
Boosted Random Forest
Yohei Mishina, Masamitsu Tsuchiya and Hironobu Fujiyoshi
Department of Computer Science, Chubu University, 1200 Matsumoto-cho, Kasugai, Aichi, Japan
Keywords:
Boosting, Random Forest, Machine Learning, Pattern Recognition.
Abstract:
The ability of generalization by random forests is higher than that by other multi-class classifiers because of
the effect of bagging and feature selection. Since random forests based on ensemble learning requires a lot of
decision trees to obtain high performance, it is not suitable for implementing the algorithm on the small-scale
hardware such as embedded system. In this paper, we propose a boosted random forests in which boosting
algorithm is introduced into random forests. Experimental results show that the proposed method, which
consists of fewer decision trees, has higher generalization ability comparing to the conventional method.
1 INTRODUCTION
Random forest(Breiman, 2001) is a multi-class clas-
sifier that is robust against noise, has high discrimina-
tion performance, and is capable of training and clas-
sifying at high speed. It is therefore attracting atten-
tion in manyfields, including computer vision, pattern
recognition, and machine learning(Amit and Geman,
1997), (Lepetit and p. Fua, 2006), (J. Shotton and
Cipolla, 2008), (J. Shotton et al., 2011), (Gall et al.,
2011). Random forest controls loss of generalization
in training due to overfitting by introducing random-
ness in bagging and feature selection(Ho, 1998) when
constructing an ensemble of decision trees. Each
decision tree in random forest is independent, so
high speed can be attained by parallel processing in
tree training and classification. Boosting(Freund and
Schapire, 1995) is a typical ensemble training algo-
rithm that is used to sequentially construct classifiers
for random forest that involve independent decision
trees. Boosting is an ensemble training algorithm that
combines weak learners, which individually have low
discriminating performance, to construct a classifier
of higher discriminating performance. Boosting gen-
erally attains high discrimination by sequential train-
ing of classifiers in which the training sample for
which the previous classifier produced classification
errors is used to train the subsequent classifier to pro-
duce correct classification. However, boosting tends
to overfit the training sample. Random forest, on the
other hand, uses randomness in the construction of the
decision trees, thus avoiding overfitting to the training
sample. For that reason, a large number of decision
trees must be constructed to obtain high generality.
However, increasing the number of decision trees in-
creases the memory requirements, so that approach is
not suited to implementation on small-scale hardware
such as embedded system. We therefore propose a
boosted random forest method, in which a boosting
algorithm is introduced in random forest. The pro-
posed method constructs complementary classifiers
by successive decision tree construction and can yield
classifiers with smaller decision trees while maintain-
ing discrimination performance.
2 RANDOM FOREST
Random forest is an ensemble training algorithm that
constructs multiple decision trees. It suppresses over-
fitting to the training samples by random selection
of training samples for tree construction in the same
way as is done in bagging(Breiman, 1996),(Breiman,
1999), resulting in construction of a classifier that is
robust against noise. Also, random selection of fea-
tures to be used at splitting nodes enables fast train-
ing, even if the dimensionality of the feature vector is
large.
2.1 Training Process
In the training of random forest, bagging is used to
create sample sub sets by random sampling from the
training sample. One sample set is used to construct
one decision tree. At splitting node n, sample set S
n
is split into sample sets S
l
and S
r
by comparing the
594
Mishina Y., Tsuchiya M. and Fujiyoshi H..
Boosted Random Forest.
DOI: 10.5220/0004739005940598
In Proceedings of the 9th International Conference on Computer Vision Theory and Applications (VISAPP-2014), pages 594-598
ISBN: 978-989-758-004-8
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

value of feature quantity x
i
with a threshold value
τ. The splitting function of the splitting node se-
lects combinations that can partition the most samples
from among randomly selected features {f
k
}
K
k=1
and
threshold {τ
h
}
H
h=1
for each class. The recommended
number of feature selections, K, is the square root of
the feature dimensionality. The evaluation function
used for selecting the optimum combination is the in-
formation gain, ∆G. The splitting processing is re-
peated recursively until a certain depth is reached or
until the information gain is zero. A leaf node is then
created and the class probability P(c|l) is stored.
2.2 Classification Process
An unknown sample is input to all of the decision
trees, and the class probabilities of the leaf nodes ar-
rived at are output. The class that has the largest av-
erage of the class probabilities obtained from all of
the decision trees, P
t
(c|x), according to Eq. (1) is the
classification decision.
P(c|x) =
1
T
T
∑
t=1
P
t
(c|x) (1)
2.3 Number of Decision Trees and
Discriminating Performance
Random forest achieves generality by using a large
number of decision trees for ensemble training. How-
ever, it is difficult to obtain the optimum number of
trees for training, so there are many redundant deci-
sion trees that consume a large amount of memory.
3 BOOSTED RANDOM FOREST
Random forest is robust against noise and has high
generality because of random training. However, it
requires many decision trees, as using fewer deci-
sion trees reduces performance. It therefore cannot
maintain generality when implemented on small-scale
hardware. For that reason, boosting is introduced to
random forest. The purpose of using boosting is to
maintain generality even with a small number of de-
cision trees by using the fact that sequential training
constructs complementary decision trees for the train-
ing samples.
3.1 Training Process
The proposed training algorithm involves one proce-
dure for when the sample weighting is updated and
another procedure for when there is no
Algorithm 1: Proposed method.
Require: Training samples {x
1
,y
1
,w
1
},..., {x
N
,y
N
,w
N
};
x
i
∈ X , y
i
∈ {1,2, . . .,M},w
i
Init: Initialize sample weight w
i
:
w
(1)
i
⇐
1
N
.
Run:
for t = 1 : T do
Make subset S
t
from training samples.
∆G
max
⇐ −∞.
for k = 1 : K do
Random sampling from feature f
k
.
for h = 1 : H do
Random sampling from threshold τ
h
.
Split S
n
into S
l
or S
r
by f
k
and τ
h
.
Compute information gain ∆G:
∆G = E(S
n
) −
|S
l
|
|S
n
|
E(S
l
) −
|S
r
|S
n
|
E(S
r
).
if ∆G > ∆G
max
then
∆G
max
⇐ ∆G
end if
end for
end for
if ∆G
max
= 0 or reach a maximum depth then
Store the probability distribution P(c|l) to leaf node.
else
Generating a split node recursively.
end if
if Finished training of decision tree then
Estimate class label ˆy
i
:
ˆy
i
= arg max
c
P
t
(c|l).
Compute error rate of decision tree ε
t
:
ε
t
=
N
∑
i:y
i
6=ˆy
i
w
(t)
i
/
N
∑
i=1
w
(t)
i
.
Compute weight of decision tree α
t
:
α
t
=
1
2
log
(M−1)(1−ε
t
)
ε
t
if α > 0 then
Update weight of training sample w
i,t+1
:
w
(t+1)
i
=
(
w
(t)
i
exp(α
t
) if y
i
6= ˆy
i
w
(t)
i
exp(−α
t
) otherwise.
else
Reject a tree
end if
end if
end for
updating. First, a training sample of size N,
{x
1
,y
1
,w
1
},.. ., {x
N
,y
N
,w
N
}, that have a feature of
dimension d and class labels y ∈ M are prepared. The
training sample weight, w, is initialized to
1
N
. Sample
sets are created by random sampling from the train-
ing sample. Decision trees are constructed using the
sample sets in the same way as in random forest. Pro-
posed algorithm 1 is described in above.
3.1.1 Node Splitting
The flow of the proposed method is illustrated in
Fig. 1. The splitting function selects combinations of
randomly-prepared features and thresholds that have
BoostedRandomForest
595

Figure 1: Training algorithm of the proposed method.
the highest information gain. The information gain
∆G is computed by
∆G = E(S
n
) −
|S
l
|
|S
n
|
E(S
l
) −
|S
r
|
|S
n
|
E(S
r
), (2)
where S
n
is sample set at node n, S
l
is sample set at
left child node, S
r
is sample set at right child node,
and E(S ) is entropy computed by
E(S ) = −
M
∑
j=1
P(c
j
)logP(c
j
). (3)
In calculating the information gain, the samples are
prioritized by largest weight and the probability of
class c
j
, P(c
j
), is calculated using the weight of sam-
ple i, w
i
computed using
P(c
j
) =
∑
i∈S∧y
i
=c
j
w
i
/
∑
i∈S
w
i
, (4)
where, S is the sample set that arrived at node. A leaf
node is created when recursivesplitting has developed
the decision tree to a certain depth or when the infor-
mation gain of a sample set that has reached a node is
zero. The leaf node stores the class probability P(c)
obtained with Eq. (4).
3.1.2 Decision Tree Weighting
In the same way as for multi-class boosting(Kim and
Cipolla, 2008), (Saberian and Vasconcelos, 2008), the
decision tree weight, α
t
, is calculated by
α
t
=
1
2
log
(M− 1)(1− ε
t
)
ε
t
, (5)
where, ε
t
is the error rate of the decision tree and M
is the number of classes. The expected value for the
successful classification rate in random classification
is
1
M
. If the classification error rate exceeds 1 −
1
M
,
the value of α is negative in Eq. (5) and the decision
tree is discarded. The training sample is classified by
the constructed decision trees and the error rate is cal-
culated from the weights of the incorrectly classified
samples as
ε
t
=
N
∑
i:y
i
6= ˆy
i
w
(t)
i
/
N
∑
i=1
w
(t)
i
. (6)
3.1.3 Updating Training Sample Weights
Decision trees that easily correct classification of the
samples that have been incorrectly classified in the
next step are constructed by making the weights of
incorrectly classified samples large as
w
(t+1)
i
=
(
w
(t)
i
exp(α
t
) if y
i
6= ˆy
i
w
(t)
i
exp(−α
t
) otherwise,
(7)
where ˆy
i
is estimated class label using
ˆy
i
= arg max
c
P
t
(c|l). (8)
After updating the training sample weights, the
weights are normalized to N. Constructing the deci-
sion trees and updating the training sample weights in
that way is repeated to obtain T decision trees and T
weighted decision trees. After all decision trees have
been constructed, the decision tree weights are nor-
malized.
3.2 Classification Process
An unknown sample is input to all of the decision
trees as shown in Fig. 1, and the class probabilities
that are stored in the arrived-at leaf nodes are output.
Than, the outputs of the decision trees, P
t
(c|x), are
weight-averaged using the decision tree weights as
P(c|x) =
1
T
T
∑
t=1
α
t
P
t
(c|x). (9)
The class that has the highest probability ˆy is output
as the classification result by
ˆy = arg max
c
P(c|x). (10)
4 EXPERIMENTAL RESULTS
To show the effectiveness of the proposed method,
the number of nodes are compared for the proposed
method and the conventional method at the same level
of generalization ability. For the proposed method,
we investigated procedures with and without sequen-
tial sample weight updating.
VISAPP2014-InternationalConferenceonComputerVisionTheoryandApplications
596
4.1 Data Set
The evaluation experiments used four data sets,
Pendigits, Letter, Satelite, and Spambase, from those
published by the UCI Machine Learning Repository
as a set of machine training algorithm benchmarks.
The data sets are described briefly in Table 1.
Table 1: Data sets.
Dataset Training Tests Class Dim.
Pendigits 7,494 3,498 10 16
Letter
10,000 10,000 26 16
Satelite 4,435 2,000 6 36
Spamebase
3,221 1,380 2 57
4.2 Training Parameter
In this experiment, the depth of the decision trees for
training parameters was fixed at 5, 10, 15, and 20.
We compared the minimum value of the miss rate by
changing the number of decision trees. The number
of candidates for the split function was 10 times the
square root of the number of feature dimensions.
4.3 Experimental Results
The error ratio for each dataset of the conven-
tional random forest(RF) and for the proposed
method(boosted random forest with or without sam-
ple weight updating, BRF, BRF w/o updating) are
shown in Table 2, 3, and 4 respectively. The miss
Table 2: Error rate by random forest [%].
Depth Pen Letter Satelite Spame Ave.
5 8.38 22.95 13.05 6.88 12.82
10 3.97 7.25 9.95 5.58 6.69
15 3.66 6.40 9.30 5.14 6.13
20 3.69 6.20 9.10 4.71 5.92
Table 3: Error rate by boosted random forest w/o updating
[%].
Depth Pen Letter Satelite Spame Ave.
5 8.18 22.75 12.95 6.81 12.67
10 3.92 7.50 10.05 5.58 6.76
15 3.66 6.20 9.40 5.07 6.08
20 3.72 6.10 9.10 4.64 5.89
rate of the proposed method was lower than that of the
random forest when the number of depth for decision
trees was shallower. In contrast, when the number of
depth for decision trees was deeper, the miss rate of
the proposed method was equal to or lower than that
of the random forest. It is clear that the classification
Table 4: Error rate by boosted random forest [%].
Depth Pen Letter Satelite Spame Ave.
5 3.72 11.45 10.70 4.57 7.61
10 2.55 5.00 8.35 4.13 5.01
15 2.69 4.55 8.25 3.77 4.81
20 2.66 4.40 8.20 3.55 4.70
!"
#"
$!"
$#"
%!"
%#"
&!"
!" $!" %!" &!" '!" #!" (!" )!" *!" +!" $!!" $$!" $%!" $&!" $'!" $#!"
!"##$%&'()*+
,-./(%$01$'%((#
!!,-"
!!.,-"/01"2345678"
!!.,-"
!"
#"
$!"
$#"
%!"
%#"
&!"
!" $!" %!" &!" '!" #!" (!" )!" *!" +!" $!!" $$!" $%!" $&!" $'!" $#!"
!"##$%&'()*+
,-./(%$01$'%((#
!!,-"
!!.,-"/01"2345678"
!!.,-"
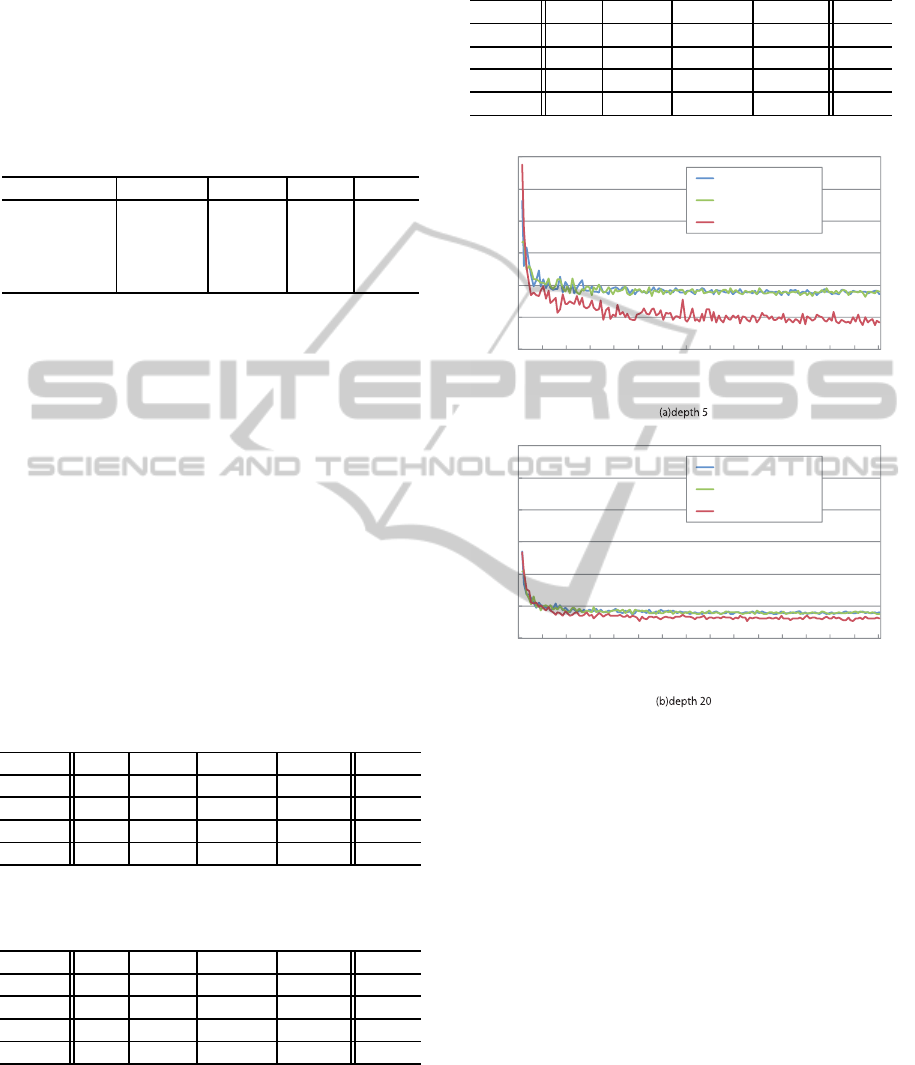
Figure 2: Generalization error of pendigits.
performance of the boosted random forest with up-
dating sample weight is superior. Figure 2 shows the
miss rate for each depth in the case of the “Pendig-
its” dataset. From Fig. 2, we realized that the ran-
dom forest requires more depth in order to obtain a
higher classification performance than the proposed
method. In contrast, the proposed “boosted random
forest” method does not require more depth because
it has been trained by choosing the split function with
difficult training samples at upper nodes, which have
a heavier sample weight.
4.4 Memory Usage for Decision Trees
For the implementation of decision trees on small-
scale hardware, less memory is better. Therefore,
in this section we compare the amount of memory
needed for each method. For each node, the total
memory of a split function is 11 bytes, of which the
selected feature dimension is 1 byte, the threshold is
BoostedRandomForest
597
2 bytes, and the pointer for a child node is 8 bytes.
For each leaf node, total memory is estimated by the
number of class bytes. Thus, we estimate the amount
of memory B required for decision trees by
B =
T
∑
t=1
(N
s,t
× 11+ N
l,t
× M), (11)
where the number of trees is T, number of split nodes
is N
s,t
, number of leaf nodes is N
l,t
and number of
classes is M.
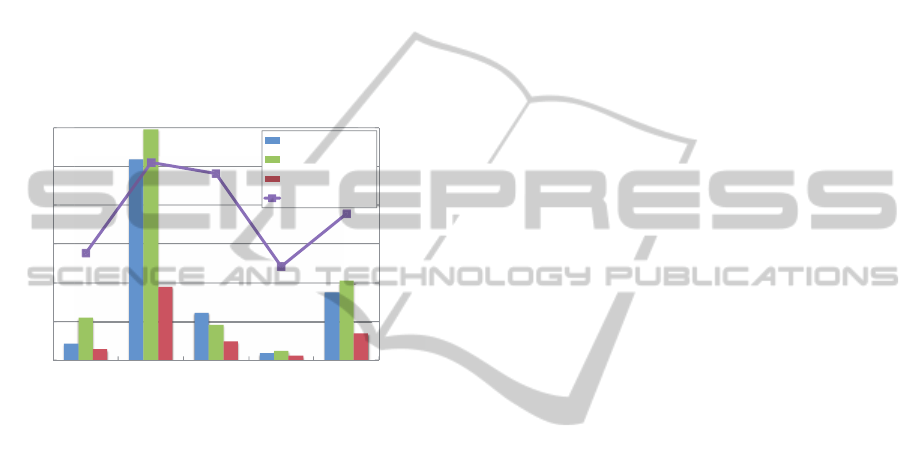
Figure 3 shows the amount of memory for each
method with minimum error rate and the reduction
ratio of the proposed method compared to the ran-
dom forest. The amount of memory required by the
!"!##
$%"!##
%!"!##
&%"!##
!#
%!!#
'!!!#
'%!!#
$!!!#
$%!!#
(!!!#
)*+,-.-/0# 1*2*3# 45/*6-/*# 4758*950*# :;*35.*#
!"#$%&'()*+,)
-".'/0)*12,
!!<=#
!!><=#?@A#B7,5C+.#
!!><=#
3*,BDCA+#
Figure 3: Amount of memory and reduction rate.
proposed “boosted random forest” method is signif-
icantly reduced while maintaining the higher classi-
fication performance. Due to sequential training, the
boosted random forest consists of complementary de-
cision trees that enable the final classifier to be con-
structed in favor of those instances misclassified by
previous decision trees.
5 CONCLUSIONS
We have proposed a boosted random forest in which
a boosting algorithm is introduced to a conventional
random forest. The boosted random forest maintains
a high classification performance, even with fewer
decision trees, because it constructs complementary
classifiers through sequential training by boosting.
Experimental results show that the total memory re-
quired by the boosted random forest is 47% less
than that of the conventional random forest. It is
thus suited to implementation in low-memory, small-
scale hardware applications such as embedded sys-
tems. Our future work includes experimental evalua-
tion for image recognition problems that are currently
difficult to classify.
REFERENCES
Amit, Y. and Geman, D. (1997). Shape quantization and
recognition with randomized trees. In Neural Compu-
tation. MIT Press.
Breiman, L. (1996). Bagging predictors. In Machine Learn-
ing. Springer.
Breiman, L. (1999). Using adaptive bagging to debias re-
gressions. In Technical Report. Statistics Dept. UCB.
Breiman, L. (2001). Random forests. In Machine learning.
Springer.
Freund, Y. and Schapire, R. (1995). A decision-theoretic
generalization of on-line learning and an applica-
tion to boosting. In Computational learning theory.
Springer.
Gall, J., Yao, A., Razavi, N., Van Gool, L., and Lempitsky,
V. (2011). Hough forests for object detection, track-
ing, and action recognition. In Pattern Analysis and
Machine Intelligence. IEEE.
Ho, T. K. (1998). The random subspace method for con-
structing decision forests. In Pattern Analysis and Ma-
chine Intelligence. IEEE.
J. Shotton, a. A. F., Cook, M., Sharp, T., Finocchio, M.,
Moore, R., Kipman, A., and Blake, A. (2011). Real-
time human pose recognition in parts from single
depth images. In Computer Vision and Pattern Recog-
nition. IEEE.
J. Shotton, M. J. and Cipolla, R. (2008). Semantic texton
forests for image categorization and segmentation. In
Computer Vision and Pattern Recognition. IEEE.
Kim, T.-K. and Cipolla, R. (2008). Mcboost: Multiple clas-
sifier boosting for perceptual co-clustering of images
and visual features. In Advances in Neural Informa-
tion Processing Systems.
Lepetit, V. and p. Fua (2006). Keypoint recognition using
randomized trees. In Pattern Analysis and Machine
Intelligence. IEEE.
Saberian, M. and Vasconcelos, N. (2008). Multiclass boost-
ing: Theory and algorithms. In Advances in Neural
Information Processing Systems.
VISAPP2014-InternationalConferenceonComputerVisionTheoryandApplications
598
