
A New Technique of Policy Trees for Building a
POMDP based Intelligent Tutoring System
Fangju Wang
School of Computer Science, University of Guelph, Guelph, Canada
Keywords:
Intelligent Tutoring System, Partially Observable Markov Decision Process, Pomdp Solving, Policy Tree.
Abstract:
Partially observable Markov decision process (POMDP) is a useful technique for building intelligent tutoring
systems (ITSs). It enables an ITS to choose optimal tutoring actions when uncertainty exists. An obstacle
to applying POMDP to ITSs is the great computational complexity in decision making. The technique of
policy trees may improve the efficiency. However, the number of policy trees is normally exponential, and the
cost for evaluating a tree is also exponential. The technique is still too expensive when applied to a practical
problem. In our research, we develop a new technique of policy trees for better efficiency. The technique is
aimed at minimizing the number of policy trees to evaluate in making a decision, and reducing the costs for
evaluating individual trees. The technique is based on pedagogical orders of the contents in the instructional
subject. In this paper, we first provide the background of ITS and POMDP, then describe the architecture of
our POMDP based ITS, and then present our technique of policy trees for POMDP solving, and finally discuss
some experimental results.
1 INTRODUCTION
Intelligent tutoring systems (ITSs) have become use-
ful teaching aids in computer supported education.
An ITS is a computer system that performs one-to-
one, interactive, adaptive tutoring. Research in edu-
cation science discovered that one-to-one interactive
tutoring can achieve better teaching results than lin-
ear classroom lecturing (Bloom, 1984). ITSs are de-
veloped to offer the benefit of one-to-one interactive
tutoring without the costs of dedicating one human
teacher to each student. In recent years, ITSs have
been applied in many fields including mathematics
(Woolf, 2009), physics (Vanlehn, 2010), medical sci-
ence (Woolf, 2009), and web-based adult education
(Cheung, 2003).
Adaptive teaching is a key feature of an ITS. In
each tutoring step, it chooses the optimal action ac-
cording to the current knowledge state and affective
state of its student. A knowledge state is a representa-
tion of the student’s mastery of the instructional sub-
ject, while an affective state is an indicator of the stu-
dent’s frustration, boredness, etc.
Information about students’ current states plays an
important role in adaptive tutoring. However, in a
practical tutoring process, the student’s states may not
be completely observable to the teacher. Quite often,
the teacher does not know exactly what the student’s
states are, and what the most beneficial tutoring ac-
tions should be (Woolf, 2009). For building an adap-
tive tutoring system, partially observable Markov de-
cision process (POMDP) provides useful tools to deal
with the uncertainties. It enables a system to take op-
timal actions even when information of states is un-
certain and/or incomplete.
In a POMDP, the information about student states
is modeled by a set of states. Note we use POMDP
states to model student states. At a point of time, the
decision agent is in a state, which represents the cur-
rent state of the student. The agent chooses the most
beneficial action based on what the current state is.
Finding the optimal solutions (or actions) is the
task of POMDP solving. A practical technique is to
use policy trees, in which decision making involves
evaluating policy trees and choosing the optimal one.
The technique of policy trees is still very expensive,
although it is better than many others for POMDP
solving. In making a decision, the number of pol-
icy trees to evaluate is normally exponential in the
number of possible observationsand POMDP horizon
(Carlin and Zilberstein, 2008). The cost for evaluat-
ing a policy tree is also exponential in the two vari-
ables (Rafferty et-al, 2011). The computational com-
plexity discourages the application of the policy tree
Wang, F.
A New Technique of Policy Trees for Building a POMDP based Intelligent Tutoring System.
In Proceedings of the 8th International Conference on Computer Supported Education (CSEDU 2016) - Volume 1, pages 85-93
ISBN: 978-989-758-179-3
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
85

technique to practical tutoring problems.
We develop a novel technique of policy trees, aim-
ing at minimizing the number of trees to evaluate in
making a decision, and reducing the costs for evaluat-
ing individual trees. This technique is based on the in-
formation of pedagogical order of the contents in the
instructional subject. In this paper, we first provide
the background knowledge of ITS and POMDP, re-
view some existing work of using POMDP for build-
ing ITSs, with emphasis on POMDP solving, then we
present our technique of policy trees, and finally we
discuss some experimental results.
2 INTELLIGENT TUTORING
SYSTEMS
Two major features of an ITS are knowledge tracking
and adaptive instruction: An ITS should be able to
store and track a student’s knowledge states during
a tutoring process, and choose the optimal tutoring
actions accordingly.
The core modules in an ITS include a domain
model, a student model, and a tutoring model. The
domain model stores the domain knowledge, which
is basically the knowledge in the instructional sub-
ject. For a subject, an ITS may teach concepts or
problem-solving skills, or both. In the domain model,
the knowledge for the former is usually declarative,
while the knowledge for the latter is procedural.
The student model contains information about stu-
dents. There are two types of student information: the
information about the behavior of general students in
studying the subject, and the information about the
current state of the student being tutored. The tutor-
ing model represents the system’s tutoring strategies.
In each tutoring step, the agent accesses the stu-
dent model to obtain information about the student’s
current state, then based on the information it applies
the tutoring model to choose a tutoring action and re-
trieves the domain model for the knowledge to teach.
After taking the action, it updates the student model,
chooses and takes the next action based on the up-
dated model, and so on, till the tutoring session ends.
The above discussion suggests that intelligent tu-
toring can be modeled by a Markov decision process
(MDP). In MDP, the decision agent is in a state at
any point of time. Based on information of the state,
it chooses and takes the action it considers optimal.
After the action, the agent receives an award and en-
ters a new state, where it chooses the next action, and
so on. In MDP, states are completely observable to
the decision agent, and the agent knows exactly what
the current state is. However, as mentioned before,
in a tutoring process a student’s states are not always
completely observable. Partially observable Markov
decision process (POMDP) is a more suitable model-
ing tool for intelligent tutoring processes.
3 PARTIALLY OBSERVABLE
MARKOV DECISION PROCESS
The major components of a POMDP are S, A, T, ρ, O,
and Z, where S is a set of states, A is a set of actions,
T is a set of state transition probabilities, ρ is a reward
function, O is a set of observations, and Z is a set of
observation probabilities. At a point of time, the deci-
sion agent is in state s ∈ S, it takes action a ∈ A, then
enters state s
′
∈S, observes o ∈O, and receives award
r = ρ(s,a,s
′
). The probability of transition form s to
s
′
after a is P(s
′
|s,a) ∈ T. The probability of observ-
ing o in s
′
after a is P(o|a, s
′
) ∈ Z. Since the states are
not completely observable, the agent infers state in-
formation from its observations, and makes decisions
based on its inferred beliefs about the states.
An additional major component in POMDP is the
policy denoted by π. It is used by the agent to choose
an action based on its current belief:
a = π(b) (1)
where b is the belief, which is defined as
b = [b(s
1
),b(s
2
),...,b(s
Q
)] (2)
where s
i
∈ S (1 ≤ i ≤ Q) is the ith state in S, Q is the
number of states in S, b(s
i
) is the probability that the
agent is in s
i
, and
∑
Q
i=1
b(s
i
) = 1.
Given a belief b, an optimal π returns an optimal
action. For a POMDP, finding the optimal π is called
solving the POMDP. For most applications, solving
a POMDP is a task of great computational complex-
ity. A practical method for POMDP-solving is using
policy trees. In a policy tree, nodes are actions and
edges are observations. Based on a policy tree, after
an action (at a node) is taken, the next action is deter-
mined by what is observed (at an edge). Thus a path
in a policy tree is a sequence of “action, observation,
action, observation, ..., action”.
In the method of policy trees, a decision is to
choose the optimal policy tree and take the root ac-
tion. Each policy tree is associated with a value func-
tion. Let τ be a policy tree and s be a state. The value
function of s given τ is
V
τ
(s) = R (s,a)+γ
∑
s
′
∈S
P(s
′
|s,a)
∑
o∈O
P(o|a,s
′
)V
τ(o)
(s
′
)
(3)
where a is the root action of τ, γ is a discounting fac-
tor, o is the observation after the agent takes a, τ(o) is
CSEDU 2016 - 8th International Conference on Computer Supported Education
86

the subtree in τ which is connected to the node of a by
the edge of o, and R (s,a) is the expected immediate
reward after a is taken in s, calculated as
R (s,a) =
∑
s
′
∈S
P(s
′
|s,a)R (s,a,s
′
) (4)
where R (s,a,s
′
) is the expected immediate reward
after the agent takes a in s and enters s
′
. The sec-
ond term on the right hand side of Eqn (3) is the dis-
counted expected value of future states.
From Eqns (2) and (3), we have the value function
of belief b given τ:
V
τ
(b) =
∑
s∈S
b(s)V
τ
(s). (5)
Then we have π(b) returning the optimal policy tree
ˆ
τ
for b:
π(b) =
ˆ
τ = argmax
τ∈T
V
τ
(b), (6)
where T is the set of policy trees to evaluate in mak-
ing the decision.
Now we discuss how the belief is updated. After
the agent takes a in s, it enters into s
′
and observes
o. It then has a new belief b
′
. the new belief is a
function of b, a, o, and s
′
. Recall a belief is a vector
(see Eqn (2)). Updating a belief is done by calculating
the individual elements. The following is the formula
actually used to calculate element b
′
(s
′
) in b
′
:
b
′
(s
′
) =
∑
s∈S
b(s)P(s
′
|s,a)P(o|a, s
′
)/P(o|a) (7)
where P(o|a) is the total probability for the agent to
observe o after taking a. It is calculated as
P(o|a) =
∑
s∈S
b(s)
∑
s
′
∈S
P(s
′
|s,a)P(o|a, s
′
). (8)
P(o|a) is used in Eqn (7) as a normalization factor so
that the elements in b
′
sum to one.
From the above description, we can see that each
decision step, which consists of choosing an action
(by using Eqns (3), (4), (5), and (6)) and updating the
belief (by using Eqns (7) and (8)), requires computa-
tion over the entire state space S and solution space T .
The two exponential spaces have been a bottleneck in
applying POMDP to practical problems.
4 RELATED WORK
The work of applying POMDP to computer supported
education started in as early as 1990s (Cassandra,
1998). In the early years’ work, POMDP was used
to model internal mental states of individuals, and to
find the best ways to teach concepts. Typically, the
states of a student had a boolean attribute for each of
the concepts, the actions available to the teacher were
various types of teaching techniques, and the observa-
tions were the results of tests given periodically. The
goal could be to teach as many of the concepts in a fi-
nite amount of time, or to minimize the time required
to learn all the concepts.
The recent work related with applying POMDP to
intelligent tutoring included (Williams et al, 2005),
(Williams and Young, 2007), (Theocharous et-al,
2009), (Rafferty et-al, 2011), (Chinaei et-al, 2012),
and (Folsom-Kovarik et-al, 2013). The work was
commonly characterized by using POMDP to opti-
mize and customize teaching, but varied in the defi-
nitions of states, actions, and observations, and in the
strategies of POMDP-solving. In the following, we
review some representativework in more details, with
emphasis on POMDP-solving.
In the work reported in (Rafferty et-al, 2011),
the researchers created a system for concept learn-
ing. They developed a technique of faster teaching by
POMDP planning. The technique was for computing
approximate POMDP policies, which selected actions
to minimize the expected time for the learner to un-
derstand concepts. The researchers framed the prob-
lem of optimally selecting teaching actions by using a
decision-theoretic approach, and formulated teaching
as a POMDP planning problem. In the POMDP, the
states represented the learners’ knowledge, the tran-
sitions modeled how teaching actions stochastically
changed the learners’ knowledge, and the observa-
tions indicated the probability that a learner would
give a particular response to a tutorial action. Three
learner models were considered in defining the state
space: memoryless model, discrete model with mem-
ory, and continuous model.
For solving the POMDP, the researchers devel-
oped an online method of forward trees, which are
variations of policy trees. A forward tree is con-
structed by interleaving branching on actions and ob-
servations. For the current belief, a forward trees was
constructed to estimate the value of each pedagogical
action, and the best action was chosen. The learner’s
response, plus the action chosen, was used to update
the belief. And then a new forward search tree was
constructed for selecting a new action for the updated
belief. The cost of searching the full tree is exponen-
tial in the task horizon, and requires an O(|S|
2
) oper-
ations at each node. To reduce the number of nodes
to search through, the researchers restricted the tree
by sampling only a few actions. Additionally, they
limited the horizon to control the depth of the tree.
The work described in (Folsom-Kovarik et-al,
2013) was aimed at making POMDP solvers feasi-
ble for real-world problems. The researchers created
A New Technique of Policy Trees for Building a POMDP based Intelligent Tutoring System
87

a data structure to describe the current mental status
of a particular student. The status was made up of
knowledge states and cognitive states. The knowl-
edge states were defined in terms of gaps, which are
misconceptions regarding the concepts in the instruc-
tional domain. Observationsare indicators that partic-
ular gaps are present or absent. The intelligent tutor
takes actions to discover and remove all gaps. The
cognitive states tracked boredom, confusion, frustra-
tion, etc. The intelligent tutor accounts for a learner’s
cognitive state so as to remove gaps more effectively.
To facilitate POMDP solving, the researchers
developed two scalable representations of POMDP
states and observation: state queue and observation
chain. They introduced parameter d
jk
for describing
the difficulty of tutoring concept j before concept k.
By reordering the gaps to minimize the values in d, a
strict total ordering over the knowledge states, or pri-
ority, can be created. A state queue only maintained
a belief about the presence or absence of one gap, the
one with the highest priority. The state queues al-
lowed a POMDP to temporarily ignore less-relevant
states. The state space in a POMDP using a state
queue was linear, not exponential.
The existing techniques for improving POMDP
solving have made good progress towards building
practical POMDP based ITSs. However they had lim-
itations. For example, as the authors of (Rafferty et-
al, 2011) concluded, computational challenges still
existed in their technique of forward trees, despite
sampling only a fraction of possible actions and us-
ing very short horizons. Also, how to sample the
possible actions and how to shorten the horizon are
challenging problems. As the authors of (Folsom-
Kovarik et-al, 2013) indicated, the methods of state
queue and observation chain might cause information
loss, which might in turn degrade system performance
in choosing optimal actions.
5 AN ARCHITECTURE OF
POMDP ITS
We develop an experimental system as a test bed for
our techniques, including the technique for POMDP
solving in ITSs. In this section, we discuss how we
cast an ITS onto the POMDP, and how we define
states, actions, and observations.
5.1 Casting an ITS onto POMDP
The instructional subject of the ITS is the basic
knowledge of software. The system is for concept
learning. It tutors a student at a time, in a turn-by-turn
interactive way. In a tutoring session, the student asks
questions about software concepts, and the system
chooses the optimal tutoring actions based on its in-
formation about the student’s current states. POMDP
is used for choosing the optimal tutoring actions.
Most concepts in the subject have prerequisites.
When the student asks about a concept, the system
determines whether it should start with explaining a
prerequisite for the student to make up some required
knowledge, and, if so, which one to explain. The op-
timal action is to explain the concept that the student
needs to make up in order to understand the originally
asked concept, and that the student can understand it
without making up any other concepts.
We cast the ITS student model onto the POMDP
states, and represent the tutoring model as the
POMDP policy. At the current stage, the student
model contains information about knowledge states
only. In the architecture, ITS actions are represented
by POMDP actions, while student actions are treated
as POMDP observations.
At any point in a tutoring process, the decision
agent is in a POMDP state, which represents the
agent’s information about the student’s current state.
Since the states are not completely observable, the
agent infers the information from its immediate ac-
tion and observation (the student action), and repre-
sents the information by the current belief. Based on
the belief, the agent uses the policy to choose the op-
timal action to respond to the student.
5.2 Defining States
We define the states in terms of the concepts in the
subject. In software basics, the concepts are data, pro-
gram, algorithm, and many others. We use a boolean
variable to represent each concept: Variable C
i
rep-
resents concept C
i
. C
i
may take two values
√
C
i
and
¬C
i
.
√
C
i
indicates that the student understands con-
cept C
i
, while ¬C
i
indicates that the student does not.
A conjunctive formula of such values may repre-
sent information about a student knowledge state. For
example, (
√
C
1
∧
√
C
2
∧¬C
3
) represents that the stu-
dent understands C
1
and C
2
, but not C
3
. When there
are N concepts in a subject, we can use formulas of N
variables to represent student knowledge states. For
simplicity, we omit the ∧ operator, and thus have for-
mulas of the form:
(C
1
C
2
C
3
...C
N
) (9)
where C
i
may take
√
C
i
or ¬C
i
(1 ≤ i ≤ N). We call
a formula of (9) a state formula. It is a representation
of which concepts the student understands and which
concepts the students does not.
CSEDU 2016 - 8th International Conference on Computer Supported Education
88

In the POMDP, each state in S is associated with
a state formula. When the decision agent is in a state,
from the formula of the state, it has the information of
the student’s current knowledge state.
5.3 Actions and Observations
In a tutoring session, asking and answering questions
are the primary actions of the student and system.
Other actions are those for greeting, confirmation, etc.
In an ITS for concept learning, student actions
are mainly asking questions about concepts. Asking
“what is a query language?” is such an action. We
assume that a student action concerns only one con-
cept. In this paper, we denote a student action of ask-
ing about concept C by (?C), and use (Θ) to denote
an acceptance action, which indicates that the student
is satisfied by a system answer, like “I see”, “Yes”,
“please continue” or “I am done”.
The system actions are mainly answering ques-
tions about concepts, like “A query language is a high-
level language for querying.” We use (!C) to denote a
system action of explaining C, and use (Φ) to denote
a system action that does not explain a concept, for
example a greeting.
6 THE NEW TECHNIQUE OF
POLICY TREES
The goal of our technique is to minimize the number
of trees to evaluate when the agent makes a decision,
and to reduce the costs for evaluating individual trees.
The technique is based on the information of prereq-
uisite relationships.
6.1 Prerequisite Relationships in
Learning
In most science subjects, there are pedagogical or-
ders for teaching/learning contents. The relationship
of content prerequisites is a pedagogical order. If, to
well understand concept C
j
, a student must first un-
derstand concept C
i
, we call C
i
a prerequisite of C
j
.
For example, in the subject of software basics, data is
a prerequisite of database, and in mathematics, func-
tion is a prerequisite of derivative. A concept may
have zero, one or more prerequisites, and a concept
may be a prerequisite of zero, one or more other con-
cepts. In this paper, whenC
i
is a prerequisite ofC
j
, we
call C
j
a successor of C
i
. Figure 1 illustrate a directed
acyclic graph (DAG) representing the direct prereq-
uisite relationships between a subset of the concepts
in software basics. Note that the relationships in the
graph may not be complete and accurate. They are
used in examples for discussing our technique only.
bit byte data
binary digit
high level
language
assembly
language
machine
language
instruction program
application
program
word
language
programming
file
query
language
Figure 1: The DAG representing direct prerequisite rela-
tionships in a subset of the concepts in software basics.
In our research, we observed, through examining
real tutoring sessions between human students and
teachers, that the concepts asked by a student in a tu-
toring session usually have prerequisite/successor re-
lationships with each other. Quite often, right after
asking about a concept, a student may ask about a pre-
requisite of the concept. This happens when the sys-
tem’s answer makes the student to realize that he/she
needs to make up some knowledge. For example, the
student starts a tutoring session with question “What
is a database?” After the system explains “database”
in terms of “file”, the student may ask “What is a
file?”. Sometimes, after a system’s answer about a
concept, a student may ask about a related concept,
like a successor of the concept originally asked. This
usually happens when the student has been satisfied
with the answer and wants to learn more. For exam-
ple, the student may ask a question about “data ware-
house” after being satisfied by an explanation about
“database”.
Based on the observation, we develop a set of
techniques in which the information of prerequisites
is used to group concepts into subspaces, and to re-
duce the costs in evaluating policy trees. In the fol-
lowing, we discuss our algorithms for tree construc-
tion and application.
6.2 Policy Trees and Atomic Trees
We classify student questions into the original ques-
tions and current questions. An original question
starts a tutoring session, and a current question is to
be answered in the current step. In the above example
of “database” and “file”, “What is a database?” is the
original question, and “what is a file?” is the current
question before the system answers it.
A New Technique of Policy Trees for Building a POMDP based Intelligent Tutoring System
89
The concept in the original question is the one
that the student originally wants to learn. The student
asks the current question usually for understanding
the original question. Sometimes, the current ques-
tion may also be made by the agent for the student to
make up some knowledge. At the beginning of a ses-
sion, the original question is also the current question.
In our discussion, we denote the original and cur-
rent questions by (?C
o
) and (?C
u
) respectively, and
assume C
u
∈ (℘
C
o
∪C
o
), where ℘
C
o
is the set of all
the direct and indirect prerequisites ofC
o
. For the pair
of (?C
o
) and (?C
u
), we construct a set of policy trees.
We denote the set by T
C
o
C
u
. When the original ques-
tion is (?C
o
) and current question is (?C
u
), to answer
(?C
u
) the agent evaluates all the policy trees in T
C
o
C
u
,
selects the optimal, and takes the root action of it. The
agent evaluates a policy tree to estimate the expected
return that results from taking the root action in the
current step.
We construct a policy tree by integrating some
atomic trees. In this subsection, we discuss how to
create atomic trees, and in the next subsection, how
to integrate atomic trees into policy trees. In con-
structing a policy tree, we take into consideration the
predictable student actions and the correspondingsys-
tem actions. As described, we observed that student
questions in a tutoring session likely concern concepts
having prerequisite/successor relationships. Thus in a
session, we can predict possible student questions.
For each concept in the subject, we create an
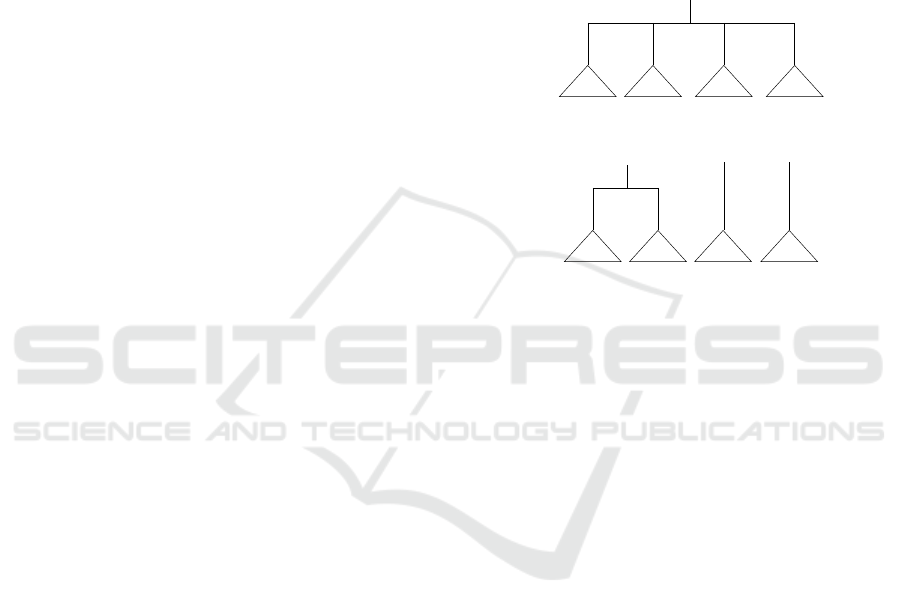
atomic tree. In the atomic tree of C, the root is (!C),
and there is one or more edges for connecting the root
with its children. The edges are labelled with the pre-
dictable student actions after the root action is taken:
After (!C), the predictable student action can be an
acceptance action, or a question about one of the pre-
requisites of C. We thus label the edges with the pre-
dictable student actions (treated as observations).
Assume C has L (L = 0,1,2, ...) direct successors,
and M (M = 0, 1,2, ...) direct and indirect prerequi-
sites. In the atomic tree of C, the root has M + 1 edges
connecting it with as many as M + 1 children, which
are expanded atomic trees of other concepts. The last
edge is labeled (Θ) for connecting the root with the
atomic tree of one of the direct successors of C. When
L = 0, the edge connects the root with an action for
terminating the session.
When M > 0, the first M edges are for connect-
ing the root with the atomic trees of the M prereq-
uisites. The ith edge is labeled with (?C
i
) and con-
nects the atomic tree of C
i
, which is the ith prereq-
uisite of C (1 ≤ i ≤ M). When M = 0, the atomic
tree has only one edge connecting a successor. Fig-
ure 2 illustrates the atomic trees of ML (machine lan-
guage, top), PL (programminglanguage, bottom left),
BD (binary digit, bottom middle), and IN (instruction,
bottom right), based on the DAG in Figure 1.
In an atomic tree, a triangle with a concept name
is a dummy subtree, and “Suc” stands for a succes-
sor. A dummy subtree with name C is not a part of
the atomic tree but will be substituted with the atomic
tree ofC or substituted with a system action for termi-
nating the session, when the atomic tree is integrated
into a policy tree.
(!ML)
BD PL SucIN
(Θ)(?BD)(?IN) (?PL)
IN
(?IN) (Θ)
Suc
(!PL)
(!BD)
Suc
(Θ)
(!IN)
(Θ)
Suc
Figure 2: Atomic trees of ML, PL, BD, and IN.
6.3 Policy Tree Construction
Now we informally discuss the algorithm for con-
structing policy trees. We still denote the original and
current questions by (?C
o
) and (?C
u
) respectively. We
also assume C
u
is in (℘
C
o
∪C
o
), otherwise, we con-
sider (?C
u
) starts a new session. For the pair of (?C
o
)
and (?C
u
), we construct a set of policy trees T
C
o
C
u
.
In the set there is one or more policy trees for each
C ∈(℘
C
u
∪C
u
).
In a policy tree for C with C
o
being the concept in
the original question, the root action is (!C), and every
leaf is an action for terminating the session. The ter-
minating action is connected by an edge of (Θ) to an
action of (!C
o
). The connected (!C
o
) and (Θ) repre-
sent that the student accepts the answer to the original
question. Thus the tutoring session can be terminated.
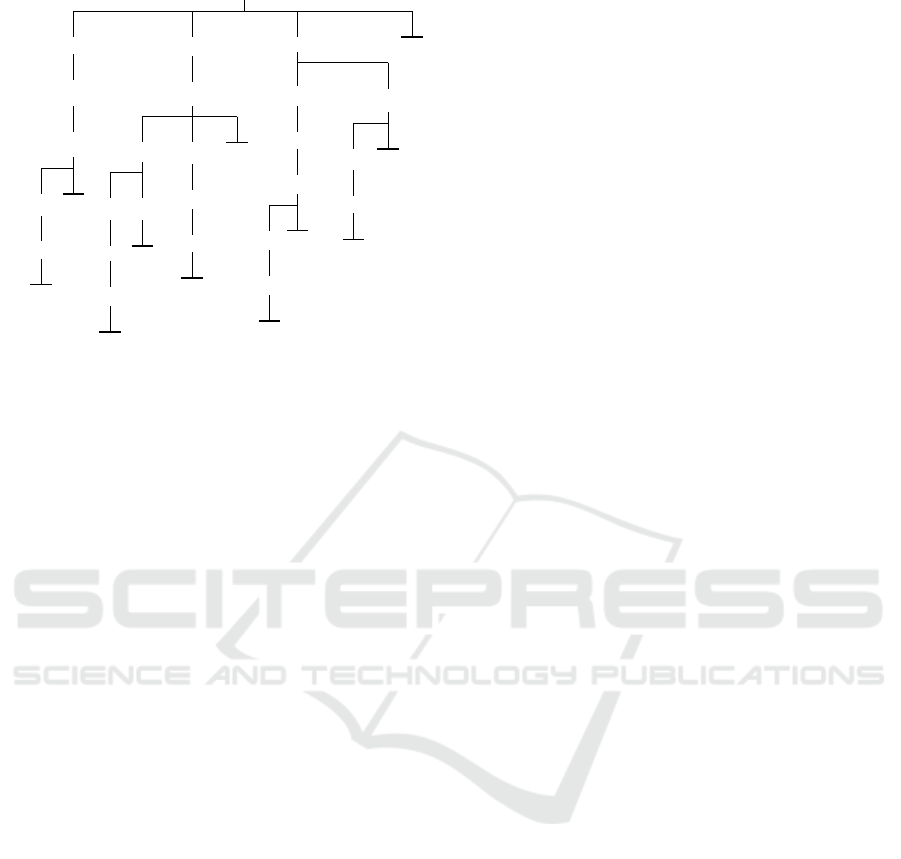
In a policy tree, every path from the root to a leaf is
a process of tutoring. It starts with answering the cur-
rent question, and ends when the student accepts the
answer to the original question. Figure 3 illustrates
a policy tree, in which the original and current ques-
tions are both (?ML). In this tree, a thick horizontal
line denotes a terminating action.
We start constructing a policy tree for C in T
C
o
C
u
by expanding the atomic tree of C: Substituting the
dummy subtrees with atomic trees, then expanding
the atomic trees, and so on, until all the leaf nodes
become terminating actions. For example, in expand-
CSEDU 2016 - 8th International Conference on Computer Supported Education
90
(!IN)
(!ML)
(!BD)
(!PL)
(?IN)
(!PL)
(?BD)
(!BD)
(!ML)
(!PL)
(!ML)
(?PL)
(!BD)
(!ML)
(?IN)
(!IN)
(!ML)
(?BD)
(!ML)
(?IN)
(!ML)
(!PL)
(!ML)
(!BD)
(?PL) (?IN)
(?BD)
(!PL)
(!ML)
(!ML)
(Θ)
(Θ)
(?BD)
(Θ)
(Θ)
(Θ)
(Θ)
(Θ)
(Θ)
(Θ)
(Θ)
(Θ)
(Θ)
(Θ)
(Θ)
(Θ)
(Θ)
(Θ)
(Θ)
(!PL)
(!IN)
(!IN) (!ML)
(Θ)
(Θ)
(Θ)
(Θ)
(Θ)
(Θ)
(Θ)
Figure 3: A policy tree for ML.
ing the atomic tree of ML, we substitute the dummy
subtree named IN with the atomic tree of IN, then ex-
pand the atomic tree of IN by substituting the dummy
subtree named Suc with the atomic tree of PL, which
is a successor of IN, and so on, when we use a depth-
first method.
In expanding an atomic tree, we have two rules for
adding a terminating action and eliminating an edge:
• If the root of the atomic tree is (!C
o
), i.e. to an-
swer the original question, substitute the dummy
subtree connected by the edge of (Θ) with a ter-
minating action.
• If the question associated with an edge has been
answered in the path from the root, eliminate the
edge without substituting the dummy subtree it
connects.
The question (?C
′
) associated with an edge has been
answered, if in the path from the root to the edge,
there is a node of (!C
′
) or (!C
′′
) immediately followed
by an edge of (Θ), whereC
′′
is a direct or indirect suc-
cessor of C
′
.
As an example, the set of T
ML
ML
includes the pol-
icy trees for ML, IN, BD, and PL. (Note (℘
ML
∪
ML) = {ML, IN, BD, PL}.) The policy tree for ML is
showed in Figure 3, the policy tree for IN is actually
the first (left-most) subtree, the policy tree for BD is
the second subtree, and the policy tree for PL is the
third subtree.
6.4 Making a Decision with the Trees
All the sets of policy trees are pre-constructed and
stored in a tree database. When the agent needs a
strategy to answer a question, it retrieves the database,
and gets a set of trees to evaluate to find the optimal.
For example, when the original and current questions
are both (?ML), the agent evaluates the four trees in
T
ML
ML
discussed above. In general, when the original
question is (?C
o
) and the agent needs to answer the
current question (?C
u
), it evaluates all the policy trees
in T
C
o
C
u
based on its belief, and finds the tree of the
highest value (optimal tree). When choosing the op-
timal policy tree by using Eqn (6), we substitute T
with T
C
o
C
u
.
A policy tree is not a tutoring plan that the agent
must follow in the future. It is the strategy for the
current step. After the optimal tree is selected, the
agent takes the root action. After taking the action, it
terminates the session or has a new current question,
depending on the student action (observation):
• If the student action is (Θ), and the (Θ) edge con-
nects to a terminating action, the agent terminates
the tutoring session;
• If the student action is (Θ), and the (Θ) connect
to (!C), the agent considers (?C) as the current
question in the next step.
• If the student action is (?C), the agent considers
(?C) as the current question in the next step.
In the next step, to answer the current question
which is determined by using the rule given above,
the agent chooses an action in the same way, i.e. by
evaluating a set of policy trees, and so on. Continue
the above example with (?ML) being both the original
and current questions. If the policy tree for ML is the
optimal, the agent takes action (!ML). After (!ML), if
the student action is (Θ), the agent follows the edge
of (Θ) in the tree, and takes the terminating action to
finish the session. However, if after (!ML) the student
action is (?PL), the agent considers the current ques-
tion in the next step is (?PL). It evaluates the trees in
T
ML
PL
, and continues until it takes a terminating action.
7 EXPERIMENTS AND ANALYSIS
We conducted the experiments by using the experi-
mental ITS described before, which teaches concepts
in software basics. Currently, keyboard and screen
are used for system input and output. It interactively
teaches a student at a time, answering the student’s
questions about the concepts. When the student asks
a question about a concept that has prerequisites, the
system chooses an optimal strategy to teach. POMDP
is the engine to make decisions based on information
(belief) about the student’s current knowledge states.
We use “rejection rate” to evaluate how the stu-
dents like the system’s answers. After the system ex-
plains a concept, if the student asks a question about
a prerequisite of the concept, or says something like
A New Technique of Policy Trees for Building a POMDP based Intelligent Tutoring System
91

“I already know this concept”, we consider that the
student rejects the system action. The rejection rate is
defined as the ratio of the number of rejected system
actions to the total number of system actions.
Encouraging results have been achieved. Com-
pared with directly teaching the concept asked by
the student, or randomly choosing a prerequisite to
start with, the teaching based on students’ knowledge
states has achieved better result. The rejection rates
have dropped significantly. We do not discuss the per-
formance in adaptive teaching, for this paper mainly
addresses the problem of solution space.
Table 1: Numbers of concepts, tree sets, trees, and tree
heights in sub-spaces.
Sub- # of # of # of Max
space concepts tree sets trees height
1 21 231 1,771 30
2 23 276 2,300 18
3 20 210 1,540 26
4 27 378 3,654 35
5 25 325 2,925 32
6 26 378 3,744 37
The data set used to generate the following re-
sults includes about 90 concepts in software basics.
The concepts have zero to five direct prerequisites.
Based on the prerequisite/successor relationships, we
partition the state space into six sub-spaces (Wang,
2015). Also based on the prerequisite/successor rela-
tionships, the policy tree construction algorithm cre-
ated six groups of policy trees. Table I lists the num-
bers of concepts, numbers of tree sets, numbers of
policy trees, and maximum tree heights in the sub-
spaces. The construction of policy trees does not rely
on the result of state space partitioning. Since both
space partitioning and tree construction are based on
concept prerequisite/successor relationships, the con-
cepts in a policy tree are in the same subspace. Thus
we can consider that the solution space is split into the
same number of subspaces.
In the experiments, the average number of policy
trees (τs) in a tree set (T ) is less than ten. The av-
erage height of the policy trees is less than 20. The
maximum number of edges at a node is the number of
concepts in a subspace plus one (the acceptance ac-
tion). As we observed, the actual numbers of edges
at nodes are much smaller than the numbers of con-
cepts in subspaces. Many edges are eliminated in pol-
icy tree construction (as described in the subsection of
tree construction.). In a decision step, the number of
policy trees to evaluate, the heights of the trees, and
the numbers of edges at nodes depend on the con-
cept in the current question. For a concept near the
lower end (having less prerequisites) the three num-
bers are small. Fora concept near the higher end (hav-
ing more prerequisites) the three numbers are big. For
the higher end concepts, there is room for further im-
provement.
When making a decision, the agent evaluates a
small number of trees. The average is less than 10
in the experiments. This does not create major effi-
ciency problems for a modern computer. When the
experimental ITS runs on a desktop computer with
an Intel Core i5 3.2 GHz 64 bit processor and 16GB
RAM, the response time for answering a question is
less than 300 milliseconds. This includes the time for
calculating a new belief, choosing a policy tree, and
accessing the database of domain model. For a tutor-
ing system, such response time could be considered
acceptable.
The experiments show that the policy tree tech-
nique can minimize the number of policy trees evalu-
ated in making a decision. When looking for a strat-
egy to answer a question, the agent needs to evaluate
a set of pre-constructed policy trees, determined by
the original and current questions. The set includes
only the policy trees for the concepts in the current
question and some of its prerequisites and successors.
They are the concepts that the student may want to
learn after asking the original question. The policy
trees for the concepts unrelated to the tutoring session
are not included in the set. In addition, since the pol-
icy trees to evaluate include the related concepts only,
and unnecessary edges are pruned as early as possi-
ble, the costs for evaluating individual trees have been
reduced.
8 CONCLUDING REMARKS
Policy trees have been accepted as a practical ap-
proach for POMDP solving. In developing a policy
tree approach, two key tasks are minimizing the num-
ber of trees to evaluate in making a decision, and the
costs for evaluating individual trees. So far, the tasks
have not been well researched in building POMDP
based ITSs. In our research, we contribute a new tech-
nique for constructing policy trees, and applying them
in choosing optimal tutoring actions. Our technique is
based on the nature of education processes, and thus
especially suitable for building systems of computer
supported education. The technique can be applied
to any tutoring tasks in which the subjects have ped-
agogical orders in the contents. Encouraging results
have been achieved in our initial experiments.
CSEDU 2016 - 8th International Conference on Computer Supported Education
92

ACKNOWLEDGEMENTS
This research is supported by the Natural Sci-
ences and Engineering Research Council of Canada
(NSERC).
REFERENCES
Bloom, B. S. (1984) The 2 sigma problem: the search for
methods of group instructions as effective as one-to-
one tutoring. In Educational Researcher, 13(6), 4-16.
Carlin, A. and Zilberstein, S. (2008) Observation Compres-
sion in DEC-POMDP policy trees. In Proceedings of
the 7th International Joint Conference on Autonomous
Agents and Multi-agent Systems, 31-45.
Cassandra, A. (1998) A survey of pomdp applications. In
Working Notes of AAAI 1998 Fall Symposium on Plan-
ning with Partially Observable Markov Decision Pro-
cess, 17-24.
Cheung, B., Hui, L., Zhang, J., and Yiu, S. M. (2003)
SmartTutor: an intelligent tutoring system in web-
based adult education. In Elsevier The journal of Sys-
tems and software, 68, 11-25.
Chinaei, H. R., Chaib-draa, B., and Lamontagne, L. (2012)
Learning observation models for dialogue POMDPs.
In Canadian AI’12 Proceedings of the 25th Cana-
dian conference on Advances in Artificial Intelligence
, Springer-Verlag Berlin, Heidelberg, 280-286.
Folsom-Kovarik, J. T., Sukthankar, G., and Schatz, S.
(2013) Tractable POMDP representations for intelli-
gent tutoring systems. In ACM Transactions on In-
telligent Systems and Technology (TIST) - Special
section on agent communication, trust in multiagent
systems, intelligent tutoring and coaching systems
archive, 4(2), 29.
Rafferty, A. N., Brunskill, E., Thomas, L., Griffiths, T.
J., and Shafto, P. (2011) Faster Teaching by POMDP
Planning. In Proceesings of Artificial Intelligence in
Education (AIED) 2011), 280-287.
Theocharous, G., Beckwith, R., Butko, N., and Philipose,
M. (2009) Tractable POMDP planning algorithms for
optimal teaching in SPAIS. In IJCAI PAIR Workshop
(2009).
VanLehn, K., van de Sande, B., Shelby, R., and Gersh-
man, S. (2010) The Andes physics tutoring system:
an experiment in Freedom. In Nkambou et-al eds. Ad-
vances in Intelligent Tutoring Systems. Berlin Heidel-
berg: Springer-Verlag, 421-443.
Wang, F. (2015) Handling Exponential State Space in a
POMDP-Based Intelligent Tutoring System. In Pro-
ceedings of 6th International Conference on E-Service
and Knowledge Management (IIAI ESKM 2015), 67-
72.
Williams, J. D., Poupart, P., and Young, S. (2005) Factored
Partially Observable Markov Decision Processes for
Dialogue Management. In Proceedings of Knowledge
and Reasoning in Practical Dialogue Systems.
Williams, J. D. and Young, S. (2007) Partially observable
Markov decision processes for spoken dialog systems.
In Elsevier Computer Speech and Language, 21, 393-
422.
Woolf, B. P. (2009) Building Intelligent Interactive Tutors.
Burlington, MA, USA: Morgan Kaufmann Publishers.
A New Technique of Policy Trees for Building a POMDP based Intelligent Tutoring System
93
