
A Prototype for Automating Ontology Learning and Ontology Evolution
Gerhard Wohlgenannt, Stefan Belk and Matthias Schett
Vienna University of Economics and Business, Augasse 2-6, 1090 Wien, Austria
Keywords:
Ontology Learning, Ontology Evolution, Crowdsourcing.
Abstract:
Ontology learning supports ontology engineers in the complex task of creating an ontology. Updating ontolo-
gies at regular intervals greatly increases the need for expensive expert contribution. This naturally leads to
endeavors to automate the process wherever applicable. This paper presents a model for automated ontology
learning and a prototype which demonstrates the feasibility of the proposed approach in learning lightweight
domain ontologies. The system learns ontologies from heterogeneous sources periodically and delegates all
evaluation processes, eg. the verification of new concept candidates, to a crowdsourcing framework which
currently relies on Games with a Purpose. Furthermore, we sketch ontology evolution experiments to trace
trends and patterns facilitated by the system.
1 INTRODUCTION
Ontologies are a cornerstone technology for the Se-
mantic Web, but the creation of ontologies is a cum-
bersome and very complex problem. Semi-automatic
ontology learning helps to reduce effort by providing
the ontology engineer with a starting point.
Ontology evolution is concerned with the adapta-
tion of the ontology to changes in the domain (data-
driven change), changed user requirements (user-
driven change) or to correct flaws in the original de-
sign. Ontology evolution requires frequent updates
or rebuilding of the ontology, esp. if investigating
emerging trends and patterns in highly dynamic do-
mains. In such a context, a greatly automated ontol-
ogy learning process is very beneficial.
The work presented in this position paper builds
upon and extends an ontology learning framework
first published in 2005 (Liu et al., 2005). Since then
the system has been improved to better support het-
erogeneous input sources (Wohlgenannt et al., 2012)
and to detect non-taxonomic relations (Weichselbraun
et al., 2010).
We introduce a prototype that aims to keep man-
ual input in ontology learning and evolution to a min-
imum by automating the workflow in the ontology
learning cycle. It delegates demand for human input
to sources that are cheaper and much more scalable
then conventional evaluation by domain experts. So,
the goal is to minimize manual (domain expert and
engineer) effort in repeated ontology learning cycles.
This effort can be measured against other ontology
learning systems. The presented architecture is built
for a specific framework, but the ideas are supposed to
have a general purpose. Finally, we draft experiments
for trend and pattern detection.
2 RELATED WORK
Early work in ontology learning (M
¨
adche and Staab,
2001) not only suggests methodologies for ontology
learning, but also defines the tasks involved, broadly
speaking the learning of concepts, taxonomic rela-
tions, non-taxonomic relations and axioms. The pre-
sented work focuses on lightweight ontologies, which
include concepts and taxonomic relations. For the ac-
quisition of new concepts related to existing concepts
many authors exploit Harris’ distributional hypothe-
sis (Harris, 1968), which states that two words are
similar to the extend that they share similar context.
Large projects like NeOn
1
developed complex on-
tology engineering environments. The NeOn toolkit
includes the Text2Onto (Cimiano et al., 2005) on-
tology learning framework, which is Java-based, and
geared towards the learning of rather expressive on-
tologies from domain text. Our work stems from a
smaller project dedicated to learning lightweight on-
tologies from heterogeneous input sources with a fo-
cus on automation and evolution experiments.
1
www.neon-project.org
407
Wohlgenannt G., Belk S. and Schett M..
A Prototype for Automating Ontology Learning and Ontology Evolution.
DOI: 10.5220/0004630504070412
In Proceedings of the International Conference on Knowledge Engineering and Ontology Development (KEOD-2013), pages 407-412
ISBN: 978-989-8565-81-5
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)
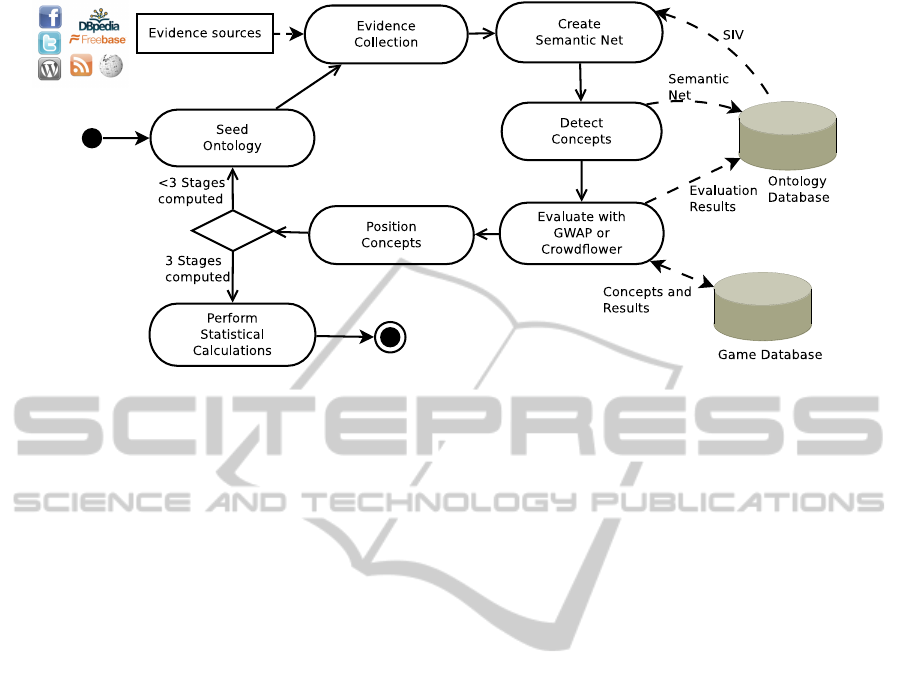
Figure 1: The Ontology Learning Process.
The evaluation of newly acquired concept candi-
dates with Games with a Purpose (GWAPs) or hu-
man labor markets such as CrowdFlower is a cen-
tral factor to make our system scalable. Noy et
al. (Natasha F. Noy and Musen, 2013) demonstrate
the suitability of Crowdsourcing with Amazon Me-
chanical Turk for evaluating hierarchical relations in
ontologies. GWAPs have already been used for exam-
ple for mapping Wikipedia articles to specific classes
in the Proton ontology in the OntoPronto game (Sior-
paes and Hepp, 2008) or for relation detection be-
tween concepts (Scharl et al., 2012). Existing tools
typically do not offer a tight integration of evaluation
results into the learning algorithms, however.
Ontology evolution can be defined as the “timely
adaptation of an ontology to the arising changes and
the consistent management of these changes” (Haase
and Stojanovic, 2005). It helps to keep ontologies up-
to-date and useful. The presented prototype integrates
heterogeneous input sources in the evolution process,
which to our knowledge is a novel approach except
for initial efforts in the RELExO framework (May-
nard and Aswani, 2010). In contrast to the Probabilis-
tic Ontology Model (POM) in Text2Onto (Cimiano
et al., 2009), which aims at change management as-
pects of ontology evolution, our automated approach
targets the detection of trends and patterns in the data
structures underlying and reflecting the ontology.
3 THE ONTOLOGY LEARNING
FRAMEWORK
This section gives an overview of the process and pro-
totype that performs ontology learning and captures
ontology evolution with minimal manual input and
effort. For more information about the underlying
architecture and algorithms see (Wohlgenannt et al.,
2012).
The system is written in Python, some minor com-
ponents are developed in Java for performance rea-
sons. It can roughly be divided into three parts:
1. A Web service & Web interface written in Python
which orchestrates the processes and serves as a
human interface for administrative tasks and as a
monitoring tool.
2. The ontology extension component. It computes
and positions new concepts in a domain ontology.
3. A keyword computation service written in Java,
which is the most prominent source for evidence
collection (from text).
This paper focuses on the Web service & Web in-
terface, as those components are crucial for automat-
ing the process. The whole system is designed to re-
duce the amount of time experts have to invest in or-
der to create new ontologies to a minimum. Expert
contribution is only needed to install the system and
initially configure the ontology learning cycle.
Figure 1 outlines the general workflow of a sin-
gle extension step which extends a seed ontology into
an extended ontology. At the end of the cycle the ex-
tended ontology serves as a new seed ontology for the
next iteration. In our system the ontology extension
iterations are called stages, by default the whole pro-
cess consists of three stages (defined in the configura-
tion of the Web service).
The initial seed ontology is typically a small set
of concepts and relations (specified in an OWL file)
which is characteristic of the respective domain. In
order to extend the ontology we collect evidence for
related concepts from a number of evidence sources.
KEOD2013-InternationalConferenceonKnowledgeEngineeringandOntologyDevelopment
408

This evidence includes keywords determined with
co-occurrence statistics from domain corpora using
the keyword computation service, related terms sug-
gested by social sources such as Twitter, Flickr or
Technorati to capture very recent terminology and
trends, hyponyms and hypernyms proposed by Word-
Net (Fellbaum, 1998), etc. As we periodically gener-
ate new ontologies from scratch to trace the evolution
of the domain, all evidence stems from the time pe-
riod in question (by default the last month). For more
details on evidence collection see (Liu et al., 2005).
The accumulated evidence data is collected in a
semantic net, which is then transformed into a spread-
ing activation network. The weights in the network
are influenced by the so called source impact value
(SIV) of the source which suggested the evidence. The
source impact values reflect the estimated quality of
the evidence source, and are currently our primary
target when optimizing the ontology learning process.
Through activating the spreading activation network,
the system computes the 25 most important candidate
concepts for the given seed ontology. Currently, a
Facebook-based GWAP is used to eliminate unrelated
concepts. The game has similar mechanics as the one
described in (Scharl et al., 2012).
The players of the game evaluate the concepts
by analyzing their relevance to the ontology’s do-
main, the result is then sent back to the ontology
Web service. A more powerful evaluation framework
which performs evaluation tasks either with (refined)
GWAPs or delegates the job to human labor markets
such as CrowdFlower
2
is under development. The
candidate concepts evaluated as relevant will then be
positioned in the ontology, for positioning algorithm
details see (Liu et al., 2005). Finally, the system cre-
ates a graphical representation of the ontology and
saves it into the file system (in OWL format).
The result (extended ontology) from stage one is
the starting point for the next stage, which repeats
the whole computation and evaluation process. The
framework is designed to compute an arbitrary num-
ber of stages (extension iterations), but for our pur-
poses three stages are appropriate.
As briefly mentioned, the ontology learning sys-
tem automatically optimizes its own performance by
adapting source impact values per evidence source.
After completion of the three ontology extension
stages the Web service calculates new source impact
values. They are based on the evaluation of con-
cepts suggested by the source in the current run and a
weighted arithmetic mean of previous ratings over the
past 365 days.
As shown in Figure 1, all important data collected
2
crowdflower.com
or computed by the system is stored in a database
for various reasons: persistence, easy access, and
support for evolution experiments (see Section 5).
The database contains metadata about each ontology
(stage), the evidence collected for the ontology, all
concepts, all evaluation results, source impact values,
etc.
Automation. A lot of effort has been made to au-
tomate the system as far as possible. A Web service
(see next section) controls the workflow, evaluation
(GWAPs/CrowdFlower) is the only task in the learn-
ing cycle where human input cannot be avoided. Fur-
thermore, to speed up computations we use caching
strategies in various processes:
• The evidence collection phase covers processes
that are computationally complex (such as the
computation of keywords via co-occurrence
statistics) or call third party APIs. With the help
of the eWRT toolkit
3
the framework applies fine-
grained caching strategies to only call the respec-
tive evidence collection service for a seed when
the necessary data cannot be derived from previ-
ous computations already existing in the system.
• The evaluation service (Facebook GWAP) stores
the results of past concept validation processes,
and lets users only evaluate entirely new concepts.
To allow for changes in the domain, concepts have
to be re-evaluated after a period of six months.
• To improve the run-time performance of the
spreading activation algorithms we experiment
with an approximation technique called spectral
association (Havasi et al., 2012).
• When manually calling the ontology extension
process, eg. for experimenting with parameter
settings, new domains or revised code, various
steps in the process can be deactivated easily and
thereby forced to re-use existing data.
4 THE WEB SERVICE &
ADMINISTRATION
INTERFACE
This section includes technical information about the
Web service and the corresponding administrative in-
terface. The main function of the Web service is to
guide the workflow, ie. calling the involved compo-
nents with the right parameters and handling the com-
munication between internal and external services.
3
www.weblyzard.com/ewrt
APrototypeforAutomatingOntologyLearningandOntologyEvolution
409
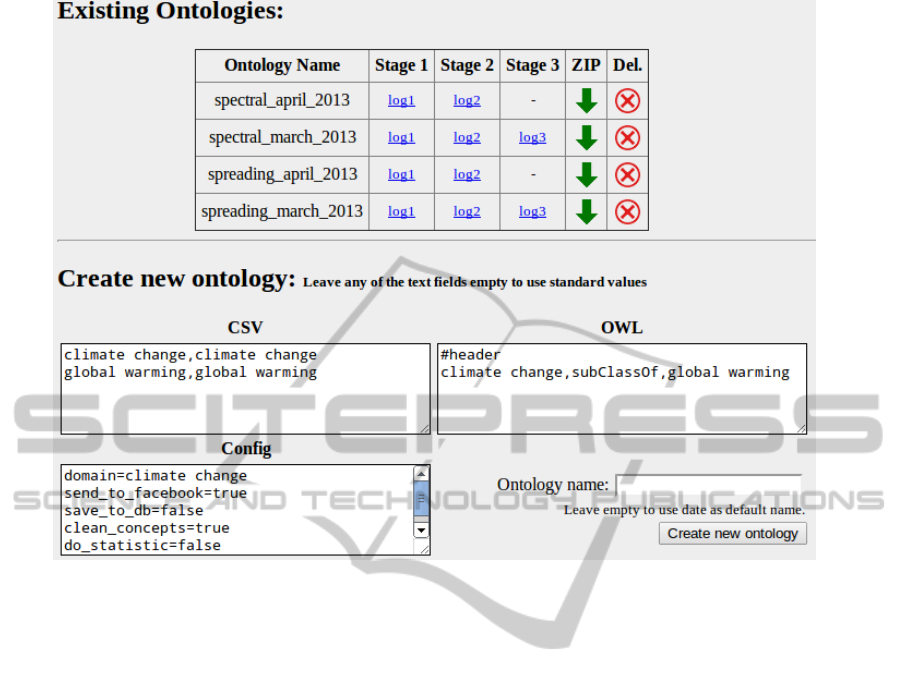
Figure 2: The Administration Interface (clipped).
In our environment, a cron job initiates the gen-
eration of new ontologies for all predefined configu-
rations at the end of each month via the REST API
of the Web service. A monthly interval is appropriate
for our purposes, but any other interval is conceivable.
The ontology learning system uses the evidence col-
lected for the respective period.
The communication to the GWAP API to create
evaluation tasks and to receive the results for those
tasks is a critical component. The system uses a
JSON format to communicate with the crowdsourcing
framework. The format contains the ID of the ontol-
ogy as key on the root level, and for any ontology we
use its domain (eg. “climate change”) as key, and the
candidate concepts (the terms which represent them)
as values. The JSON objects returned from evalua-
tion additionally contain the results, encoded as the
number of votes “relevant”, “not relevant”, and “un-
decided” for a candidate, as in the example below:
{"Ontology CC 2013-04 spectral":
{ "climate change": [
["CO2",4,0,0],
["water",0,2,2],
[....], ]
} }
To raise validity of results, the system uses inter-
player agreement on every evaluation task. The num-
ber of conforming votes necessary for evaluating a
concept candidate is configurable.
Moreover, the Web service handles the following
jobs which help to minimize manual intervention:
• Check for the existence and correct installation of
the required Linux and Python components and
the availability of the keyword computation ser-
vice; notify the user if anything is missing.
• Create the folder structure for new ontologies in
the file system
• Handle and save log, config and JSON files for
each ontology
• Create graphical representations of the created on-
tologies for each stage
• Compute new source impact values based on the
results of the evaluation.
Figure 2 shows parts of the administration inter-
face (clipped to contain only a very few ontologies to
save space). The interface is divided into four parts.
At the top (not shown in the screenshot) it displays
information about the current status of the system and
provides a link to the Web service’s global log file.
Below there is a list of ontologies existing in the sys-
tem. For any ontology the user can view the logs for
the three stages, download all data or delete it. The
logs also contain the resulting ontology graph.
KEOD2013-InternationalConferenceonKnowledgeEngineeringandOntologyDevelopment
410

Figure 3: An extended ontology (clipped).
Additionally to the fully automated generation of
ontologies, the user can also create an ontology man-
ually, this can be easily done via the Web interface’s
“Create new ontology” form found below the list of
existing ontologies. This allows the user to define and
experiment with various configurations which affect
the ontology learning process.
The user has a wide variety of parameter settings
to choose from, these can be grouped into the follow-
ing classes:
• Algorithms and evidence sources: Set the algo-
rithms to be used to create the new ontology
(eg. spreading activation or spectral association),
or set the period of time to be used.
• Testing: Just compute the ontologies, but do not
save the results into the database (save to db),
save the results into another database to bet-
ter separate results for production and testing
environments (db name), do (not) update the
source impact values after the completed run
(do statistics).
• Evaluation: Disable evaluating and filter-
ing terms via the evaluation service but just
keeping all concept candidates automatically
(send to facebook), or not filtering the con-
cepts even if GWAP evaluation has been done
(clean concepts).
The text areas CSV and OWL are for entering the
seed ontology for a new ontology learning process.
The OWL text area receives the seed concepts and
their relations as triples of subject, predicate and ob-
ject. These concepts are consistent with the CSV area
where a regular expression can be set for each con-
cept; the text based evidence sources (eg. keyword
detection) use the regular expression as a lexical rep-
resentation of the concept.
Finally the user can give the new ontology a name,
if omitted, a name including creation date and time
will be generated.
The last part of the interface (not shown in the
screenshot) displays information about ontology com-
putations currently running, including their names,
starting time, parameter settings, etc., and gives the
option to terminate running computations.
Figure 3 depicts parts on an extended ontology,
the yellow boxes represent the original seed concepts,
whereas shades of green denote concepts added in
stage one (light-green), two (green) and three (dark-
green).
5 ONTOLOGY EVOLUTION
EXPERIMENTS PLANNED
As already discussed, a relational DBMS (Post-
greSQL
4
) manages all of the information that is rele-
vant to trace the evolution of the ontology and there-
fore the domain – on the level of concepts and evalu-
ation results, but also on the fine-grained level of evi-
dences which finally lead to concept candidates.
Based on the database, we plan to detect various
4
www.postgresql.com
APrototypeforAutomatingOntologyLearningandOntologyEvolution
411

types of trends, for example rising, falling and cyclic
patterns. SQL-queries and data visualization will help
achieve the following:
• Trace the observed quality of evidence sources
based on the history of source impact values.
• Monitor the quality of the ontology learning sys-
tem itself via the ratio of relevant to irrelevant con-
cept candidates.
• Investigate which sources suggest which con-
cepts, and shifts between sources.
• Examine aggregated (eg. all text or all social ev-
idence sources) patterns, or comparisons across
domains.
6 CONCLUSIONS
This position paper presents the enhancements to an
existing ontology learning system – adding novel fea-
tures to automate the ontology learning cycle as far as
possible. These features allow for a wide range of on-
tology evolution experiments which reflect and detect
data-driven change in the domain.
The main contributions of the paper are (i) provid-
ing a model which supplies a high level of automation
for learning and evolving lightweight ontologies, (ii)
describing a prototype which implements this model
as a Web service, including the administration inter-
face and parameters, (iii) presenting trend and pattern
detection experiments facilitated by the automated ar-
chitecture and the database that collects fine-grained
data about ontological elements over time.
Future work includes the completion of a more
powerful evaluation framework which performs eval-
uation tasks either with (refined) GWAPs or delegates
them to CrowdFlower. The new evaluation frame-
work is under development. Furthermore, after col-
lecting longitudinal data, we will conduct and extend
the ontology evolution experiments described in Sec-
tion 5.
ACKNOWLEDGEMENTS
The presented work was developed within DIVINE
(www.weblyzard.com/divine), a project funded by the
Austrian Ministry of Transport, Innovation & Tech-
nology (BMVIT) and the Austrian Research Pro-
motion Agency (FFG) within FIT-IT (www.ffg.at/fit-
it). The work has also been supported by uComp
(www.ucomp.eu), a project in EU’s ERA-NET
CHIST-ERA programme.
REFERENCES
Cimiano, P., Maedche, A., Staab, S., and Voelker, J. (2009).
Ontology learning. In Staab, S. and Rudi Studer,
D., editors, Handbook on Ontologies, International
Handbooks on Information Systems, pages 245–267.
Springer Berlin Heidelberg.
Cimiano, P., Pivk, A., Schmidt-Thieme, L., and Staab,
S. (2005). Ontology Learning from Text, chapter
Learning Taxonomic Relations from Heterogeneous
Sources of Evidence, pages 59–76. IOS Press, Am-
sterdam.
Fellbaum, C. (1998). Wordnet an electronic lexical
database. Computational Linguistics, 25(2):292–296.
Haase, P. and Stojanovic, L. (2005). Consistent evolution
of owl ontologies. In Proceedings of the Second Eu-
ropean Semantic Web Conference, Heraklion, Greece,
pages 182–197.
Harris, Z. S. (1968). Mathematical Structures of Language.
Wiley, New York, NY, USA.
Havasi, C., Borovoy, R., Kizelshteyn, B., Ypodimatopou-
los, P., Ferguson, J., Holtzman, H., Lippman, A.,
Schultz, D., Blackshaw, M., and Elliott, G. T. (2012).
The glass infrastructure: Using common sense to cre-
ate a dynamic, place-based social information system.
AI Magazine, 33(2):91–102.
Liu, W., Weichselbraun, A., Scharl, A., and Chang, E.
(2005). Semi-automatic ontology extension using
spreading activation. Journal of Universal Knowledge
Management, 0(1):50–58.
M
¨
adche, A. and Staab, S. (2001). Ontology learning for the
semantic web. IEEE Intelligent Systems, 16(2):72–79.
Maynard, D. and Aswani, N. (2010). Bottom-up Evolution
of Networked Ontologies from Metadata (NeOn De-
liverable D1.5.4).
Natasha F. Noy, Jonathan Mortensen, P. A. and Musen, M.
(2013). Mechanical turk as an ontology engineer?
In Proceedings of the ACM Web Science 2013 (Web-
Sci’13), Paris, Forthcoming.
Scharl, A., Sabou, M., and F
¨
ols, M. (2012). Climate quiz:
a web application for eliciting and validating knowl-
edge from social networks. In Bressan, G., Silveira,
R. M., Munson, E. V., Santanch
`
a, A., and da Grac¸a
Campos Pimentel, M., editors, WebMedia, pages 189–
192. ACM.
Siorpaes, K. and Hepp, M. (2008). OntoGame: Weaving
the semantic web by online games. In Bechhofer,
S., Hauswirth, M., Hoffmann, J., and Koubarakis,
M., editors, 5th European Semantic Web Conference
(ESWC), volume 5021, pages 751–766. Springer.
Weichselbraun, A., Wohlgenannt, G., and Scharl, A. (2010).
Refining non-taxonomic relation labels with external
structured data to support ontology learning. Data &
Knowledge Engineering, 69(8):763–778.
Wohlgenannt, G., Weichselbraun, A., Scharl, A., and
Sabou, M. (2012). Dynamic integration of multiple
evidence sources for ontology learning. Journal of In-
formation and Data Management (JIDM), 3(3):243–
254.
KEOD2013-InternationalConferenceonKnowledgeEngineeringandOntologyDevelopment
412
