
Parallel Multi-path Forwarding Strategy
for Named Data Networking
Abdelkader Bouacherine, Mustapha Reda Senouci and Billal Merabti
A.I. Laboratory, Ecole Militaire Polytechnique,
P.O. Box 17, Bordj-El-Bahri 16111, Algiers, Algeria
Keywords:
Named Data Networking, NDN Flow, NDN Fairness, Forwarding Strategy, Forwarding Decisions, Weighted
Alpha-proportional Fairness, Flow Assignment Problem.
Abstract:
Named Data Networking (NDN) is one of the most promising instantiations of the Information Centric Net-
working (ICN) philosophy. This new design needs a new thinking due to the fact that the definitions of some
concepts used in TCP/IP paradigm are no longer appropriate. In this context, flow and fairness concepts are
examined and new perspectives are proposed. An important literature exists about forwarding strategies and
congestion control in NDN context. Unfortunately, the lack of definitions pushed many researchers to use the
TCP/IP heritage. As a consequence, they neither fully benefit from the native multi-path support nor address
the fairness problem. In order to overcome such a drawback and to meet end-users fairness while optimizing
network throughput, a new Parallel Multi-Path Forwarding Strategy (PMP-FS) is proposed in this paper. The
PMP-FS proactively splits traffic by determining how the multiple routes will be used. It takes into consid-
eration NDN in-network caching and NDN Interest aggregation features to achieve weighted alpha fairness
among different flows. Obtained preliminary results show that PMP-FS looks promising.
1 INTRODUCTION
Internet is built on redundancy in both communica-
tion and information networks. Exploiting this multi-
plicity is a necessity and an obligation nowadays and
in the future Internet (Qadir et al., 2015). With the
Information Centric Networking (ICN) proposals, the
inherited constraints imposing the single-path routing
that limit the utilization of Internet network multi-
plicity have disappeared. Named Data Networking
(NDN) (Jacobson et al., 2009; Zhang et al., 2010;
Afanasyev et al., 2014) is a future Internet architec-
ture proposal rolling under the ICN paradigm. The
NDN comes with a new communication model based
on four main characteristics:
1. Receiver-driven data retrieval model: The user
expresses an Interest with a uniquely identified
name. The routers use this latter to retrieve the
data whose name matches the requested one, and
return it to the user;
2. Local state information decisions: They are based
on the kept local state information. No global
knowledge exists;
3. Loop free forwarding plane: The Interest carries a
nonce and the corresponding returned data packet
follows the same path in the reverse direction.
Thus, none the Interests and data objects can loop
for a sufficient period of time;
4. One-to-one flow balance: One Interest brings
back at most one data object.
The above communication model led to an adap-
tive forwarding plane. The latter combined with an-
other innovative feature (i.e. the NDN in-network
caching) constitute a platform for multi-path support
called ”NDN native multi-path support”. This fea-
ture can be used to take advantage of the Internet
multiplicity in a parallel (simultaneously) or in a se-
quence manner (serial) as a backup configuration (de-
tect failure and retry alternative paths). NDN native
multi-path support is used to optimize the efficiency
(throughput) on one hand, and ensures that end-users
get a fair share (fairness) on the other hand.
Serving end-users in a fair manner while maxi-
mizing network throughput is fundamental and a chal-
lenging task in designing a forwarding plane. The
TCP/IP paradigm was built on end-to-end communi-
cation model. In this model, the source and the desti-
36
Abdelkader, B., Senouci, M. and Merabti, B.
Parallel Multi-path Forwarding Strategy for Named Data Networking.
DOI: 10.5220/0005964600360046
In Proceedings of the 13th International Joint Conference on e-Business and Telecommunications (ICETE 2016) - Volume 1: DCNET, pages 36-46
ISBN: 978-989-758-196-0
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

nation are known. Packets in the network are tagged
by this information. As a consequence, the fairness
between end-users is directly related to the fairness
between the flows. With this legacy, we inherited
most of the definitions that we use in nowadays com-
munications and networking community.
Identifying the end-users packets in NDN (In-
terests and data objects) is meant to be impossible
in-between within the network. This is the main
difference between NDN and the TCP/IP paradigm
caused by the disappearance of end-to-end commu-
nication model. The NDN architecture is location-
independent. Therefore, the NDN Interests can be
forwarded individually and independently and data
can be duplicated anywhere and so many times in the
network (NDN in-network caching feature).
The location-independent nature of NDN, the in-
network caching, and the Interest aggregation features
brought by NDN are a shifting innovation in network-
ing. This made the rich literature about multi-path
forwarding strategies, fairness and congestion control
for the TCP/IP architecture no longer appropriate. Al-
though, an important literature exists in NDN context,
the lack of definitions forced many researchers to use
the TCP/IP heritage. The unpredicted Interest aggre-
gation within the network and the important variation
in RT T (Round Trip Time) measurements, as a result
of the in-network caching feature, prevent achieving
adequate fairness and handling the dynamics in re-
turning data (Yi, 2014). Thus, the native multi-path
support has not been taking advantage of.
To design a multi-path forwarding strategy, one
has to overcome two barriers. First, it is a necessity to
define the NDN flow independently of the source and
destination of Interests and data. Second, it is manda-
tory to maintain end-users fairness and to adopt ap-
proaches without relying on RT T measurements.
In this context and in order to benefit of NDN na-
tive multi-path support, in this paper, we make the
following contributions:
• We explain and clarify ambiguities of the inher-
ited definitions of flow and fairness and we pro-
pose new definitions (perspectives) in the context
of NDN (section 3).
• We formulate the parallel multi-path forwarding
packets as an optimization problem for Coordi-
nated Multi-Path Flow Control (section 4).
• We propose a new localized Parallel Multi-Path
Forwarding Strategy (PMP-FS) (section 4). The
PMP-FS proactively splits traffic by determining
how the multiple routes will be used. It takes into
consideration the NDN in-network caching and
the NDN Interest aggregation features to achieve
weighted alpha fairness among different flows
(Mo and Walrand, 2000).
• We report and discuss PMP-FS preliminary re-
sults (section 5).
2 BACKGROUND AND RELATED
WORK
Internet is built on redundancy. It is a system built on
shared resources. As a system, it seeks to optimize its
efficiency (throughput) on one hand, and because of
its sharing nature, it seeks to ensure that end-users get
a fair share (fairness), on the other hand.
The native support of parallel multi-path forward-
ing in NDN is to be taken advantage of. Indeed, the
NDN Forwarding Information Base (FIB) entry con-
tains a list of ranked next-hops for a specific name
prefix to a fetched data object with a unique name.
This data object can be duplicated (cached) anywhere
and so many times in the network. These characteris-
tics lead to a competition between outgoing Interests
as to be forwarded to the set of best possible face(s)
while preserving fairness between end-users.
2.1 Background
Fairness is a crucial concept in networking that needs
complementary information to be understood, since it
varies from equality to equity and can be defined in
many ways. It has therefore already been the subject
of intensive research. Many definitions were given
such as Weighted Proportional Fairness (Kelly, 1997),
Proportional Fairness (Mazumdar et al., 1991), and
the Max-Min Fairness (Hahne, 1991). A unifying
mathematical model to fair throughput was first in-
troduced in (Mo and Walrand, 2000). The so-called
alpha-fair utility functions U
s
(x
s
) (Equation 1), which
defines the different notions of fairness depending on
the choice of a parameter α . This latter is a kind of
degree of fairness that controls the trade-off between
efficiency and fairness. Please refer to Table 1 for no-
tations.
U
s
(x
s
) =
w
α
s
x
1−α
s
1−α
, i f α 6= 1
w
s
log(x
s
) , i f α = 1
(1)
f or w > 0, α ≥ 0, l ∈ L
For example, α = 0 with w = 1 corresponds to the
system maximum efficiency or throughput, α → ∞
with w = 1 corresponds to the Max-Min fairness, and
α = 2 with w =
1
RT T
2
corresponds to the TCP fair
(Low, 2003).
Parallel Multi-path Forwarding Strategy for Named Data Networking
37
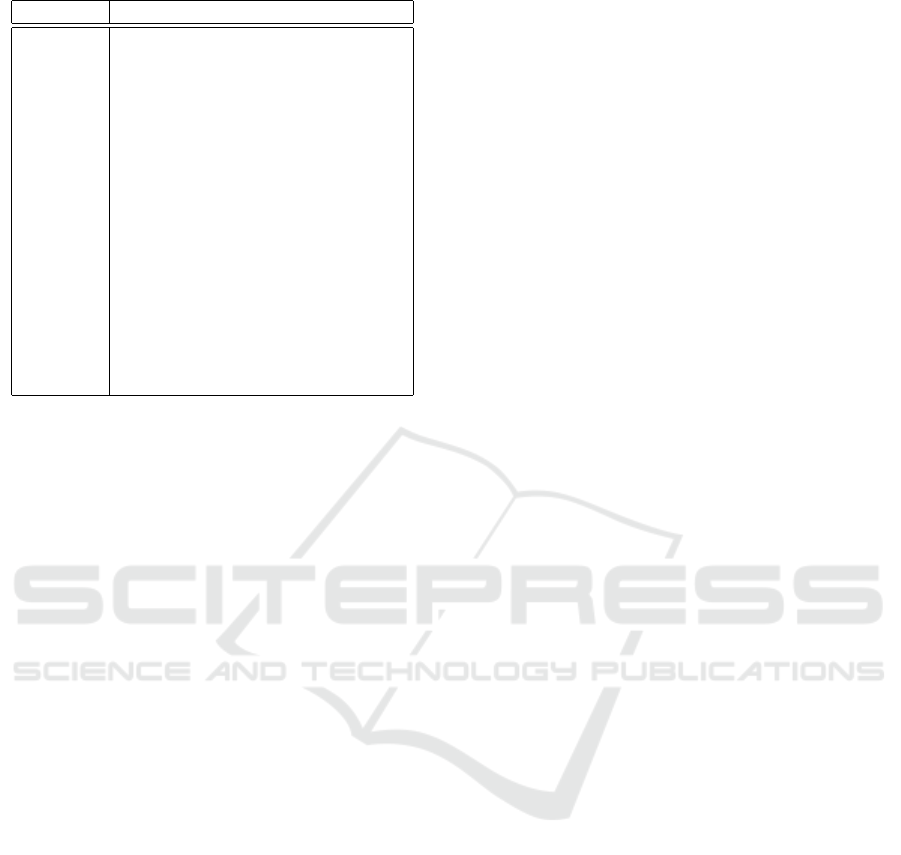
Table 1: Notations.
Notation Meaning
L set of resources (arcs)
P set of paths or routes
l ∈ P resource l is on path p
C
l
capacity of resource l
AX ≤ C capacity constraints
S set of flows
s individual flow (session)
w
s
weight of flow (session) s
x
s
rate of flow (session) s
y
p
flow rate on path p
U
s
(x
s
) alpha-fair utility functions
q a number close but less than 1
α a parameter reflecting the fairness
f l number of active flows
µ
l
shadow price, or rate of
congestion indication at resource l
The proposed fairness schemes used in the TCP/IP
paradigm with enough bandwidth demand allocates
equal bandwidth to the active flows. As a conse-
quence, the fairness between end-users is directly re-
lated to the fairness between the flows. It has worked
because we had a sharp definition of the flow. It is not
the case of NDN.
2.2 Related Work
NDN differs mainly from the IP paradigm by the dis-
appearance of the end-to-end communication model.
NDN is source-destination free, where NDN routers
have no idea of the provenance of Interests and their
possible destinations. Speaking of end-users fairness
passes certainly through a clear definition of the NDN
flow.
In (Wang, 2013), the author gives a definition
of NDN flow as triplet [( group of Interests, data
fetched by this group), client, name-prefix]. He sup-
poses that the name-prefix is indivisible in the rout-
ing/forwarding domain and the Interests are not for-
warded individually. The author claims that the diffi-
culty of defining a flow is not due to the multi-homing
and NDN in-caching feature. We do not agree with
the client component, since NDN routers ignore com-
pletely the sources and destinations of the traffic. We
claim as the authors of (Yi et al., 2012; Yi et al.,
2013; Yi, 2014) did, that fairness in NDN context can
be only defined by the names prefixes carried by the
packets.
Let us take the definition of a flow presented in
(Wang, 2013) and the max-min fairness presented in
(Yi, 2014). At the equilibrium state, the max-min
fairness allocates equal bandwidth to the active flows.
Let us have the example of ”www/com/Facebook/”
as a name prefix or as a delegation name (Afanasyev
et al., 2015a), representing one FIB entry under which
we have 9999 pending Interests. The latter name
prefix will get the same bandwidth share with an-
other name prefix of 99 pending Interests. Most re-
searchers might consider, as we do, this equality as
unfair. Defining the NDN flow to maintain end-users
fairness is mandatory. In the next section, we present
definitions of flow and fairness in the context of NDN.
3 DEFINITIONS
To define an NDN flow two questions should be an-
swered:
1. How NDN routers treat names?
2. How NDN routers treat different types of data?
To answer the first question, let us examine the
NDN Forwarding Information Base (NDN FIB) func-
tionalities. The NDN FIB entry contains a list of
ranked next-hop for specific name prefix. Due to scal-
ability issues (Baid et al., 2012; Narayanan and Oran,
2015), consensus has not yet been reached on how
and what prefix names to populate the FIB. They are a
subject of intensive research (Afanasyev et al., 2015b;
Afanasyev and Wang, 2015; Song et al., 2015; Yuan
et al., 2012). All mentioned proposals advocate that
NDN packet is forwarded by performing a look-up
of its content name using the Longest Prefix Match-
ing (LPM) or the Longest Prefix Classification (LPC).
The different Interests with the same routable prefix
name issued by different end-users are forwarded un-
der the same FIB name-prefix. Furthermore, the Inter-
ests forwarded under the same FIB entry at one router
might be forwarded under different FIB entries at an-
other router, and therefore could be forwarded sepa-
rately.
To answer the second question, we examined the
NDN Pending Interest Table (NDN PIT) functional-
ities. As a core component, PIT is responsible for
keeping track of the awaiting Interest packets (Yi
et al., 2012; Yuan and Crowley, 2014). An Interest
is issued by one end-user but it could be aggregated
(becoming subsequent Interest) once or many times
at the downstream routers. Therefore, for a given
router within the network, a pending Interest could
be issued by one or many end-users. A returned data
object could satisfy one or multiple end-users. The
Interest aggregation feature combined with other fea-
tures (NDN in-network caching, adaptive forwarding
plane, ...) make the power of the NDN architecture. It
is important to notice that Interests to be aggregated
DCNET 2016 - International Conference on Data Communication Networking
38
should have the exact same prefix name and generally
this concerns the static content or a Content Delivery
Networks (CDN) content. Another aspect to consider
is the fact that under the same routable name (prefix-
name), we can find a big number of different distinct
Interests issued by one or more than one end-user.
From the above discussion, it is clear that defining
a flow should be local to the router and for a specific
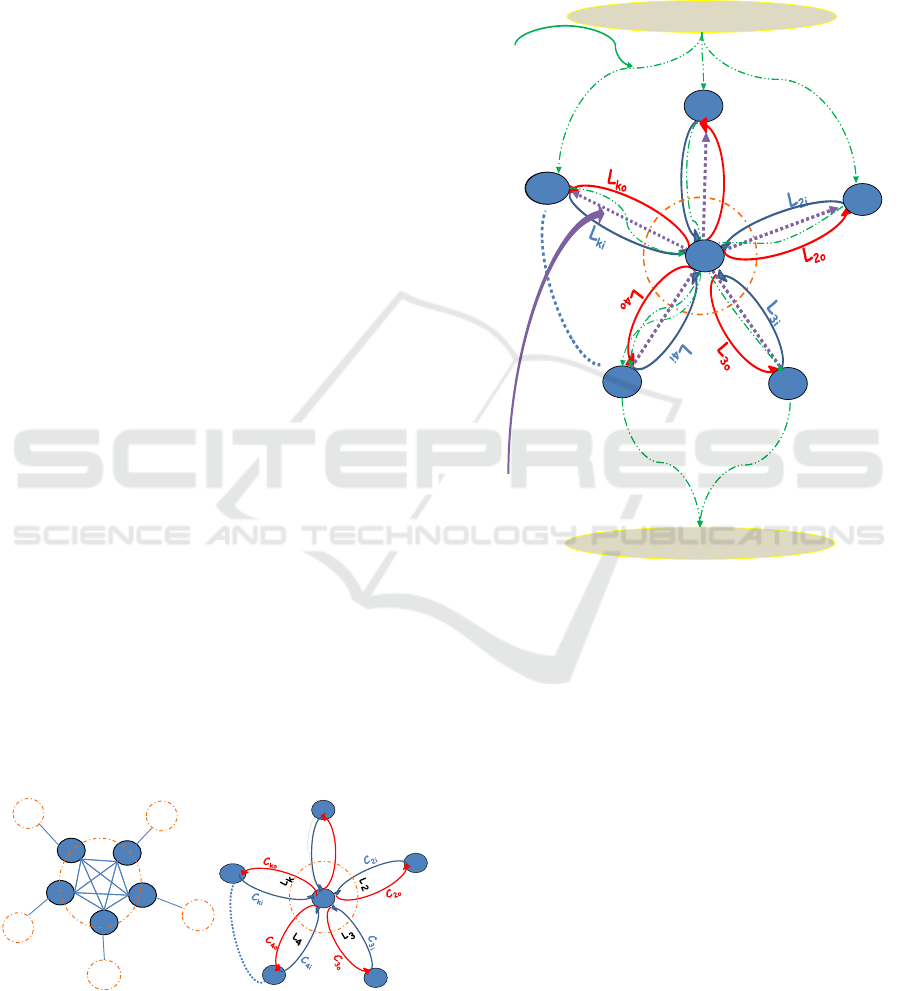
period of time (FIB update). In order to have a clear
idea, we model a Router R and its links with its neigh-
bor routers by a weighted directed graph G.
3.1 Router Model
A router R is connected to its K
ith
neighbor router by
a link L
k
with capacity C
k
, through the corresponding
face F
k
. The faces of the router R are completely con-
nected to each other with infinite capacity links (Fig-
ure 1-a).
We model the router and its direct links as a di-
rected graph G = (F, L,C) (Figure 1-b) where:
• F is a set of vertices (Router faces and a virtual
central node R);
• L is the set of edges (Router links);
• C is a function whose domain is L, it is an assign-
ment of capacities to the edges (Router links in
terms of inputs and outputs bandwidth);
• The order of graph is k + 1 and the size of G is
|L(G)| = 2k;
• L
ki
denotes the arc going from F
k
to R, represents
the downstream through the K
ith
face F
k
, with a
capacity C
ki
;
• L
ko
denote the arc going from R to F
k
, represents
the upstream through the K
ith
face F
k
, with a ca-
pacity C
ko
;
• C
ki
+C
ko
<= C
k
, is the capacity of bidirectional
link k connecting the router R and the K
ith
neigh-
bor router, through the face F
k
(Figure 1).
F1
Fk
F4
F2
F3
R
1
R
2
R
3
R
4
R
k
L1
L3
L2
L4
Lk
R
C
1
C
2
C
3
C
4
C
k
(a)
F1
F4
F2
F3
R
F
k
L
1
C
1
i
C
1o
(b)
Figure 1: Router Model.
Definition 3.1. A Flow in NDN context is a set of In-
terests and their corresponding returned data objects
forwarded under the same FIB entry proper to a router
during a given period. These Interests may have been
requested from one or multiple faces and forwarded
through one or multiple faces (Figure 2).
Returned data under
The same FIB ent ry
F1
F4
Fk
L
1i
L
1o
Virtual End-User
Virtual End-User
Interests forwarded under
the same FIB entry
F3
Fk
F2
R
Figure 2: NDN Flow.
Example of NDN Flow: Let us consider an exam-
ple from Figure 2. In case the Interests were re-
ceived from face F
3
and F
4
, the FIB lookup mecha-
nism choses for them the same FIB entry with the cor-
responding FIB outgoing faces F
1
,F
2
and F
k
. We con-
sider, with analogy to the connected oriented model:
• A virtual end-user source makes connections
(max. of six, three in our example) to the other
virtual end-user destination;
• The tuple (virtual end-user source, F
3
, R, F
2
, vir-
tual end-user destination) is a connection;
• If an Interest is forwarded through face F
2
and it
is received from face F
3
, the Interest will use the
resources l
3i
through R and l
2o
;
• The returned data will follow the reverse path l
2i
through R and l
3o
.
This set of Interests and their corresponding returned
data objects, are considered for this router as one
NDN flow.
Parallel Multi-path Forwarding Strategy for Named Data Networking
39

Definition 3.2. In the presence of competing elastic
flows, a Flow Assignment is fair in NDN context if
the assignment is weighted alpha-fair, where:
• Weights represent the normalized number of dis-
tinct awaiting sub-interests and the answered In-
terests from the Content Store (CS) as a function
of time.
• Distinct data object packets sizes and heteroge-
neous round-trip times (RT T s) are taken into con-
sideration.
3.2 Discussion
The fairness must be addressed across flows, across
network and across time (Briscoe, 2007). The pro-
posed definition of NDN flow and the fairness crite-
ria does not specify whether many flows can serve a
common end-user. We claim in this paper a realis-
tic user-centric conception of fairness. The weighted
α-proportional fairness imposed between virtual end-
users flows at each node ensures fairness between the
real end-users. The notion of friendliness imposed
by the emergence of the peer-to-peer networks in the
context of TCP/IP paradigm does not need to be ad-
dressed in the context of NDN. Taking the definitions
above, all the applications and sessions are friendly to
each other if the flows are fairly tackled.
In (Yi, 2014), the authors present Fair Interest
Limiting (FIL). An NDN version of the fair queu-
ing mechanism used in the TCP/IP paradigm that suf-
fers from the same limitations in terms of fairness
(Briscoe, 2007). Besides, it does neither take the un-
predictable effect of content in-network caching and
the Interest aggregation feature nor the distinct data
object packets sizes and heterogeneous round-trip
times (RT T s) into consideration on the fairness evalu-
ation. At the opposite, weights presented in the above
definition come as an answer. The weights must be a
function of time to deal with the dynamic nature and
unpredictable changes in the network caused by the
effect of in-network caching and the Interest aggrega-
tion features.
4 PARALLEL MULTI-PATH
FORWARDING STRATEGY
Internet has a multi-path nature. This latter was not
exploited by the inherited Internet technologies al-
though its benefits in terms of resilience and resource
usage efficiency (Qadir et al., 2015). The efforts of
deploying an Internet-scale multi-path protocol were
facing the end-to-end communication model. Ex-
changing path information and the large forwarding
tables lead to computational and storage overhead in
large-scale networks. In this context, scalability was
the black hole (Qadir et al., 2015; Baid et al., 2012).
In this section, we diagnose the problem, outline
the research problems and design considerations. Fur-
ther, we fix the objectives and we propose a new for-
warding strategy.
4.1 Diagnosis: The Nature of the
Challenge
The future Internet is definitely multi-path (Qadir
et al., 2015). In this context, we propose the PMP-
FS which is a multi-path strategy that takes advantage
of NDN native support of parallel multi-path forward-
ing. It aims to serve end-users in a fair manner with-
out the need of identifying them while maximizing
network throughput. Here, it is significant to men-
tion:
• The requested data objects in NDN may be cached
in different locations and in different periods of
time by the multi-homing mechanism and/or the
NDN in-caching mechanism. The whole data ob-
jects may be in one place or dispersed in different
places;
• The order of data packets arrival constitutes an-
other difference in forwarding packets between
NDN and TCP/IP paradigm. The order of data
packets arrival is very important in TCP/IP, which
is not the case in NDN. The returned data will be
recomposed for application use by end-users;
• Each flow (session) aims at maximizing its
throughput;
• Resources are limited: the competition between
flows as to be better served by forwarding them to
the set of the best possible face(s) is unavoidable;
• Preserving not only fairness between end-users
but also efficiency and scalability are a require-
ment;
• PMP-FS is to be executed at every NDN router;
• PMP-FS should respect the real time (line-speed)
constraint;
• PMP-FS should take the effect of content in-
network caching mechanism and the subsequent
awaiting Interests on the evaluation of fairness;
• Hop-by-hop Interest shaping mechanism to en-
sure the whole network stability is necessary;
• We assume that the flows are elastic, the routing
plane is responsible for populating the FIB and we
DCNET 2016 - International Conference on Data Communication Networking
40

make no assumptions about whether the paths are
disjoint.
4.2 Guiding Policy: Dealing with the
Challenge
In (Yi et al., 2012; Yi et al., 2013; Yi, 2014), the
authors use multi-path feature that NDN offers for
recovering from failures (detect failure and retry al-
ternative path) and divert excess traffic to other paths
which we call serial multi-path. This latter approach
ignores the competing nature of flows. Oppositely,
parallel multi-path uses all or part of the available
paths in a controlled way to forward the Interests of a
flow simultaneously over this set of available paths.
The PMP-FS splits traffic and achieves fairness in
NDN context of the active flows over multiple differ-
ent faces at each time slot. This increases reliability,
robustness and fault tolerance. The PMP-FS works as
follows:
• A hop-by-hop Interest shaping module proposed
in (Wang et al., 2013) is used as a congestion con-
trol mechanism. It is to be executed at every NDN
router to ensure the whole network stability. The
result of this module is the links input and out-
put capacities between the router at hand and its
neighbor routers;
• At every new FIB entry picked:
1. A new flow queue created and set as inactive;
2. The first group of Interests ( f Interests) is for-
warded immediately;
3. The flow queue becomes active when the for-
warded Interests bring back data. The size of
data object is estimated;
4. Proportional Integral Controller Enhanced
(PIE) is used (Pan et al., 2013).
• At every data object packet received or cache hit:
1. Increment the per flow counter.
• At every time slot:
1. the PMP-FS collects:
– The vector of per flow counters;
– The information about the pending Interests
and the awaiting Interests for each active NDN
flow and their corresponding FIB entries;
– The links input and output capacities: the re-
sult of the hop-by-hop Interest shaping capaci-
ties minus the reserved bandwidth for the end-
ing sessions (empty flows queues).
2. Flow Assignment module is executed for the
active flows queues: the result is a matrix A of
Flow Assignment;
3. Forwarding Decision module is executed:
– Taking as input:
∗ the matrix A of Flow Assignment of the last
step;
∗ the vector of the number of the pending In-
terests;
∗ the vector of estimated sizes of data objects
of the active flows;
– The output is a matrix D of the number of In-
terests to forward for each flow over each face;
• The matrix D is used to forward the incoming
Interests and for every Interest answered another
one from the same flow is sent.
The time slot must be chosen in a manner that en-
able us to integrate the new flows softly and elim-
inate the RT T variations effect on fairness. We
take 25 msec as the time slot which is about the
third of mean Internet RT T .
4.3 Action Plan: Carrying out the
Guiding Policy
NDN follows the pull-based model. Interests come
through one of the faces. Based on the FIB, these
Interests are forwarded through other face(s). The re-
turned data follows the reverse direction. The global
architecture of PMP-FS is depicted in Figure 3.
• At every new FIB entry picked:
– When a router receives an Interest and in case
the checking of the CS and the PIT results in
a negative response, the FIB is checked. At
this moment a new FIB entry is picked and the
a f ter receive Interest action is triggered.
– The variation in data object sizes is taken into
consideration by the per-flow queuing (coun-
ters per name-space) and the flow will be con-
sidered by the Flow Assignment module only
when it is active. In this case, we have the esti-
mated size of the data object packets. The latter
is smoothly updated at each received data ob-
ject (the be f ore satis f y Interest action is trig-
gered).
– Forwarding the first group of Interests of a
newly created flow over a set f of faces gives us
an opportunity to measure the performance and
rank the faces both dynamically and locally ( f
best faces ranked by the routing plane).
– Proportional Integral Controller Enhanced
(PIE) is used as an acceptance mechanism
by dropping incoming Interests and sending
pack NACKs based on a probability. Depar-
ture rate and the flow queue length are used
Parallel Multi-path Forwarding Strategy for Named Data Networking
41
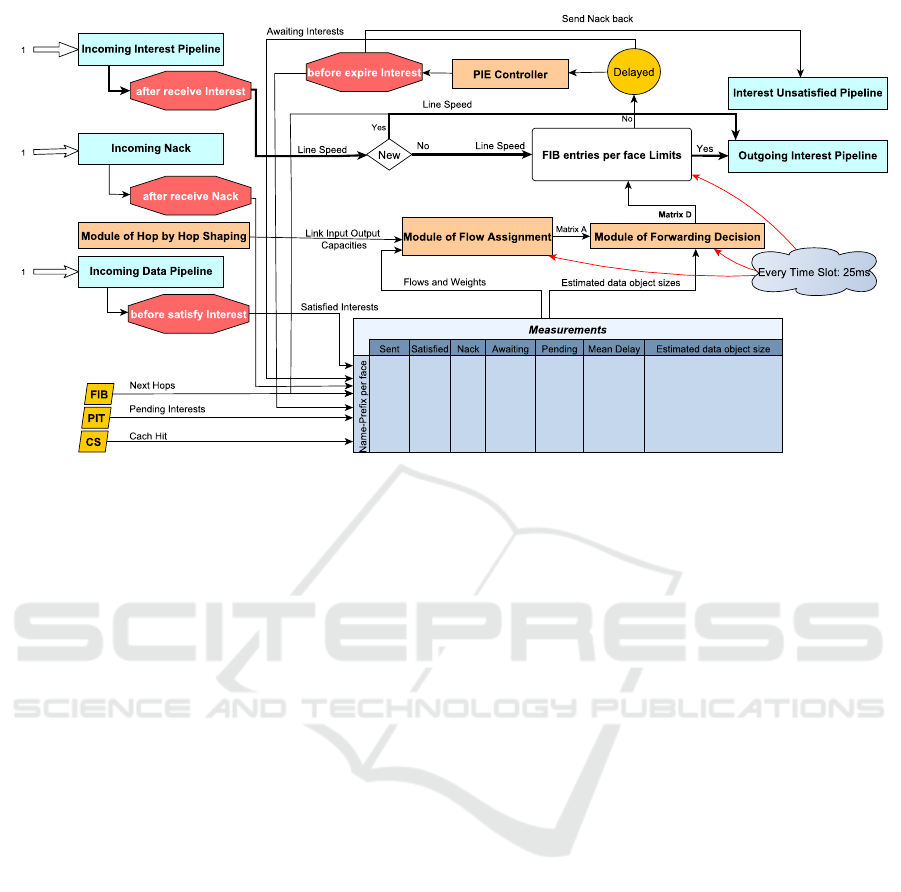
Figure 3: PMP-FS Global Architecture.
(Pan et al., 2013). When sending NACKs the
be f ore expire Interest action is triggered to up-
date the counters in measurements table.
• At every time slot (every 25 msec)
1. the PMP-FS collects:
– The information about the pending and the
awaiting Interests with their corresponding
FIB entries for each active NDN flow and the
Interests that hit the cache. These will be used
as weights;
– The links input and output capacities: the re-
sult of the capacities of the hop-by-hop shap-
ing minus the reserved space for the ending
sessions (empty flows queues);
2. The Flow Assignment module is executed for
the active flows. The result is a matrix A of
Flow Assignment over the faces. The objective
of this module is to perform a controlled split-
ting of the active flows over the faces while sat-
isfying the limited bandwidth constraints of the
outgoing and ingoing router links. In the next
section, the problem mathematical formulation
is presented.
3. The module of Forwarding Decision: The one-
to-one interdependence between Interests and
data objects called NDN flow balance propri-
ety gives us the opportunity to carry out a con-
trolled splitting of the flows over the faces by
only deciding where and how many Interests of
the active flows to forward.
Taking as inputs the matrix of Flow Assignment
of the last step and the vector of estimated sizes
of the active flows data objects, we get the ma-
trix D of the maximum number of Interests to
be forwarded for each flow over each face.
The matrix D is used to forward the incoming
Interests, the next time slot and for every Inter-
est answered another one from the same flow is
sent.
4.3.1 Network Model and Problem Formulation
To design The Flow Assignment module of the PMP-
FS, we use the model described previously (cf. sub-
section 3.1). We use the directed graph G = (F, L,C)
(cf. Figure 1).
For a better understanding, let us take the exam-
ple of the NDN flow f w (see Figure 2): if Interests
of the same flow enter through face F
3
and F
4
, their
corresponding FIB outgoing faces are face F
1
, F
2
and
F
k
. If an Interest of flow f w is forwarded through face
F
2
and it is received from face F
3
. The latter Interest
would use the resources l
3i
through R and l
2o
. The
returned data object will follow the reverse path, l
2i
through R and l
3o
.
This flow f w is competing with other flows to
grab the max of bandwidth. The links capacities are
the result of the hop-by-hop Interest shaping mecha-
nism. The issue will be an optimization problem that
takes into consideration only the paths and seizes of
returned data objects.
The Flow Assignment module will decide the
splitting of active flows (sessions) over the paths
while satisfying the limited bandwidth constraints. In
DCNET 2016 - International Conference on Data Communication Networking
42
other words, the module gives a solution of an opti-
mization problem for a weighted alpha fair flow as-
signment. It takes into consideration the paths and
seizes of returned data objects only. The result of this
optimization will be used to decide on the number of
Interests of each flow to be forwarded on each face.
Real time was always an issue when solving the
Flow Assignment and the Coordinated Multi-Path
Flow Control type of problems. The computation
scalability led to the use of off-line methods. The
authors in (McCormick et al., 2014) propose an al-
gorithm that could be executed in the range of mil-
liseconds and could be used as an on-line tool. It is
proposed as a Software Defined Networking (SDN)
Traffic Engineering tool based on the work presented
in (Voice, 2007). Oppositely to (McCormick et al.,
2014), we use the proposed algorithm in a distributed
manner to achieve weighted alpha-fairness flow as-
signment at each router of the network. We apply the
algorithm in our proposed network model (cf. Fig-
ure 1).
The Flow Assignment optimization using
weighted alpha-fair utility functions is defined as
follows:
Maximize
∑
s∈S
w
α
s
X
1−α
s
1 − α
(2)
Sub ject to
∑
p∈l
y
p
≤ C
l
∑
p∈s
y
p
= x
s
(3)
f or w > 0, α 6= 1, x > 0, y > 0, l ∈ L
The resulting updating rules, following (Mc-
Cormick et al., 2014; Kelly et al., 2008; Voice, 2007),
using the same notations as in Table 1 are:
y
p
= ((
w
s(p)
x
s(p)
)
α
1
∑
l∈p
µ
l
)
1
1−q
x
s(p)
(4)
µ
l
(t + 1) = µ
l
(t) +
1−q
2
µ
l
(t)
"
∑
p∈l
y
p
(t)−c
l
c
l
#
(5)
x
s
(t + 1) = x
s
(t) +
1−q
2(α+q−1)
x
s
(t)
"
∑
p∈s
y
p
(t)
q
−x
s
(t)
q
x
s
(t)
q
#
(6)
The main advantage of this formulation is that the
updating rules can be implemented in parallel. The
µ
l
(t) is the shadow price of the link l at iteration t of
the path p.
In the sequel, we present some preliminary results.
Furthermore, we discuss implementation and evalua-
tion considerations.
5 PERFORMANCE EVALUATION
The general structure of the module describing how
we can implement the formulation described in sub-
subsection 4.3.1 is shown in algorithm 1.
Algorithm 1: Flow Assignment Module.
Input: G = (F,L,C), Weights W [ f l].
1 begin for All Flows s do
2 for All Sub Flows of s do
3 for All Sub Flows Y
p
do
4 y
p
← ((
w
s(p)
x
s(p)
)
α
1
∑
l∈p
µ
l
)
1
1−q
x
s(p)
5 repeat
6 for All links l do
7 µ
l
← µ
l
+
1−q
2
µ
l
h
∑
p∈l
y
p
−c
l
c
l
i
8 for All Aggregate Flows X
s
do
9 x
s
← x
s
+
1−q
2(α+q−1)
x
s
h
∑
p∈s
y
q
p
−x
q
s
x
q
s
i
10 Y
P
old ← y
p
11 for All Sub Flows Y
p
do
12 y
p
← ((
w
s(p)
x
s(p)
)
α
1
∑
l∈p
µ
l
)
1
1−q
x
s(p)
13 until (|y
p
−Y
P
old| < 10
−5
)
14 return Matrix of Flow Assignment A
5.1 Preliminary Results
An implementation of algorithm 1 in C++ on an Intel
Core i5-3550 (6M Cache, 3.3 GHz) processor gives
the results shown in Figure 4.
0 5 0 0 1 0 0 0 1 5 0 0 2 0 0 0 2 5 0 0
0
2 0 0 0
4 0 0 0
6 0 0 0
8 0 0 0
E x e c u t i o n T i m e ( s )
N u m b e r o f F l o w s
N u m b e r o f F a c e s = 1 0 0
α= 4
q = 0 . 7 5
Figure 4: Execution times per number of flows without par-
allelism.
The execution time grows exponentially with the
number of flows, which explains the real-time issue
that was previously mentioned. In Figure 5, we stud-
ied the effect of number of faces on the execution
time. Obtained results show that the number of faces
does not affect the execution time.
The Field-programmable Gate Array (FPGA) im-
plementation of algorithm 1 on BT 21CN network
Parallel Multi-path Forwarding Strategy for Named Data Networking
43

0 5 0 1 0 0 1 5 0 2 0 0 2 5 0
0
5 0
1 0 0
1 5 0
2 0 0
2 5 0
3 0 0
N u m b e r o f F l o w s = 5 0 0
α= 4
q = 0 . 7 5
T i m e o f E x e c u t i o n ( s )
N u m b e r o f F a c e s
Figure 5: Execution times per number of faces without par-
allelism.
comprising 106 nodes and 234 links was done by
(McCormick et al., 2014) on a Virtex 7 FPGA. The
simulation was run with more than ten thousand
(10000) flows in less than two (2) msec (McCormick
et al., 2014). If we have a router with hundred (100)
faces, following our model we would have one hun-
dred and one (101) nodes and two hundred (200) links
network. The RT T in todays Internet is around 80 ms
on average (Perino and Varvello, 2011). We take
25 msec as the time slot, which is about the third of In-
ternet RT T average. With the latter frequency of exe-
cution of the Flow Assignment module (three times in
one RT T round), PMP-FS can integrate the new flows
softly and eliminate the RT T variations effect on fair-
ness. This proves the computation time scalability of
our PMP-FS.
5.2 Discussion
The actual configuration of the FPGA implementa-
tion of (McCormick et al., 2014) supports 512 links,
32000 flows and 96K paths. Using our model, the
latter configuration is equivalent to a router with 256
faces and 32000 NDN flows.
The number of active flows in a core router is in
the order of 10
3
(Mills et al., 2010), which makes the
PMP-FS an excellent choice for use on Internet scale
network. But it is significant to mention that one has
to design for the future. We argue, besides the techni-
cal advances in the future that would make the mod-
ule limits higher, our proposal is configurable. It is
in the same spirit as (Afanasyev and Wang, 2015).
The use of hierarchical names by NDN made our pro-
posal flexible to the level of granularity. Maintaining
per-flow states information is undesirable in large net-
works but in the case of PMP-FS one has to see it as
a class-level or flow aggregation with different gran-
ularities. Setting the degree of granularity (the level
of the FIB entry in the name tree to consider by the
Flow Assignment Module) depend on the role of the
router in the network (Edge or Core Router). The lat-
ter flexibility makes the PMP-FS adaptable to support
any exponential growth of Internet. In this context, it
is worth highlighting that:
• The choice of the degree of granularity combined
with the weights of NDN flows makes PMP-FS
able to handle any number of flows. The fairness
would not be affected and can be controlled by the
choice of the degree of granularity;
• The degree of granularity is used to reduce the
per-flow state managed by each router and to con-
trol the processing time and storing space;
• The weights of NDN flows can be used to support
differentiated bandwidth allocation (based on pri-
ority);
• The in and out link capacities used by the Assign-
ment Flow Module can be used and configured to
leave room in the links for QoS guaranteed appli-
cations.
• The packets (Interests and Data Objects) are for-
warded in line speed.
6 CONCLUSION AND FUTURE
WORK
In this paper, we have proposed a new Parallel Multi-
Path Forwarding Strategy (PMP-FS) that takes into
consideration NDN in-network caching and NDN In-
terest aggregation features to achieve weighted alpha
fairness among different NDN flows. In one hand, the
proposed PMP-FS is a general framework for han-
dling fairness and throughput (by setting the tuning
parameters (e.g. α and q)). In the other hand, it
can handle all type of application needs (delay, band-
width, ...) and communication protocols (over TCP,
Ethernet, ...). Besides it can be used to implement
differentiated services by routable name-prefix pro-
viding quality of service (QoS). We do believe that
the major drawback of the proposed solution is the
need of an extra hardware. However, we do believe
also that it will add value of robustness and efficiency
in the future Internet architecture.
The evaluation of the PMP-FS in the ndnSIM 2.1,
an open-source simulator for NDN (Afanasyev et al.,
2012; Mastorakis et al., 2015), is a work-in-progress.
In this context, it is worth pointing out that the for-
warding strategies implemented in the ndnSIM are
special cases of the proposed PMP-FS strategy:
• Best Route Strategy: PMP-FS with one best link;
DCNET 2016 - International Conference on Data Communication Networking
44

• Multi-cast Strategy: PMP-FS with all upstreams
indicated by FIB entry;
• Client Control Strategy: PMP-FS testing specific
Interests and allowing them to be forwarded to
preconfigured outgoing faces.
REFERENCES
Afanasyev, A., Burke, J., Zhang, L., Claffy, K., Wang,
L., Jacobson, V., Crowley, P., Papadopoulos, C.,
and Zhang, B. (2014). Named Data Networking.
ACM SIGCOMM Computer Communication Review,
44(3):66–73.
Afanasyev, A., Moiseenko, I., and Zhang, L. (2012).
ndnSIM: NDN simulator for NS-3. Technical report,
NDN-0005.
Afanasyev, A., Shi, J., Zhang, B., Zhang, L., Moiseenko,
I., Yu, Y., Shang, W., Huang, Y., Abraham, J. P.,
Dibenedetto, S., Fan, C., Pesavento, D., Grassi, G.,
Pau, G., Zhang, H., Song, T., Abraham, H. B., Crow-
ley, P., Amin, S. O., Lehman, V., and Wang, L.
(2015a). NFD Developer ’ s Guide. Technical report,
NDN-0021.
Afanasyev, A. and Wang, L. (2015). Map-and-Encap for
Scaling NDN Routing. Technical report, NDN-0004.
Afanasyev, A., Yi, C., Wang, L., Zhang, B., and Zhang,
L. (2015b). SNAMP: Secure Namespace Mapping to
Scale NDN Forwarding. IEEE Global Internet Sym-
posium (GI 2015).
Baid, A., Vu, T., and Raychaudhuri, D. (2012). Comparing
alternative approaches for networking of named ob-
jects in the future Internet. In Computer Communica-
tions Workshops (INFOCOM WKSHPS), 2012 IEEE
Conference on Emerging Design Choices in Name-
Oriented Networking, pages 298–303.
Briscoe, B. (2007). Flow rate fairness: Dismantling a re-
ligion. ACM SIGCOMM Computer Communication
Review, 37(2):63–74.
Hahne, E. L. (1991). Round-robin scheduling for max-min
fairness in data networks. Selected Areas in Commu-
nications, IEEE Journal on, 9(7):1024–1039.
Jacobson, V., Smetters, D. K., Briggs, N. H., Plass, M. F.,
Stewart, P., Thornton, J., and Braynard, R. L. (2009).
VoCCN: Voice-over Content-Centric Networks. Pro-
ceedings of the 2009 workshop on Re-architecting the
internet, pages 1–6.
Kelly, F. (1997). Charging and rate control for elastic traf-
fic. European Transactions on Telecommunications,
8(1):33–37.
Kelly, F., Raina, G., and Voice, T. (2008). Stability and fair-
ness of explicit congestion control with small buffers.
ACM SIGCOMM Computer Communication Review,
38(3):51.
Low, S. H. (2003). A duality model of TCP and queue man-
agement algorithms. IEEE/ACM Transactions on net-
working, 11(4):525–536.
Mastorakis, S., Afanasyev, A., Moiseenko, I., and Zhang,
L. (2015). ndnSIM 2 . 0 : A new version of the NDN
simulator for NS-3. Technical report, NDN-0028.
Mazumdar, R., Mason, L. G., and Douligeris, C. (1991).
Fairness in network optimal flow control: optimality
of product forms. Communications, IEEE Transac-
tions on, 39(5):775–782.
McCormick, B., Kelly, F., Plante, P., Gunning, P., and
Ashwood-Smith, P. (2014). Real time alpha-fairness
based traffic engineering. Proceedings of the third
workshop on Hot topics in software defined network-
ing - HotSDN ’14, 1(1):199–200.
Mills, K., Filliben, J., Cho, D., Schwartz, E., and Genin, D.
(2010). Study of Proposed Internet Congestion Con-
trol Algorithms. Technical report, NIST Special Pub-
lication 500-282.
Mo, J. and Walrand, J. (2000). Fair end-to-end Window-
based Congestion Control. IEEE/ACM Trans. Netw.,
8(5):556–567.
Narayanan, A. and Oran, D. (2015). Ndn and Ip Routing
Can It Scale ? In Proposed Information-Centric Net-
working Research Group (ICNRG), Side meeting at
IETF-82, Taipei.
Pan, R., Natarajan, P., Piglione, C., Prabhu, M. S., Subra-
manian, V., Baker, F., and VerSteeg, B. (2013). PIE: A
lightweight control scheme to address the bufferbloat
problem. In 14th International Conference on High
Performance Switching and Routing (HPSR), IEEE,
pages 148–155, Taipei, Taiwan.
Perino, D. and Varvello, M. (2011). A reality check for
content centric networking. In Proceedings of the
ACM SIGCOMM workshop on Information-centric
networking - ICN ’11, page 44, New York, USA.
ACM Press.
Qadir, J., Ali, A., Yau, K.-l. A., Sathiaseelan, A., and
Crowcroft, J. (2015). Exploiting the power of mul-
tiplicity: a holistic survey of network-layer multipath.
arXiv:1502.02111v1 [cs.NI], pages 1–35.
Song, T., Yuan, H., Crowley, P., and Zhang, B. (2015). Scal-
able Name-Based Packet Forwarding: From Millions
to Billions. In Proceedings of the Second Interna-
tional Conference on Information-Centric Network-
ing, ICN ’15, pages 19–28, New York, USA. ACM.
Voice, T. (2007). Stability of multi-path dual congestion
control algorithms. IEEE/ACM Transactions on Net-
working, 15(6):1231–1239.
Wang, Y. (2013). Caching, Routing and Congestion Control
in a Future Information-Centric Internet. PhD thesis,
North Carolina State University.
Wang, Y., Rozhnova, N., Narayanan, A., Oran, D., and
Rhee, I. (2013). An improved hop-by-hop interest
shaper for congestion control in named data network-
ing. ACM SIGCOMM Computer Communication Re-
view, 43(4):55–60.
Yi, C. (2014). Adaptive forwarding in named data network-
ing. PhD thesis, The University Of Arizona.
Yi, C., Afanasyev, A., Moiseenko, I., Wang, L., Zhang, B.,
and Zhang, L. (2013). A Case for Stateful Forwarding
Plane. Computer Communications, 36(7):779–791.
Parallel Multi-path Forwarding Strategy for Named Data Networking
45

Yi, C., Afanasyev, A., Wang, L., Zhang, B., and Zhang, L.
(2012). Adaptive forwarding in named data network-
ing. ACM SIGCOMM Computer Communication Re-
view, 42(3):62.
Yuan, H. and Crowley, P. (2014). Scalable Pending Interest
Table design: From principles to practice. Proceed-
ings - IEEE INFOCOM, pages 2049–2057.
Yuan, H., Song, T., and Crowley, P. (2012). Scalable NDN
Forwarding: Concepts, Issues and Principles. 21st
International Conference on Computer Communica-
tions and Networks (ICCCN), pages 1–9.
Zhang, L., Estrin, D., Burke, J., Jacobson, V., Thorton,
J. D., Smetters, D. K., Zhang, B., Tsudik, G., Claffy,
K., Krioukov, D., Massey, D., Papadopoulos, C., Ab-
delzaher, T., Wang, L., Crowley, P., and Yeh, E.
(2010). Named Data Networking. Technical report,
NDN-0001.
DCNET 2016 - International Conference on Data Communication Networking
46
