
VabCut: A Video Extension of GrabCut for Unsupervised Video
Foreground Object Segmentation
Sebastien Poullot
1,2
and Shin’Ichi Satoh
1,3
1
NII, Tokyo, Japan
2
JFLI, CNRS, Tokyo, Japan
3
University of Tokyo, Tokyo, Japan
Keywords:
Video Segmentation, Points of Interest, Outliers Removal, Frame Alignment, Motion M-layer, GrabCut.
Abstract:
This paper introduces VabCut, a video extension of GrabCut, an original unsupervised solution to tackle the
video foreground object segmentation task. Vabcut works on an extension of the RGB colour domain to
RGBM, where M is the motion. It requires a prior step: the computation of the motion layer (M-layer) of
the frame to segment. In order to compute this layer we propose to intersect the frame to segment with N
temporally close aligned frames. This paper also introduces a new iterative and collaborative method for an
optimal frame alignment, based on points of interest and RANSAC, which automatically discards outliers and
refines the homographies in turns. The whole method is fully automatic and can handle standard video, i.e.
not professional, shaky, blurry or else. We tested VabCut on the SegTrack 2011 benchmark, and demonstrated
its effectiveness, it especially outperforms the state of the art methods while being faster.
1 INTRODUCTION
A clean segmentation of the objects in images and
videos is a keystone to visual comprehension. For
humans as for machines, for interpreting a scene,
it is essential to be able to represent the relations
and interactions between its macro components, i.e.
some people and/or some objects, in their environ-
ment. The application range of video segmentation
is wide, from smart video indexing to robot vision.
This paper focuses on the separation of foreground
objects from background in videos, i.e. video fore-
ground object segmentation. The task is essentially a
complex binary classification problem (foreground or
background) of each pixel in a large spatio-temporal
space. The human intervention is known to reduce
the computational burden (Chockalingam et al., 2009;
Brendel and Todorovic, 2009) whereas fully auto-
mated methods are known to be very computationally
heavy (Lee et al., 2011; Ma and Latecki, 2012; Zhang
et al., 2013).
Concerning image segmentation, ten years ago,
the semi-automatic method GrabCut (Rother et al.,
2004) has been a great step in the field. The user
draws a rectangular bounding box around the ob-
ject of interest then the algorithm automatically and
quickly segments it. The method showed very accu-
rate results and is still very popular. A weakness of
the approach concerns the importance of the input:
the bounding box drawn around the object must not
contain any part of the object to segment, otherwise
the algorithm is disrupted and may fail.
The core of our proposition is an extension of
grabcut, namely VabCut, which takes as input the still
image RGB layer and a motion M-layer for perform-
ing a fully automatic video foreground object seg-
mentation. This M-layer is computed between N tem-
porary close video frames. Compared to the state
of the arts methods we claim that our approach has
many practical advantages: it does not need any prior
knowledge, learning or preprocessing of the video, it
is fully automatic and fast. Furthermore it can handle
non professional videos where low quality, bad focus,
shaky hands, fast camera moves and so on may oc-
cur. Only two assumptions are done: 1. a foreground
object moves and 2. it appears in temporally close
frames (within 1/5 second). If the object stops moving
the method can not properly segment it, if the object
gets out of the video frame, it may take 1/5 second
after new appearance to properly segment it again.
The next section presents some related works on
the video segmentation. Our approach is developed
in section 3 in three subsections; the first one presents
an original method for optimal frame alignment, the
362
Poullot S. and Satoh S..
VabCut: A Video Extension of GrabCut for Unsupervised Video Foreground Object Segmentation.
DOI: 10.5220/0004677103620371
In Proceedings of the 9th International Conference on Computer Vision Theory and Applications (VISAPP-2014), pages 362-371
ISBN: 978-989-758-004-8
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

Figure 1: Some illustrations of our results (on right)
compare to (Lee et al., 2011) automatic method on Seg-
Track2011. Ours is almost 100 times faster.
second one presents the M-layer creation, the third
one presents the VabCut algorithm itself. Section 4
furnishes and discusses the parameters, then the qual-
ity and the efficiency are evaluated and compared
to the state of the art methods on a reference fore-
ground video object segmentation benchmark: Seg-
Track2011 (Tsai et al., 2010). The method shows
good accuracy while fast processing. Moreover, we
also contribute to the community by presenting an ex-
tension of the benchmark. Indeed, on two videos, not
only one but two foreground objects appear, we man-
ually annotated them and made them available for the
community. We also furnish the results of our method
on this new dataset.
2 RELATED WORKS
Various approaches have been proposed for video
foreground object segmentation. The semi-
unsupervised ones need some human intervention for
initialization (Chockalingam et al., 2009; Brendel
and Todorovic, 2009; Tsai et al., 2010), most of the
time the contour of the objects to segment on the first
frame of a shot. The initialization gives a very strong
input to the method and is very useful to reduce the
computational costs, usually 1fps can be processed.
But if the video shots are very short, or the objects
often come in and out, very frequent updates of the
initialization is required and thus impractical.
Some other methods are fully automatic. (Grund-
mann et al., 2010) shows very impressive results on
video segmentation on a large range of videos, cam-
era motions, motions, objects, animals and people. It
introduces a quite simple but smart hierarchical 3D
spatial temporal segmentation. It cleverly segments
videos in consistent volumes but can not clearly sep-
arate background and foreground objects, and a fore-
ground object is generally divided in sub areas. The
method requires quite heavy computations and mem-
ory, but a parallel out-of-the-core implementation can
process 1 fps.
Recently, features trajectory based methods have
shown great results, for example (Thomas and Jiten-
dra, 2010; Ochs and Brox, 2011) propose to gather
similar dense point trajectories in order to segment the
frames. Unfortunately these approaches need a long
term study of the features, i.e. can not be done on-
line, and have quite an heavy computational burden.
From the image figure segmentation field, some
notable works on co-segmentation (Joulin et al.,
2012) could be an interesting approach for video fore-
ground object segmentation cases. Each instance of a
foreground object could be seen as an element of a
low entropy class. One issue is that the background
in a video does not change so much and could disrupt
such method. Furthermore, for still images the meth-
ods are computationally expensive, it could be even
more if adapted to the video case.
Recently, for video foreground object segmenta-
tion (Lee et al., 2011) have proposed a fully unsuper-
vised method based on ”key-segments”. They are per-
sistent edges that have a dynamic comportment dif-
ferent than neighbourhood. These edges are likely
to belong to the foreground objects. The idea is to
evaluate the ”objectness” of small areas conjointly
in all frames, and group them as objects (by spec-
tral clustering). The results are comparable to meth-
ods which require human intervention however it re-
quires to analyse extensively the frame contents, i.e.,
a large part of the spatio-temporal space is explored.
The method requires to pre-process the whole video
at first and due to the complexity it is quite slow (5
minutes for a frame) and consumes a huge amount
of memory. Despite the slow processing, the method
shows better results than both pre-existing fully auto-
matic and semi automatic methods on SegTrack2011
challenging benchmark (Tsai et al., 2010). (Ma and
Latecki, 2012) worked on a some similar approach
but with stronger constraints. One of the constraints is
that a foreground object must appear in every frames
of a video, which is quite a strong assumption. This
constraint is respected in SegTrack2011 benchmark,
their results shows some quality and speed improve-
ments compared to (Lee et al., 2011). (Zhang et al.,
2013) further explores this direction, they also exploit
VabCut:AVideoExtensionofGrabCutforUnsupervisedVideoForegroundObjectSegmentation
363

the optical flow to predict the new shape and posi-
tion of the object in adjacent frames in order to shrink
the space of objects to explore. The objects are in-
serted in a layered directed acyclic graph, where the
longest paths are the ones presenting the more ”ob-
jectness”. To our knowledge their proposition shows
the best score on SegTrack2011.
The aforementioned methods do not need to align
the frames, they suppose that the frame rate is fast
enough to consider that the object moves smoothly,
i.e. its position and shape are very similar in next
frames. Some other approaches relies on the frame
alignment, once aligned their subtraction highlights
the areas of motion, these areas potentially are fore-
ground objects. The main advantage of such approach
is to reduce the number of candidate areas for ”ob-
jectness”. (Sole et al., 2007) and (Ghanem et al.,
2012) address this problem in sports videos where
camera moves are quite smooth and typical. (Kong
et al., 2010) aligns two video sequences in order to
detect suspect objects in streets in videos shot from
a moving car. Closer to our works (Granados et al.,
2012) propose some background in-painting, i.e., re-
moving a foreground object in a shot, based on mul-
tiple frame alignment. Each frame is decomposed in
several planes, in order to process multiple homogra-
phies with the next and previous frames. The quality
of their results are very impressive. The main draw-
back of the frame alignment approach is that if it is
not accurate some false positive and loud noise occur
and disrupt the algorithms.
3 VabCut:A VIDEO MOTION
EXTENSION OF GrabCut
The idea of VabCut is simple, whereas GrabCut works
on the RGB space for segmenting still images, we
propose a solution that conjointly works on the mo-
tion information for segmenting video objects. The
state of the art methods mostly separate image and
motion, VabCut set them on a same level for segmen-
tation: the motion is considered as an extra colour.
The approach consists of two main steps: 1. com-
pute the motion M-layer of the frame F
t
using tempo-
rally close frames, 2. perform VabCut algorithm with
the RGB layer and the M-layer of F
t
as inputs.
For computing the M-layer, different approaches
can be used, basically direct registration or point reg-
istration methods. We here propose an original fast
but robust point method frame alignment solution.
3.1 Robust Frame Alignment
The frame alignment is based on an estimation of
the camera motion between two frames. Two main
approaches for alignment can be distinguished: di-
rect registration or point based registration. The first
approach gives more precise correspondences, but is
usually computationally very heavy (Bergen et al.,
1992), the second one is faster but usually more ap-
proximative. We here propose an original point based
approach which aims to keep the computation burden
low while tackling some issues of the simple points
matching approach.
A simple point matching process happens in 3
steps: 1. points of interest detection and descriptor
computation, 2. descriptor matching, 3. outliers re-
moval and homography computation.
Concerning the points of interest and descriptors,
during the ten last years, the computer vision commu-
nity has been very influenced by David Lowe’s works,
especially the well-known SIFT descriptors ((Lowe,
2004; Brown and Lowe, 2007)). This descriptor has
shown some great capabilities for image matching
even under some strong transformations. Since then
the family of points of interest (PoI) and descriptors
have been flourishing (SURF, FAST, BRIEF, ROOT-
SIFT, etc). For temporally close image matching, we
have 2 concerns, first, any PoI detector and any de-
scriptor has some weakness (not representative, not
discriminative, not robust, etc) depending on the vi-
sual contents of the images, second, the objects of in-
terest in a video may attract the PoI detector while the
background is not well described.
The aforementioned third step of a matching pro-
cess is typically performed by RANSAC family algo-
rithms, which are known to be robust to noise. The
result of a RANSAC processing is an homography
matrix that aligns the two frames. However if the
number of outliers is too high compared to inliers the
process fails. For example, it may mistakenly align
foreground objects, suggesting that background has
moved and the foreground objects have not.
To prevent this failure we propose an iterative and
collaborative process that identifies and remove the
outliers even when over represented in order to refine
the frame alignment. In a nutshell, the process is as
follows: 1. compute and match multiple sets of PoI
and local descriptors, 2. for each set run RANSAC
algorithm for removing some outliers and compute
an homography between the two frames, 3. evalu-
ate the quality of each resulting homography, 4. take
the worst homography has a marker of outliers, re-
move the potential outliers from each sets, next iter-
ation from RANSAC step. Each step is developed in
VISAPP2014-InternationalConferenceonComputerVisionTheoryandApplications
364

the following of this subsection.
First, for a set of PoI and descriptor, (for example,
DoG+SIFT), the features are extracted on frame F
t
and F
t+δt
. The local descriptor matching is performed
between the two frames in a dual constraint way,
let D
s
l
2
be the l
2
-distance in the description space, a
match between the descriptors d
t,i
and d
t+δt, j
is kept
if:
∀d
t,k
∈ F
t
,D
s
l
2
(d
t,k
,d
t+δt, j
) > D
s
l
2
(d
t,i
,d
t+δt, j
)∧
∀d
t+δt,k
∈ F
t+δ
,D
s
l
2
(d
t,i
,d
t+δt,k
) > D
s
l
2
(d
t,i
,d
t+δt, j
)
Second, RANSAC is run on the two selected
sets of points {P
t
} and {P
t+δt
} and returns the
matrix H
t,t+δt
of a probable linear transformation
(homography)between these sets. The point p(x,y, 1)
in F
t+δt
is projected in F
t
at position p
′
(x
′
,y
′
,w
′
),
p
′
= p× H
t,t+δt
where:
H
t,t+δt
=
h
11
h
12
h
13
h
21
h
22
h
23
h
31
h
32
h
33
(1)
The Cartesian coordinates of point p
′
in frame F
t
are (x
′
/w
′
,y
′
/w
′
).
The two previous steps are run for multi-
ple sets of PoI and local descriptors S
i
t,t+δt
=
{{P
i
t,t+δt
},{D
i
t,t+δt
}}. For example the classic {DoG,
SIFT} set, but also {SURF, SURF}, or {DoG,
BRIEF}, etc. For each set S
i
t,t+δt
the homography
H
i
t,t+δt
is computed.
Third, the homographies must be evaluated in or-
der to select the most reliable one for alignment of the
frames. The matching of two sets of 2D points be-
tween successive frames reduces the case to an affine
transformation, therefore, in homography matrix 3.1,
h
31
= h
32
= 0 and h
33
= 1. h
13
and h
23
correspond
to the translations, respectively T
x
and T
y
, the typi-
cal camera moves for following a foreground object.
They are the consequences of the rotations on camera
vertical and horizontal axis. h
11
,h
12
,h
21
and h
22
are
the consequences of multiple factors. Mostly it de-
pends on the rotation R
θ
t,t+δt
of angle θ of the camera
on its focal axis, and on the shearing Sh
t,t+δt
, defor-
mation due to the concavity of the lens, and forward,
backward moves of the camera:
h
11
h
12
h
21
h
22
!
∼
cosθ sinθ
−sinθ cosθ
!
sh
x
0
0 sh
y
!
The shearing depends on positions {P
t
} and
{P
t+δt
} in their respective frame and on the camera
translation Tc
x,y,z
. The pixels on the borders undergo
a stronger shearing. If the PoI are considered to ap-
pear uniformly on the frames, each set of point {P
t
}
undergo an identical shearing. Therefore, for scoring
an homography H
i
t,t+δt
, Sh
i
t,t+δt
can be neglected, and
h
11
,h
12
,h
21
, h
22
are only consequences of the rota-
tion of the camera on its focal axis R
θ
t,t+δt
. Contrary
to the translations, this shooting move is not natural
and should not be strong. If it is strong it is usually
the sign of an alignment failure, not of a bad camera
move, therefore it should be penalized. For a set of
PoI and descriptors C
i
, we propose to define an align-
ment cost as follows:
S
a
(H
i
t,t+δt
) =
q
(h
i
11
− 1)
2
+ (h
i
22
− 1)
2
+ h
i
21
2
+ h
i
12
2
If the camera does not rotate h
i
11
= h
i
22
= 1 and
h
i
12
= h
i
21
= 0, thus S
a
(C
i
t,t+δt
) = 0. Between two cam-
era moves estimation, the one depicting the more re-
alistic camera move is kept: for n set S
i
t,t+δt
of PoI and
descriptors, the homography H
i
having the lower cost
S
a
(H
i
t,t+δt
) is selected:
H
s
= argminS
a
(H
i
t,t+δt
)
i∈[0,n]
An important point is that the score is designed to
promote the camera natural moves. However the ho-
mography containing shearing and other undergone
transformations consequences is fully applied for per-
forming the alignment between frames.
Fourth, some spatial arrangements of the PoI in
the frames induce bad frame alignment. Basically, if
the number of PoI extracted from the background is
small compared to the number of PoI extracted from
the foreground objects, the process fails. Indeed, if
such unbalanced distribution occurs the foreground
objects points become the references for frames align-
ment. The resulting alignment leads to messy irrele-
vant segmentations. RANSAC is a non-deterministic
algorithm and could be run many times on each set
C
i
until a low alignment cost is found. However if
the sets of points contain spacial consistent noise (the
object points), the probability is very low. To pre-
vent this, we propose to iteratively remove points on
the foreground objects in order to correct the balance
between foreground and background. Instead of fo-
cusing on the best alignment, which are also possibly
tricked by the foreground objects, we propose to in-
vestigate the worst alignment for improving the other
ones.
Each alignment is based on a set S
i
t,t+δt
which
point positions P
i
t,t+δt
may not be shared (for exam-
ple points detected by DoG and SURF), however their
proximity in the frame plane can be exploited. Our
proposition is to consider the positions of the PoI of
VabCut:AVideoExtensionofGrabCutforUnsupervisedVideoForegroundObjectSegmentation
365
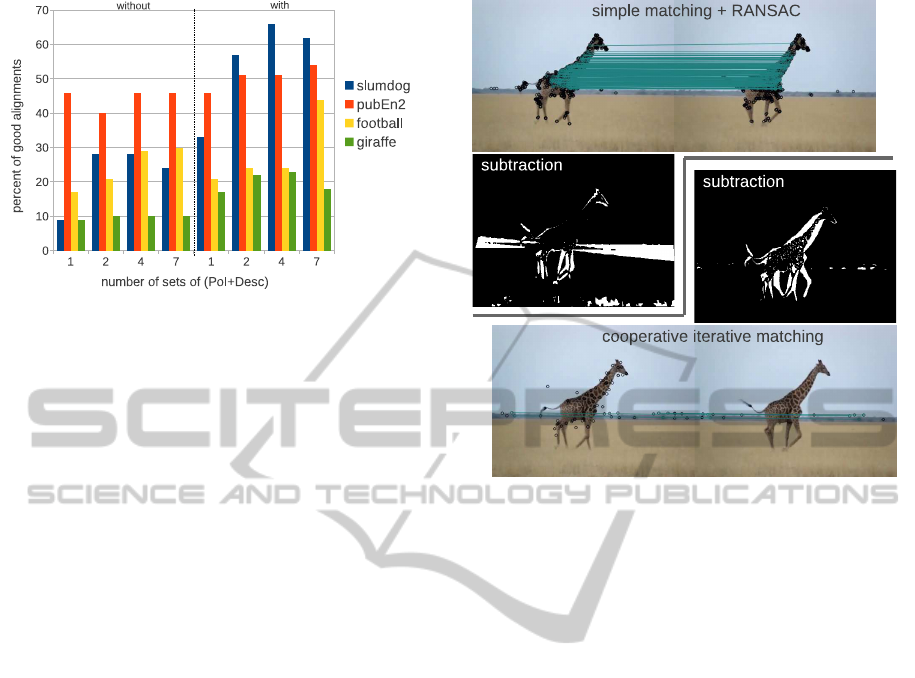
Figure 2: Correction of the alignments on 4 very challeng-
ing videos. On the left without collaborative iterative pro-
cedure, on the right with the procedure, both based on 1,
2, 4 or 7 sets of PoI/descriptors. The base line is the first
column, it corresponds to a standard RANSAC alignment
using DoG/SIFT set of features. The percentages of good
alignment clearly increases with the collaborative iterative
method.
the worst alignment as markers of the outliers: for
each other set S
i
t,t+δt
, the PoI close to these positions
(under a threshold distance Th
D
) are removed and
the RANSAC algorithm is run again. The procedure
stops if, at any time, an alignment cost is below the
threshold Th
S
a
. If this condition is not satisfied be-
fore all the PoI are removed from all sets S
i
t,t+δt
, the
best alignment seen along the iterative process is kept.
We propose here a short evaluation of our propo-
sition for robust frame alignment. Figure 2 dis-
plays a hand made evaluation of the reliability of the
homographies performed on three videos proposed
by (Grundmann et al., 2010) and the giraffe video
(also illustrated in figure 3). These videos were cho-
sen because they are very inconvenient: they are close
ups where averagely 80% of the descriptors are on the
foreground objects in motion (95% for the giraffe).
We counted the correct homographies frame to frame
with the simple processing, four first columns group,
and the collaborative iterative processing, four next
ones. For each case, 1, 2, 3 or 7 sets of PoI and de-
scriptors were computed. The simple process using
one set can be considered as the baseline (first col-
umn). It can be seen that the collaborative iterative
method using 7 sets (last column) strongly improves
the reliability of the alignment. Overall it gives 125%
more good alignments than the baseline. Figure 3 il-
lustrates a typical case of successful correction.
Only one homography H
t,t+δt
is kept between two
frames and considered as the right camera motion es-
timation. The frame F
t+δt
is projected on F
t
plane.
The resulting image F
′
t+δt
and F
t
can then be sub-
tracted at pixel level in order to obtain a map that
Figure 3: A successful correction case in the giraffe video.
The result of a simple RANSAC processing is displayed
on top left, most of the matches are found on the giraffe
body. The alignment is wrong and the frame subtraction
mask (in black and white, it is thresholded for comprehen-
sion) reveals the skyline, the giraffe legs and its head. On
bottom right, the collaborative iterative process found a bet-
ter alignment after two iterations. It can be seen that the
selected matches are now only located on the skyline. The
alignment and the resulting subtraction are satisfactory.
highlights the areas of motion, the M-layer.
3.2 Spatio-temporal M-layer
The subtraction of two frames F
t
and F
t+δt
is infor-
mative but not precise about the spatio-temporal loca-
tion of the objects (see figure 3) At least three frames
must be processed to obtain a satisfactory localization
of the object (it gives a kind of spatio-temporal trian-
gulation). However, if an object in F
t−δt
comes back
to the same position at F
t+δt
, the triangulation of the
three frames F
t−δt
, F
t
and F
t−δt
gives a result equal
to the subtraction of F
t−δt
and F
t
or F
t
and F
t+δt
. For
tackling this issue, we propose to ensure the spatio-
triangulation by using more than three frames. Fig-
ure 4 illustrates the proposition with five frames. The
frame F
t
is intersected with four other ones, two for
the original triangulation, and two other ones for en-
suring. To perform the intersection of this three tem-
porary M-layers, the min operator at pixel-level is ap-
plied. The more temporary M-layers are used the less
false positive pixels remain in the final M-layer, on the
other hand some true positive pixels are lost as well.
VISAPP2014-InternationalConferenceonComputerVisionTheoryandApplications
366

Figure 4: On top row, the successive frames of a video. On
bottom row, the M-layers, using F
t−2
, F
t
and F
t−2
, using F
t
and F
t+1
, and using F
t
and F
t+3
. The final M-layer is the
intersection of the three previous one.
In the evaluation section, it will be seen that removing
the false positive is essential for the method.
An advantage of this super triangulation is that the
noise caused by the approximation of the alignment
is partially removed. A drawback is that the absolute
position of the object in F
t
must be shared by the four
other frames. If the object or/and the camera movetoo
fast, this condition may not be fulfil and the process
may fail.
3.3 Video Foreground Object
Segmentation with VabCut
GrabCut (Rother et al., 2004) is widely used as a
step for image and video segmentation (Chen et al.,
2009; Yang et al., 2011). Originally it is an interac-
tive method, the user intervention is required to draw
a bounding box around the object to segment in a pic-
ture. Vabcut algorithm is fully automatic, the bound-
ing box is drawn depending on the location of the ar-
eas of motion, it works on the RGBM domain, color
plus motion, and optimizes the areas models (FG and
BG) generated at initialization.
VabCut Bounding and Super Bounding Box. In or-
der to automatically find a bounding box for VabCut,
a binary version of the previously computed motion
M-layer is computed. For this, an adaptive thresh-
old based on local intensity Th
li
is applied. The ar-
eas of activity are cliques of white pixels (white con-
nected surfaces). The cliques close to each other, un-
der a distance threshold Th
db
, are merged as one blob.
Each blob B
i
is a potential foreground object. From
each blob B
i
a bounding box bb
i
can be automatically
drawn. Due to previous processings, a blob may be
smaller than the real object, therefore its bounding
box is enlarged by E
bb
pixels in every direction.
Speaking about the original GrabCut algorithm,
if it is performed using bb
i
directly on the original
frame, the part inside bb
i
is labelled as unknown, the
part outside is labelled as background. The algorithm
is based on Gaussian mixture models (GMMs) of the
colours. At initialization two models are build, one
from the background area, one from the unknown
area. When the background is large compared to
the unknown area, they may share some visual sim-
ilarity, as a result their initials GMMs are inextrica-
ble and GrabCut fails. If the background is different
from the background contained in the bounding box
Grabut fails as well. For these two reasons only a
close area around the bounding box should be con-
sidered as background. Therefore for VabCut a super
bounding box sbb
i
is computed by enlarging the size
of bb
i
by a factor F
sbb
. Then VabCut is run using the
same bounding box bb
i
and the area between sbb
i
and
bb
i
as background.
Inside VabCut. In the following, we fit to the nota-
tions used in (Rother et al., 2004) so that the reader
can easily refer to this article. In VabCut the pixel z
n
at position (x,y) in frame F
i
is defined in 4 dimen-
sions:
z
n
= (R
n
,G
n
,B
n
,M
n
) (2)
where M is the value in the M-layer previously com-
puted for this frame. The colorimetric distance be-
tween 2 pixels is a regular Euclidean L
2
-distance us-
ing uniformly the 4 dimensions:
D
L
2
(z
n
,z
m
) =
p
(R
n
− R
m
)
2
+ (G
n
− G
m
)
2
+ (B
n
− B
m
)
2
+ (M
n
− M
m
)
2
(3)
The change of space has an impact on the whole
algorithm. The distance is used for performing the K-
means that initializes the GMMs models, and is also
used in the Gibbs energy E computation of the seg-
mentation:
E(α
,k,θ,z) = U(α,k, θ,z) + V(α,z) (4)
where α
is the vector of areas the pixels belong to
(here it can take two values, α
n
= {FG,BG}), k is
the vector of components of the GMM the pixels be-
long to (k
n
∈ [1,K]), θ
is the vector of the models of
area of the pixels (θ
n
= {FG,BG}), z is the vector of
pixels values in 4 dimensions (as in equation 3.3). U
measures how the segmentation fit to the model and
V is the smoothness term. The algorithm iteratively
minimizes the energy E. Please refer to (Rother et al.,
2004) for more details on the algorithm.
Independent Optimization of the GMM of the BG
and FG Areas. In the basic GrabCut algorithm, the
VabCut:AVideoExtensionofGrabCutforUnsupervisedVideoForegroundObjectSegmentation
367

number of Gaussian distribution in the mixtures is
fixed to K = 5 for the background as for the fore-
ground. However the compositions of these two areas
can be very simple, in that case they are represented
by too many Gaussian distributions. On the opposite,
they can be very complex, and in that case they are not
represented by enough Gaussian distributions. The
relevancy of a model can be estimated by computing
its entropy ξ, or the error between the prediction and
the original data. A low entropy or a low error means
that the model fits well to the data.
In the following we first propose to estimate the
entropy of the background and foreground models in
order to pick the right K for each one. The Grab-
Cut algorithm is initialized by a K-means algorithm
in order to build K Gaussian distributions for both
background and foreground pixels. Originally the K-
means algorithm iteratively refines the positions of K
centroids in order to satisfy the lower possible entropy
of the system. At each iteration step, this entropy is
defined as the sum of the L2-distances between each
data point S
i
and its representative centres C
S
i
.
ξ
KM
(K) =
nbSamples
∑
i=1
d
L2
(S
i
,C
S
i
) (5)
A low entropy characterizes a model in which the
data points are closed to their representative centroid:
the clusters are compact and the data well separated.
Depending on the initialization of the representative
centroids the results may vary a bit and it is hard
to know whether the global minimal entropy as been
found. Usually the algorithm stops after a predefined
number of iterations or when the attribution of the
data points to the representative centroids is stable be-
tween two iterations (the entropy is stable). By per-
forming many initial random draws an optimal model
of lowest entropy may be found, but considering the
description space and the initial number K, the num-
ber of solutions |S| to explore is way too large. Let
note |S
f
|, the feature space size, then |S| ≈ |S
f
|
K
.
In our practical case, for 4 colours channels on the
[0;255] range and K = 5 then |S| ≈ 1.3 × 10
48
. Of
course many solutions can be pruned out with so-
phisticated techniques (smart sampling for example),
however performing random draws gives very few
chances to improve the model for a huge loss of com-
putations.
As mentioned before, the entropy of the model
may remain high because K does not fit to the real
number of observable Gaussian distributions in the
data. Therefore we propose to run the K-means al-
gorithm on a range of values. For each value the en-
tropy of each area ξ
KM
(area,K) is estimated by the
K-means entropy (equation 3.3). The K offering the
lower entropy gives the optimal number of Gaussian
distributions to use for VabCut algorithm. In order to
have a data model as refined as possible, two indepen-
dent models, one on the background pixels, one on the
foreground pixels, are computed, having respectively
K
BG
and K
FG
Gaussian distributions:
K
BG
= argminξ
KM
(BG,K)
K∈[K
min
,K
max
]
(6)
K
FG
= argminξ
KM
(FG, K)
K∈[K
min
,K
max
]
(7)
A second proposition is to evaluate the mixture of
Gaussians generated by K-means using an Expecta-
tion Maximization (EM) classifier. Again, one clas-
sifier is used for each area. The train set and the
test set are the same: all the pixels from each area.
An EM classifier return a list of probability P(z
n
) =
p
1
(z
n
), p
2
(z
n
),..., p
K
(z
n
) for each pixel to belong to
each model of a K-GMM. We define the relevancy of
the model according to the EM classifier error of pre-
diction:
ξ
EM
(area,K) =
nbSamples
∑
i=n
p
j
(z
n
), z
n
∈ K
j
(8)
The selected K
BG
and K
FG
respectively for the BG
and the FG areas become:
K
BG
= argmaxξ
EM
(BG,K)
K∈[K
min
,K
max
]
(9)
K
FG
= argmaxξ
EM
(FG, K)
K∈[K
min
,K
max
]
(10)
The comparison between the two GMM optimiza-
tions are given in the next and last evaluation section.
4 EVALUATION
The tests are run on a laptop, processor Intel i7-
3520M@2.90GHz, using only one core.
Parameter Consideration. For setting up the param-
eters we tested our algorithm on a large set of videos,
composed of ten Youtube videos, all animals into the
wild, the set from (Grundmann et al., 2010) and the
segTrack2011 benchmark (Tsai et al., 2010). This one
is also the base for comparison with the state of the art
methods.
The frames can be more or less temporally dis-
tant, we tested our algorithms on 15fps to 30fps video,
VISAPP2014-InternationalConferenceonComputerVisionTheoryandApplications
368

Table 1: The top part of the tab shows the results on the ground truth furnished by (Tsai et al., 2010). Average mean pixel
error comparison for SegTrack 2011, the lower the better. F
1
is indicated as well, the higher the better. The bottom part of the
tab adds the results on the complete ground truth, manually annotated by our team.
Method VabCut VabCut VabCut VabCut GrabCut
EM-5f KM-5f KM-3f KM-OptFlow NO-3f
parachute 156 0.98 141 0.98 155 0.98 281 0.96 152 0.98
girl 577 0.95 683 0.95 884 0.93 1291 0.89 1273 0.90
monkey 748 0.70 897 0.67 908 0.67 1195 0.57 764 0.67
deer 861 0.70 870 0.70 1019 0.65 1047 0.59 917 0.61
birdfall 215 0.75 210 0.76 202 0.78 402 0.64 214 0.74
total 2557 2801 3168 4216 3320
monkey and dog 1749 0.52 1895 0.50 1850 0.52 2103 0.46 1820 0.47
cheetah and deer 1322 0.67 1298 0.68 1255 0.69 1721 0.54 1709 0.52
total all 4019 4227 4346 5789 5125
in any case all the frames are used. It exactly corre-
sponds to figure 4, the basic algorithm takes 3 frames
(t-2,t,t+2), the full version takes 5 frames.
For the collaborative iterative frame alignement
(subsection 3.1) 7 sets of PoI and local descrip-
tors are computed, namely: DoG+SIFT, DoG+Brief,
SURF+Brief, ORB+ORB, FAST+Brief, FAST+SIFT,
MORPHE+Brief. They are all set with default pa-
rameters. MORPHE is a home made descriptor, it
identifies singularity points (angles and straight lines)
on the canny edges filtering of a frame. The qual-
ity threshold is Th
S
a
= 0.05, the distance threshold is
Th
D
= 10pix for low definition videos (segTrack2011
for example) and proportionally increases with the
video definition (these two threshold appear in the
point fourth of the subsection 3.1).
About the bounding box and super bounding box
(subsection 3.3 first part), the intensity threshold Th
li
at pixel level is adaptive to the local mean intensity
(a linear function (0,10) → (255,30) computed on
the 9 × 9 neighbour pixels). The threshold merg-
ing distance between blobs is fixed to Th
db
= 25pix
for low definition videos (segTrack2011 for example)
and proportionally increases with the video defini-
tion. E
bb
= 5pix and the surface of a sbb
i
is set to
1.75∗ sur face(bb
i
).
Finally, for VabCut GMM optimization (subsec-
tion 3.3 last part), K ∈ [2− 11] values are tested.
SegTrack 2011 Benchmark. Our approach was
tested on the video database proposed by (Tsai et al.,
2010). It is composed of 6 short videos, in which each
frame has been hand-labelled. The ground truth of
each frame is a mask containing the position of only
one moving object in each sequence. The ”penguins”
video results are not given here, indeed it contains a
colony of penguins, and only one is annotated as a
good detection. Our algorithm tends to detect all the
penguins. The scores are average per frame pixel er-
ror rate from (Tsai et al., 2010):
ε(S) =
XOR(S, GT)
F
=
FP+ FN
F
(11)
with S is the resulting segmentation, GT the furnished
ground truth and F the number of frames of the se-
quence. FP are the false positive pixels and FN are
the false negative. We also indicate the F
1
scores:
F
1
=
2× P× R
P+ R
(12)
with P as precision and R as recall:
P =
TP
(TP+ FP) × F
, R =
TP
(TP+ FN) × F
(13)
where TP are the true positive pixels. This measure
expresses the balance and the completion of the seg-
mentation.
The ground truth provided by (Tsai et al., 2010)
is incomplete, on the video cheetah and monkey, not
only one animal appears but two, therefore we man-
ually extended the ground truth. First we compared
the results on the original ground truth by incorporat-
ing incrementally our propositions, see table 1. The
nomenclature for the method used is as follows: on
the first line, GrabCut or Vabcut method, on the sec-
ond line, 5f or 3f (5 or 3 frames intersection) or op-
tical flow is the method for computing the M-layer,
EM, KM or NO (EM, K-means or no optimization) is
the method for optimizing the GMMs.
As can be seen, the VabCut algorithm dramati-
cally improves the quality of the results on the girl
video, while it is quite stable on the other videos.
Improving the results on the parachute is very chal-
lenging (see F
1
scores), the object is very well sep-
arated from its background and the segmentation is
VabCut:AVideoExtensionofGrabCutforUnsupervisedVideoForegroundObjectSegmentation
369

Table 2: Average mean pixel error comparison for SegTrack
2011, the lower the better, 1:(Zhang et al., 2013), 2: (Ma and
Latecki, 2012), 3: (Lee et al., 2011)
Method VabCut (1) (2) (3)
EM-5f
parachute 156 220 221 288
girl 577 1488 1698 1785
monkey 748 365 472 521
deer 861 633 806 905
birdfall 215 155 189 201
total 2557 2861 3377 3700
benefit 10.6% 24.3% 30.9%
very good even with the original GrabCut algorithm.
The monkeycase is quite similar, the contrast with the
background is very strong and GrabCut can already
perform quite good.
The combination VabCut-EM-5f gives the best
overall results, which means that VabCut requires a
M-layer with not much false positives in it, which fits
to the original GrabCut property (and as mentioned
in subsection 3.2). The results with VabCut-OptFlow
confirms this property, the flow motion does not fit
very precisely to the object contour, the M-layer con-
tains more false positive motion, consequently the re-
sults are degraded.
About the new ground truth, an important point
must be mentioned. The improvement on monkey and
dog is quite low, indeed the dog appear in less than
half of the frames and does not move so much. As
VabCut is based on motion, it does not perform so
good. On the other hand, the improvement on cheetah
and deer is very high, here the two animals are in mo-
tion all along the video, VabCut brings some benefit.
Figure 5 illustrates some results on two videos from
the benchmark, 6 shows some more qualitative results
on videos proposed by (Grundmann et al., 2010).
Compare to the state of the art automatic meth-
ods (table 2), our overall score is the best, especially
because of the girl video. On the deer and monkey
videos, it is harder to make a straight comparison, as
our method tends to find the two animals in the two
videos. Plus, we want to point out that for the monkey
video, there are 10 frames is a row (from 212 to 222)
where our method can not succeed. Indeed the mon-
key is almost out of the scope and run away, the result-
ing M-layers are void in this subsequence (this possi-
ble issue is mentioned at the end of subsection 3.2). If
this subsequence is removed, the score becomes 646
instead of 748 (first column of tables 2 and 1).
About the time computation, our VabCut-EM-5f
is quite slow, about 18 seconds per frame on the Seg-
Track2011 videos (320x240). By using only half of
Figure 5: Some results on SegTrack 2011. The first column
shows the superimposition of the frames after alignment
(only 2 frames for clarity), the second one shows the M-
layer (motion is in red), the third column shows the bound-
ing boxes and super bounding boxes, the fourth one shows
the final segmentation. The 2 tops rows are from the deer
and cheetah video, on the top one, the 2 animals are found,
on the bottom one, only the deer, indeed the cheetah is not
in the overlapping part of the frames (see the M-layer). The
2 bottom rows are from the girl video, showing quite accu-
rate segmentation.
the pixel for learning and the other one for predicting,
the quality is stable and the computation time for a
frame is lowered to 10 seconds. The VabCut-KM-5f
is much more faster, requiring 4 seconds per frame.
If the method is still far from real time, it is however
faster than (Lee et al., 2011) method, which requires
about 300 seconds per frame, (Ma and Latecki, 2012)
is not clear about time consumption, (Zhang et al.,
2013) does not mention it. The memory consumption
is almost null, and the process can be performed on a
streaming video with no length limit.
5 CONCLUSIONS AND FUTURE
WORKS
In this paper, we propose an efficient and effective au-
tomatic one-pass method for video foreground object
segmentation. It is based on a motion estimation be-
tween temporally close frames after point based align-
ment, and VabCut an extended version of GrabCut in
the motion domain. The method has many practical
advantages. It is fully automatic, does not require any
preprocessingof the video, does not learn any models,
and does not consume memory. It can handle every-
day’s life videos, shaky hands, fast camera or objects
moves. On the challenging SegTrack2011 benchmark
VISAPP2014-InternationalConferenceonComputerVisionTheoryandApplications
370

Figure 6: Some of our segmentation results on the videos proposed by (Grundmann et al., 2010).
it achieves better results than the state of the art auto-
matic methods, which may also be very much slower.
As limitations, the proposed method can not detect
still foreground object, moreover if a foreground ob-
ject stops moving it is lost. Our next works will focus
on the consistency over time of detected foreground
objects, in order to propagate, clean and track the ob-
jects.
REFERENCES
Bergen, J. R., Anandan, P., Hanna, K. J., and Hingorani, R.
(1992). Hierarchical model-based motion estimation.
In ECCV, pages 237–252.
Brendel, W. and Todorovic, S. (2009). Video object seg-
mentation by tracking regions. In ICCV.
Brown, M. and Lowe, D. G. (2007). Automatic panoramic
image stitching using invariant features. International
Journal of Computer Vision, 74(1).
Chen, T., Cheng, M.-M., Tan, P., Shamir, A., and Hu, S.-
M. (2009). Sketch2photo: internet image montage. In
SIGGRAPH.
Chockalingam, P., Pradeep, S. N., and Birchfield, S. (2009).
Adaptive fragments-based tracking of non-rigid ob-
jects using level sets. In ICCV.
Ghanem, B., Zhang, T., and Ahuja, N. (2012). Robust video
registration applied to field-sports video analysis. In
ICASSP.
Granados, M., Kim, K. I., Tompkin, J., Kautz, J., and
Theobalt, C. (2012). Background inpainting for
videos with dynamic objects and a free-moving cam-
era. In ECCV.
Grundmann, M., Kwatra, V., Han, M., and Essa, I. (2010).
Efficient hierarchical graph based video segmentation.
In CVPR.
Joulin, A., Bach, F., and Ponce, J. (2012). Multi-class
cosegmentation. In CVPR.
Kong, H., Audibert, J.-Y., and Ponce, J. (2010). Detect-
ing abandoned objects with a moving camera. IEEE
Trans. on Image Processing, 19(8).
Lee, Y. J., Kim, J., and Grauman, K. (2011). Key-segments
for video object segmentation. In ICCV.
Lowe, D. G. (2004). Distinctive image features from scale-
invariant keypoints. International Journal of Com-
puter Vision, 60:91–110.
Ma, T. and Latecki, L. (2012). Maximum weight cliques
with mutex constraints for video object segmentation.
In CVPR, pages 670–677.
Ochs, P. and Brox, T. (2011). Object segmentation in video:
A hierarchical variational approach for turning point
trajectories into dense regions. In ICCV.
Rother, C., Kolmogorov, V., and Blake, A. (2004). Grabcut:
Interactive foreground extraction using iterated graph
cuts. ACM Trans. On Graphics, 23.
Sole, J., Huang, Y., and Llach, J. (2007). Mosaic-based
figure-ground segmentation along with static segmen-
tation by mean shift. In SIP.
Thomas, B. and Jitendra, M. (2010). Object segmentation
by long term analysis of point trajectories. In ECCV.
Tsai, D., Flagg, M., and Rehg, J. (2010). Motion coherent
tracking with multi-label mrf optimization. In BMVC.
Yang, L., Guo, Y., Wu, X., and Li, S. (2011). An inter-
active video segmentation approach based on grabcut
algorithm. In CISP.
Zhang, D., Javed, O., and Shah, M. (2013). Video object
segmentation through spatially accurate and tempo-
rally dense extraction of primary object regions. In
CVPR.
VabCut:AVideoExtensionofGrabCutforUnsupervisedVideoForegroundObjectSegmentation
371
