
Evaluating the Cloud Architecture of AToMPM
Jonathan Corley
1
, Eugene Syriani
2
and Huseyin Ergin
1
1
Department of Computer Science, University of Alabama, Tuscaloosa, AL, U.S.A.
2
Department of Computer Science, University of Montreal, Montreal, Canada
Keywords:
Multi-view, Multi-user, Collaboration, Architecture, Volume Testing, Stress Testing.
Abstract:
In model-driven engineering, stakeholders work on models in order to design, transform, simulate, and analyze
systems. Complex systems typically involve many stakeholder groups working in a coordinated manner on
different aspects of a system. Therefore, there is a need for collaborative platforms to allow modelers to
work together. Previously, we introduced the cloud-based multi-user tool AToMPM, designed to address the
challenges for building a collaborative platform for modeling. This paper presents on the multi-user, multi-
view architecture of AToMPM and an initial evaluation of its performance and scalability.
1 INTRODUCTION
Complex systems engineering typically involves
many stakeholder groups working in a coordinated
manner on different aspects of a system. In a model-
driven engineering (MDE) context, engineers ex-
press their models in different domain-specific lan-
guages (DSLs) to work with abstractions expressed
in domain-specific terms (Combemale et al., 2014).
Recently, there has been a growing trend toward
collaborative environments especially those utiliz-
ing browser-based interfaces (e.g., Google Docs or
Trello
1
). Additionally, this trend can be seen in
software development tools, such as Eclipse Che
2
.
Cloud-based technology to support collaboration has
also started to gain interest in the MDE com-
munity (Paige et al., 2014). Example tools are
AToMPM (Syriani et al., 2013), cloud-based multi-
user web interface for modeling and transformations,
and WebGME (Mar
´
oti et al., 2014), a web-based col-
laborative modeling environment.
These collaborative environments bring new con-
cerns. Modeling tools, frameworks, and language
workbenches typically consider all developed arti-
facts as models. Although users believe they are
working on distinct models, there is a single under-
lying model (Atkinson and Stoll, 2008) that ensures
consistency among the users. Users effectively oper-
ate on a view, projection of the model, that shows a
1
docs.google.com, www.trello.com
2
https://eclipse.org/che/
portion of the model in its own concrete syntax repre-
sentation.
This paper focuses on the multi-user capabilities
of AToMPM. In previous work (Corley et al., 2016),
we presented in detail the four collaboration sce-
narios that the multi-view modeling enhancement of
AToMPM supports: (1) two users are working on the
exact same artifact simultaneously; (2) two users are
working on different parts of the same artifact; (3) two
users with different expertise are working on distinct
artifacts that, together, compose the overall system;
and (4) one user is working on a view that projects
two models, while another user is working on a view
of one of these models. These form the functional
requirements of our architecture. In contrast, this pa-
per focuses on the non-functional requirements of the
architecture described in Section 2.
In order to ensure consistency and synchroniza-
tion among the artifacts produced by each stake-
holder, we favor a cloud-based environment. In previ-
ous work (Corley and Syriani, 2014), we presented an
early prototype of the multi-view modeling architec-
ture of AToMPM. In this paper, we present an updated
version of the architecture that provides modeling as a
service (i.e., multi-user, multi-view modeling storage
and processing capability) to any client able to main-
tain a connection with the system (e.g., browser-based
clients, mobile and tablet clients, and traditional desk-
top clients). Moreover, the primary contribution of
this paper is an evaluation of this architecture with
regards to performance as the number of users in-
creases, described in Section 4.
Corley, J., Syriani, E. and Ergin, H.
Evaluating the Cloud Architecture of AToMPM.
DOI: 10.5220/0005776903390346
In Proceedings of the 4th International Conference on Model-Driven Engineering and Software Development (MODELSWARD 2016), pages 339-346
ISBN: 978-989-758-168-7
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
339

2 NON-FUNCTIONAL
REQUIREMENTS
The primary guiding concern driving this work is to
create a system that can support collaboration and
modeling where it is most natural to the users.
2.1 Responsiveness
A primary concern for our architecture is to provide
an acceptable level of responsiveness. Most opera-
tions on models in AToMPM, such as model trans-
formations and larger distributed processes and stor-
age, are based on CRUD (create, read, update, delete)
operations, it is imperative to ensure these operations
are processed in a minimal amount of time. A user
across a session will make many individual CRUD
operations, thus these operations should not present
a notable delay in the users process.
2.1.1 Models and Views in AToMPM
Two modelers working within a shared artifact to col-
laborate on a larger project may not always share
the same focus, working with subsets of the same
model. Alternatively, modelers may desire to visu-
alize a model for varying purposes. AToMPM utilizes
views to provide each modeler with the capability to
refine the scope and style of visualization when work-
ing on shared artifacts. A specific view may contain
only a portion of a model or utilize a distinct visual-
ization.
In AToMPM, models are separated into two cate-
gories: abstract models and views. This distinction
allows modelers to work with portions of a model
and use distinct representation, arrangement, and siz-
ing for the elements of their view; AToMPM exclu-
sively supports a graphical syntax for models. Thus,
stakeholders are able to share models, allowing mod-
elers with varying skills to work collaboratively on the
same model. An abstract model is the abstract syntax
of a model conforming to the metamodel of a given
DSL. Conceptually, a view is a projection of an ab-
stract model onto a DSL that uses the most appropri-
ate representation of a subset of the model’s elements
for the needs of the expert modeler working on that
part of the model. A view references a set of elements
from the abstract model. The view also maintains a
list of other models necessary to use the specific view,
including a concrete syntax model. By varying the
concrete syntax between views, different users may
view the same model in their own notations (e.g., Eu-
ropean vs. American notations for electrical circuit
diagrams). Finally, the view includes a mapping of
model elements to concrete syntax information, since
these mappings are specific to a view of the model.
These mappings might include the absolute position,
rotation angle, and size scaling of the element.
2.2 Managing Conflicting Requests
As the number of concurrent users accessing a shared
resource increases, conflicting requests become in-
evitable. Managing conflicting requests is a primary
concern for systems enabling shared access to re-
sources. However, the architecture is designed to pro-
cess requests based on order of arrival: every request
will either succeed or fail based on the conditions of
the model at the time it is processed. We chose this
opportunistic method of conflict management to al-
low automatic resolution of all requests and improve
responsiveness. The architecture focuses upon resolv-
ing all messages with minimal processing to preserve
responsiveness. This focus on responsiveness also
works to reduce the possibility of conflicting requests.
Decreasing time spent processing and providing up-
dates to the user more quickly both decrease the win-
dow in which users may provide conflicting requests.
If the time to process a request and then update all
clients is one second, then a conflicting request must
occur within one second of the prior request.
However, the client systems may still detect fail-
ures or even lost updates (a scenario where a second
update overwrites a prior update before the second
user is made aware of the first update), because the
architecture provides continuous updates to all rele-
vant users as each request is made by any user. When
a user creates an element, all users receive an up-
date stating the element has been created. The client
system may take advantage of this stream of updates
to identify conflicting requests and provide more ad-
vanced and costly methods of conflict management,
but we did not implement any yet. In case of conflicts
that cannot be automatically resolved, the client sys-
tem enables users to interact with each other directly
via an instant chat window, so they can manage such
conflicts themselves.
3 MODELING AS A SERVICE
In this section, we present the architecture of
AToMPM. This architecture has been designed to re-
solve the challenges of providing an efficient multi-
user, multi-view modeling environment. The compo-
nents of this architecture are client systems, Model-
verse Kernel (MvK), and a set of controllers coor-
dinating the other two components. The three com-
MODELSWARD 2016 - 4th International Conference on Model-Driven Engineering and Software Development
340

ponents communicate by exchanging change logs en-
coded in JSON that contain all the necessary informa-
tion to perform a task, or undo it. The design provides
modeling as a service through a distributed network
of controllers managing the concerns of a multi-user,
multi-view modeling system, being independent from
the implementation of the client.
The Modelverse (Van Mierlo et al., 2014) is a
centralized repository to store and manipulate mod-
els and provides an API, the MvK, that processes all
modeling actions; e.g., primitive requests on and ex-
ecution of models that are stored in the Modelverse.
AToMPM includes a default web client, but the under-
lying architecture supports a wide variety of clients by
exposing a simple API with connections and trans-
missions made using 0MQ
3
, an open source socket
messaging library with support for a large variety of
languages and platforms.
3.1 Controllers
The controllers of the architecture encompass a series
of distinct controllers that ensure consistency among
clients, view(s), and model(s). A user can perform
CRUD operations, load a model, add or remove ele-
ments from a view, execute a model or set of models,
and more. These requests are sent into the system
through a message forwarder that routes messages to
the proper controller for processing. Reciprocally, a
response forwarder returns responses to clients. This
pattern enables clients and controllers to subscribe to
messages regarding any number of specific views of
models without needing to connect to the dynamically
spawned controllers that manages the relevant views
and abstract models.
3.1.1 Model Controller
The model controller provides a layer above the MvK
that incorporates multi-user, multi-view modeling. A
model controller manages a given model and all views
of that model, and there exists one model controller
per active abstract model. In this way, the process-
ing of concurrent user requests is distributed based on
the artifacy being used. However, all requests for a
given model are managed by a single controller en-
suring consistency for the model and the associated
views. Whenever a model operation alters a portion
of the abstract model, the resulting changelog is pub-
lished to all that have subscribed to a view that ref-
erences the updated portion of the model. The view
operations are guaranteed to have no side effect on the
model and thus do not need to update users of other
3
http://zeromq.org/
views. Load and read requests are performed directly
at the model controller, which are resolved locally us-
ing cached information. For all other operations, the
model controller coordinates the processing of primi-
tive operations within the MvK. Model controllers en-
sure that a sequence of primitive operations is valid
and separates models from views, whereas they are
treated uniformly within the MvK.
To enable automatic resolution of conflicting mes-
sages, the model controller guarantees one message
must complete successfully (win) and other conflict-
ing messages will fail. Incoming client changelogs
are queued to be processed using a FIFO strategy.
Thus, operations that originate from clients sending
a changelog may fail based on the results of a previ-
ous message. By allowing the earlier message to win,
the system does not need to process any rollback op-
erations due to conflicting messages. This scenario
of conflicting messages is mitigated in practice by the
publishing update messages to ensure all users main-
tain a consistent copy of the model. Thus, even if
multiple users send conflicting messages simultane-
ously, the users will be notified of the resolution for
all messages. Furthermore, because users are notified
of all updates immediately, the likelihood of generat-
ing conflicting messages is minimized.
3.1.2 Supercontroller
Model controllers manage all model and view related
operations. For each model, there exists exactly one
model controller. However, the system may have any
number of models. If the system maintained these
model controllers at all times, a significant amount
of resources would be wasted on model controllers
that are not in use. To mitigate this issue, we spawn
model controllers as needed on a distinct processor.
Controlling which model controllers are active and
assigning the model controllers to resources is the pri-
mary responsibility of the supercontroller. The super-
controller ensures there exists at most a single model
controller for a given abstract model and its related
view(s), and it monitors all client changelogs enter-
ing the system. When a client changelog is encoun-
tered that requires a model controller not yet spawned,
the supercontroller manages spawning the model con-
troller. Additionally, the supercontroller ensures all
client changelogs received during the spawning pro-
cess are queued and forwarded after the model con-
troller is sucessfully spawned. Any client changelog
intended for an active model controller is ignored by
the supercontroller.
Evaluating the Cloud Architecture of AToMPM
341

3.1.3 Node Controllers
When a model controller is spawned, it is assigned to
a node controller. Node controllers are abstract repre-
sentations of available hardware computing resources
(e.g., nodes in a cluster, CPUs, cores), and provide an
interface to these resources for the supercontroller.
4 EVALUATION
This section presents an empirical evaluation of the
architecture, focusing on the Controllers, targeting
two key concerns: communication time for transmit-
ting requests and processing time for handling re-
quests transmitted. AToMPM is evaluated through a
series of experiments where the size of models and
number of concurrent users are varied independently.
These experiments exercise the system in a wide va-
riety of expected conditions including worst case sce-
narios to evaluate the performance of the system. This
serves as volume and stress testing of the MVC archi-
tecture of AToMPM. We conducted three experiments
to answer the following research questions: (RQ1)
How does the architecture scale regarding the number
of concurrent users? (RQ2) How effective is the ar-
chitecture in responding to a user request as the size
of the model increases?
4.1 Setup
The supercontroller was running on a dual-core ma-
chine (3.33 GHz, 4GB RAM) and the MvK on a
quad-core machine (3.1 GHz, 8GB RAM). Two dual-
core machines (3.33 GHz, 4GB RAM) and a quad-
core machine (2.4 GHz, 8Gb RAM) were simulating
users to have true concurrency. The node controllers
were running on three dual-core machines (3.33 GHz,
4GB RAM) and a quad-core machine (3.1 GHz, 8GB
RAM).
This resulted in a load of 50 users and 50 model
controllers per machine for each experiment. The ex-
periment setup preloaded all users, model controllers,
and models in the MvK before measuring. This
warmup phase put the system in an average expected
case; i.e., how the system would perform after ini-
tial requests for each model controller. The startup
time for a model controller is significant at approx-
imately 2-3 seconds to spawn its process and some
additional time spent building the cache of elements
for the model and initial view. For all experiments,
we used the same basic Petri net model with vary-
ing numbers of places (duplicated when necessary to
have multiple models). Note that all views referenced
every element of the associated abstract model. Thus,
we measured the worst case scenario for performance.
4.2 Experiments
Each of the following experiments varied the num-
ber of concurrent users and model size independently.
The variable for number of concurrent users is U =
1, 25, . . . , 200 with increments of 25. The variable for
model size is N = 1, 50, . . . , 200 with increments of
50. Here N represents the number of places (i.e., el-
ements) in the Petri nets model. We conducted three
experiments. Each experiment varied the resources
shared by the users. However, all users send a series
of load, create, and delete requests. Load is a read all
request sent to obtain an initial version of the model.
Create is the most expensive single element operation.
Delete is the least expensive single element opera-
tion. The load requests have a list of N dictionaries
for a model of size N with each dictionary containing
the relevant information for a specific model element.
Each request is repeated 10 times by each user to min-
imize random machine and network effects on trans-
mission time. Furthermore, all transmission were per-
formed on a LAN to minimize network latency and
routing effects on transmission time. In Experiment
1, each user connects to the same view of the same
model. In Experiment 2, each user connects to a dis-
tinct view of the same model. In Experiment 3, each
user connects to a distinct view of a distinct model.
Experiments 1 and 2 are designed to simulate col-
laboration scenarios 1 and 2. However, experiment 3
is not a precise simulation of scenario 3. Experiment
3 simulates multiples users accessing distinct models
(where each model has its own view), but the models
are not related, as described in collaboration scenario
3. Experiment 3 presents a near-simulation of the sce-
nario to provide an initial evaluation of the scaling as
the number of concurrent users increases. Designing a
set of related models scaling from 1-200 models in the
set is not feasible and would likely present additional
factors impacting scaling. These experiments are de-
signed primarily to focus on the performance scaling
of the system as the number of concurrent users is in-
creased and how the specifics of a collaboration sce-
nario impact the performance scaling.
4.3 Results
Before discussing the three experiments, we evaluate
the Controllers in a best case scenario without net-
work overhead in the communication with the MvK
and with a single user accessing an existing model
controller (i.e., the model controller had already been
MODELSWARD 2016 - 4th International Conference on Model-Driven Engineering and Software Development
342
0
5
10
15
20
25
30
35
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000
Request Duration (ms)
Model Size
Create Load Update
Figure 1: Create, Load, and Delete requests on a model
controller with local MvK.
0
100
200
300
400
500
600
700
800
900
1000
1
50
100
150
200
1
50
100
150
200
1
50
100
150
200
1
50
100
150
200
1
50
100
150
200
Request Duration (ms)
Model Size
# Concurrent User Requests
1 50 100 150 200
Figure 2: Results for experiment 1: Create Request.
spawned and loaded its local caches before the user
request). The results of the best case scenario (pre-
sented in Figure 1) establishes a baseline of process-
ing capability for the system. The time to load a view
and the related model pair depends on the size of the
model. We measured approximately 3-4ms per 1,000
elements loaded, but this time will vary slightly de-
pending on the performance capability of the com-
puting resources (we used a machine with 3.33 GHz
processor speed and 4GB total RAM). Both create
and delete requests took a relatively constant amount
of time regardless of model size. Minor variances
were noted, but with variances from the norm being
no more than 3-5ms these variances can be attributed
to random variance in system performance. Create
requests are not affected by the size of the model, but
are slower than delete requests. The time to perform
a load request is linear with respect to the size of the
model, because load requires accessing each element
in the model. Also, unlike the other three operations,
load bypasses the MvK using a cache in the model
controller.
Experiment 1. demonstrates an approximately
constant response time except at 1 user for all oper-
ations. We only show the create operations in Fig-
ure 2 since delete and load performed similarly to
create. Smaller model sizes have a lot of variance,
because the network communication is predominant.
The most important result of experiment 1 is the large
0
500
1000
1500
2000
2500
1
50
100
150
200
1
50
100
150
200
1
50
100
150
200
1
50
100
150
200
1
50
100
150
200
Message Duration (ms)
Model Size
# Concurrent User Requests
1 50 100 150 200
(a) Create request
0
300
600
900
1200
1500
1
50
100
150
200
1
50
100
150
200
1
50
100
150
200
1
50
100
150
200
1
50
100
150
200
Message Duration (ms)
Model Size
# Concurrent User Requests
1 50 100 150 200
(b) Load request
Figure 3: Results for experiment 2.
ranges for most runs. All runs contain approximately
1,500 data points which are typically uniformly dis-
tributed over a wide standard deviation. The aver-
age coefficient of variance (CoV) across all runs was
63.5% and the median CoV was 46.6%. The large
variation is due to the fact that all messages are be-
ing sent at approximately the same time, similar to
a distributed denial-of-service. This results in mes-
sages being queued at the model controller and MvK
which must be processed sequentially. The variance
grows more significant as the number of users in-
creases: i.e., the number of messages received concur-
rently increase. Experiment 1 and 2 share this quality
due to their design: all users are on the same abstract
model, thus both experiments will be processed by a
single model controller. Nevertheless, all clients re-
ceive their response within less than a second. We
expect relatively small numbers of users (e.g., less
than 10) per Model Controller. Thus, we have de-
signed for consistency when multiple users access the
same model, but we have not focused on distributing
the processing within a model controller to efficiently
manage large numbers of users concurrently collabo-
rating on a single model.
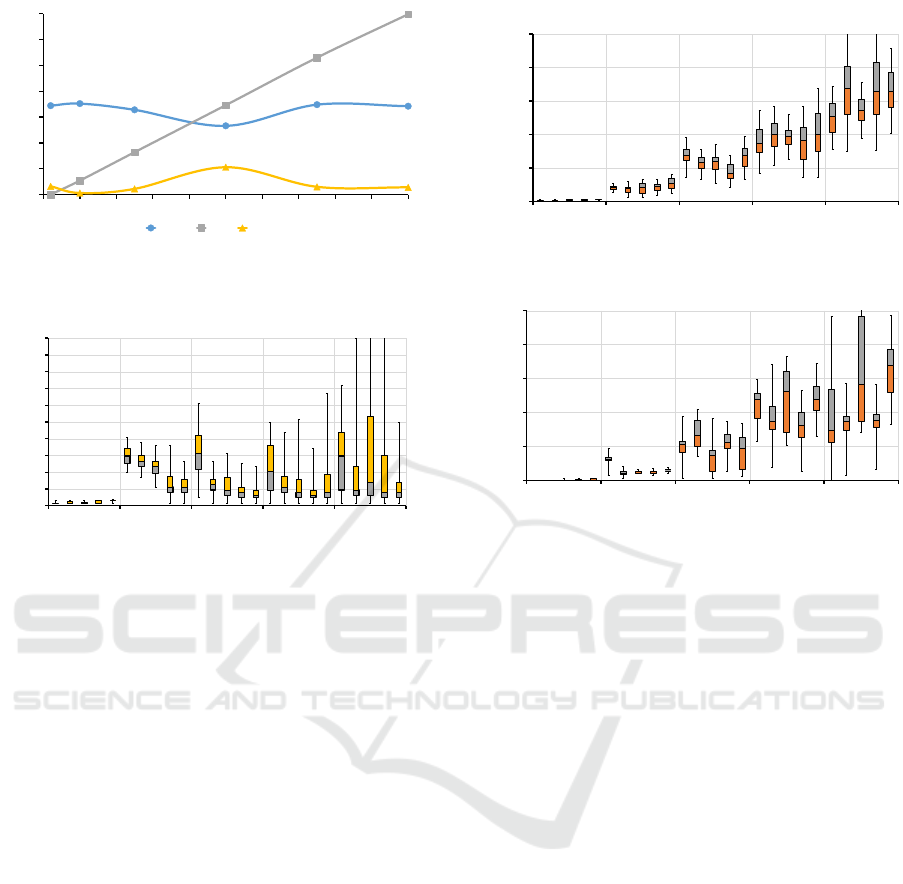
Experiment 2. demonstrates a linear increase as
the number of users increases, but again model size
has little to no impact (depicted in Figure 3). Load op-
erations, which ignore the MvK, scale similarly albeit
Evaluating the Cloud Architecture of AToMPM
343
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
1
50
100
150
200
1
50
100
150
200
1
50
100
150
200
1
50
100
150
200
1
50
100
150
200
Request Duration (ms)
Model Size
# Concurrent User Requests
1 50 100 150 200
(a) Create request
0
2
4
6
8
10
12
14
0 50 100 150 200
Request Duration (ms)
Concurrent Users
Model Size 1 Model Size 50 Model Size 100 Model Size 150 Model Size 200
(b) Load request
Figure 4: Results for experiment 3.
slightly improved compared to the create requests.
Thus, the bottleneck lies in how the model controller
is managing multiple concurrent views.
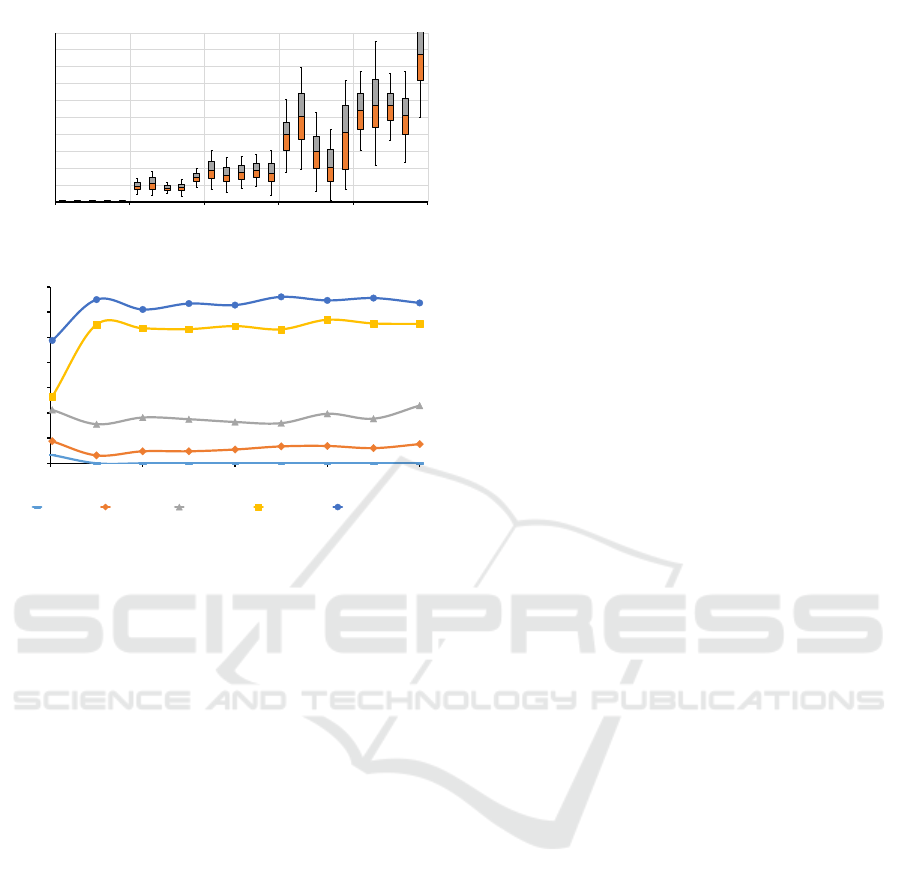
Experiment 3. is designed to test the scalability
in the expected case where users are more evenly dis-
tributed across model controllers. In Figure 4, load
is constant with respect to the number of concurrent
users. However, the other operations perform slowly,
taking at least a second. The main reason for that is
the current implementation of the MvK. Although the
Controllers are a distributed system, the MvK queues
all request and processes them sequentially. We ex-
pect improved performance of these operations once
the MvK is moved to a distributed design.
4.4 Discussion
In the following, we discuss the implications of our
results with regard to our two identified research ques-
tions.
RQ1. Experiment 1 for all request types and ex-
periment 3 for load demonstrate promising scaling
with regards to increased number of concurrent users.
However, experiment 2 identifies that many users ac-
cessing distinct views poses a concern for scalability
with performance at U = 200 approaching 2 seconds
for a create request. Nevertheless, the most signifi-
cant concern is the limitation of the current MvK as
demonstrated by comparing the create and load re-
sults for experiment 3. Create scales linearly reach-
ing response times in excess of 5 seconds while load
requests do not scale with number of users in exper-
iment 3. The results indicate a strong need for dis-
tributed processing in the MvK, and strong promise
for the overall performance in experiment 3; i.e., our
expected average case. Overall, we feel the system
performs well with obvious deficiencies when many
users (U > 50) employ distinct views of the same sys-
tem. Also, the system is unable to leverage the full
potential of the model controllers due to the current
performance bottle neck of the MvK. In conclusion,
the Controllers portion of the architecture can effi-
ciently handle multiple users sending concurrent re-
quests, but unusually large numbers of users on one
or more views of a model will adversely affect scala-
bility.
RQ2. Our results for the main experiments do not
indicate scaling as model size varies. However, due to
limitation of the MvK, we were unable to test reason-
ably large models during the main experiments. Cur-
rently, the MvK stores active models within memory
and fails to swap out models as the limits of RAM
are reached. Thus, when we perform an experiment
with many users (up to 200 in these experiements) ac-
cessing distinct models and views of significant size
(i.e., moderate and large scale models), the system
will crash due to reaching memory bounds. Due to
the limitations of the MvK, we refer to the results in
our best case scenario (i.e., using a single model con-
troller with a localhost connection to the MvK) as pre-
sented in Figure 1. These results demonstrate that cre-
ate and delete requests are not influenced by the size
of the model. This is expected since create and delete
requests target a single element and are not influenced
by model size. However, load is affected by the model
size, because it reads all the elements in both the ab-
stract model and the view. In conclusion, we find that
the system scales as expected with regards to model
size, but further work is needed to investigate poten-
tial interactions of the variables N and U (i.e., repeat-
ing the main experiments with large scale models to
ensure our results hold true as the number of concur-
rent users increases).
4.5 Threats to Validity
The first threat to validity regards the metamodel. The
performance results have only been measured on sim-
ilar Petri net models. Different formalisms may influ-
ence the results, in particular those exposing complex
inter-object relationships or heavy objects: i.e., many
attributes or large attributes. Another threat to valid-
MODELSWARD 2016 - 4th International Conference on Model-Driven Engineering and Software Development
344

ity is that we have not measured results in scenarios
using large scale models. Our results demonstrate
the performance scaling as size of the model is in-
creased, but do not demonstrate the interaction of si-
multaneously scaling the model size and concurrent
number of users. We were unable to test this sce-
nario due to limitations at the MvK level. Thus, we
must leave investigating the interaction of these two
variables for future work. We identify a threat to va-
lidity regarding the experimental setup. The method
for distributing controllers among available machines
has an influence on the overall performance. We as-
sume an ideal distribution of model controllers among
machines. In practice, the distribution of these con-
trollers may not be ideal, but the exact distribution
depends on the specfics of the load balancing algo-
rithm and factors specific to a given scenario. De-
pending on the load balancing strategy these factors
might include order of spawn for model controllers,
size of model/views on a given model controller, or
frequency of requests to a given model controller. The
experiments presented here provide an initial evalua-
tion identifying promisiong areas and areas in need of
further improvement in the current architecture. We
leave evaluating the complex task of load balancing
in our architecture to future work.
5 RELATED WORK
We only discuss related work focusing on multi-user
modeling environments. Nevertheless, there are also
related work in web diagramming environments
4
, dis-
tributed databases (
¨
Ozsu and Valduriez, 2011), and
distributed simulation (Zhang et al., 2010).
Modern modeling tools are primarily native desk-
top applications, e.g., MetaEdit+ (Kelly et al., 1996).
AToMPM is one of the first web-based collabora-
tion tool for MDE. It takes advantage of the ever in-
creasing capabilities of web technologies to provide a
purely in-browser interface for multi-paradigm mod-
eling activities. Nevertheless, Clooca (Hiya et al.,
2013) is a web-based modeling environment that lets
the user create DSLs and code generators. However,
it does not offer any collaboration support.
Recently, Maroti et al. proposed WebGME,
a web-based collaborative modeling version of
GME (Mar
´
oti et al., 2014). It offers a collaboration
where each user can share the same model and work
on it. In contrast with the Modelverse, WebGME re-
lies on a branching scheme (similar to the GIT ver-
sion control system) to manage the actions of different
4
https://cacoo.com/
users on the same model. Thus, WebGME supports
scenarios 1 and 2, but not in an always-online envi-
ronment, unlike in AToMPM where operations imme-
diately resolve.
The GEMOC Initiative (Combemale et al., 2014)
produced GEMOC Studio, a modeling system within
the Eclipse ecosystem. Users compose multiple DSLs
into a cohesive system with well-defined interaction
of the various models (Combemale et al., 2013).
GEMOC Studio provides a solution for scenario 3
similar to the Controllers, but does not handle con-
current users.
Gallardo et al. proposed a 3-phase frame-
work to create collaborative modeling tools based
on Eclipse (Gallardo et al., 2012). The difference
between creating a regular DSL and a collaborative
modeling tool in their system is the addition of the
technological framework, adding collaboration sup-
port to the DSL. Naming it “TurnTakingTool”, mul-
tiple users are able to modify an existing model by
utilizing a turn-based system. The framework helps
the user to create the DSL as a native eclipse plug-in
with concurrency controls, graphical syntax and mul-
tiple user support.
Basciani et al. proposed MDEForge (Basciani
et al., 2014), a web-based modeling platform. MDE-
Forge offers a set of services to the end user by a
rest api, including transformation, model, metamodel
editing. Although, the idea seems elegant, the system
was not ready at the time of writing this paper. The
authors, also, mention adding the collaborative capa-
bilities of the platform in the future.
6 CONCLUSION
In this paper, we presented the cloud architecture of
AToMPM providing modeling as a service and de-
signed to support collaborative modeling scenarios.
We presented a preliminary evaluation focusing on
how scaling the number of concurrent users impacts
the response time for create, delete, or load requests.
The results reveal that the controllers in the architec-
ture are efficient with regards to number of concur-
rent users, but the MvK currently presents a bottle-
neck. We plan to explore a strategy supporting dis-
tributed processing and storage for low-level model-
ing operations within the MvK. and then investigate
load balancing strategies to manage distributing pro-
cessing and storage among distributed nodes with dis-
tinct performance and storage capabilities.
Evaluating the Cloud Architecture of AToMPM
345

REFERENCES
Atkinson, C. and Stoll, D. (2008). Orthographic Model-
ing Environment. In Fundamental Approaches to Soft-
ware Engineering, volume 4961 of LNCS, pages 93–
96. Springer.
Basciani, F. et al. (2014). MDEForge: an extensible Web-
based modeling platform. In (Paige et al. 2014), pages
66–75.
Combemale, B. et al. (2013). Reifying Concurrency for Ex-
ecutable Metamodeling. In Software Language En-
gineering, volume 8225 of LNCS, pages 365–384.
Springer.
Combemale, B. et al. (2014). Globalizing Modeling Lan-
guages. Computer, pages 68–71.
Corley, J. et al. (2016). Cloud-based Multi-View Model-
ing Environments. In Modern Software Engineering
Methodologies for Mobile and Cloud Environments.
IGI Global.
Corley, J. and Syriani, E. (2014). A Cloud Architecture
for an Extensible Multi-Paradigm Modeling Environ-
ment. In MODELS 2014 Poster Session and the ACM
SRC, pages 6–10.
Gallardo, J., Bravo, C., and Redondo, M. A. (2012). A
model-driven development method for collaborative
modeling tools. Journal of Network and Computer
Applications, 35(3):1086–1105.
Hiya, S., Hisazumi, K., Fukuda, A., and Nakanishi, T.
(2013). clooca : Web based tool for Domain Specific
Modeling. In MODELS’13: Invited Talks, Demos,
Posters, and ACM SRC, volume 1115, pages 31–35.
CEUR-WS.org.
Kelly, S., Lyytinen, K., and Rossi, M. (1996). MetaEdit+
A fully configurable multi-user and multi-tool CASE
and CAME environment. In Conference on Advanced
Information Systems Engineering, volume 1080 of
LNCS, pages 1–21. Springer.
Mar
´
oti, M. et al. (2014). Next Generation (Meta)Modeling:
Web- and Cloud-based Collaborative Tool Infrastruc-
ture. In Multi-Paradigm Modeling, volume 1237,
pages 41–60. CEUR-WS.org.
¨
Ozsu, M. T. and Valduriez, P. (2011). Principles of dis-
tributed database systems. Springer Science & Busi-
ness Media.
Paige, R. F. et al., editors (2014). Proceedings of the 2nd In-
ternational Workshop on Model-Driven Engineering
on and for the Cloud, volume 1242. CEUR-WS.org.
Syriani, E. et al. (2013). AToMPM: A Web-based Model-
ing Environment. In MODELS’13: Invited Talks, De-
mos, Posters, and ACM SRC, volume 1115. CEUR-
WS.org.
Van Mierlo, S., Barroca, B., Vangheluwe, H., Syriani, E.,
and K
¨
uhne, T. (2014). Multi-Level Modelling in the
Modelverse. In Multi-Level Modelling, volume 1286,
pages 83–92. CEUR-WS.org.
Zhang, H. et al. (2010). A model-driven approach to multi-
disciplinary collaborative simulation for virtual prod-
uct development. Advanced Engineering Informatics,
24(2):167 – 179. Enabling Technologies for Collabo-
rative Design.
MODELSWARD 2016 - 4th International Conference on Model-Driven Engineering and Software Development
346
