
Real-time Curve-skeleton Extraction of Human-scanned Point Clouds
Application in Upright Human Pose Estimation
Frederic Garcia and Bj
¨
orn Ottersten
Interdisciplinary Centre for Security Reliability and Trust (SnT), University of Luxembourg, Luxembourg City, Luxembourg
Keywords:
Curve-skeleton, Skeletonization, Human Pose Estimation, Object Representation, Point Cloud, Real-time.
Abstract:
This paper presents a practical and robust approach for upright human curve-skeleton extraction. Curve-
skeletons are object descriptors that represent a simplified version of the geometry and topology of a 3-D
object. The curve-skeleton of a human-scanned point set enables the approximation of the underlying skeletal
structure and thus, to estimate the body configuration (human pose). In contrast to most curve-skeleton extrac-
tion methodologies from the literature, we herein propose a real-time curve-skeleton extraction approach that
applies to scanned point clouds, independently of the object’s complexity and/or the amount of noise within
the depth measurements. The experimental results show the ability of the algorithm to extract a centered
curve-skeleton within the 3-D object, with the same topology, and with unit thickness. The proposed approach
is intended for real world applications and hence, it handles large portions of data missing due to occlusions,
acquisition hindrances or registration inaccuracies.
1 INTRODUCTION
Human pose estimation not only is one of the funda-
mental research topics in computer vision, but a nec-
essary step in active research topics such as scene un-
derstanding, human-computer interaction and action
or gesture recognition; a side-effect of the recent ad-
vances in 3-D sensing technologies.
In this paper, we address the problem of human
pose estimation in the context of 3-D scenes scanned
by multiple consumer-accessible depth cameras such
as the Kinect or the Xtion Pro Live. To that end, we
propose to use curve-skeletons, a compressed repre-
sentation of the 3-D object. Curve-skeletons are ex-
tremely useful in computer graphics and increasingly
being used in computer vision for their valuable aid
to address many visualization tasks including shape
analysis, animation, morphing and/or shape retrieval.
Indeed, curve-skeletons represent a simplified version
of the 3-D object with a major advantage of preserv-
ing both its geometry and topology information. This,
in turn, allows to estimate the object configuration or
object pose after approximating its skeletal structure.
The remainder of the paper is organized as fol-
lows: Section 2 covers the literature review on the
most recent curve-skeleton extraction approaches for
point cloud datasets. Section 3 introduces our real-
time curve-skeleton extraction approach. In Section 4
we evaluate and analyze the resulting curve-skeletons
from multiple scanned 3-D models. To do so, both
real and synthetic data have been considered. Finally,
concluding remarks are given in Section 5.
2 RELATED WORK
Curve-skeleton makes decisive contribution for hu-
man pose estimation as it enables to estimate the
body configuration by fitting the underlying skele-
tal structure. Consequently, an extensive research
can be found in the literature, with many approaches
strongly dependent on the requirements of their ap-
plications. In the following we only review the most
representative methods for curve-skeleton extraction
from point cloud datasets. For a complete review,
we refer the reader to the comprehensive survey of
Cornea et al. (Cornea et al., 2007).
Skeletonization algorithms can be divided in four
different classes: thinning and boundary propagation,
distance field-based, geometric, and general/field
functions (Cornea et al., 2007). However, recent ap-
proaches are providing excellent results by combining
different techniques from different classes (Cao et al.,
2010) (Sam et al., 2012) (Tagliasacchi et al., 2009).
Au et al. (Au et al., 2008) proposed a curve-skeleton
extraction approach by mesh contraction using Lapla-
54
Garcia F. and Ottersten B..
Real-time Curve-skeleton Extraction of Human-scanned Point Clouds - Application in Upright Human Pose Estimation.
DOI: 10.5220/0005298300540060
In Proceedings of the 10th International Conference on Computer Vision Theory and Applications (VISAPP-2015), pages 54-60
ISBN: 978-989-758-090-1
Copyright
c
2015 SCITEPRESS (Science and Technology Publications, Lda.)

cian smoothing. They used connectivity surgery to
preserve the original topology and an iterative pro-
cess as an energy minimization problem with con-
traction and attraction terms. Though special atten-
tion must be paid to the contraction parameters, the
method fails in the case of very coarse models. Wa-
tertight meshes are required due to the mesh connec-
tivity constraint from the Laplacian smoothing. Cao
et al. (Cao et al., 2010) extended their work to point
cloud datasets. To do so, a local one-ring connec-
tivity of point neighborhood must be done for the
Laplacian operation, which significantly increases the
processing time. An alternative approach proposed
by Tagliasacchi et al. (Tagliasacchi et al., 2009) uses
recursive planar cuts and local rotational symmetric
axis (ROSA) to extract the curve-skeleton from in-
complete point clouds. However, their approach re-
quires special attention within object joints and it is
not generalizable to all shapes. Similarly, Sam et
al. (Sam et al., 2012) use the cutting plane idea but
only two anchors points must be computed. They
guarantee centeredness by relocating skeletal nodes
using ellipse fitting. However, although the result-
ing curve-skeletons from this work preserve most of
the required properties cited by Cornea et al. (Cornea
et al., 2007), they are impractical when real-time is
required. We herein overcome this limitation by com-
puting the skeletal candidates in the 2-D space.
3 PROPOSED APPROACH
In the following we introduce our approach to extract
the curve-skeleton from upright human-scanned point
clouds. Our major contribution, in which we address
the real-time constraint, is based on the extraction of
the skeletal candidates in the 2-D space. We have
been inspired by image processing techniques used
in silhouette-based human pose estimation (Li et al.,
2009). The final 3-D curve-skeleton results from back
projecting these 2-D skeletal candidates to their right
location in the 3-D space.
Let us consider a scanned point cloud P repre-
sented in a three-dimensional Euclidean space E
3
≡
{p(x,y, z)|1 ≤ x ≤ X,1 ≤ y ≤ Y,1 ≤ z ≤ Z}, and de-
scribing a set of 3-D points p
i
representing the under-
lying external surface of an upright human body. The
first step concerns the voxelization of the given point
cloud to account for the point redundancy resulting
from registering multi-view depth data. To that end,
we have considered the surface voxelization approach
presented in (Garcia and Ottersten, 2014). The result-
ing point cloud P
0
presents both a uniform point den-
sity and a significantly reduction of the points to be
further processed. Our goal is to build a 2-D image
representing the front view of the 3-D body in order
to extract its curve-skeleton using 2-D image process-
ing techniques. To do so, we define a cutting-plane π
being parallel to x and y-axis of E
3
and intersecting
P
0
at
¯
p, the mean point or centroid of the point set P
0
,
i.e.,
¯
p =
1
k
·
∑
k
i=1
p
i
. From our experimental results,
π crossing
¯
p provides good body orientations in the
case of upright body postures, e.g., walking, running
or working. Alternative body configurations are dis-
cussed in Section 4.1. We determine the body orienta-
tion by fitting a 2-D ellipse onto the set of 3-D points
lying on π, i.e., ∀p
i
|p
i
(z) =
¯
p(z). We note that in prac-
tice and due to point density variations, 3-D points
are not necessarily lying on π. Therefore, we con-
sider those 3-D points in P
0
with p
i
(z) ∈ [
¯
p(z) ± λ],
and λ being related to the point density of P
0
, as
depicted in Fig. 1a. We note that λ has to be cho-
sen large enough to ensure a good description of the
body contour. In turn, the higher the point density
the smaller the λ value should be. Fig. 1b illus-
trates the resulting 2-D ellipse using the Fitzgibbon
et al. (Fitzgibbon and Fisher, 1995) approach, imple-
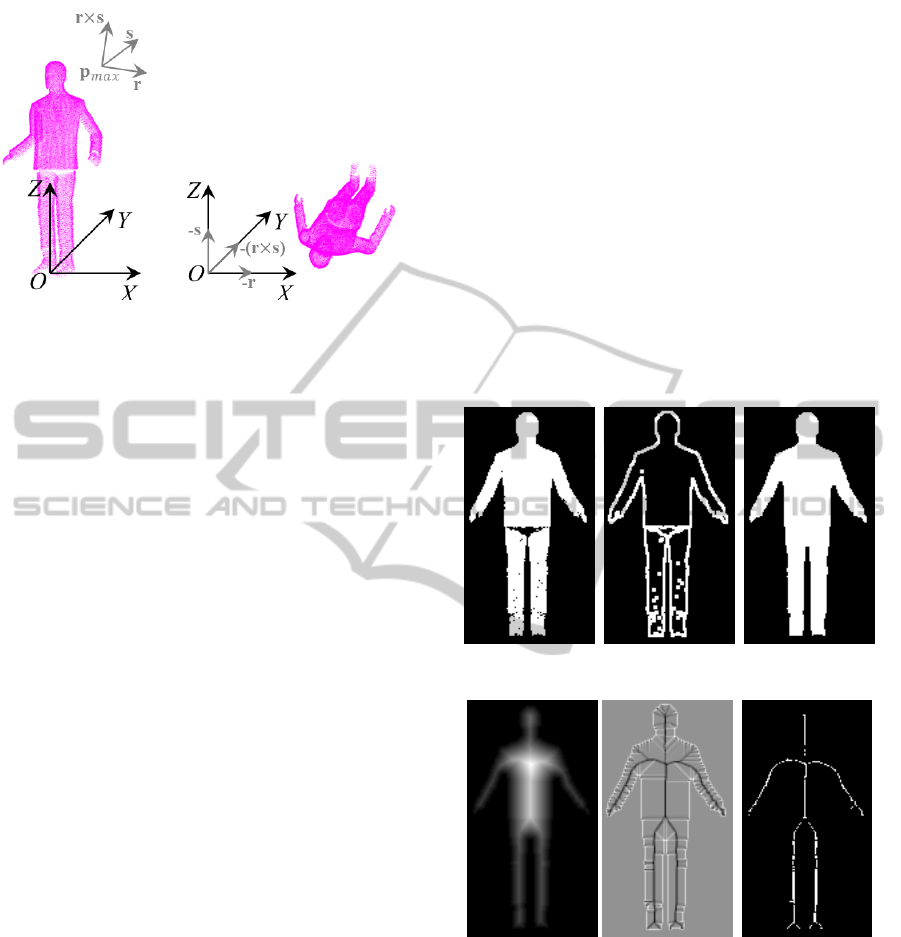
mented in OpenCV (Bradski and Kaehler, 2008). r
and s are unitary vectors along the major and minor el-
lipse axes, respectively. c is the ellipse centroid. Once
the body orientation is known, we build the 2-D image
I representing the front view of the human body. To
do so, we can project P
0
to the 2-D plane π
0
defined
by the ellipse major axis r and with normal vector
s. Image dimensions are given by the projections of
the minimum p
min
= (x
min
,y
min
,z
min
) and maximum
p
max
= (x
max
,y
max
,z
max
) 3-D point coordinates from
P
0
. An alternative solution is to translate P
0
from
the coordinate frame C
1
= (r, s, r × s), and origin
at p
max
, depicted in Fig. 2a, to the coordinate frame
C
2
= (−r,−(r × s), −s), and origin at (0,0,0), de-
(a) (b)
Figure 1: (a) Selected 3-D points (in green color) for el-
lipse fitting. (b) Fitted ellipse using OpenCV (Bradski and
Kaehler, 2008).
Real-timeCurve-skeletonExtractionofHuman-scannedPointClouds-ApplicationinUprightHumanPoseEstimation
55
(a) P
0
(b) P
00
Figure 2: (a) P
0
at C
1
. (b) P
00
at C
2
.
picted in Fig. 2b, i.e., P
00
= T
C
2
C
1
· P
0
. By doing so, the
2-D plane π
0
coincides with the two-dimensional Eu-
clidean space with x and y axes coincident to E
3
, i.e.,
E
2
≡ {I(m,n)|1 ≤ m ≤ M,1 ≤ n ≤ N}. Therefore,
I(m,n) =
255 if p
i
∈ P
00
∀
i
0 otherwise,
(1)
with m = δ · round
p
i
(x)
and n = δ · round
p
i
(y)
,
and δ the conversion factor between metric units and
pixels (herein we set δ = 100, i.e., 1 mm = 1 pixel).
Fig. 3a shows the resulting image I after projecting
P
00
onto E
2
.
In 2-D image processing, distance field or dis-
tance transform (DT) is commonly used to build im-
age maps D from binary images. Pixel values indicate
the minimum distance between the selected pixel and
its nearest boundary pixel, i.e., the closest zero pixel.
That is, D(u) = min{d(u,v)|I(v) = 0}, with d(u,v)
being the Euclidean, Manhattan or Chessboard dis-
tance metric. We note that the resulting image map
is highly sensitive to zeros pixels, and thus holes in
the image will significantly alter the resulting image
map. A valid approach to fill the body silhouette in
the case of a constant density of points and without
omission of data is the use of morphological operators
such as dilation and erosion operators. However, fill-
ing the body silhouette becomes more intricate when
treating incomplete point clouds with large portions
of data missing, e.g., around the pelvis in Fig. 3a. We
therefore propose to extract the contours of I and fill
the area bounded by the most external contour, i.e.,
the body silhouette, which results in a dense body sil-
houette, as shown in Fig. 3c. To do so, we use the
contour following algorithm proposed by Suzuki et
al. (Suzuki and Abe, 1985) (see Fig. 3b). Among the
aforementioned distance metrics, we herein have con-
sidered the Euclidean DT described in (Felzenszwalb
and Huttenlocher, 2004). From the resulting image
map D in Fig. 3d, we realize that higher-valued map
pixels correspond to centered pixels within the sil-
houette boundary and thus, skeletal candidates. In-
deed, skeletal candidates coincide with low-valued
edges on the result of the Laplace operator on D,
i.e., ∆D = ∂
2
D/∂
2
m + ∂
2
D/∂
2
n, as can be observed
in Fig. 3e. The final 2-D coordinates of the skeletal
candidates J are given by an adaptive thresholding on
the low-valued edges in ∆D, i.e.,
J(u) =
255 if ∆D(u) < τ
0 otherwise,
(2)
being τ the adaptive threshold value. A valid τ
value can be automatically obtained using Otsu’s
method (Sezgin and Sankur, 2004). The pixel posi-
(a) I. (b) (c)
(d) D. (e) ∆D. (f) J.
Figure 3: (a) I from (1). (b) Contours of I. (c) Body silhou-
ette. (d) Euclidean DT D. (e) Laplace operator ∆D. (f) J
from (2).
tions of the skeletal candidates from (2) correspond to
the x and y coordinates of the 3-D points q
i
that will
constitute the final curve-skeleton J , as depicted in
Fig 4, i.e., q
i
(x) = m and q
i
(y) = n ∀J(m, n) = 255.
We determine the missing q
i
(z) coordinate for each
skeletal candidate J(u
i
) by defining the line l
i
with
unit vector the z-axis of E
3
and intersecting at the cor-
responding skeletal candidate J(u
i
). The missing co-
ordinate corresponds to the middle point between the
VISAPP2015-InternationalConferenceonComputerVisionTheoryandApplications
56

Figure 4: (a) Skeletal candidates J (in blue color) and the
location of a skeletal candidate J(u
i
) in the 3-D space, i.e.,
q
i
(z).
lower p
j
and upper p
k
intersected points on the exter-
nal contour of the selected slice, also computed using
the contour following algorithm in (Suzuki and Abe,
1985), i.e., q
i
(z) = p
j
(z) +
p
k
(z) − p
j
(z)
/2. The fi-
nal 3-D curve-skeleton J results from projecting back
the 3-D points q
i
from C
2
to C
1
, i.e., J = T
C
1
C
2
· J =
(T
C
2
C
1
)
−1
· J .
4 EXPERIMENTAL RESULTS
In the following we evaluate the proposed curve-
skeleton extraction approach on both real and syn-
thetic data. In addition, we present a visual
comparison against the curve-skeleton extraction
via Laplacian-based contraction approach presented
in (Cao et al., 2010), and the runtime analysis. All
reported results have been obtained using a Mobile
Intel
R
QM67 Express Chipset with an integrated
graphic card Intel
R
HD Graphics 3000. The pro-
posed approach has been implemented in C++ lan-
guage using the OpenCV (Bradski and Kaehler, 2008)
and PCL (PCL, 2014) libraries.
Four different 3-D models have been consid-
ered to evaluate the proposed curve-skeleton extrac-
tion approach, i.e., the standing Bill from the V-
Rep repository (VRE, 2014), and the Nilin Combat,
Iron Man and Minions, from the publicly available
TF3DM
TM
repository (TF3, 2014). The vast majority
of available 3-D models are built as textured polyg-
onal models, being flexible and easily to be rendered
by computers. However, the number of polygons is
far below the number of 3-D points of a real scanned
object; mainly within regions with uniform geome-
try. Consequently, we have transformed the represen-
tation of the considered 3-D models from polygonal
meshes to real 3-D point sets. To do so, we have
simulated a multi-view sensing system composed of
4 RGB-D cameras using V-Rep (VRE, 2014), a very
versatile robot simulator tool in which the user can
replicate real scenarios, as shown in Fig. 5. Synthetic
Figure 5: Experimental environment using V-Rep.
data results from the registration of the depth data ac-
quired by each virtual RGB-D camera.
Fig. 6 shows the scanned 3-D models (in purple
color), after data registration and surface voxeliza-
tion, and their respective extracted curve-skeletons.
We note that the resulting curve-skeletons present the
same topology and geometry as the 3-D object; being
unit wide and centrally placed within the underlying
scanned surface.
We show, in Fig. 7, a visual comparison against
Cao et al. approach (Cao et al., 2010). One of the
limitations of Cao et al. approach is the need of
1-ring neighborhood to perform the Laplacian-based
contraction. As a result, their approach fails in the
presence of large portions of data missing, as occurs
around the pelvis in Fig. 7c and Fig. 7f. Furthermore,
contraction and attraction weights must be manu-
ally tunned in order to obtain a unit thickness curve-
skeleton. Herein, we have considered the default set-
tings provided by the authors. We also note that the
consumption time to extract each curve-skeleton is
above 1 minute.
Table 1: Running time to extract the curve-skeleton of the
3-D models presented in Fig. 6 (units are in ms).
3-D Model
Running time
Orientation Silhouette D ∆D p
i
(z) Total
Standing Bill
2.5 0.2 0.3 0.0 193.0 252.2
(23650 points)
Nilin Combat
1.6 0.0 0.1 0.1 159.6 206.0
(18730 points)
Iron Man
2.7 0.1 0.4 0.2 390.6 473.0
(33358 points)
Minions
1.5 0.3 0.1 0.2 105.4 150.8
(18426 points)
Man 1
1.3 0.7 0.3 0.1 232.7 279.5
(18053 points)
Man 2
0.9 0.4 0.4 0.1 287.5 341.6
(21263 points)
Woman 1
0.4 0.1 0.3 0.1 109.3 142.1
(12986 points)
Real-timeCurve-skeletonExtractionofHuman-scannedPointClouds-ApplicationinUprightHumanPoseEstimation
57

(a) (b) (c) (d)
(e) (f) (g) (h)
(i) (j) (k) (l)
(m) (n) (o) (p)
Figure 6: Curve-skeleton extraction from synthetic object-scanned point clouds. 1
st
row, Standing Bill (23650 points). 2
nd
row, Nilin Combat (18730 points). 3
rd
row, Iron Man (33358 points). 4
rd
row, Minions (18426 points).
Real data has been generated from a multi-view
sensing system composed of 2 consumer-accessible
RGB-D cameras, i.e., the Asus Xtion Pro Live cam-
era, with opposed field-of-views, i.e., with no data
overlapping. The relationship between the two cam-
eras was determined using the stereo calibration
implementation available in OpenCV (Bradski and
Kaehler, 2008) and a transparent checkerboard (black
squares are visible from both sides). Better regis-
tration approaches based on ICP, bundle adjustment
or the combination of both can also be considered.
However, it is shown in Fig. 8 that the current ap-
proach perfectly extracts the curve-skeleton on such a
coarse registered point clouds, handling large portions
of missing data as well as registration inaccuracies.
Fig. 8 presents 3 coarse registered point clouds of two
mans and one woman. Note that despite the large por-
tions of data missing due to self occlusions and inac-
curate registration of both views, our approach is able
to extract an accurate curve-skeleton that preserves
both topology and geometry of the scanned model.
Table 1 reports the running time to extract the
curve-skeleton of the 3-D models presented in Fig. 6
and Fig. 8. We note that we have reported CPU-
based values without using data-parallel algorithms or
graphics hardware (GPU). Most of consumption time
is invested on determining the missing 3-D coordi-
nate of each skeletal candidate whereas 2-D process-
ing time is almost negligible, as it was expected.
4.1 Limitations and Future Work
The resulting curve-skeleton depends strongly on the
DT computed from the front view of the human body.
Therefore, occluded body parts due to crossing arms
or legs will not be considered and can provide wrong
skeletal candidates. Furthermore, having one or both
arms too close to the torso will make DT to consider
them as part of the torso. Similarly, if both legs are too
close, they can be considered as a single one. We plan
to solve these body configurations by using both tem-
poral and RGB information. Indeed, we herein pro-
VISAPP2015-InternationalConferenceonComputerVisionTheoryandApplications
58

(a) (b) (c) (d) (e) (f)
(g) (h) (i) (j) (k) (l)
(m) (n) (o) (p) (q) (r)
Figure 7: Visual comparison against curve-skeleton extraction via Laplacian-based contraction (Cao et al., 2010). 1
st
row,
Standing Bill. 2
nd
row, Nilin Combat. 3
rd
row, Iron Man. 1
st
and 4
th
col., Input dataset. 2
nd
and 5
th
col. Resulting
curve-skeleton using our approach. 3
nd
and 6
th
col. Resulting curve-skeleton using (Cao et al., 2010).
pose a very fast approach to estimate a coarse curve-
skeleton that will be the basis to fit a human model
skeleton. We plan to use a progressive fitting of the
skeleton model starting from the torso limb. In gen-
eral, the torso limb corresponds to the lowest-valued
edges from the Laplace operation output.
5 CONCLUDING REMARKS
A real-time approach to extract the curve-skeleton of
an upright human-scanned point cloud has been de-
scribed. Our main contribution is in estimating the
2-D skeleton candidates using image processing tech-
niques. By doing so, we address the real-time con-
straint. The final curve-skeleton results from locating
the previous computed 2-D skeleton candidates in the
3-D space. The resulting curve-skeleton preserves the
centeredness property as well as the same topology
and geometry as the 3-D model. Future work includes
the treatment of alternative body configurations than
upright. The use of temporal and RGB information
will be also investigated in order to increase the ro-
bustness of the approach.
ACKNOWLEDGEMENTS
This work was supported by the National Re-
search Fund, Luxembourg, under the CORE project
C11/BM/1204105/FAVE/Ottersten.
Real-timeCurve-skeletonExtractionofHuman-scannedPointClouds-ApplicationinUprightHumanPoseEstimation
59
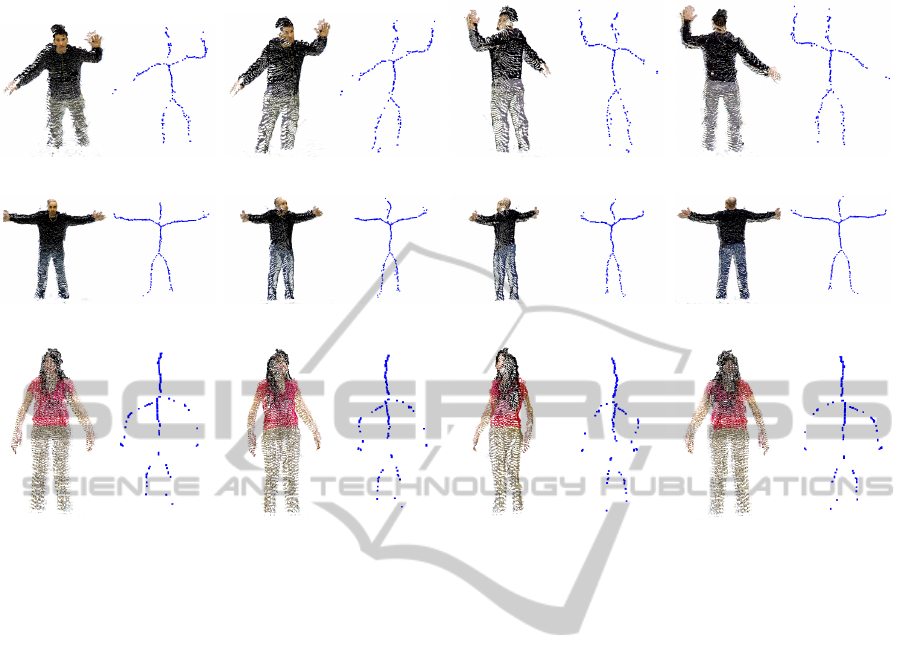
(a) (b) (c) (d)
(e) (f) (g) (h)
(i) (j) (k) (l)
Figure 8: Curve-skeleton extraction from upright human-scanned point clouds. 1
st
row, Man 1 (18053 points). 2
nd
row, Man 2
(21263 points). 3
rd
row, Woman 1 (12986 points).
REFERENCES
(2014). Point Cloud Library (PCL). http://pointclouds.org/.
(2014). TF3DM
TM
. http://tf3dm.com/.
(2014). Virtual robot experimentation platform (v-rep).
http://www.coppeliarobotics.com/.
Au, O. K.-C., Tai, C.-L., Chu, H.-K., Cohen-Or, D., and
Lee, T.-Y. (2008). Skeleton extraction by mesh con-
traction. In ACM SIGGRAPH 2008 Papers, pages
44:1–44:10. ACM.
Bradski, G. and Kaehler, A. (2008). Learning OpenCV:
Computer Vision with the OpenCV Library. O’Reilly
Media, 1st edition.
Cao, J., Tagliasacchi, A., Olson, M., Zhang, H., and Su, Z.
(2010). Point Cloud Skeletons via Laplacian Based
Contraction. In Shape Modeling International Con-
ference (SMI), pages 187–197.
Cornea, N., Silver, D., and Min, P. (2007). Curve-skeleton
properties, applications, and algorithms. IEEE Trans-
actions on Visualization and Computer Graphics,
13(3):530–548.
Felzenszwalb, P. F. and Huttenlocher, D. P. (2004). Dis-
tance transforms of sampled functions. Technical re-
port, Cornell Computing and Information Science.
Fitzgibbon, A. and Fisher, R. B. (1995). A buyer’s guide to
conic fitting. In In British Machine Vision Conference,
pages 513–522.
Garcia, F. and Ottersten, B. (2014). CPU-Based Real-Time
Surface and Solid Voxelization for Incomplete Point
Cloud. In IEEE International Conference on Pattern
Recognition (ICPR), pages 2757–2762.
Li, M., Yang, T., Xi, R., and Lin, Z. (2009). Silhouette-
based 2d human pose estimation. In International
Conference on Image and Graphics (ICIG), pages
143–148.
Sam, V., Kawata, H., and Kanai, T. (2012). A robust
and centered curve skeleton extraction from 3d point
cloud. Computer-Aided Design and Applications,
9(6):969–879.
Sezgin, M. and Sankur, B. (2004). Survey over image
thresholding techniques and quantitative performance
evaluation. Journal of Electronic Imaging, 13(1):146–
168.
Suzuki, S. and Abe, K. (1985). Topological structural anal-
ysis of digitized binary images by border following.
Computer Vision, Graphics, and Image Processing,
30(1):32–46.
Tagliasacchi, A., Zhang, H., and Cohen-Or, D. (2009).
Curve skeleton extraction from incomplete point
cloud. In ACM SIGGRAPH 2009 Papers, SIGGRAPH
’09, pages 71:1–71:9. ACM.
VISAPP2015-InternationalConferenceonComputerVisionTheoryandApplications
60
