
Surprising Recipe Extraction based on Rarity and Generality
of Ingredients
Kyosuke Ikejiri, Yuichi Sei, Hiroyuki Nakagawa, Yasuyuki Tahara and Akihiko Ohsuga
Graduate School of Information Systems, University of Electro-Communications, Chofu-city, Tokyo, Japan
Keywords: Data Mining, Recipe, Information Recommendation.
Abstract: Many surprising recipes that utilize different ingredients or cooking processes from normal recipes exist on
user-generated recipe sites. The easiest way to find surprising recipes is to use the search function of the recipe
sites. However, the titles of surprising recipes do not always include a keyword, such as “surprise”, or an
indication that a recipe is unusual in any way. Therefore, we cannot find surprising recipes very easily. In this
paper, we propose a method to extract surprising or unique recipes from those user-generated recipe sites. We
propose an RF-IIF (Recipe Frequency-Inverse Ingredient Frequency) based on TF-IDF (Term Frequency-
Inverse Ingredient Frequency). First, we calculate the surprising value of the ingredients by using RF-IIF.
Then, we calculate the surprising value of each recipe by summing the surprising values of the ingredients that
appear in a recipe. Finally, we extract recipes that have high surprising values as surprising recipes of the dish
category. In the evaluation experiment, the subjects requested an evaluation about each surprising recipe. As a
result, we showed that the extracted recipes were valid recipes and also had a surprising or unusual element.
Therefore, we showed the usefulness of the proposed method.
1 INTRODUCTION
Planning meals for every day of the week is very
hard. Recently, many user-generated recipe sites,
where anyone can freely post their recipes, have
appeared on the Internet. The number of recipes and
users on these user-generated recipe sites are
increasing every year. Visitors to the site can use the
search function on the recipe sites to find recipes for
their desired dishes. Thus, many people use user-
generated recipe sites when they are in the planning
stage of their dishes and meals.
On user-generated recipe sites, there are not only
normal recipes, but also surprising or unusual
recipes. A “surprising recipe” has different
ingredients or cooking processes from the normal or
traditional version of the recipe. When a person feels
tired of normal recipes, they are able to cook a wider
variety of dishes if they can browse surprising
recipes. The easiest way to find surprising recipes is
to use the search function of the recipe sites.
However, the titles of surprising recipes do not always
include the keyword “surprise”. Therefore, we cannot
find those unique recipes simply by using the search
function. Many surprising recipes are buried within
the long lists of “normal” recipes.
We propose using RF-IIF (Recipe Frequency-
Inverse Ingredient Frequency) based on TF-IDF to
calculate the “surprise” value of an ingredient in a
recipe. The surprise value of a recipe is calculated by
summing the surprising values of ingredients used in
the recipe.
The next section describes application scenarios,
while Sections 3, 4, and 5 discuss our proposed
method in detail and evaluate it. In Section 6 we
introduce related work and Section 7 discusses future
work and concludes the paper.
2 APPLICATION SCENARIOS
Suppose that a housewife who cooks every day
from her normal repertoire wants to make a different
version of a dish from her standard fare. In that
situation, we consider that her satisfaction level will
increase if she can browse surprising, new recipes on
user-generated recipe sites.
For example, suppose that she wants to eat ground
steak, but is tired of standard ground steak recipes.
However, she can find a surprising recipe for ground
steak, which uses cucumber sauce, for example, if
she uses our proposed method. As another example,
428
Ikejiri K., Sei Y., Nakagawa H., Tahara Y. and Ohsuga A..
Surprising Recipe Extraction based on Rarity and Generality of Ingredients.
DOI: 10.5220/0004817304280436
In Proceedings of the 6th International Conference on Agents and Artificial Intelligence (ICAART-2014), pages 428-436
ISBN: 978-989-758-015-4
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)
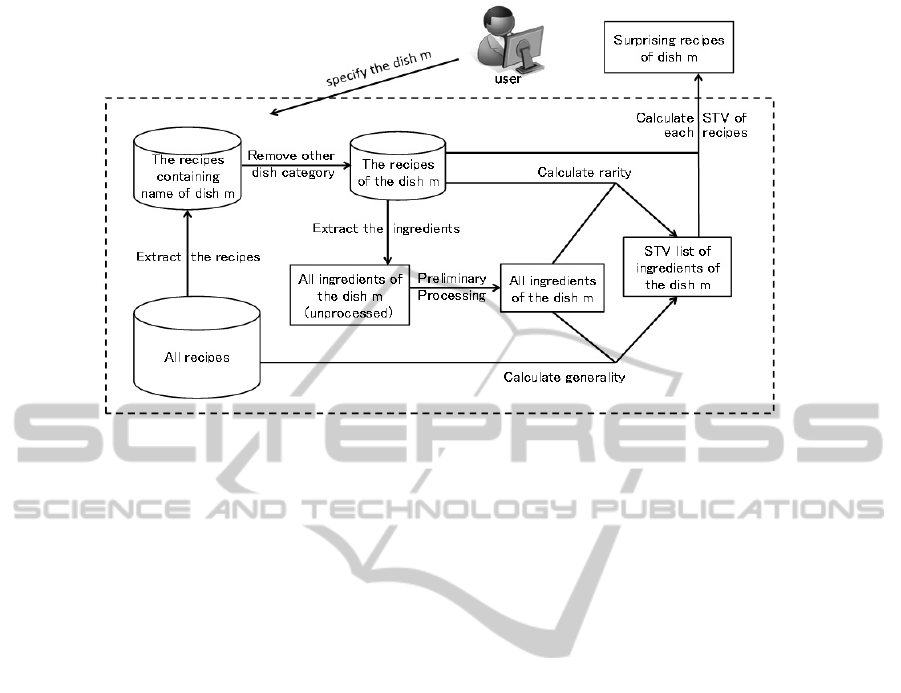
Figure 1: Overview of our proposed method.
let’s assume that she wants to find a surprising
recipe for pasta. In this case, she can find recipes,
such as one for cream pasta, which uses rice powder.
Yet again, she is able to create a surprising recipe if
she uses our proposed method, rather than a
traditional cookbook.
In our proposed method, the user can specify the
name of his or her favorite dish. Therefore, she can
browse a few different recipes than those she usually
makes. Thus, our proposed method is effective when
she wants to eat a slightly different dish, even if she
doesn’t want to try a completely new recipe.
3 APPROACH
In this paper, we calculate each surprising value of
an ingredient of the dish category specified by a user
to extract surprising recipes. We define surprising
recipes as those that use surprising ingredients.
Additionally, we define surprising ingredients as
ones that have a low frequency of appearance in
certain dish recipes within the specified category,
but have a high frequency of appearance in other
dish recipes.
First, we extract recipes from the dish category
(e.g., ground steak) that are specified by a user from
all recipes on the user-generated recipe site. Some of
the recipes in the user-generated recipe site are
categorized, but many of them are not categorized.
Therefore, we extract all recipes containing the
name of the dish category specified by a user in the
recipe name. However, recipes of other categories
may exist in the extracted recipes. Therefore, we
remove recipes from other categories from this set of
recipes and extract all the ingredients in these
recipes by the methods described in 3.1 and 3.2.
Then, we calculate surprising values of the
ingredients described in 3.3, and finally, we extract
surprising recipes by using the surprising value of
ingredients described in 3.4. We show an overview
of our proposed method in Figure 1.
3.1 Remove other Category Dishes
For example, we extract recipes containing “ground
steak” in the recipe title when we want to extract
ground steak recipes from the list of all recipes.
However, some extracted recipes may not belong to
the specified category. For example, the recipe
whose title is “ground steak bread” which should
belong to the “bread” category, can be extracted
when the user specify the category “ground steak”.
Therefore, we remove these recipes with the
following method. First, we make lists of categories
of dishes on the user-generated recipe site. However,
we can remove the category from the lists if the dish
name that we want to extract contains the category
name. For example, we want to extract recipes of
“ground steak”, but there is also “steak” on the list.
Then, we remove recipes from the extracted recipes
if the recipe title contains words on that list. As a
result, we will extract only the ground steak recipes.
3.2 Preliminary Processing
On a user-generated recipe site, users can write
down ingredients and the cooking processes of
SurprisingRecipeExtractionbasedonRarityandGeneralityofIngredients
429

specific recipes. Thus, the descriptions have words
that are not ingredients (e.g., comments for readers),
including spelling variations and extra words (e.g.,
“*”, “(1)”, “(2)”). First, we limit our search to only
ingredient names by removing symbols such as “*”
and “(1), (2), …”, as well as parentheses like
“(bigger)”. Then, we remove spelling variations of
ingredients. In this paper, we manually compile a list
of spelling variants of ingredients within two
categories of dishes in our evaluation (see section
4)
1
. We consider we can automate this process using
such techniques (Young, 2012), (Maarten, 2008) on
spelling variations. We plan to apply these
techniques in the future. Finally, we manually
remove words that are clearly not ingredients.
3.3 Calculating Surprising Theoretical
Value of Ingredients
Let m represent the dish category specified by a
user. Ingredients with a low frequency of appearance
in the dish category m have possibility for surprising
ingredients within the dish category m. However,
such ingredients may not be well known among
users. If the user does not know the ingredients at
all, she might not feel that they are surprising. In this
paper, we propose that users feel surprised when
they are recommended to use ingredients that are
well known, but do not normally come up as
ingredients for the specified dish category.
i
Moreover, if the ingredients are very rare, users
cannot buy them in normal supermarkets. Therefore,
among those ingredients that have a low frequency
of appearance in the specified dish category, the
ingredients with a high frequency of appearance in
all recipes are considered surprising recipes within
the dish category m.
The technique, called TF-IDF (Term Frequency-
Inverse Document Frequency) is used to obtain the
characteristic word in a certain document. TF is the
frequency of appearance of words in the document.
IDF is the inverse frequency of appearance of words
in the document set. TF-IDF, which represents the
weight of a certain word, is calculated by
multiplying the TF and the IDF. In other words, the
weight of the word that appears frequently in a
certain document but does not appear in other
documents is high. Thus, it is possible to obtain the
characteristic words of a certain document. Many
people utilize a method based on TF-IDF in fields
1
We also applied the list to the third category. As a result, we
were able to remove the spelling variants of ingredients without
problem.
that involve information retrieval (Jiaul, 2013),
(Luis, 2012), (Senthil, 2012).
In this paper, we define surprising ingredients of
a certain dish category as “the ingredient that have a
low frequency of appearance in the specified
category, but a high frequency of appearance in
other categories”. This is similar to the idea of TF-
IDF. In order to extract surprising ingredients, we
propose RF-IIF (Recipe Frequency-Inverse
Ingredient Frequency), which is based on TF-IDF, to
calculate the surprising value of each ingredient. We
call the resultant value that is calculated based on
RF-IIF as the surprising theoretical value (STV).
RF-IIF
i,m;p
(Equation (1)) represents the
surprising value of ingredient i among the dish
category m, specified by a user, with the parameter
p. RF-IIF
i,m;p
is calculated from RF
i
(Equation (2))
and IIF
i,m
. RF
i
represents the generality of the
ingredient i, and IIF
i,m
(Equation (3)) represents the
rarity of the ingredient i within the dish category m.
R
all
is the number of all recipes, R
i
is the number of
recipes including the ingredient i within the list of all
recipes, R
m
is the number of recipes in the dish
category m, R
i,m
is the number of recipes that
include the ingredient i within the dish category m.
The parameter p is used for adjusting the weight of
the rarity and generality of ingredients. We can
extract ingredients with higher rarity from the dish
category m by increasing p.
p
miipmi
IIFRFIIFRF
,;,
-
(1)
all
i
i
R
R
RF
(2)
mi
m
mi
R
R
IIF
,
,
log
(3)
3.4 Calculating Surprising Theoretical
Value of Recipes
On most user-generated recipes sites, recipes usually
consist of five elements: title, completion image,
ingredients list, cooking process, and a comment by
the poster of the recipe. We think that most posters
will emphasize the inclusion of an ingredient when
they use it as a surprising ingredient. In this case,
they are likely to write the ingredient name on the
comment column. We morphologically analyze the
comments connected to the recipes of the dish
category m. If an ingredient name occurs in the
comment section of the recipe, then we add its
surprising value to the STV of the recipe. In this
way, we can calculate the STV of recipes.
ICAART2014-InternationalConferenceonAgentsandArtificialIntelligence
430

Specifically, we define E as a set of elements that
are used to calculate STV of the recipe and we
define I
e
as a multi-set of ingredients within element
E. We define S
r,m;p
as the STV of recipe r in dish
category m when the weight parameter is p. S
r,m;p
is
calculated by
EeIi
pmipmr
e
IIFRFS
;,;,
-
(4)
4 EVALUATIONS
4.1 Abstract of Evaluations
We evaluated the surprising recipes that were
recommended by our proposed method. Our results
demonstrate the effectiveness of our proposed
method.
We extracted surprising recipes from the dish
categories of “ground steak”, “pasta” and “gratin”
from a user-generated recipe site with our proposed
method. The weight parameter p was set to 5
because we had obtained a good result beforehand.
Then, we extracted 10 recipes with the top 10 STVs
as surprising recipes from each dish category.
In order to evaluate the validity of the extracted
surprising recipes, we conducted a questionnaire
survey. We presented the full text of the surprising
recipe in the questionnaire. The subjects were asked
to evaluate the text using a five-point Likert scale in
terms of the surprising value and proper value of
each surprising recipe. The surprising value
represents whether or not the recipe is surprising or
unusual from the subject’s perspective. The proper
value represents whether or not the recipe tastes
delicious to the subject. Furthermore, we asked the
subjects about their sex, age, and the usefulness of
the proposed method using a five-point Likert scale.
Table 1 represents the details of the questionnaire
regarding surprising value, proper value, and the
usefulness of the proposed method.
We divided the subject into two groups; one is a
group of specialists and the other is a group of non-
specialists. Specialists are those who have the
qualification of a chef or a dietitian. Non-specialists
could include anyone else. We collected the answers
of three specialists and 10 non-specialists about the
ground steak, answers from three specialists and 13
non-specialists about the pasta, and responses from
five specialists and 15 non-specialists regarding the
gratin. The sex ratio of male to female was 6:4 and
90 percent of the subjects were in their twenties.
Table 1: Details of the questionnaire about surprising
value, proper value, and the usefulness of the proposed
method.
4.2 Dataset
It is possible to extract surprising recipes using our
proposed method from Food.com, Allrecipes.com
and other similar sites, but in this paper, we used
data from COOKPAD (COOKPAD), which has the
highest number of Japanese users and recipes in
terms of user-generated recipe sites. We collected
data from 1,492,366 recipes and 12,826,094
ingredients from COOKPAD. We conducted
experiments on recipes for ground steak, pasta, and
gratin because in most recipes for ground steak and
gratin, relatively standard ingredients are typically
used, whereas in recipes for pasta, a wide range of
variation in seasoning and ingredients exists. All of
the researched dishes are very popular in Japan.
We extracted 12,327 recipes and 161,307
ingredients which contained the keyword “ground
steak” in a recipe title, 37,426 recipes and 371,797
ingredients that contained the keyword “pasta” in a
recipe title, and 14,056 recipes and 140,782
ingredients that contained the keyword “gratin” in a
recipe title. Next, we removed recipes that belonged
to other categories using the technique described in
3.1. After that, we extracted 11,645 recipes and
156,852 ingredients for ground steak, 35,593 recipes
and 367,837 ingredients about pasta, and 12,240
recipes and 122,995 ingredients related to gratin.
Then, we removed spelling variants and extra words
of ingredients using the technique described in 3.2.
4.3 Results
Table 3 represents the top 20 ingredients ranked by
surprising values that were obtained through our
proposed method. Cucumber and sweet potato are
found in the ground steak list, banana and konnyaku
for the pasta, and chocolate or kelp for the gratin.
These ingredients, which have high STVs, are not
thought to be traditionally used for making those
dishes. Table 4 represents the extracted surprising
surprising value proper value
usefulness of the
proposed method
5 very surprised
seems very
delicious
very useful
4 surprised seems delicious useful
3 neutral neutral neutral
2 unsurprised
seems
unappetizing
unuseful
1 very unsurprised
seems very
unappetizing
very unuseful
SurprisingRecipeExtractionbasedonRarityandGeneralityofIngredients
431

Table 3: Example about STV of ingredients.
recipes calculated by the STV of their ingredients.
We analyzed the results of the questionnaire. Table 5
represents the average of surprising measure value
(ASMV) and average of proper measure value
(APMV) about each dish. SMV of the recipe
represents the percentage of the persons who
selected “very surprised” or “surprised” from a five-
point Likert scale about the recipe. ASMV is
average of SMV of all recommended recipes (10
recipes). The same may be said of APMV.
ASMVs of non-specialists are higher than
ASMVs of specialists. That is because specialists
have more knowledge of the ingredients and dishes
than non-specialists and specialists are aware of
various cooking methods that use non-traditional or
surprising ingredients. Moreover, we can say that the
extracted recipes are useful because APMVs are 50
percent or more, and the maximum of APMV is
nearly 80 percent.
Figure 2 represents graphs of ASMVs of top x
recipes ranked by STVs. For example, Figure 2
represents ASMV of the top 5 recipes ranked by
STVs when x=5. From Figure 2, we know that SMV
tends to decrease with a decreasing STV. The graph
about the gratin is slightly different from the others,
but it shows the same result when x=4 or more.
Therefore, we can say that STV roughly correlates
with the SMV of the actual recipe.
Table 6 represents the percentage of the people
who selected “very useful” or “useful” for the
usefulness of the recommended recipes. More than
60 percent of subjects think that the recommended
recipes are useful, except for ground steak. Thus, we
can say that there would be a demand for our
proposed method of finding and extracting
surprising recipes from user-generated recipe sites.
5 DISCUSSION
First, we will discuss Table 5. Because specialists
have more knowledge of the various ingredients and
dishes than a non-specialist, we assumed that the
specialists would consider many recipes “not
surprising”. Thus, we suggest that we can extract
recipes that are well known for specialists but are
relatively unknown to non-specialists. Moreover, we
know from Table 5 that the evaluation results of
pasta are the lowest of the three. There are standard
ingredients for gratin, and recipes of gratin are
almost all similar to each other. The same is true for
ground steak. In contrast, there are various recipes
for pasta because there are many kinds of pasta
sauces and various uses of pasta itself. For this
reason, there is the possibility that many people
would not feel surprised at certain recipes, even if
she is recommended a recipe that she had never seen
before. Therefore, we think that the evaluation
rank ingredient name STV ingredient name STV ingredient name STV
1 bread flour 516 baking powder 1662 dry yeast 1711
2 baking powder 410 pancake mix 1406 cocoa 989
3 cucumber 247 vanilla 1144 baking powder 955
4 chicken leg 235 dry yeast 770 pancake mix 756
5 salt-free butter 212 banana 768 vinegar 603
6 fried tofu 209 cocoa 674 gelatin 583
7 fat-free milk 190 rice 437 cucumber 528
8 pasta 189 strawberry 336 chili oil 520
9 ham 169 chocolate 298 powdered gelatin 486
10 rice 143 coating of egg roll 293 kelp 484
11 fried oil 138 rice flour 253 sesame 369
12 sweet potapo 132 brown sugar lump 239 chocolate 355
13 apple 115 egg white 214 ginger 331
14 sausage 114 tempura flour 207 bean vermicelli 294
15 dried bonito 110 konnyaku 194 chocolate bar 293
16 cake flour 108 bread 191 chinese chive 285
17 chili bean sauce 108 scinnamon 191 pickled plum 268
18 plain yogurt 103 shortening 182 lettuce 267
19 seasoned cod roe 101 green powder 167 bread flour 257
20 cream cheese 99 dough 158 whole wheat flour 242
ground steak pasta gratin
ICAART2014-InternationalConferenceonAgentsandArtificialIntelligence
432

Table 4: Titles of extracted surprising recipes.
Table 5: The result of the questionnaire about the ASMV and APMV.
Table 6: The results of the questionnaire about the
usefulness of the proposed method.
resultof pasta is the lowest of the three. We suggest
that our proposed method is more effective to use for
dish categories that are commonly composed of
standard recipes.
In addition, as represented in Table 6, more than
60 percent of the subjects selected “very useful” or
“useful” for the recommended recipes, and more
than half of subjects answered that the proposed
method is useful. The ratio of answering “very
useful” or “useful” about recommended recipes of
ground steak is the lowest of the three, although the
ASMV of ground steak is higher than that of pasta.
This represents that usefulness is not dependent on
the ASMV of a recipe. As mentioned above, we
think that there are many restaurants that prepare
unusual ground steak, but there are fewer restaurants
that offer unusual pasta and gratin. Thus, we think
that the impression of a recipe being surprising for
ground steak is less than potentially surprising
recipes for pasta and gratin. We consider that if
surprising recipes of pasta and gratin exist, many
people would want to know them. For this reason,
we think that the usefulness of ground steak is the
lowest of the three.
Our proposed method extracts surprising recipes
by specifying the name of the dish category.
Therefore, we cannot use our proposed method
directly in a situation where an individual wants to
know a recipe that uses all the ingredients in the
refrigerator. Therefore, we think that the usefulness
may improve even further by proposing a method
that can extract a surprising recipe by specifying
names of ingredients, rather than by the name of the
dish category.
6 RELATED WORK
A great deal of research about the recipe of the dish
exists. The user has the taste of various ingredients,
so the user may not be satisfied if they are
recommended the same recipe. Then, a recipe
recommendation system that considers the taste of
rank ground steak pasta gratin
1
Good in summer. Ground steak of
yam and cucumber
Simple. Tropical curry soup pasta Ginger cream gratin of vegetables
2
Good in summer! Grated cucumber
ground steak
Pasta sauce. Rice gratin Vinegar potato gratin
3
A bite-size tofu ground steak. Chock
taste
Simple. Pasta dipped in rice flour gratin
of soft-boiled egg
Salt kelp yogurt! Healthy gratin of
fish
4 My favorite. Natto ground steak Isoflavone. Rice pasta
One material. Gratin of salt kelp and
radish
5
Magic powder!? Ground steak plump
anyone
Simple cream pasta with rice flour Egg gratin of spinach and kelp
6
Ground steak refreshing in
vegetables
To diet! Increased bulk pasta ultimate
Refreshing healthy gratin of chinese
cabbage and penne
7
Simple shotening of time lunch.
Cheese ground steak rice
Japanese-style rice flour pasta of
seasoned cod roe and maitake mashroom
Side dish gratin of avocado and salt
kelp
8
Ground steak. Japanese-style apple
sauce
Creamy tomato pasta Gratin of avocado and soybean curd
9 Soy pulp ground steak
Rice flour. Cream pasta of bok choy and
bacon
Texture of seaweed is a decisive
factor. Excellent gratin
10 Soybean plenty ground steak Scallop. Young sardines. Garlic pasta
Super easy! Potato gratin to make
with HM
ASMV APMV ASMV APMV ASMV APMV
non-specialist 0.62 0.62 0.55 0.78 0.81 0.75
specialist 0.23 0.67 0.17 0.57 0.60 0.74
ground steak pasta gratin
ground steak pasta gratin
non-specialist 0.70 0.85 0.87
specialist 0.33 0.67 0.80
SurprisingRecipeExtractionbasedonRarityandGeneralityofIngredients
433
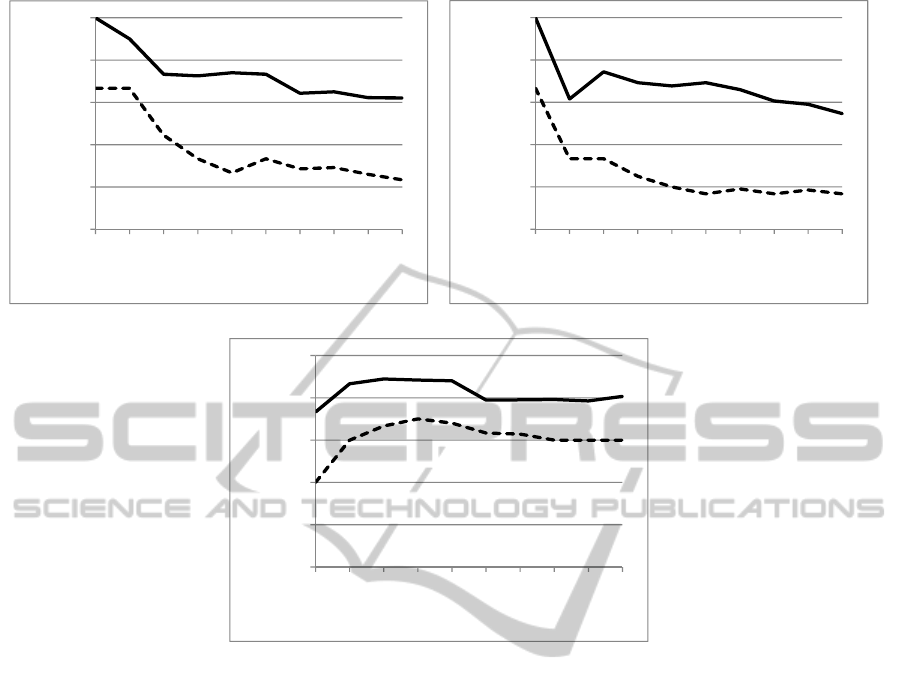
(a) Ground steak (b) Pasta
(c) Gratin
Figure 2: ASMVs of top x recipes ranked by STVs.
an individual exists. Ueda et al. (Ueda, 2008)
calculated the score of each ingredient by using the
technique based on TF-IDF from the cooking history
of a user. They then calculated the score of the
recipe from the score of its ingredients. The high
score recipe was recommended as a suitable recipe
for a specific user. Moreover, Ueda et al. (Ueda,
2011) estimated the score of likes and dislikes about
various ingredients from the browsing history and
cooking history of a user. Then, they calculated the
score of the recipe from the score of its ingredients.
Furthermore, they set up a variable of time, so
recommendations for cooking similar recipes would
not happen every day. Moreover, Maruyama et al.
(Maruyama, 2012) recognized ingredients, through
image processing techniques, in images that site
users were taking on their mobile devices. The
system could then recommend a suitable recipe that
used the recognized ingredients.
These recipe recommendation systems that are
being considered do exist. Yajima et al. (Yajima,
2009) calculated the cooking difficulty of a recipe
from its ingredients, as well as the cooking processes
involved in the recipe by inputting ingredients,
seasoning, and personal taste of a user. Additionally,
a suitable recipe for the situation could be
recommended by inputting the schedule of a user.
Moreover, Akazawa et al. (Akazawa, 2012)
recommended recipes that could utilize the
ingredients in the refrigerator of a user by inputting
the quantity of the ingredients and their “best
before” date that were found in the user’s
refrigerator. They also calculated the leftover
quantity of the ingredients that were purchased,
which would remain after the necessary amounts of
ingredients were used for the recipe. In this way, the
user does not need to input all of the information the
next time.
A recommendation system that offers dietary
therapy support also exists (Kitamura,
2009)(Tagawa, 2013)(Youri, 2011)(Jill, 2010).
Tagawa et al. calculated the nutritional values of
recipes by making Linked Data from information
about the recipe and the Japanese standard
ingredient composition table. They obtained the
results of the nutrition calculation of the recipe by
0.0
0.2
0.4
0.6
0.8
1.0
14710
ASMV
ranktopx
non‐specialist
specialist
0.0
0.2
0.4
0.6
0.8
1.0
14710
ASMV
ranktopx
non‐specialist
specialist
0.0
0.2
0.4
0.6
0.8
1.0
14710
ASMV
ranktopx
non‐specialist
specialist
ICAART2014-InternationalConferenceonAgentsandArtificialIntelligence
434

comparing the name of the recipe to the same dish
name on the menu of the restaurant, then estimating
the nutritional facts about the menu of the restaurant.
In addition, the system distinguishes whether or not
a menu is a suitable menu in terms of nutritional
content by registering age, weight, and amount of
exercise of a user into the system. Moreover, Youri
et al. proposed the recommendation system for
healthy recipes. The system discriminates important
feature of the original recipe from its text, and
creates the feature vector, then calculates the
similarities between recipes. If the similar recipe has
a high health index, then the original recipe is
replaced by it.
Research about alternative ingredients in recipes
also exists. Karasawa et al. (Karasawa, 2004)
calculated the feature score of ingredients and the
cooking action of each recipe group by classifying
the recipes and using TF-IDF. They regarded the
ingredients that had a low feature score as general
ingredients. The system extracts the ingredients that
are normal and have a frequency of appearance in a
recipe group as ingredients that could substitute.
Moreover, Shidochi et al. (Shidochi, 2009) proposed
a system that extracts the ingredients and the
cooking action from each recipe text, and they
obtained the characteristic cooking action of each
ingredient by using TF-IDF. Furthermore, the
system creates the vector of the cooking action of
the ingredients, along with the characteristic cooking
action of the ingredients in the same dish category.
Then, the system extracts the ingredients that have
the vector of the cooking action with high cosine
similarity as the ingredients that can be substituted.
Moreover, Chun et al. (Chun, 2012) built a network
of ingredient complements and a network of
ingredient substitutes. They extract alternative
ingredients and remove ingredients used as options
by using both of their networks.
Fang et al. (Fang, 2012) proposed a system that
generates a menu (set of multiple recipes) for dinner,
as an example. The system calculates the similarity
between recipes from their ingredients. Moreover,
they obtained the co-occurrence relation of the
recipes from the site so a menu can be
recommended. Finally, the system generates a menu
that consists of a group of suitable recipes by
inputting the ingredients obtained by a user
In the field of information recommendation in
recent years, a system that recommends information
suited to the taste of the user has come under some
criticism, mainly because it has been argued that it
may not actually improve the satisfaction level of
the users. Instead, the element of surprise and
novelty about the information has attracted more
attention. (Murakami, 2008)(Yuan, 2012). However,
these systems recommend the information which is
of little interest to the user and never browsed by
using the user information. Therefore, it cannot be
used for our proposed method because their purpose
is different from our purpose.
As this section has made very clear, many
research studies about cooking recipes and
recommending culinary information exist. However,
there have not been any studies that focused on the
element of surprise about a recipe and its ingredient,
so the purpose and the techniques of the past studies
are different from our proposed method.
7 CONCLUSIONS AND FUTURE
WORK
In this paper, we proposed a method that extracts
surprising recipes from a dish category specified by
a user on user-generated recipe sites by using the
frequency of appearance of surprising ingredients.
We calculated the STV of each ingredient based
on RF-IIF, which is calculated from the rarity score
and the generality score of the ingredient. The rarity
score is the frequency of appearance of the
ingredient in the dish category, while the generality
score is the frequency of appearance of the
ingredient in all of the site’s recipes. Then, we
calculated the STV of each recipe based on the STV
of its ingredients, and extracted 10 surprising recipes
that had the top 10 highest STVs in three dish
categories ground steak, pasta, and gratin. In the
evaluation experiment, the subjects were requested
to make an evaluation about the surprising value and
the proper value of each surprising recipe. As a
result, we showed that 80 percent of the subjects
answered “seems very delicious” or “seems
delicious” about the extracted recipes, and more than
half considered the recipes to be surprising.
Moreover, we showed that our proposed method was
a valid method by showing that the STV, which is a
theoretical value of surprise, has a correlation with
SMV, which is the surprise value obtained from the
results of the questionnaires.
In any future work, we will improve the accuracy
of the surprising recipe extraction. In addition, we
will eliminate the redundancy of extracted recipes by
first calculating the similarity between recipes.
Furthermore, we will consider improvements to the
system that can extract surprising recipes by
specifying the ingredient names instead of
specifying a dish category name.
SurprisingRecipeExtractionbasedonRarityandGeneralityofIngredients
435

ACKNOWLEDGEMENTS
This research was subsidized by JSPS 24300005,
23500039, 25730038.
The authors would like to express their deepest
appreciation to the COOKPAD Inc., who provided
the recipe data of COOKPAD for us.
The authors would also like to express their
deepest appreciation to the entire staff of Professor
Honiden’s laboratory at the University of Tokyo and
Professor Fukazawa’s lab at Waseda University,
both of whom provided helpful comments and
suggestions.
REFERENCES
Young-J. C., 2012. Finding Food Entity Relationships
using User-generated Data in Recipe Service. In CIKM
2012. Proceedings of the 21st ACM international
conference on Information and knowledge
management.
Maarten C., Arjen P. de V., Marcel J. T. R., 2008.
Detecting Synonyms in Social Tagging Systems to
Improve Content Retrieval. In SIGIR 2008.
Proceedings of the 31st annual international ACM
SIGIR conference on Research and development in
information retrieval.
Jiaul H. P., 2013. A Novel TF-IDF Weighting Scheme for
Effective Ranking. In SIGIR 2013. Proceedings of the
36th international ACM SIGIR conference on
Research and development in information retrieval.
Luis F. S. T., Gabriel P. L., Rita A. R., 2012. An
Extensive Comparison of Metrics for Automatic
Extraction of Key Terms. In ICAART 2012.
Proceedings of the 4th International Conference on
Agents and Artificial Intelligence.
Senthil M., Rose C., Vibha S. S., Avinava D., 2012.
AUSUM: Approach for Unsupervised Bug Report
SUMmarization. In FSE 2012. Proceedings of the
ACM SIGSOFT 20th International Symposium on the
Foundations of Software Engineering.
“COOKPAD”. COOKPAD Inc.. http://cookpad.com.
Ueda M., Ishihara K., Hirano Y., Kajita S., Mase K., 2008.
Recipe Recommendation Method Based on Personal
Use History of Foodstuff to Reflect Personal
Preference. In Database Society of Japan Letters Vol.6
No.4, pp.29-32. (in Japanese).
Ueda M., Takahata M., Nakajima S., 2011. User’s Food
Preference Extraction for Personalized Cooking
Recipe Recommendation. In SPIM 2011. 2nd
Workshop on Semantic Personalized Information
Management: Retrieval and Recommendation.
Maruyama T., Kawano Y., Yanai K., 2012. Real-time
Mobile Recipe Recommendation System Using Food
Ingredient Recognition. In IMMPD 2012. Proceeding
of the 2nd ACM international workshop on Interactive
multimedia on mobile and portable devices.
Yajima A., Kobayashi I., 2009. “Easy” Cooking Recipe
Recommendation Considering User’s Conditions. In
WI-IAT 2009. Proceedings of The 2009
IEEE/WIC/ACM International Joint Conference on
Web Intelligence and Intelligent Agent Technology-
Volume03.
Akazawa Y., Miyamori H., 2012. Proposal of a Search
System for Cooking Recipes Considering Ingredients
in Refrigerators. In DEIM 2012. The 4th Forum on
Data Engineering and Information Management. (in
Japanese).
Kitamura K., Yamasaki T., Aizawa K., 2009. FoodLog:
capture, analysis and retrieval of personal food images
via web. In CEA 2009. Proceedings of the ACM
multimedia 2009 workshop on Multimedia for cooking
and eating activities.
Tagawa Y., Tanaka A., Minami Y., Namikawa D.,
Shimomura M., Ymaguchi T., 2013. Supporting Diet
Therapy Based on Japanese Linked Data. In JSAI
2013. The 27th Annual Conference of the Japanese
Society for Artificial Intelligence. (in Japanese).
Youri van P., Gijs G., Paul K., 2011. Deriving a Recipe
Similarity Measure for Recommending Healthful
Meals. In IUI 2011. Proceedings of the 16th
international conference on Intelligent user interfaces.
Jill F., Shlomo B., 2010. Intelligent Food Planning:
Personalized Recipe Recommendation. In IUI 2010.
Proceedings of the 15th international conference on
Intelligent user interfaces.
Karasawa T., Hamada R., Ide I., Sakai S., Tanaka H.,
2004. Extraction of Knowledge about the Material and
Recipe from Cooking Teaching Materials Text. In
IPSJ 2004. The 66th Annual Conference of the
Information Processing Society of Japan. (in
Japanese).
Shidochi Y., Takahashi T., Ide I., Murase H., 2009.
Finding Replaceable Materials in Cooking Recipe
Texts Considering Characteristic Cooking Actions. In
CEA 2009. Proceedings of the ACM multimedia 2009
workshop on Multimedia for cooking and eating
activities.
Chun-Y. T., Yu-R. L., Lada A. A., 2012. Recipe
recommendation using ingredient networks. In WebSci
2012. Proceedings of the 3rd Annual ACM Web
Science Conference.
Fang-Fei K., Cheng-Te L., Man-Kwan S., Suh-Yin L.,
2012. Intelligent menu planning: recommending set of
recipes by ingredients. CEA 2012. Proceedings of the
ACM multimedia 2012 workshop on Multimedia for
cooking and eating activities.
Murakami T., Mori K., Orihara R., 2008. Metrics for
Evaluating the Serendipity of Recommendation Lists.
In JSAI 2007. Proceedings of the 2007 conference on
New frontiers in artificial intelligence.
Yuan C. Z., Diarmuid O S., Danele Q., Tamas J., 2012.
Auralist: Intoducing Serendipity into Music
Recommendation. In WSDM 2012. Proceedings of the
fifth ACM international conference on Web search and
data mining.
ICAART2014-InternationalConferenceonAgentsandArtificialIntelligence
436
