
Big Data Knowledge Service Framework based on Knowledge Fusion
∗
Fei Wang
1
, Hao Fan
1†
and Gang Liu
2
1
School of Information Management, Wuhan University, Luojiasan Road, Wuhan, P.R. China
2
School of Information Management, Central China Normal University, Luoyu Road, Wuhan, P.R. China
Keywords:
Knowledge Fusion, Knowledge Service, Process Model, Implementation Pattern, System Framework.
Abstract:
In big data environments, knowledge fusion is the necessary prerequisite and effective approach to implement
knowledge service. This paper firstly analyses the requirements of big data knowledge service and the contents
of knowledge fusion, constructs a multi-level architecture of knowledge service based on knowledge fusion.
Then, this paper presents a design of a knowledge fusion process model and analyses its implementation
patterns. Finally, a system framework of big data knowledge service is proposed based on knowledge fusion
processes, in which processes of both knowledge fusion and knowledge service are organically combined
together to provide an effective solution to achieve personalized, multi-level and innovative knowledge service.
1 INTRODUCTION
Knowledge is awareness and understanding about
people or things in the objective world, which is gen-
erated by feeling, communicating and logic reasoning
activities in the course of practice and education and
maybe facts, information or skills. With the devel-
opment of data creating, releasing, storing and pro-
cessing technologies, data is showing a rapid growth
trend in all society areas. Of all the data available
to the human civilization, 90% were produced in the
past two years (Meng and Chi, 2013). Big data gives
rise to the emergence of large scale knowledge bases.
Famous knowledge base research projects, e.g. DB-
pedia, KnowItAll, NELL and YAGO, use informa-
tion extraction techniques acquiring knowledge from
high quality network data sources (e.g. Wikipedia),
and automatically realize its construction and man-
agement (Suchanek and Weikum, 2014). Facts in
knowledge bases, including entity names, semantic
classes and their relationships, are derived from tex-
tual data in Web.
Meanwhile, big data brings about information
overload and pollution too, in which knowledge also
presents characteristics of heterogeneity, diversityand
independence. In the era of data, with rapidly increas-
∗
This paper is supported by the Chinese NSFC Inter-
national Cooperation and Exchange Program, Research on
Intelligent Home Care Platform based on Chronic Diseases
Knowledge (71661167007).
†
Corresponding Author
ing of information and knowledge, knowledge dis-
covery has become the research focus in various dis-
ciplines, including data science and information sci-
ence(Ye and Ma, 2015). Therefore, in order to im-
prove the efficiency and quality of knowledge service,
issues of analysing and utilizing knowledge existing
in big data, eliminating the inconsistency between dif-
ferent sources, and extracting, discovering and induc-
ing the potential valuable connotations, have become
important in knowledge management researches.
Knowledge Service (KS) is to meet user needs, by
analysing the knowledge requirements in the domain,
and applying knowledge acquisition, analysis, reor-
ganization and implementation processes via service
procedures helping users to find and form solutions
(Zhang, 2000). In big data environments, KS is no
longer limited to traditional literature and information
services, but turns its perspective into massive frag-
mented information, user behaviors and relationships,
and the resulting real-time, unstructured and machine
data (Qin et al., 2013). Features of multi-source, het-
erogeneous, real-time and low value density data have
brought unprecedented challenges to KS.
Knowledge Fusion (KF) is to acquire and utilize
knowledge aiming at the KS problems. Operated by
KF activities, implicate and undiscovered valuable
knowledge is mined from various distributed and het-
erogeneous data sources. KF converts autonomous
knowledge into a new one with higher levels of in-
tension and reliability, while KS helps users to find
potential associations between knowledge and fact,
116
Wang, F., Fan, H. and Liu, G.
Big Data Knowledge Service Framework based on Knowledge Fusion.
DOI: 10.5220/0006036301160123
In Proceedings of the 8th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2016) - Volume 3: KMIS, pages 116-123
ISBN: 978-989-758-203-5
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

improve decision-making levels by making more effi-
cient, objective and scientific judgments. KF becomes
a new growth point for KS (Tang and Wei, 2015).
2 RELATED WORK
2.1 Processes of KF
KF is a new concept developed on Information Fu-
sion. There are many intersections between the two
research areas. The early definition of KF is given
by Preece in the KRAFT project (Preece et al., 2001),
refers to a process locating and extracting knowledge
from multiple, heterogeneous on-line sources, and
transforming it so that the union of the knowledge
can be applied in problem-solving. Smirnov studies
on patterns for context-based KF in decision support
system (Smirnov et al., 2015), provides several KF
patterns including Simple, Flat, Extension, Config-
ured, Instantiated, Historical and Adaptation fusion,
specifically for decision-making demands.
Hou (Hou et al., 2006) and Xu (Xu et al., 2010)
believe that KF is to acquire new knowledge via intel-
ligently processing distributed databases, knowledge
bases and data warehouses by transforming, integrat-
ing and fusing knowledge. Xu gives a KF frame-
work based on ontology to reduce the fused knowl-
edge scale and improve its validity and accuracy.
The framework is composed by functional modules
such as constructing meta-knowledge set, determin-
ing knowledge measure indicators, designing fusion
algorithms and handling post-fusion knowledge.
Gou (Gou and Wu, 2006) proposes a method to
share and integrate distributed knowledge sources by
using the fusion process to map knowledge objects
into the ontology base and construct the knowledge
set, in which KF algorithms based on Genetic Algo-
rithm and Semantic Rule are used, and a feedback
mechanism is considered to optimize the fusion pro-
cess and knowledge space.
Qiu (Qiu and Yu, 2015) and Guo (Guo et al., 2012)
review and evaluate research trends and theoretical
developments of KF, point out that, there is not yet
a general framework for KF systems, as well as di-
rectly applicable KF algorithms and standardized pro-
cedures. Existing researches mainly focus on specific
KF frameworks, algorithms, and practical theories.
2.2 Framework of Big Data KS
Big data KS is produced in processes of acquiring,
storing, organizing and analysing data for decision-
making, which is a new model of information service
used to solve demands of handling structured, semi-
structured and unstructured data multi-dimensionally.
It has features of intelligent services oriented, auton-
omy demands, uncertainty and customer driven, and
is based on processes of sharing knowledge, ability
and resources (Qin et al., 2013). Kawtrakul indicates
that intelligently applying KS promotes the demand
of innovative and service-oriented economy, and the
key function of innovative service is to provide per-
sonalized KS (Kawtrakul, 2010). Research on big
data KS management needs to solve several key is-
sues such as representable, treatable, combinable and
reliable abilities of big data.
In terms of research on KS framework, Gao (Gao
et al., 2016) studies a library KS model based on asso-
ciated data, divides the KS process into three levels:
publishing resource, integrating resource and apply-
ing resource. Zhou (Zhou, 2008) provides a frame-
work of personalized KS based on SOA, considering
generation and acquisition mechanisms of the frame-
work and its implementation methods, and realizing
personalized KS according to user feedback infor-
mation and different requirements. Zhu (Zhu et al.,
2010) proposes a distributed KS framework based on
cloud-shadowmodel, which is supposed to be applied
in knowledge management systems.
Guan (Guan, 2015) provides a factor-relationship
model of big data KS based on the knowledge sup-
ply chain, “acquisition-processing-storage-service-
transfer”. It uses knowledge bases to store contents
required by KS processes, which is limited in terms of
massive data migration and dynamic knowledge up-
dating. Li (Li et al., 2013) analyses an architecture
of big data KS platform by partitioning it into sev-
eral hierarchical layers, systematically expounds the
key technologies required to build the platform. How-
ever, without analysing module relationships and log-
ical structures in layers, it lacks method analysis for
KS realization.
As discussed above, there is no uniform definition
of KF concepts and research categories, and a general
KF framework oriented to KS requirements has not
yet formed. It is necessary to carry out research on a
general applicable KF process model, and propose a
system framework of KS based on KF processes.
3 REQUIREMENT ANALYSIS ON
BIG DATA KS
In big data environments, data represents information
assets characterized by such a high volume, velocity,
variety and veracity to require specific technologies
and analytical methods for transforming it into value,
Big Data Knowledge Service Framework based on Knowledge Fusion
117

which brings new challenges to KS activities such as
knowledge acquisition, analysis and storage. The 4Vs
of big data puts forward new requirements of KS real-
ization such as heterogeneous, multi-source, implicit,
dynamic and verifiability demands.
KF is a process of applying knowledge extraction,
analysis, reorganization and integration activities over
multiple heterogeneous knowledge sources, mining
the implied valuable knowledge and information, and
forming new knowledge oriented to user needs. This
section discusses the KF contents oriented to the KS
requirements, and proposes a multi-level architecture
of KS based on KF processes.
3.1 KF Contents for KS Requirements
3.1.1 Heterogeneous Demand for KS
The accessing methods and querying results of het-
erogeneous knowledge sources are different from
each other, and so do its structures and contents.
Implementing KS over heterogeneous knowledge
sources, first of all, needs to access, define and de-
scribe the required contents. Knowledge objects from
different sources may be defined in different ways,
which needs to be transformed via a unified descrip-
tion method to carry out structural comparison and
content analysis among them. Then, subsequent KF
activities can be applied to discover and correct in-
consistency among the knowledge objects, to elimi-
nate redundant or repeated ones. Thus, oriented to
KS demand of heterogeneity, KF requires activities
of knowledge extraction, knowledge representation,
knowledge trans-formation and knowledge cleansing.
Knowledge extraction is built for extracting em-
bedded contents from sources to form knowledge ob-
jects, through activities of identification, comprehen-
sion, selection and induction. Knowledge represen-
tation is a process of defining and describing orga-
nizational structures, association rules and content-
handling mechanisms of knowledge objects. Knowl-
edge transformation transfers heterogeneous knowl-
edge into homogeneous one with uniform structure
represented in the same method, which is the key
issue solving the heterogeneity problem. Knowl-
edge cleansing is a process of reviewing and check-
ing knowledge objects, removing duplicate contents
and correcting errors, providinga unified and accurate
knowledge source for following KS activities, which
ensures correctness and consistency of the source.
3.1.2 Multi-source Demand for KS
Knowledge existing in multiple sources might be ho-
mogeneous on its structures and contents, but also re-
sults in the multi-source demand of KS, which needs
to select, aggregateand reorganize fragmented knowl-
edge, and so called knowledge integration. The con-
cepts of knowledge integration and knowledge fusion
have overlaps in term of dealing with multi-sources
and multi-structures knowledge objects, both of them
have connections and differences.
Literally, integration is the process of aggregat-
ing multiple individual objects to form a whole one,
while fusion is the process of recombining multiple
individual objects, and splitting and dismantling it
into a complete one. Integration emphasizes aggre-
gation and combination, while fusion is more empha-
sis on merging and reorganizing. After fusion pro-
cesses, knowledge objects should have new emerging
features relative to the original ones. Therefore, this
paper argues that KF is the advanced stage of knowl-
edge integration. KF applies fusion algorithms and
matching rules over the result of knowledge integra-
tion to implement deduction, discovery and innova-
tion of knowledge.
Furthermore, KF is also different from knowledge
aggregation, in which KF has no need to keep and
remain all knowledge concepts, relationships and in-
stances from the original sources, but need to con-
struct the required objects meeting KS demands.
3.1.3 Implicit Demand for KS
The implicit demand refers to identifying effective,
novel, potentially valuable knowledge objects and as-
sociations in services. Knowledge mining is a pro-
cess of finding and discovering implicit knowledge
objects from knowledge collections, linking the ob-
jects within a more explicit and effective way, and re-
sulting in new knowledge objects and associations.
In KF processes, knowledge mining can not
be completed individually by itself, but work with
knowledge integration together in manners of com-
plementary, interdependent, mutually supportive and
iterative. Knowledge integration constructs founda-
tion sources to support knowledge mining, and the
derivativeknowledgegenerated by knowledgemining
is further used to support recombining and reorganiz-
ing knowledge as well as eliminating redundancies,
by which the result of knowledge integration is opti-
mized and refined progressively. The two processes,
carrying out alternately, help users to obtain solutions
efficiently from massive, low value and complicated
data sources, to meet the implicit demand.
3.1.4 Dynamic Demand for KS
In big data environments, rapidly growing and contin-
uously updating data involves the dynamic demand
KMIS 2016 - 8th International Conference on Knowledge Management and Information Sharing
118
!"
#$%&'%()*+
!"
,&-*.)(/0
!+*1&23-2
42(.)$2%&
5%%6
7%%6
8%%6
6%%6
"%%6
9%3**: ;2<=62.$)>2 620%+()>=,+%&?@)@A:2+,>>2@@
95"6BC"6 9D%@2 E,4F 9((:B"G8B6HG8 ;65I H)33&21%.2 A+(*&*-?
Customized 62.$)>2
8.2>)@)*+=62.$)>2
62.$)>2
H%+%-202+(
J%&'2K%3323=
62.$)>2
62.$)>2
6(.%(2-?
!+*1&23-2
42:.2@2+(%()*+=
!+*1&23-2
G.%+@L*.0%()*+=
!+*1&23-2=
M&2%+@)+-
!+*1&23-2=
#N(.%>()*+
!+*1&23-2=H%(>/)+- !+*1&23-2=7+(2-.%()*+ !+*1&23-2=H)+)+-
F2(1*.O=!+*1&23-2=6*'.>2@
P
,@@*>)%(23
5%(%
I)+O23
!+*1&23-2
")2&3=!+*1&23-2=D%@2@
I)(2.%>('.2
;D
D'@)+2@@=
;D
42@2%.>/
;D
P
92(2.*-2+2*'@=5%(%
6>)Q=
5%(%
Product
Data
P
8%(2+(
5%(%
!+*1&23-2
H%)+(2+%+>2
!+*1&23-2
8.*$2+%+>2
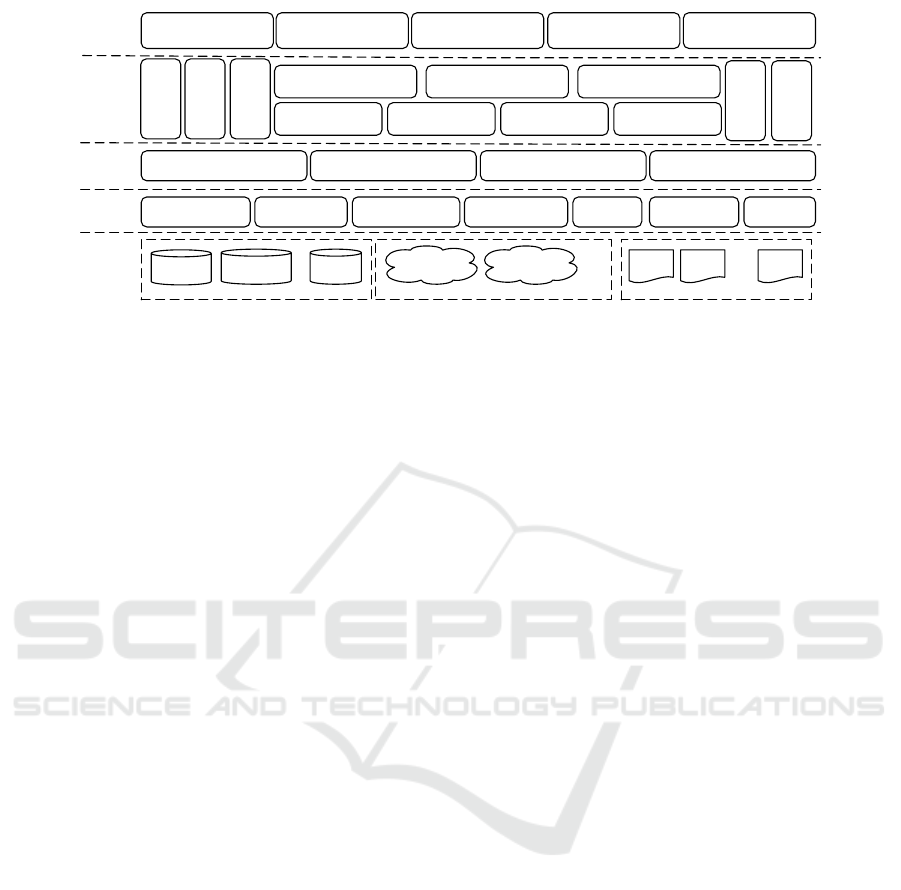
Figure 1: Muti-Level Architecture of Big Data Knowledge Service based on Knowledge Fusion.
of KS, i.e. the result of KS is constantly changing
with the updates of the knowledge sources. Knowl-
edge maintenance is the activity used to solve the dy-
namic demand. When the source content is modified
and changed, the fused knowledge needs to be up-
dated as well to ensure the consistency, reliability and
real-time abilities.
According to specific requirements of users, main-
tenance strategies might be either periodically or im-
mediately. In addition, due to the high cost of mi-
grating large data, incremental maintenance is a fea-
sible approach to implement knowledge maintenance.
Namely, only the changes of the knowledge sources
are captured and used to compute the updates of fused
knowledge, i.e. the fused knowledge is refreshed with
the updates rather than recomputed from scratch.
3.1.5 Verifiability Demand for KS
The verifiability demand is used to guarantee the cor-
rectness and validity of KS results. Both processes
generating results and source references for making
decisions, need to be traceable and verifiable. Knowl-
edge provenance is a process of finding and tracing
the lineages and the producing procedures of fused
knowledge, which results in either metadata record-
ing and annotating knowledge migration, conversion,
cleansing and integration procedures, or the original
information and initial data content of a specific fused
knowledge object, in the knowledge sources.
In addition to knowledge provenance, knowledge
evaluation is required for evaluating KF activities and
results, in terms of measuring the standardization, ef-
fectiveness and logicality of the activities, and ap-
praising the correctness, accuracy and completeness
of the results. Knowledge provenance can be used to
evaluate correctness and accuracy, to meet the verifi-
ability demand of KS.
3.2 Multi-level Architecture of KS
As discussed above, KF is the necessary prerequi-
site and effective means to implement big data KS.
To meet KS requirements, KF contents include activi-
ties of knowledge extraction, representation, transfor-
mation, cleansing, integration, mining, maintenance,
provenance and evaluation. Based on these KF activ-
ities, this paper proposes a multi-level architecture, as
shown in Figure 1, constructing the KS implementa-
tion procedure within five levels: Data-as-a-Service
(DaaS), Infrastructure-as-a-Service (IssA), Platform-
as-a-Service (PaaS), Fusion-as-a-Service (FaaS), and
Software-as-a-Service (SaaS).
Knowledge is widely distributed in various hetero-
geneous knowledge sources in big data environments,
the DaaS layer provides the underlying data sources
for KS activities. The IaaS layer provides support for
accessing data and extracting knowledge from the un-
derlying sources, via protocols, middleware tools or
APIs embedded within the big data infrastructure.
Parts of KF activities, such as knowledge extrac-
tion, representation, retrieval, maintenanceand prove-
nance, need to access knowledge sources and handle
the knowledge initially extracted from the sources.
The PaaS layer is specifically designed to provide
channels for these KF activities exchanging data with
the IaaS interfaces. The Fusion-as-a-service (FaaS)
layer, which is originally proposed in this paper, con-
tains the core activities of KF process that is used for
mainly solving demands of the upper KS activities.
The SaaS layer constitutes the business logic part
of big data KS directly interacting with users to
achieve the performance of personalized, multi-level
and innovative services. Customized services produce
personalized efforts to meet specific user demands in
accordance with requirement expressions; Precision
services produce different services for different users,
according to user types, preferences and behavior
Big Data Knowledge Service Framework based on Knowledge Fusion
119
!"#$%&'
()*+,-$
+,)
&."/0
!*)%&'
&."/1)23)
4-#)
5)$/"*6
7"8*9)
(-$-
7"8*9)
&':;,-18-$+".:<:=#)*:'))2>-96
4(:?.-1@#+#
A""1#
B.C*-#$*89$8*):
!1-$C"*D
E)>:(-$-
?!B
E)>:
7)*,+9):
!1-$C"*D
F$"1"3@
&'
G81)#
&'
?13"*+$HD
I+*$8-1
J-.21+.3
K-$)*-1+L)2
&7
=#)*%
M"-1
N".$).$
7"18$+".
I-18)%
-22)2
=#)*:O8)*+)#:P:
G)Q8+*)D).$#
K-+.$).-.9)
;R$*-9
$+".
N1)-.#
+.3
B.$)3*-
$+.3
&."/0
E0H"8#)
G)S*)#
).$+.3
A*-.C"*
+.3
G)$*+),
+.3
&."/0
5)$/"*
6
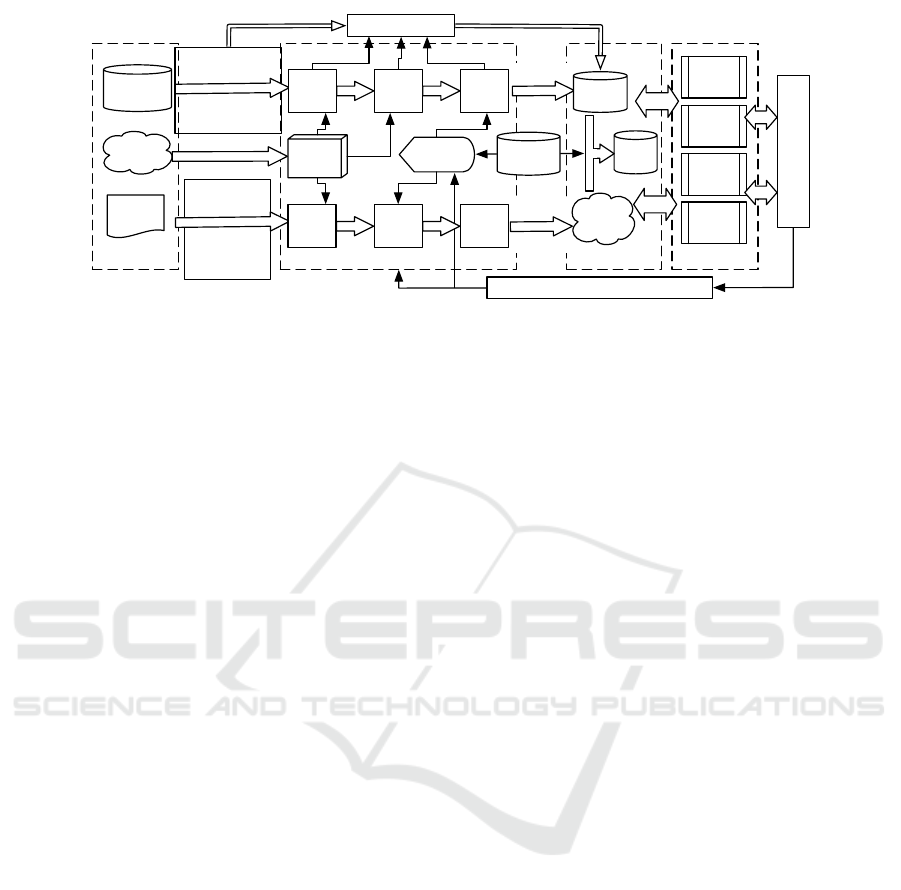
Figure 2: Process Model of Big Data Knowledge Fusion.
characteristics. Value-added services are going be-
yond regular service ranges, adopting unconventional
methods to achieve valuable services, as a perfor-
mance of service innovation.
Service management covers quality standards, se-
curity specifications, evaluation indicators, etc., to en-
sure KS qualities. Service strategy includes service
optimization, distribution and identification, etc., to
promote personalized and multi-level services.
4 PROCESSES OF BIG DATA KF
4.1 KF Process Model
KF activities can be treated as functional modules that
transform inputs into outputs, and used for composing
the KF process model. We roughly split the KF pro-
cess into three stages: Pre-KF, In-KF and Post-KF,
shown in Figure 2, in which the wide-white-line ar-
rows represent flows of data and knowledge, and the
fine-line ones represent flows of control information.
In Pre-KF stage, massive knowledge exists in
the initial state, and is widely located in distributed
knowledge bases and network sources. The big data
infrastructure and Web service platforms provide sup-
ports for accessing the Pre-KF knowledge.
The In-KF stage contains the main activities of
KF, either migrating knowledge objects from the
sources and storing it in the knowledge base though
knowledge extraction, cleansing and integration ac-
tivities, or generating knowledge networks to define
knowledge structures and associates though knowl-
edge representation, transformation and retrieval ac-
tivities. Knowledge networks aggregate and reorga-
nize knowledge definitions, structures and associates
from the source. Meanwhile, the In-KF stage in-
cludes the part of constructing domain ontology, de-
signing fusion algorithms and rules according to user
requirements and its problem definitions, which can
be revised and validated by accepting user feedbacks.
Also, it is necessary to establish a measurementmech-
anism for evaluating KF activities and it results, in
order to measure the efficiency and effectiveness and
provide a basis for optimizing and improving KS.
KF is a necessary prerequisite and effective means
for the realization of big data KS. From literature
service to information service and knowledge ser-
vice, which is a gradually deepening and developing
process. Based on the fused and derivative knowl-
edge, KS activities are divided into four types: user-
goal oriented, knowledge-content oriented, problem-
solution oriented and value-added oriented.
The user-goal oriented KS is a target driven ser-
vice, which is focusing on “whether or not did the
service solve users problems?”, but not “does the
service provide the information users need?”. The
knowledge-content oriented KS is based on logic ac-
quisition, through information acquisition and inte-
gration to form knowledge products in line with the
needs of users. The problem-solution oriented KS is
committed to helping users find or form a compre-
hensive solution through the continuous inquiry, anal-
ysis and reorganization of information and knowl-
edge. The value-added KS is concerned with repro-
cessing the existing services, realizing service values
by improving the efficiency of applying and innovat-
ing knowledge, so as to form new service products
with unique value.
4.2 KF Implementation Pattern
KS is supported both by knowledge that is rela-
tively stable, verified and frequently accessed, such as
the pathogenesis of a disease, clinical manifestation,
characteristic index, commonly used drugs, treatment
and pathological knowledge in chronic disease man-
agement situations; and by knowledge that is widely
KMIS 2016 - 8th International Conference on Knowledge Management and Information Sharing
120

existing in the network, real-time updated, usually
changing and unfrequently visited, such as the diag-
nosis treatment cases of the same disease type, and its
related research works, news reports, and so on.
Costs of big data accession, migration and stor-
age are very high. It is infeasible for realizing KS
by organizing and storing all source knowledge into a
single knowledge warehouse. Thus, this paper distin-
guishes KF implementation patterns into three types:
oriented to materialized knowledge warehouse, ori-
ented to virtual knowledge network, and based on the
mixed models.
4.2.1 Oriented to Materialized Knowledge
Warehouse
The KF implementation pattern oriented to material-
ized knowledge warehouse is to prepare knowledge
that is relatively stable and need to be frequently vis-
ited by KS activities, in terms of providing a local
organization and storage mode.
Knowledge warehouse is an integrated collection
facing topics, non volatile and changeable, which is
used to decision-support for knowledge service and
management processes. The so-called materialized is
to acquire the knowledge objects required by KS in
advance, and physically preserve it in warehouses, in
order to avoid repeatedly visiting and computing op-
erations over the sources.
Under this pattern, data analysing and processing
tools provided by the big data infrastructure are used
to support knowledge extraction activities. Appro-
priate knowledge objects are migrated and stored in
the warehouse by steps of knowledge cleansing, inte-
grating and loading. During the procedure, not only
knowledge objects, but also knowledge structures and
associates are handled to establish knowledge shar-
ing and reusing mechanisms. There is also implicit
knowledge in the warehouse needing to be excavated
and discovered, according to the types of user require-
ments, to form types of derivative knowledge.
4.2.2 Oriented to Virtual Knowledge Network
The KF implementation pattern oriented to virtual
knowledge network is used for handling knowledge
widely existing in the network and providing access
to methods for KS activities.
Knowledge networks might be divided into
three types: subject-subject, subject-knowledge and
knowledge-knowledge. In this paper, we refer to
knowledge-knowledge networks defining knowledge
structures, associates and constraints among knowl-
edge objects. Virtual knowledge networks contain
the knowledge definitions, but do not contain specific
knowledge units and instances. The time of execut-
ing conventional data query and analysis technologies
will increase to be unacceptable for handling big data,
and the pattern oriented to virtual network is mainly
used for dealing with this high-costs.
In addition to containing definitions of structures,
associates and constraints of fused knowledge ob-
jects, virtual knowledge networks use metadata, i.e.
the query statements over the data sources, to describe
procedures generating the fused objects. When KS
users need to access specific knowledge contents and
instances of virtual knowledge networks, user queries
are decomposed, step by step, into various specific
sub-queries over data sources. Based on Web service
platforms and its data processing API, knowledge re-
trieval module acquires query results from the source
in manners of stream or batch processing. Knowl-
edge representation, transformation and integration
activities further use the results to produce fused and
derivative knowledge to meet the user requirements.
4.2.3 Based on Mixed Models
The KF implementation pattern based on the mixed
modes comprehensively handle knowledge types re-
quired for KS activities, in which both material-
ized warehouses and virtual networks are considered.
Since linked knowledge will change along with the
changes of network, it is necessary to apply dynamic
selection of data sources and evaluate its knowledge
quality, and design adaptable strategies for choosing,
maintaining and updating the fused knowledge mate-
rialized in the warehouse.
5 SYSTEM FRAMEWORK OF
BIG DATA KS
5.1 KS Framework Model
As discussed above, KF processes either gather
and transform various, distributed and heterogeneous
knowledge into a materialized warehouse, or use
virtual network to link massive remote knowledge
sources. Both of them feasibly provide available
knowledge sources for following-up KS activities.
In order to achieve personalized, multi-level and
innovative services, this paper further analyses the KS
process, decomposes its activities, and constructs a
system framework based on the KF process model,
as shown in Figure 3, to meet the KS requirements.
Personalized and multi-levels demands for pre-
cision services require to analyse user requirements
and decompose complex problems into smaller, more
Big Data Knowledge Service Framework based on Knowledge Fusion
121

!"#$%&'#$(#"%)%*#+'($#,#-."
/0%1$23#""
4567'6.(2-
/-287#9:#%;#$5(3#%<1=
;#$5(3#
>2,?2-#-.
;#,6-.(3
*#6"2-(-:
0(#79
<-67@A(-:
B-.272:@
C6"#
;#$5(3#
D#32,?2".
;#$5(3#
D#"3$(E(-:
;#$5(3#
*#".$'3.'$(-:
;#$5(3#
F6.3G(-:
;#$5(3#
=,?7#,#-.(-:
H#.I
;2'$3#
D6.6
;2'$3#
/-28I
C6"#
J
Pre-KF
F6.#$(67(A#9
/K
L($.'67
/-28I%H#.I
Post-KF
Knowledge Service Stratigy
;#$5(3#
B?.(,(A(-:%
;#$5(3#
%<77236.(-:%
;#$5(3#%
=9#-.(M@(-:%
1$2E7#,
D#32,?2"(I%
/-28I
=-.#:$6.(2-
/-28I%
>7#6-"(-:
/-28I
*#.$63.(2-
/-28I
*#.$(5#67
/-28I
N$6-"M2$,6.(2-
/-28I
*#?$#"#-.6.(2-
In-KF
/-287#9:#
F6(-.#-6-3#%
/-287#9:#
1$25#-6-3#%
/;%F6-6:#,#-.
;#$5(3#
;#3'$(.@%
;#$5(3#
&'67(.@
;#$5(3#
4567'6.(2-
Figure 3: System Framework of Big Data KS based on KF.
manageable and tractable sub-problems. Then, the
service components needed to solve sub-problems are
compared with the ones provided by the KS system.
Throughservice matching and restructuring activities,
KS solutions for the entire problem are formed, and fi-
nally implemented with the support of KF processes.
In the framework, the KS API is the interface in-
teracting with users. User queries and requirements
are analysed and resolved by semantic reasoning and
domain analysis activities based on domain ontol-
ogy. Then, activities of problem decomposition, ser-
vice matching, service restructuring and service im-
plementation are used to realize the requirements.
Semantic reasoning focuses on knowledge con-
cepts and their relevance in semantic levels, and do-
main analysis is an analytical activity of the concept
objects in a particular field, such as domain defini-
tion, commonality abstraction, characteristic descrip-
tion, concept description, relationship identification,
and so on. Semantic reasoning and domain analy-
sis are necessary manners to decompose user require-
ments, and generally require the participation of do-
main experts for completion.
Service matching is a process of retrieving and
finding the service component satisfying user require-
ments from the base storing various service compo-
nents and specifications. Service matching may use
the Universal Description, Discovery, and Integration
(UDDI) standards to establish norms to complete ser-
vice releasing and discovering processes. Service re-
structuring is to test and verify the service compo-
nents found in service matching, remove redundan-
cies, and reassemble them into a feasible service solu-
tion. After service restructuring, the service solution
is converted to access requests over the fused knowl-
edge, and executed by service implementation activi-
ties, mainly including processes of request analysing
and decomposing, request rewriting and executing,
result assembling and integrating, etc.
Service description and service decomposition ap-
ply granularity analyses on services provided by KF
processes and its results, i.e. fused knowledge, re-
sulting in fine-grained service components and spec-
ifications, which are used for matching with the de-
composed fine-grained user requirements, and re-
constructing service solutions further accurately and
specifically satisfying the user requirements.
The KS framework presented here reveals cor-
responding relationships and influence mechanisms
among KS activities and KF processes, and provides
a systematic solution for implementing personalized,
multi-level and innovative services for KS users.
5.2 KS Strategy
The KS strategy is concerned with the processes
of service identification, allocation and optimiza-
tion. Service identification is to abstract applicable
and functionalized service components from complex
business flows, which is carrying out standardized
management on the service interfaces. The KF pro-
cess, as the basis of KS, includes knowledge repre-
sentation, extraction, cleansing, transformation and
integration modules. Different modules combined to-
gether form different KF implementation patterns ori-
ented to either materialized warehouses or virtual net-
works. Service identification is mainly to standardize
the interface definition and component functionality
of the services provided by KF processes, and enable
them to be feasible and accessible for KS activities.
Service allocation is the process of assigning the
identified service to appropriate users and problem
domains according to the requirements, so as to real-
ize precision services. Among user requirements and
service components with different granularity, there
might be one-to-one, one-to-many or many-to-many
mapping associations. Based on analysing and clas-
sifying these associations, allocation principles and
mechanisms are developed to supply references for
service matching and restructuring.
In specific situations, one requirement might cor-
respond with a variety of service allocation strategies.
Different strategies produce different service match-
ing and restructuring schemes, so that service solu-
tions and implementation results are varied. Service
optimization is to analyse affecting effects of service
allocation strategies, adjust service matching and re-
structuring schemes, and optimize KF process results,
so as to ensure the realization of innovative KS.
KMIS 2016 - 8th International Conference on Knowledge Management and Information Sharing
122

5.3 KS Management
KS management is essential to improve the quality of
service (QoS) of the framework, in terms of standard-
izing and administrating security measures, quality
standards and evaluation indicators of KS. Security
measures include mechanisms of user authentication,
role administration and privilege management, gener-
ally working along with the service allocation strate-
gies, to assign appropriate KS solutions for various
types and levels of users, in which both the security
and the precision of the services are considered.
Quality standards and evaluation indicators are in-
terdependent and complementary. Combined with
the evaluation module of KF process, quality stan-
dards are used to determine and classify the corre-
spondence relationships between KF results and KS
requirements in various degrees and levels, which
is also the standard of satisfaction for KS demands,
while evaluation indicators are used to assess the QoS
in perspectives of user cognition and sensation, to in-
dicate the differences between user expectation and
user perception, between expected service results and
experienced service results, and between desired ser-
vice qualities and perceived service qualities.
6 CONCLUSIONS
KF is a new research topic rising to the challenges
of KS. The emergence of massive, various and het-
erogeneous knowledge in big data environments im-
plies new demands on both KF and KS implementa-
tions. This paper reviews current research on KF pro-
cesses and KS frameworks, and analyses big data KS
requirements in terms of KF contents. Then this pa-
per constructs the KF process model and implementa-
tion patterns, proposes a multi-level architecture and
a system framework of big data KS, organically com-
bining with KF processes together, to meet demands
of personalized, multi-level and innovative services.
In future work, we will consider to apply the KF
process model for empirical analysis in a specific do-
main, i.e. chronic diseases knowledge management.
REFERENCES
Gao, J., Li, K., and Liang, Y. (2016). Research on library
knowledge service model based on linked data. Infor-
mation Science, 34(05):64–68.
Gou, J. and Wu, Y. (2006). Knowledge fusion: A new
method to share and integrate distributed knowledge
sources. In 1st European Conference on Technology
Enhanced Learning, Greece, October, 1-4.
Guan, S. (2015). Study on key elements and implemen-
tation model of big data knowledge service platform.
Library Forum, 06:87–93.
Guo, Q., Guan, X., and Cao, X. (2012). Research progress
and trends of knowledge fusion. Journal of China
Academy of Electronics and Information Technology,
7(3).
Hou, J., Yang, J., and Jiang, Y. (2006). Knowledge fusion
algorithm based on metadata and ontology. Journal
of Computer-Aided Design and Computer Graphics,
18(06):819–813.
Kawtrakul, A. (2010). Beyond knowledge management:
knowledge service innovation. In Intl Conference on
Data Engineering and Management.
Li, Z., Cui, J., and Chen, C. (2013). Research on key tech-
nologies of big data knowledge service platform con-
struction. Information and Documentation Services,
02:29–34.
Meng, X. and Chi, X. (2013). Big data management: con-
cepts, technologies and challenges. Computer Re-
search and Development, 50(1):146–169.
Preece, A., Hui, K., and Gray, A. (2001). Kraft: An agent
architecture for knowledge fusion. International Jour-
nal of Cooperative Information Systems, 10(12):171–
195.
Qin, X., Li, C., and Mai, F. (2013). The connotation, typical
features and conceptual model of large data knowl-
edge service. Information and Documentation Ser-
vices, (02):18–22.
Qiu, J. and Yu, H. (2015). Research progress and trends of
knowledge fusion in perspectives of knowledge sci-
ence. Library and Information Service, 59(08):126–
132+148.
Smirnov, A., Levashova, T., and Shilov, N. (2015). Patterns
for context-based knowledge fusion in decision sup-
port systems. Information Fusion, (21):114–129.
Suchanek, F. and Weikum, G. (2014). Knowledge bases in
the age of big data analytics. In Proceedings of the
VLDB Endowment, volume 7, pages 1713–1714.
Tang, X. and Wei, W. (2015). The growth points of knowl-
edge service in big data age. Researches in Library
Science, (05):9–14.
Xu, C., Li, A., and Liu, X. (2010). Knowledge fusion archi-
tecture. Journal of Computer-Aided Design and Com-
puter Graphics, 22(07).
Ye, Y. and Ma, F. (2015). The rise of data science and its
relation with information science. Journal of Informa-
tion Science, 34(6):575–580.
Zhang, X. (2000). Towards knowledge service: searching
for growth points of library and information work in
the new century. Journal of Library Science in China,
26(5):32–37.
Zhou, L. (2008). Personalized knowledge service architec-
ture based on soa. In Proceeding of 22nd National
Symposium of Computer Information Management.
Zhu, J., Shen, S., and Zhao, D. (2010). Knowledge ser-
vice architecture based on ontological cloud shadow
model. In Academic annual conference of information
society of China Electronic Association Proceeding.
Big Data Knowledge Service Framework based on Knowledge Fusion
123
