
Job Recommendation from Semantic Similarity of
LinkedIn Users’ Skills
Giacomo Domeniconi, Gianluca Moro, Andrea Pagliarani, Karin Pasini and Roberto Pasolini
DISI, Universit
`
a degli Studi di Bologna, Via Venezia 52, Cesena, Italy
Keywords:
Job Seeking, Hierarchical Clustering, Latent Semantic Analysis, Recruiting, Recruitment.
Abstract:
Until recently job seeking has been a tricky, tedious and time consuming process, because people looking for
a new position had to collect information from many different sources. Job recommendation systems have
been proposed in order to automate and simplify this task, also increasing its effectiveness. However, current
approaches rely on scarce manually collected data that often do not completely reveal people skills. Our
work aims to find out relationships between jobs and people skills making use of data from LinkedIn users’
public profiles. Semantic associations arise by applying Latent Semantic Analysis (LSA). We use the mined
semantics to obtain a hierarchical clustering of job positions and to build a job recommendation system.
The outcome proves the effectiveness of our method in recommending job positions. Anyway, we argue
that our approach is definitely general, because the extracted semantics could be worthy not only for job
recommendation systems but also for recruiting systems. Furthermore, we point out that both the hierarchical
clustering and the recommendation system do not require parameters to be tuned.
1 INTRODUCTION
Job hunting (or job seeking) refers to the process peo-
ple looking for a job perform in order to find it. Dif-
ferently, finding out the right employee is a key as-
pect for enterprises, which continuously have to re-
cruit according to their current needs. Both tasks are
sides of the same general problem, namely allowing
communication between companies and potential ap-
plicants for the sake of establishing an employment
relationship. Since each manual search is onerous
and tedious, methods exist that help automating these
processes, such as job recommendation systems (Pa-
parrizos et al., 2011; Malinowski et al., 2006) on the
one hand and recruiting systems (Lee, 2007; Eck-
hardt et al., 2008) on the other hand. The former
cope with the problem of automatically finding a job
which is as inherent to people skills as possible. Vice
versa, the latter are used by Human Resources depart-
ments to select candidates fitting the skills enterprises
are looking for. The concept of skills is crucial in
both previous mentioned tasks, because it could help
pointing out people capabilities even better than in the
state of the art approaches, which only focus on either
academic degree (Dinesh and Radhika, 2014; Chiru-
mamilla et al., 2014) or preceding job positions (Pa-
parrizos et al., 2011).
Nowadays, except from custom private solu-
tions possibly built in-house, social networks like
LinkedIn
1
, Facebook
2
and Twitter
3
are the most used
recruiting systems by enterprises, because informa-
tion available in such context is proven to be useful
(Flecke, 2015). (Davison et al., 2011) pointed out that
LinkedIn provides more accurate information com-
pared to Facebook because everybody in a person’s
network can easily contradict her assertions. This can
be a reason why (Zide et al., 2014) define LinkedIn
as the world’s largest professional network. In ad-
dition to its reliability, LinkedIn also offers recruiter
accounts aiming to support the recruiting process, so
that about 94% of recruiters use it (Kasper, 2015). In-
stead, the same trend does not hold within social me-
dia job seekers, where only 40% makes use of this
network, although members are sometimes notified of
possibly interesting job offers. LinkedIn professional
secrecy does not allow us a complete understanding
of the techniques used to recommend job positions.
Anyway, analyzing some public profiles and the rela-
1
www.linkedin.com
2
www.facebook.com
3
twitter.com
270
Domeniconi, G., Moro, G., Pagliarani, A., Pasini, K. and Pasolini, R.
Job Recommendation from Semantic Similarity of LinkedIn Users’ Skills.
DOI: 10.5220/0005702302700277
In Proceedings of the 5th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2016), pages 270-277
ISBN: 978-989-758-173-1
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

tive recommended job positions, we notice that there
are often wrongly retrieved (i.e. not interesting) of-
fers because of homonymy. This issue could make
the job seeking process less effective, more manually
conducted and time consuming.
Diversely, a job recommendation system should
match requests and offers of jobs by favouring the
best possible fit among candidates and companies ac-
cording to people skills and companies’ needs.
In this paper, we introduce a job recommenda-
tion system based on Latent Semantic Analysis (LSA)
(Dumais et al., 1988) for the support in the job seek-
ing process, evaluating its performance through a
hierarchical clustering of job positions. Clustering
is useful to partition data into previously unknown
groups of similar items and is applied in a large va-
riety of contexts (Cerroni et al., 2015). Hierarchical
clustering aids to build a folksonomy (a user-defined
taxonomy) of jobs useful to correlate them, whereas
normally only each person’s job positions are avail-
able as plain text. So, the basic idea is to discover
similarity between different job positions and then to
find out their latent associations with people skills.
Job positions are represented as vectors of skills
and mapped into a transformed space by applying
LSA to the skill-position co-occurrence matrix. Then,
a complete-linkage hierarchical clustering technique
is applied to correlate the transformed job positions,
using cosine similarity as inter-cluster distance mea-
sure. Instead, the job recommendation algorithm we
propose aims to suggest a list of recommended jobs
that fit people skills. In fact, people are represented
as vectors of skills just like job positions. The al-
gorithm starts from a skill-position matrix built with
training data and expanded by applying LSA. After-
wards, cosine similarity between people and positions
in the skill-position matrix is computed for each test
instance. Thus, since the algorithm basically outputs
how much jobs fit people skills, an ordered list of
recommended job positions can be built according to
their similarity with each person’s skills.
To evaluate our method, we take LinkedIn as ref-
erence scenario because of its widespread use, crawl-
ing real public profiles from which we can easily infer
information about people skills and current job posi-
tions. We assume that current job position is the one
fitting best the skill set of each person (i.e. the label of
each test vector), although we are aware that this cri-
teria is only partly correct, because somebody’s job
might not fit her skills. Then, we perform classifi-
cation assigning the most likely k positions to each
test vector; finally, we test performance by comput-
ing the maximum recall within the k suggested posi-
tions, exploiting the previously built hierarchy. To the
best of our knowledge, there are no works about job
recommendation exploiting either LinkedIn or other
social networks. Our approach is therefore not di-
rectly comparable with the state of the art, because
we focus on large scale data in terms of both job po-
sitions and skills. Moreover, differently from other
approaches (Chi, 1999; Malinowski et al., 2006; Pa-
parrizos et al., 2011), we argue that our method does
not require manually collecting data, because they are
already available on social networks. Finally, it can
be noted that neither the hierarchical clustering of po-
sitions nor the job recommendation algorithm require
parameters to be tuned. This makes our approach easy
to use and profitable in real scenarios.
The rest of the paper is organised as follows. Sec-
tion 2 outlines the state of the art approaches about re-
cruiting and job recommendation systems. Section 3
introduces our methods for position clustering and job
recommendation. Section 4 discusses the performed
experiments. Finally, section 5 summarises results
and points out possible future works.
2 RELATED WORK
The recruiting (or recruitment) process has been ex-
tensively studied in human resources field (Medsker
et al., 1994; Allen and Van der Velden, 2001), giving
increasing attention to the E-recruitment, namely a re-
cruitment process based on web information (Kinder,
2000; Thompson et al., 2008) especially gathered
from social networks such as LinkedIn, Facebook,
Twitter, Xing (Zide et al., 2014; Flecke, 2015). The
majority of these works focus on the human resource
aspect of the recruitment process (Buettner, 2014; Pa-
parrizos et al., 2011). Instead the job hunting prob-
lem, i.e. finding out the best job positions available in
relation to users’ skills and qualities, has seldom been
analyzed.
Several past studies proved the helpfulness of ma-
chine learning approaches for job placement. For in-
stance, in (Min and Emam, 2003), rules created by a
decision tree are used to manage the recruitment of
truck drivers. In (Chi, 1999), the authors apply prin-
cipal component analysis to establish jobs that can
be adequately performed by various types of disabled
workers.
Some existing works (Dinesh and Radhika, 2014;
Chirumamilla et al., 2014) focus on the academic de-
gree of students, aiming to predict both their academic
performance at early stage of their curricula and their
placement chance, using supervised classifiers like
SVMs or neural networks. (Elayidom et al., 2011)
propose a decision tree based approach which helps
Job Recommendation from Semantic Similarity of LinkedIn Users’ Skills
271

students choosing a good branch that may fetch them
placement in either rural or urban sectors.
There exist several works related to job recom-
mendation starting from the candidate profiles (Sit-
ing et al., 2012; Paparrizos et al., 2011). (Rafter
et al., 2000) propose an online Job Finder engine that
uses a collaborative filtering algorithm with some user
preferences. In (Malinowski et al., 2006) a bilateral
people-job recommender system is proposed to match
applicants to job opening profiles. Differently, (Pa-
parrizos et al., 2011) recommend job positions to ap-
plicants based only on the job history of other em-
ployees. (Buettner, 2014) proposes a recommender
system based on social network information, rely-
ing on three fit measures related to candidates. Not
too different is the work by (Gupta and Garg, 2014),
where candidate profile matching as well as preserv-
ing their job preferences are used.
User profiling is one of the major issues of these
approaches, because retrieving, selecting and han-
dling such data is hard. (Rubin et al., 2002) show
the importance of extracurricular activities as users’
skills indicator. (Paparrizos et al., 2011) define user
profiles with three components: personal informa-
tion, current and past professional positions, current
and past educational information. Similarly, (Buet-
tner, 2014; Gupta and Garg, 2014) use information
related to companies, users, user preferences and so-
cial interactions; on the other hand, (Chi, 1999) uses a
set of 41 skills. Our work deeply differs from the job
recommendation approaches listed above because of
the data being used. In fact, they use features related
to the current and past experiences (in employment or
education). Instead, we propose an approach that re-
lies on the set of skills of a person, thus providing a
prediction of the best job in relation to user’s capabil-
ities and knowledge.
According to (Zide et al., 2014), social media are
seldom exploited for recruiting purposes. In their
work, the authors study and find variables that re-
cruiters assess when looking at applicants’ LinkedIn
profiles, such as completeness of information. As far
as we know, the most similar work with respect to
our proposal and used data is (Bastian et al., 2014),
where a folksonomy of skills is constructed and a rec-
ommender system for skills is implemented. In par-
ticular, their goal is analyzing users’ skills extracted
from LinkedIn with the aim of helping users into pro-
file skill filling. On the other hand, finding out rela-
tionships between jobs and users’ skills through ma-
chine learning techniques is one of the main proposal
of our work, addressing both the recruitment and the
job hunting processes.
3 METHOD DESCRIPTION
We describe here the process used to perform cluster-
ing of job positions and to recommend such positions
to any person given its set of skills.
We consider a set U = {u
1
,u
2
,...} of user profiles
(hence just profiles), each of them being the descrip-
tion of a specific person.
To each profile u is associated a set S(u) of skills,
representing the competencies which the correspond-
ing person declares to have. The same skill may be
associated to more than one profile. The set of all dis-
tinct skills is denoted by S = {s
1
,s
2
,...}.
To each profile u is also associated a current job
position p(u). The same job position may be the cur-
rent one for more than one profile. We denote by
P = {p
1
, p
2
,...} the set of all distinct job positions.
3.1 Clustering of Job Positions
We are interested in obtaining a folksonomy of possi-
ble job positions (hence just positions) from the avail-
able data. In order to do so, we perform a hierarchical
clustering of positions in P .
A structured representation of possible positions
is needed in order to measure their mutual distances.
We extract a vector-based representation, where skills
are used as features. Specifically, from the set U of
known profiles, we build a |S | × |P | matrix C count-
ing the co-occurrences between skills and positions
across them. Values in C are computed as follows:
c
i, j
=
u ∈ U : s
i
∈ S(u) ∧ p
j
= p(u)
(1)
In practice, c
i, j
is the number of profiles having
both s
i
among skills and p
j
as position. Each posi-
tion is then represented as a weighted mix of different
skills, according to those possessed by persons em-
ployed in that position.
Intuitively, skills within the set S can be semanti-
cally similar to each other or even be synonyms: for
example, “ms office” can be considered as strictly re-
lated to “ms word”, while they are both quite unre-
lated to “psychology”. The vector-based representa-
tion of positions would be improved by augmenting
for each position (vector) the relevance of skills (fea-
tures) related to those explicitly included in the mix.
This aspect has been addressed in text analysis,
where correlations usually exist between terms (fea-
tures) appearing throughout text documents (vectors).
A well-known technique in this context is Latent
Semantic Analysis (LSA), which employs Singular
Value Decomposition (SVD) to obtain a lower-rank
approximation of a term-document matrix (Dumais
et al., 1988). Equivalently, we apply LSA to the skill-
position matrix C to obtain a transformed matrix C
0
.
ICPRAM 2016 - International Conference on Pattern Recognition Applications and Methods
272

We first decompose C into three factors.
C = U · Σ · V
T
(2)
U and V are orthogonal matrices with eigenvec-
tors of C, while Σ is a diagonal matrix with eigen-
values. These matrices define a latent vector space,
where skills and positions are represented by rows of
U and V, while values in Σ indicate the importance of
each dimension of this space: lower values are sup-
posed to represent dimensions yielding mostly noise
instead of valid information. By setting all values of
Σ except the r highest ones to 0 and multiplying back
the three components, we obtain the transformed ma-
trix C
0
, which is a denoised approximation of C with
rank r. For the r parameter, we choose the minimum
value for which the sum of retained eigenvalues is at
least 50% of the total.
The transformed matrix C
0
, as the original one C,
contains for each position p
k
a column vector p
k
rep-
resenting it. We evaluate the distance between two
positions as the inverse of their cosine similarity.
d(p
a
, p
b
) = 1 − cos(p
a
,p
b
) = 1 −
p
a
· p
b
||p
a
|| ·||p
b
||
(3)
The mutual distances between positions are finally
given in input to a complete-linkage agglomerative
clustering algorithm, which extracts a dendrogram of
all positions. This dendrogram has the form of a bi-
nary tree with positions as leaves: Section 4 shows
some excerpts of it obtained in our tests.
3.2 Job Recommendation
Other than extracting a consistent hierarchy of posi-
tions, the knowledge of a set of profiles can be used
to infer the most advisable job positions for any other
profile u
e
, whose set of skills S(u
e
) is given.
This constitutes in practice a job recommendation
system, where the best positions are suggested to any
person according to her skills. While the positions of
known profiles are assumed to be correct, it should be
noted that there are usually multiple advisable posi-
tions corresponding to a set of skills. A recommenda-
tion system should return a set of most likely positions
and all of them can be equally valid.
The recommendation method we use is simply
based on representing both positions and profiles as
comparable vectors and seeking for each profile the
positions with the most similar vectors. Skills of the
set S are used as features. To each profile will cor-
respond a ranking of the known positions, of which
only the first k items are usually considered.
Each profile u
e
is simply represented by a binary
vector u
e
, whose values are 1 in correspondence of
skills known by the person and 0 elsewhere.
For what regards the vectors representing posi-
tions, we reuse results from the positions clustering
method: one option is to use columns of the original
skill-position co-occurrences matrix C, another one
is to use instead its low-rank approximation C
0
com-
puted by means of LSA as described above.
In both cases, we compare the profile skills vector
u
e
to each column p
j
by means of cosine similarity.
For a given number k of positions to be recommended,
we return the set R
k
(u
e
) of k positions whose vectors
are most similar to u
e
: these constitute the positions
recommended for u
e
.
4 EXPERIMENTS
The methodology described above to extract a hierar-
chy of job positions and to recommend them has been
tested on a set of data extracted from LinkedIn. Op-
erations have been carried out by software based both
on the Java platform and on the open source R envi-
ronment for statistical analysis.
4.1 Dataset Composition
The benchmark dataset we used has been extracted
from publicly accessible LinkedIn profiles of users
from Italy: for each one we considered the set of skills
declared by its owner and the current job position.
Both skills and positions are specified by users as
free text: many of them are present in multiple in-
stances across profiles, but the majority of skills are
only present in few or single profiles, due e.g. to ty-
pos or uncommon names. Another issue is the use
of different languages across the dataset: many users
filled in their profile in Italian due to being their native
language, whereas many others used English to target
a wider audience. Due to these aspects, the same ac-
tual skill or position can be found multiple times with
different names.
We performed some preprocessing operations to
obtain two disjoint groups of profiles suitable as train-
ing and test sets: the former is used to compute sim-
ilarities between skills and positions and to build the
hierarchy, the latter is used instead to evaluate the ac-
curacy of the recommendation method.
Our final dataset is composed of 42,056 profiles
for training and 30,639 for test, with 6,985 unique
skills, 2,241 distinct positions and at least 3 skills for
each profile. Distribution of both skills and positions
is highly skewed: for example, the most recurring po-
sition is “studente” (Italian for student) with 1,693
training profiles and 1,383 test ones, while there are
some positions with only one representative profile.
Job Recommendation from Semantic Similarity of LinkedIn Users’ Skills
273

0.6 0.5 0.4 0.3 0.2 0.1 0.0
impiegata amm.va
professionista nel settore servizi legali
praticante legale
patrocinatore legale
avvocato penalista
praticante avvocato
senior legal counsel
attorney
legal specialist
lawyer
legal advisor
legal counsel
associate
senior associate
avvocato − libero professionista
law practice professional
studio legale
professionista nel settore studio legale
libero professionista giudiziario
praticante avvocato abilitato al patrocinio
professionista nel settore giudiziario
notaio
consulente legale
independent legal services professional
libero professionista servizi legali
avvocato amministrativista
trainee lawyer
independent law practice professional
avvocato cassazionista
avvocato libero professionista
libero professionista avvocato
praticante avvocato abilitato
avvocato civilista
avvocato
libero professionista studio legale
[independent law office]
[lawyer]
[civil lawyer]
[attorney]
[freelance
lawyer]
[cassation lawyer]
[administration lawyer]
[legal advisor]
[notary]
[law office]
[freelance lawyer]
[attorney]
[criminal defense lawyer]
[attorney]
[lawyer]
[legal services professional]
[administration employee]
[legal office
professional]
[attorney]
[judiciary professional]
[judiciary freelancer]
Figure 1: Cluster of legal job positions.
4.2 Positions Hierarchy
We applied the first step of the methodology to infer
a hierarchy of job positions from the training profiles.
The goal of this part is to obtain a consistent folkson-
omy where similar occupations are grouped together
and well separated from unrelated ones.
Due to the absence of a compatible gold standard,
it is not possible to quantitatively evaluate the correct-
ness of the inferred hierarchy. Instead, we browsed
through the obtained tree to check whether the ob-
tained clusters are meaningful. As a sample, we re-
port in Figures 1 and 2 some clusters of the hierarchy
we obtained, also showing the bottom-most binary
splits between elements. As discussed above, tracked
positions have both English and Italian names; we
provide in the figures a translation of the latter ones
for readers’ convenience.
From the first sample, it can be observed that the
clustering algorithm mostly succeeded in outlining
groups of related job positions. As we used the co-
occurrences with skills shared across profiles to infer
the relatedness between positions rather than words
used to express them, similar occupations are effec-
tively grouped into the same cluster, even if expressed
1.0 0.8 0.6 0.4 0.2 0.0
independent telecommunications professional
security
telecommunications professional
personal trainer
computer networking professional
network manager
network engineer
network specialist
cassiere
capotreno
operatrice telefonica
naturopata
panettiere
professionista nel settore media radiotelevisivi
retail professional
[TV/radio media professional]
[baker]
[naturopathy specialist]
[telephone operator]
[train conductor]
[cashier]
Figure 2: Cluster of mixed job positions.
with different terms. For the same reason, equal po-
sitions with distinct English and Italian names are
mostly successfully grouped together as well.
On the other hand, as the sample of Figure 2 sug-
gests, even some unrelated positions have been pos-
sibly grouped together in the clustering. This can be
due to some singularities in the co-occurrences be-
tween skills and positions in our training set. It turns
out that positions associated to a sufficient number
of profiles and skills have a consistent representation,
whereas others that rarely occur throughout the pro-
files are mostly associated to unrelated skills.
For example, by looking at the sample cluster, the
“personal trainer” position has been considered sim-
ilar to occupations dealing with computer networks.
While this appears illogical, the cause can be found
in the profiles used to infer the taxonomy. Of the 9
training profiles having “personal trainer” as the cur-
rent position, two declare IT and telecommunications-
related skills such as “linux” and “tcp/ip”. In a pro-
file set where there are no other occupations signifi-
cantly similar to “personal trainer” with sufficient oc-
currences, this position ends up to be grouped with
unrelated ones due to some profiles declaring their
peculiar skills together, thus erroneously “linking”
them. Another example is the “panettiere” (Italian for
baker) position: only two of our training profiles de-
clare this as current employment. While one of them
explicitly includes “bakery” within abilities, all the
other skills of both are unrelated, mostly consisting
of very generic ones, such as “teamwork” and “prob-
lem solving”, which can be equally linked to other
uncommon positions.
To sum up, the obtained hierarchy successfully de-
lineates a large number of groups of similar job posi-
tions, although with few clusters of unrelated occu-
ICPRAM 2016 - International Conference on Pattern Recognition Applications and Methods
274
pations which are not sufficiently characterized in the
training set. In the following we use this hierarchy to
evaluate recommendations of job positions.
4.3 Results of Job Recommendation
In the second part of our experiments, we com-
puted job recommendations for profiles of the test set,
hereby denoted by U
test
, comparing the answers from
our method with the known ones.
In our experimental evaluation, ignoring further
information, we consider the current occupation of
each person as the correct answer that should be given
by the recommender. However, for a number of rea-
sons, this position can’t actually be with certainty
among the best possible recommendations. As dis-
cussed above, due to use of free text, a position may
have many synonyms and misspelled variants indicat-
ing the same concept but considered as distinct ele-
ments of P . A recommended job may also be strongly
related to the actual one, such that it requires a very
similar set of skills. Ultimately, for practical reasons,
any person may be practicing a job which is notably
unrelated to his or her skills. All these aspects intro-
duce some outliers and potential errors in both train-
ing and test data, which can be detrimental for quan-
titative evaluations of accuracy.
The algorithm can output any number k of most
recommended positions: the known position of any
test profile could either be among them or not. We
want to evaluate for different values of k how much
frequently the recommender hits the actual positions
of test profiles. For all values of k ranging from 1 to
50, we evaluated the recall@k, i.e. the ratio of test
profiles w.r.t. their total for which the known position
is among the top k recommendations.
R@k =
|u ∈ U
test
: p(u) ∈ R
k
(u)|
|U
test
|
(4)
As discussed above, a position given by the
method for a profile may actually be a good recom-
mendation even if different from the known one for
that profile. Specifically, positions that are similar to
the target one are usually equally good recommenda-
tions. We can leverage the previously computed hier-
archical clustering of positions to evaluate how much
a recommended position is close to the actual one. To
this extent, we use the hierarchical recall (hR) mea-
sure proposed in (Silla and Freitas, 2011): given an
actual position p
a
and a single recommendation p
r
,
the hR is the ratio between the depth (i.e. the dis-
tance from the root, denoted here by ∆) of their deep-
est common ancestor (CA) and that of p
a
. For k rec-
ommendations for the same profile, the maximum hR
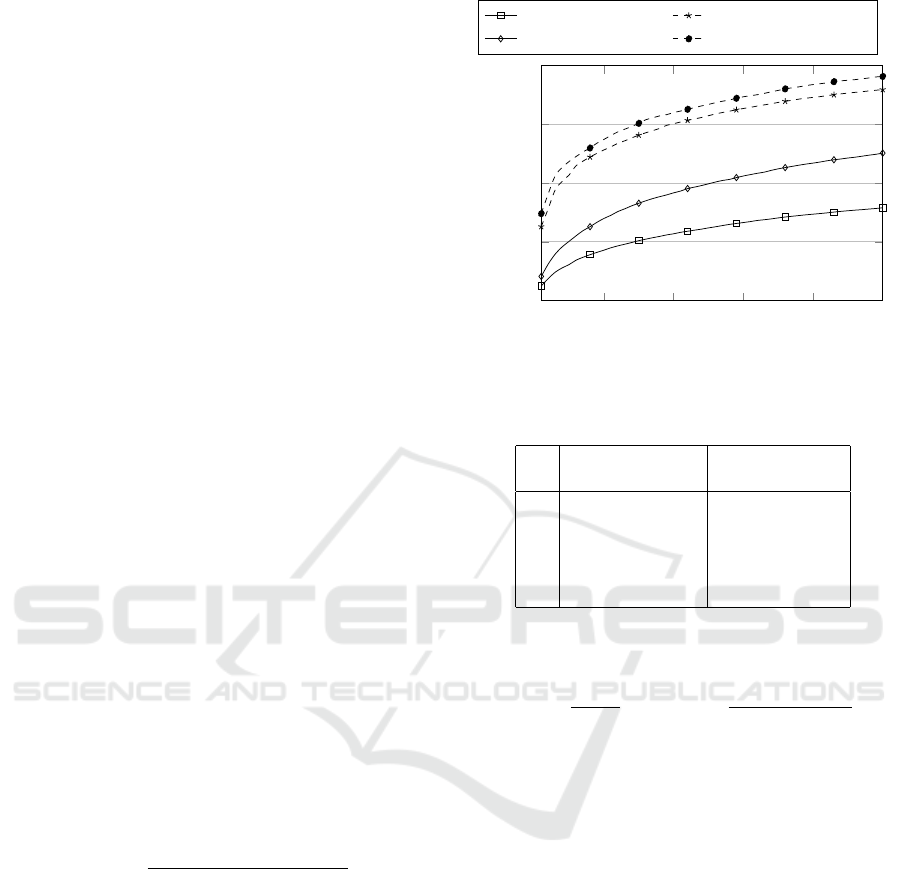
1 10 20 30 40 50
0
0.2
0.4
0.6
0.8
k
R@k / hR@k
R-Original matrix hR-Original matrix
R-LSA matrix
hR-LSA matrix
Figure 3: Trends of standard (solid lines) and hierarchical
(dashed lines) recall for all values of k from 1 to 50.
Table 1: Standard and hierarchical recall for some k values.
Original matrix LSA matrix
k R@k hR@k R@k hR@k
1 0.050 0.252 0.082 0.296
5 0.123 0.428 0.202 0.474
10 0.172 0.513 0.280 0.549
20 0.228 0.602 0.367 0.640
50 0.316 0.718 0.502 0.763
between them is considered; for the whole test set of
profiles, the mean of these results is computed.
hR@k =
1
|U
test
|
∑
u∈U
test
max
r∈R
k
(u)
∆(CA(p(u),r))
∆(p(u))
(5)
Recommendations of job positions for all test pro-
files have been computed using both the described ap-
proaches, i.e. representing positions with either the
original co-occurrences matrix C or its low-rank ap-
proximation C
0
obtained from LSA. In both cases, we
compared recommendations with known positions to
compute both standard and hierarchical recall for all
values of k from 1 to 50. Table 1 reports recall values
for some specific values of k, while the plot in Figure
3 summarizes all the measurements.
The comparison between results obtained with the
two matrices shows that the use of LSA always ap-
pears to be beneficial for the accuracy of the recom-
mendations, as it improves the representation of posi-
tions according to their statistically estimated related-
ness. Considering this, we focus the rest of the analy-
sis on the results for the LSA matrix.
Obviously, the accuracy grows as the number k
of recommendations to be returned is raised, because
it is more likely to hit the exact position or a very
similar one. However, a smaller set of good recom-
mendations can often be more valuable in practice
Job Recommendation from Semantic Similarity of LinkedIn Users’ Skills
275
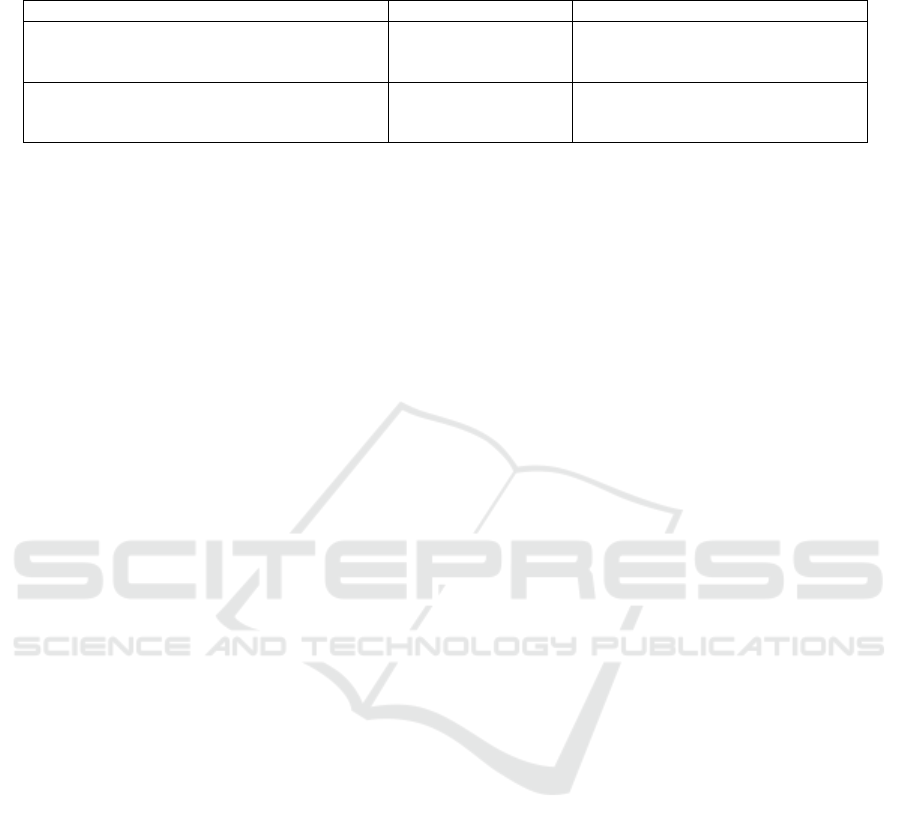
Table 2: Example test profiles with skills, known positions and recommendations. English translations of Italian position
names are reported in italic.
Skills (alphabetical order) Known position Top 3 recommendations
blogging, e-commerce, facebook, responsabile customer (1) marketing manager
marketing communications, marketing strategy, service (customer (2) sales manager
social media, social media marketing service manager) (3) titolare (owner)
adults, mental health, psychology, psychologist (1) psicologa (psychologist, woman)
psychotherapy (2) psicoterapeuta (psychotherapist)
(3) psicologa psicoterapeuta (woman)
than a larger one, which could more likely include
improper elements. Looking at the standard recall,
we see that a single recommendation for each profile
exactly matches the known occupation in 8.2% of the
test cases. As the number of recommendations grows,
the known position is more likely to be hit: this hap-
pens in about one case every five with k = 5, one every
four with k = 8 and one every two with k = 50.
Compare the standard recall to the hierarchical
one for equal values of k, the latter is superior by a
consistent gap, ranging between 21% and 27%. This
suggests that in many cases where the exact known
position is not within the recommendations, at least
one of them is anyway very similar.
This can also be observed by manually comparing
recommendations to known positions. Table 2 shows,
for a couple of test profiles, both the actual known
position and the recommended ones. It can be noted
that, while the method fails at getting the exact oc-
cupation within the very top recommendations, these
are nonetheless positions intuitively quite similar to it
or even synonyms, which are in general equally valid
and plausible for the given skills.
5 CONCLUSIONS AND FUTURE
WORK
We presented a job recommendation system based
on exploiting known co-occurrences between skills
and potential job positions, which are elaborated by
means of LSA to discover latent relationship between
them. We also showed how the same data can be used
to automatically build a folksonomy of job position by
means of hierarchical clustering, in order to discover
groups of related occupations.
The methods have been tested using a set of public
profiles extracted from LinkedIn, naturally subject to
noise and inconsistencies; we only applied a couple of
trivial preprocessing steps to them. Despite this, we
extracted a clustering where most of the groups are
actually composed of related positions.
Concerning recommendations, a quantitative ex-
perimental evaluation trivially based on real job po-
sitions shows promising results, where in half of the
cases the exact actual occupation of a person is within
the top 50 recommended positions out of more than
2,000 possibilities. By leveraging the folksonomy of
positions extracted above and looking at some spe-
cific cases we see that, even when the exact position
name is not hit, homonyms and similar occupations
are generally suggested.
Such a recommendation system can potentially
aid both individuals seeking for occupations where
their abilities can effectively be endorsed and re-
cruiters which have to evaluate the best candidates for
specific positions. The method has no parameter to be
set apart from the number of recommendations to be
returned, so it is simple and ready to use in practice.
One potential direction for further research would
be to devise a method which fits even better to a re-
cruitment system, for example by swapping the roles
of profiles and positions, so that a set of recommended
candidates can be obtained for a given occupation.
Another goal is to increase accuracy of recom-
mendation, for example by testing other machine
learning methods such as nearest neighbour classifiers
or even exploiting the generated hierarchy. Also the
vector representations of profiles, skills and positions
could possibly be improved, for example by borrow-
ing suitable weighting schemes from text categoriza-
tion (Domeniconi et al., 2015).
Finally, we consider to test clustering and rec-
ommendation with more extended datasets, includ-
ing more profiles and possibly further information for
each, in order to improve the results for both tasks.
REFERENCES
Allen, J. and Van der Velden, R. (2001). Educational mis-
matches versus skill mismatches: effects on wages,
job satisfaction, and on-the-job search. Oxford eco-
nomic papers, pages 434–452.
Bastian, M., Hayes, M., Vaughan, W., Shah, S., Sko-
moroch, P., Kim, H., Uryasev, S., and Lloyd, C.
(2014). Linkedin skills: large-scale topic extraction
and inference. In Proceedings of the 8th ACM Confer-
ence on Recommender systems, pages 1–8. ACM.
ICPRAM 2016 - International Conference on Pattern Recognition Applications and Methods
276

Buettner, R. (2014). A framework for recommender sys-
tems in online social network recruiting: An interdis-
ciplinary call to arms. In System Sciences (HICSS),
2014 47th Hawaii International Conference on, pages
1415–1424. IEEE.
Cerroni, W., Moro, G., Pasolini, R., and Ramilli, M. (2015).
Decentralized detection of network attacks through
P2P data clustering of SNMP data. Computers & Se-
curity, 52:1 – 16.
Chi, C.-F. (1999). A study on job placement for handi-
capped workers using job analysis data. International
Journal of Industrial Ergonomics, 24(3):337 – 351.
Chirumamilla, V., Bhagya, S. T., Sasidhar, V., and Indira,
S. (2014). Novel approach to predict student place-
ment chance with decision tree induction. nterna-
tional Journal of Systems and Technologies, 7(1):78–
88.
Davison, H. K., Maraist, C., and Bing, M. N. (2011). Friend
or foe? the promise and pitfalls of using social net-
working sites for hr decisions. Journal of Business
and Psychology, 26(2):153–159.
Dinesh, K. A. and Radhika, V. (2014). A survey on pre-
dicting student performance. International Journal
of Computer Science and Information Technologies,
5(5):6147–9.
Domeniconi, G., Moro, G., Pasolini, R., and Sartori, C.
(2015). A study on term weighting for text catego-
rization: a novel supervised variant of tf.idf. In Pro-
ceedings of the 4th International Conference on Data
Management Technologies and Applications.
Dumais, S. T., Furnas, G. W., Landauer, T. K., Deerwester,
S., and Harshman, R. (1988). Using latent semantic
analysis to improve access to textual information. In
Proceedings of the SIGCHI conference on Human fac-
tors in computing systems, pages 281–285. ACM.
Eckhardt, A., Laumer, S., and Weitzel, T. (2008). Extend-
ing the architecture for a next-generation holistic e-
recruiting system. In CONF-IRM 2008 Proceedings,
page 27.
Elayidom, S., Idikkula, S. M., and Alexander, J. (2011).
A generalized data mining framework for placement
chance prediction problems. International Journal of
Computer Applications (0975–8887) Volume.
Flecke, L. K. (2015). Utilizing facebook, linkedin and xing
as assistance tools for recruiters in the selection of job
candidates based on the person-job fit.
Gupta, A. and Garg, D. (2014). Applying data mining tech-
niques in job recommender system for considering
candidate job preferences. In Advances in Computing,
Communications and Informatics (ICACCI), 2014 In-
ternational Conference on, pages 1458–1465. IEEE.
Kasper, K. (2015). Half of all job seekers arent in it for
the long haul, jobvite job seeker nation study shows.
Retrieved from: http://www.jobvite.com/press-
releases/2015/half-job-seekers-arent-long-haul-
jobvite-job-seeker-nation-study-shows/, 09-09-2015.
Kinder, T. (2000). The use of the internet in recruitment-
case studies from west lothian, scotland. Technova-
tion, 20(9):461–475.
Lee, I. (2007). An architecture for a next-generation holis-
tic e-recruiting system. Communications of the ACM,
50(7):81–85.
Malinowski, J., Keim, T., Wendt, O., and Weitzel, T. (2006).
Matching people and jobs: A bilateral recommenda-
tion approach. In System Sciences, 2006. HICSS’06.
Proceedings of the 39th Annual Hawaii International
Conference on, volume 6, pages 137c–137c. IEEE.
Medsker, G. J., Williams, L. J., and Holahan, P. J. (1994).
A review of current practices for evaluating causal
models in organizational behavior and human re-
sources management research. Journal of Manage-
ment, 20(2):439–464.
Min, H. and Emam, A. (2003). Developing the profiles of
truck drivers for their successful recruitment and re-
tention: a data mining approach. International Jour-
nal of Physical Distribution & Logistics Management,
33(2):149–162.
Paparrizos, I., Cambazoglu, B. B., and Gionis, A. (2011).
Machine learned job recommendation. In Proceed-
ings of the fifth ACM Conference on Recommender
Systems, pages 325–328. ACM.
Rafter, R., Bradley, K., and Smyth, B. (2000). Person-
alised retrieval for online recruitment services. In The
BCS/IRSG 22nd Annual Colloquium on Information
Retrieval (IRSG 2000), Cambridge, UK, 5-7 April,
2000.
Rubin, R. S., Bommer, W. H., and Baldwin, T. T. (2002).
Using extracurricular activity as an indicator of inter-
personal skill: Prudent evaluation or recruiting mal-
practice? Human Resource Management, 41(4):441–
454.
Silla, J. C. N. and Freitas, A. A. (2011). A survey of hier-
archical classification across different application do-
mains. Data Mining and Knowledge Discovery, 22(1-
2):31–72.
Siting, Z., Wenxing, H., Ning, Z., and Fan, Y. (2012). Job
recommender systems: a survey. In Computer Science
& Education (ICCSE), 2012 7th International Confer-
ence on, pages 920–924. IEEE.
Thompson, L. F., Braddy, P. W., and Wuensch, K. L. (2008).
E–recruitment and the benefits of organizational web
appeal. Computers in Human Behavior, 24(5):2384 –
2398. Including the Special Issue: Internet Empower-
ment.
Zide, J., Elman, B., and Shahani-Denning, C. (2014).
Linkedin and recruitment: how profiles differ across
occupations. Employee Relations, 36(5):583–604.
Job Recommendation from Semantic Similarity of LinkedIn Users’ Skills
277
