
Putting Web Tables into Context
Katrin Braunschweig, Maik Thiele, Elvis Koci and Wolfgang Lehner
Database Technology Group, Department of Computer Science, Technische Universitat Dresden, Dresden, Germany
Keywords:
Information Extraction, Web Tables, Text Tiling, Similarity Measures.
Abstract:
Web tables are a valuable source of information used in many application areas. However, to exploit Web
tables it is necessary to understand their content and intention which is impeded by their ambiguous semantics
and inconsistencies. Therefore, additional context information, e.g. text in which the tables are embedded,
is needed to support the table understanding process. In this paper, we propose a novel contextualization
approach that 1) splits the table context in topically coherent paragraphs, 2) provides a similarity measure
that is able to match each paragraph to the table in question and 3) ranks these paragraphs according to their
relevance. Each step is accompanied by an experimental evaluation on real-world data showing that our
approach is feasible and effectively identifies the most relevant context for a given Web table.
1 INTRODUCTION
The Web has developed into a comprehensive re-
source not only for unstructured or semi-structured
data, but also for relational data. Millions of rela-
tional tables embedded in HTML pages or published
in the course of Open Data/Open Government initia-
tives provide extensive information on entities and
their relationships from almost every domain. Re-
searchers have recognized these Web tables as an im-
portant source of information for applications such as
factual search (Yin et al., 2011), entity augmentation
(Eberius et al., 2015; Yakout et al., 2012), and ontol-
ogy enrichment (Mulwad et al., 2011).
These Web tables are very heterogeneous, often
with ambiguous semantics and inconsistencies in the
quality of the data. Consequently, inferring the se-
mantics of these tables is a challenging task that
requires a designated table understanding process.
Since Web tables are typically very concise, addi-
tional contextual information is needed to understand
their content and intention. On the Web, we encounter
context in the form of headlines, captions or surround-
ing text. Text referring to a table can provide a sum-
mary of the content or conclusions drawn from it. It
also frequently offers a more detailed description of
various table entries to clarify terms or indicate re-
strictions on attributes (Hurst, 2000). However, not all
information mentioned in potential context sections is
actually relevant to the table. For instance, a query
term that appears in the context of a table does not
guarantee that the answer to the query is contained
in the table. The verbosity of the context, especially
when considering large texts, often introduces noise
that leads to incorrect interpretations (Pimplikar and
Sarawagi, 2012). Consequently, evaluating the rele-
vance of potential context segments as well as estab-
lishing an explicit link to the table content is essen-
tial in order to reduce noise and prevent misinterpreta-
tions. In this paper we take a closer look at the context
available for tables on the Web in order to improve its
impact on Web table understanding. Therefore, we
focus on the relevance of different context sources
with respect to providing useful additional informa-
tion on table content. Our objective is to identify
measures that enable the evaluation of context infor-
mation regarding its connection to table content and
the reduction of noise based on these measures. By
reducing the noise, we expect table understanding ap-
proaches based on table context as well as information
extracted from it to be less ambiguous.
Problem Statement. We view the challenge of re-
ducing the noise in the table context as a paragraph
selection problem. Consequently, the objective is to
identify paragraphs in long text segments which are
semantically related or relevant to a table. We can
split this problem into three subtasks, as illustrated in
Figure 1, which also determine the structure of the
paper.
1. First, the text is decomposed into topically coher-
ent paragraphs. Selecting the best segmentation
158
Braunschweig, K., Thiele, M., Koci, E. and Lehner, W.
Putting Web Tables into Context.
DOI: 10.5220/0006034701580165
In Proceedings of the 8th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2016) - Volume 1: KDIR, pages 158-165
ISBN: 978-989-758-203-5
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

1. Text Segmentation 2. Relevance Estimation 3. Ranking and Selection
Figure 1: Overview of the paragraph selection task.
granularity is important, as the paragraph size can
affect the selection process. If paragraphs are too
large, we run the risk of retaining noise in the con-
text. Yet, if paragraphs are too small, they do not
provide enough content to make an informed de-
cision regarding their relevance to the table.
2. Second, a similarity measure is used to match
each paragraph to the table in question in order to
evaluate its relevance. Since the overlap between
table content and context information is very lim-
ited, it is important to select an appropriate mea-
sure to estimate the relevance of the paragraphs.
3. And finally, all paragraphs are ranked according
to their relevance and irrelevant, noisy paragraphs
are filtered out.
2 TEXT SEGMENTATION
The objective of the text segmentation step is to split
long text sections into semantically coherent seg-
ments or paragraphs. various text segmentation algo-
rithms have been proposed in the literature, includ-
ing algorithms addressing lexical cohesion (Hearst,
1997), topic detection and tracking algorithms (Allan,
2002), as well as probabilistic models (Beeferman
et al., 1999). In this paper, we employ a linear text
segmentation approach similar to TextTiling (Hearst,
1997), which detects shifts in topics by measuring
the change in vocabulary within the text. Using a
sliding window approach, vocabulary changes are de-
tected by measuring the coherence between adjacent
text sections. Significant changes in coherence de-
termine the position of break points, as they indicate
topic shifts. In detail, the approach we adopted works
like follows:
1. Coherence Scores: To measure the coherence,
the text is first tokenized and split into smaller
units. Common units are sentences or pseudo-
sentences, i.e. token sequences of fixed length.
While sentences provide for more natural bound-
aries, pseudo-sentences ensure that sections of
equal size are compared. Two adjacent blocks
of size b (in text units) are used to measure the
change of vocabulary, as illustrated in Figure 2. A
text similarity measure, such as the cosine similar-
ity of the term frequency vectors, determines the
coherence score s
c
at the gap between both blocks.
Sliding through the text with a step size of one text
unit (sentence or pseudo-sentence), the coherence
is measured throughout the text, resulting in a se-
quence of coherence scores. Low scores indicate
potential topic shifts.
2. Smoothing: Before identifying the break points
in the text, the sequence of coherence scores is
smoothed to reduce the impact of small variations
in coherence. In this paper, an iterative moving
average smoothing is applied.
3. Depth Scores: To identify suitable break points,
the gaps of interest are the locations of the local
minima of the coherence sequence. The signifi-
cance of a topic shift is indicated by the depths
of a local minimum compared to the coherence
of neighboring text sections. This depth score s
d
is defined as the sum of the differences in coher-
ence between local minimum i and the closest lo-
cal maxima before (m
−
) and after (m
+
) the mini-
mum, respectively.
s
d
(i) = s
c
(m
−
) + s
c
(m
+
) − 2 · s
c
(i) (1)
4. Break Points: As only significant vocabulary
changes are likely to represent topic shifts in the
text, a threshold is defined to filter out insignif-
icant changes. Only gaps with a depth score
s
d
≥ µ − t · σ are selected as break points. t is
an adjustable threshold parameter, while µ and σ
are the mean and standard deviation of the depth
scores, respectively. In some cases, the result-
ing break point requires further adjustment. If
pseudo-sentences are used and a break point lies
within a sentence, the next sentence break before
or after the break point is used instead. Similarly,
if the source text contained structural information,
Putting Web Tables into Context
159

Figure 2: Linear text segmentation in TextTiling algorithm.
such as paragraphs, break points can be adjusted
to fall on paragraph breaks nearby.
There are several parameters in the text segmenta-
tion algorithm that impact the quality of the returned
segments, including the unit and block sizes, l and b,
as well as the threshold parameter t. In addition, the
selection of an appropriate similarity measure as well
as smoothing technique also influence the number and
location of break points. The optimal parameters de-
pend on the characteristics of the text corpus.
3 RELEVANCE ESTIMATION
USING WORD- AND
TOPIC-BASED SIMILARITY
After splitting the context into smaller topical sec-
tions, our next goal is to evaluate the relevance of each
segment with respect to the table content. Treating
both the table and the context as a bag of words, i.e.
assuming independence between words, we first focus
on word-based similarity measures to estimate the rel-
evance. The assumption is that if words from the ta-
ble content, such as attribute labels or cell entries, are
frequently mentioned in the context, it is very likely
that the text describes the table. Processing tables as a
loose collection of words is a common approach, for
example to find related tables (Cafarella et al., 2009)
or to retrieve tables that match a user query (Pimplikar
and Sarawagi, 2012). Incorporating the table struc-
ture, which often provides implicit information about
the dependencies between table entries, is much more
difficult, because table structures are very heteroge-
neous and there are no general rules that apply to all
tables.
Word-based similarity measures generally con-
sider the frequency of terms as well as their signif-
icance to evaluate the similarity between text seg-
ments. Regarding a table as a loose collection of
words, we face several issues. First of all, ta-
bles present information in a compact format, with
most textual entries limited to words or short phrases
and some of the information represented implicitly
through the semantics of the table structure. Com-
pared to text, tables contain significantly less explicit
information, leading to very sparse term vectors. Sec-
ond, the frequency of terms in a table is not represen-
tative of their importance regarding the tables main
topic. Attribute labels, which are designed to describe
the table content, generally only appear once, while
some attribute values can appear numerous times due
to redundancy in the table.
These characteristics are very similar to the char-
acteristics of keyword queries in text retrieval sys-
tems. Compared to a longer text document, the term
vector of a query is also very sparse, with little or no
repetition of terms. Consequently, we can regard a ta-
ble as a long keyword query. In the literature, a wide
range of retrieval functions has been proposed, which
score documents based on query relevance and spar-
sity. These retrieval functions present one option to
identify relevant context segments for Web tables.
Considering that we also have a significant num-
ber of large tables on the Web, which feature a term
count similar to that of the average context paragraph,
we can consider text similarity as another option to
evaluate context relevance.
3.1 Retrieval Functions
First, we consider several state-of-the-art retrieval
functions to estimate the relevance of context seg-
ments with respect to a table. The objective of a re-
trieval function is to rank documents based on their
relevance to a query, which generally is a list of
keywords or phrases. Different retrieval functions
use different techniques to address the importance
of query terms and the length of the document. As
retrieval functions we consider the following estab-
lished techniques: As the first retrieval function, we
use the TF-IDF score. As we only match the table
terms to the paragraphs of the table’s context, not to
paragraphs in the context of other tables, we define
the IDF score per table context, as the number of
paragraphs in the context divided by the number of
paragraphs that contain term t. We refer to this score
as the Inverse Paragraph Frequency (IPF). As a sec-
ond retrieval approach, we consider language mod-
els, probabilistic models that reflect the distribution of
terms in documents (Ponte and Croft, 1998). We con-
sider unigram models, which assume independence
between terms. Retrieval based on language models
ranks documents based on the likelihood of the query
(or table T) given the document model M
D
. Addition-
ally we apply smoothing techniques such as Jelinek-
KDIR 2016 - 8th International Conference on Knowledge Discovery and Information Retrieval
160

Mercer smoothing and Dirichlet smoothing to avoid
issues for query terms that do not appear in a doc-
ument. As the last group of retrieval functions, we
consider Okapi BM25, a probabilistic retrieval func-
tion frequently used for text retrieval (Robertson et al.,
1996). To score a document, the scoring function
takes into account the frequency of a term both in the
query and the document as well as the inverse docu-
ment frequency of the term. In addition, the size of the
document |D| as well as the average document size of
the collection avgdl are included to correct the score
depending on the size of the document at hand.
3.2 Similarity Metrics
In addition to various document retrieval functions,
we compare various symmetric text similarity mea-
sures. Probably the most common text similarity
measure is the cosine similarity of weighted term
vectors, which has also been used frequently in the
Web table recovery literature. Besides this measure,
we also consider two alternative measures, proposed
by (Whissell and Clarke, 2013), which represent sym-
metric variants of popular retrieval functions. In de-
tail, we consider the following text similarity mea-
sures in our study: The cosine similarity Cosine TF-
IDF represents a similarity measure frequently used
in connection with the vector space model, which
models texts or documents as vectors of term weights,
one for each term in a dictionary (Salton and Buck-
ley, 1988). The most common weighting functions
for the terms in the documents include the TF-IDF
score and its variants. We further consider a sym-
metric similarity measure based on language mod-
els proposed by (Whissell and Clarke, 2013). Us-
ing language models, it is often very likely for two
long documents to feature many similarities simply
due to terms that are very frequent in the language
and, thus, appear in most documents. To account for
this scenario, (Whissell and Clarke, 2013) incorpo-
rate logP(∗|C) to model chance, where C is the col-
lection or background model that reflects the general
term frequency in the language. (Whissell and Clarke,
2013) also propose a symmetric variant of the Okapi
BM25 retrieval function. To ensure symmetry, the
first factor of the retrieval function is replaced by a
factor that equals the second factor, utilizing the same
parameters k
1
and b. Again, we can use different vari-
ants of IDF or omit the score.
3.3 Topic-based Similarity
If the vocabulary in the documents is large, word-
based similarity measures operate in a very high-
dimensional space, as the size of the vocabulary de-
termines the dimensionality. In practice, computing
the similarity in such a high-dimensional space can
be computationally very expensive and impractical.
Furthermore, the analyzed data becomes very sparse
in such a high-dimensional space, which can impact
the ability to identify similar documents. To address
this dimensionality issue associated with word-based
similarity measures, we consider topic modeling as
an alternative. Instead of comparing tables and con-
text segments at word level, where the size of the vo-
cabulary determines the dimensionality, we compare
the topics associated with the words, instead. In ad-
dition to reducing the dimensionality, topic modeling
also enables the identification of implicit matches be-
tween a table and the associated context, where both
describe the same topic, but do not explicitly use the
same terms to describe it. Such relations between ta-
bles and context cannot be detected via word-based
matching.
Topic modeling aims to identify abstract topics in
a document collection and to model each document
based on its association with one or more of these top-
ics. In general, the presence of a topic is determined
from the frequency and co-occurrence of terms in the
document, and, in most cases, a topic is represented
as a probability distribution over all terms in the vo-
cabulary. In this paper, we focus on LDA to model
topics in tables as well as their context.
Latent Dirichlet Allocation (LDA) is a generative
probabilistic model to model topics in text collec-
tions (Blei et al., 2003). LDA is based on a generative
process that allows for documents to cover multiple
topics. The model incorporates topics K, documents
D and words from a fixed vocabulary N. W
d,n
denotes
the n-th word in document d. The topical structure
in a corpus is modeled by random variables φ
k
, θ
d
and Z
d,n
. Each topic k is described by a multinomial
probability distribution φ
k
over the term vocabulary.
Furthermore, each document d is associated with a
multinomial distribution θ
d
which describes the topic
proportions for the document. As each document can
describe multiple topics, this distribution reflects the
mixture of topics in the document. Finally, Z
d,n
de-
notes the topic assignment for word n in document d.
Variables α and β are hyper-parameters.
Similarity Measures. For each document or docu-
ment section, the LDA inference generates a vector
of topic proportions
b
θ
d
, which represents a discrete
probability distribution over all topics. Consequently,
in order to measure the similarity between the topical
representations of two documents, we can apply mea-
sures that quantify the similarity between probability
Putting Web Tables into Context
161

distributions. (Blei and Lafferty, 2009) suggest the
Hellinger distance.
Another common measure is the Kullback-Leibler
(KL) divergence, which, in its original form, is not
strictly a metric, as it is not symmetric. The KL
divergence of probability distribution P
2
from P
1
is
denoted as D
KL
(P
1
||P
2
). As a symmetric variant of
the KL divergence we use th sum of D
KL
(d
1
||d
2
) and
D
KL
(d
2
||d
1
).
3.4 Evaluation and Comparison
All presented approaches present viable options for
table-to-context matching. Considering the diverse
characteristics of Web tables, it is difficult to favor one
approach over the other. To gain a better understand-
ing of the functionality and behavior of these mea-
sures with respect to Web tables, we conduct a com-
parative study, analyzing different measures proposed
in the literature for a test set of Web tables. For the
evaluation, we use a set of 30 tables extracted from the
English Wikipedia along with their respective pages.
To retrieve context paragraphs, we utilize the orig-
inal structure of the Wikipedia articles, considering
headlines as natural topic boundaries. We manually
judged each resulting paragraph as either relevant or
not relevant. After applying the different measures to
score the context paragraphs, we use Mean Recipro-
cal Rank (MRR) and Mean Average Precision (MAP)
to evaluate the suitability of the similarity measures.
To determine the suitability of these retrieval func-
tions, we evaluate each retrieval function (with differ-
ent parameter settings, if applicable) on the test set.
To analyze the sensitivity of each approach to table
size, we split the test set into small, medium sized
and large tables, with table sizes of less than 20 terms,
between 20 and 200 terms and more than 200 terms,
respectively. In Figure 3, we present the best overall
MRR and MAP scores for each approach.
Overall, all retrieval functions achieve high scores
with only little variance across the different functions.
For our test set, the highest MMR and MAP scores are
achieved using retrieval functions based on language
models with Dirichlet smoothing (see Figure 3(a)).
The results indicate that more sophisticated retrieval
functions such as language models or BM25 are bet-
ter suited for the identification of relevant context than
the simple weighting scheme. The symmetric simi-
larity measures show only little variance between the
different measures.
However, comparing the cosine and BM25 simi-
larity measures, we can see that for our test set the
cosine similarity with simple TF weights outperforms
the more complex weighting scheme of BM25 (see
Figure 3(c)). For both approaches, we can also ob-
serve that inverse paragraph frequency (IPF) performs
better than the other IDF variants.
The analysis of the various symmetric similarity
measures for different table sizes shows slightly more
variation. As expected, all measures achieve the high-
est scores for larger tables with more than 200 terms.
Overall, symmetric text similarity measures produced
results of high quality.
To evaluate the suitability of LDA to estimate the
relevance of table context, we trained the LDA model
using a corpus of 1, 000 English Wikipedia articles
(from which the test tables were selected). For the
hyper-parameters, we use the settings often recom-
mended in the literature (Wei and Croft, 2006), with
β = 0.01 and α =
50
K
, where K is the number of top-
ics considered in the model. We varied the number
of topics in our experiments, but limit the results pre-
sented here to K ∈
{
200, 500, 1000
}
.
For each table and each context segment, we in-
fer a topic distribution using the trained LDA model
and measure the similarity between the topic distribu-
tion of the table and the topic distribution of each seg-
ment in the context of the table. Figure 3(d) shows the
overall MRR and MAP scores. The scores achieved
on our test set with different topic counts indicate
that topic modeling is significantly less effective in
estimating the context relevance, compared to word-
based matching techniques. We observe only very lit-
tle variation for different topic counts.
In our analysis, we can identify two possible rea-
sons for the significantly lower results. The first issue
is the table size. It appears that most tables in our test
set are too small, i.e. they contain too few terms, in
order to enable a meaningful inference of topic distri-
butions. An analysis of tables of different sizes con-
firms this assumption, as both MRR and MAP scores
improve with increasing table size.
The second issue is the topic count and granular-
ity. In an open domain scenario, such as the Web,
we face a huge number of possible topics, which is
replicated, although on a slightly smaller scale, on
Wikipedia. Using very general topics reduces the
number, however, in order to distinguish between the
topics of paragraphs of the same document, we re-
quire very detailed topics. Consequently, it is very
difficult to model the subtle differences between para-
graphs, if the overall corpus is heterogeneous and di-
verse.
For our test set, directly applying LDA to Web ta-
bles and their respective context segments does not
offer any benefits compared to the word-based simi-
larity measures. Therefore, we do not further consider
this approach in the remainder of this paper.
KDIR 2016 - 8th International Conference on Knowledge Discovery and Information Retrieval
162

(a) Retrieval Functions:
Vector Space and Language
Model
0.8
0.82
0.84
0.86
0.88
0.9
0.92
0.94
0.96
0.98
1
TF TF-IPF TF-IDF (Doc) TF-IDF (Pass) TF TF-IPF TF-IDF (Doc) TF-IDF (Pass)
Okapi BM25 (short) Okapi BM25 (long)
MRR MAP
(b) Retrieval Functions:
Okapi BM25 short and long
0.8
0.82
0.84
0.86
0.88
0.9
0.92
0.94
0.96
0.98
1
TF TF-IPF TF-IDF
(Doc)
TF-IDF
(Pass)
Dir.
Smooth.
J.-M.
Smooth.
TF TF-IPF TF-IDF
(Doc)
TF-IDF
(Pass)
Cosine Similarity Language Model Okapi BM25
MRR MAP
(c) Similarity Measures:
Cosine Similarity, Language
Model and Okapi BM25
0.4
0.42
0.44
0.46
0.48
0.5
0.52
0.54
0.56
0.58
K=200 K=500 K=1000 K=200 K=500 K=1000
simH simKL
MRR MAP
(d) Latent Dirichlet Alloca-
tion
Figure 3: Evaluation of retrieval functions, similarity measures and LDA to estimate the relevance of context segments.
4 CONTEXT SELECTION -
FILTER AND THRESHOLD
After evaluating the relevance of each context section
with respect to the table, using a retrieval function or
symmetric text similarity measure, we can retrieve a
ranked list of context sections. In the final step, we
need to decide which context sections to keep for sub-
sequent processing and which sections to discard as
irrelevant or noisy. Consequently, we require a thresh-
old for the relevance score.
Finding the optimal threshold for a large collec-
tion of tables and their respective contexts is very
challenging, as the Web pages can have very different
characteristics. In some cases, only a small section on
the Web page is related to the content of a table, while
in other cases the entire Web page can be regarded as
relevant. Furthermore, the similarity measures are not
always able to make a clear distinction between rel-
evant and irrelevant context. Thus, when selecting a
relevance threshold, we face a trade-off between elim-
inating noise in the context and missing potentially
relevant information. To address this trade-off, we
consider two alternative threshold specifications: A
rank-based threshold is a popular selection approach
in retrieval systems. Instead of considering the value
of the relevance score, context segments are regarded
as relevant based on their position in the ranked list
of all context sections. Only the top k sections are re-
trieved.In contrast, the score-based threshold is not
associated with a fixed position in the ranked list,
and, instead, takes the variance of the relevance scores
across the context sections into account. In particular,
the threshold is defined as follows: θ
score
= µ − t · σ,
where µ and σ are the mean and standard deviation of
the relevance scores, respectively.
While the rank-based threshold returns the same
number of context sections for each table, the score-
based threshold is different for each table. For each
approach, we can adjust the threshold by varying the
parameters k and t, respectively. Using the test set of
30 Web tables and associated context sections, we can
analyze the characteristic behavior of each threshold
approach. Varying the threshold parameters, we mea-
sure the accuracy as well as the F
1
measure, averaged
across all tables. Accuracy measures the percentage
of correctly identified context sections, i.e. the num-
ber of relevant sections that have been retrieved as
well as the number of irrelevant sections that have
been discarded. The F
1
measure only considers the
retrieved sections and takes into account precision and
recall. The precision states how many of the retrieved
sections are actually relevant to the table, while recall
states how many of the relevant sections have been
retrieved. Figure 4 shows the results. In our evalua-
tion, we consider three different measures to compute
the relevance scores of the context sections. As the
different retrieval functions and similarity measures
we studied in the previous section all produce very
different relevance scores and rankings, the choice of
a scoring function can influence the quality of the re-
trieved context sections. For the experiments, we con-
sider the cosine similarity of TF scores, a symmet-
ric similarity score based on language models with
Dirichlet smoothing (LM) as well as the BM25 re-
trieval function. As a baseline, we measure the accu-
racy and F
1
for the case where all context sections are
retrieved. Consequently, a higher score indicates an
improvement achieved through context selection.
Figures 4(a) and 4(b) show the results for the rank-
based threshold approach for k in the range [1, 10].
There are only little differences between the various
scoring functions. We can see an obvious improve-
ment over the baseline, which is decreasing as more
context is retrieved. The less significant improvement
in F
1
measure indicates the weakness of a fixed rank-
based threshold. With a fixed number of retrieved
context sections, this approach does not adapt very
well to the different characteristics of Web table con-
text, where some tables have significantly less rele-
vant context sections than others.
The results of the score-based threshold are pre-
sented in Figures 4(c) and 4(d), for parameter t in the
range [−1, 1]. Here we can clearly see the impact of
Putting Web Tables into Context
163
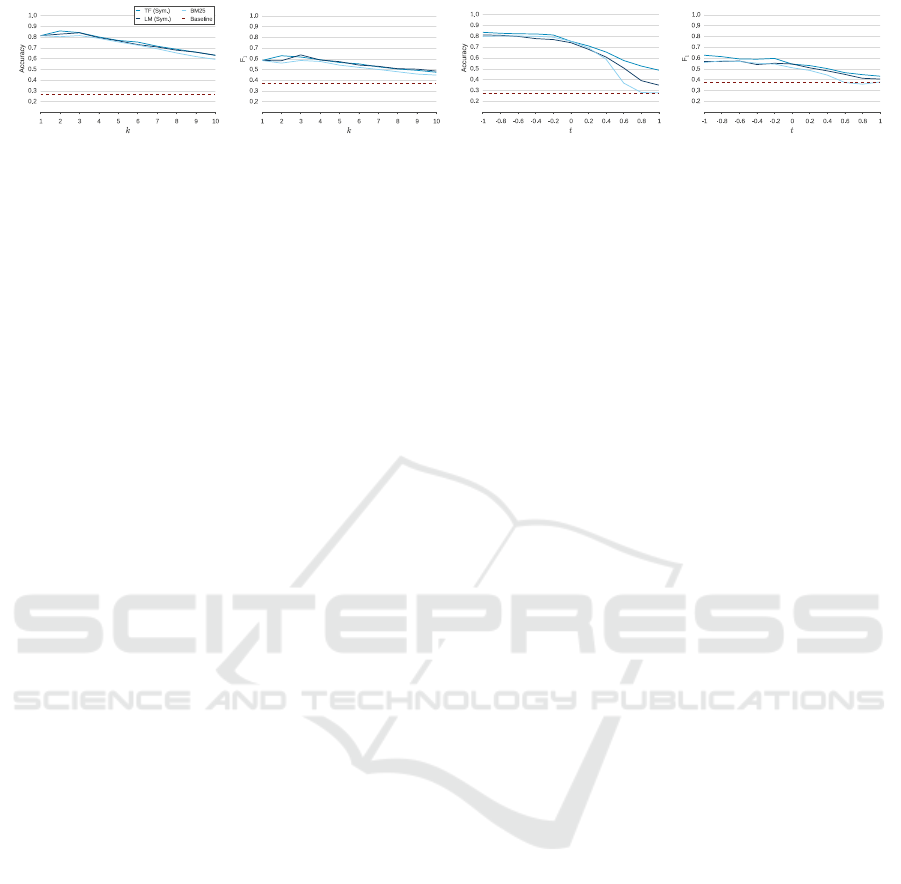
(a) Accuracy of Rank-based
Threshhold
(b) F
1
of Rank-based
Threshhold
(c) Accuracy of Score-based
Threshhold
(d) F
1
of Score-based
Threshhold
Figure 4: Average accuracy and F
1
measure of context selection using rank-based and score-based thresholds.
the scoring function, especially for higher values of
t. Overall, the maximum accuracy and F
1
values that
can be achieved with this threshold approach are very
similar to those achieved with a rank-based threshold.
The score-based threshold assumes some variation in
the relevance scores of the context sections. However,
if all context sections are equally relevant and receive
very similar scores, the threshold discards some of the
relevant sections, which is reflected by F
1
.
5 RELATED WORK
A table in a document is generally not an independent
object, but one of many components that carry infor-
mation content. Table recovery research has identified
the potential for other document components, such
as titles or text, to affect how table content is inter-
preted (Embley et al., 2006). Therefore, various work
related to table recognition and table understanding,
as well as applications that utilize document tables,
take the context of a table into account, e.g. the ta-
ble retrieval system TINTIN or the question answering
system QuASM (Pinto et al., 2002) that consider text
that is close to or between rows of a table (Pyreddy
and Croft, 1997). To improve the quality of the pro-
cess involved in table and context identification and
extraction, the authors of (Pinto et al., 2003) proposed
a classification approach based on conditional random
fields. Again, they focus solely on context that is lo-
cated directly before, after or within the boundaries of
the table.
In his thesis (Hurst, 2000), Hurst also includes text
segments that are not co-located with the table, such
as headings and the main text, and studies formats of
references to tables in the text. Such references can be
explicit, including an index for the table, as in “shown
in Table 2.2”, or implicit, without a unique string, as
in “in the following table”. Hurst focuses mainly on
the extraction of tables and context information, but
does not consider the relevance of context segments
with respect to a table, or the utilization of contextual
information to interpret the table content.
Contextual information is taken into account in
various applications. These include the identifica-
tion of a semantic relation between tables (Yakout
et al., 2012), establishing the relevance of a table in
response to a search query (Limaye et al., 2010; Pim-
plikar and Sarawagi, 2012), as well as the detection
of hidden attributes (Cafarella et al., 2009; Ling et al.,
2013). The selection of contextual information that is
considered suitable differs significantly amongst the
individual approaches. While many approaches do
not define a specific selection of context and sim-
ply consider all available information, others limit the
amount of information considered. In (Yakout et al.,
2012) the context is restricted to text that directly sur-
rounds the table on the Web page. In (Cafarella et al.,
2009) the authors further reduce the contextual infor-
mation by taking only significant terms into account,
specifically the top-k terms based on TF-IDF scores.
A more elaborate context selection technique is pro-
posed by (Pimplikar and Sarawagi, 2012) and subse-
quently applied by (Sarawagi and Chakrabarti, 2014).
Relevant context segments are selected based on their
position in the DOM tree of the document. Consid-
ered context types include heading and text segment.
Starting from the path between the table node and the
root of the DOM tree, all text nodes that are siblings
of nodes on the path are included. In order to esti-
mate its relevance to the table, each of these nodes is
then scored based on its distance from the table, its
position relative to the path as well as the occurrence
of formatting tags such as bold or italics. However,
as (Pimplikar and Sarawagi, 2012) skip further details
about the extraction of context segments, the suitabil-
ity of this technique is difficult to evaluate.
For search applications, the similarity between the
search terms and the table with its context is com-
puted, whereas integration applications measure the
similarity between two tables and their respective
context segments. In (Yakout et al., 2012) TF-IDF
is applied to identify conceptually related tables, con-
sidering the similarity between both context sections
as well as a table-to-context similarity between one
table and the context associated with the other ta-
ble (Yakout et al., 2012). This simple measure is fur-
ther extended by (Pimplikar and Sarawagi, 2012) to
KDIR 2016 - 8th International Conference on Knowledge Discovery and Information Retrieval
164

enable collective matching that incorporates the table
and context into a single similarity score.
In summary, the context of a table is frequently
recognized as an important resource in table under-
standing. However, the relevance of specific context
paragraphs with respect to a table has received only
limited attention so far.
6 CONCLUSION
To exploit the rich information stored in billions
of Web tables, additional contextual information is
needed to understand their content and intention. In
the most general case the overall document containing
the Web table could be considered to support table un-
derstanding. However, since most of the context will
not be related to the Web table at all this introduces
to much noise. Therefore, we proposed a novel con-
textualization approach for Web tables based on text
tiling and similarity estimation to evaluate the rele-
vance of context information. We performed a de-
tailed analysis of state-of-the-art retrieval functions
such as TF-IDF, language models, Okapi BM25, and
LDA and applied them on the Web table in ques-
tion as well as the different context paragraphs. Our
evaluation showed that language models with Dirich-
let smoothing deliver excellent results with an MRR
score of almost 0.98. We finally studied different
ranking schemes that enable us to effectively identify
the most relevant context paragraphs for a given Web
table.
REFERENCES
Allan, J. (2002). Introduction to topic detection and track-
ing. In Topic Detection and Tracking, pages 1–16.
Kluwer Academic Publishers.
Beeferman, D., Berger, A., and Lafferty, J. (1999). Statisti-
cal models for text segmentation. Machine Learning
- Special Issue on Natural Language Learning, 34(1-
3):177–210.
Blei, D. M. and Lafferty, J. D. (2009). Topic models. Text
Mining: Classification, Clustering, and Applications,
10:71.
Blei, D. M., Ng, A. Y., and Jordan, M. I. (2003). Latent
dirichlet allocation. The Journal of Machine Learning
Research, 3:993–1022.
Cafarella, M. J., Halevy, A. Y., and Khoussainova, N.
(2009). Data integration for the relational web. Pro-
ceedings of the VLDB Endowment, 2:1090–1101.
Eberius, J., Thiele, M., Braunschweig, K., and Lehner, W.
(2015). Top-k entity augmentation using consistent
set covering. In SSDBM’15, SSDBM ’15, pages 8:1–
8:12, New York, NY, USA. ACM.
Embley, D. W., Hurst, M., Lopresti, D., and Nagy, G.
(2006). Table-processing paradigms: a research sur-
vey. IJDAR’06, 8(2-3):66–86.
Hearst, M. A. (1997). Texttiling: Segmenting text into
multi-paragraph subtopic passages. Computational
Linguistics, 23(1):33–64.
Hurst, M. (2000). The Interpretation of Tables in Texts. PhD
thesis, University of Edinburgh.
Limaye, G., Sarawagi, S., and Chakrabarti, S. (2010). An-
notating and searching web tables using entities, types
and relationships. Proceedings of the VLDB Endow-
ment, 3:1338–1347.
Ling, X., Halevy, A. Y., Wu, F., and Yu, C. (2013). Synthe-
sizing union tables from the web. In IJCAI’13, pages
2677–2683.
Mulwad, V., Finin, T., and Joshi, A. (2011). Generating
linked data by inferring the semantics of tables. In
VLDS’11, pages 17–22.
Pimplikar, R. and Sarawagi, S. (2012). Answering table
queries on the web using column keywords. Proceed-
ings of the VLDB Endowment, 5(10):908–919.
Pinto, D., Branstein, M., Coleman, R., Croft, W. B., King,
M., Li, W., and Wei, X. (2002). Quasm: A system
for question answering using semi-structured data. In
JCDL’02, pages 46–55. ACM.
Pinto, D., McCallum, A., Wei, X., and Croft, W. B. (2003).
Table extraction using conditional random fields. In
SIGIR’03, pages 235–242. ACM.
Ponte, J. M. and Croft, W. B. (1998). A language modeling
approach to information retrieval. In SIGIR’98, pages
275–281. ACM.
Pyreddy, P. and Croft, W. B. (1997). Tintin: A system for
retrieval in text tables. In JCDL’97, pages 193–200.
ACM.
Robertson, S. E., Walker, S., Jones, S., Hancock-Beaulieu,
M. M., and Gatford, M. (1996). Okapi at trec-3. In
TREC’96, pages 109–126.
Salton, G. and Buckley, C. (1988). Term-weighting ap-
proaches in automatic text retrieval. Information Pro-
cessing and Management: an International Journal,
24(5):513–523.
Sarawagi, S. and Chakrabarti, S. (2014). Open-domain
quantity queries on web tables: Annotation, response,
and consensus models. In SIGKDD’14, pages 711–
720.
Wei, X. and Croft, W. B. (2006). Lda-based document mod-
els for ad-hoc retrieval. In SIGIR 2006, pages 178–
185. ACM.
Whissell, J. S. and Clarke, C. L. A. (2013). Effective
measures for inter-document similarity. In CIKM’13,
ACM, pages 1361–1370.
Yakout, M., Ganjam, K., Chakrabarti, K., and Chaudhuri, S.
(2012). Infogather: Entity augmentation and attribute
discovery by holistic matching with web tables. In
SIGMOD’12, pages 97–108. ACM.
Yin, X., Tan, W., and Liu, C. (2011). Facto: A fact lookup
engine based on web tables. In WWW’11, pages 507–
516.
Putting Web Tables into Context
165
