
Comparative Evaluations of a Hierarchical Categorization of
Search Results based on a Granular View of Domain Ontologies
Silvia Calegari, Fabio Farina
∗
and Gabriella Pasi
DISCo, Universit`a di Milano–Bicocca, Milano, Italy
Keywords:
Granular Domain Ontology, Search Results Categorization, Evaluations.
Abstract:
The aim of this paper is to evaluate the effectiveness of a categorization approach of search results based on the
use of domain ontologies with respect to the application of standard single-label and multi-label classification
algorithms. In particular, the approach in (Calegari et al., 2011) is considered, where the categorization process
is performed thanks to the adoption of a taxonomy of information represented as a granular view of a domain
ontology.
1 INTRODUCTION
The huge amount of information on the Web is always
in continuous overwhelming. A drawback of this situ-
ation is that for people is more difficult to discover out
information that could satisfy their information needs
as by the evaluation of a query produced by a search
engine several pages of results can be obtained. In-
deed, people often use search engines to formulate
queries related to their specific interests (such as pro-
fessional activities or hobbies); and they spend a lot
of time to focusing the attention on relevant search
results. The identification of relevant search results is
becoming a time consuming activity; to support the
user during his/her searches on the Web, in the lit-
erature several solutions have been proposed such as
personalization issues (Daoud et al., 2008; Ma et al.,
2007; Shahabi and Chen, 2003; Calegari and Pasi,
2010; Baeza-Yates and Maarek, 2011; Teevan et al.,
2005; Calegari and Pasi, 2008), relevance feedback
approaches (Salton and Buckley, 1990; Lv and Zhai,
2010; Halpin and Lavrenko, 2011; Ruthven and Lal-
mas, 2003), etc.
The research reported in this paper is related to
the problem of categorizing the results produced by
search engines in response to users’ queries. The task
is to help users in easily identifying the search re-
sults that could satisfy at best their information needs.
Twofold is the advantage of using a categorization
method for the Web: (1) a set of search results is
grouped into one or more categories, and (2) the la-
∗
Now at Consortium GARR, the Italian NREN.
bel of each category is set with a suited semantic that
expresses the meaning of the categorized search re-
sults, respectively. This way, a user can identify the
relevant search results faster.
In the literature, both unsupervised and super-
vised techniques of categorization have been pro-
posed (Carpineto et al., 2009; Sebastiani, 2002). The
focus of this paper is on unsupervised approaches that
make use of an external reference knowledge, gener-
ally a taxonomy, to associate each search result with
one or more categories of the considered resource.
For example, in (Ren et al., 2009) a general purpose
ontology to couple each search result with one cate-
gory of the ontology (single-label categorization) is
used. Instead, in (Calegari et al., 2011) a hierarchi-
cal multi-label categorization approach based on the
use of granular views of a domain ontology is pro-
posed. The usage of a domain ontology to categorize
Web search results allows to support users in easily
identifying their relevant search results than a general
purpose ontology. As (1) it avoids the problem of cat-
egorizing search results in ambiguous categories, (2)
it limits the number of categories used during the cat-
egorization process by reducing the time of selection
of the right category, and (3) people often use search
engines to formulate queries on specific interests that
refer to topical domains.
However, to define effective categorization algo-
rithms based on a domain ontology is not an easy
task as ontologies are complex structures. In (Cale-
gari and Ciucci, 2010) a method to generate a granu-
lar view of an ontology is proposed. A granular view
is a compact representation of an ontology where the
361
Calegari S., Farina F. and Pasi G..
Comparative Evaluations of a Hierarchical Categorization of Search Results based on a Granular View of Domain Ontologies.
DOI: 10.5220/0004625003610366
In Proceedings of the International Conference on Knowledge Engineering and Ontology Development (KEOD-2013), pages 361-366
ISBN: 978-989-8565-81-5
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

ontology concepts are grouped into coarser granules
based on shared properties of the original concepts.
Then, a granular view allows to manage the concepts
linked with different properties in order to define a
new subsumption relation among the analyzed con-
cepts according to common properties that they share.
The obtained granular ontology based on the new sub-
sumption relation is named granular view, and it has
less nodes (concepts) than the original domain ontol-
ogy; as a consequence a categorization process based
on this simplified representation is faster and simpler.
The objective of this paper is to evaluate the cate-
gorization method proposed in (Calegari et al., 2011),
that can be applied with different levels of accuracy
based on which information granules are selected in
the granular view of the reference domain ontology
to assess its efficacy. In particular, two kinds of cat-
egorization may be performed, i.e. single-label and
multi-label. To this goal, we extend the approach de-
fined in (Calegari et al., 2011) to also guarantee a
single-label categorization. To assess the effective-
ness of the single-label categorization, in this paper,
some comparative evaluations have been performed
with respect to standard single-label classifiers i.e.,
the Multinomial Na¨ıve Bayes, the linear SVM (i.e.
LibLinear), and the quadratic SVM (i.e. LibSVM,
classifiers). Moreover, the results of another kind of
evaluation are reported in this paper: the effectiveness
of the multi-label categorization has been evaluated
by comparing the search results produced by using
the original domain ontology with those produced by
using its granular view.
The paper is organized as follows: Section 2 gives
the methodology used for the multi-label and the
single-label categorization based on a granular view,
Section 3 and Section 4 present the details concern-
ing the metrics used for the evaluations, and the data
of the experiments, respectively. Finally, in Section 5
some conclusions and future activities are stated.
2 CATEGORIZATION OF
SEARCH RESULTS BASED ON
A GRANULAR VIEW
In this section, we shortly sketch the categorization
method (Calegari et al., 2011) used to associate each
search result with one or more topical granules be-
longing to the granular view, named multi-label cat-
egorization. Here, we extend the considered catego-
rization method with the case of single-label catego-
rization. The new property allows to the system to
associate each search result only with a topical gran-
ule of the granular view. This way, the categorization
method can be compared with standard single-label
classifiers to test its effectiveness with approaches
recognized as milestone evaluators in the literature
(see Section 3 and Section 4).
The notion of a granular view of a domain ontol-
ogy O is formally defined as a pair:
G
O
= {G,R
IS−A
},
where G is a set of granules, and R
IS−A
is the IS-A
subsumption relation defined on the set of granules
G. To generate a granular view of a domain ontol-
ogy means to group into granules the entities of O
that share some properties and properties value. From
O only the instances linked by the IS-A relation and
the properties defined on them are considered. More
formal details concerning how the granular view is
obtained are reported in (Calegari and Ciucci, 2010;
Calegari et al., 2011) as this aspect is out of topic with
respect to the aim of this paper.
Multi-label Categorization. Let Res the set of
search results, then the association of a search result
R
i
∈ Res with one or more granules g
k
∈ G is per-
formed by two subsequent steps:
1. “Search results conceptual indexing”. Both ti-
tle and snippet of R
i
are indexed via the con-
trolled vocabulary constituted by G ; we denote by
Rep(R
i
) the set of the representative granules ex-
tracted from title and snippet
2. “Association of search results R
i
with granule g
k
”.
For each granule g
k
in Rep(R
i
) the correspond-
ing result R
i
is associated. The association is per-
formed by selecting the corresponding granules
from Rep(R
i
) to the granules linked in R
IS−A
.
Then, R
i
is recursively associated with the parent
granules of g
k
in the hierarchy, and Ass
G
O
(g
k
) is
the set containing such granules.
Single-label Categorization. The identification of
the more relevant topical granule is chosen by analyz-
ing the set Rep(R
i
) of each search result obtained as
described in the previous paragraph, i.e. Multi-label
categorization. Now, the selection of the granule is
made by considering how the granules in Rep(R
i
) are
organized in R
IS−A
; then, the granule is chosen by
considering the common parent granule.
A Simple Example. Let us consider the vocabulary
of the following granular view related to the Wine
Ontology
2
. The set of granules is G := { Marietta
Zinfandel, Mountadan Pinot Noir, Lane Tanner Pinot
2
http://www.w3.org/2001/sw/WebOnt/guide-src/wine
KEOD2013-InternationalConferenceonKnowledgeEngineeringandOntologyDevelopment
362

Root
Grape Wines
Red Wines
Still Red Wines
Light Red Wines
Marietta Zinfandel
Mountandam Pinot Noir
Mountandam Pinot Noir
Lane Tanner Pinot Noir
Root
Grape Wines
Red Wines
Still Red Wines
Light Red Wines
Marietta Zinfandel
Mountandam Pinot Noir
Mountandam Pinot Noir
Lane Tanner Pinot Noir
Figure 1: Multi-label categorization of the search result R
1
provided by the granular view.
Noir, Red Wines, Grape Wines, Still Red Wines, Light
Red Wines}. During a search session a user is inter-
ested in finding, for instance, information about red
wines and he/she writes the following query q=“red
wines in France”, and a list of search results is dis-
played.
By analysing the first result R
1
, we have: Ti-
tle=“A guide to French Still Red Wines” and Snip-
pet=“Discover the wines of France, their history an
d valleys;...Lane Tanner Pinot Noir is a famous red
wine produced in. .. ”. From these two texts, we index
R
1
by the granules of G
O
. We obtain Title(R
1
) =Still
Red Wine and Snippet(R
1
) =Lane Tanner Pinot Noir.
Thus, Rep(R
1
) = Title(R
1
) ∪ Snippet(R
1
)={Lane
Tanner Pinot Noir,Still Red Wines}.
By considering the case of multi-label categoriza-
tion, Figure 1 depicts the situation after the applica-
tion of Step 1 and Step 2 where the result R
1
has
been categorized in the following granules Lane Tan-
ner Pinot Noir, Red Wines, Grape Wines, Still Red
Wines, Light Red Wines. The procedure is repeated
for each search result in Res.
By considering the case of single-label categoriza-
tion for Rep(R
1
), Figure 2 shows that the single cho-
sen granule is Red Wines as it is the common par-
ent granule of Lane Tanner Pinot Noir and Still Red
Root
Grape Wines
Red Wines
Still Red Wines
Light Red Wines
Marietta Zinfandel
Mountandam Pinot Noir
Mountandam Pinot Noir
Lane Tanner Pinot Noir
Root
Grape Wines
Red Wines
Still Red Wines
Light Red Wines
Marietta Zinfandel
Mountandam Pinot Noir
Mountandam Pinot Noir
Lane Tanner Pinot Noir
Figure 2: Single-label categorization of the search result R
1
provided by the granular view.
Wines. Again, the process is repeated for each search
result in Res.
At the end, the user gets the search results orga-
nized as a tree of granules according to the consid-
ered categorization methodology, i.e. multi-label or
single-label, respectively.
3 EVALUATIONS
As previously outlined, the first objective is to com-
pare the effectiveness of the approach proposed in
(Calegari et al., 2011) for the task of single-label cat-
egorization with the effectiveness of the cited single-
label classifiers in the Introduction as defined in the
Weka
3
toolkit. To this aim the standard IR measures
of agreement, recall and precision are adopted. The
second objective is to evaluate the considered method
for the multi-label categorization task; in (Calegari
et al., 2011) a comparative evaluation of the multi-
label categorization performed on the original domain
ontology with respect to the multi-label categoriza-
tion on its granular view has been presented in terms
of agreement, recall and precision. In this paper we
3
http://www.cs.waikato.ac.nz/ml/weka/
ComparativeEvaluationsofaHierarchicalCategorizationofSearchResultsbasedonaGranularViewofDomain
Ontologies
363

extend and report comparative evaluations based on
different indicators, i.e. the NDCG, and the S-Recall
measures.
DCG, discounted cumulative gain, measures the
gain of an item based on its position in the result
list. In our context an item refers to a Web search
result, and for our experiments we adopted the mod-
ified NDCG formulation proposed in (Agrawal et al.,
2009). This modification explicitly models a judg-
ment value in addition to the ranking obtained by the
application of the methodology, and it normalizes the
DCG values by comparing them to an ideal rank given
by domain experts. In our case, the judgment assigned
by domain experts to each Web search result can be
either 0 (Bad) or 1 (Excellent). Formally, given a
query q:
NDCG(q) =
∑
g
k
∈G
q
DCG(Ass
G
O
(g
k
))
DCG(Ass
exp
(g
k
))
!
/|G
q
|,
where G
q
=
S
R
i
∈Res
Rep(R
i
), and Ass
exp
(g
k
) is the as-
sociation performed by experts for each search result.
The S-Recall defined in (Zhai et al., 2003) is based
on ”arguments”; in our context arguments are both
topics and subtopics. S-Recall evaluates the size of
the set containing the granules obtained in response
to a query q over the total number of granules G as
S-Recall(q) =
|
S
R
i
∈Res
q
C
α
(R
i
)|
|G|
,
where C
α
(R
i
) is the set of granules with at least an
associated result produced by the categorization pro-
cess.
4 EXPERIMENT
The method has been implemented as a standalone
service that interacts with the Yahoo! Search Engine,
and which returns to the user the categorized search
results. We conducted the experiments by using the
Wine Ontology defined by the Stanford University
4
.
A granular view has been obtained from the Wine on-
tology by following the methodology in (Calegari and
Ciucci, 2010). The first experiments aim to analyze
the behaviour of the considered categorization ap-
proach with respect to the standard single-label clas-
sifiers mentioned in Section1. To this aim, with each
search result only the broader granule (in the hier-
archy) is associated by analyzing the set of granules
Rep(R
i
).
To generate the domain dependent data set related
to the Wine domain, we asked to four wine experts
4
http://www.w3.org/2001/sw/WebOnt/guide-src/wine
to define 44 topical queries and next, 880 search re-
sults have been selected. To this set of results we ap-
plied the standard test split with a percentage 70-30
to select training and test set, respectively. In order
to approximate a uniform distribution to improve the
classifiers prediction capability, we applied a random
re-sample on the training set.
Figure 3: Single-label Categorization.
To compare the considered categorization method
(Calegari et al., 2011) with the single-label catego-
rizations on the same data set, during the training
phase, the wine experts have acted as assessors in or-
der to labeling each search result with the more ap-
propriate granule of the granular view of the Wine
Ontology. Then, the training phase has been applied
on 1814 instances. Each instance is characterized by
the following attributes: the query, the search result,
and the granules set by the domain experts. For the
test phase, it has been necessary to set some parame-
ters for the LibSVM and the LibLIN classifiers. Lib-
SVM has been run with the radial basis kernel func-
tion with ν = 1.0, while for LibLIN the cost&bias pa-
rameter had a unitary value with the L
2
metric. The
test phase has been performed on 687 instances and
for each instance the granule chosen by the consid-
ered approaches (i.e., the Multinomial Na¨ıve Bayes,
LibLinear, LibSVM, and the single-label categoriza-
tion of Section 2, named Granular View) has been
compared with the one identified by the experts by
defining the optimal solution.
Figure 3 shows that the Granular View method
improves the considered standard single-label classi-
fiers. It happens because the standard classifiers do
not consider the semantic that each search result can
have. In particular, when a search result can seman-
tically belong to more than one granule, the prob-
lem is to identify the granule that better represents
the several meanings. The single-label categoriza-
tion approach explained in Section 2 shows close re-
sults with respect to the expert expectation by prefer-
ring the common coarsest granule among the selected
ones. This way, the multiple meaning of a search re-
sult are obtained more precisely.
KEOD2013-InternationalConferenceonKnowledgeEngineeringandOntologyDevelopment
364
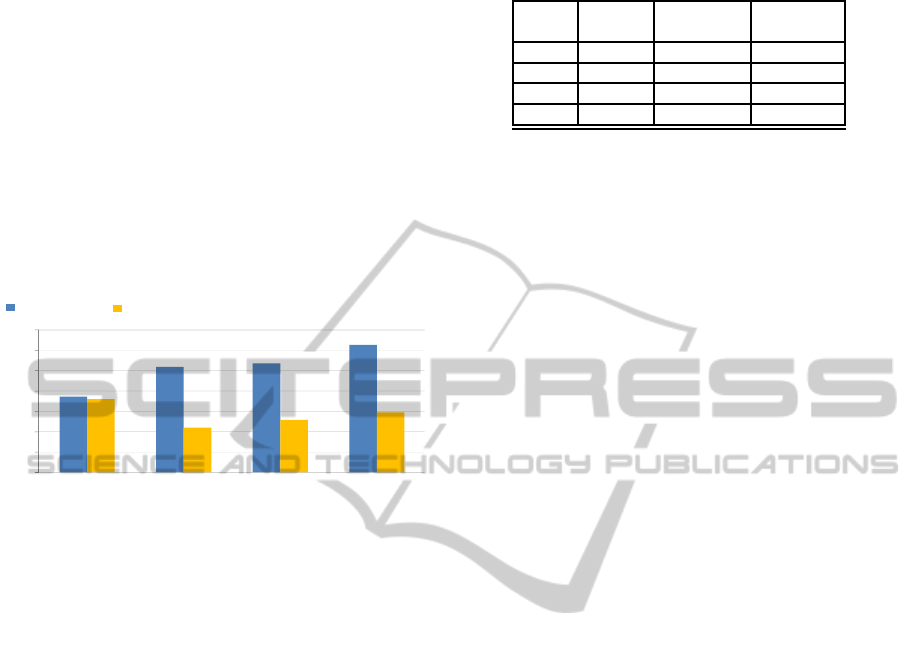
To this experiment, the Multinomial Na¨ıve Bayes
has been chosen as it is one of the most adopted clas-
sifiers and it is based on the assumption that each at-
tribute/feature is independent with respect to the other
ones. This is the case suited for our evaluations as
each search results has to be classified with a granule
and its choice is independent with respect to the other
granules used in the attributes set. Support Vector
Machine and linear classifiers are de-facto standards
for classification problems. Even with a limited popu-
lation, LibLinear and LibSVM classifier can identify
the optimal solution by obtaining results slightly less
accurate than what obtained with our single-label cat-
egorization approach.
0,3
0,35
0,4
0,45
0,5
0,55
AVG(NDCG)
0,2
0,25
0,3
0,35
0,4
0,45
0,5
0,55
@5 @10 @15 @20
cut @
AVG(NDCG)
Granular View
Ontology
Figure 4: NDCG: Multi-label categorization.
By the second experiment, the method proposed
in (Calegari et al., 2011) has been applied to com-
pare the hierarchical multi-label categorization based
on the original domain ontology (by only consider-
ing the subsumption relation) versus the hierarchical
multi-label categorization based on the granular view
of the original domain ontology.
The granular view is made up of 162 nodes,
whereas the taxonomy of the domain ontology is
made up of 219 nodes. We have compared the cat-
egorization on a set of 44 queries defined by four
wine experts, and we analyzed the top 20 results at
different precision levels: @5, @10, @15 and @20.
NDCG@5 indicates that both taxonomies consider
the same results with the same ranking order, and then
the measure discounts them in a similar way. The
lower NDCG(q) values indicate that the taxonomy of
the domain ontology gives to the results a different
categorization with respect to the ones assigned by ex-
perts; instead, the use of the granular view produces
higher NDCG(q) as it preserves the ranking.
The S-Recall(q) evaluations for the categorization
provided by experts and both the taxonomies have
highlighted that a very small portion of information
is involved for each query. Table 1 shows that the
domain ontology exhibits a worse behaviour than its
granular view: several unnecessary nodes are in fact
used to categorize the search results with the conse-
Table 1: S-recall: multi-label categorization.
cut@ Expert Granular Domain
View Ontology
@5
0.02 0.10 0.22
@10
0.03 0.15 0.28
@15
0.04 0.19 0.21
@20
0.05 0.34 0.41
quence that the user spends a lot of time in navigating
the hierarchy for discovering the search results.
5 CONCLUSIONS
In this paper we have presented some evaluations of a
method aimed at categorizing search results based on
a granular view of a domain ontology to both multi-
label categorization and single-label categorization.
In this last case, we have proposed an extension of
the considered multi-label categorization method in
order to manage cases of single-label categorization
on search results. This way, it is possible to compare
the method with standard classifiers such as the Multi-
nomial Na¨ıve Bayes, the LibLinear, and the LibSVM,
respectively.
To test the effectiveness of the considered multi-
label categorization approach, we have performed
new evaluations in addition to (Calegari et al., 2011)
such as NDCG and S-Recall. The granular view
has exhibited a better behaviour than the original do-
main ontology in multi-label categorization, and it has
achieved good results if compared to standard single-
label classifiers.
As a future research, we will consider other do-
mains, and we will evaluate the approach compared to
other standard hierarchical and deep classifiers (e.g.,
C4.5, random forest, Boltzman machines).
REFERENCES
Agrawal, R., Gollapudi, S., Halverson, A., and Ieong, S.
(2009). Diversifying search results. In WSDM ’09,
pages 5–14, New York, NY, USA. ACM.
Baeza-Yates, R. A. and Maarek, Y. (2011). Web retrieval:
the role of users. In Ma, W.-Y., Nie, J.-Y., Baeza-
Yates, R. A., Chua, T.-S., and Croft, W. B., editors,
SIGIR, pages 1303–1304. ACM.
Calegari, S. and Ciucci, D. (2010). Granular computing ap-
plied to ontologies. International Journal of Approxi-
mate Reasoning, 51:391–409.
Calegari, S., Farina, F., and Pasi, G. (2011). Topical cat-
egorization of search results based on a domain on-
tology. In Amati, G. and Crestani, F., editors, ICTIR,
volume 6931 of Lecture Notes in Computer Science,
pages 262–273. Springer.
ComparativeEvaluationsofaHierarchicalCategorizationofSearchResultsbasedonaGranularViewofDomain
Ontologies
365

Calegari, S. and Pasi, G. (2008). Personalized ontology-
based query expansion. In Web Intelligence/IAT Work-
shops, pages 256–259. IEEE.
Calegari, S. and Pasi, G. (2010). Ontology-based informa-
tion behaviour to improve web search. Future Inter-
net, 2(4):533–558.
Carpineto, C., Osinski, S., Romano, G., and Weiss, D.
(2009). A survey of web clustering engines. ACM
Computing Surveys, 41(3):17:1–17:38.
Daoud, M., Tamine-Lechani, L., and Boughanem, M.
(2008). Using a graph-based ontological user profile
for personalizing search. In CIKM ’08: Proceeding of
the 17th ACM conference on Information and knowl-
edge management, pages 1495–1496, New York, NY,
USA. ACM.
Halpin, H. and Lavrenko, V. (2011). Relevance feedback
between hypertext and semantic web search: Frame-
works and evaluation. Web Semant., 9(4):474–489.
Lv, Y. and Zhai, C. (2010). Positional relevance model
for pseudo-relevance feedback. In Proceedings of
the 33rd international ACM SIGIR conference on Re-
search and development in information retrieval, SI-
GIR ’10, pages 579–586, New York, NY, USA. ACM.
Ma, Z., Pant, G., and Sheng, O. R. L. (2007). Interest-based
personalized search. ACM Trans. Inf. Syst., 25.
Ren, A., Du, X., and Wang, P. (2009). Ontology-based cat-
egorization of web search results using YAGO. In
In Comput. Sciences and Optimiz., pages 800–804.
IEEE.
Ruthven, I. and Lalmas, M. (2003). A survey on the use
of relevance feedback for information access systems.
Knowl. Eng. Rev., 18(2):95–145.
Salton, G. and Buckley, C. (1990). Improving retrieval per-
formance by relevance feedback. Journal of the Amer-
ican Society for Information Science, 41:288–297.
Sebastiani, F. (2002). Machine learning in automated text
categorization. ACM Comput. Surv., 34(1):1–47.
Shahabi, C. and Chen, Y.-S. (2003). Web information
personalization: Challenges and approaches. DNIS.
LNCS., 2822:5–15.
Teevan, J., Dumais, S. T., and Horvitz, E. (2005). Person-
alizing search via automated analysis of interests and
activities. In Baeza-Yates, R. A., Ziviani, N., Mar-
chionini, G., Moffat, A., and Tait, J., editors, SIGIR,
pages 449–456. ACM.
Zhai, C., Cohen, W. W., and Lafferty, J. (2003). Beyond
independent relevance: Methods and evaluation met-
rics for subtopic retrieval. In In Proceedings of SIGIR,
pages 10–17.
KEOD2013-InternationalConferenceonKnowledgeEngineeringandOntologyDevelopment
366
