A New Approach for Collaborative Filtering based on Bayesian
Network Inference
Loc Nguyen
Sunflower Soft Company, Ho Chi Minh City, Vietnam
Keywords: Collaborative Filtering, Bayesian Network.
Abstract: Collaborative filtering (CF) is one of the most popular algorithms, for recommendation in cases, the items
which are recommended to users, have been determined by relying on the outcomes done on surveying their
communities. There are two main CF-approaches, which are memory-based and model-based. The model-
based approach is more dominant by real-time response when it takes advantage of inference mechanism in
recommendation task. However the problem of incomplete data is still an open research and the inference
engine is being improved more and more so as to gain high accuracy and high speed. I propose a new
model-based CF based on applying Bayesian network (BN) into reference engine with assertion that BN is
an optimal inference model because BN is user’s purchase pattern and Bayesian inference is evidence-based
inferring mechanism which is appropriate to rating database. Because the quality of BN relies on the
completion of training data, it gets low if training data have a lot of missing values. So I also suggest an
average technique to fill in missing values.
1 INTRODUCTION
The recommendation system is a system which
recommends to the users, all the items which are
those among a large number of existing items in
database. Items which are to point to anything that
users are to considering such as products, services,
books, news papers, etc. And there has been also an
expectation that the recommended items will be
likely the ones that the users would be like the most.
Another words, such mentioned items are going to
go along with the users’ interests.
By those meanings, there are two
recommendations systems, found to be with a
common trends: content-base filtering (CBF) and
collaborative filtering (CF) (Su & Khoshgoftaar,
2009, pp. 3-13) (Ricci, et al., 2011, pp. 73-139):
- The CBF recommends an item to a user if such
item has similarities in contents to other items
that he like most in the past (and his rating for
such item is high). Note that each item has
contents which are their properties and so all
items will compose a matrix, called the items
content matrix.
- The CF on the other hands, recommends an item
to user if his neighbors (mean the other users that
are similar to him) are interested in such item.
Notes that, user’s rating on any item does
express his interest on that item. For that reason,
all user’s ratings which carry out on the items
will also composes a matrix, called the rating
matrix.
Both of the above mentioned filtering (CBF and CF)
do have their own strong, as well weak points. The
CBF is the one to focus on the item’s contents and
user personality’s interests. And it is designed to
recommend different items to different users. Each
user therefore, can receive a unique
recommendation; and this is also the strong point of
CBF filtering. However CBF doesn’t tend towards
community like CF does. As the items that users
may like “are hidden under” user community, CBF
hasn’t been capable of discovering such implicit
items. Because of this, it is acknowledged as a
common weak point of CBF. Moreover, in case the
number of users becomes larger at a huge volume,
CBF may give a wrong prediction; else the accuracy
of CF will get increased.
If there will be a huge contents associated with
items, for instance and these items have had various
properties then CBF in return, will consume even
much more system resources, as well the processing
time in order to analyze these items whereas, CF as a
Nguyen, L..
A New Approach for Collaborative Filtering based on Bayesian Network Inference.
In Proceedings of the 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2015) - Volume 1: KDIR, pages 475-480
ISBN: 978-989-758-158-8
Copyright
c
2015 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
475
matter of fact, doesn’t pay any regard to the contents
of the meant items. Instead the CF only works on the
users’ ratings of the items and it is known as the
strong point of this CF type. Because of that, CF
wouldn’t be encountering with problems, such as
how to analyze the richness in items’ contents.
However this is also to reflecting the weak points of
CF type as well, simply because CF can also do
some unexpected recommendations in some
situations, in which items are to be considered
suitable to users, but they don’t relate to users’
profiles in fact. The problem then even turns into
more serious trouble when having to facing with too
many items which aren’t rated. It turns the rating
matrix into the spare one which is to containing
various missing values. In order to alleviate this
weakness of the CF type, there have been two
techniques which could be helpful, used for
improvements:
- The combinations of the CF and CBF types. This
technique is breaking into two stages. First, it
applies CBF to setting up a complete rating
matrix, and then the next step would be the CF
type, which is used to making predictions for
recommendations. This mentioned technique will
be positively useful to improve the predictions’
precision. But it does consuming more time
when the first stage plays the role of the filtering
step or pre-processing step while the content of
items must be fully represented as a requirement.
This technique is designed to requiring both, the
items’ content matrix, and the rating matrix.
- Compressing the rating matrix into a
representative model, which then is used to
predict all the missing data for recommendations.
This is a model-based approach for the CF type.
Note that to this CF type, there have been two
common approaches, such as the memory-based
and the model-based approaches. The model-
based approach applies statistical and machine
learning methods to mining the rating matrix.
The result of this mining task is the above
mentioned model.
Although the model-based approach doesn’t give
result which is as precise as the combination
approach, it can solve the problem of huge database
and sparse matrix. Moreover it can responds user’s
request immediately by making prediction on
representative model though instant inference
mechanism. So this paper focuses on model-based
approach for CF based on Bayesian network
inference. There are many other researches which
apply Bayesian network (BN) into CF. Authors
(Miyahara & Pazzani, 2000) propose the Simple
Bayesian Classifier for CF. Suppose rating values
range in the integer interval {1, 2, 3, 4, 5}, there is a
set of 5 respective classes {c
1
, c
2
, c
3
, c
4
, c
5
}. The
Simple Bayesian Classifier uses Naïve Bayesian
classification method (Miyahara & Pazzani, 2000, p.
4) to determine which class a given user belongs to.
Mentioned in (Su & Khoshgoftaar, 2009, p. 9), the
NB-ELR algorithm is an improvement of Simple
Bayesian Classifier, which combines Naïve
Bayesian classification and extended logistic
regression (ELR). ELR is a gradient-ascent
algorithm, which is a discriminative parameter-
learning algorithm that maximizes log conditional
likelihood (Su & Khoshgoftaar, 2009, p. 9). NB-
ELR algorithm gains high classification accuracy on
both complete and incomplete data. Author
(Langseth, 2009) assumes that there is a linear
mapping from the latent space of users and items to
the numerical rating scale. Such mapping which
conforms the full joint distribution over all ratings
constructs a BN. Parameters of joint distribution are
learned from training data, which are used for
predicting active users’ ratings. According to
(Campos, et al., 2010), the hybrid recommender
model is the BN that includes three main kinds of
nodes such as feature nodes, item nodes, and user
nodes. Each feature node represents an attribute of
item. Active users’ ratings are dependent on these
nodes.
In general, other researches focus on
classification based on BN, discovering latent
variables, and predicting active users’ ratings while
this research focuses on using BN to model users’
purchase pattern and taking advantages of inference
mechanism of BN. It is the potential approach
because it opens a new point of view about
recommendation domain. In section 2 I propose an
idea for the model-based CF algorithm based on
Bayesian network. Section 3 tells about the
enhancement of our method. Section 4 is the
evaluation and its results. Section 5 is the
conclusion.
2 A NEW CF ALGORITHM
BASED ON BAYESIAN
NETWORK
The basic idea of model-based CF is to try to find
out an optimal inference model which can give real-
time response. Besides, sparse matrix and black
sheep are considered as important problems which
need to be solved. I propose a new model-based CF
KDIR 2015 - 7th International Conference on Knowledge Discovery and Information Retrieval
476
algorithm based on Bayesian network (Neapolitan,
2003, p. 40) inference so as to gain high accuracy
and solve the problem of sparse matrix. In general,
our method aims to build up Bayesian network (BN)
from rating matrix. Each node of such BN represents
an item and each arc expresses the dependence
relationship between two nodes. Whenever
recommendation task is required, the inference
mechanism of BN will determine which items are
recommended to user, based on the posterior
probabilities of such items. The larger the posterior
probability of an item is, the higher it’s likely that
this item is bought by many users. So such item has
high frequency and it should be recommended to
new users. If the rating matrix is sparse, we try to
replace missing values by estimated values so that it
is easy and efficient to build up BN from complete
matrix instead of from sparse matrix. The technique
of how to estimate missing values is discussed later.
New algorithm includes 4 steps:
1. Transposing user-based matrix to item-based
matrix.
2. Filling in missing values.
3. Learning BN from item-based matrix.
4. Performing recommendation task.
Steps 1, 2, 3 are offline-mode processes and so they
don’t affect the ability of real-time response in step
4. These steps are described in following sub-
sections 2.1, 2.2, 2.3, and 2.4.
2.1 Transposing User-based Matrix to
Item-based Matrix
User-based matrix is the original format of rating
matrix in which each row contains ratings that a
concrete user giving to many items. Otherwise, for
item-based matrix, each row contains ratings that a
concrete item receiving from many users. User-
based matrix transposed into item-based matrix in
this step is considered as simple pre-processing step
which is simple but very important because BN is
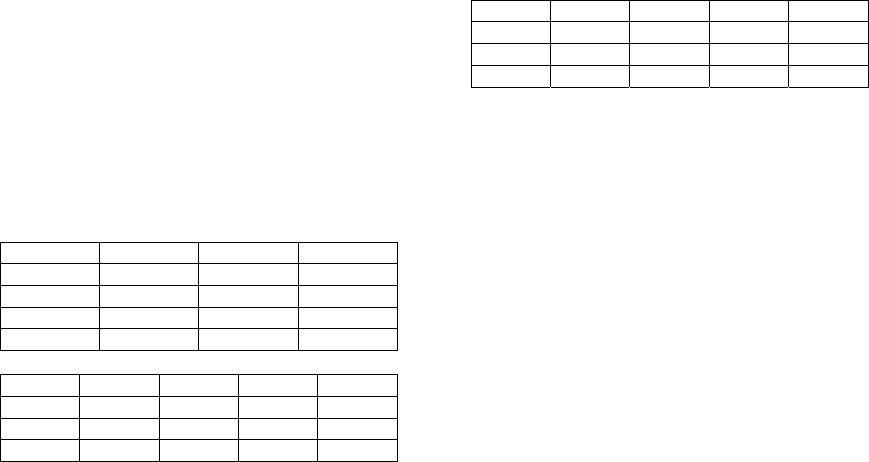
Table 1: Transposing user-based matrix to item-based
matrix.
item
1
item
2
item
3
user
1
r
11
= 1 r
12
= 3 r
13
= ?
user
2
r
21
= 3 r
22
= ? r
23
= 5
user
3
r
31
= 4 r
32
= 2 r
33
= 1
user
4
r
41
= ? r
42
= ? r
43
= 3
user
1
user
2
user
3
user
4
item
1
r
11
= 1 r
21
= 3 r
31
= 4 r
41
= ?
item
2
r
12
= 3 r
22
= ? r
32
= 2 r
42
= ?
item
3
r
13
= ? r
23
= 5 r
33
= 1 r
43
= 3
constituted of item nodes. In real context, the
number of customers is unlimited and increased
much more than the number of items. We use item-
based matrix in order to keep the size of BN in small
so that the speed of inference is improved in
recommendation task (see step 4). Table 1 is an
example of transposing user-based matrix to item-
based matrix. Question marks (?) indicates missing
values.
2.2 Filling in Missing Values
The BN learned from complete rating matrix is more
adequate than the one learned from sparse matrix.
Some methods can learn BN from incomplete data
while other methods require complete data. In case
of requirement of complete data, the simplest way to
fill in incomplete data is to replace missing values
by average values. An average value is an estimate
of missing value. The replacement is iterative and
overlap procedure, which is considered as estimation
process:
- Replacement is done via many iterations.
Replacing missing values with average values in
next iteration is based on estimated values in
previous iteration.
- Average value is calculated as the mean of user
vector. If user vector is empty then the mean of
item vector becomes an estimate of average
value.
By applying average method, we have completely
estimated item-based rating matrix shown in table 2.
Table 2: Completely estimated item-based rating matrix.
user
1
user
2
user
3
user
4
item
1
r
11
= 1 r
21
= 3 r
31
= 4 r
41
= 3
item
2
r
12
= 3 r
22
= 4 r
32
= 2 r
42
= 3
item
3
r
13
= 2 r
23
= 5 r
33
= 1 r
43
= 3
This average technique is fast but not accurate
because replaced values don’t reflect the real values
that users rate on an item. Learning methods which
can undertake incomplete data in order to construct
BN are recommended but they go beyond this
research.
2.3 Learning BN from Item-based
Matrix
Machine learning techniques are used to learn BN
from the item-based matrix shown in tables 1 and 2.
The research applies the K2 learning algorithm built
in the Elvira system (Serafín, et al., 2003) into
constructing BN.
A New Approach for Collaborative Filtering based on Bayesian Network Inference
477
2.4 Performing Recommendation Task
Recommendation task is performed according to
evidence-based inference in BN. Firstly, it
determines posterior probabilities (PoP) of nodes in
networks and secondly, recommends which nodes
have high PoP to users. The target BN, learned from
item-based matrix, is considered user’s purchase
pattern and existing her/his rated items are
considered evidences. This method has two
advantages:
- Using BN being itself purchase pattern can
discover user interests and predict her/his
purchase trend in future. So the quality of
recommendation is improved.
- Evidence-based inference in BN is a solid and
powerful deduction mechanism. This decreases
mean square of error when estimating missing
ratings.
The target BN is very small with only three nodes
and so the complexity of computation is
insignificant and does not affect ability of real-time
response of recommendation system but when BN
gets huge, it becomes serious problem that needs to
be resolved. The Pearl algorithm (Neapolitan, 2003,
pp. 126-156) is the classical method to solve this
problem by propagating messages over the network
according to two different directions. This research
applies an inference algorithm – the variable
elimination method of propagation built in Elvira
system (Serafín, et al., 2003) into calculating
posterior probabilities.
Besides, next section will mention an
enhancement technique which alleviates such
complexity of computation.
3 AN ENHANCEMENT –
CLUSTERED BAYESIAN
NETWORKS
As discussed, however the number of items is
limited and not increased as much as the number of
users, it is still so large. Obviously, BN consists of
connected nodes but it may contain some incoherent
or unconnected nodes because it is learned from
large data. Such incoherent nodes make the
inference mechanism less efficient. This is problem
of incoherence among item nodes, which need
solved.
Suppose that there are a lot of items in
supermarket and they are divided into categories
(groups). Clothes items (T-shirts, trousers, jeans,
pulls, etc.) in the same category (clothes category)
are related together. So they are connected nodes in
BN and compose naturally a sub-group of nodes.
Nevertheless, other items not related to clothes
category will become incoherent nodes which are
unconnected to clothes nodes. The inference based
on whole BN including incoherent groups of nodes
is less precise. This issue is solved by learning one
BN for each category, thus, we build up many
individual BN (s) and each BN represents a group of
related items. In other words, a large and whole BN
is decomposed into small and individual BN (s) so
that nodes in the same individual BN are more
coherent. For example, three individual BN (s) are
built up, which correspond with three categories in
supermarket: clothes, furniture and electrical goods.
In case that the training data set (rating matrix)
doesn’t specify explicitly categories, we will apply
clustering technique into discovering groups of
items. So the improvement in building up BN
includes two steps:
1. Applying clustering methods such as k-mean,
k-medoid, etc. into grouping items. We can
classify items into groups (categories)
manually, thus each item can belong to more
than one group.
2. For each group (category) of items:
a. Training data set is pruned. Namely, for
each row of rating matrix, columns which
are not corresponding to items in this
group are removed.
b. BN is learned from pruned training
dataset. Such BN is called individual BN.
Note that a node can belong to more than one
individual BN. It is a drawback but occurs in
commercial context, an item can be classified into
more than one category (group).
So every time recommendation task is required
(in step 4 of our method), the inference process is
executed on individual BN instead of whole BN as
before. The speed is improved because the number
of nodes in individual BN is much smaller than in
whole large BN. But another issue is raised “given
active user how to choose a right individual BN in
order to perform inference task?”. If we browse over
all of individual BN (s) and all their nodes to find
out the right BN which contains most items (nodes)
of active user, it consumes a lot time and computer
resources. So it requires another approach. This is an
open research but I also suggest a solution so-called
mapping table (MT) technique.
The basic idea of MT technique is to create a
mapping table (MT) at the same time to learning
BN. Each row of MT is a key-value pair. Key is
KDIR 2015 - 7th International Conference on Knowledge Discovery and Information Retrieval
478

node’s name. Value is the bit set indicating which
individual BN (s) to which this node belongs. Each
bit of this bit set represents the occurrence of an
individual BN, in other words, whether or not such
individual BN contains the node specified by the
key. Suppose there are 3 individual BN (s) such as
BN
0
, BN
1
, BN
2
and 8 nodes such as A, B, C, D, E, F,
G, H. The example MT is described in table 3.
Table 3: Mapping table.
A 100
B 100
C 010
D 010
E 001
F 001
G 011
H 011
This MT is interpreted as follows: “nodes A and B
belong to BN
0
”, “nodes C and D belong to BN
1
”,
“nodes E and F belong to BN
2
”, “nodes G and H
belong to BN
1
and BN
2
, respectively”.
Given active user and her/his rated items, for
each individual BN, the total number of nodes
contained in this BN is counted. Which individual
BN has the highest total number is chosen as right
one on which inference task will be executed. For
instance, given nodes E, F, G and H on which an
active user rates, we have:
- The total number of nodes contained in BN
0
is 0,
t
0
= 0 because BN
0
doesn’t any node rated by
active user.
- The total number of nodes contained in BN
1
is 0,
t
1
= 2 because BN
1
contains G and H.
- The total number of nodes contained in BN
2
is 0,
t
2
= 4 because BN
2
contains E, H, G and H.
Because t
4
is maximal, BN
2
is the right individual BN.
4 EVALUATION
Database Movielens (GroupLens, 1998) including
100,000 ratings of 943 users on 1682 movies is used
for evaluation. Database is divided into 5 folders,
each folder includes training set over 80% whole
database and testing set over 20% whole database.
Training set and testing set in the same folder are
disjoint sets.
The system setting includes: processor
Pentium(R) Dual-Core CPU E5700 @ 3.00GHz,
RAM 2GB, available RAM 1GB, Microsoft
Windows 7 Ultimate 2009 32-bit, Java 7 HotSpot
(TM) Client VM. The proposed BN method is
compared to four other methods: Green Fall –
model-based CF using mining frequent itemsets
technique, neighbor item-based method, neighbor
user-based and SVD (Ricci, et al., 2011, pp. 151-
152). Note that the BN method is enhanced by
clustering individual BN (s) aforementioned in
section 3.
There are 7 metrics (Herlocker, et al., 2004, pp.
19-39) used in this evaluation: MAE, MSE,
precision, recall, F1, ARHR and time. Time metric is
calculated in seconds. MAE and MSE are predictive
accuracy metrics that measure how close predicted
value is to rating value. The less MAE and MSE are,
the high accuracy is. Precision, recall and F1 are
quality metrics that measure the quality of
recommendation list – how much the
recommendation list reflects user’s preferences.
ARHR is also quality metric that indicates how well
recommendation list is matched to user’s rating list
according to rating ordering. The large quality
metric is, the better algorithm is.
The evaluation result is shown in table 4 as
follows:
Table 4: Evaluation result.
BN
method
Green
Fall
Item-
based
User-
based
SVD
MAE 0.6127 0.7241 0.5222 0.9319 0.5363
MSE 0.9023 1.1640 0.6675 2.1664 1.1734
Precision 0.1430 0.1328 0.0245 0.0014 0.0041
Recall 0.0552 0.0523 0.0092 0.0005 0.0015
F1 0.0785 0.0739 0.0131 0.0008 0.0021
ARHR 0.0504 0.0442 0.0043 0.0005 0.0016
Time 1.8780 0.0050 9.3706 8.3831 0.0176
The proposed BN method is much more effective
than other methods when getting high quality via
metrics precision, recall, F1 and ARHR. Its accuracy
is approximate to item-based, user-based methods,
SVD and better than Green Fall via metrics MAE
and MSE. It consumes more time than Green Fall
and SVD but less time than item-based method and
user-based method.
In general, BN method is good at
recommendation quality and Green Fall is good at
real-time response. The other drawback of BN
method is that it requires a lot of computer resources
to learn data. Thus, building up BN takes much more
time than mining frequent itemsets.
5 CONCLUSION
The essence of our method is to learn Bayesian
A New Approach for Collaborative Filtering based on Bayesian Network Inference
479
network (BN) from item-based rating matrix. After
that BN inference is applied into recommending
items to user. Therefore, complexity of the proposed
algorithm is dependent on both learning task and
inference task. However, only inference task is
considered in real time application because learning
task is done in offline mode.
In the evaluation, our method is compared with
other memory-based and model-based methods such
as Green Fall, item-based, user-based and SVD. The
result shows that the BN method is very effective
when it gains high quality via precision, recall, F1
and ARHR metrics. However, learning BN is a big
problem. This research is still open.
ACKNOWLEDGEMENTS
This research is the place to acknowledge Madam
Do, Phung T. M. and Sir Vu, Dong N. who gave me
valuable comments and advices. These comments
help me to improve this research.
REFERENCES
Campos, L. M. d., Fernández-Luna, J. M., Huete, J. F. &
Rueda-Morales, M. A., 2010. Combining content-
based and collaborative recommendations: A hybrid
approach based on Bayesian networks. International
Journal of Approximate Reasoning, September, 51(7),
p. 785–799.
GroupLens, 1998. MovieLens datasets. [Online]
Available at: http://grouplens.org/datasets/movielens/
[Accessed 3 August 2012].
Herlocker, J. L., Konstan, J. A., Terveen, L. G. & Riedl, J.
T., 2004. Evaluating Collaborative Filtering
Recommender Systems. ACM Transactions on
Information Systems (TOIS), 22(1), pp. 5-53.
Langseth, H., 2009. Bayesian Networks for Collaborative
Filtering. s.l., Tapir Akademisk Forlag, pp. 67-78.
Miyahara, K. & Pazzani, M. J., 2000. Collaborative
Filtering with the Simple Bayesian Classifier. In: R.
Mizoguchi & J. Slaney, eds. PRICAI 2000 Topics in
Artificial Intelligence. s.l.:Springer Berlin Heidelberg,
pp. 679-689.
Neapolitan, R. E., 2003. Learning Bayesian Networks.
Upper Saddle River(New Jersey): Prentice Hall.
Ricci, F., Rokach, L., Shapira, B. & Kantor, P. B., 2011.
Recommender Systems Handbook. s.l.:Springer New
York Dordrecht Heidelberg London.
Serafín, C. M., Carmelo, R. T., Pedro, M. L. & Francisco,
V. J. D., 2003. Elvira system. 0.11 ed. s.l.:National
University of Distance Education.
Su, X. & Khoshgoftaar, T. M., 2009. A Survey of
Collaborative Filtering Techniques. Advances in
Artificial Intelligence, Volume 2009.
KDIR 2015 - 7th International Conference on Knowledge Discovery and Information Retrieval
480
