
A New Risk Chart for Acute Myocardial Infarction by a Innovative
Algoritm
Federico Licastro
1
, Manuela Ianni
2
, Roberto Ferrari
3
, Gianluca Campo
3
, Massimo Buscema
4
,
Enzo Grossi
5
and Elisa Porcellini
1
1
Department of Experimental, Diagnostic and Specialty Medicine, University of Bologna,
Via S. Giacomo 14, 40126 Bologna, Italy
2
Azienda Ospedaliera Sant'Orsola Malpighi, Seragnoli Institute, University of Bologna,
Via Massarenti, 9, 40138, Bologna, Italy
3
Department of Cardiology, University of Ferrara, Corso Giovecca 203, 44100, Ferrara, Italy
4
Semeion Research Center of Communication Science, Via Sersale 117, 00128 Roma, Italy
5
Bracco Foudation, via Folli 50, 20134 Milan, Italy
Keywords: Acute Myocardial Infarction (AMI), Artificial Neural Network (ANN), Twist Algorithm, Risk Chart.
Abstract: Acute myocardial infarction (AMI) is complex disease; its pathogenesis is not completely understood and
several variables are involved in the disease.. The aim of this paper was to assess: 1) the predictive capacity
of Artificial Neural Networks (ANNs) in consistently distinguishing the two different conditions (AMI or
control). 2) the identification of those variables with the maximal relevance for AMI. Genetic variances in
inflammatory genes and clinical and classical risk factors in 149 AMI patients and 72 controls were
investigated. From the data base of this case/control study 36 variables were selected. TWIST system, an
evolutionary algorithm able to remove redundant and noisy information from complex data sets, selected 18
variables. Fitness, sensitivity, specificity, overall accuracy of the association of these variables with AMI
risk were investigated. Our findings showed that ANNs are useful in distinguishing risk factors selectively
associated with the disease. Finally, the new variable cluster, including classical and genetic risk factors,
generated a new risk chart able to discriminate AMI from controls with an accuracy of 90%. This approach
may be used to assess individual AMI risk in unaffected subjects with increased risk of the disease such as
first relative with positive parental history of AMI.
1 INTRODUCTION
Morbidity and mortality of coronary heart disease
(CHD) are high and acute myocardial infarction
(AMI) is the major clinical complication of CHD
(Yusuf S
, 2001, Levi F,
2002).
AMI is a multi-factorial disease with a complex
and incompletely defined pathogenesis. In fact,
genetic, clinical and phenotypic factors are involved
in the clinical history of the disease.
Knowledge regarding risk factors predisposing to
AMI is still incomplete. It is known that many CHD
events occur in individuals with at most one risk
factor among those included in the Framingham risk
assessment.
Different investigations confirmed that
biomarkers of inflammation, such as increased blood
homocysteine (Cummings DM, 2006)
,
C-reactive
protein (Ridker PM, 2000) and cytokine levels
(Packard RR, 2008; Zhang C, 2008; Andersson J,
2010; Pamukcu B, 2010 and Biasillo G, 2010) could
be considered new risk factors for CHD and AMI.
Genetic variations, represented by single
nucleotide polymorphisms (SNPs) in the promoter
region of several genes regulating metabolic and
immune functions from case/control studies were
found to be associated with an increased risk of AMI
(Licastro F, 2010 and Ianni M, 2012).
Moreover, recent genome-wide association
(GWA) studies have contributed to the discovery of
new SNPs associated with CHD and AMI (Patel RS,
2011).
However, a single gene variant has a limited
contribution to the total genetic load of AMI.. This
252
Licastro F., Ianni M., Ferrari R., Campo G., Buscema M., Grossi E. and Porcellini E..
A New Risk Chart for Acute Myocardial Infarction by a Innovative Algoritm.
DOI: 10.5220/0005183102520259
In Proceedings of the International Conference on Health Informatics (HEALTHINF-2015), pages 252-259
ISBN: 978-989-758-068-0
Copyright
c
2015 SCITEPRESS (Science and Technology Publications, Lda.)

situation may partially explain the contradictory
results of genetic association studies using the
candidate gene SNP approach in AMI (Kullo IJ,
2007; Hamsten A, 2008; Chiappelli M, 2005).
Therefore it is important to introduce new
statistical methods to approach relationship of risk
factors with AMI.
The Auto Contractive Map algorithm (AutoCM)
has already been used to explore the concomitant
presence and the associations among several genetic
and phenotypic variables with AMI in a multi factor
network (Licastro F, 2010 ). Individual phenotype
biomarkers can vary widely as a function of time
and may be different among subjects as result of
gender, concomitant diseases, metabolic disorders,
dietary intake and other environmental variables;
therefore, to understand natural processes and
recreate those processes may be useful to employ
machine learning systems able to manage highly non
linear interactions (Penco S, 2005; Lisboa PJC,
2002; Grossi E, 2007).
Artificial neural networks (ANNs) function are
able to reconstruct the imprecise rules which may be
underlying a complex set of data (testing) (Coppedè
F, 2013). In recent years ANNs have been used
successfully in medicine, for example they have
been used to investigate the predictive values of risk
factors related to the conversion from amnestic mild
cognitive impairment to AD (Tabaton M, 2010), to
differentiate fronto-temporal dementia from AD
(Franceschi M, 2011) to identify genetic variants
essential to differentiate sporadic amyotrophic
lateral sclerosis cases from controls (Penco S, 2008;
Buscema M, 2012), or maternal risk for Down
syndrome child (Coppedè F, 2010).
In this pilot study we applied ANNs to
investigate genetic, clinic and phenotypic markers in
149 patients with AMI and 72 healthy subjects
selected from a previously described investigation
(Licastro F, 2010). The present study was performed
by using supervised ANNs to develop a predictive
model able to distinguish AMI patients from healthy
controls on the basis of classical risk factors and
gene variants involved in the disease.
Moreover, TWIST algorithm (Buscema M,
2004) was applied to the genetic, clinical and
phenotypic dataset in order to select relevant
variables associated with AMI risk. Sensitivity and
specificity of this selected group of variables in
relation with AMI risk was then tested. No previous
study has investigated the relationship among clinic,
phenotypic and genetic polymorphisms by ANNs
and TWIST in AMI.
The aim of this study was to investigate whether
these innovative mathematical approaches might
identify key new variables to better assess AMI risk
and describe a new risk chart for the disease.
2 MATERIALS AND METHODS
2.1 Subjects
149 consecutive patients with clinical diagnosis of
AMI (mean age = 71 ± 12; 70% male and 29%
female) from the Cardiology Unit of Ferrara
University Hospital were enrolled. Each patient met
diagnostic criteria for AMI based on
electrocardiography changes and standard laboratory
findings confirmed by echocardiography and
coronary angiography.
Controls consisted of 72 healthy subjects (mean
age = 75 ± 5; 49% male and 51% female) belonging
to a longitudinal population study, called “Conselice
study of brain aging” (Ravaglia G, 2001)
.
All
controls did not show cardiovascular or
inflammatory diseases at the beginning of the follow
up (1999-2000) and were still free of these
pathological conditions at the end of the follow up
(2004-2005).
The research protocol was approved by relevant
institutional review boards, all participants gave
written and informed consent and the investigation is
consistent with the principles outlined in the
Declaration of Helsinki.
2.2 SNP Detection
Genomic DNA from peripheral blood leukocytes of
AMI and healthy controls was obtained by a method
described elsewhere (Grimaldi LM, 2000). Genetic
determination of polymorphism in promoter regions
of IL-1β-511 C/T (rs16944), IL-6 -174 C/G
(rs=1800795), IL-10 -1082 G/A (rs1800896), TNF-
α -308 G/A (rs1800629), ACT -51 G/T (rs1884082),
VEGF -2578 C/A (rs699947) and HMGCR -911
C/A (rs3761740) genes was performed by Real
Time-PCR method. SNP-specific primers and
probes were designed according to the TaqMan
genotyping assay by ABI (Foster City, CA, USA)
and the assays were performed in 25 µl total volume
on Stratagene MX3000P following manufacturer’s
instructions (Licastro F, 2010; Chiappelli M, 2005).
IFNγ (rs2430561) and IL-6 (rs1800795) genotypes
were assayed by Real Time-PCR using the following
allele specific modified LNA primers (Latorra D,
2003).
ANewRiskChartforAcuteMyocardialInfarctionbyaInnovativeAlgoritm
253

IFN(+874)(rs2430561):
Primers F:
5’TTTATTCTTACAACACAAAATCAAATC+T-3’,
5’-TTTATTCTTACAACACAAAATCAAATC+A-3’,
Primer R
5’-TGTGCCTTCCTGTAGGGTATTATTA-3’
Il-6(-174)(rs1800795):
Primer F
5’-TCCCCCTAGTTGTGTCTTGC+C-3’,
5’-TCCCCCTAGTTGTGTCTTGC+G-3’,
Primer R
5’-AATCCCACATTTGATATAAATCTTTGT-3’
RT-PCR was performed in 96 well plates using
Stratagene MX3000P platform. Reaction volume
included a SYBR Green PCR Master Mix with the
enzyme, Mg
2+
and dNTPs (ABI, Fosteer City, CA,
USA) PCR primers and genomic DNA (0.5ng/µl)
was of 25µl . A start of 10 min at 95°C was followed
by 40 cycles at 95°C for 15 s and 60°C for 60 s.
2.3 Plasma Lipid Profile Detection
Plasma levels of total cholesterol, triglycerides and
HDL were measured by commercial clinical
laboratory assay.
2.4 Artificial Neural Networks (ANNs)
ANNs are adaptive models for the analysis of data;
these algorithms are inspired to the functioning
processes of the human brain (Grossi E, 2007) and
they are able to modify their internal structure in
relation to a function objective. The adaptive feature
is fundamental in case of complex data set in which
non linearity prevails.
The ANNs are particularly suited for solving
problems of the non linear type, being able to
reconstruct the approximate rules put into a certain
set of data. In this study, we applied supervised
ANNs to data network in which the result of the
processing (the output desired) is already defined.
Supervised ANNs calculate an error function that
measures the distance between the desired fixed
output (target) and their own output, and adjust the
connection strengths during the training process to
minimize the result of the error function. The
learning constraint of the supervised ANNs tests its
own output to overlap that of a determined target.
The general form of these ANNs is: y = f(x,w∗),
where we constitutes the set of parameters which
best approximate the function. The ANNs used in
the study are characterized by the law of learning
and topology. The laws of learning identify
equations which translate the ANNs inputs into
outputs, and rules by which the weights are modified
to minimize the error or the internal energy of the
ANN. In this study, we have used as a standard
model the Back Propagation standard (BP-FF)
(Rumelhart DE, 1982), belonging to a very large
family of ANNs defined by different interconnected
layers of nodes. These are characterized by a non
linear function, which can be differentiated and
limited, and has a linear combination of the
activations coming from the previous layer in the
input. The function is generally a sigmoid type.
The fundamental equation that characterizes the
activation of a single node and therefore, the transfer
of the signal from one layer to another is showed in
Fig 1.
Results obtained with these ANNs have also
been compared with a model of linear statistic such
as, the Linear Discriminant Analysis (LDA;
Software SPSS) (Tabaton M, 2010).
Fig 1: Single node activated value equation xj = node
activation value; f = sigmoidal function; W= vector of
weights arriving at j-n node; s = weights and nodes layer;
xi = Input nodes at J-n node.
2.5 Twist Algorithm
TWIST (Training With Input Selection and Testing)
is a new evolutionary algorithm (Buscema M, 2004)
able to generate two subsets of data with a very
similar probability density of distribution and with
the minimal number of effective variables for pattern
recognition.
Consequently, in the TWIST algorithm every
individual of the genetic population will be defined
by two vectors of different lengths:
1) the first one, showing which records (N) have
to be stored into the subset A and which ones have
to be stored into the subset B;
2) the second one, showing which inputs (M)
have to be used into the two subsets and which one
have to be deleted.
TWIST has already been applied to medical data
base with promising results (Penco S, 2005; Tabaton
M, 2010; Coppedè F, 2010; Buscema M, 2005;
Lahner E, 2008; Buri L, 2010; Street ME, 2008;
Buscema M, 2010; Rotondano G, 2011; Pace F,
2010). TWIST consists of a population of
Multilayer Perceptrons. The “reverse strategy” used
HEALTHINF2015-InternationalConferenceonHealthInformatics
254

in this algorithm tends to generate two subsets with
the same probability density function, and this is
exactly the gold standard of every random
distribution criterion (Buscema M, 2005).
In addition, when the “reverse strategy” is
applied, two fitness indicators are generated: the
accuracy on the subset B after the training on the
subset A, and the accuracy on the subset A after the
training on the subset B. But only the lower
accuracy of the two is saved as the best fitness of
each individual of the genetic population rather than
an average of the two or the higher of the two. This
criterion increases the statistical probability that the
two sub-samples are equally balanced during the
genetic evolution because of the quasi logarithmic
increase of the optimization process. We have also
demonstrated experimentally (Buscema M, 2013)
that when there is no information in a dataset, the
behaviors of the TWIST algorithm, the Training and
Testing Random Splitting and the K-Fold Cross
Validation are absolutely equivalent. Therefore,
TWIST does not code noise to reach optimistic
results (Buscema M, 2013).
Each ANN has to learn a subset of the global
dataset and has to be tested with another subset of
the dataset in a blind way. By this application the
fitness function of TWIST is re-programmed: the
population of Multilayer Perceptrons is exchanged
with a population of simple K Nearest Neighbour
(KNN), based on Euclidean metric. Basic kNN
algorithm is able to find the Euclidean similarity
between two samples that is training set and testing
set. So kNN is a suitable cost function for Twist
optimization. ANNs for classification are applied in
a second step, when the two subsamples (Training
and Test set) are already defined.
This change makes TWIST faster and more
oriented to discover explicit similarities between
input variables and classes (AMI and controls).
2.6 Training and Testing Protocol
Training and testing validation protocols consisted
of the following steps:
1) Division of the data set in to two sub-samples:
subset A and subset B. In the first run subset A was
used as the Training Set and the subset B as the
Testing Set.
2) Application of ANN trained on the Training Set.
In this phase the ANN learns to associate the input
variables with those that are indicated as targets.
3) At the end of training phase all the values
adaptively created by the artificial neural networks
and predefined as setting parameters are freezed and
kept apart for the testing phase
4) The Testing Set, which has not be seen before,
was then shown to the classificator that expressed an
evaluation based on the previously training; this
operation was performed for each input vector; each
result (output vector) was not communicated to the
classificator.
5) The ANN was evaluated only in reference to the
generalization ability acquired during the Training
phase.
6) In a second run an identical ANN is applied to
subset B which was used as training subset and then
to subset A which used as a testing subset.
2.7 The Receiver-Operating
Characteristic Curves (ROCs) and
Areas under Curves (AUC)
Sensitivity and specificity along with positive and
negative predictive values with 95 % confidence
intervals for each strategy were estimated by AUC.
ROCs were calculated and compared for clinical and
statistical rules with a nonparametric approach using
a paired design (Delong ER, 1988). Odds ratio was
used for computing the association of variables with
the selected outcome. Chi-squared test was used to
assess the statistical significance of differences
among proportions. All p values involve hypothesis
tests against a two-sided alternative. Differences
were considered significant at a 0.05 probability
level (Buri L, 2010).
3 RESULTS
The original data set included the following
variables: Male, Female, Age<50 years, Age=50
years, Age>50 years, High BMI, Diabetes, High
cholesterol, Low HDL, High triglycerides, AMI,
Controls, CC genotype IL-1ß, CT genotype IL-1ß,
TT genotype IL-1ß, GG genotype ACT, GT genotype
ACT, TT genotype ACT, GG genotype IL-6, GC
genotype IL-6, CC genotype IL-6, CC genotype
HMGCR, CA genotype HMGCR, AA genotype
HMGCR, GG genotype IL-10, GA genotype IL-10,
AA genotype IL-10, CC genotype VEGF, CA
genotype VEGF, AA genotype VEGF, TT genotype
IFN-γ, TA genotype IFN-γ, AA genotype IFN-γ, GG
genotype TNF-α, GA genotype TNF-α, AA genotype
TNF-α.
The application of the TWIST algorithm allowed
the selection of 18 variables (italic variables) from a
previously established larger data set with 36
ANewRiskChartforAcuteMyocardialInfarctionbyaInnovativeAlgoritm
255
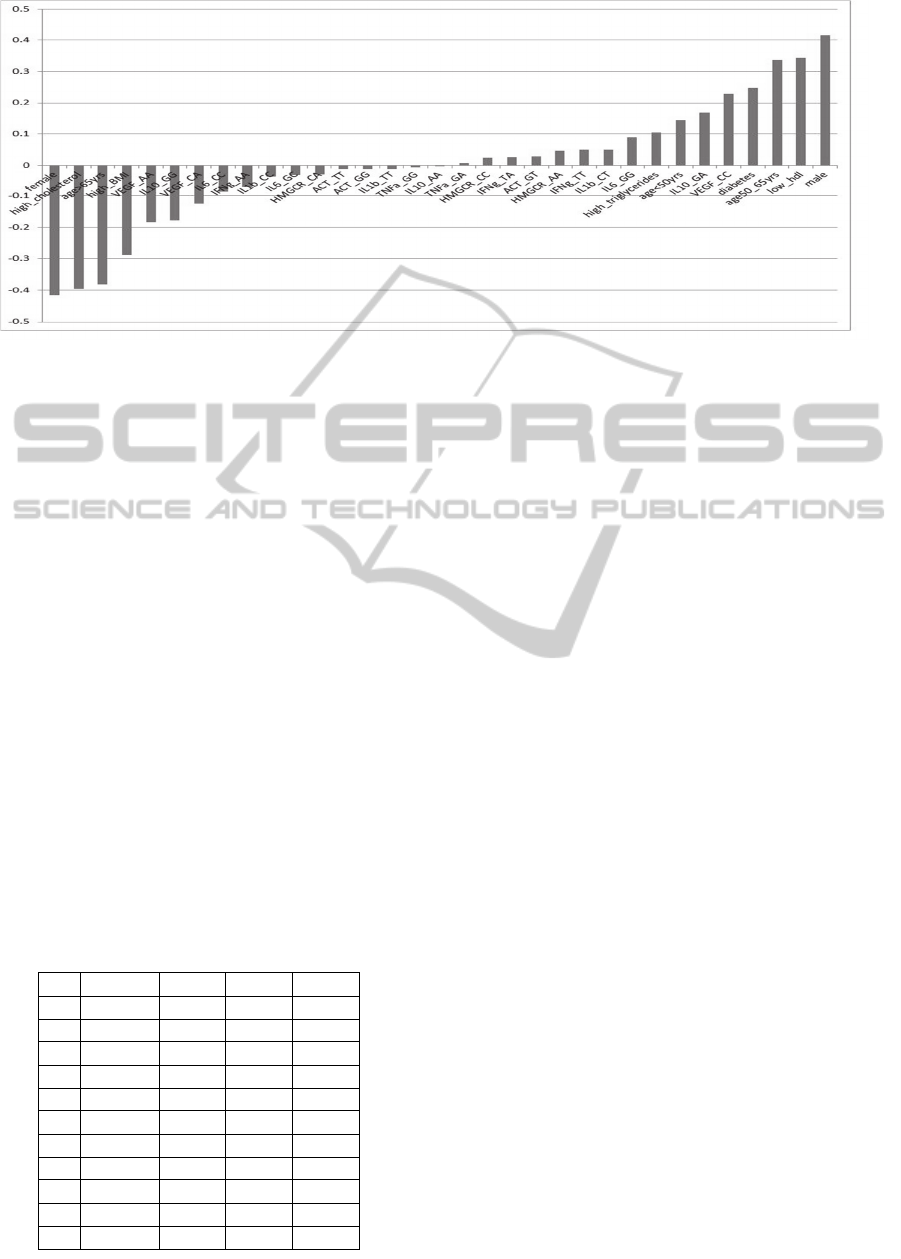
Figure 2: Linear correlation index in AMI.
variables (all variables).
The linear correlation indexes of 36 variables in
AMI patients has been reported in figure 2 where
variables appears more associated (up the line) or
less associated (down the line) with the AMI .
Tables 1 showed the results regarding sensitivity,
specificity and overall accuracy according AUC
analysis regarding association with AMI by using
the variables data set after the TWIST selection. By
10 different applications, the mean sensitivity
resulted 89.9%, mean specificity 85.4%, mean
overall accuracy 87.6.
The results obtained with independent
application of Back Propagation feed forward
artificial neural network using 8 hidden nodes in
sequence a-b and b-a were stable and consistently
reached an average overall accuracy near to 90%.
Consequently, the tested algorithms were able to
find a good correlation between some variables and
diagnosis, after the removal of noisy attributes.
Data from this investigation suggest a new risk
chart to be applied for the prevention of AMI in
unaffected subjects.
Table 1.
Table 1 Results obtained with the application of
10 independent supervised ANNs, five with the
sequence a-b. and five with the sequence b-a (see
text for explanation) in discriminating AMI from
control status by using the 18 variables after
selection operated by the TWIST algorithm.
4 DISCUSSION
A recent investigation by using a new CHD risk
assessment model described that age, gender,
diabetes and family history of AMI in combination
with seven blood biomarkers yielded a 43% clinical
net reclassification of patients previously considered
of intermediate risk level by Framingham’s criteria
(Cross DS, 2012).
In a German population study, among 10,981
men followed up for 11 years, 378 subjects
developed AMI; current smoking, excess body
weight and physical inactivity were associated with
the disease (Li K, 2014).
A recent investigation
confirmed that smoking (66%), hypertension (50%)
and diabetes (43%) were the principal risk factors
for AMI. However, the study conclusion was that
none of these factors reached an association so solid
to be used for AMI prediction in unaffected subjects
(Juárez-Herrera Ú, 2013).
This notion was reinforced by results from an
independent investigation on 605 consecutive
patients hospitalized for a first AMI showing that the
preventive potential of a classical risk factor
based health check was limited (Mortensen MB,
2013).
Moreover above quoted studies used
conventional statistical models and therefore
required a large number of patients and controls.
N
ANN Sens. Spec Acc.
1 *1 (ab) 83.51 90.48 86.99
2 *2 (ab) 86.6 85.71 86.16
3 *3 (ab) 84.54 83.33 83.93
4 *4 (ab) 85.57 88.1 86.83
5 *5 (ab) 96.15 83.33 89.74
6 *1 (ba) 92.31 83.33 87.82
7 *2 (ba) 94.23 83.33 88.78
8 *3 (ba) 94.23 86.67 90.45
9 *4 (ba) 94.23 86.67 90.45
10 *5 (ba) 87.63 83.33 85.48
Mean 89.9 85.43 87.66
HEALTHINF2015-InternationalConferenceonHealthInformatics
256

In the pilot study described here, ANNs and
other new potent mathematical algorithms have been
used and the need of large number of cases was not a
limitation. By applying these new statistical
algorithms we searched for a cluster of variables
able to discriminate AMI cases form healthy
controls.
TWIST algorithm operated a selection of 18
factors. and reached an average overall accuracy
near to 90%. On the other hand, results obtained
with the same validation protocol using all 36
variables were clearly inferior with an average
overall accuracy of 74.99% (data not shown).
Present results partially confirm previously
published findings showing that SNP in pro-
inflammatory genes were associated with increased
AMI risk in a different patients set by using a
diverse non conventional statistical analysis
(Licastro F, 2011) .
In conclusion the tested algorithms were able to
find a set of variables highly associated with AMI
diagnosis in men. This cluster is comprehensive of
new SNPs which can be easily assessed in
laboratory practice. Thereafter, the new cluster of
variables might be used to better describe AMI risk
in unaffected subjects with positive familiarity of the
disease.
These findings need to be confirmed in larger
case/control or longitudinal population studies.
REFERENCES
Andersson J, Libby P and Hansson GK. 2010 ‘Adaptive
immunity and atherosclerosis’ Clin Immunol; vol. 134,
no. 1, pp. 33–46.
Biasillo G, Leo M, Della Bona R, Biasucci LM. 2010
‘Inflammatory biomarkers and coronary heart disease:
from bench to bedside and back’ Intern Emerg Med;
vol. 5, no. 3, pp. 225–233.
Buri L, Hassan C, Bersani G, Anti M, Bianco MA,
Cipolletta L, Di Giulio E, Di Matteo G, Familiari L,
Ficano L, Loriga P, Morini S, Pietropaolo V, Zambelli
A, Grossi E, Intraligi M, Buscema M, SIED
Appropriateness Working Group. 2010
‘Appropriateness guidelines and predictive rules to
select patients for upper endoscopy: a nationwide
multicenter study’ Am J Gastroenterol; vol. 105, no.
6, pp. 1327-1337.
Buscema M, Breda M, Lodwick W. 2013’Training With
Input Selection and Testing (TWIST) algorithm: a
significant advance in pattern recognition performance
of machine learning’ Journal of Intelligent Learning
Systems and Applications, vol. 5, pp. 29-38.
Buscema M, Grossi E, Capriotti M, Babiloni C, Rossini P.
2010 ‘The I.F.A.S.T. Model Allows the Prediction of
Conversion to Alzheimer Disease in Patients with
Mild Cognitive Impairment with High Degree of
Accuracy’ Curr Alzheimer Res; vol. 7, no. 2, pp. 173-
187.
Buscema M. 2004 ‘Genetic Doping Algorithm (GenD):
Theory and Application’ Expert Syst; vol. 21, no. 2,
pp. 63-79.
Buscema M, Grossi E, Intraligi M, Garbagna N, Andriulli
A, Breda M. 2005 ‘An Optimized Experimental
Protocol Based on Neuro-Evolutionary Algorithms.
Application to the Classification of Dyspeptic Patients
and to the Prediction of the Effectiveness of Their
Treatment’ Artif Intell Med; vol. 34, no. 33, pp. 279-
305.
Buscema M, Penco S and Grossi E. 2012 ‘A Novel
Mathematical Approach to Define the Genes/SNPs
Conferring Risk or Protection in Sporadic
Amyotrophic Lateral Sclerosis Based on Auto
Contractive Map Neural Networks and Graph Theory’
Neurol Res Int. 478560.
Chiappelli M, Tampieri C, Tumini E, et al. Porcellini E,
Caldarera CM, Nanni S, Branzi A, Lio D, Caruso M,
Hoffmann E, Caruso C, Licastro F. 2005 ‘Interleukin-
6 gene polymorphism is an age-dependent risk factor
for myocardial infarction in men’ Int J Immunogenet;
vol. 32, no. 6, pp. 349–353.
Coppedè F, Grossi E, Migheli F, Migliore L. 2010
‘Polymorphisms in Folate-Metabolizing Genes,
Chromosome Damage, and Risk of Down Syndrome
in Italian Women: Identification of Key Factors Using
Artificial Neural Networks’ BMC Med Genomics; vol.
3, no. 42.
Coppedè F, Grossi E, Buscema M, Migliore L. 2013
‘Application of artificial neural networks to investigate
one-carbon metabolism in Alzheimer's disease and
healthy matched individuals’ PLoS One; vol. 8, no. 8,
pp. e74012.
Cross DS, McCarty CA, Hytopoulos E, Beggs M, Nolan
N, Harrington DS, Hastie T, Tibshirani R, Tracy RP,
Psaty BM, McClelland R, Tsao PS, Quertermous T.
2012 ‘Coronary risk assessment among intermediate
risk patients using a clinical and biomarker based
algorithm developed and validated in two population
cohorts’ Curr Med Res Opin; vol. 28, no. 11, pp.
1819-1830.
Cummings DM, King DE, Mainous AG, Geesey ME.
2006 ‘Combining serum biomarkers: the association
of C-reactive protein, insulin sensitivity, and
homocysteine with cardiovascular disease history in
the general US population’ Eur J Cardiovascular Prev
Rehabil; vol. 13, no. 2, pp. 180–185.
Delong ER , Delong DM and Clarke-Pearson DL. 1988
‘Comparing the areas under two or more receiver
operating characteristic curves: a nonparametric
approach’ Biometrics; vol. 44, no. 3, pp. 837-45.
Franceschi M, Caffarra P, Savarè R, Cerutti R, Grossi E;
Tol Research Group. 2011 ‘Tower of London test: a
comparison between conventional statistic approach
and modelling based on artificial neural network in
differentiating fronto-temporal-dementia from
ANewRiskChartforAcuteMyocardialInfarctionbyaInnovativeAlgoritm
257

Alzheimer’s disease’ Behav Neurol; vol. 24, no. 2, pp.
149-158.
Grimaldi LM, Casadei VM, Ferri C, Veglia F, Licastro F,
Annoni G, Biunno I, De Bellis G, Sorbi S, Mariani C,
Canal N, Griffin WS, Franceschi M. 2000
‘Association of early-onset Alzheimer's disease with
an interleukin-1alpha gene polymorphism’ Ann
Neurol; vol. 47, no. 3, pp. 361-365.
Grossi E, Mancini A and Buscema M. 2007 ‘International
experience on the use of artificial neural networks in
gastroenterology’ Dig Liver Dis; vol. 39, no. 3, pp.
278-285.
Hamsten A and Eriksson P. 2008 ‘Identifying the
susceptibility genes for coronary artery disease: from
hyperbole through doubt to cautious optimism’ J
Intern Med; vol. 263, no. 5, pp. 538–552.
Ianni M, Callegari S, Rizzo A, Pastori P, Moruzzi P,
Corradi D, Porcellini E, Campo G, Ferrari R, Ferrario
MM, Bitonte S, Carbone I, Licastro F. 2012 ‘Pro-
inflammatory genetic profile and familiarity of acute
myocardial infarction’ Immun Ageing; vol. 9, no. 1,
pp. 14.
Juárez-Herrera Ú, Jerjes-Sánchez C, RENASICA II
Investigators. 2013 ‘Risk factors, therapeutic
approaches, and in-hospital outcomes in Mexicans
with ST-elevation acute myocardial infarction: the
RENASICA II multicenter registry’ Clin Cardiol; vol.
36, no. 5, pp. 241-248.
Kullo IJ and Ding K. 2007 ‘Mechanisms of disease: The
genetic basis of coronary heart disease’ Nat Clin Pract
Cardiovasc Med; vol. 4, no. 10, pp. 558–569.
Lahner E, Intraligi M, Buscema M, Centanni M, Vannella
L, Grossi E, Annibale B. 2008 ‘Artificial Neural
Networks in the Recognition of the Presence of
Thyroid Disease in Patients with Atrophic Body
Gastritis’ World J Gastroenterol; vol. 14, no. 4, pp.
563-568.
Latorra D, Campbell K, Wolter A, Hurley JM. 2003
‘Enhanced allele-specific PCR discrimination in SNP
genotyping using 3' locked nucleic acid (LNA)
primers’ Hum Mutat; vol. 22, no. 1, pp. 79-85.
Levi F, Lucchini F, Negri E, La Vecchia C. 2002 ‘Trends
in mortality from cardiovascular and cerebrovascular
diseases in Europe and other areas of the world’
Heart; vol. 88, no. 22, pp. 119–124.
Li K, Monni S, Hüsing A, Wendt A, Kneisel J, Groß ML,
Kaaks R. 2014 ‘Primary preventive potential of major
lifestyle risk factors for acute myocardial infarction in
men: an analysis of the EPIC-Heidelberg cohort’ Eur J
Epidemiol; vol. 29, no. 1, pp. 27-34.
Licastro F, Chiappelli M, Porcellini E, Campo G,
Buscema M, Grossi E, Garoia F, Ferrari R. 2010
‘Gene-gene and gene - clinical factors interaction in
acute myocardial infarction: a new detailed risk chart’
Current Pharmaceutical Des; vol. 16, no. 7, pp. 783–
788.
Licastro F, Chiappelli M, Caldarera CM, Porcellini E,
Carbone I, Caruso C, Lio D, Corder EH. 2011
‘Sharing pathogenetic mechanisms between acute
myocardial infarction and Alzheimer disease as shown
by partially overlapping of gene variant profiles’ J Alz
Dis; vol. 23, no. 3, pp. 421-431.
Lisboa PJC. 2002 ‘A review of evidence of health benefit
from artificial neural networks in medical
intervention’ Neural Netw; vol. 15, no. 1, pp. 11-39.
Mortensen MB, Sivesgaard K, Jensen HK, Comuth W,
Kanstrup H, Gotzsche O, May O, Bertelsen J, Falk E.
2013 ‘Traditional SCORE-based health check fails to
identify individuals who develop acute myocardial
infarction’ Dan Med J; vol. 60, no. 5, A4629.
Pace F, Riegler G, de Leone A, Pace M, Cestari R,
Dominici P, Grossi E, EMERGE Study Group. 2010
‘Is It Possible to Clinically Differentiate Erosive from
Non erosive Reflux Disease Patients? A Study Using
an Artificial Neural Networks-Assisted Algorithm’
Eur J Gastroenterol Hepatol; vol. 22, no. 10, pp.
1163-1168.
Packard RR and Libby P. 2008 ‘Inflammation in
atherosclerosis: from vascular biology to biomarker
discovery and risk prediction’ Clin Chem; vol. 54, no.
1, pp. 24–38.
Pamukcu B, Lip GY, Devitt A, Griffiths H, Shantsila E.
2010 ‘The role of monocytes in atherosclerotic
coronary artery disease’ Ann Med; vol. 42, no. 6, pp.
394–403.
Patel RS and Ye S. 2011 ‘Genetic determinants of
coronary heart disease: new discoveries and insights
from genome-wide association studies’ Heart; vol. 97,
no. 18, pp. 1463–1473.
Penco S, Grossi E, Cheng S, Intraligi M, Maurelli G,
Patrosso MC, Marocchi A, Buscema M. 2005
‘Assessment of the Role of Genetic Polymorphism in
Venous Thrombosis Through Artificial Neural
Networks’ Ann Hum Genet; vol. 69, no. 6; pp. 693-
706.
Penco S, Buscema M, Patrosso MC, Marocchi A, Grossi
E. 2008 ‘New application of intelligent agents in
sporadic amyotrophic lateral sclerosis identifies
unexpected specific genetic background’ BMC
Bioinformatics; vol. 9, pp. 254.
Ravaglia G, Forti P, Maioli F, Orlanducci P, Sacchetti L,
Flisi E, Dalmonte E, Martignani A, Cucinotta D,
Cavalli G. 2001 ‘Conselice study: a population based
survey of brain aging in a muncipality of the Emilia
Romagna region: (A.U.S.L. Ravenna). Design and
methods’ Arch Gerontol Geriatr Suppl; vol. 7, pp.
313-324.
Ridker PM, Rifai N, Pfeffer M, Sacks F, Lepage S,
Braunwald E. 2000 ‘Elevation of tumor necrosis
factor-alpha and increased risk of recurrent coronary
events after myocardial infarction’ Circulation; vol.
101, no. 18, pp. 2149–2153.
Rotondano G, Cipolletta L, Grossi E, Koch M, Intraligi M,
Buscema M, Marmo R; Italian Registry on Upper
Gastrointestinal Bleeding (Progetto Nazionale
Emorragie Digestive). 2011 ‘Artificial Neural
Networks Accurately Predict Mortality in Patients
with Non variceal Upper GI Bleeding’ Gastrointest
Endoscop; vol. 73, no. 2, pp. 218-226.
Rumelhart DE and McClelland JL. 1982 ‘An interactive
HEALTHINF2015-InternationalConferenceonHealthInformatics
258

activation model of context effects in letter perception:
Part 2. The contextual enhancement effect and some
tests and extensions of the model’ Psychol Rev; vol.
89, no.1, pp. 60-94.
Street ME, Grossi E, Volta C, Faleschini E, Bernasconi S.
2008 ‘Placental Determinants of Fetal Growth:
Identification of Key Factors in the Insulin-Like
Growth Factor and Cytokine Systems Using Artificial
Neural Networks’ BMC Pediatr; vol. 8, no. 24.
Tabaton M, Odetti P, Cammarata S, Borghi R, Monacelli
F, Caltagirone C, Bossù P, Buscema M, Grossi E.
2010 ‘Artificial Neural Networks Identify the
Predictive Values of Risk Factors on the Conversion
of Amnestic Mild Cognitive Impairment’ J Alzheimers
Dis; vol. 19, no. 3, pp. 1035-1040.
Yusuf S, Reddy S, Ounpuu S, Anand S. 2001 ‘Global
burden of cardiovascular diseases: part I: general
considerations, the epidemiologic transition, risk
factors, and impact of urbanization’ Circulation; vol.
104, no. 22, pp. 2746–2753.
Zhang C. 2008 ‘The role of inflammatory cytokines in
endothelial dysfunction’ Basic Res Cardiol; vol. 103,
no. 5, pp. 398–406.
ANewRiskChartforAcuteMyocardialInfarctionbyaInnovativeAlgoritm
259
