Can Social Network Be Used for Location-aware Recommendation?
Pasi Fränti, Karol Waga and Chaitanya Khurana
School of Computing, University of Eastern Finland, Joensuu, Finland
Keywords: Social Network, Location-Aware Search, Recommendations, Personalization.
Abstract: Our goal is to give recommendations for mobile users about interesting places around his current location.
The only input is the user, location and time. In this work, we study whether the social network of the user
can be utilized for improving recommendations. We will answer the following two questions: (1) can we
measure user similarity based on their Facebook profile and location history, (2) do these imply usefulness
for the recommendations.
1 INTRODUCTION
Location-based services have become widely used
due to the fast development of positioning systems
in multimedia phones. We study recommendation
system for a mobile user who wants information
about nearby services such as shops and restaurants.
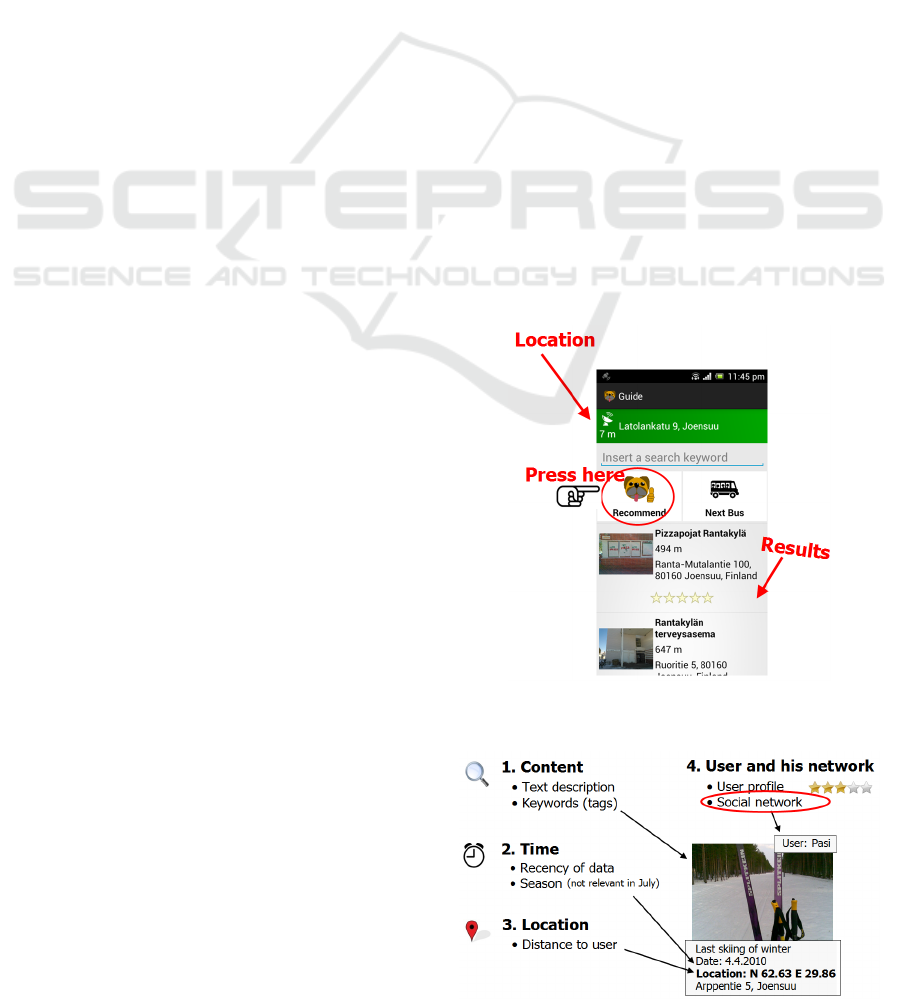
User can make a query specified by keyword(s), or
he can just ask general recommendation without any
keywords as input (see Fig. 1). In the latter case, the
relevance of a service must be determined merely by
other factors such as user location, time and personal
preferences. In (Fränti et al., 2011), relevance of a
recommendation was considered to consist of four
aspects:
Location
Time
Content
User and his/her network
Location is the key aspect but not the only one,
see Fig. 2. In (Waga et al., 2012), recommendations
were influenced by the overall search history by
giving higher rating for entries with popular
keywords in their title or tags, see Fig. 3. Extra
points were given to keywords that were used often,
used recently, or search in the nearby location of the
user. Keywords used by the user himself were also
given higher score. Recommended items were taken
both from Mopsi service directory, and from the
photo collections of the users.
In this work, we study whether a network of the
user can be used for improving recommendation.
Social knowledge was explored in (Bao et al., 2012)
by considering opinions of local experts in the given
area. This can be useful for improving rating of the
services by utilizing users whose opinions matter
most. User network can also become useful when
making recommendations, especially for the
Figure 1: Recommendation in Mopsi
(http://cs.uef.fi/mopsi).
Figure 2: Four aspect of relevance in geo-tagged photo.
558
Fränti P., Waga K. and Khurana C..
Can Social Network Be Used for Location-aware Recommendation?.
DOI: 10.5220/0005495805580565
In Proceedings of the 11th International Conference on Web Information Systems and Technologies (WEBIST-2015), pages 558-565
ISBN: 978-989-758-106-9
Copyright
c
2015 SCITEPRESS (Science and Technology Publications, Lda.)
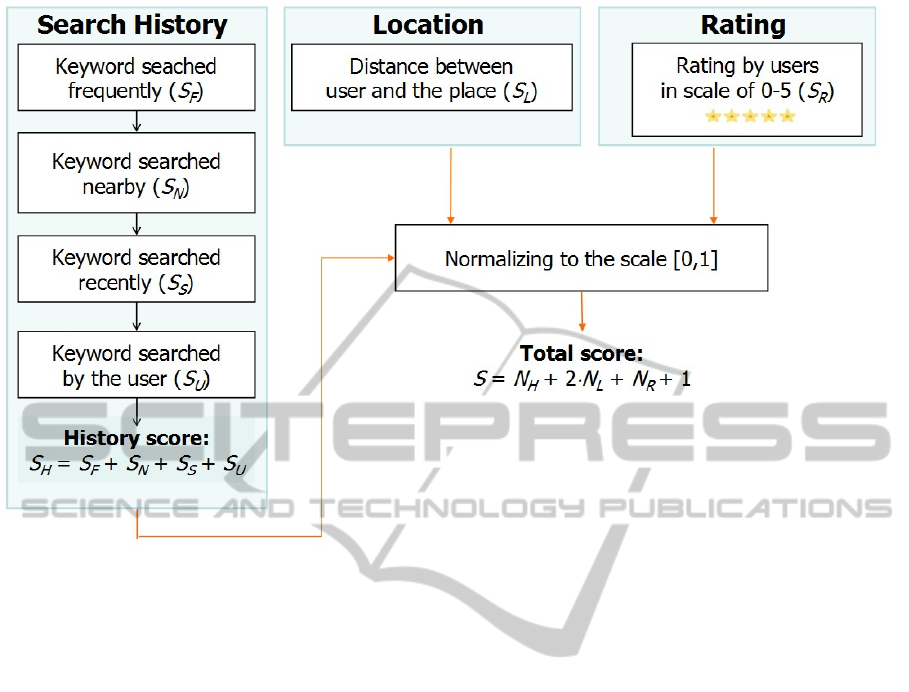
Figure 3: Scoring recommendations based on relevance to user.
so-called cold start users, from whom we have very
little or no previous history data. Profiles and
parameters used for their friends and similar users
can provide good initial guess for personalizing the
recommendations (Yang et al., 2012).
For utilizing the network, it is not clear what type
of network should be used, and how much a given
user should influence the recommendation for
another user. For this task, we study how similar two
users are when measured by the following features:
1. Friendship in Facebook
2. Pages liked in Facebook
3. Places visited in Mopsi
We perform qualitative experiment with a small
set of nine Mopsi users. We study the facebook
pages the users like, and the frequency of the places
they have visited in Joensuu. We study how much
the user similarity according to these features
correlate to the subjective opinions of the user
themselves, and also how they useful they rank the
recommendations of the other users in the location-
aware recommendation context.
The main findings are that the user similarity
correlates with all the features studied but not very
strongly. There is mild correlation with the user
locations (0.28) and the pages liked (0.47) but the
strongest correlation is with the facebook friendship.
In most cases, users ranked their facebook friends as
more similar than the others. However, when asked
how useful they would expect the data (photos in
Mopsi) of the other users, all the correlations
decreases and indicate that these features are not
easy to utilize on location-aware recommendation
system.
2 UTILIZING USER NETWORKS
So far, user networks have been the least utilized
aspect in Mopsi recommendations. The service is
public to entire world and there are no friend-to-
friend connections. Currently the only user network
implemented is the one suggested by clustering the
users according to their location, see Fig. 4. This can
be used to inform people who else is in the same
area. We next discuss possible types of network
from the following perspectives:
Social network vs. information sharing network
Buddy network vs. stranger network
Selected friends vs. automatic ad hoc network
On-line vs. offline network
For a more extensive taxonomy of social web
sites, see (Kima et al., 2010).
CanSocialNetworkBeUsedforLocation-awareRecommendation?
559

2.1 Effectiveness of the Network
By far the most widely used networks nowadays are
the social networks implemented by Facebook,
Twitter, Google+, Instagram and other similar
platforms where users explicitly specify with whom
they share their data. Social network has indeed very
strong influence whose data is more relevant to the
user but it is not the only possible network.
Users in general are more interested what their
friends are doing than other people in general.
However, in recommendation system, the relevance
of the information is more important than the social
aspect. In location-aware recommendation system,
users are seeking for information around his current
location. A user visiting the place often is therefore
more likely to have more relevant information than a
friend. In this view, we have more pragmatically
driven information sharing platform rather than
merely a social network.
Another aspect of social network is that how
well the people connected actually know each other.
According to the small-world phenomenon (Watts
and Strogatz, 1998), we can reach anyone in the
world by six steps, on average.
Figure 4: Example of clustering users according to their
location.
It was shown in (Barrat and Weigt, 2000) that even a
small amount of disorder (randomness) in the
network is able to trigger the small-world behaviour
even if the network was otherwise strongly
clustered. Therefore, the connectivity of the network
is not the bottleneck but the quality of the links is.
Network like Facebook is not really friend
network, but a term like buddy network would be
more appropriate. Due to social pressure, people
often try to be as connected as possible, which does
not really make sense from the efficiency point of
view. Having 400 Facebook friends does not imply
that the person has 400 real friends; a more likely
number would be about 10 or less. Nevertheless, the
people who are linked together know each other, and
the small-world phenomenon applies.
From information distribution point of view, the
relevance of the information sent via network is
affected by how many people we are connected to,
and how often we use these links. Instead of sharing
information via a large number of links, few strong
connections are likely to be more effective than a
large number of weaker links. The strength of the
connection is therefore more important than the
connection itself.
Contrary to social networks, strangers may also
be linked together because of sharing the same
interest. In cough surfing, people offer
accommodation to others without financial
compensation (Bolici, 2009). The key aspects in
such stranger network are the reputation and trust
between the users. In Mopsi, only information is
traded but in the same way, the reputation of the
author influences how trustworthy we consider
his/her data. Recommendations can be used to build
up the trust, and improve the quality of the
information.
2.2 Automatically Created Networks
For computer scientists, anything that can be
automated is always worth to consider. Users can be
linked based on their behaviour how they use the
service (Gratz and Botev, 2009), or simply
according to their location. In Mopsi, the location is
taken into account in the recommendation system
already, but the similarity of the users is not yet
utilized. In (Bacon and Dewan, 2009), similar users
are recommended to each other. Once there will be
enough users in the service, similarity can be used to
offer personalized search result.
A more ambitious ad hoc network is considered
in (Wu et al., 2009) using face analysis technique to
identify people in photos, and use this information to
create more complex social network automatically.
If more thorough content analysis could be
successfully done, people with the same hobbies
could be connected automatically.
Another approach is to combine location-based
service and social network from two independent
components as done in (Simon et al., 2009). One can
then focus on developing the location-based media
collection and service directory, and utilize existing
network for user identity and all the social
WEBIST2015-11thInternationalConferenceonWebInformationSystemsandTechnologies
560

networking functionalities that come along. In
Mopsi, we implemented login using Facebook
credentials, which allows users to share their Mopsi
data in Facebook: the system generates (optional)
status update to inform their network buddies as
shown in Fig. 5. Data is still stored also in Mopsi but
all the discussion happens in Facebook.
2.3 Behaviour in a Public Network
The nature of being an on-line or offline network
affects how people use it. In our case, the data
collection itself has online nature but since there is
no online conversation forum in Mopsi, the system
is more like offline by its nature.
Personality also affects how people use social
networks. Extravert personalities are more likely to
engage social activities but according to (Ross et al.,
2009), personality has much smaller effect than
expected on how they use Facebook. For example,
social person is likely to join more groups but it does
not reflect much on the size of the network, or how
extensively the communicative functions are used.
This can be partly explained by the fact that
Facebook is less widely used for on-line chatting
than other forums for live communication.
Figure 5: Facebook status update via Mopsi photo upload.
The level of neuroticism in personality, however,
affects on how much people preferred text (writing
on the wall) or sharing photos in Facebook. People
with higher sensitivity to threat use more textual
expression and less photo sharing because it was
more controllable due to its off-line nature Ross et
al., 2009). Another study showed that the identity
people present in their social network can differ a lot
from their real personalities. It was observed that the
image people gave was more real in off-line chatting
environment than in offline social network (Zhao et
al., 2008).
The privacy issue can also be important for
people who would want to use the service, but wish
not to reveal their identity or even location. Methods
have been developed specifically to prevent the
system to combine user’s identity and location
(Takabi et al., 2009), which actually contradicts our
goals of specifically sharing the user location. This
reflects the privacy concern, which the social
network and information sharing evidently weaken
if not adequately solved.
In Mopsi, the motivation is to encourage people
to share their information via their personal
collection, and use their network for the same. We
should encourage people to share as much
information as possible so that it would have high
coverage, but on the other hand, keep the quality of
the information trustworthy so that it would be
relevant and therefore useful to recommend to
others. Division of the service to two different
concepts – personal collection and service database
– aims at reaching both of the goals at the same
time. How to transfer data from the personal
collection to the open database is a point of further
development.
3 SIMILARITY OF USERS
We study next empirically the connections between
users in Facebook and in Mopsi. We selected nine
volunteers who work either in our lab or nearby (see
Table 1). They all live in Joensuu use both Mopsi
and Facebook, and know each other at some level.
Most of them are linked in Facebook as well. We
asked them to evaluate their relationship and rank
the other people from 1 to 8 using the following two
criteria:
Q1: How similar you find the person is to you?
Q2: How useful you find his/her Mopsi photos?
For the second question, context is that does he
recommend, via his/her Mopsi postings, useful and
interesting places to visit in future. The first question
was to measure similarity whereas the second tries
to explore whether the usefulness goes beyond
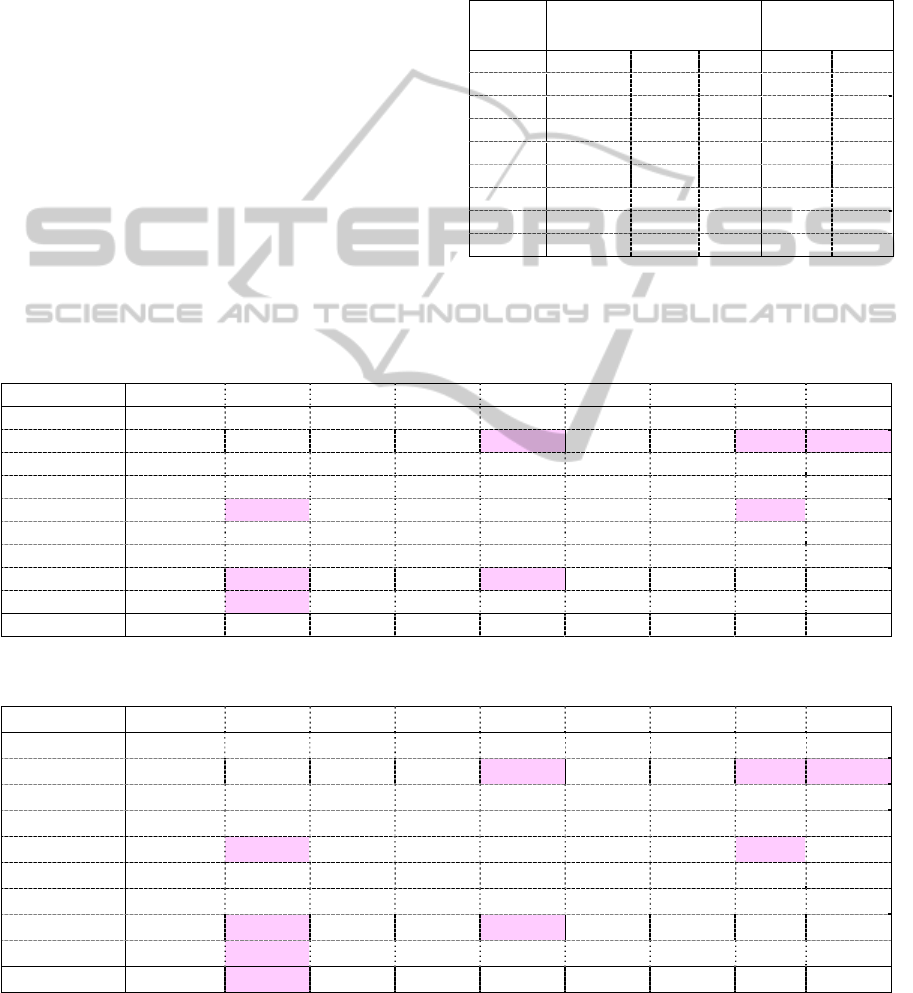
similarity and friendship. The resulting rankings are
shown in Tables 2 and 3. Pink background of a cell
is used to indicate that the users are not linked in
Facebook. As expected, if one considers the other
similar, they are also connected in Facebook. In this
regard, similarity and connection in social network
seems to correlate.
CanSocialNetworkBeUsedforLocation-awareRecommendation?
561
3.1 Analysis of the User Evaluations
Detailed inspection of the data reveals that the
similarity ranking is quite subjective. The sum
values show that certain people tend to be more
often “similar” than others. For example, Radu, Pasi
and Andrei have average rankings of 1.5, 2.8 and
3.0. In specific, Radu is the most similar for five
other users, and ranked 2
nd
or 3
rd
for the rest. By
common sense, everyone cannot be just like Radu,
but knowing him we conclude that most people
would not mind being like him. Further analysis of
the FB data (not included here) shows that the more
the photos and status updates of a particular user are
liked and commented, the more similar he/she is
considered.
The two rankings have reasonable high
correlation with each other (0.52) but there are few
differences. In the usefulness evaluation Pasi
becomes the highest ranked due to frequent
publishing of travel photos. Also Julinka’s photos
are considered more useful for the same reason.
Otherwise, the usefulness and similarity rankings are
quite similar. However, we asked how useful users
expect the data of their friends to be, but in fact, the
expectation may not match the reality. Some low
rankings might be biased towards low publication
activity rather than the usefulness of these photos.
Table 1: Volunteers participating in the experiment.
Mopsi Facebook
photos places visits friends pages
Andrei 676 96 676 463 285
Julinka 3850 122 2116 229 154
Mikko 190 84 292 55 14
Oili 6467 164 1261 298 63
Pasi 9716 208 3847 88 67
Radu 1417 122 912 298 19
Rezaei 716 85 587 193 16
Chait 63 22 53 580 195
Jukka 991 126 682 142 120
Table 2: User similarity based on their own view.
Andrei Julinka Mikko Oili Pasi Radu Rezaei Chait Jukka
Andrei - 7 8 4 2 1 3 6 5
Julinka 2 - 4 3 6 1 5 7 8
Mikko 7 8 - 5 1 2 4 6 3
Oili 3 5 7 - 2 1 4 8 6
Pasi 3 8 5 4 - 2 6 7 1
Radu 1 8 4 5 2 - 3 7 6
Rezaei 4 7 2 6 1 3 - 8 5
Chait 2 8 4 7 5 1 3 - 6
Jukka 2 7 5 4 3 1 8 6 -
Average: 3.0 7.3 4.9 4.8 2.8 1.5 4.5 6.9 5.0
Table 3: Expected usefulness of friend’s photos.
Andrei Julinka Mikko Oili Pasi Radu Rezaei Chait Jukka
Andrei
- 5 8 4 1 2 6 7 3
Julinka
2 - 6 3
4 1 5 7 8
Mikko
4 1 - 8 2 6 7 5 3
Oili
4 5 7 - 1 2 6 8 3
Pasi
2
7 1 4 - 5 8 6 3
Radu
2 5 7 4 1 - 6 8 3
Rezaei
6 2 7 3 1 5 - 8 4
Chait
3
7 8 4 2 1 6 - 5
Jukka
3
6 5 4 1 2 8 7 -
Average:
3.3 4.8 6.1 4.2 1.6 3.0 6.5 7.0 4.0
WEBIST2015-11thInternationalConferenceonWebInformationSystemsandTechnologies
562

3.2 Similarity in Page Liking
For testing the similarity of users, we compared how
many same Facebook pages the users liked. For
example, Mikko and Radu like four same pages
(Mopsi, Impit Finland, S+SSPR 2014 and East
Finland Graduate School of Computer Science &
Engineering), out of total 29 pages that either both
or one of them likes. Using these numbers, we
define their similarity by Jaccard coefficient as the
number of matches divided by the total number of
pages: 4/29 = 14%, see Figure 6.
The similarity values for the page likes are
shown in Table 3. As expected, lowest values are
typically among users who are not linked in
Facebook. The page liking correlates also reasonably
well (0.47) with the user similarity values (Table 2)
but the correlation with the usefulness values
(Table 3) is much smaller (0.17). Therefore, even if
user similarity could be estimated by their user
profiles in facebook, using it for location-aware
recommendation would still be questionable.
Figure 6: Sample similarity calculations of users based on
their likes in Facebook.
Table 4: Similarity values for Facebook page likings (%).
A J M O P Ra Re C JP
Andrei
- 3 2 3 5 2 2 3 2
Julinka
3 - 1 2
1 1 1 1 1
Mikko
2 1 - 7 6 25 16 3 5
Oili
3 2 7 - 8 6 6 3 4
Pasi
5
1 6 8 - 6 4 24
Radu
2 1 25 6 6 - 14 3 5
Rezaei
2 1 16 6 4 14 - 2 3
Chait
3
1 3 3 2 3 2 - 1
Jukka
2
1 5 4 4 5 3 1
-
Another issue is that liking exactly the same
page is not likely to happen in larger scale. For
example, if one person likes McDonalds and the
other one a local brand Hesburger, they are still
similar as they like fast food restaurants. We
considered counting matches of the categories the
pages belong to. Facebook has roughly 54 million
pages, which all belong to 107 predefined
categories. For example, McDonalds and Hesburger
are both in fast food category. The same Jaccard
measure can still be applied.
However, results using category matches show
even lower correlation because the categories are too
general. We therefore dropped this idea and use page
liking as such. Fig. 7 shows part of the similarity
graph for the set of test users.
3.3 Similarity in Location History
For studying location activity, we selected 293
places from Mopsi services as the visit places in
Joensuu. We recorded user activities until
31.12.2014 as follows: (1) places where they took
photos, (2) places where tracking a route was started
or ended. Each activity is counted as a visit to the
nearest place to the location of the activity. We used
only locations within the bounding box (28.65E,
63.44N, 31.58E, 62.25N) that roughly covers
Joensuu city and the rural areas of the municipality.
There are 10,426 visits in total. The number of visits
of each user is reported in Table 1.
Figure 7: Similarity graph constructed from the biggest
similarities in page likings.
The location data of a user forms a frequency
histogram consisting of 293 bins. The most popular
places with the corresponding visit frequencies are
listed in Fig. 8.
Location similarity of two users i and j are
calculated using Bhattacharyya distance between
their histograms:
⋅−=
jiB
ppD ln
CanSocialNetworkBeUsedforLocation-awareRecommendation?
563

AT C JP Jul M O P Ra Rez
Joensuun kirkko 1 3 9 572 3 19 24 1 7 639
Science Park 20 8 6 62 9 245 102 45 28 525
Joen TV-huolto J,Simanainen 0 1 1 388 0 1 3 0 2 396
Salomökki 1 41 2 62 0 3 69 106 15 15 313
Niinivaara otto3 183 0 4 17 1 19 72 8 4 308
keskusta 1 0 1 2 0 5 1 280 1 0 290
Lounasravintola Louhi 31 6 8 149 1 8 11 25 15 254
Lounasravintola Puisto 9 6 2 12 2 30 18 112 41 232
Kiesa 5 0 77 1 0 1 2 142 1 229
Noljakan kirkko 2 4 0 10 5 6 83 106 9 225
Figure 8: Most popular places and their corresponding visit frequencies.
Table 5: Location similarities.
A J M O P Ra Re C JP
Andrei
- 0,33 0,32 0,34 0,54 0,50 0,51 0,38 0,45
Julinka
0,33 - 0,29 0,45 0,52 0,40 0,40 0,46 0,35
Mikko
0,32 0,29 - 0,27 0,53 0,59 0,38 0,30 0,37
Oili
0,34 0,45 0,27 - 0,46 0,37 0,51 0,60 0,30
Pasi
0,54 0,52 0,53 0,46 - 0,68 0,68 0,52 0,54
Radu
0,50 0,40 0,59 0,37 0,68 - 0,58 0,45 0,65
Rezaei
0,51 0,40 0,38 0,51 0,68 0,58 - 0,53 0,56
Chait
0,38 0,46 0,30 0,60 0,52 0,45 0,53 - 0,42
Jukka
0,45 0,35 0,37 0,30 0,54 0,65 0,56 0,42 -
where the summation is done over all the 293
entries, and p
i
, p
j
are the relative frequencies of the
given place. For example, Andrei has frequency
183/676 = 0.19 for the Niinivaara Otto 3, which is
an ATM machine near to his home. Other similar
visits happens near the users’ homes (Julinka used to
live opposite to Joensuu kirkko), or working place
(everyone except JP works in Science Park).
The similarity results are summarized in Table 4.
Only mild correlation (0.28) is recognized with the
similarity of the users based on their personal views
and their location history, and even smaller with the
usefulness measure (0.17). Open question is how
much the choice of the methodology influences the
results, and if some choices made there could be
changed. For example, the number of places and
how they are chosen. High frequencies of the home
and work places of the users had also a relative large
effect: not living or visiting the same area might
significantly decrease the similarity of such user.
Nevertheless, the results indicate that the
location history has relatively small impact on user
similarity and it is not clear how they could be used
on improving recommendations.
4 CONCLUSIONS
Small-scale study was made with nine Mopsi and
Facebook users to find out whether user similarity
and their expected usefulness for recommendation
could be predicted from Facebook profile and
location history. Based on the results we observed
that matching page likes in Facebook correlated with
user similarity whereas the location history had only
mild correlation. Neither of these statistics predicts
which user’s data is expected to be most useful.
However, we also noticed that if a user gives
many likes and comments of the photos of another
user, then he considers this user more similar than
WEBIST2015-11thInternationalConferenceonWebInformationSystemsandTechnologies
564

others; and what’s more important, consider his data
more useful for location-aware recommendation. We
therefore conclude that, yes, social network can be
used for improving recommendations, but not with
the data (page likes and location history) in the way
studied in this work.
Nevertheless, the results showed correlations and
revealed potentially useful factors indicating user
similarity. These findings should be confirmed by
large-scale testing. We also plan to make similar
study using likes and comments, which have been
applied for recommending events and friends in (De
Pessemier et al, 2013).
REFERENCES
J. Bao, Y. Zheng, M.F. Mokbel, “Location-based and
preference-aware recommendation using sparse geo-
social networking data”, Int. Conf. on Advances in
Geographic Information Systems (SIGSPATIAL),
199-208, Redondo Beach, CA, 2012.
K. Bacon, P. Dewan, “Towards automatic recommenda-
tion of friend lists”, CollaborateCOM, Crystal City,
Washington DC, Nov 2009.
A. Barrat and M. Weigt, “On the properties of small-world
network models”, Eur.Phys.J. B, 13, 547-560, 2000.
F. Bolici, “No hotel in D.C.”, CollaborateCOM, Crystal
City, Washington DC, Nov 2009.
T. De Pessemier, J.Minnaert, K. Vanhecke, S. Dooms,
L. Martens, “Social Recommendations for Events”,
ACM Conf. on Recommender Systems, Hong Kong,
China, October 2013.
P. Fränti, J. Chen and A. Tabarcea, "Four aspects of
relevance in location-based media: content, time,
location and network", Int. Conf. on Web Information
Systems & Technologies (WEBIST'11),
Noordwijkerhout, Netherlands, 413-417, May 2011.
P. Gratz, J. Botev, “Collaborative filtering via epidemic
aggregation in distributed virtual environments”
Collaborate COM, Crystal City, Washington DC, Nov
2009.
C.J. Hutto, S. Yardi, E. Gilbert, ”A longitudinal study of
follow predictors on twitter”,SIGCHI Conf. on Human
Factors in Computing Systems (CHI’13), 821-830,
2013.
W. Kima, O.-R. Jeong, S.-W. Lee, “On social web sites”,
Information Systems, 35, 215-236, 2010.
C. Ross, E. S. Orr, M. Sisic, J. M. Arseneault, M. G.
Simmering, R. R. Orr, “Personality and motivations
associated with Facebook use”, Computers in Human
Behavior, 25, 578-586, 2009.
J.R. Simon, D.R. Gonzalez, C.F. Grande, C.E. Gomez,
A.P. de la Llave, F.O. Lacalle, K.D.R. Permingeat,
“NEMOS: Working towards the ‘social’ mobile
phone”, ICME 2009, 1784-1788, New York City, July
2009.
H. Takabi, J.B.D. Joshi, H.A. Karimi, “A collaborative k-
anonymity approach for location privacy in location-
based services”, CollaborateCOM, Crystal City,
Washington DC, Nov 2009.
K. Waga, A. Tabarcea and P. Fränti, "Recommendation of
points of interest from user generated data collection",
IEEE Int. Conf. on Collaborative Computing:
Networking, Applications and Worksharing
(CollaborateCom), Pittsburgh, USA, 2012.
D. Watts and S. Strogatz, “Collective dynamics of 'small-
world' Networks”, Nature, 393, 440-442, 1998.
P. Wu, W. Ding, Z. Mao, D. Tretter, “Close & closer:
“Discover social relationship from photo collections”,
ICME 2009, 1652-1655, New York City, July 2009.
X. Yang, H. Steck, Y. Guo, Y. Liu, “On Top-k
Recommendation using Social Networks”, ACM
Conf. on Recommender Systems, Dublin, Ireland, 67-
74, Sept. 2012.
S. Zhao, S. Grasmuck, J. Martin, “Identity construction on
Facebook: Digital empowerment in anchored
relationships”, Computers in Human Behavior, 24,
1816-1836, 2008.
CanSocialNetworkBeUsedforLocation-awareRecommendation?
565
