
DSaaS
A Cloud Service for Persistent Data Structures
Pierre Bernard le Roux
1
, Steve Kroon
1,2
and Willem Bester
1
1
Computer Science, Stellenbosch University, Stellenbosch, South Africa
2
CSIR/SU Centre for Artificial Intelligence Research, Stellenbosch, South Africa
Keywords:
DaaS, SaaS, Cloud Computing, Persistent Data Structure, Version Control System, Hash-Array Mapped Trie.
Abstract:
In an attempt to tackle shortcomings of current approaches to collaborating on the development of structured
data sets, we present a prototype platform that allows users to share and collaborate on the development of data
structures via a web application, or by using language bindings or an API. Using techniques from the theory
of persistent linked data structures, the resulting platform delivers automatically version-controlled map and
graph abstract data types as a web service. The core of the system is provided by a Hash Array Mapped Trie
(HAMT) which is made confluently persistent by path-copying. The system aims to make efficient use of
storage, and to have consistent access and update times regardless of the version being accessed or modified.
1 INTRODUCTION
Collaboration on structured data can be difficult,
time-consuming, and frustrating. For structured data
sets, this usually involves creating multiple copies of
the data and using primitive forms of versioning on
the data set, such as keeping copies of various ver-
sions on multiple computers with different names in
different directories. These approaches often lead to
unnecessary duplication, inconsistencies and inaccu-
racies in the data.
A more sophisticated approach is to use a Ver-
sion Control System (VCS). While this can allevi-
ate some of the problems sketched above, most VCSs
are designed to version control text documents and
source code, where the lines in a file constitute the
units between which deltas—differences in content—
are calculated. Using source code VCSs for other
data works relatively well when the data can be repre-
sented efficiently in tabular form, such as the comma-
separated values (CSV) format understood by many
data analysis applications (Pollock, 2015). However,
in other cases navigating the trade-offbetween storing
large files and the time impact of resolving long delta
chains is non-trivial for large data sets (Bhattacherjee
et al., 2015).
1.1 System Overview
Web-based data services allow developers to read and
write data from a central, shared data service. The
core values of these services are that they allow mul-
tiple clients to concurrently access and modify the
data from anywhere. A developer can then write
a network application—for example, a mobile or a
browser-based application—that accesses and modi-
fies these data structures.
The prototype system we introduce here, referred
to as DSaaS
1
(from “Data Structures as a Service”),
attempts to address the shortcomings of traditional
structured data collaboration techniques by providing
a platform for users to share data structures, and to
collaborate on their development and maintenance.
By using techniques from the theory of persistent
linked data structures, the platform delivers automati-
cally version-controlled abstract data types in a man-
ner similar to a web-based data service.
In particular, DSaaS currently provides access to
cloud-based map (i.e., symbol table) and directed
graph data structures. The map structure was cho-
sen because it is the foundational data structure for
some languages, such as objects in JavaScript (Kan-
tor, 2015) and dictionaries in Python (Python, 2015),
and can be used to implement the array and directed
1
DSaaS can be accessed at http://cs.sun.ac.za/
∼kroon/dsaas.
Roux, P., Kroon, S. and Bester, W.
DSaaS - A Cloud Service for Persistent Data Structures.
In Proceedings of the 6th International Conference on Cloud Computing and Services Science (CLOSER 2016) - Volume 1, pages 37-48
ISBN: 978-989-758-182-3
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
37

graph abstract data types. The directed graph data
structure was developed as a proof of concept of
adding a new data structure to the system by leverag-
ing the map implementation, and facilitates a number
of other linked structures which are special cases of
graphs. DSaaS users can create and share data struc-
tures, and can view and modify any previous version
of any of their data structures via the web interface or
language bindings—currently, a prototype Java lan-
guage binding is provided. Language bindings aim to
facilitate interaction with the data structures stored in
the system by enabling existing code to make use of
the service with only minimal changes relative to pre-
vious use of language-specific data structures. Both
the web interface and the language bindings access
most of the functionality of the DSaaS system via a
RESTful API (Fielding, 2000), which developers can
also use directly.
1.2 Use Cases
DSaaS aims at fine-grained version control for struc-
tured data sets. Below, we outline a few potential ap-
plication areas that could benefit from such a system.
Note that some of these applications could be enabled
using a VCS, but as discussed earlier, such solutions
are not ideal.
First, the approach used in DSaaS enables scien-
tific studies to enhance reproducibility by reporting
the exact version of data used for an experiment or
computation, by providing intermediate results after
various processing or preprocessing steps, and by al-
lowing verification of a computation by investigating
the development of data structures used during its ex-
ecution. The latter can be viewed as an audit trail for
a computation.
The same audit trail perspective highlights poten-
tial uses in teaching programming and debugging.
DSaaS could be used to illustrate how data structures
function by replaying the evolution of a data struc-
ture as various operations are performed on it. Simi-
larly, it could be used as a debugging tool, since it has
the ability to visualize the data structure as it evolves
during use. A benefit of this approach is that debug-
ging could be performed offline, without the use of
watches and breakpoints to interrupt the code execu-
tion.
Since the API and language bindings allow DSaaS
data structures to be used in session-based inter-
preters, such as the IPython interpreter (P´erez and
Granger, 2007), these data structures can be conve-
niently shared and accessed from multiple interpreters
in multiple languages, without the usual developer’s
overhead of serializing and deserializing, or parsing.
1.3 Paper Outline
Section 2 primarily introduces important terminology
and concepts necessary to understand the system im-
plementation. The general architecture of the system
is discussed in Section 3, after which Section 4 de-
tails selected technical aspects of its operation. A
major challenge for DSaaS is providing efficient ac-
cess to and modification of all historical versions of
a data structure while making efficient use of stor-
age. We thus present some preliminary experimental
results in Section 5, illustrating the system’s current
performance and comparing it to another system with
similar aims. An appendix outlines some system fea-
tures and capabilities outside the main scope of the
paper for the interested reader. Note that a project re-
port (le Roux, 2015) contains expanded discussions
of various aspects of DSaaS presented in this paper.
2 BACKGROUND
This section begins by discussing our system’s place
in the landscape of cloud services. Thereafter the
core ideas of persistent data structures are introduced,
including an overview of path-copying, a classical
technique for obtaining persistence of data structures.
Finally, we introduce the Hash Array Mapped Trie
(HAMT), the key data structure used in our imple-
mentation.
2.1 Cloud Service Models
DSaaS combines the Data as a Service (DaaS) and
Software as a Service (SaaS) cloud service mod-
els. It provides DaaS since the data structures it
manages are stored and maintained by the service,
while it provides SaaS because of the service’s web-
based mechanisms for manipulating the data struc-
tures. In this sense, it is somewhat similar to the
GitHub (GitHub, 2015) and Bitbucket (Bitbucket,
2015) services. However, a notable difference is that
while these services allow centralised editing of the
source code, it is not the dominant approach for do-
ing so. In contrast, DSaaS maintains the data struc-
tures centrally, with updates performed via the web
interface and the API.
Other services combining the DaaS and SaaS
models are collaborative document editing services,
such as the office suite component of Google
Drive (Google, 2015), where users can share, view,
and collaborate on documents from multiple devices.
This is almost exactly the type of service DSaaS aims
to provide, except that the objects stored are data
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
38

structures rather than specific document types. Be-
sides that, most collaborative document editing ser-
vices primarily offer partial persistence of documents,
while DSaaS provides confluent persistence of data
structures; see Section 2.2.
The Dat project (Ogden, 2015b) provides version
control for data sets, but with an architectural ap-
proach different to the client–server model we em-
ploy. The similarities are the fine-grained access con-
trol and a dedicated API for managing the data.
2.2 Persistent Data Structures
We next discuss the idea of persistence for data struc-
tures, its various forms, and a technique of persist-
ing pointer-based data. Persistent data structures
have found use in many applications such as func-
tional programming languages, computational geom-
etry, pattern matching, etc. (Straka, 2013). The ter-
minology we use below is based on (Driscoll et al.,
1986).
A data structure that does not provide access
to its history is called an ephemeral data structure.
Ephemeral data structures are changed in-place as
updates occur, and only the most recent version is
ever available. Local library data structure imple-
mentations, such as those in the Java Collections
Framework (Watt and Brown, 2001), are typically
ephemeral.
In contrast, a persistent data structure is a data
structure that provides access to different versions
of a similar (in the sense of expected operations)
ephemeral data structure. For example, a persistent
map data structure provides access to different ver-
sions of a map data structure. When the data structure
is created, it stores only an empty initial version. Sub-
sequent updates lead to new versions of the underly-
ing ephemeral data structure, all of which are stored
implicitly in the persistent data structure. These per-
sistent data structures play a central role in functional
programming languages because they provide an effi-
cient approach to implementing immutability.
2.2.1 Forms of Persistence
There are various forms of persistence:
Partial Persistence permits queries on all the ver-
sions, but only allows modifications to the most
recent version. The version history then forms a
sequence of versions, ordered with respect to tem-
poral evolution.
Full Persistence allows queries of and modifications
to all previous versions of the data structure. With
full persistence the version history forms a tree
r
a
bd
e
c
r
a
bd
e
c
r
′
c
′
f
Figure 1: An example of path-copying in a pointer-based
tree structure. To add a new node f as a child of node c, a
new version is created that can access the new nodes while
still referencing elements from the old version which re-
main unchanged.
where any path from the root to a leaf is ordered
by temporal evolution.
Confluently Persistence data structures are fully
persistent and also support a merge operation that
allows two previous versions of the data structure
to be combined to create a new version of the data
structure. Here the version history forms a di-
rected acyclic graph (DAG).
Our approach in DSaaS was to develop a conflu-
ently persistent map data structure, and use it to im-
plement a confluently persistent directed graph data
structure. This means that the entire development his-
tory of multiple versions of each data structure is al-
ways available, and these versions can be merged to
create new versions. This allows multiple users to
work on the same data structure concurrently.
2.2.2 Path-copying
Path-copying (Driscoll et al., 1986) is a technique for
persisting pointer-based data structures based on the
insight that an update of such a data structure will
typically only affect a small subset of the nodes in
the structure. The path-copying method is thus able
to maintain both the original and new versions of the
data structure by duplicating only the affected nodes.
When a node is duplicated in a new version, all nodes
referencing the previous node must also be modified
to reference the new version. Typically, this leads to
the creation of paths of duplicated nodes, hence the
name of the technique. An example where a new node
is added to a tree is illustrated in Figure 1. As can be
seen in the figure, a new root r
′
and another new node
c
′
are created when the node f is added. These allow
the developer to access the original version of the data
structure from root r and the new version from root r
′
.
2.3 Hash Array Mapped Trie (HAMT)
An HAMT is an implementation of the map data type
that allows fast retrieval of key–value pairs while us-
ing memory efficiently (Bagwell, 2001). Given a
DSaaS - A Cloud Service for Persistent Data Structures
39

...001001
Bitmap
Reference Array
...101000
(k
1
,v
1
)
(k
2
,v
2
) (k
3
,v
3
)
Figure 2: An example of an HAMT. The grey blocks repre-
sent the bitmaps, and the white cells represent the array of
references to key–value pairs stored in this trie.
key–value pair (k, v), the HAMT applies a hash func-
tion h to k, and stores the resulting hash h(k) as an
entry in a compressed trie structure, with the value
associated with that h(k) being the original key–value
pair (k, v). To enable use of a trie structure, the hash
h(k) must be represented as a sequence of characters
from some alphabet. This is done in a straightforward
manner by chunking h(k) into groups of 5 bits. The
HAMT then uses a bitmap in each node to indicate
which children are non-null, while the non-null refer-
ences are stored in a resizable array. These array ele-
ments either refer to other HAMT nodes or directly to
key-value pairs. We illustrate some of these aspects
in the example below—for more information on the
HAMT, see (Bagwell, 2001).
Example 1. Figure 2 gives an example of a two-node
HAMT storing three key–value pairs. For each node,
the bitmap shows the lower-order bits and the ele-
ments of the reference array corresponding to the set
bits. For accessing the HAMT, we chunk the output
of the hash function h from left to right, but positions
in the bitmap are numbered from right to left.
Assume h(k
1
) has
00000
as its first five bits, and
therefore, the numeric value of the first five bits is 0.
Therefore, to retrieve v
1
, one must check if position 0
in the bitmap (i.e., the rightmost position) is set, and
calculate the number of lower-order bits (i.e., bits to
the right of the position) set in the bitmap to identify
which element of the reference array to access. In
the figure, position 0 is set, and the number of lower-
order bits set is 0, so that the key–value pair (k
1
,v
1
)
is stored at position 0 in the reference array.
Now, assume h(k
2
) starts with
00011 00011
, and
h(k
3
) with
00011 00101
. To retrieve v
3
, one first
checks whether position 3—the binary value of the
first five bits of h(k
3
)—in the root node’s bitmap
is set, and then one again calculates the number of
lower-order bits set to find the position of (k
3
,v
3
) in
the reference array. In the figure there is only one
lower-order bit set; therefore the search for v
3
contin-
ues to the node referenced in the root’s reference array
at position 1. This node is queried in a similar way,
but using the next five bits of h(k
3
) to discover that
the bit for position 5 is set, and only one lower-order
bit is set, so that (k
3
,v
3
) can be found at the second
element of the reference array.
Since the HAMT is essentially a tree structure, it
can be converted into a persistent data structure by
path-copying. This is an essential component of the
current DSaaS system.
3 ARCHITECTURE
DSaaS incorporates both client- and server-side soft-
ware. The server provides both static content (mainly
client-side software) and dynamic content to the user.
Client-side software includes a client-side web ap-
plication, as well as language bindings that connect
to the server via the API service. All static content
is available over HTTP, and the dynamic content is
available through both HTTP and web-sockets. The
dynamic content is handled by the API service, which
provides access to all the system features.
When a browser visits the base DSaaS URL, the
web application is downloaded. The web applica-
tion then uses the API service to communicate further
with the server. Third-party systems can also com-
municate with the API service by either using the lan-
guage bindings, making their own HTTP calls to the
API service, or by implementing their own integration
layer to connect with the provided socket.
The next subsection discusses the client tools
available for accessing the service, focusing on the
Java language binding. Thereafter, the components of
the API service are considered.
3.1 Client Tools
The client tools currently included in the system are
the browser-based client application and the Java lan-
guage bindings. The browser-based client application
allows users to share, inspect and manage the con-
tents and properties of data structures to which they
have access. The application, which follows a design
inspired by the Flux architecture (Facebook, 2015),
is served from a static HTTP server and consists of a
combination of JavaScript, HTML, and CSS files.
While many operations can be performed via the
client application in principle, it is impractical to
use the browser for many updates to large-scale data
structures. Thus it is desirable to provide a more
automated mechanism for interacting with the data
structures in DSaaS. As a proof of concept, a proto-
type language binding has been implemented for Java.
This language binding is essentially a wrapper around
the HTTP and web-socket protocols that allows the
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
40
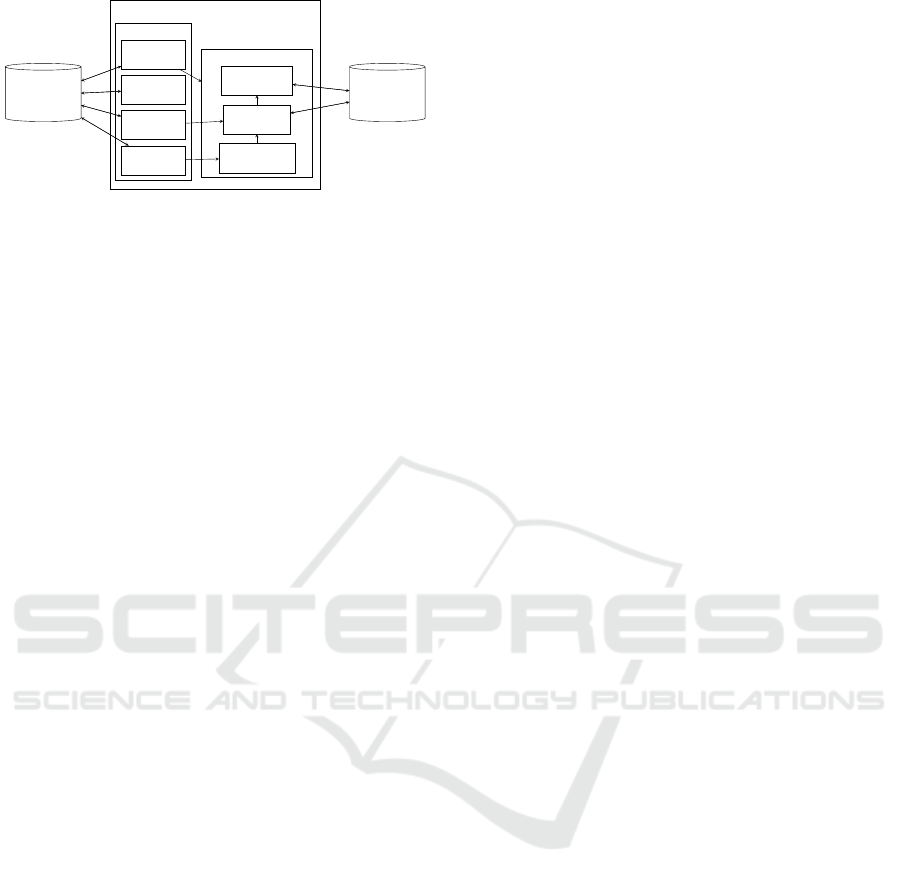
API Service
Key-Value
Database
Document
Database
API Module
General
User
Map
Graph
Data Structure Module
Version History
Versioned Trie
Versioned Graph
Figure 3: Data communication between the components of
the API service and data stores.
data structure updates and query calls to be processed
as a Java application runs.
The aim of language bindings for the service is
to provide access to the service with the least possi-
ble effort from a developer’s perspective. With this
approach, the developers need only initially specify
which data structures and versions they wish to use—
this process is similar to checking out a version in a
Git repository in that it establishes the base version
to which future operations are applied. Once this has
been done, the binding encapsulates the data struc-
ture in a class exposing an API consistent with that
language’s traditional libraries for manipulating and
querying the data structure; in this way, the checked-
out version appears to the developer to be an instance
of the regular (ephemeral) data type.
For example, the Java DSaaS language binding
exposes the map data structure in a class implement-
ing the
java.util.Map
interface. For the directed
graph, there is no standard Java interface, and there-
fore, we defined a suitable interface.
The language binding library automatically
fetches data from the service as the local system needs
it. Lazy local caching of portions of the data structure
is performed to improve performance.
3.2 API Service
We now consider in more detail the architecture of the
API service used by the browser-based client applica-
tion and library bindings. Figure 3 shows the com-
ponents of the API service, which are grouped into
an API module and a data structure module, each of
which is discussed below.
3.2.1 API Module
All operations and features supported by the data
structures are accessed through API requests. Thus all
HTTP requests that interact with the data structures,
as well as user management requests, are handled by
the API module. This module is also responsible for
maintaining a consistent representation of the data on
the client by using web-sockets (Fette and Melnikov,
2011).
The API module consists of multiple handlers.
There are general, graph, map, and user handlers
for the different request types and socket subscrip-
tions. Each handler is responsible for validating and
responding to requests, logging API calls, and keep-
ing track of analytics. The user handler interacts di-
rectly with the document database (discussed in Sec-
tion 3.2.3), whereas most other handlers interact with
both the document database and the data structure
module. The general handler also has the responsi-
bility of pushing real-time version history updates to
subscribed clients via web-sockets.
3.2.2 Data Structure Module
The data structure module consists of versioned trie,
versioned graph, and version history submodules.
The versioned trie, based on a persistent HAMT
obtained using path-copying, is the underlying struc-
ture for exposing a confluently persistent map data
structure to the API. This map implementation pro-
vides the usual operations of inserting, replacing, or
removing a key–value pair, retrieving the value asso-
ciated with a given key, and retrieving a collection of
values, keys, or key–value pairs. The operations for
retrieving collections have additional functionality for
retrieving a range of elements, as opposed to retriev-
ing all elements in one request. All these operations
operate on a specific version of the data structure, and
return either the requested information, or in the case
of an update, an identifier for a new version of the data
structure.
Similarly the versioned graph—which is imple-
mented using the versioned trie as a symbol table to
represent the nodes and the edges of the graph—is the
underlying structure for exposing a confluently per-
sistent directed graph structure to the API. This di-
rected graph data type provides a decorated graph by
allowing the storage of additional data as attributes
of nodes and edges. Typical graph operations, such
as adding and removing a node or an edge, updating
a node’s or an edge’s attributes, and retrieving a col-
lection of nodes or edges, are available, and again,
operate on a specific version of the data structure.
Finally, the version history is used for recording
the relationships between the various versions of each
data structure and is implemented as a directed acyclic
graph. The version history also serves as a visual aid
in the web application, helping the user to navigate
the potentially complex connections between versions
that may arise during use of the data structures.
DSaaS - A Cloud Service for Persistent Data Structures
41

3.2.3 Databases
The primary database used by DSaaS is a NoSQL
key–value data store. For the prototype, Lev-
elDB (Google, 2015) is used because it is a fast
database, and stores keys and values as strings. This
makes it easy to store the JSON representation of the
data structures.
2
The reason a key–value store is used is that the
database should be fast, highly scalable, and as close
as possible to having a distributed array. This makes
translating the data structures from in-memory data
structures to stored data structures less complex. Tra-
ditional relational databases are unnecessary, provid-
ing superfluous functionality.
For the metadata and user data, greater querying
functionality is required to simplify the design; here a
traditional relational database works well. MongoDB
(Membrey et al., 2010) was used as a document store
for storing data related to the user management, data
structure metadata, and logs.
4 TECHNICAL DETAILS
The two most essential components of DSaaS are the
versioned trie and the version history modules. These
are vital to the system’s performance, because they
provide the underlying data structure and operations
necessary for the versioning and storage of the data.
Our versioned trie implementation is inspired by
the Clojure implementation of a persistent HAMT
data structure which is used as its core functional
map data structure (Clojure, 2015). As in Clojure,
we use path-copying for obtaining persistence of the
HAMT. Our implementation differs from a straight-
forward Javascript port of the implementation used by
Clojure in a number of ways: (a) it is implemented to
work on storage instead of directly in memory; (b)
it adds a merge operation that allows combining two
versions to provide confluent persistence; (c) it identi-
fies transpositions of the same data structure (instead
of viewing the same trie obtained through a different
sequence of operations as different); and (d) it keeps
references to the various versions in a navigable graph
structure explicitly by means of the version history
module instead of doing so implicitly. These differ-
ences are discussed in more detail below. We end the
section with a discussion of how the versioned graph
is built using the versioned trie, and considerations for
adding new data structures to DSaaS.
2
Note that while other NoSQL databases might be more
suitable for large-scale deployment, our current interest is
purely in the feasibility of the approach.
4.1 Moving to Storage
Modifying the original HAMT implementation to a
storage-based implementation was done by writing
the data to storage as they are created and only fetch-
ing the necessary values from storage when they are
needed. By employing a key–value store, this process
was fairly straightforward, although it required giv-
ing unique identifiers for all objects stored in the key–
value store. The identifiers used were either hashes of
key–valuepairs for leaf nodes or a uniquely generated
identifier for internal nodes.
4.2 Merging
The system also provides a three-way merge opera-
tion (Santos, 2013) for automatically combining two
different versions, avoiding tedious manual applica-
tion of the primitive data structure operations to one
of the versions to create a combination of the two ver-
sions.
3
The result of the merge operation can be described
as follows. Given two versions L and L
′
, sharing a
common ancestor K, a set of updates K L was ap-
plied to K to create L; similarly, K L
′
was applied
to K to create L
′
. To merge L into L
′
, the set of updates
K L must be applied to L
′
. However, this may lead
to merge conflicts, for example, if L and L
′
both con-
tain the same key, not originally in K, with different
values.
DSaas deals with conflicts arising from the opera-
tion merge(L,L
′
), merging L into L
′
, by giving prece-
dence to the data in the first argument L, which is
called the principal version—that is, the data in L
overrides the data in L
′
(and K). Note that this means
the merge operation is not symmetric in its arguments
in the presence of merge conflicts.
Example 2. An illustration of the merge process is
given in Figure 4, where the map records different
versions of a food order for a restaurant customer:
Map versions B and C are both derived from a com-
mon ancestor version A. The restaurant software
now requests a merge of these two versions. Rel-
ative to the common ancestor A of versions B and
C, it is evident that, to create version B, the value
for the key Food was changed from “Burger” to
“Pizza”, whereas to obtain version C, the key–value
pair (Drink, “Soda”) was removed and the key–value
pair (Extra, “Cheese”) was added (i.e., these are the
3
This merge operation differs considerably from that
proposed in the original literature on confluent persis-
tence (Kaplan, 1995), however: in particular, while their
proposed operation allowed generating data structures with
size exponential in the number of operations, ours does not.
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
42

Version A
Name John
Food Burger
Drink Soda
Version B
Name John
Food Pizza
Drink Soda
Version C
Name John
Food Burger
Extra Cheese
Version D
Name John
Food Steak
Drink Soda
Version E
Name John
Food Pizza
Extra Cheese
Version F
Name John
Food Pizza
Extra Cheese
Figure 4: An example of the three-way merge used in
DSaaS. To merge versions B and C, the changes made since
the common ancestor version A are taken into account. A
merge involving versions D and E involves a conflict, and
the result depends on which version is considered the prin-
cipal version.
changes in A C). The final merged version E takes
all these changes into account. Since there are no con-
flicts between the edits, the result will be the same re-
gardless of whether B is merged into C, or vice versa.
Example 3. Map version D is derived from version
A by changing the key–value pair (Food, “Burger”) to
(Food, “Steak”). A merge involving versions D and
version E features a conflict, as the value of Food
is different in the two maps, and both differ from
the value of Food for their common ancestor ver-
sion A. This conflict is automatically resolved by us-
ing the value from the principal version: merging D
into E via merge(D,E) will result in the key–value
pair (Food, “Steak”) being stored in the merge result,
while merging E into D (as illustrated in Figure 4)
will maintain the key–value pair (Food, “Pizza”) in
the result.
The implementation of merge(L,L
′
) involves first
finding a nearest common ancestor K of L and L
′
, and
then following a recursive merge process on the three
tries representing these three map versions. A nearest
common ancestor K of L and L
′
is a common ancestor
that minimizes the sum of the shortest path lengths
from K to L and from K to L
′
.
4
The process starts by
making a duplicate of the root node at version L
′
—this
4
In general L and L
′
may have multiple nearest common
ancestors, and which one is chosen may subtly influence the
merge result in some cases.
is the entry point to the trie version after the merge
is completed. The system then applies the following
rules for each of the 32 possible bit positions p in the
bitmap of the HAMT nodes for the three versions.
1. (BASE) If p is set only in the bitmap of the node
of L, then the subtrie correspondingto the position
is added to the newly created trie version and p is
set.
2. (BASE) If p is not set in the bitmap of the node of
L, but is set in the bitmaps of the corresponding
nodes of both K and L
′
, and these both reference
the same child node for p, then the subtrie corre-
sponding to that child node’s subtree is removed
from the newly created trie version, and p is unset.
3. When p is set for two or more of K, L, and L
′
,
there is the potential for a conflict. A conflict
arises when the child corresponding to p in the
different trie versions differ. If the child refer-
ences are the same, no conflict arises, and the sec-
ond base case resolves any issues for position p.
Otherwise:
(a) (RECURSE) If all the non-null child references
refer to HAMT nodes, a recursive merge call is
performed on the subtries corresponding to p in
each trie version to construct a new subtrie for
use in the new trie version, and to set (or unset
if the new subtrie is null) p.
5
(b) (BASE) Various intricate cases must be dealt
with carefully to resolve conflicts when one
or more of the non-null child references refers
to a key–value pair. Depending on the case,
this may involve adding (or removing) the key-
value pair to (or from) a corresponding sub-
trie, merging key–valuepairs into a new HAMT
node, or overwriting the value associated with
the key in the new trie version.
4.2.1 Differencing
When dealing with multiple versions of a data struc-
ture, it is also natural to ask what the difference be-
tween two versions is. Therefore, DSaaS provides a
query operation to obtain the difference between ver-
sions of a data structure in a human-readable format:
As with classical text file differencing utilities, the
query output shows which key–value pairs must be
added to or removed from one version to obtain the
other.
The implementation of the difference operation
between two versions follows a procedure similar to
5
Note that in this case, one of the three subtries may be
null.
DSaaS - A Cloud Service for Persistent Data Structures
43

the merge operation, except that the operations re-
quired to transform one version into the other are
recorded and combined into an output string.
4.3 Transpositions
The original HAMT will give different version iden-
tifiers and use space for multiple versions with the
exact same contents if they were created in different
ways. We therefore adapted Zobrist hashing (Zobrist,
1970) for identifying transpositions. Zobrist hashing
is a probabilistic hashing technique which is designed
to incrementally build hashes and is commonly used
in game tree search (Marsland, 1986). This is done by
generating a random bitstring for each new key-value
pair added to the trie. This random bitstring is then
bitwise XOR’ed with the current version identifier to
produce the new version identifier. If a key–value pair
is subsequently removed, its bitstring is once again
bitwise XOR’ed with the current version identifier to
produce the new version identifier. Since the bitwise
XOR is its own inverse, adding a key–value pair and
removing it directly afterwards from an initial version
leads to the same version identifier as the initial ver-
sion. This simple example illustrates the general prin-
ciple: the version identifier will depend on the con-
tent of the version, and not on the path followed to
obtain it. There is a risk of hash collisions with this
scheme where two tries with different contents are as-
signed the same version identifier. However, this risk
can be made vanishingly small by using sufficiently
long random bit-strings (albeit at the cost of increased
computation requirements)—our implementationcur-
rently uses bit-strings of length 64.
4.4 Version History
In order to allow access to previous versions of the
trie, access pointers to previous versions are stored
in nodes of a separate directed graph structure. The
graph itself represents the relationships between the
various versions, where the nodes represent versions,
and edges represent updates to the data structure. For
the map, these updates could be insertion, replace-
ment, or removal of a key–value pair, or a merge op-
eration. This graph structure is explicitly stored in
LevelDB, where every key is a version identifier for
a node and the value is a list of the version identifiers
for the node’s edge destinations. DSaaS can thus pro-
vide an access map of the various versions of the data
structure to the developer by presenting the version
history graph in a navigable format. By having each
user operate in their own namespace provided by the
system, each data structure of each user can be given
its own individual version history.
For classical confluent persistence, the graph rep-
resenting the relationship between various versions is
a directed acyclic graph; however, due to our detec-
tion of transpositions, the possibility of cycles in the
graph arises. This is an interesting technical challenge
for future work; however our current approach is to
discard any edge whose addition to the version his-
tory would create a cycle.
4.5 Versioned Graph
DSaaS provides a versioned graph which employs the
versioned trie to provide a single symbol table for rep-
resenting both the nodes and edges of the graph. In
the case of the versioned graph, typical operations in-
clude adding or removing a node or an edge, or merg-
ing two graph versions. These operations generally
require multiple map operations to complete. While
the intermediate versions of the symbol table during
such an operation are perfectly valid maps, they are
not generally consistent with a corresponding graph
version. Thus, to achieve a suitable granularity for
versioning new core data types, certain lower-level
operations should effectively be grouped into trans-
actions.
The directed graph provides a proof of con-
cept of this approach, grouping the map operations
used when performing a graph operation into a sin-
gle transaction, which then generates a single new
directed graph version corresponding to the single
graph API call. Merging and differencing of ver-
sioned graphs is almost identical to the processes for
versioned tries, due to the use of the versioned trie as
a symbol table for storing the graph nodes and edges.
As a further example, in the context of a binary
search tree (BST), deleting a value from the BST
should be equivalent to creating one new version.
However, if the BST were implemented using a di-
rected graph representation, then the deletion requires
a number of changes to the underlying graph struc-
ture, which without such transactioning would result
in multiple intermediate graph versions being created
which do not represent valid BSTs.
5 EVALUATION
To benchmark the core of our prototype, we ran
some simple tests comparing execution time of the
DSaaS versioned trie and the Dat core library (Ogden,
2015a). We also tested the storage usage of our core
operations. Finally, we evaluated the Java language
binding by comparing access to a local machine and
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
44
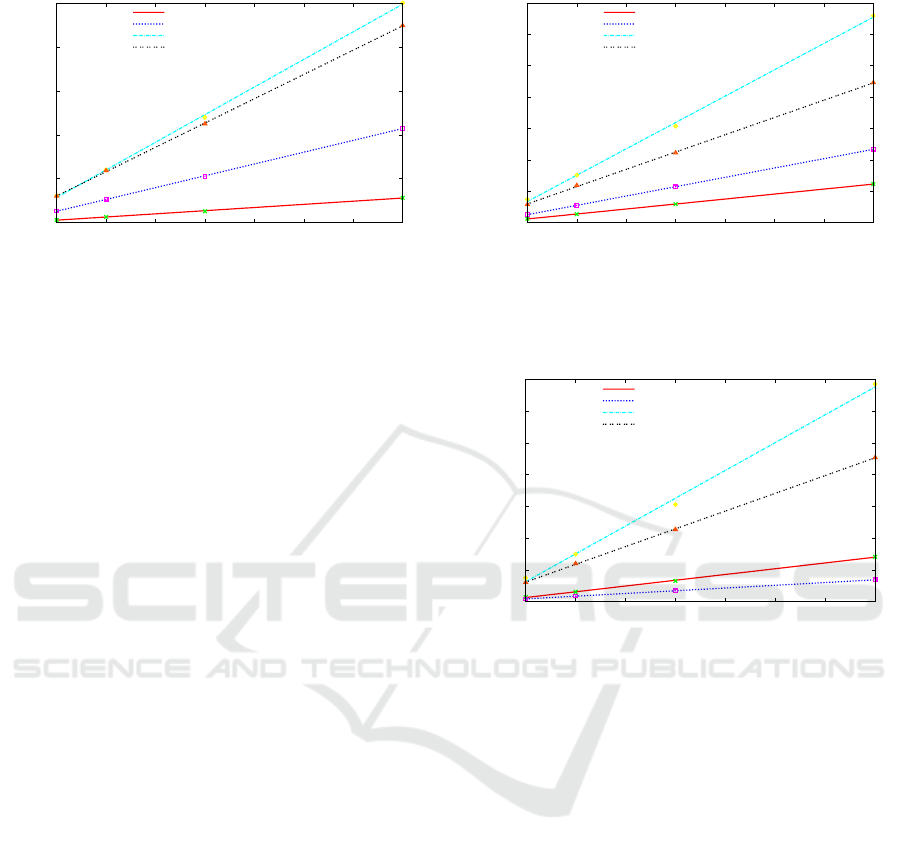
0
5
10
15
20
25
2000 4000 6000 8000 10000 12000 14000 16000
Running Time (seconds)
Number of Key-Value Pair Insertions
DSaaS vs Dat
DSaaS Get
Dat Get
DSaaS Put
Dat Put
Figure 5: Running times for inserting batches of key-value
pairs using the same key with different values and retrieving
the values from different versions at the end.
to a remote server in terms of latency and throughput.
The experiments were run on an Acer Aspire 5750
containing a Core i7 processor, 8GB RAM and 500
GB Seagate Momentus 5400 rpm hard drive.
5.1 Execution Time
The following tests were run on the local machine.
The first test used the core libraries to insert 2 000,
4 000, 8000, and 16000 unique randomstrings in turn
as values for a fixed key into a versioned map pro-
vided by the two systems. Each insertion replaced the
existing value, and resulted in a new version; after-
wards, the value associated with the key was retrieved
for each version.
Figure 5 plots the running times in seconds against
the number of insertions: Insertion times on Dat are
somewhat better than on DSaaS for a larger number
of iterations, whereas retrieval times are faster on the
DSaaS platform than on Dat. This is likely due to
DSaaS doing a single operation to retrieve a key–
value pair from a specified version, as opposed to Dat
having to perform two operations: First, Dat retrieves
the version (this operation is called a checkout) and
then it queries the key–valuepair for the retrieved ver-
sion.
The next test was similar, except randomly gen-
erated keys and values were used instead of a single
fixed key. Retrieval of a key was performed at the ver-
sion it was inserted. Figure 6 plots the results: DSaaS
is slightly slower than in the previous experiment, but
is still faster than Dat during retrieval from different
versions, presumably for the same reason as above.
The final test differed from the second test in that
each key–value pair was retrieved from the final ver-
sion after all the key–value pairs had been added.
From Figure 7, it is evident that the retrieval and in-
sertion times are very similar, and that Dat outper-
0
5
10
15
20
25
30
35
2000 4000 6000 8000 10000 12000 14000 16000
Running Time (seconds)
Number of Random Key-Value Pair Insertions
DSaaS vs Dat
DSaaS Get
Dat Get
DSaaS Put
Dat Put
Figure 6: Running times for inserting different batches of
random key-value pairs, and then retrieving the values from
different versions.
0
5
10
15
20
25
30
35
2000 4000 6000 8000 10000 12000 14000 16000
Running Time (seconds)
Number of Random Key-Value Pair Insertions
DSaaS vs Dat
DSaaS Get
Dat Get
DSaaS Put
Dat Put
Figure 7: Running times for inserting batches of different
random keys and values, and retrieving batches of values
from the final version.
forms DSaaS when it does not have the extra penalty
of checking out a new version before each retrieval.
Therefore, DSaaS is better for manipulating and
accessing various versions—there is no penalty asso-
ciated with retrieving multiple versions. This is im-
portant for DSaaS, as multiple users may be manipu-
lating or accessing the same data structure simultane-
ously and requiring each user to first checkout a ver-
sion would add an unnecessary time penalty.
5.2 Storage Usage
5.2.1 Insertion
The storage usage of the versioned trie was evalu-
ated by sequentially inserting batches of sizes 500,
1000, 2 000, 4 000, 8 000 and 16 000 from a data set
of 165995 payment records made by the County of
Denver (County of Denver, 2015), in each case result-
ing in a linear version history of length corresponding
to the number of the elements inserted. For the ex-
DSaaS - A Cloud Service for Persistent Data Structures
45
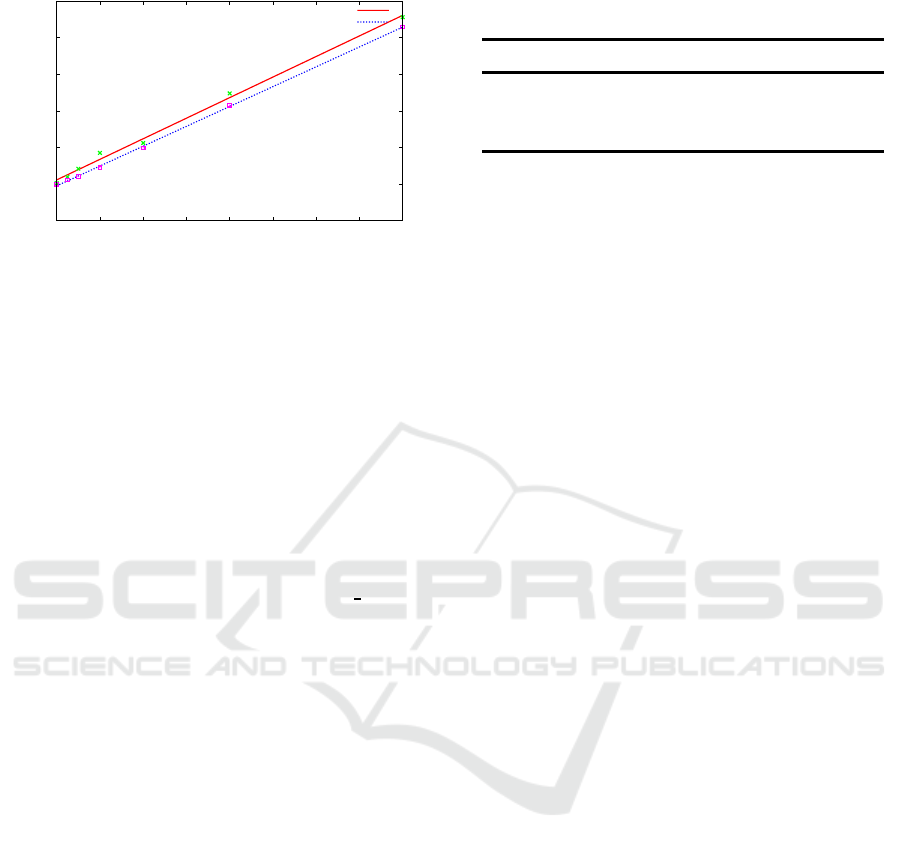
-5
0
5
10
15
20
25
0 2000 4000 6000 8000 10000 12000 14000 16000
Size (MB)
Batch Size
Versioned Trie Size Experiments
Size On Disk
Size from DB
Figure 8: Storage usage when inserting batches of real-life
information into the versioned trie.
periment, the RowID was used as key, and the payee,
funding source, city, and amount were serialized into
a JSON string for use as the corresponding value.
A small program was built using the Java library
binding for sending the experimental data to a local
server. Before inserting each sequence, the directory
containing the database for all the data structures and
version data was cleared. Thereafter, the data struc-
ture was created through the web interface and the
Java program was executed. For each batch size, the
size of the database was found by using LevelDB’s
approximateSize()
, and the size of the
db data
di-
rectory was determined by the Linux command-line
utility program
du
.
Figure 8 plots the data and a least squares linear
fit for each storage metric. As expected, we obtain al-
most exactly linear growth (R
2
= 0.99), with the slope
indicating that everykey–value pair inserted increases
the disk storage used by approximately 1.3 KiB. Since
the average size of a key–value pair in this data set
is 107 bytes, the system can thus store the full his-
tory of the structure with roughly a 12-fold increase
in storage over only storing an ephemeral version in
this case.
5.2.2 Removal
The effect of removal on storage usage was tested by
first inserting elements and then, starting at the last
version, removing all the elements again. This was
done in batches of sizes: 500, 1000, 2 000, 4 000,
8 000, and 16000 from the data set.
Data storage size increases linearly when remov-
ing data; again we give a reminder that we are pre-
serving the entire history as it changes. In this case,
the least squares linear fit (R
2
= 0.99) indicates that
a single removal adds approximately 1KiB of data.
Therefore, bearing in mind that the key–value pairs
used have an average size of 107 bytes, remember-
Table 1: The latency (in ms) for the put operation using
the library binding to connect to a remote server and the
localhost, and using JavaScript to test it on the core system.
Approach Latency (ms)
Remote Server (Library Binding) 206
Localhost (Library Binding) 8
Core (JavaScript) 2
ing a removal in the version history costs the storage
equivalent of 10 data items in the ephemeral structure.
5.2.3 Merging
Next we attempted to evaluate the impact of the merge
operation on the storage required by the system. This
involved adding k distinct elements from the initial
version, where k proceeds over the sequence 500,
1000, 2000, 4000, 8000, and 16000. This was done
in two batches—both batches have unique elements—
creating two final version identifiers. The merge oper-
ation was then applied to the two distinct final version
identifiers, with storage measured before and after the
application of the operation, and the change in data
structure size was recorded for each k.
A linear relationship (R
2
= 0.99) between the
batch size and the increase in storage was found. The
increase in storage was, however, smaller than rein-
serting the items added during the merge: Merging
16000 with 16000 unique elements results in an in-
crease in size of approximately 650KB, equivalent to
approximately 6000 items.
5.3 Latency and Throughput
The Java library binding was used to send requests
to a remote server as well as the localhost in an ef-
fort to measure the latency and throughput of each
request. In addition, the same operations were exe-
cuted using JavaScript to interface directly with the
core versioned trie. The results are summarized in
Table 1. We observe a decrease in performance of
roughly an order of magnitude by employing the API
service, and another order of magnitude by routing
the requests over the network. Addressing these per-
formance degradations will be crucial to making this
system more attractive for practical use.
6 CONCLUSION
This prototype is a step in the direction of a new
service-oriented architecture for enabling collabora-
tion on data structures. We developed a modified im-
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
46

plementation of the HAMT data structure to fit our
needs for a confluently persistent map, and used the
map to implement a confluently persistent directed
graph. We then exposed these data structures, with
additional operations such as merging, differencing
and forking, through an API of a web service than can
be accessed by any web-enabled front-end or through
a library binding.
This prototype can be improved in many ways;
the main focus should be on increasing the system’s
speed and making it more storage-efficient. One op-
tion is experimenting with different implementations
for the core versioned map data structures to iden-
tify the fastest and most efficient implementation. For
example, instead of an HAMT, a fully persistent B-
tree (Brodal et al., 2012) or Stratified B-Tree (Twigg
et al., 2011) could be considered. Another important
task is reducing the latency of the system—this can
be tackled by looking into various ways of optimizing
the library binding, such as using sockets, better local
caching and sending batch requests.
On the front-end, the system can be improved by
adding more data structures; adding better security by
using HTTP(s) and encryption; and improving front-
end performance by maintaining the front-end data in
a data structure similar to the back-end.
ACKNOWLEDGEMENTS
The financial assistance of the National Research
Foundation (NRF) towards this research is hereby ac-
knowledged. Opinions expressed and conclusions ar-
rived at, are those of the author and are not neces-
sarily to be attributed to the NRF. The financial and
spatial assistance of the Naspers Media Lab is hereby
acknowledged.
REFERENCES
Bagwell, P. (2001). Ideal hash trees. Technical report.
http://infoscience.epfl.ch/record/64398/files/idealhas
htrees.pdf [Accessed: 2015-11-07].
Bhattacherjee, S., Chavan, A., Huang, S., Deshpande, A.,
and Parameswaran, A. (2015). Principles of dataset
versioning: Exploring the recreation/storage tradeoff.
In 41st International Conference on Very Large Data
Bases, volume 8, pages 1346–1357, Kohala Coast,
Hawaii.
Bitbucket (2015). Git and mercurial code management for
your team. https://bitbucket.org/ [Accessed: 2015-08-
29].
Brodal, G. S., Sioutas, S., Tsakalidis, K., and Tsichlas, K.
(2012). Fully persistent B-trees. In Proc. 23rd An-
nual ACM-SIAM Symposium on Discrete Algorithms,
pages 602–614.
Clojure (2015). Clojure Source Code of the Persistent-
HashMap.java. https://github.com/clojure/ clo-
jure/blob/master/src/jvm/clojure/lang/Persistent
HashMap.java [Accessed: 2015-11-09].
County of Denver (2015). Denver Open Data Catalog:
Checkbook. http://data.denvergov.org/dataset/city-
and -county-of-denver-checkbook [Accessed: 2015-
10-01].
Driscoll, J. R., Sarnak, N., Sleator, D. D., and Tarjan, R. E.
(1986). Making data structures persistent. In Pro-
ceedings of the Eighteenth Annual ACM Symposium
on Theory of Computing, pages 109–121. ACM.
Facebook (2015). Flux. https://facebook.github
.io/flux/docs/overview.html [Accessed: 2015-05-19].
Fette, I. and Melnikov, A. (2011). The WebSocket
Protocol. RFC 6455 (The WebSocket Protocol).
http://tools.ietf.org/html/rfc6455 [Accessed: 2015-
08-01].
Fielding, R. T. (2000). Architectural styles and the design
of network-based software architectures. PhD thesis,
University of California, Irvine.
GitHub (2015). Github – where software is built.
https://github.com/ [Accessed: 2015-08-29].
Google (2015). Google drive – cloud storage and
file backup for photos, docs and more. https://
www.google.com/drive/ [Accessed: 2015-08-29].
Google (2015). LevelDB. http://leveldb.org/ [Accessed:
2015-05-20].
Kantor, I. (2015). Objects JavaScript Tutorial. http://java
script.info/tutorial/objects [Accessed: 2015-08-30].
Kaplan, H. (1995). Persistent data structures. In Mehta, D.
and Sahni, S., editors, Handbook of Data Structures
and Applications. CRC Press.
le Roux, P. B. (2015). DSaaS: A Cloud Service for
Persistent Data Structures. Honours project report,
Stellenbosch University Computer Science Division.
http://cs.sun.ac.za/∼kroon/dsaas/docs/dsaas
report.pdf
[Accessed: 2016-02-15].
Marsland, T. A. (1986). A review of game-tree pruning.
ICCA Journal, 9(1):3–19.
Membrey, P., Plugge, E., and Hawkins, D. (2010). The
Definitive Guide to MongoDB: the NoSQL Database
for Cloud and Desktop Computing. Apress.
Ogden, M. (2015a). maxogden/dat-core. https://github
.com/maxogden/dat-core [Accessed: 2015-08-13].
Ogden, M. (2015b). Versioned Data, Collaborated.
http://dat-data.com/ [Accessed: 2015-08-13].
P´erez, F. and Granger, B. E. (2007). IPython: a system for
interactive scientific computing. Computing in Sci-
ence and Engineering, 9(3):21–29.
Pollock, R. (2015). Git and GitHub for data.
http://blog.okfn.org/2013/07/02/git-and-github-
for-data/ [Accessed: 2015-08-30].
Python (2015). Built-in Types – Python 2.7.10
documentation. https://docs.python.org/2/library/std
types.html♯mapping-types-dict [Accessed: 2015-08-
30].
DSaaS - A Cloud Service for Persistent Data Structures
47

Santos, P. (2013). Three-Way Merge.
http://www.drdobbs.com/tools/three-way-merging-
a-look-under-the-hood/240164902 [Accessed:
2016-02-11].
Straka, M. (2013). Functional Data Structures and Algo-
rithms. PhD thesis, Computer Science Institute of
Charles University, Prague.
Twigg, A., Byde, A., Milos, G., Moreton, T., Wilkes, J., and
Wilkie, T. (2011). Stratified B-trees and Versioned
Dictionaries. In Proceedings of the 3rd USENIX Con-
ference on Hot Topics in Storage and File Systems,
HotStorage, volume 11, pages 10–10.
Watt, D. A. and Brown, D. (2001). Java Collections: an
Introduction to Abstract Data Types, Data Structures
and Algorithms. John Wiley & Sons, Inc.
Zobrist, A. L. (1970). A new hashing method with applica-
tion for game playing. ICCA Journal, 13(2):69–73.
APPENDIX
This appendix discusses a number of additional as-
pects of the DSaaS system potentially of interest to
the reader, but not central to the main paper.
Access Control
Since DSaaS is a web application providing a service
to multiple users, it is imperative to ensure users are
only granted access to data at a level corresponding to
the permissions allocated to them.
Registration and authentication for the system is
currently handled using Google’s single sign-on au-
thentication service, with each user selecting a unique
namespace during registration. Each data structure
is allocated to its creator’s namespace, and the data
structure is also given a unique identifier, as speci-
fied by the creator, within the namespace. This makes
it possible to identify a data structure unambiguously
by its namespace and data structure identifier.
Various access levels—none, read, read/write, and
administration—specify the actions any given user
can perform on a particular data structure. The cre-
ator of a data structure automatically has administra-
tor access, whereas other users have none by default.
An administrator of a data structure may modify the
access level of other users—the common usage of
granting new users read or stronger access is called
sharing—and also has access to modify selected prop-
erties of the data structure.
To facilitate wider sharing beyond the fine-grained
mechanism above, two special users are defined.
The special user “registered” represents all registered
users of the system. Since the system can also be used
without registration, the special user “public”, which
represents all users of the system—including casual,
unregistered visitors—is also defined.
Data Freedom
A forking feature is provided to enable duplication
of data structures. Forking creates a virtual copy of
a data structure. The virtual copy mechanism used
saves space by duplicating the version history of the
data structure, without duplicating the underlying per-
sistent data structure. Since each version stored by
the versioned trie is immutable, the developer of the
forked version can carry on applying updates and the
original trie will not be influenced.
Pull requests and changes—which allow the
changes made to a forked data structure to be incor-
porated into the original— could be added as future
improvements.
Besides forking, a user may wish to extract a
data structure from the system for offline storage or
use. Alternatively, a user may wish to import a pre-
viously exported data structure, or even import data
from other sources. To facilitate this, DSaaS provides
an export operation which allows users to download
a JSON-formatted version of a data structure and its
history. Such a file can also be imported into the sys-
tem; however, importing data in other formats is not
yet supported. Note that exporting and re-importing
a data structure is essentially the same as completely
duplicating (not forking) the data structure.
REPRODUCIBILITY
The prototype DSaaS system is open source, and all
code is available at https://bitbucket.org/dsaas/. The
code repositories include code for the client applica-
tion, the server, and the language bindings, as well as
testing code and code used for performing the experi-
ments in this paper—note that in all cases the reposi-
tory version used for experiments is tagged as “closer-
article”.
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
48
