
Influence of Norms on Decision Making in Trusted Desktop Grid Systems
Making Norms Explicit
Jan Kantert, Lukas Klejnowski, Yvonne Bernard and Christian M
¨
uller-Schloer
Institute of Systems Engineering, Wilhelm Gottfried Leibniz University of Hanover, Hanover, Germany
Keywords:
Multi-Agent-Systems, Norms, Decision Making, Desktop-grid System, Trust.
Abstract:
In a Trusted Desktop Grid agents cooperate to improve the speedup of their calculations. Since it is an open
system, the behaviour of agents can not be foreseen. In previous work we have introduced a trust metric to cope
with this information uncertainty. Agents rate each other and exclude undesired behaving agents. Previous
implementations of agents used hardcoded logic for those ratings. In this paper, we propose an approach to
convert implicit rules to explicit norms. This allows learning agents to understand the expected behavior and
helps us to provide an improved reaction to attacks by changing norms.
1 INTRODUCTION
In Organic Computing (M
¨
uller-Schloer and Schmeck,
2011) we develop new methods to cope with growing
complexity of today’s computing systems. Since em-
bedded and mobile devices are getting cheaper and
more powerful, new software design paradigms are
required. With systems consisting of multiple dis-
tributed devices we need to take care of efficiency and
robustness, as well as maintaining openness and au-
tonomy. We model devices as agents in a multi-agent
system. Since we are in an open system we cannot
assume a well-defined behaviour from an agent. To
cope with this information uncertainty we introduced
a trust metric (Bernard et al., 2010). Agents will co-
operate based on trust and can exclude misbehaving
agents to ensure high performance.
Our scenario is an open Trusted Desktop Grid
(TDG), where agents have parallelisable jobs and
need to cooperate to achieve better performance.
Agents need to decide for whom they want to work
and whom they want to give their work to. Since
TDG is an open system, malicious agents like freerid-
ers, which will not work for other agents, or egoists,
which will return fake results, may also join the sys-
tems. To improve the overall performance those at-
tackers need to get isolated, which can be done by
using trust. Agents will give each other ratings based
on their actions and will use the corresponding trust
value to make their decisions.
In this paper, we convert our internal agent rules,
which lead to trust ratings, to explicit norms. This al-
lows other learning agents to understand the expected
behaviour in our system. Additionally, it allows us to
change norms to adapt to a changed environment. In
Chapter 2 we present our motivation to use explicit
norms. Afterwards we describe more details about
our application scenario in Chapter 3. In Chapter 4,
we picture the challenges of decision-making in TDG.
After understanding the current behaviour, we pro-
pose new explicit norms in Chapter 5. We discuss
related and future work in Chapter 6 and finish with a
conclusion in Chapter 7.
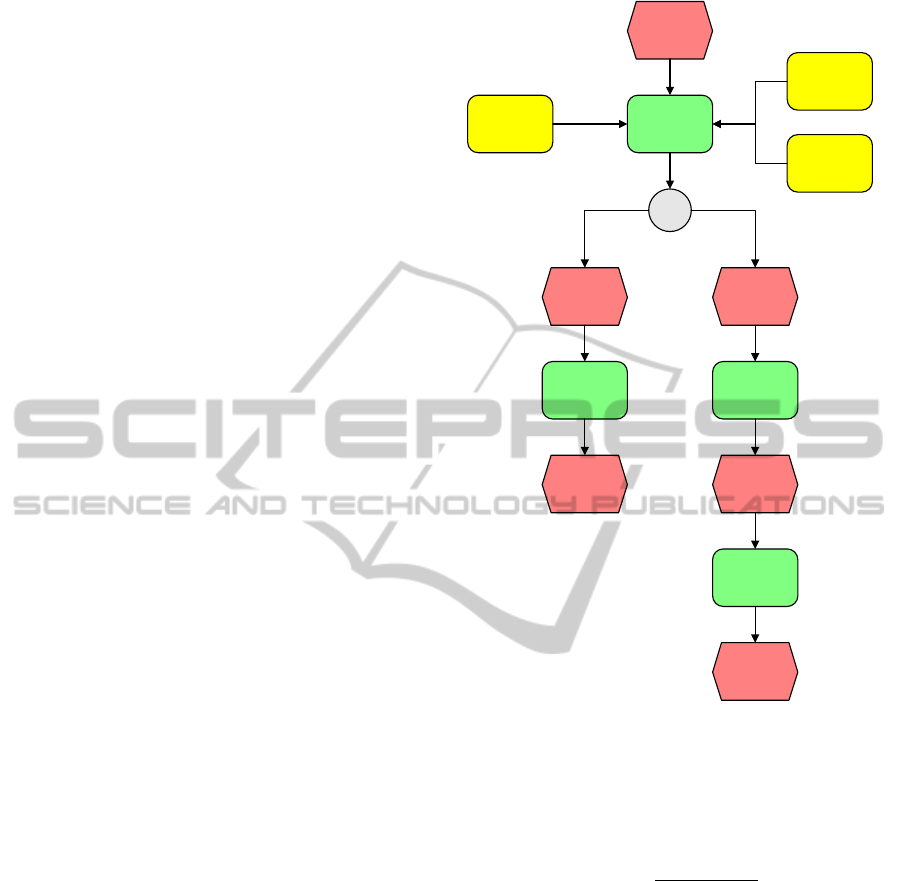
Reward Estimation
Based on trust
value
Worker Submitter
Learn
Reward
Calculate
Reward
Trust value
Figure 1: Block diagram of the decision process with
worker and submitter.
2 MOTIVATION
In a distributed system with multiple agents it is hard
to find a perfect global solution using a central ob-
278
Kantert J., Klejnowski L., Bernard Y. and Müller-Schloer C..
Influence of Norms on Decision Making in Trusted Desktop Grid Systems - Making Norms Explicit.
DOI: 10.5220/0004918002780283
In Proceedings of the 6th International Conference on Agents and Artificial Intelligence (ICAART-2014), pages 278-283
ISBN: 978-989-758-016-1
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)
serving instance, because there are too many parame-
ters to optimise. By giving agents more autonomy we
want them to find better and more flexible solutions
for job distribution in a changing environment. But
since agents are selfish we need to enforce the system
goals. Giving them a set of norms allows them to un-
derstand the expected behaviour and act according to
it. The central instance will create and modify norms
to reach the global system goal. However, sometimes
agents may offend a norm to perform better and im-
prove the overall system performance.
Agents need to take decisions in a self-referential
fitness landscape (Cakar and M
¨
uller-Schloer, 2009).
Every action taken will influence decisions of other
agents, because it will influence trust relations and the
amount of work in the system. In our past implemen-
tations, decisions were made based on hard limits on
the trust value of other agents, and the outcome of
actions was known at design time. For example, af-
ter working for another agent the agent would get a
positive trust rating. In case of missing a deadline
or rejecting a work unit the agent would get a nega-
tive rating. This worked out very well in most situ-
ations. Unfortunately, in extreme situations like col-
lusion attacks or overload those static outcome of ac-
tions could lead to trust breakdowns and bad perfor-
mance (Castelfranchi and Falcone, 2010).
In our current agent implementation we have a
static decision mechanism which leads to positive
emergent behaviour of the system. However, our
Trusted Desktop Grid is an open system, which other
agents may join at any time and which does not have a
dependable definition of expected behaviour for other
agents. This leads to attacking agents being able to
exploit the system without breaking any implicit or
explicit rules (Bernard et al., 2012). To obtain a clear
understanding of the expected system behaviour we
want to formulate explicit norms from the implicit be-
haviour. We want to analyse the norms and improve
robustness by adjusting norms afterwards. This will
allow us to perform better detection and mitigation of
malicious behaviour and thus improved system per-
formance.
3 APPLICATION SCENARIO
Our application scenario is an open Trusted Desktop
Grid System. Agents generate a bag of tasks at evenly
distributed random times and need to compute these
tasks as fast as possible. They can cooperate with
other agents and try to maximise their speedup by
working for each other.
When computing the job on their own it will take
Job offer
received
Estimate
Reward
XOR
Reward of
rejecting
prevails
Reward of
accepting
prevails
Reputation
Environment
Norms
Reject job Accept job
Job has been
rejected
Job has been
accepted
Do job
Job is done
Figure 2: event driven process chain of the worker in
Trusted Desktop Grid.
an agent time
own
. When cooperating it will take only
time
distributed
, which should be smaller than time
own
.
The speedup can be calculated with those two times:
speedup =
time
own
time
distributed
(1)
New agents can join the system at any time. Exist-
ing agents can leave the system and will do so if they
are unable to achieve speedup greater than one. Ev-
ery agent needs to decide for which agent it wants to
work and to which agent it wants to give its work.
Since the TDG is an open system agents will try to
cheat to gain an advantage. It is unknown in advance
whether an agent will behave according to the rules.
To cope with this information uncertainty we intro-
duced a trust metric T ( f rom,to) which describes the
trust of agent A
x
in relation to agent A
y
:
x 6= y, −1 ≤ T (x, y) ≤ 1 (2)
The trust value is based on previous interactions be-
tween the agents and predicts how well an agent will
InfluenceofNormsonDecisionMakinginTrustedDesktopGridSystems-MakingNormsExplicit
279
behave according to the rules in the system. If an
agent A
x
does not have sufficient experiences with an-
other agent A
y
it will use the global reputation R
y
of
the agent to rate it:
R
y
=
n
∑
i=1
T (i, y)
n
(3)
Every agent has the primary goal to maximise the
speedup on calulating its jobs. This is the only rea-
son why it will participate in the system. To give all
agents the opportunity to gain a good speedup our sys-
tem has two goals:
• Maximise cooperation
• Ensure fairness
Since agents can only achieve a speedup when they
cooperate the first goal is parallel to the goal of all
agents. Cooperation is measured by the sum of all
returned work units in the system:
cooperation =
n
∑
i=1
n
∑
j=1
ReturnWork(A
i
, A
j
) (4)
The second goal is needed to prevent exploitation of
agents, which would make them leave the system. We
measure the fairness of an agent by the submit/work
ratio which should be about one. Afterwards we
aggregate the difference between ratio and 1 for all
agents and try to minimise this value.
f airness =
n
∑
i=1
1 −
submit
i
work
i
(5)
4 DECISION MAKING
Agents have a submitter and a worker component as
can be seen in Figure 1. The worker component needs
to decide whether it wants to work for another agent
and will gain reputation by accepting and complet-
ing jobs. The submitter component is responsible for
finding the best cooperation partners when a job is
available. In general, the submitter will be more suc-
cessful if the agent has a high reputation.
Every agent needs to make a decision for two
questions:
• For which agent do I want to work? (Submitter)
• Which agents will I give my work to? (Worker)
As seen in Figure 2, if an agent gets asked whether
it wants to work for another agent it needs to estimate
its own reward for rejecting or accepting the job. Re-
jecting a job will give the agent a negative trust rat-
ing of Penalty
re ject
. Accepting and returning a job
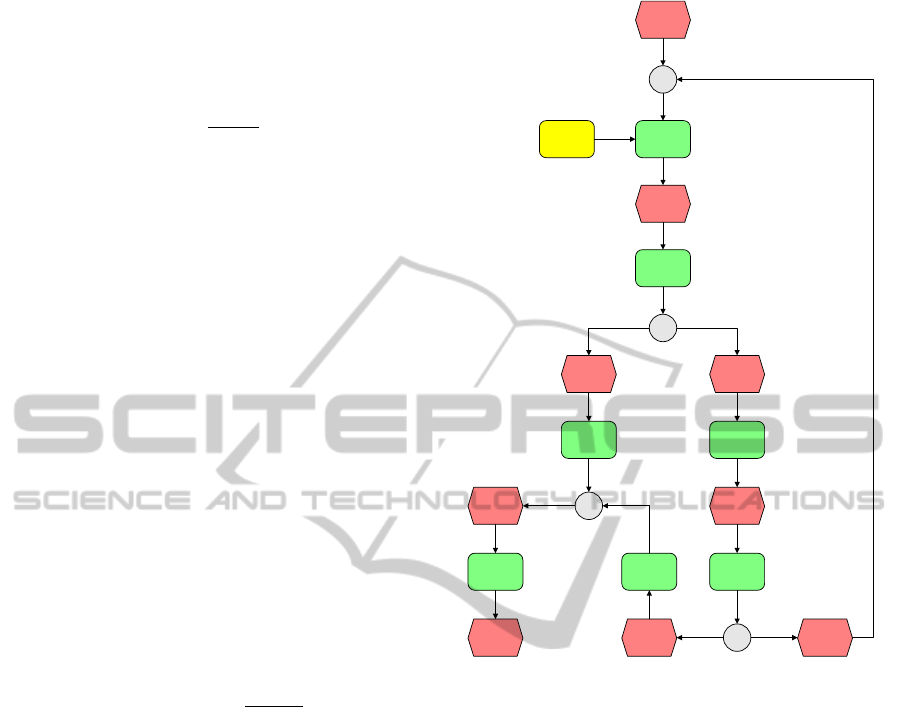
Job available
for distribution
Select workers
and replication
factor
Workers have
been selected
Send job to
worker
XOR
Worker
accepted job
Worker
rejected job
Check if all
workers have
been asked
Yes No
Do job on your
own
Wait for worker
Job is finished
XOR
XOR
XOR
Rate worker
Done
Rate worker
Worker has
been rated
Norms
Figure 3: event driven process chain of the submitter in
Trusted Desktop Grid.
will give it a positive rating of Incentive
workDone
. The
worker can also accept and later cancel the job, which
leads to a negative rating of Penalty
canceled
, which is
usually higher than the penalty for just rejecting the
job and therefore will not be a good option in most
cases.
In the past we had a fixed threshold table for the
acceptance of jobs. If one agent A
x
got a request to
work for another agent A
y
it would get the reputation
R
y
of the requesting agent. Based on it’s own repu-
tation R
x
it would do a lookup in the threshold table
and would only accept the job if R
y
is higher than the
threshold in the table. Agent A
x
will also reject the
job if its workqueue is full.
We made this more flexible by using a reward es-
timator in (Kantert et al., 2013), which calculates the
expected reward for a certain reputation. This allowed
an agent to estimate the reward for accepting or reject-
ing a job in advance. When evaluating the new deci-
sion making we found out that our previous agents
were not always choosing the optimal action to op-
timise their own reward, which should be their pri-
ICAART2014-InternationalConferenceonAgentsandArtificialIntelligence
280

Table 1: Implicit norms in the Trusted Desktop Grid.
Evaluator Action Context Sanction/Incentive
1 Worker Re jectJob(A
w
, A
s
) T (A
w
, A
s
) > 0 T (A
s
, A
w
) = T (A
s
, A
w
) − Penalty
re ject
T (A
w
, A
s
) ≤ 0 -
2 Worker ReturnJob(A
w
, A
s
) T (A
s
, A
w
) = T (A
s
, A
w
) + Incentive
workDone
3 Worker CancelJob(A
w
, A
s
) T (A
s
, A
w
) = T (A
s
, A
w
) − Penalty
canceled
4 Submitter GiveJobTo(A
s
, A
w
) T (A
s
, A
w
) ≥ T
SuitableWorker
Speedup
mary goal. Those agents did exclude agents with a
low reputation by not working for them, which is gen-
erally good for the overall system performance, but
the incentive to work for a potential malicous agent is
the same as the incentive to work for a well behaving
agent with high reputation.
The submitter of an agent will try to distribute jobs
to other agents to leverage parallel processing. As
seen in Figure 3 it will select a list of workers and
orders them by the time they promise to finish the job.
Consequently it asks them if they are willing to accept
the job. If no worker was found the agent will execute
the job on its own. After a job is done the speedup
gets calulated and the agent will know how well he
performed. We use this value to create statistics and
to improve the reward estimator.
In the current implementation we will only select
workers with a reputation higher than T
SuitableWorker
.
If this did not work the submitter will replicate the
job (not shown in Figure 3 for simplicity) and ask
multiple workers to execute the work, which will im-
prove the chance that at least one worker will finish
the work. Afterwards it will do the calulation on its
own. This behaviour is hardcoded and agents do not
replicate jobs if the reputation of the worker is high.
However there is no mechanism to prevent an exten-
sive use of replication and a learning agent would just
replicate every job to improve the reliablility.
With our previous agent implementation we had
a set of hardcoded rules, which lead to a good over-
all system performance. However when we made our
agents more autonomous and selfish it turned out that
our rating system and rules have some loop holes.
Since our TDG is an open system a targeted attacker
or learning agent could easily exploit the system to
perform better while deteriorating the overall system
performance.
We decided to look further into the implicitly ex-
pected behaviour of agents in our system. By using
hardcoded rules we prevent our agents from perform-
ing certain actions, but since there is no limitation
other implementations may abuse them. We want to
make the rules and expectations in the system more
explicit by using norms in the next chapter.
5 NORMS
A norm describes the expected behaviour of one agent
in a group agents. Depending on the context a certain
action will trigger a sanction or incentive. Because
there can no longer be a static decision mechanism
we introduced a learning reward estimator to find the
best suitable actions for a given environment (Kan-
tert et al., 2013). Since agents will always try to opti-
mise their own reward we need to influence the reward
given to an agent. Unfortunately we cannot directly
do this, because the reward is based on the speedup
reached while computing work units. However agents
depend on the collaboration of other agents to achieve
a high speedup, and other agents will base their deci-
sion to cooperate on the reputation of the agents. We
want to exploit this to influence the decision making
by norms and indirectly modify the reward an agent
gets from the system.
5.1 Representation
We describe a norm by a tuple:
Norm = hEvaluator, Action, (Policy
1
. . . Policy
n
)i
(6)
Policy = hContext, Sanctioni (7)
Norm = hEvaluator, Action,
(hContext, Sanctioni, hContext, Sanctioni. .. )i (8)
The Evaluator is either the worker or submitter part
of an agent. Both have different Actions they can per-
form:
• Worker
– AcceptJob(A
w
, A
s
) - Agent A
w
accepts a job
from agent A
s
– Re jectJob(A
w
, A
s
) - Agent A
w
rejects a job
from agent A
s
– ReturnJob(A
w
, A
s
) - A
w
returns the correct
calulation for job to A
s
– CancelJob(A
w
, A
s
) - A
w
cancels job of A
s
• Submitter
InfluenceofNormsonDecisionMakinginTrustedDesktopGridSystems-MakingNormsExplicit
281

Table 2: Proposed explicit norms for Trusted Desktop Grid.
Evaluator Action Context Sanction/Incentive
1 Worker Re jectJob(A
w
, A
s
) T (A
w
, A
s
) > 0 T (A
s
, A
w
) = T (A
s
, A
w
) − Penalty
re ject
T (A
w
, A
s
) ≤ 0 -
2 Worker ReturnJob(A
w
, A
s
) T (A
w
, A
s
) > 0 T (A
s
, A
w
) = T (A
s
, A
w
) + Incentive
workDone
T (A
w
, A
s
) ≤ 0 T (A
s
, A
w
) = T (A
s
, A
w
)
+Incentive
workDoneLowTrust
3 Worker CancelJob(A
w
, A
s
) T (A
s
, A
w
) = T (A
s
, A
w
) − Penalty
canceled
4 Submitter GiveJobTo(A
s
, A
w
) Speedup
ReplicationFactor ≥ 1 Speedup; T (A
w
, A
s
) = T (A
w
, A
s
) − Penalty
replication
– AskForDeadline(A
s
, A
w
) - A
s
asks worker A
w
for the deadline for a job
– GiveJobTo(A
s
, A
w
) - A
s
asks worker A
w
to do a
job
– CancelJob(A
s
, A
w
) - A
s
cancels a job A
w
is
working on
– ReplicateJob(copies) - Will copy a job multi-
ple times and use GiveJobTo() on them
A norm may have multiple Policies, which consist of
a Context and a Sanction, which can also be an incen-
tive. The Context contains one or multiple conditions
which must be true to trigger a certain Sanction. Since
all agents want to achieve a maximal speedup, it is not
possible to give a direct reward to an agent and we
can only increase or decrease the speedup indirectly
by varying the reputation of an agent. The Sanction
may also influence more indirect values, which can
influence the success of an agent:
• Incentive
– Reputation is increased
– Monetary incentives
• Sanction
– Reputation is decreased
– Loss of monetary incentives
– Agent gets excluded from Trusted Communi-
ties (Bernard et al., 2011)
5.2 Implicit Norms
In Table 1 we listed all implicit norms of our cur-
rent system. The column Evaluator contains the en-
tity, which performs the Action in the second column.
There are two actors: A
s
is the submitting agent and
A
w
is the working agent. The column Context con-
tains the conditions for a certain outcome in the col-
umn Sanction.
To summarise the implicit norms: An agent al-
ways has to accept and return every job if the request-
ing agent has a positive reputation. An agent should
give a job to another agent with at least a reputation of
T
SuitableWorker
or otherwise replicate it. Especially the
last part might be difficult: The agents cannot decide
to behave differently and accept a sanction. Those
are hard rules and we want to change them to give
agents more autonomy. When we create norms from
an observing instance, we only have a limited system
overview. Sometimes it may be better for an agent
and the system to violate a norm for improving the
overall performance.
5.3 Improved Norms for TDG
To improve norms in the system to enforce the same
behaviour as our hardcoded rules we need to solve the
following issues:
1. Isolation of not cooperating agents - There should
be a motivation for agents to exclude not cooper-
ating agents.
2. Replication should only be used when necesary -
There should be a penalty when using replication
to limit its usage.
To cope with the first challenge there should be no
incentive or a small sanction for working for agents
with a low reputation. The easiest solution would
be to remove the incentive for working for agents
with a low reputation. However, this would pre-
vent the recovery after a trust breakdown (Castel-
franchi and Falcone, 2010). If agents do not trust
each other, there will not be an incentive for an
agent to work for others than itself. A better solu-
tion would be to lower the incentive for working for
agents with low reputation. Therefore, we introduce a
new Incentive
workDoneLowTrust
with the constraint that
Incentive
workDoneLowTrust
< Incentive
workDone
. In Ta-
ble 2, Norm 1, we already allow agents to reject a job
from agents with a low reputation without any sanc-
tions. We extended Norm 2 to lower the incentive for
accepting jobs from agents with low reputation.
One way to solve the second challenge would be
to put a small trust sanction on the use of replication.
This would lower the reputation of the agent and make
it slightly harder for the agent to find cooperation part-
ners. If the agent only makes use of replication infre-
quently, this will not have a big impact on the overall
ICAART2014-InternationalConferenceonAgentsandArtificialIntelligence
282

reputation. It is still a challenge to enforce this norm
since detection of replication is not trivial in a dis-
tributed system. We changed Norm 4 in Table 2 to
impose a small penalty for agents replicating jobs.
6 RELATED AND FUTURE
WORK
This work is part of wider research in the area of
norms in multi-agent systems. However, our focus
is more on improving system performance by using
norms than researching the characteristics of norms
(Singh, 1999). We use the same widely acknowledged
conditional norm structure as described in (Balke
et al., 2013). Most of our norms can be characterised
as ”prescriptions” based on (von Wright, 1963), be-
cause they regulate actions. Our norms are gener-
ated by a central elected component representing all
agents which classifies them as a ”r-norm” according
to (Tuomela and Bonnevier-Tuomela, 1995).
Assuming we could detect extreme situations, we
want to improve the system behaviour by chang-
ing the decision-making during runtime using norms.
This would allow us to motivate agents to cooperate in
case of a trust breakdown (Castelfranchi and Falcone,
2010) by giving a larger incentive to do so. We could
also encorage agents to work with existing peers and
temporarily ignore newcomers by lowering the incen-
tive to work with newcomers. However, we do not
want to limit our agents too much to allow them to
keep their autonomy.
To improve fairness in the Trusted Desktop Grid,
it may be useful to have a monetary component in ad-
dition to the reputation for every agent (Huberman
and Clearwater, 1995). Agents would get a mone-
tary incentive for every finished job and would need
to pay other agents for the calculation of their jobs.
Trust would be used to prevent malicious behaviour
and allow better money exchange.
7 CONCLUSIONS
Making norms explicit helped us to understand the
needed behaviour for our system to perform well. It
allowed us to detect and to fix potential loopholes,
which could be exploited by attackers. Addition-
ally, it gives us the ability to change the expected be-
haviour at runtime to react to collusion attacks. We
plan to experiment with different incentives to adjust
the norms to fit the system goals.
REFERENCES
Balke, T., Pereira, C. d. C., Dignum, F., Lorini, E., Rotolo,
A., Vasconcelos, W., and Villata, S. (2013). Norms
in MAS: Definitions and Related Concepts. In Nor-
mative Multi-Agent Systems, volume 4 of Dagstuhl
Follow-Ups, pages 1–31. Schloss Dagstuhl–Leibniz-
Zentrum fuer Informatik.
Bernard, Y., Klejnowski, L., Bluhm, D., H
¨
ahner, J., and
M
¨
uller-Schloer, C. (2012). An Evolutionary Ap-
proach to Grid Computing Agents. In Italian Work-
shop on Artificial Life and Evolutionary Computation.
Bernard, Y., Klejnowski, L., Cakar, E., Hahner, J., and
Muller-Schloer, C. (2011). Efficiency and Robust-
ness Using Trusted Communities in a Trusted Desktop
Grid. In Self-Adaptive and Self-Organizing Systems
Workshops (SASOW), 2011 Fifth IEEE Conference on.
Bernard, Y., Klejnowski, L., H
¨
ahner, J., and M
¨
uller-Schloer,
C. (2010). Towards Trust in Desktop Grid Systems.
Cluster Computing and the Grid, IEEE Int. Sympo-
sium on, 0:637–642.
Cakar, E. and M
¨
uller-Schloer, C. (2009). Self-Organising
Interaction Patterns of Homogeneous and Heteroge-
neous Multi-Agent Populations. In Self-Adaptive and
Self-Organizing Systems, 2009. SASO ’09. Third IEEE
Int. Conference on, pages 165–174.
Castelfranchi, C. and Falcone, R. (2010). Trust Theory: A
Socio-Cognitive and Computational Model. Wiley.
Huberman, B. A. and Clearwater, S. H. (1995). A multi-
agent system for controlling building environments. In
Proceedings of the First International Conference on
Multiagent Systems, pages 171–176.
Kantert, J., Bernard, Y., Klejnowski, L., and M
¨
uller-
Schloer, C. (2013). Estimation of reward and decision
making for trust-adaptive agents in normative environ-
ments. accepted at ARCS2014.
M
¨
uller-Schloer, C. and Schmeck, H. (2011). Organic Com-
puting - Quo Vadis? In Organic Computing - A
Paradigm Shift for Complex Systems, chapter 6.2,
page to appear. Birkh
¨
auser Verlag.
Singh, M. P. (1999). An ontology for commitments in
multiagent systems. Artificial Intelligence and Law,
7(1):97–113.
Tuomela, R. and Bonnevier-Tuomela, M. (1995). Norms
and agreements. European Journal of Law, Philoso-
phy and Computer Science, 5:41–46.
von Wright, G. H. (1963). Norms and action: a logical
enquiry. Routledge & Kegan Paul.
InfluenceofNormsonDecisionMakinginTrustedDesktopGridSystems-MakingNormsExplicit
283
