1
(c) Component of the leakage due to helper data w
given ˜c for different number of quantization inter-
vals N.
Figure 4: Leakage of category C in category estimation scenario.
the attacker almost certainty about certain (binary)
medical diagnoses. Using more dimensions from im-
proved biometric feature extraction thus creates a pri-
vacy issue.
5 CONCLUSIONS
We have studied and quantified two kinds of leakage.
The first due to a mismatch that can emerge due to
improved understanding of feature distributions after
the system has been set up, and the second if the at-
tacker knows an enrolled user belongs to a specific
category with a specific feature distribution. We for
the latter we distinguished between the leakage about
the enrolled secret and about the (medical diagnostic,
racial, etc.) category.
From the results we can conclude that most of
the leakage is caused by a priori information and
only little information is revealed by the helper data.
Only situations in which very specific information is
known to the attacker can cause more serious key
leakage. We believe that the Diagnostic Category
Leakage (DCL), which has been introduced in this
paper, can serve as a practical measure for privacy-
sensitive leakage of biometric systems.
REFERENCES
Agrafioti, F. and Hatzinakos, D. (2008). ECG based recog-
nition using second order statistics. In Communication
Networks and Services Research Conference, 2008.
CNSR 2008. 6th Annual, pages 82 –87.
Chen, C., Veldhuis, R., Kevenaar, T., and Akkermans, A.
(2007). Multi-bits biometric string generation based
on the likelihood ratio. In Proc. IEEE Int. Conf. on
Biometrics: Theory, Applications, and Systems.
de Groot, J. and Linnartz, J.-P. (2011). Zero leakage quan-
tization scheme for biometric verification. In Proc.
IEEE Int. Conf. Acoust., Speech, Signal Process.
de Groot, J. and Linnartz, J.-P. (2012). Optimized helper
data scheme for biometric verification under zero
leakage constraint. In Proc of the 33st Symp on Inf
Theory in the Benelux.
Dodis, Y., Reyzin, L., and Smith, A. (2004). Fuzzy extrac-
tors: How to generate strong keys from biometrics and
other noisy data. In LNCS. Springer.
Ignatenko, T. and Willems, F. (2009). Biometric systems:
Privacy and secrecy aspects. Information Forensics
and Security, IEEE Transactions on, 4(4):956 –973.
Jain, A. K., Ross, A., and Uludag, U. (2005). Biometric
template security: Challenges and solutions. In Pro-
ceedings of European Signal Processing Conference,
pages 1–4.
Juels, A. and Sudan, M. (2006). A fuzzy vault scheme. Des.
Codes Cryptogr., 38:237–257.
Juels, A. and Wattenberg, M. (1999). A fuzzy commitment
scheme. In CCS ’99: Proceedings of the 6th ACM
conf on Comp and comm security.
Labati, R. D., Piuri, V., and Scotti, F. (2012). Biomet-
ric privacy protection: Guidelines and technologies.
In E-Business and Telecommunications, pages 3–19.
Springer.
Linnartz, J.-P. and Tuyls, P. (2003). New shielding functions
to enhance privacy and prevent misuse of biometric
templates. In Audio- and Video-Based Biometric Per-
son Authentication. Springer.
Matsumoto, T., Matsumoto, H., Yamada, K., and Hoshino,
S. (2002). Impact of artificial ”gummy” fingers on
fingerprint systems. Optical Security and Counterfeit
Deterrence Techniques, 4677:275–289.
Verbitskiy, E. A., Tuyls, P., Obi, C., Schoenmakers, B.,
and
ˇ
Skori´c, B. (2010). Key extraction from general
nondiscrete signals. Information Forensics and Secu-
rity, IEEE Transactions on, 5(2):269 –279.
DiagnosticCategoryLeakageinHelperDataSchemesforBiometricAuthentication
511
