
A Low Illumination Environment Motion Detection Method based on
Dictionary Learning
Huaxin Xiao Yu Liu, Bin Wang, Shuren Tan and Maojun Zhang
College of Information System and Management, National University of Defense Technology, Changsha, P.R. China
Keywords:
Low illumination, Motion detection, Dictionary learning, Sparse coding.
Abstract:
This paper proposes a dictionary-based motion detection method on video images captured under low light
with serious noise. The proposed approach trains a dictionary by background images without foreground. It
then reconstructs the test image according to the theory of sparse coding, and introduces the Structural Simi-
larity Index Measurement (SSIM) as the detection standard to identify the detection caused by the brightness
and contrast ratio changes. Experimental results show that compared to the mixture of Gaussian model and
ViBe method, the proposed method can reach a better result under extreme low illumination circumstance.
1 INTRODUCTION
With the continuous improvement of equipment man-
ufacturing and computer processing capability, the
intelligent video surveillance technology has been
widely applied to transportation, industry, defense
and other fields. The intelligent processing in video
surveillance such as tracking, classification, behavior
understanding and so on, depends on the correct mo-
tion detection. Therefore, motion detection is a basic
and crucial step with important research significance.
For a fixed scene camera, the commonly used de-
tection methods are frame difference (Hui and Siu,
2007) and background subtraction (Piccardi, 2004).
Frame difference method is fast, but for complex
scenes the accuracy of detection is relatively low.
Study and application on background subtraction are
more widely. The main idea of this algorithm is to
establish a background model of the monitored scene
through a suitable method, then calculate the differ-
ence between the current frame image and the back-
ground model which segments the foreground area
from the scene. Three Gaussian distributions cor-
responding to the road, shadow and vehicle (Fried-
man and Russell, 1997) were used to model the traf-
fic surveillance system. Then, a mixture of multiple
Gaussian distributions (Stauffer and Grimson, 1999)
was employed to model the pixels in the scene which
was proved to be a better solution to the modeling of
complex background. Unlike the mixture of Gaus-
sian model, Oliver et al. (Oliver et al., 2000) took into
account the spatial correlation and captured the eigen-
backgrounds by the eigenvalue decomposition. They
adopted the Distance From Feature Space (DFFS) as a
detection criterion. An incremental principal compo-
nent analysis (Mittal et al., 2009) and robust principal
component analysis (Wright et al., 2009) were respec-
tively introduced which fully considered the structural
information of the image. It can effectively deal with
the brightness and other global changes. Recently, a
universal background subtraction called ViBe (Bar-
nich and Droogenbroeck, 2011) combined three in-
novative mechanisms to obtain a faster and better per-
formance relatively.
The aforementioned methods are mainly for the
complex and dynamic scene in the background, such
as rain, waves and shaking trees, other than the low
illumination environment. Large noise, low value and
small differences in grey level are the typical charac-
teristics of low light images. Excessive large noise
and low grey value bring great influence on detec-
tion, which lead to the existing motion detection al-
gorithms work improperly. In Fig. 1, we compare
Fig. 1(b) the mixture of Gaussian model and Fig. 1(c)
the ViBe method with Fig. 1(d) the proposed method.
Compared with Fig. 1(b) and Fig. 1(c), the proposed
method can effectively reduce the noise caused by low
illumination and make the detection more robust.
In the perspective of the image blocks, the paper
establishes the dictionary for each block, then recon-
structs the test image according to the theory of sparse
coding and finally treats the difference between the
reconstruction image and the denoising background
image and SSIM threshold as the detection criterions.
147
Xiao H., Liu Y., Wang B., Tan S. and Zhang M..
A Low Illumination Environment Motion Detection Method based on Dictionary Learning.
DOI: 10.5220/0004753701470154
In Proceedings of the 3rd International Conference on Pattern Recognition Applications and Methods (ICPRAM-2014), pages 147-154
ISBN: 978-989-758-018-5
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

(a) (b) (c) (d)
Figure 1: Motion detection methods comparison under low light. Fig. 1(a): The test images. The range of illumination in
the test images is 0.1-0.5 lx. Fig. 1(b): The detection results of the mixture of Gaussian model (Stauffer and Grimson, 1999).
Fig. 1(c): The detection results of the ViBe method (Barnich and Droogenbroeck, 2011). Fig. 1(d): The detection results of
the proposed method.
This paper takes the mean of the sum of the collected
background images as a denoising image to ensure
the consistency of each experiment. As a result of the
dictionary learning and sparse coding, the method can
obviously remove most of the noise, and effectively
identify detection caused by the brightness, contrast
and other factors.
The rest of this paper is organized as follows. Sec-
tion 2 describes the basic principle based on three as-
sumptions. Section 3 presents the proposed method.
Section 4 shows the experimental results under differ-
ent illumination circumstances. Section 5 concludes
and discusses future possible research direction.
2 BASIC PRINCIPLE
According to the approximate description of the pro-
posed method on Section 1, the approach can be sim-
ply divided into three parts: basis vectors acquisi-
tion by dictionary learning, image reconstruction with
sparse coding and foreground detection. The princi-
ples of the three parts are based on the below assump-
tions that make a good explanation of the proposed
method in theoretical aspects.
An arbitrary signal x ∈ R
n
can be represented
sparsely and linearly by a small number of atoms in
the dictionary D ∈ R
n×k
:
ˆx = argmin
α
kx −Dαk
2
2
st.kαk
0
≤t (1)
where k is the number of atoms and kαk
0
is the L
0
norm, counting the number of nonzero entries in the
vector.
Many experiments indicate that such sparse de-
composition is very effective in the application of sig-
nal processing (Chen et al., 1998). After the vector-
ization, an image can also be seen as a signal and de-
composed sparsely, as described in the following as-
sumption:
Assumption 1: any of an image can be sparsely
and linearly represented by using some specific basis
vectors in image space.
The information contained in an image can be rep-
resented by the particular structures that are also re-
garded as basis vectors in the image space. So, in Fig.
2(a), we show using the basis vectors to represent an
arbitrary background of a scene.
Sparse decomposition always hopes that the re-
construction signal could be as close as possible to the
original signal. The changes of the structures of the
ICPRAM2014-InternationalConferenceonPatternRecognitionApplicationsandMethods
148
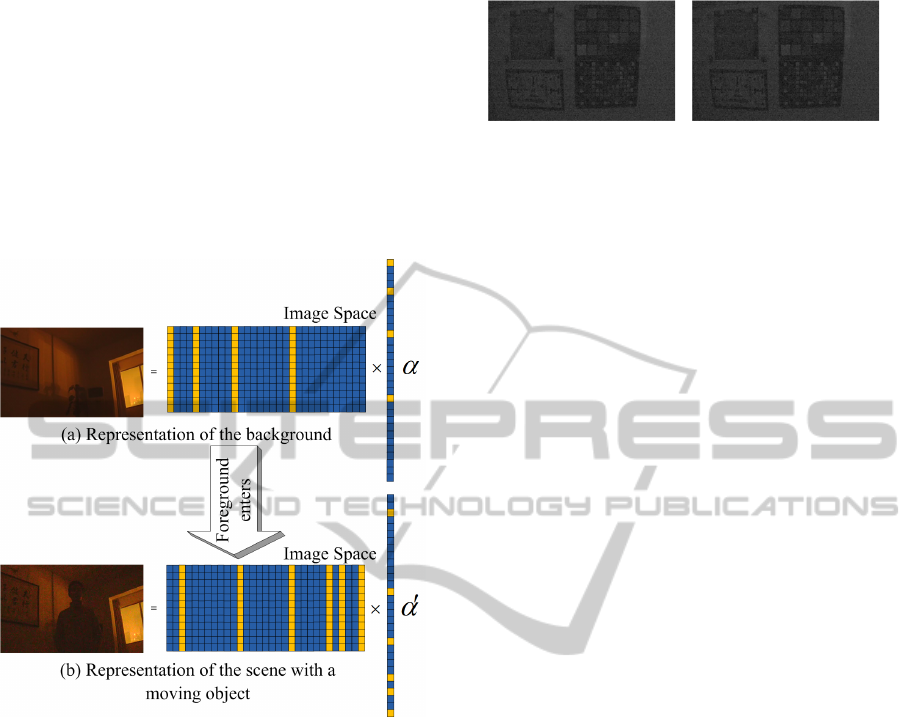
background will bring new information which means
there is a moving target. Then the original sparse de-
composition will not exist, and we should reselect the
bases of the image space. The process is shown in
Fig. 2(b). Based on the above analysis, we propose
the second hypothesis:
Assumption 2: the foreground will lead to changes
in the structures of background, and then make the
backgrounds bases in the image space transform.
Figure 2: Sparse representation of the scene.
With the two assumptions, we can easily under-
stand the proposed approach. When a background im-
age with the foreground is reconstructed by the orig-
inal bases, the part of the background which isnt af-
fected by the foreground can be easily recovered. The
other part, because of lack of the foreground bases,
will be reconstructed with a deviation. Through the
measure of the deviation, we can achieve the purpose
of detection.
The two predominant sources of noise in digi-
tal image acquisition are the stochastic nature of the
photon-counting and the intrinsic thermal and elec-
tronic fluctuations of the acquisition devices. With
the decreasing of the light, the rapid boosting of the
first one will lead to the surveillance video containing
a large number of randomly distributed noise. When
the noise flashing level is too large, it will make the
existing detection methods not effective. Combina-
tion of the basis vectors idea, we consider the noise
satisfies the following assumption:
Assumption 3: noise is randomly and discretely
(a) (b)
Figure 3: The result of denoising. Fig. 3(a): The original
image with 0.05 lx. Fig. 3(b): The reconstructed image.
distributed in the basis vectors of image space.
As described in Assumption 3, statistical noise
is typically distributed through the larger space ran-
domly and irregularly. So, when reconstructing an
image though sparse coding, only several atoms in
dictionary are selected to represent the original sig-
nal. Additionally, most of the noise can be effec-
tively removed. These factors ensure our method can
be well suited for handling low illumination environ-
ments. As shown in Fig. 3, the Fig. 3(a) contains large
noise caused by the low illumination. After the dictio-
nary learning and sparse reconstruction, the Fig. 3(b)
eliminates the noise level, and well preserves the de-
tails.
3 THE PROPOSED METHOD
Those three assumptions described in Section 2 are
the bases for the proposed approach. First, based on
Assumption 1, we use the way of dictionary learn-
ing to obtain the basis vectors of the image space,
and sparse coding to sparsely reconstruct the test im-
age. Then according to Assumption 2, when the
foreground object enters, it changes the structures of
background and that part of recovered image. We can
then combine the threshold region and SSIM values as
the detection standards to determine the foreground
area. In Fig. 4, we draw a brief flowchart about the
process of dealing with each image block in three
parts.
3.1 Dictionary Learning
Dictionary has been proved very effective for sig-
nal reconstruction and classification in audio and im-
age processing domain (Mairal et al., 2010). Com-
pared with the traditional methods such as wavelet
and principal component analysis, dictionary learn-
ing does not emphasize the orthogonality of bases,
which makes its representation of the signal have bet-
ter adaptability and flexibility.
We extract the background frames without fore-
ground from the surveillance video to form a training
ALowIlluminationEnvironmentMotionDetectionMethodbasedonDictionaryLearning
149

Figure 4: The brief flowchart of processing each image
block.
set with N samples. As shown in Fig. 5, the collected
images are divided into m×l blocks of size
√
n ×
√
n
pixels. The jth image block of the ith sample can be
vectorized as a vector ~x
i j
∈ R
n
. Then put the jth im-
age block of each sample together and consist of a
training set X
j
= {~x
i j
| i = 1, ··· ,N} for the ith block.
Its dictionary D
j
∈ R
n×k
satisfies the following for-
mula:
D
j
= argmin
D
j
N
∑
i=1
min
α
i
(k~x
i j
−D
j
α
i
k
2
2
+ λkα
i
k
1
) (2)
where α
i
is the ith sparse coefficient and λ is a regu-
larization parameter.
Figure 5: Creating the training set with N samples. Each
image is divided into m ×l blocks of size
√
n ×
√
n pixels.
We use the Online Dictionary Learning algorithm
(Mairal et al., 2010) to solve the formula (2). In each
loop, the algorithm adopts stochastic gradient descent
method to choose a vector ~x
i j
which is regarded as x
t
from X
j
and t is the times of the repeat. Based on the
previous t −1 loops, it applies sparse coding to get
the tth decomposition coefficient α
t
. The formula is
as follows:
α
t
= argmin
α∈R
k
1
2
kx
t
−D
t−1
αk
2
2
+ λkαk
1
(3)
Then update the dictionary D
t−1
= [d
1
,··· , d
k
col-
umn by column and get a new dictionary D
t
. Update
rules are as follows:
(
u
j
←
1
A
j j
(b
j
−Dα
j
) + d
j
d
j
←
1
max(ku
j
k,1)
u
j
(4)
where A = [a
1
,··· , a
k
] =
∑
t
i=1
α
i
α
T
i
and B =
[b
1
,··· , b
k
] =
∑
t
i=1
x
i
α
T
i
.The new dictionary meets the
penalty function
ˆ
f
t
(D) =
1
t
∑
t
i=1
1
2
kx
i
−D
t−1
α
i
k
2
2
+
λkα
i
k
1
minimum.
The algorithm is simple, fast and suitable for large
scale image processing, and Mairal et al.(2010) have
shown that the algorithm can converge to a fixed
point. The test videos in this article have 1280 ×720
and 720×480 two specifications. High image quality
of the monitored scene will lead to a result of great
data. Other classical dictionary learning algorithms
such as K-SVD (Aharon et al., 2006) take too much
time to train the samples that can not meet the require-
ments of this paper.
We calculate the dictionary of each block in turn
and then obtain the whole image dictionary D:
D = [D
1
,D
2
,··· , D
m×l
] (5)
3.2 Sparse Coding
Sparse coding is a class of methods choosing good
basis vectors automatically for unlabeled data. It dis-
covers basis functions that capture higher level fea-
tures in the data (Lee et al., 2006). In Section 3.1,
we obtain the basis vectors by the dictionary learning.
According to Assumption 1, we can use this set of
basis vectors to reconstruct any of the test image and
get the sparse coefficient on the basis vectors through
sparse coding. For any of the test images Y , we use
the same way of block and vectorization and get the
vectors of blocks {~y
i
∈R
n
|i = 1, ··· ,m ×l}. For any
~y
i
, its sparse coefficients on the dictionary should sat-
isfy the following constraint:
min
α∈R
n
k~y
i
−D
i
α
i
k
2
2
st.kα
i
k
1
≤t (6)
or
min
α∈R
n
1
2
k~y
i
−D
i
α
i
k
2
2
+ λ
1
kα
i
k+
λ
2
2
kαk
2
2
(7)
ICPRAM2014-InternationalConferenceonPatternRecognitionApplicationsandMethods
150

The constraint is a Lasso or Elastic-Net problem
and we adopt the LARS algorithm (Efron et al., 2004)
to solve it. For an arbitrary signal ~y
i
, the algorithm
first computes the covariance matrix D
i
D
T
i
and D
i
~y
i
,
and decomposes them to get the sparse coefficients
with a Cholesky-based algorithm. When the solu-
tion is sufficiently sparse and the scale of the prob-
lem is reasonable, LARS algorithm is very effective.
Furthermore, the solution has the exact precision and
does not rely on the correlation of atoms in the dictio-
nary unless the solution is not unique.
Solve all image blocks in turn with LARS algo-
rithm and we can obtain the sparse coefficients α of
whole image:
α = [α
T
1
,α
T
2
,··· , α
T
m×l
]
T
(8)
Then, the reconstructed image
ˆ
Y is
ˆ
Y = D ×α =
n
~y
i
∈ R
n
| i = 1, ··· ,m ×l
o
(9)
(a) (b)
Figure 6: Sparse reconstruction. Fig. 6(a): The grey scale
images of testing images. Fig. 6(b):The grey scale images
of reconstructed images.
Fig. 6 is a contrast with before and after sparse
reconstruction. Fig. 6(a) and Fig. 6(b) are the grey
scale images of the test images and reconstructed
images respectively. We notice that Fig. 6(b) can
well reconstruct the area of the background without
foreground, while the area with moving target has
a significant change. Furthermore, compared with
Fig. 6(a), Fig. 6(b) has an obvious denoising effect
and effectively reduces the noise impact on the detec-
tion
3.3 Foreground Detection
Referring to the idea of the background subtraction
method, the paper calculates the difference between
the background image
¯
Y and the reconstructed image
ˆ
Y by blocks. It then sums them to be the vector ∆:
∆ =
(
n
∑
j=1
(
¯
Y
i
( j) −
ˆ
Y
i
( j)) | i = 1, ··· m ×l
)
(10)
where
¯
Y
i
( j) and
ˆ
Y
i
( j) are respectively the jth pixel of
ith block in
¯
Y and
~
Y .
Then we use the threshold region E to judge the
vector ∆. Within the region, it means the structure
of the block does not change, i.e. no foreground
accesses. On contrary, there is an object enters the
scene. The paper assumes the data in vector ∆ approx-
imatively follows the Gaussian distribution. There-
fore, we set the upper and lower limit of the threshold
region E with 3σ criterion:
(
maxE = µ + 3σ
minE = µ −3σ
(11)
where µ and σ are the mean and variance of the differ-
ences between background images and reconstructed
images in the training set.
In low illumination environment, the sparse recon-
struction cant distinguish the brightness, contrast and
other information well. When only use the threshold
region to determine whether the structure of the im-
age block is changed, it is easy to cause wrong detec-
tion. To reduce the impact of non-structural informa-
tion, this work introduces the SSIM as the detection
criterion which defines the structure information in-
dependent of the brightness and contrast and reflects
the properties of objects structure in the scene (Wang
et al., 2004). The model of SSIM is defined as follow:
SSIM(X ,Y ) = [l(X,Y )]
α
[c(X,Y )]
β
[s(X,Y )]
γ
(12)
where l(X,Y ), c(X ,Y ) and s(X,Y ) are respectively
the relative function of brightness, contrast and struc-
ture between block X and Y block. α, β and γ are the
coefficients of weight.
We judge these blocks not in the threshold region
again with the SSIM threshold. Though Fig. 7(b), as
a result of only using the threshold region, can effec-
tively detect moving target, we can notice that there
are many erroneous detection blocks with the struc-
ture that are hardly not changed. Calculate the SSIM
ALowIlluminationEnvironmentMotionDetectionMethodbasedonDictionaryLearning
151

values of blocks in blue box and discover a large num-
ber of blocks SSIM values are above 0.8 that indi-
cates many blocks without in the threshold region are
similar to the ones in the background image. So we
can take those blocks whose SSIM values are above
a certain threshold into normal again. Fig. 7(c) and
Fig. 7(d), as results with different SSIM thresholds,
make the detection result more accurate. Especially
in Fig. 7(d), it can filter out the shadow area because
of covering. Since the original images illumination
is too low, in order to facilitate observation, the pa-
per increases the brightness of Fig. 7(b), Fig. 7(c) and
Fig. 7(d).
(a) (b)
(c) (d)
Figure 7: Present the detection results with blue boxes.
Fig. 7(a): The original image with 0.01 lx. Fig. 7(b): Only
using threshold region. Fig. 7(c): Using the threshold re-
gion and SSIM threshold and the threshold of SSIM is 0.9.
Fig. 7(d): Using the threshold region and SSIM threshold
and the threshold of SSIM is 0.8. In order to facilitate ob-
servation, the paper increases the brightness of Fig. 7(b),
Fig. 7(c) and Fig. 7(d).
4 EXPERIMENTAL RESULT
In this paper, the image block is treated as processing
unit and the size of blocks has a certain impact on
the computing speed, detection results and recovered
image effects.
Smaller blocks can ensure the precision of ex-
perimental results, as shown in Fig. 8(a). However,
if the size of the block is over small, it is hardly to
satisfy the accuracy of detection, as shown in the
second row of Fig. 8. Larger blocks can guarantee
the accuracy and have a better denoising effect with
higher computing cost. Precision and accuracy are
a pair of tradeoff parameters and it is difficult to
simultaneously ensure both at a high level. After
several tests, we respectively select 16 × 16 and
40 ×40 as the block size for resolution of 720 ×480
in Fig. 8 and 1280 ×720 in Fig. 9 and Fig. 10.
(a) (b) (c)
Figure 8: Different sizes of blocks comparison under 0.1-
0.5 lx. Present the detection results with blue boxes.
Fig. 8(a): 16 ×16. Fig. 8(b): 40 ×40. Fig. 8(c): 60 ×60.
(a) (b) (c)
Figure 9: The experimental results with 0.5-1.0 lx.
Fig. 9(a): The grey scale images of reconstructed images.
Fig. 9(b): The results indicated by the blue boxes. Fig. 9(c):
The results of segmenting the foreground.
In order to fully test the proposed method, we use
surveillance cameras to capture a number of videos at
different illumination and background environments.
In Fig. 8, 9 and 10, the range of illumination is re-
spectively 0.1-0.5 lx, 0.5-1.0 lx and 0.01-0.05 lx. The
(a) of Fig. 9 and 10 are the recovered grey scale im-
ages by using dictionary learning and sparse coding.
Contrast with the background image, you can find the
area with foreground entering significantly changed.
(b) are the detection results through the threshold re-
gion and SSIM filtering out. Just as shown in Fig. 7,
in order to facilitate observation, the paper increases
the brightness of Fig. 10 (a) and (b). (c) is the result
of dividing the foreground.
For extreme low illumination (under 0.1 lx) and
grey level (less than 15) in Fig. 10, the proposed
method can effectively detect the moving target. For
ICPRAM2014-InternationalConferenceonPatternRecognitionApplicationsandMethods
152

(a) (b) (c)
Figure 10: The experimental results with 0.01-0.05 lx.
Fig. 10(a): The grey scale images of reconstructed im-
ages. Fig. 10(b): The results indicated by the blue boxes.
Fig. 10(c): The results of segmenting the foreground. In or-
der to facilitate observation, the paper increases the bright-
ness of Fig. 10(a) and Fig. 10(b).
small objects suddenly appearing in the background,
the present method can also effectively detect the tar-
get, as shown in Fig. 9. The small objects in the Fig. 9
are a foam cross and a paper box and take about 20
frames to across the whole scene. However, since
the dictionary is learned from the background images
without foreground, the recovered blocks are close to
the background when the colours of foreground and
background are similar. This circumstance increases
the difficulty in detecting, such as the human legs in
the second row of Fig. 10.
Table 1: Detection results under different illumination of
environment and sizes of moving target. The size of the
block is 40 ×40 pixels.
1 lx 0.5 lx 0.1 lx 0.01 lx
5 blocks 100% 100% 40% 20%
10 blocks 100% 90% 70% 60%
30 blocks 89% 85% 83% 70%
50 blocks 86% 90% 80% 68%
100 blocks 85% 88% 79% 76%
In Table 1, we simply census the detection results
under different illumination of environment and sizes
of moving target. The left-most column of the Table
1 presents the number of blocks of the moving object
occupying in the image and the size of the blocks is
40 ×40 pixels. These values are approximation. The
top row in Table 1 shows the different values of illu-
mination. The percent describes the proportion of the
object that the proposed method can detect. We can
find that when the illumination is above 0.5 lx, the
proposed method can detect near 90% of the blocks
of the moving target holding in the image. With the
illumination decreasing to 0.01 lx, it can still iden-
tify about 70% of the blocks while it is difficult for
human vision to distinguish most of them, such as in
Fig. 7. The Table 1 sufficiently reflects the robust of
the proposed method in extreme low illumination en-
vironment.
5 DISCUSSION
Most of the existing motion detection algorithms do
not adequately take into account the extreme low il-
lumination situation. This paper proposes a motion
detection algorithm based on dictionary learning on
video images captured under low light. The experi-
ments show that compared to the mixture of Gaussian
model and the ViBe method, the proposed method
achieves a better detection results even in the case
that human eyes are difficult to distinguish. When
a portion of the moving object is close to the back-
ground, it is difficult to detect this region which is the
inadequacy of this paper. In addition, the paper also
carries out small objects detection under low light ex-
periment. Smaller and faster motion detection in low
illumination can be considered as the future direction
of this work.
ACKNOWLEDGEMENTS
This research was partially supported by National
Science Foundation of China (NSFC) under project
No.61175006 and No.61175015.
REFERENCES
Aharon, M., Elad, M., and Bruckstein, A. (2006). K-svd: an
algorithm for designing overcomplete dictionaries for
sparse representation. Signal Processing, IEEE Trans-
actions on, 54(11):4311–4322.
Barnich, O. and Droogenbroeck, M. V. (2011). Vibe: A
universal background subtraction algorithm for video
sequences. Image Processing, IEEE Transactions on,
20(6):1709–1724.
Chen, S. S., Donoho, D. L., and Saunders, M. A. (1998).
Atomic decomposition by basis pursuit. scientific
computing, 20(1):33–61.
Efron, B., Hastie, T., Johnstone, I., and Tibshirani, R.
(2004). Least angle regression. The Annals of statis-
tics, 32(2):407–499.
Friedman, N. and Russell, S. (1997). Image segmentation
in video sequences: a probabilistic approach. In Pro-
ceedings of the Thirteenth Conference on Uncertainty
in Artificial Intelligence, pages :1232–1245.
Hui, K. C. and Siu, W. C. (2007). Extended analysis
of motion-compensated frame difference for block-
based motion prediction error. Image Processing,
IEEE Transactions on, 16(5):1232–1245.
Lee, H., Battle, A., Raina, R., and Ng, A. (2006). Efficient
sparse coding algorithms. In Advances in neural in-
formation processing systems, pages :801–808.
Mairal, J., Bach, F., and J. Ponce, G. S. (2010). Online
learning for matrix factorization and sparse coding.
Machine Learning Research, 11:19–60.
ALowIlluminationEnvironmentMotionDetectionMethodbasedonDictionaryLearning
153

Mittal, A., Monnet, A., and Paragios, N. (2009). Scene
modeling and change detection in dynamic scenes: a
subspace approach. Computer Vision and Image Un-
derstanding, 113(1):63–79.
Oliver, N. M., Rosario, B., and Pentland, A. P. (2000). A
bayesian computer vision system for modeling human
interactions. Pattern Analysis and Machine Intelli-
gence, IEEE Transactions on, 22(8):831–843.
Piccardi, M. (2004). Background subtraction techniques: a
review. In Systems, Man and Cybernetics, IEEE inter-
national conference on, pages :3099–3104.
Stauffer, C. and Grimson, W. E. L. (1999). Adaptive back-
ground mixture models for real-time tracking. In
Computer Vision and Pattern Recognition, IEEE con-
ference on, pages :246–252.
Wang, Z., Bovik, A. C., Sheikh, H. R., and Simoncelli, E. P.
(2004). Image quality assessment: From error visi-
bility to structural similarity. Image Processing, IEEE
Transactions on, 13(4):600–612.
Wright, J., Ganesh, A., and S. Rao, Y. M. (2009). Ro-
bust principal component analysis? In Proceedings
of the Conference on Neural Information Processing
Systems.
ICPRAM2014-InternationalConferenceonPatternRecognitionApplicationsandMethods
154
