
Invariant Shape Prior Knowledge for an Edge-based Active Contours
Invariant Shape Prior for Active Contours
Mohamed Amine Mezghich, Slim M’Hiri and Faouzi Ghorbel
GRIFT Research Group, CRISTAL Laboratory,
´
Ecole Nationale des Sciences de l’Informatique, ENSI,
Campus Universitaire de la Manouba, 2010 Manouba, Tunisia
Keywords:
Active Contours, Shape Prior, Phase Correlation, Rigid Transformations, Invariant Descriptors.
Abstract:
In this paper, we intend to propose a new method to incorporate geometric shape prior into an edge-based
active contours for robust object detection in presence of partial occlusions, low contrast and noise. A shape
registration method based on phase correlation of binary images, associated with level set functions of the
active contour and a reference shape, is used to define prior knowledge making the model invariant with respect
to Euclidean transformations. In case of several templates, a set of complete invariant shape descriptors is used
to select the most suitable one according to the evolving contour. Experimental results show the ability of the
proposed approach to constrain an evolving curve towards a target shapes that may be occluded and cluttered
under rigid transformations.
1 INTRODUCTION
Active contours (Kass et al., 1988; Cohen, 1991; Xu
and Prince, 1997; Malladi et al., 1995; Caselles et al.,
1997; Chan and Vese, 2001) have been widely used
in image segmentation. One can classify them into
two families : The boundary-based approach which
depends on an edge stopping function to detect ob-
jects and the region-based approach which is based
on minimizing an energy’s functionnal to segment ob-
jects in the image. Given that these classical active
contours are intensity-based models, there is still no
way to caracterize the global shape of an object. Es-
pecially in presence of occlusions and clutter, all the
previous models converge to the spurious contours re-
sulted from large local gradient nearby. Many works
incorporate shape prior into the active contour mod-
els. Leventon et al., (Leventon et al., 2000) associ-
ated a statistical shape model to the geodesic active
contours (Caselles et al., 1997). At each step of the
surface evolution, the maximum a posteriori position
and shape are estimated and used to move globally the
surface while local evolution is based on image gra-
dient and curvature. Chen et al., (Chen et al., 2001)
defined an energy’s functional based on the quadratic
distance between the evolving curve and the average
shapes of the target object after alignment. This en-
ergy is then incorporated into the geodesic active con-
tours. Bresson et al., (Bresson et al., 2003) extended
(Chen et al., 2001) approach by integrating the sta-
tistical model of shape proposed by (Leventon et al.,
2000) in the energy functional. Fang and Chan (Fang
and Chan, 2007) introduced a statistical shape prior
into the geodesic active contour to detect partially
occluded object. To speed up the algorithm, an ex-
plicit alignment of the shape prior model and the cur-
rent evolving curve is done to calculate pose parame-
ters. Foulonneau et al., (Foulonneau et al., 2004) in-
troduced a geometric shape prior into a region-based
active contours (Chan and Vese, 2001) based on the
Legendre moments of the characteristic function and
in (Charmi et al., 2010), the authors defined a geomet-
ric shape prior for the region-based active contours
after alignment of the evolving contour and the ref-
erence shape. It’s well know that shape priors based
on contour alignment methods force these approaches
to segment only single object in the image and go
without the contribution of level set, i.e. its ability to
segment multiple objects at once, see (Bresson et al.,
2003). Besides, contour alignment methods are not
adapted to estimate the rigid transformation parame-
ters in the case of objects with holes (which often oc-
curs in medical imagery like MRI brain’s white mat-
ter). This justifies the use of the registration meth-
ods instead of those based on contours alignment.
In this work, we focus on adding a new geometric
shape prior to an edge-based active contours (Malladi
et al., 1995) based on phase correlation. At the begin-
ing, we assume that the shape of reference is known
in advance like the work of (Zhang and Freedman,
454
Mezghich M., M’Hiri S. and Ghorbel F..
Invariant Shape Prior Knowledge for an Edge-based Active Contours - Invariant Shape Prior for Active Contours.
DOI: 10.5220/0004692304540461
In Proceedings of the 9th International Conference on Computer Vision Theory and Applications (VISAPP-2014), pages 454-461
ISBN: 978-989-758-004-8
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

2003; Cremers et al., 2003; Foulonneau et al., 2004;
Chan and Zhu, 2005). Then we will introduce our ap-
proach to select the best shape according to the evolv-
ing contour in situation where the shape of reference
is unknown and many templates are available. The
improved model can retain all the advantages of the
level set approach and have the additional ability of
being able to handle the case of images with multi-
ple objects under partial occlusions and noise. The
remainder of this paper is organized as follows : In
section 2, we will briefly recall the used shape regis-
tration method based on phase correlation. Then, in
section 3, the proposed shape prior will be presented.
We assume that at this stage, the shape of reference
is known in advance. In section 4, we present our
method to choose the suitable shape in case of many
references. Experiments will be presented and com-
mented in order to study the robustness of the model
in section 5. Finally, we conclude the work and high-
light some possible perspectives in section 6.
2 SHAPES REGISTRATION
Before incorporating the prior knowledge into the ac-
tive contours model, the reference shape or the sta-
tistical model must be first transformed to best match
the current shape. We adopt the well know method
of phase correlation in Fourier space that is appro-
priate to estimate the translation vector and for es-
timating the rotation angle and the scaling factor,
we use the proposed method of phase correlation in
Fourier-Mellin space. We recall this method which
is based on the Analytical Fourier-Mellin Transform
(AFMT), see (M’Hiri et al., 2012) for a detailed de-
scription. A comparative study with other global reg-
istration methods is presented in (Sellami and Ghor-
bel, 2012). Let f (r, θ) be a polar representation of
the image with the radius r according to the center of
gravity of the image to offset translation and θ the an-
gle according to the horizontal. It was pointed out in
(Ghorbel, 1994) that the crucial numerical difficulties
in computing the Fourier-Mellin transform of an im-
age might be solved by using the Analytical Fourier-
Mellin Transform (AFMT) given by
M
f
σ
(k, v) =
1
2π
Z
+∞
0
Z
2π
0
f (r, θ)r
σ−iv
e
−ikθ
dr
r
dθ,
(1)
where σ > 0 is a fixed and strictly positive real num-
ber. Since no discrete transform exists, three approxi-
mations of the AFMT have been designed : the direct,
the cartesian and the fast algorithm, see (Derrode and
Ghorbel, 2001). Let f
φ
re f
and f
φ
be two binary im-
ages associated respectively with level set functions
φ
re f
and φ. Denote by M
f
σ,φ
re f
and M
f
σ,φ
the AFMT
of respectively f
φ
re f
and f
φ
with the same value of σ.
f
φ
re f
and f
φ
have the same shape if and only if there is
a similarity (α
0
, β
0
) ∈ G = (R
∗
+
, S
1
) such that
∀(r, θ) ∈ G, f
φ
(r, θ) = f
φ
re f
(
r
α
0
, θ − β
0
),
(2)
The action of planar similarities in Fourier-Mellin
space leads to
M
f
σ,φ
(k, v) = α
σ−iv
0
e
−ikβ
0
M
f
σ,φ
re f
(k, v),
(3)
By calculating the normalized cross-spectrum, only
information on phase difference will be preserved
Φ(k, v) =
M
∗
f
σ,φ
re f
(k, v)M
f
σ,φ
(k, v)
|M
∗
f
σ,φ
re f
(k, v)||M
f
σ,φ
(k, v)|
= α
−iv
0
e
−ikβ
0
,
(4)
Phase correlation of two images represented respec-
tively by f
φ
re f
and f
φ
is defined as
C
T f m
(α, β) =
Z
+∞
0
∑
Z
Φ(k, v)α
iv
e
ikβ
dv,
(5)
We can deduce the images transformation’s parame-
ters (α, β) by estimating (α
0
, β
0
) that maximize the
correlation function C
T f m
. Having the parameters of
rigid transformation between the two binary images,
we perform the registration of the image f
φ
re f
accord-
ing to the following formula (Chan and Zhu, 2005)
f
reg
φ
re f
(x, y) =
α f
φ
re f
(
(x−a)cos θ+(y−b)sin θ
α
,
−(x−a)sin θ+(y−b)cos θ
α
),
(6)
where (a, b) represents the translation vector, θ the
rotation angle and α is the scaling factor. On the re-
sulting image (Fig.1), the pixels in black (resp. white)
correspond to positive areas (resp. negative) of the
signed distance map which is associated to level set
function. The image on the right of Fig.1 shows the
product function given by
f
prod
(x, y) = f
reg
φ
re f
(x, y) · f
φ
(x, y),
(7)
By construction, the function f
prod
is negative in
the areas of variability between the two binary images
(occlusion, clutter, missing parts etc.) whereas in pos-
itive regions, the objects are similar. Thus, in what
Figure 1: Left : f
reg
φ
re f
, Middle : f
φ
, Right : f
prod
.
InvariantShapePriorKnowledgeforanEdge-basedActiveContours-InvariantShapePriorforActiveContours
455

follows, we propose to update the level set function φ
only in regions of variability between shapes to make
the evolving contours overpass the spurious edges and
recover the desired shapes of objects. This property
recalls the Narrow Band technique used to acceler-
ate the evolution of the level set functions (Malladi
et al., 1995). In many works like those of (Foulonneau
et al., 2004; Foulonneau et al., 2006) and (Leventon
et al., 2000; Fang and Chan, 2006; Fang and Chan,
2007), all the pixels in the image, called n, are in-
voked in the process of incorporating the shape prior
which may increase the calculus complexity (O(n
2
))
of the model. In our work, only pixels of the region
of variablity, called k, are invoked. Generaly k << n,
hence the calculus complexity (in our case O(k
2
)) is
reduced. This remark will be more developed in sec-
tion 5.
3 THE PROPOSED SHAPE PRIOR
Geometric active contours are iterative segmentation
methods which use the level set approach (Osher and
Sethian, 1988) to determine the evolving front at each
iteration. Working with this approach makes it possi-
ble to manage topology changing of the contour like
splitting and merging, and consequently the segmen-
tation of an arbitrary number of objects in the image.
In (Malladi et al., 1995), the level set method is used
to model the shape of objects with an evolving front.
The evolution’s equation of the level set function φ,
which is the embedding function associated to the ac-
tive contour, is
φ
t
+ F|∇φ| = 0,
(8)
F is a speed function of the form F = F
0
+ F
1
(K)
where F
0
is a constant advection term equals to (±1)
depending of the object inside or outside the initial
contour. The second term is of the form −εK where
K is the curvature at any point and ε > 0, is a constant
real. To detect objects in the image, the authors pro-
posed the following function which stops the level set
function’s evolution at the object boundaries
g(x, y) =
1
1+|∇G
σ
∗ f (x,y)|
p
, p >= 1
(9)
where f is the image and G
σ
is a Gaussian filtre with
a deviation equals to σ. This stopping function has
values that are closer to zero in regions of high image
gradient and values that are closer to unity in regions
with relatively constant intensity. Hence, the discrete
evolution equation is
φ
n+1
(i, j)−φ
n
(i, j)
∆t
= −g(i, j) F(i, j) |∇φ
n
(i, j)|,
(10)
It’s obvious that the evolution is based on the stop-
ping function g which depends on the image gradi-
ent. That’s why this model leads to unsatisfactory re-
sults in presence of occlusions, low contrast and even
noise. To make the level set function evolves in the
regions of variability between the shape of reference
and the target shape, we propose the new stopping
function as follows
g
shape
(x, y) =
0, i f ψ(x, y) >= 0,
sign(φ
re f
(x, y)), else,
(11)
where ψ(x, y) = φ(x, y) · φ
re f
(x, y), φ is the level set
function associated to the evolving contour, while φ
re f
is the level set function associated to the shape of ref-
erence after registration. As it can be seen, the new
proposed stopping function only allows for updating
the level set function in the regions of variability be-
tween shapes. In these regions g
shape
is either 1 or -1
because in the case of partial occlusions, the function
is equals to 1 in order to push the evolving curve in-
ward (deflate) and in case of missing parts, this func-
tion is equals to -1 to push the contour towards the
outside (inflate). This property recalls the Balloon
snake’s model proposed by Cohen in (Cohen, 1991)
in which the direction of evolution (inflate or deflate)
should be precised from the beginning. In our work,
the direction of evolution is hundled automatically
based on the sign of φ
re f
. The total discrete evolu-
tion’s equation that we propose is
φ
n+1
(i, j)−φ
n
(i, j)
∆t
=
−(w g(i, j) + (1 − w) g
shape
(i, j)) F(i, j)|∇φ
n
(i, j)|,
(12)
where w is a weighting factor between the image-
based force and the knowledge-driven force. To il-
lustrate the ability of the proposed shape prior to con-
strain geometrically an active contour, we show the
evolution of the contour under the influence of the
proposed shape prior term only (i.e. w = 0). We
present in Fig.2 an example of successive evolutions
between several shapes of different topologies. We
have chosen for initial curve a green square. The first
shape of reference is a tree leaf. An intermediate step
in this evolution is shown by the first row and the fi-
nal curve is presented by the last column. This last
configuration of the contour is used as an initial curve
for the next experiment by taking the image of the
left and right ventricles of the heart as a reference and
then finally in the same way by taking the shape of a
pen and a ring as shapes of reference.
4 CASE OF MANY REFERENCES
In presence of many templates, we have to choose the
VISAPP2014-InternationalConferenceonComputerVisionTheoryandApplications
456

Figure 2: Curve evolution under the proposed shape prior.
most suitable one according to the evolving curve. In
(Fang and Chan, 2006), a new statistical shape prior is
proposed for robust object detection. This prior model
is capable to handle multiple shape states of the ob-
ject. A Gaussian Mixture Model (GMM) is used to
estimate the data distribution in the feature subspace
and a Bayesian classifier is used to assign the cur-
rently detected object to the most similar shape clus-
ter. A shape prior is then constructed by using the sta-
tistical properties of that cluster to constrain the sub-
sequent curve evolution. This model requires a pre-
liminary step which consist in aligning the training
data. Besides PCA must be applied. In (Charmi et al.,
2009), the authors proposed a geometric approach to
add prior information to the snake model in case of
many references. A set of complete and locally sta-
ble invariants to Euclidean transformations, based on
Fourier transform of the contour, is used to define new
force which makes the snake overcome some well-
known problems. Motivated by (Charmi et al., 2009),
we propose in this section to use as criterion the dis-
tance between a complete family of similarity invari-
ant features based on the AFMT suggested in (Ghor-
bel, 1994; Derrode and Ghorbel, 2001). This family
can be easily rewritten and applied to any strictly pos-
itive value σ in the following way, ∀(k, v) ∈ (Z, R):
I
f
σ
(k, v) = M
f
σ
(0, 0)
−σ+iv
σ
e
−ikArg(M
f
σ
(1,0))
M
f
σ
(k, v),
(13)
Completeness is recognized as an important criterion
for full shape discrimination and reconstruction from
features. Since this invariant set is convergent for
square summable functions, it can be shown in (Ghor-
bel, 1994) that the following function defines a true
mathematical distance between shapes :
d
2
(I
f
σ
, I
g
σ
) = (
Z
+∞
−∞
∑
k∈Z
|I
f
σ
(k, v) − I
g
σ
(k, v)|
2
dv)
1
2
,
(14)
f and g represent two gray-scale objects. Due to nu-
merical sampling and approximation, we never have
exactly zero and the value of the distance is used for
the quantification for the similarity between objects,
regardless of their pose, orientation and size in the
image.
5 EXPERIMENTAL RESULTS
In this section, the proposed model with shape prior
will be applied to the segmentation problem. Conse-
quently the model will evolves under both data and
prior terms. In order to reduce the computational
complexity and to have a good estimation of the pa-
rameters of the rigid transformation as in (Foulonneau
et al., 2004; Fang and Chan, 2007), we first evolve the
active contour without shape prior until convergence
(i.e. w = 1). This first result provides an initializa-
tion for the model with prior knowledge. To promote
the convergence to the target shape, we generally give
more weight to prior knowledge (i.e w <= 0.5). In the
next experiment, we compare our model to that pro-
posed by Fang and Chan in (Fang and Chan, 2007).
The shape of reference is provided by image (a). Im-
ages (b) and (c) represent repectivelly the results ob-
tained by our model and the model of Fang and Chan.
It is visually clear that in region of variability (occlu-
sion), the proposed approach gives a better result. By
Figure 3: (a) : The reference, (b) : Result obtained by our
model, (c) : Result obtained by Fang and Chan model, (d)
: Segmentation without shape prior, (e) and (f) : Segmenta-
tion with the proposed model.
the second row, we handle a situation where the object
to be detected is no longer connected (due to missing
parts or hole). In such situations, methods based on
contours alignment does not allow to estimate the pa-
rameters of the rigid transformation. Thanks to regis-
tration by phase correlation, our model can handle this
case and consequently the detection of the target ob-
ject. In order to illustrate how the calculus complex-
ity can be reduced by updating the evolving level set
function only in the regions of variability between the
reference and the target objects, we compute the exe-
cution time for the image (b) until convergence with
InvariantShapePriorKnowledgeforanEdge-basedActiveContours-InvariantShapePriorforActiveContours
457
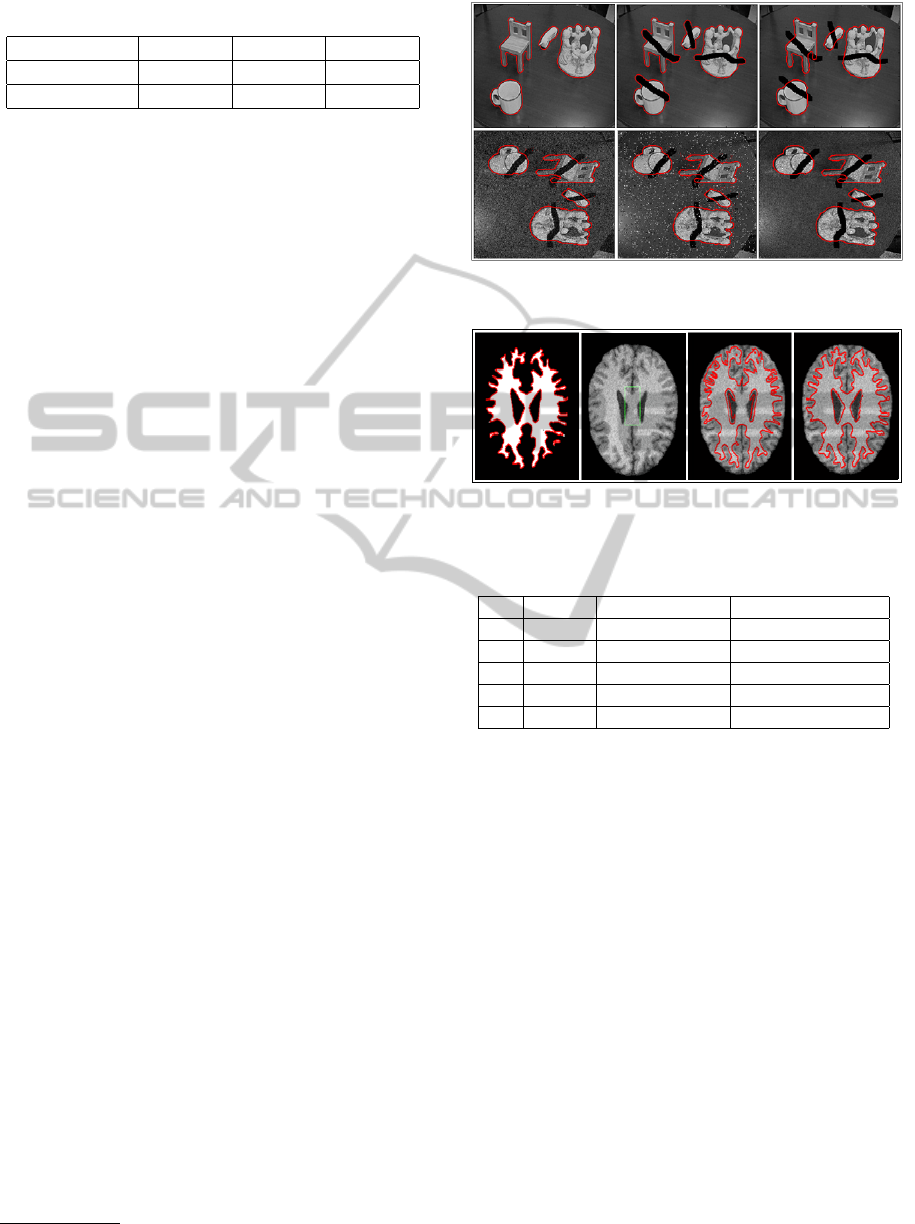
Table 1: Execution time depending on the image size.
128x128 256x256 512x512
Our model 9.743 30.671 151.998
Fang’s model 10.157 41.153 299.3
different sizes (128x128, 256x256 and 512x512). We
recall that for the model proposed by (Fang and Chan,
2007), the proposed shape prior is as follows :
φ
n+1
(i, j) = φ
n
(i, j) + ∆t(φ
∗
(i, j) − φ
n
(i, j)),
(15)
where φ
∗
is the shape model. We set the same values
for the weighting factor and time step and we consider
that the shape of reference (the shape model) is given.
The table below presents the needed execution time
(in seconds) to have satisfactory results. It’s clear that
for an important image size, our approach needs less
iterations to reach good results. In Fig. 4, the case
of real image with several objects under partial oc-
clusions and different types of noise (Gaussian, Salt
and Pepper and Speckle) is considered. Segmentation
without shape prior fails to detect the familiar objects
(second image of first row). However, using the shape
prior, the proposed model succeeds in segmenting the
desired objects (third image of first row). For the sec-
ond row, a rotation of −90
◦
with differents kind of
noise are applied. Results seems to be satisfactory.
In what follows, our model is applied to medi-
cal images obtained from Brain Web Simulated Data
Base
1
. We focus on the segmentation of white matter
of slice 56 that contains holes. The first image repre-
sents the reference segmentation. We have chosen to
initialize the model with a green curve. The obtained
contours without the constraint of shape are presented
by the third image. Starting with this result and after
the registration step, final segmentation based on prior
knowledge and image-based information is presented
by the last image. Table 2 shows the value of RMSE
(Root Mean Square Error), execution time until con-
vergence and the time for parameters estimation (in
seconds) of the rigid transformation for different val-
ues of w. The image size is 256 x 256. We set the total
number of iterations equals to 500. The prior knowl-
edge is introduced at the iteration 400 for different
values of w. For the second part of the experiments,
we assume that the reference shape is unknown and
we rely on the set of invariants presented in section
4 to choose the most appropriate template. Thus the
proposed algorithm is as follows :
1. Segmentation of the target object using the ac-
tive contours model (Malladi et al., 1995) without
shape prior.
1
http://mouldy.bic.mni.mcgill.ca/brainweb/
Figure 4: Several object detection under partial occlusion
and noise.
Figure 5: Segmentation of brain’s white matter.
Table 2: Variation of the RMSE and the execution time de-
pending on w.
w RMSE Execution time Motion estimation
1 0.549 24.563 -
0.8 0.237 26.264 0.430
0.4 0.230 27.009 0.470
0.1 0.222 24.798 0.375
0 0.216 27.161 0.526
2. When the evolving curve becomes stable, we
compute the set of invariant descriptors associated
with the target object.
3. We compare this set of descriptors to those associ-
ated with the available templates computed at an
off-line step, then we select the reference shape
presenting the smallest Euclidean distance.
4. Then, we perform the registration step and we
compute the proposed shape prior.
5. Finally, we evolve the model under both image
and prior forces.
In what follows (Fig.6, second row), we have
occluded some objects from the COIL database
(Columbia University) and for every object, we seek
for the best template from the available ones (first
row). For each shape, we compute its associated in-
variant descriptors to choose the appropriate template.
Table 3 summarizes the obtained results and Fig.7
shows the final segmentation without and with our
proposed method.
VISAPP2014-InternationalConferenceonComputerVisionTheoryandApplications
458
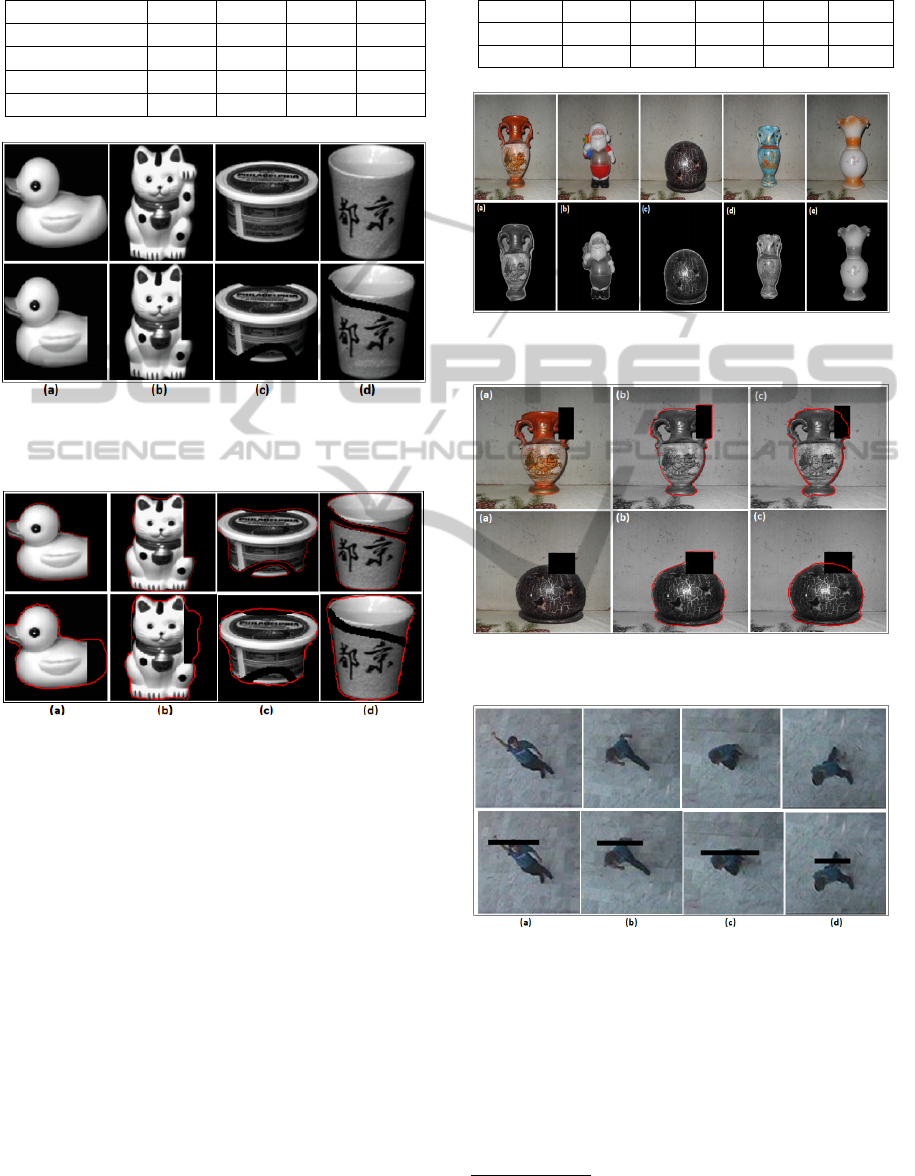
Table 3: Shape distance between every occluded object and
the set of the available references.
(a) (b) (c) (d)
(a) + occlusion 0,471 1,376 1,698 0,924
(b) + occlusion 1,460 1,113 2,088 1,445
(c) + occlusion 1,616 2,038 1,161 1,494
(d) + occlusion 1,519 1,854 1,933 1,419
Figure 6: Selected objects from the COIL database
(Columbia University), First row : the original objects, sec-
ond row : objects after partial occlusions and missing parts.
Figure 7: Detection of the familiar objects without (first
row) and with the proposed method (second row).
For this example, the selected objects were ex-
tracted from the background. Hence we directly com-
pute the value of shape descriptors on the gray-scale
images. Then we select the template of every tar-
get image. In real situation, we have to extract the
target object from the background using the active
contours model in order to compute the set of invari-
ant shape descriptors. The following experiment il-
lustrates the proposed algorithm. Fig.8 presents sev-
eral images of reference. The objects of interest were
isolated from the cluttered background of the image
using the edge-based active contours (Malladi et al.,
1995). We propose to detect the true edges of the tar-
get shapes (1) and (2) which are partially occluded
(see Fig.9, images (a) from first and second rows).
Table 4 shows the Euclidean distance between the tar-
get object’s invariants and those associated with the
available shapes of reference.
Table 4: Shape distance between the two target images and
the set of available reference objects.
(a) (b) (c) (d) (e)
Target 1 0.426 0.988 1.208 1.020 0.805
Target 2 1.308 1.509 1.160 1.364 1.483
Figure 8: The reference images and the associated objects
of interest.
Figure 9: Object detection (b) without shape prior, (c) with
shape prior.
Figure 10: Different human states under partial occlusions.
Once the reference shape with small distance is
selected, its associated level set function is used to
constrain the contour evolution towards the true con-
tours of the object of interest. For the last experiment,
we consider the segmentation of human shape under
different states and partial occlusions. Fig.10 shows
the considered human shape states. The used images
were obtained from
2
. We note that unlike the work
2
http://homepages.inf.ed.ac.uk/rbf/CAVIAR/
InvariantShapePriorKnowledgeforanEdge-basedActiveContours-InvariantShapePriorforActiveContours
459

of (Fang and Chan, 2006), the use of invariant fea-
tures allows to avoid the registration step at the learn-
ing stage and the computation of PCA on the training
data in order the estimated the appropriate number of
clusters in a low dimensional feature subspace. The
final detection results are given by Fig.11.
Figure 11: Detection of partially occluded human shapes in
video images. First row shows the detection results obtained
by the traditional edge-based active contours and the Sec-
ond row shows the result obtained by our proposed method.
6 CONCLUSIONS
New method of geometric active contours with shape
prior is presented in this research. This approach uses
the registration by phase correlation and a set of in-
variant descriptors to define prior knowledge. Exper-
iments have shown the ability of the new added term
to improve the robustness of the detection process in
presence of missing parts and partial occlusions of the
target objects. The addition of shape prior has not
increased significantly the execution time given that
the proposed approach does the registration only once
and it is done by the Fast Fourier Transform unlike
(Foulonneau et al., 2006; Charmi et al., 2008) where
at each iteration shape descriptors are calculated for a
given order which has to be set empirically. In fact, a
small order gives unsatisfactory results and a big one
increase significantly the execution time. As future
perspectives, we are working on applying our model
in the context of medical application where the shape
of reference is given by medical atlas in order to aid in
the diagnosis. Also, we plan to extend this approach
to more general transformations such as affine trans-
formations.
REFERENCES
Bresson, X., Vandergheynst, P., and Thiran, J. (2003). A pri-
ori information in image segmentation : energy func-
tional based on shape statistical model and image in-
formation. In Proc. of IEEE Conference on Image
Processing.
Caselles, V., Kimmel, R., and Sapiro, G. (1997). Geodesic
active contours. In Int. J. of Comp. Vis.
Chan, T. and Vese, L. (2001). Active contours without
edges. In IEEE Trans. Imag. Proc.
Chan, T. and Zhu, W. (2005). Level set based shape prior
segmentation. In CVPR.
Charmi, M., Derrode, S., and Ghorbel, F. (2008). Fourier-
based shape prior for snakes. In Pat. Recog. Let.
Charmi, M., Derrode, S., and Ghorbel, F. (2009). Using
fourier-based shape alignment to add geometric prior
to snakes. In ICASSP.
Charmi, M., Mezghich, M., M’Hiri, S., Derrode, S., and
Ghorbel, F. (2010). Geometric shape prior to region-
based active contours using fourier-based shape align-
ment. In IST.
Chen, Y., Thiruvenkadam, S., Tagare, H., Huang, F., Wil-
son, D., and Geiser, E. (2001). On the incorpora-
tion of shape priors into geometric active contours. In
IEEE Workshop on Variational and Level Set Methods
in Computer Vision.
Cohen, L. (1991). On active contour models and balloons.
In Graphical Models Image Process.
Cremers, D., Sochen, N., and Schnorr, C. (2003). To-
wards recognition-based variational segmentation us-
ing shape priors and dynamic labelling. In Interna-
tional Conference on Scale Space Theories in Com-
puter Vision.
Derrode, S. and Ghorbel, F. (2001). Robust and ef-
ficient fourier-mellin transform approximations for
gray level image reconstruction and complete invari-
ant description. In Computer Vision and Image Un-
derstanding.
Fang, W. and Chan, K. (2006). Using statistical shape priors
in geodesic active contours for robust object detection.
In ICPR.
Fang, W. and Chan, K. (2007). Incorporating shape prior
into geodesic active contours for detecting partially
occluded object. In Pattern Recognition.
Foulonneau, A., Charbonnier, P., and Heitz, F. (2004). Con-
traintes gomtriques de formes pour les contours actifs
orients rgion : une approche base sur les moments de
legendre. In Traitement du signal.
Foulonneau, A., Charbonnier, P., and Heitz, F. (2006).
Affine-invariant geometric shape priors for region-
based active contours. In IEEE Trans. Patt. Anal.
Mach. Intell.
Ghorbel, F. (1994). A complete invariant description for
grey-level images by the harmonic analysis approach.
In Pattern Recognition Lett.
Kass, M., Witkin, A., and Terzopoulos, D. (1988). Snakes :
active contour models. In Int. J. of Comp.Vis.
Leventon, M., Grimson, E., and Faugeras, O. (2000). Sta-
tistical shape influence in geodesic active contours. In
Proc. of IEEE Conference on Computer Vision and
Pattern Recognition.
Malladi, R., Sethian, J., and Vemuri, B. (1995). Shape mod-
eling with front propagation: A level set approach. In
IEEE Trans. Patt. Anal. Mach. Intell.
VISAPP2014-InternationalConferenceonComputerVisionTheoryandApplications
460

M’Hiri, S., Mezghich, M., and Sellemi, M. (2012). Con-
tours actifs avec a priori de forme bas ´e sur la
transform ´ee de fourier-mellin analytique. In Revue
Traitement du Signal.
Osher, S. and Sethian, J. (1988). Fronts propagating
with curvature-dependent speed: algotithms based on
hamilton-jacobi formulation. In J.of Computational
Physics.
Sellami, M. and Ghorbel, F. (2012). An invariant similarity
registration algorithm based on the analytical fourier-
mellin transform. In EUSIPCO.
Xu, C. and Prince, L. (1997). Gradient vector flow: A
new external force for snakes. In IEEE Proc. Conf.
on Computer Vision and Pattern Recognition.
Zhang, T. and Freedman, D. (2003). Tracking objects using
density matching and shape priors. In International
Conference on Computer Vision.
InvariantShapePriorKnowledgeforanEdge-basedActiveContours-InvariantShapePriorforActiveContours
461
