Temporal-based Feature Selection and Transfer Learning for
Text Categorization
Fumiyo Fukumoto and Yoshimi Suzuki
Graduate Faculty of Interdisciplinary Research, University of Yamanashi, Kofu, Japan
Keywords:
Feature Selection, Latent Dirichlet Allocation, Temporal-based Features, Text Categorization, Timeline
Adaptation, Transfer Learning.
Abstract:
This paper addresses text categorization problem that training data may derive from a different time period
from the test data. We present a method for text categorization that minimizes the impact of temporal ef-
fects. Like much previous work on text categorization, we used feature selection. We selected two types of
informative terms according to corpus statistics. One is temporal independent terms that are salient across
full temporal range of training documents. Another is temporal dependent terms which are important for a
specific time period. For the training documents represented by independent/dependent terms, we applied
boosting based transfer learning to learn accurate model for timeline adaptation. The results using Japanese
data showed that the method was comparable to the current state-of-the-art biased-SVM method, as the macro-
averaged F-score obtained by our method was 0.688 and that of biased-SVM was 0.671. Moreover, we found
that the method is effective, especially when the creation time period of the test data differs greatly from that
of the training data.
1 INTRODUCTION
Text categorization supports to improve many tasks
such as automatic topic tagging, building topic direc-
tory, spam filtering, creating digital libraries, senti-
ment analysis in user reviews, information retrieval,
and even helping users to interact with search engines
(Mourao et al., 2008). A growing number of machine
learning (ML) techniques have been applied to the
text categorization task (Xue et al., 2008; Gopal and
Yang, 2010). For reasons of both efficiency and ac-
curacy, feature selection is often used since the early
1990s when applying machine learning methods to
text categorization (Lewis and Ringuette, 1994; Yang
and Pedersen, 1997; Dumais and Chen, 2000). Each
document is represented using a vector of selected
features/terms (Yang and Pedersen, 1997; Hassan
et al., 2007). Then, the documents with category label
are used to train classifiers. Once category models are
trained, each test document is classified by using these
models. A basic assumption in the categorization task
is that the distributions of terms between training and
test documents are identical. When the assumption is
not hold, the classification accuracy was worse. How-
ever, it is often the case that the term distribution in
the training data is different from that of the test data
when the training data may drive from a different time
period from the test data. For instance, the term “Al-
cindo” frequently appeared in the documents tagged
“Sports” category in 1994. This is reasonable because
Alcindo is a Brazilian soccer player and he was one
of the most loved players in 1994. However, the term
did not occur in more frequently in the Sports cate-
gory since he retired in 1997. The observation show
that the informativeterm appeared in the training data,
is not informative in the test data when training data
may derive from a different time period from the test
data, e.g., in the above example, the term “Alcindo”
is informative in the training data with Sports cate-
gory collected from 1994, but not informative in the
test data from other years, e.g., 2005 which should be
classified into the Sports category. Moreover, man-
ual annotation of tagged new data is very expensive
and time-consuming. The methodology for accurate
classification of the new test data by making the max-
imum use of tagged old data is needed in both feature
selection and learning techniques.
In this paper, we present a method for text cate-
gorization that minimizes the impact of temporal ef-
fects. We selected two types of salient terms by us-
ing a simple feature selection technique, χ
2
statistics.
One is temporal independent terms that are salient
Fukumoto, F. and Suzuki, Y..
Temporal-based Feature Selection and Transfer Learning for Text Categorization.
In Proceedings of the 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2015) - Volume 1: KDIR, pages 17-26
ISBN: 978-989-758-158-8
Copyright
c
2015 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
17

across full temporal range of training documents such
as “baseball” and “tennis” in the Sports category. An-
other is temporal dependent terms that are salient for
a specific time period such as “Alcindo” in the Sports
category in 1994 mentioned in the above example.
Hereafter, we call it temporal-based feature selec-
tion (TbFS). As the result of TbFS, each document
is represented by using a vector of the selected inde-
pendent/dependent terms, and classifiers are trained.
We applied boosting based transfer learning, called
TrAdaboost (Dai et al., 2007) in order to minimize
the impact of temporal effects. Hereafter, we call it
temporal-based transfer learning, TbTL. The idea is
to use TrAdaboost to decrease the weights of training
instances that are very different from the test data.
The rest of the paper is organized as follows. The
next section describes an overview of existing related
work. Section 3 presents our approach, especially
describes how to adjust temporal difference between
training and test documents. Finally, we report some
experiments with a discussion of evaluation.
2 RELATED WORK
The analysis of temporal aspects is a practical prob-
lem as well as the process of large-scale heteroge-
neous data since the World-Wide Web (WWW) is
widely used by various sorts of people. It is widely
studied in many text processing tasks. One attempt
is concept or topic drift dealing with temporal ef-
fects (Kleinberg, 2002; Lazarescu et al., 2004; Folino
et al., 2007). The earliest known approach is the
work of (Klinkenberg and Joachims, 2000). They
presented a method to handle concept changes with
SVMs. They used ξα-estimates to select the win-
dow size so that the estimated generalization error
on new examples is minimized. The results which
were tested on the TREC show that the algorithm
achieves a low error rate and selects appropriate win-
dow sizes. Wang et al. developed the continu-
ous time dynamic topic model (cDTM) (Wang et al.,
2008). The cDTM is an extension of the discrete dy-
namic topic model (dDTM). The dDTM is a pow-
erful model. However, the choice of discretization
affects the memory requirements and computational
complexity of posterior inference. cDTM replaces the
discrete state space model with its continuous gen-
eralization, Brownian motion. He et al. proposed a
method to find bursts, periods of elevated occurrence
of events as a dynamic phenomenon instead of focus-
ing on arrival rates (He and Parker, 2010). They used
Moving Average Convergence/Divergence (MACD)
histogram which was used in technical stock market
analysis (Murphy, 1999) to detect bursts. They tested
the method using MeSH terms and reported that the
model works well for tracking topic bursts. He et al.
bursts model can be regarded as salient features/terms
identification for a specific time period, although their
method can not extract such terms automatically, i.e.
it is necessary to give these terms in advance as the
input of their model.
Another attempt is domain adaptation. The goal
of this attempt is to develop learning algorithms that
can be easily ported from one domain to another,
e.g., from newswire to biomedical documents (III,
2007). Domain adaptation is particularly interest-
ing in Natural Language Processing (NLP) because
it is often the case that we have a collection of la-
beled data in one domain but truly desire a model that
can work well for another domain. Lots of studies
addressed domain adaptation in NLP tasks such as
part-of-speech tagging (Siao and Guo, 2013), named-
entity (III, 2007), and sentiment classification (Glorot
et al., 2011) are presented. One approach to domain
adaptation is to use transfer learning. The transfer
learning is a learning technique that retains and ap-
plies the knowledge learned in one or more tasks to
efficiently develop an effective hypothesis for a new
task. The earliest discussion is done by ML com-
munity in a NIPS-95 workshop
1
, and more recently,
transfer learning techniques have been successfully
applied in many applications. Blitzer et al. proposed
a method for sentiment classification using structual
correspondence learning that makes use of the un-
labeled data from the target domain to extract some
relevant features that may reduce the difference be-
tween the domains (Blitzer et al., 2006). Several au-
thors have attempted to learn classifiers across do-
mains using transfer learning in the text classification
task (Raina et al., 2006; Dai et al., 2007; Sparinna-
pakorn and Kubat, 2007). Raina et al. proposed a
transfer learning algorithm that constructs an infor-
mative Baysian prior for a given text classification
task (Raina et al., 2006). The prior encodes useful
domain knowledge by capturing underlying depen-
dencies between the parameters. They reported that
a 20 to 40% test error reduction over a commonly
used prior in the binary text classification task. All
of these approaches mentioned above aimed at utiliz-
ing a small amount of newly labeled data to leverage
the old data to construct a high-quality classification
model for the new data. However, the temporal effects
are not explicitly incorporated into their models.
To our knowledge, there have been only a few
previous works on temporal-based text categorization
1
http://socrates.acadiau.ca/courses/comp/dsilver/
NIPS95 LTL/transfer.workshop.1995.html.
KDIR 2015 - 7th International Conference on Knowledge Discovery and Information Retrieval
18

(Kerner et al., 2008; Song et al., 2014). Mourao et
al. investigated the impact of temporal evolution of
document collections based on three factors: (i) the
class distribution, (ii) the term distribution, and (iii)
the class similarity. They reported that these factors
have great influence in the performance of the clas-
sifiers throughout the ACM-DL and Medline docu-
ment collections that span across more than 20 years
(Mourao et al., 2008). Salles et al. presented an ap-
proach to classify documents in scenarios where the
method uses information about both the past and the
future, and this information may change over time
(Salles et al., 2010). They address the drawbacks of
which instances to select by approximating the Tem-
poral Weighting Function (TWF) using a mixture of
two Gaussians. They applied TWF to every training
document. However, it is often the case that terms
with informative for a specific time period and in-
formative across the full temporal range of training
documents are both included in the training data that
affects overall performance of text categorization as
these terms are equally weighted in their approach.
Moreover, their method needs tagged training data
across full temporal range of training documents to
create TWF.
There are three novel aspects in our method.
Firstly, we propose a method for text categorization
that minimizes the impact of temporal effects in both
feature selection and learning techniques. Secondly,
from manual annotation of data perspective, we pro-
pose a temporal-based classification method using
only a limited number of labeled training data. Fi-
nally, from the perspective of robustness, the method
is automated, and can be applied easily to a new do-
main, or different languages, given sufficient unla-
beled documents.
3 SYSTEM DESIGN
The method consists of three steps: (1) Collection
of documents by Latent Dirichlet Allocation (LDA),
(2) Temporal-based feature selection (TbFS), and (3)
Document categorization by temporal-based transfer
learning (TbTL).
3.1 Collection of Documents by LDA
The selection of temporal independent/dependent
terms is done using documents with categories. How-
ever, manual annotation of categories are very ex-
pensive and time-consuming. Therefore, we used a
topic model and classified unlabeled documents into
categories. Topic models such as probabilistic latent
semantic indexing (Hofmann, 1999) and LDA (Blei
et al., 2003) are based on the idea that documents are
mixtures of topics, where each topic is captured by a
distribution over words. The topic probabilities pro-
vide an explicit low-dimensional representation of a
document. They have been successfully used in many
tasks such as text modeling and collaborative filtering
(Li et al., 2013). We classified documents into cat-
egories using LDA. The generative process for LDA
can be described as follows:
1. For each topic k = 1, ···, K, generate φ
k
, multi-
nomial distribution of terms specific to the topic k
from a Dirichlet distribution with parameter β;
2. For each document d = 1, · ··, D, generate θ
d
,
multinomial distribution of topics specific to the
document d from a Dirichlet distribution with pa-
rameter α;
3. For each term n = 1, ··· , N
d
in document d;
(a) Generate a topic z
dn
of the n
th
term in the doc-
ument d from the multinomial distribution θ
d
(b) Generate a term w
dn
, the term associated with
the n
th
term in document d from multinomial
φ
zdn
Like much previous work on LDA, we used Gibbs
sampling to estimate φ and θ. The sampling probabil-
ity for topic z
i
in document d is given by:
P(z
i
| z
\i
,W) =
(n
v
\i, j
+ β)(n
d
\i, j
+ α)
(n
·
\i, j
+Wβ)(n
d
\i,·
+ Tα)
. (1)
z
\i
refers to a topic set Z, not including the current as-
signment z
i
. n
v
\i, j
is the frequency of term v in topic
j that does not include the current assignment z
i
, and
n
·
\i, j
indicates a summation over that dimension. W
refers to a set of documents, and T denotes the total
number of unique topics. After a sufficient number
of sampling iterations, the approximated posterior can
be used to estimate φ and θ by examining the frequen-
cies of term assignments to topics and topic occur-
rences in documents. The approximated probability
of topic k in the document d,
ˆ
θ
k
d
, and the assignments
term w to topic k,
ˆ
φ
w
k
are given by:
ˆ
θ
k
d
=
N
dk
+ α
N
d
+ αK
. (2)
ˆ
φ
w
k
=
N
kw
+ β
N
k
+ βV
. (3)
For each year, we applied LDA to a set of doc-
uments where a set consists of a small number of
Temporal-based Feature Selection and Transfer Learning for Text Categorization
19

labeled documents and a large number of unlabeled
documents. We need to estimate two parameters for
the results obtained by LDA, i.e. one is the number
of topics/classes k, and another is the number of doc-
uments d for each topic/class. We note that the result
can be regarded as a clustering result: each element
of the clusters is a document assigned to a category
or a document without a category information. We
estimated the numbers of topics and documents using
Entropy measure given by:
E = −
1
logk
∑
j
N
j
N
∑
i
P(A
i
,C
j
)logP(A
i
,C
j
). (4)
k refers to the number of clusters. P(A
i
,C
j
) is a prob-
ability that the elements of the cluster C
j
assigned to
the correct class A
i
. N denotes the total number of
elements and N
j
shows the total number of elements
assigned to the clusterC
j
. The value of E ranges from
0 to 1, and the smaller value of E indicates better re-
sult. We chose the parameters k and d whose value
of E is smallest. For each cluster, count the numbers
for each category, and assigned the maximum num-
ber of category to each document in the cluster. If
there are more than two categories with the maximum
numbers, we assigned all of these categories to each
document in the cluster.
3.2 Temporal-based Feature Selection
The second step is to select a set of indepen-
dent/dependent terms from the training data obtained
by the first step, collection of documents by LDA.
The selection is based on the use of feature selec-
tion technique. We tested different feature selection
techniques, χ
2
statistics, mutual information, and in-
formation gain (Yang and Pedersen, 1997; Forman,
2003). In this paper, we report only χ
2
statistics that
optimized global F-score in classification. χ
2
is given
by:
χ
2
(t,C) =
n× (ad − bc)
2
(a+ c) × (b+ d) × (a+ b)× (c+ d)
. (5)
Using the two-way contingency table of a term t and
a category C, a is the number of documents of C con-
taining the term t, b is the number of documents of
other class (not C) containing t, c is the number of
documents of C not containing the term t, and d is the
number of documents of other class not containing t.
n is the total number of documents.
We applied χ
2
statistics in two ways. The first way
is to extract independent terms that are salient across
the full temporal range of training documents. For
each category C
i
(1 < i ≤ s), where s is the number of
categories, we collected all documents with the same
category across the full temporal range, and created a
set. The number of sets equals to the number of cat-
egories, s. The second way is to extract dependent
terms that are salient for a specific time period. It is
applied to the sets of documents with different years
in the same category. For a specific category C
i
, we
collected all documents within the same year, and cre-
ated a set. Thus, the number of sets equals to the num-
ber of different years in the training documents. We
selected terms whose χ
2
value is larger than a certain
threshold value and regarded these terms as indepen-
dent/dependent terms.
3.3 Document Categorization
So far, we made use of the maximum amount of
tagged old data in feature selection. The final step
is document categorization by TbTL. We trained the
model and classified documents based on TrAdaBoost
(Dai et al., 2007). TrAdaBoost extends AdaBoost
(Freund and Schapire, 1997) which aims to boost the
accuracy of a weak learner by adjusting the weights
of training instances and learn a classifier accord-
ingly. TrAdaBoost uses two types of training data.
One is so-called same-distribution training data that
has the same distribution as the test data. In general,
the quantity of these data is often limited. In con-
trast, another data so-called diff-distribution training
data whose distribution may differ from the test data
is abundant. The TrAdaBoost aims at utilizing the
diff-distribution training data to make up the deficit
of a small amount of the same-distribution to con-
struct a high-quality classification model for the test
data. TrAdaBoost is the same behavior as boosting
for same-distribution training data. The difference is
that for diff-distribution training instances, when they
are wrongly predicted, we assume that these instances
do not contribute to the accurate test data classifi-
cation, and the weights of these instances decrease
in order to weaken their impacts. Dai et al. ap-
plied TrAdaBoost to three text data, 20 Newsgroups,
SRZZ, Reuters-21578 which have hierarchical struc-
tures. They split the data to generate diff-distribution
and same-distribution sets which contain data in dif-
ferent subcategories. Our temporal-based transfer
learning, TbTL is based on the TrAdaboost. The dif-
ference between TbTL and TrAdaBoost presented by
Dai et al. is that the initialization step and output the
final hypothesis. The initialization step is to remove
outliers. The outliers (training instances) are often in-
cluded in the diff-distribution data itself, especially if
KDIR 2015 - 7th International Conference on Knowledge Discovery and Information Retrieval
20
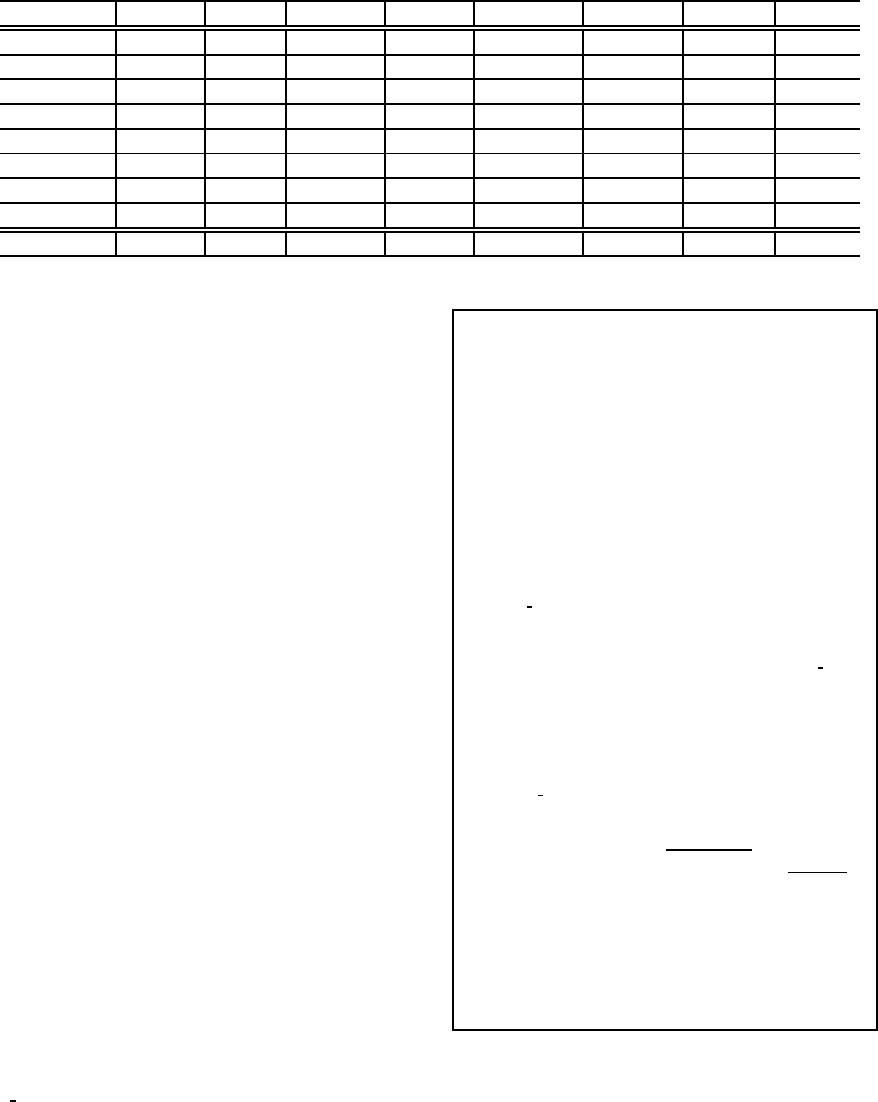
Table 1: Categorization Results (Mainichi data).
Cat SVM/wo SVM/w bSVM/wo bSVM/w TrAdaB/wo TrAdaB/w TbTL/wo TbTL/w
International 0.543∗ 0.582∗ 0.546∗ 0.682∗ 0.667∗ 0.682∗ 0.675∗ 0.693
Economy 0.564∗ 0.594∗ 0.699∗ 0.702∗ 0.665∗ 0.702∗ 0.672∗ 0.712
Home 0.432∗ 0.502∗ 0.449∗ 0.692∗ 0.660∗ 0.703∗ 0.664∗ 0.720
Culture 0.082∗ 0.102∗ 0.158∗ 0.301∗ 0.459∗ 0.493 0.402∗ 0.482
Reading 0.468∗ 0.489∗ 0.563∗ 0.571∗ 0.662∗ 0.697 0.530∗ 0.682
Arts 0.353∗ 0.372∗ 0.387∗ 0.652∗ 0.656∗ 0.663∗ 0.664∗ 0.693
Sports 0.773∗ 0.782∗ 0.792∗ 0.802 0.657∗ 0.730 0.675∗ 0.810
Local news 0.623∗ 0.644∗ 0.643∗ 0.702 0.660∗ 0.700 0.667∗ 0.710
Macro Avg. 0.480∗ 0.508∗ 0.530∗ 0.638∗ 0.636∗ 0.671∗ 0.619∗ 0.688
∗ denotes that TbTL/w is statistical significance t-test compared with the ∗ marked method, P-value ≤ 0.05
there are a large amount of diff-distribution data. As
a result, they affect overall performance of classifi-
cation. We removed these outliers in the initializa-
tion step. The second difference is the output the final
hypothesis. We empirically tested Output by both of
the TrAdaBoost proposed by Dai et al. (Dai et al.,
2007) and AdaBoost (Freund and Schapire, 1997),
and choose AdaBoost’s Output i.e. a hypothesis h
t
is created at each round by linearly combining the
weak hypotheses constructed so far h
1
, · ··, h
N
with
weights β
1
, · ··, β
N
as it was better to the result ob-
tained by TrAdaBoost, i.e. the hypothesis h
t
from the
⌈N/2 ⌉
th
iteration to the N
th
is voted in the experi-
ments. The temporal-based transfer learning, TbTL
based on TrAdaBoost is illustrated in Figure 1.
Tr
d
shows the diff-distribution training data that
Tr
d
= {(x
d
i
, c(x
d
i
))}, where x
d
i
∈ X
d
(i = 1, ···, n),
and X
d
refers to the diff-distribution instance space.
Similarly, Tr
s
represents the same-distribution train-
ing data that Tr
s
= {(x
s
i
, c(x
s
i
))}, where x
s
i
∈ X
s
(i = 1,
·· · , m), and X
s
refers to the same-distribution instance
space. n and m are the number of documents in T
d
and
T
s
, respectively. c(x) returns a label for the input in-
stance x. The combined training set T = {(x
i
,c(x
i
))}
is given by:
x
i
=
x
d
i
i = 1, ··· ,n
x
s
i
i = n+ 1, ··· ,n+ m
Steps 2, 3, and 4 of Initialization in Figure 1 are
the extraction of outliers that are different term dis-
tribution among diff-distribution training data. We
removed these training data from the original diff-
distribution training data Tr
d
, and used the remains
Tr
d
new
as in the input of TrAdaBoost. n
′
of TrAd-
aBoost in Figure 1 refers to the number of the remain-
ing diff-distribution training documents.
We used the Support Vector Machines (SVM) as
a learner. We represented each training and test doc-
ument as a vector, each dimension of a vector is an
Input {
The diff-distribution data Tr
d
, the same-distribution
data Tr
s
, and the maximum number of iterations N.
}
Output {
h
f
(x) =
∑
N
t=1
β
t
h
t
(x
i
).
}
Initialization {
1. w
1
= 1/n.
2. Train a weak learner on the training set Tr
d
, and cre-
ate weak hypothesis h
0
: X → Y
3. Classify Tr
d
by h
0
4. Create a new diff-distribution training data set
Tr
d
new
where each element x
i
satisfies
∑
n
i=1
|h
0
(x
i
) − c(x
i
) | = 0.
5. w
1
= 1/(n
′
+ m).
// n
′
refers to the number of documents in Tr
d
new
.
}
TrAdaBoost {
For t = 1,··· ,N
1. Set P
t
= w
t
/ (
∑
n
′
+m
i=1
w
t
i
).
2. Train a weak learner on the combined training set
Tr
d
new
and Tr
s
with the distribution P
t
, and create
weak hypothesis h
t
: X → Y
3. Calculate the error of h
t
on Tr
s
:
ε
t
=
∑
n
′
+m
i=n
′
+1
w
t
i
·|h
t
(x
i
)−c(x
i
)|
∑
n
′
+m
i=n
′
+1
w
t
i
.
4. Set β
t
= ε
t
/ (1− ε
t
) and β = 1/(1+
p
2lnn
′
/N).
5. Update the new weight vector:
w
t+1
i
=
w
t
i
β
|h
t
(x
i
)−c(x
i
)|
, 1 ≤ i ≤ n
′
w
t
i
β
−|h
t
(x
i
)−c(x
i
)|
t
n
′
+ 1 ≤ i ≤ n
′
+ m
}
Figure 1: Flow of the algorithm.
independent/dependent term appeared in the docu-
ment, and each element of the dimension is a term
frequency. We applied the algorithm shown in Figure
1. After several iterations, a learner model is created
by linearly combining weak learners, and a test docu-
ment is classified using a learner.
Temporal-based Feature Selection and Transfer Learning for Text Categorization
21

4 EXPERIMENTS
We evaluated our temporal-based term selection and
learning techniques by using the Mainichi Japanese
newspaper documents.
4.1 Experimental Setup
We used the Mainichi Japanese newspaper corpus
from 1991 to 2012. The corpus consists of 2,883,623
documents organized into 16 categories. We selected
8 categories, “International”, “Economy”, “Home”,
“Culture”, “Reading”, “Arts”, “Sports”, and “Local
news”, each of which has sufficient number of docu-
ments. Table 2 shows statistics of the dataset.
Table 2: The data used in the experiments.
Cat Docs Cat Docs
International 91,882 Reading 17,418
Economy 96,745 Arts 29,645
Home 47,984 Sports 183,216
Culture 20,428 Local news 282,829
All documents were tagged by using a morpho-
logical analyzer Chasen (Matsumoto et al., 2000).
We used noun words as independent/dependent term
selection. The total number of documents assigned
to these categories are 770,147. For each category
within each year, we divided documents into three
folds: 10% of documents are used as labeled train-
ing data, 50% of documents are unlabeled training
data, and 40% of documents are used to test our clas-
sification method. For each year, we classified un-
labeled data into categories using labeled data with
LDA. We empirically selected values of two param-
eters, the number of classes k, and documents d, re-
spectively. k is searched in steps of 10 from 10 to 200,
and d is searched in steps of 100 from 100 to 500. As
a result, for each year, we set k and d to 20, and 700,
respectively.
We divided original labeled training data and la-
beled data obtained by LDA into five folds for each
year. The first three folds are used in the TbFS, i.e.
we calculated χ
2
statistics using the first fold, and the
second fold is used as a training data and the third fold
is used as a test data to estimate the numbers of inde-
pendent/dependent terms. The estimation was done
by using F-score. As a result of estimation, we used
35,000 independent terms for each of the 8 categories,
and 12,000 dependent terms for each of the 8 cate-
gories in each year. The last two folds are used to
train TbTL. For each category, we used 50 documents
as the same-distribution data. When the time differ-
ence between training and test data is more than one
year, we used the remains as diff-distribution data
2
.
We used SVM-light (Joachims, 1998) as a ba-
sic learner in the experiments. We compared our
method, TbTL with TbFS (TbTL/w) with seven
baselines: (1) SVM without TbFS (SVM/wo), (2)
SVM with TbFS (SVM/w), (3) biased-SVM (Liu
et al., 2003) without TbFS (bSVM/wo), (4) biased-
SVM with TbFS (bSVM/w)), (5) TrAdaBoost with-
out TbFS (TrAdaB/wo), (6) TrAdaBoost with TbFS
(TrAdaB/w), and (7) TbTL without TbFS (TbTL/wo).
The methods without TbFS, i.e. (1), (3), (5), and (7),
we used all noun words in the documents.
TrAdaBoost refers to the results obtained by orig-
inal TrAdaBoost presented by Dai et al. Biased-SVM
is known as the state-of-the-art SVMs method, and
often used for comparison (Elkan and Noto, 2008).
Similar to the SVM, for biased-SVM, we used the last
two folds as a training data, and classified test docu-
ments directly, i.e. we used closed data. We empiri-
cally selected values of two parameters, “c” (trade-off
between training error and margin) and “j”, i.e. cost
(cost-factor, by which training errors on positive ex-
amples) that optimized F-score obtained by classifi-
cation of test documents. “c” is searched in steps of
0.02 from 0.01 to 0.61. Similarly, “j” is searched in
steps of 5 from 1 to 200. As a result, we set c and j to
0.03 and 4, respectively. To make comparisons fair,
all eight methods including our method are based on
linear kernel. Throughout the experiments, the num-
ber of iterations is set to 30.
4.1.1 Results
Categorization results for 8 categories(40% of the test
documents, i.e. 308,058 documents) are shown in Ta-
ble 1. Each value in Table 1 shows macro-averaged F-
score across 22 years. “Macro Avg” in Table 1 refers
to macro-averaged F-score across categories. The
results obtained by biased-SVM indicate the maxi-
mized F-score obtained by varying the parameters,
“c” and “j”. As can be seen clearly from Table 1,
the results with “TbTL/w” and “TrAdaB/w” were bet-
ter to the results obtained by “bSVM/w” except for
“Sports” and “Local news” in “TrAdaB/w”, although
“bSVM/w” in Table 1 was the result obtained by us-
ing the closed data. Moreover, the results obtained
by SVM with and without TbFS was the worst re-
sult among other methods. These observations show
that once the training data drive from a different time
period from the test data, the distributions of terms
between training and test documents are not identical.
2
When the creation time period of the training data is
the same as the test data, we used only the same-distribution
data.
KDIR 2015 - 7th International Conference on Knowledge Discovery and Information Retrieval
22
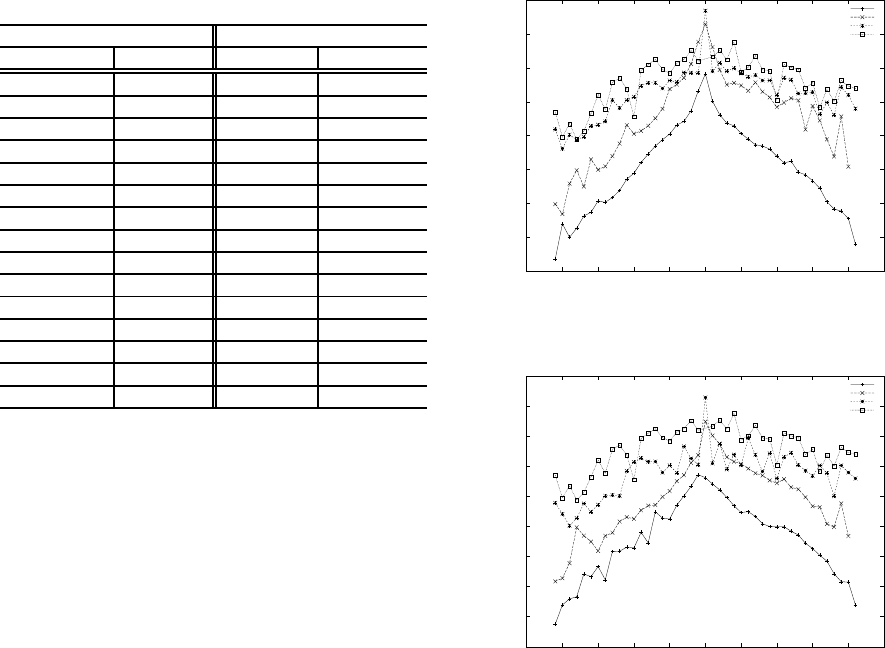
Table 3: Sample results of term selection.
Sports International
ind. dep. (2000) ind. dep. (1997)
baseball Sydney president Tupac Amaru
win Toyota premier Lima
game HP army Kinshirou
competition hung-up power residence
championship Paku government Hirose
entry admission talk Huot
tournament game election MRTA
player Mita UN Topac
defeat Miyawaki politics impression
pro ticket military employment
title ready nation earth
finals Seagirls democracy election
league award minister supplement
first game Gaillard North Korea East Europe
Olympic attackers chair bankruptcy
The overall performance with TbFS were better
to those without TbFS in all methods. This shows
that temporal-based term selection contributes clas-
sification performance. Table 3 shows the topmost
15 independent/dependent terms obtained by TbFS.
The categories are “Sports” and “International”. As
we can see from Table 3 that independent terms
such as “baseball” and “win” are salient terms of the
category “Sports” regardless to a time period. On
the other hand, “Miyawaki” listed in the dependent
terms. The term often appeared in the documents
from 1998 to 2000 because Miyawaki was a snow-
board player and he was on his first world cham-
pionship title in Jan. 1998. Similarly, in the cate-
gory “International”, terms such as “UN” and “North
Korea” are listed in the independent terms, as they
often appeared in documents regardless of the time-
line. In contrast, “Tupac Amaru” and “MRTA” are
listed in the dependent terms. It is reasonable because
in this year, Tupac Amaru Revolutionary Movement
(MRTA) rebels were all killed when Peruvian troops
stormed the Japanese ambassador’s home where they
held 72 hostages for more than four months. These
observations support our basic assumption: there are
two types of salient terms, i.e. terms that are salient
for a specific period, and terms that are important re-
gardless of the timeline.
Figures 2 and 3 illustrate F-score with/without
TbFS against the temporal difference between train-
ing and test data. Both training and test data are the
documents from 1991 to 2012. For instance, “5” of
the x-axis in Figures 2 and 3 indicate that the test
documents are created 5 years later than the training
documents. We can see from Figures 2 and 3 that
the results with TbFS were better to those without
TbFS in all of the methods. Moreover, the result ob-
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
-25 -20 -15 -10 -5 0 5 10 15 20 25
F-score
Temporal distance
"SVM_w"
"bSVM_w"
"TrAdaB_w"
"TbTL_w"
Figure 2: Performance with TbFS against temporal dis-
tance.
0.35
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
-25 -20 -15 -10 -5 0 5 10 15 20 25
F-score
Temporal distance
"SVM_wo"
"bSVM_wo"
"TrAdaB_wo"
"TbTL_w"
Figure 3: Performance without TbFS against temporal dis-
tance.
tained by “TbTL/w” in Figure 2 was the best in all of
the temporal distances. There are no significant dif-
ferences among three methods, “bSVM”, “TrAdaB”,
and “TbTL” when the test and training data are the
same time period in both of the Figures 2 and 3.
The performance of these methods including “SVM”
drops when the period of test data is far from the
training data. However, the performance of “TbTL”
was still better to those obtained by other methods.
This demonstrates that the algorithm which applies
temporal-basedfeature selection and learning is effec-
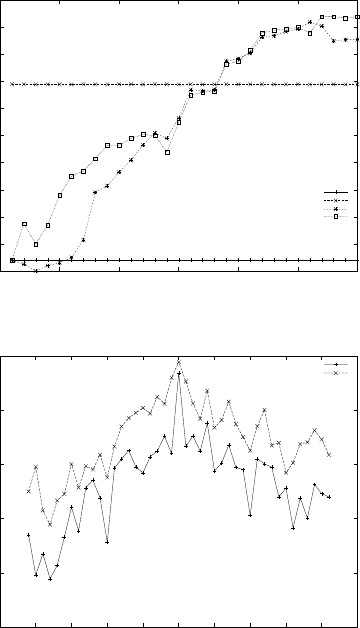
tive for categorization. Figure 4 shows the averaged
F-score of categories across full temporal range with
TbFS against the number of iterations. Although the
curves are not quite smooth, they converge around 25
iterations.
Finally, we tested how the use of LDA influences
the overall performance. Figure 5 illustrates F-score
of “TbTL/w” with and without LDA against the tem-
poral difference between training and test data. In
“TbTL/w” without LDA, we added 50% (393,759)
labeled documents to the original 10% (78,751) la-
Temporal-based Feature Selection and Transfer Learning for Text Categorization
23
0.5
0.52
0.54
0.56
0.58
0.6
0.62
0.64
0.66
0.68
0.7
0 5 10 15 20 25 30
F-score
Number of iterations
"SVM_iter"
"bSVM_iter"
"TrAdaB_iter"
"TbTL_iter"
Figure 4: F-score with TbFS against the # of iterations.
0.55
0.6
0.65
0.7
0.75
0.8
-25 -20 -15 -10 -5 0 5 10 15 20 25
F-score
Temporal distance
"TbTL_wLDA"
"TbTL_woLDA"
Figure 5: F-score with/without LDA against temporal dis-
tance.
beled training documents. As we expected, the re-
sults obtained by “TbTL/w” without LDA were better
to those with LDA in every temporal distance, and
the averaged improvement of F-score across 22 years
was 3.5%(0.723-0.688). It is not surprising because
in “TbTL/w” without LDA, we used a large number
of labelled training documents, 472,510 documents
which are very expensive and time-consuming. In
contrast, in “TbTL/w” with LDA, we used 78,751 la-
beled documents across 22 years in all, the average
number of documents per year was 3,579 across eight
categories.
5 CONCLUSIONS AND FUTURE
WORK
We have developed an approach for text categoriza-
tion concerned with the impact that the variation of
the strength of term-category relationship over time.
The basic idea is to minimize the impact of tempo-
ral effects in both feature selection and learning tech-
niques. The results using Japanese Mainichi News-
paper corpus show that temporal-based feature selec-
tion and learning method works well for categoriza-
tion, especially when the creation time of the test data
differs greatly from the training data.
There are a number of interesting directions for
future work. We should be able to obtain further ad-
vantages in accuracy in independent/dependent term
selection by smoothing the term distributions such
as organization and person name terms through the
use of techniques such as Latent Semantic Analysis
(LSA) (Deerwester et al., 1990), Log-Bilinear Doc-
ument Model (Maas and Ng, 2010), and word2vec
(Mikolov et al., 2013). The quantity of the labeled
training documents affects the overall performance.
Dai et al. attempted to use Transductive Support
Vector Machines (Dai et al., 2007; Joachims, 1999).
However, they reported that the rate of convergence is
slow. This issue needs further investigation. We used
LDA to classify unlabeled documents into categories.
There are number of other topic models such as con-
tinuous time dynamic topic model (Wang et al., 2008)
and a biterm topic model (Yan et al., 2013). It is worth
trying to test these methods for further improvement.
ACKNOWLEDGEMENTS
The authors would like to thank the referees for their
comments on the earlier version of this paper. This
work was supported by the Grant-in-aid for the Japan
Society for the Promotion of Science (JSPS), No.
25330255.
REFERENCES
Blei, D. M., Ng, A. Y., and Jordan, M. I. (2003). Latent
Dirichlet Allocation. Machine Learning, 3:993–1022.
Blitzer, J., McDonald, R., and Pereira, F. (2006). Domain
Adaptation with Structural Correspondence Learning.
In Proc. of the Conference on Empirical Methods in
Natural Language Processing, pp. 120-128.
Dai, W., Yang, Q., Xue, G., and Yu, Y. (2007). Boosting for
Transfer Learning. In Proc. of the 24th International
Conference on Machine Learning, pp. 193-200.
Deerwester, S., Dumais, S. T., Furnas, G. W., Landauer,
T. K., and Hashman, R. (1990). Indexing by Latent
Semantic Analysis. American Society for Information
Science, 41(6):391–407.
Dumais, S. and Chen, H. (2000). Hierarchical Classifica-
tion of Web Contents. In Proc. of the 23rd Annual In-
ternational ACM SIGIR Conference on Research and
Development in Information Retrieval, pp. 256-263.
KDIR 2015 - 7th International Conference on Knowledge Discovery and Information Retrieval
24
Elkan, C. and Noto, K. (2008). Learning Classifiers from
Only Positiveand Unlabeled Data. In Proc. of the 14th
ACM SIGKDD International Conference on Knowl-
edge Discovery & Data Mining, pp. 213-220.
Folino, G., Pizzuti, C., and Spezzano, G. (2007). An
Adaptive Distributed Ensemble Approach to Mine
Concept-drifting Data Streams. In Proc. of the 19th
IEEE International Conference on Tools with Artifi-
cial Intelligence, pp. 183-188.
Forman, G. (2003). An Extensive Empirical Study of Fea-
ture Selection Metrics for Text Classification. Ma-
chine Learning Research, 3:1289–1305.
Freund, Y. and Schapire, R. E. (1997). A Decision-
Theoretic Generalization of On-Line Learning and an
Application to Boosting. Journal of Computer and
System Sciences, 55(1):119–139.
Glorot, X., Bordes, A., and Bengio, Y. (2011). Domain
Adaptation for Large-Scale Sentiment Classification:
A Deep Learning Approach. In Proc. of the 28th In-
ternational Conference on Machine Learning, pp. 97-
110.
Gopal, S. and Yang, Y. (2010). Multilabel Classification
with Meta-level Features. In Proc. of the 33rd Annual
International ACM SIGIR Conference on Research
and Development in Information Retrieval, pp. 315-
322.
Hassan, S., Mihalcea, R., and Nanea, C. (2007). Random-
Walk Term Weighting for Improved Text Classifica-
tion. In Proc. of the IEEE International Conference
on Semantic Computing, pp. 242-249.
He, D. and Parker, D. S. (2010). Topic Dynamics: An Alter-
native Model of Bursts in Streams of Topics. In Proc.
of the 16th ACM SIGKDD Conference on Knowledge
discovery and Data Mining, pp. 443-452.
Hofmann, T. (1999). Probabilistic Latent Semantic Index-
ing. In Proc. of the 22nd Annual International ACM
SIGIR Conference on Research and Development in
Information Retrieval, pp. 35-44.
III, H. D.(2007). Frustratingly Easy Domain Adaptation. In
Proc. of the 45th Annual Meeting of the Association of
computational Linguistics, pp. 256-263.
Joachims, T. (1998). SVM Light Support Vector Machine.
In Dept. of Computer Science Cornell University.
Joachims, T. (1999). Transductive Inference for Text Clas-
sification using Support Vector Machines. In Proc. of
16th International Conference on Machine Learning,
pp. 200-209.
Kerner, Y. H., Mughaz, D., Beck, H., and Yehudai, E.
(2008). Words as Classifiers of Documents accord-
ing to Their Historical Period and the Ethnic Origin of
Their Authors. Cymernetics and Systems, 39(3):213–
228.
Kleinberg, M. (2002). Bursty and Hierarchical Structure
in Streams. In Proc. of the Eighth ACM SIGKDD In-
ternational Conference on Knowledge Discovery and
Data Mining, pp. 91-101.
Klinkenberg, R. and Joachims, T. (2000). Detecting Con-
cept Drift with Support Vector Machines. In Proc. of
the 17th International Conference on Machine Learn-
ing, pp. 487-494.
Lazarescu, M. M., Venkatesh, S., and Bui, H. H. (2004).
Using Multiple Windows to Track Concept Drift. In-
telligent Data Analysis, 8(1):29–59.
Lewis, D. D. and Ringuette, M. (1994). Comparison of Two
Learning Algorithms for Text Categorization. In Proc.
of the ThirdAnnual Symposium on Document Analysis
and Information Retrieval, pp. 81-93.
Li, Y., Yang, M., and Zhang, Z. (2013). Scientific Articles
Recommendation. In Proc. of the ACM International
Conference on Information and Knowledge Manage-
ment CIKM 2013, pp. 1147-1156.
Liu, B., dai, Y., Li, X., Lee, W. S., and Yu, P. S. (2003).
Building Text Classifiers using Positive and Unla-
beled Examples. In Proc. of the ICDM’03, pp. 179-
188.
Maas, A. L. and Ng, A. Y. (2010). A probabilistic Model
for Semantic Word Vectors. NIPS, 10.
Matsumoto, Y., Kitauchi, A., Yamashita, T., Hirano, Y.,
Matsuda, Y., Takaoka, K., and Asahara, M. (2000).
Japanese Morphological Analysis System Chasen Ver-
sion 2.2.1. In Naist Technical Report.
Mikolov, T., Chen, K., Corrado, G., and Dean, J. (2013).
Efficient Estimation of Word Representations in Vec-
tor Space. In Proc. of the International Conference on
Learning Representations Workshop.
Mourao, F., Rocha, L., Araujo, R., Couto, T., Goncalves,
M., and Jr., W. M. (2008). Understanding Temporal
Aspects in Document Classification. In Proc. of the
1st ACM International Conference on Web Search and
Data Mining, pp. 159-169.
Murphy, J. (1999). Technical Analysis of the Financial Mar-
kets. Prentice Hall.
Raina, R., Ng, A. Y., and Koller, D. (2006). Constructing In-
formative Priors using Transfer Learning. In Proc. of
the 23rd International Conference on Machine Learn-
ing, pp. 713-720.
Salles, T., Rocha, L., and Pappa, G. L. (2010). Temporally-
aware Algorithms for Document Classification. In
Proc. of the 33rd Annual International ACM SIGIR
Conference on Research and Development in Infor-
mation Retrieval, pp. 307-314.
Siao, M. and Guo, Y. (2013). Domain Adaptation for Se-
quence Labeling Tasks with a Probabilistic Language
Adaptation Model. In Proc. of the 30th International
Conference on Machine Learning, pp. 293-301.
Song, M., Heo, G. E., and Kim, S. Y. (2014). Analyzing
topic evolution in bioinformatics: Investigation of dy-
namics of the field with conference data in dblp. Sci-
entometrics, 101(1):397–428.
Sparinnapakorn, K. and Kubat, M. (2007). Combining
Subclassifiers in Text Categorization: A DST-based
Solution and a Case Study. In Proc. of the 13th
ACM SIGKDD International Conference on Knowl-
edge Discovery and Data Mining, pp. 210-219.
Wang, C., Blei, D., and Heckerman, D. (2008). Continuous
Time Dynamic Topic Models. In Proc. of the 24th
Conference on Uncertainty in Artificial Intelligence,
pp. 579-586.
Xue, G. R., Dai, W., Yang, Q., and Yu, Y. (2008). Topic-
bridged PLSA for Cross-Domain Text Classification.
Temporal-based Feature Selection and Transfer Learning for Text Categorization
25
In Proc. of the 31st Annual International ACM SIGIR
Conference on Research and Development in Informa-
tion Retrieval, pp. 627-634.
Yan, X., Guo, J., Lan, Y., and X.Cheng (2013). A Biterm
Topic Model for Short Texts. In Proc. of the 22nd In-
ternational Conference on World Wide Web, pp. 1445-
1456.
Yang, Y. and Pedersen, J. O. (1997). A Comparative
Study on Feature Selection in Text Categorization. In
Proc. of the 14th International Conference on Ma-
chine Learning, pp. 412-420.
KDIR 2015 - 7th International Conference on Knowledge Discovery and Information Retrieval
26
