
Improving Open Source Face Detection by Combining an Adapted
Cascade Classification Pipeline and Active Learning
Steven Puttemans
1
, Can Erg¨un
2
and Toon Goedem´e
1
1
KU Leuven, EAVISE Research Group, Jan Pieter De Nayerlaan 5, Sint-Katelijne-Waver, Belgium
2
Istanbul University, Faculty of Economics, B eyazt, 34452 Fatih/Istanbul, Turkey
{steven.puttemans, toon.goedeme}@kuleuven.be, can.e992@hotmail.com
Keywords:
Open Source, Face Detection, Cascade Classification, Active Learning.
Abstract:
Computer vision has almost solved the issue of in the wild face detection, using complex techniques like
convolutional neural networks. On the contrary many open source computer vision f rameworks like OpenCV
have not yet made the switch to these complex techniques and tend to depend on well established algorithms
for face detection, like the cascade classification pipeline suggested by Viola and Jones. The accuracy of
these basic face detectors on public datasets like FDDB stays rather low, mainly due to the high number of
false positive detections. We propose several adaptations to the current existing face detection model training
pipeline of OpenCV. We improve the training sample generation and annotation procedure, and apply an active
learning strategy. These boost the accuracy of in the wild face detection on the FDDB dataset drastically,
closing the gap towards the accuracy gained by CNN- based face detectors. The proposed changes allow us to
provide an improved face detection model to OpenCV, achieving a remarkably high precision at an acceptable
recall, two critical requirements for further processing pipelines like person identification, etc.
1 INTRODUCTIO N
Face detection (see Figure 1) is a well studied pro-
blem in computer vision, and good solutions are pre-
sented in literature. However we notice that open
source computer vision frameworks like OpenCV
(Bradski et al., 2000), offer face detecto rs based on
existing learning techniques, which are unable to
yield high acc uracies on the availab le public da ta sets.
A root ca use can be the fact that most of these mo-
dels have b een created in the earlier ages of co mpu-
ter vision, when academic research was still interested
in older cascade classifier based tec hniques, like (Vi-
ola and Jones, 2001). Academic research evolved
and moved on, discovering more promising techni-
ques like convolutional neural networks and loosing
interest in well establishe d and proven-to-work algo-
rithms. T his resulted in a well known computer vision
library still providing a basic face detector, achieving
only average detection results on any given dataset.
On the other side, users from the industry in-
terested in turning the se ope n source compu te r vi-
sion f rameworks into working applications, get stuck
at improving the existing performance of the face
detection techniques. Their internal organizational
structure does not allow to put efforts into research
that tries to bo ost the performance of current algo-
rithms. Two of the largest issues when trying to im-
prove these existing techniques, are the availability
of large amounts of training data and the achievable
accuracy limitation reported b y academic research of
different detection set-ups, using this basic detec tion
model.
In order to fill the gap we decided to investigate
how the current cascade classification pipeline for
training a face detector inside OpenCV could be adap-
ted to achieve a higher de tection accuracy. We d o this
by adjusting the face annotations, improving the nega-
tive training sample collection and by using an active
learning strategy to iteratively a dd h a rd positive (po-
sitive windows classified as negatives in the previous
iteration) and hard negative (negative windows classi-
fied as positives in the previous iteration) samples to
the object detector training process.
Furthermore, we experience that industrial appli-
cations of face detection tend to fail due to false po-
sitive detections, as seen in Figure 1, because post-
detection pro c essing steps depend on a face being
available. In th e case of a face rec ognition app li-
Figure 1: Example of C ascadeClassifier.detectMultiScale()
in OpenCV3.1 framework (OpenCVBaseline model).
396
Puttemans S., Ergun C. and GoedemÃl’ T.
Improving Open Source Face Detection by Combining an Adapted Cascade Classification Pipeline and Active Learning.
DOI: 10.5220/0006256003960404
In Proceedings of the 12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2017), pages 396-404
ISBN: 978-989-758-226-4
Copyright
c
2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

cation, the face detection can be the basis of gat-
hering training and test annota tions (Learned-Miller
et al., 2016; Wolf et al., 2011). Therefore we aim
at improving the available face detection model of
OpenCV3.1, based on local b inary patterns (Liao
et al., 20 07), aiming for a very high precision at an
acceptable recall.
The remaind e r of this paper is structured as fol-
lows. Section 2 presents related research, while
section 3 discusses the used framework and datasets.
This is followed by section 4 discussing the propo sed
approa c h in detail. Finally section 5 elaborates on the
obtained results while section 6 a nd section 7 sum up
conclusions and possible future improvements.
2 RELATED WORK
The O penCV f ramework is an open source computer
vision framework providing a collection of techniques
ranging from basic image segmentation to c omplex
3D model generation. It steadily grows in size by con-
tributions from a community of both academic re se-
archers and industrial partners, adding rec ent advan-
ces in the computer vision community, while trying
to maintain the quality of the existing back-end. We
notice that once new fu nctionality is integrated for a
longer p eriod of time and heavily used by the commu-
nity, investmen ts in improving the functionality ten ds
to stop. This could be explained by the fact that the
computer vision community has no interest in a ctual
relevant industrial implementatio ns, but rather in pus-
hing the state-of-the-art even further.
Recent advances in computer vision solve face de-
tection by usin g complex techniques like multi-task
cascaded convolutional neur al networks (Zhang et al.,
2016), co nvolutional neural networks combined with
3D information (Li et al., 2016) or recurrent convo-
lutional neural networks (Jiang and Lear ned-Miller,
2016). These techniques yield very promising results,
but tend to be fairly complex to implement in actual
applications. There is still a lack in well docu men-
ted and supported open source software libraries that
are easy to use. Furthermore we noticed Op enCV is
paving the way of integrating these newer techniques,
but up till now, their performance inside the OpenCV
framework is still not a s bug an d error free as desired
by industrial companies.
The work of Viola and Jones (Viola and Jones,
2001) on face detection using a boosted cascade of
weak classifiers has been around for q uite some time.
It is the standard frontal face detector for many indus-
trial applications so far, like e.g. digital photo came-
ras. A d ownside is that many companies use the avai-
lable so ftware to train their own more complex face
detection models, without sharing the models back
with the community. This is mainly due to the fact
that OpenCV oper ates under a BSD license, allowing
compan ie s to use the code without sharing back any
critical adaptations or changes. With our work we aim
at improving the currently availab le fr ontal face mo-
del based on local binary patterns (used as a baseline
in this publication) and achieve a model tha t is able
to accurately detect frontal faces in a large variety of
set-ups.
One cou ld argue that working on such an old
technique is basically a waste of time invested. Howe-
ver, several recent research papers like (Zheng et al.,
2016; Puttemans et al., 2016a; Fre jlichowski et al.,
2016; Puttemans et al., 2016b ; Shaikh et al., 2016)
prove the impor ta nce of such well established techni-
ques for sp ecific cases of industrial object detection.
3 FRAMEWORK AND DATASET
For building our approach we depend on the
OpenCV3.1 framework
1
, provided and maintained
by I ntel. We focus on using the CascadeClassifier ob-
ject detection functionality in the C++ interface toget-
her with the opencv
traincascade application, contai-
ning all functionality for building a boosted cascade
of weak classifiers using the approach suggested by
(Viola and Jones, 2001).
Since the training data of the current OpenCV face
detection models is no long e r availab le, we c ollected
a set of face images for training our own frontal face
detection model. The ima ges are collected from vari-
ous sources like YouTub e videos and by using a bulk
image grabber on social media, imageboards and goo-
gle image search re sults. Rem ark tha t all of these ima-
ges are not accompanied by groun d truth face labels.
On top of that, we created a multi-threaded tool that
can use an existing face detection m odel to efficiently
search for valuable face data in a given video, that can
then aga in be added to th e training data sets as hard
positive and hard negative samples.
Table 1: Training data overview for trained models.
Model #pos #neg #stages #stumps
OpenCVB xxx xxx 20 139
BoostedB 1.000 750k 26 137
IterHardPos 1.250 750k 19 146
IterHardPos+ 1.500 750k 19 149
For training our new models, we manually anno-
1
http://www.opencv.org
Improving Open Source Face Detection by Combining an Adapted Cascade Classification Pipeline and Active Learning
397

Figure 2: Changing the annotations from full-face to inner-face: (green) OpenCV (red) ours.
tate 1.000 face regions as positive tra ining windows
and combine this with 750.000 negative training win-
dows, automatically grabbed from large resolution
negative images not conta ining faces. As show in Ta-
ble 1 we then increase the positives dataset for each
new iteration with 250 extra ha rd positive samp le s.
These are gathered from a large set of positive ima-
ges, in which we know faces occur. Whenever the
initial detector is not able to find a face region, a ma-
nual intervention is required, asking for a face label,
and adding it as a training sample for the following
training iteration. The positive training set used for
training our final IterativeHardPositives+ model, can
be requested by contacting one of the paper authors.
For validating our new models and comparing
them to the existing OpenCV baseline, we use the
Face Detection Data Set and Benchmark
2
(FDDB) da-
taset (Jain and L e arned-Miller, 2010). This d ataset
contains 5171 face annotations in 2 845 images col-
lected from the larger Faces in the Wild dataset (Berg
et al., 20 05). The dataset focuses on pushing the li-
mits in unconstrained face detection. In order to be
able to obtain a dec e nt baseline, we converted the ex-
isting image annotations into the OpenCV u sed for-
mat, and made them publicly available
3
.
4 SUGGESTED APPROACH
In the following su bsections we will discuss the dif-
ferent adaptations made to the existing cascade clas-
sifier training pipeline, leading to an overall increase
in performance, as discussed in section 5.
4.1 Changing the Face’s Region of
Interest During Annotation
When taking a closer lo ok at the output of the
OpenCV LBP frontal face detector, we no tice that in
2
http://vis-www.cs.umass.edu/fddb/
3
http://eavise.be/OpenSourceFaceDetection/
many cases the detection output contains the com -
plete head, including ears, hair and sometimes even
backgr ound info rmation. This is due to the OpenCV
training data annotations. Figure 2 indicates that
OpenCV aimed to include as much facial informa tion
as p ossible to feed to the training algorith m. Since a
face detector needs to be generic, we focus on the face
part containing the most gener a l features over any gi-
ven face dataset. In order to reduce the amount o f
non-tr ivial face information, we decided to annotate
faces as th e inner face region only, seen as the red
annotations in Figure 1, and as previously sugg ested
by (Mathias et a l., 2014) for similar face detection
techniques. This approach has several benefits. I t r e-
moves tons of features fro m th e feature pool of the
boosting algorithm, reducing the amount of features
that need to be evaluated du ring model training. Furt-
hermore the inner face is more robust to rotation (both
in-plane as out-o f-plane). We elaborate more on these
in-plane and out-of-plane rotatio ns in section 5.4.
4.2 Adapting the N egative Training
Sample Collection
OpenCV offers an automated way of collecting nega-
tive samples from a set of random background ima-
ges not containing the object. The algorithm resca-
les the given negative images to different sizes and
uses a sliding window based sequential collecting of
negative windows, without any overlap between sub-
sequential windows. Once the set of negative ima ges
is completely processed, the p rocess is repeated and
adding a pixel o ffset in each image, to ob ta in slightly
different samples (at pixel level). If a set is traversed
multiple times, increasing the offset each time, this
process equals applying a pixel shifting sliding win-
dow approach, as illustrated in Figure 3(a). While the
basic idea of capturing slight differences in your data
might be a good starting point, this approach genera -
tes a huge amount of negative samples which do not
add extra meaningful knowledge to th e process, a nd
can thus not be seen as unique samples.
VISAPP 2017 - International Conference on Computer Vision Theory and Applications
398

(a) Original proces inside OpenCV framework.
(b) Suggested adapted pipeline.
Figure 3: Adaptations to the negative windows collection
process.
Lookin g at the boosting process used to train the
cascade classifier (b y default Ad a Boost ( Freund et al.,
1999)), we notice that each new negative window can
only be allowed as negative training sample for a new
stage, if the previous stages do not reject it. If there is
only a slight pixel shift for different negatives, then
this rejection p hase will just evaluate a lot of win-
dows, of which we already know that they will be
rejected. Therefore we adapted the interface and re-
moved the pixel offset pr ocedure. By removing this
proced ure and having no overlap between subsequent
negative windows, we introduce a possible loss of va-
luable information sha red a round the borders of sub-
sequent samples. This lost inform ation might conta in
critical knowledge for building a ro bust detector. To
reduce this lo ss of informatio n we refine the scale ge-
neration in the im a ge pyr a mid. Where Ope nCV ge-
nerates an image pyramid with a scale parameter of
1.4, we d e cide to lower this scale parameter value 1.1
to ensure that negative samples gathered on different
pyramid scales are diverse enough while keeping as
much valuable information as possible. Th is is illus-
trated in Fig ure 3(b). By doing so, lost information on
sample borders on one scale will be captured by either
the previous or the subsequent scale. An extra bene-
fit of refining the scale pyram id, is th a t the resulting
object detection model is more robust to scale chan-
ges of the object, able to capture smaller variations in
size.
Based on these adaptations it is quite straightfor-
ward to collect a large set of negative data samples,
something nece ssary to create a robust face detection
model for in the wild applications. Considering a high
resolution image of 1.080 × 1.920 pixels, we can al-
ready collect 30.00 0 negative training samples. This
allows us to increase the number of negative samples
per stage in our trained cascade classifier to multiple
hundred thousands of samples, trying to model the
backgr ound as good as possible. This will increase
training time per stage, but will reduce the amount of
stages, and thus make the model faster, less complex
and more accurate at detection time.
4.3 Iterative Active Learning Strategy
for Hard Training Samples
Supplyin g heaps of data to machine learning algo-
rithms allow to lear n very complex object detection
models. The downside is that both in gath ering po-
sitive an d negative trainin g data, it is very difficult to
tell which new sample will actually improve the ef-
ficiency of the detection mod e l. In order to decide
which samp les are actually valuable to be added to
the proce ss, we apply a techniq ue called active le-
arning. The idea is to use the model trained by th e
previous iteration and use that model to tell us which
samples are valuable (c lose to the decision bounda ry)
and which are not (no ambiguity in labelling), when
adding them to the next iteratio n training process, as
seen in Figure 4. We make a distinc tion between hard
negatives and hard positives as explained below. Furt-
hermore the advantage of active lea rning is that we li-
mit the amount of manual labour drastically, since we
only need to provid e labels to new tra ining samples
that add extra knowledge to the trained classifier.
4.3.1 Hard Negative Samples
Hard negative samples are gathered by collecting a set
of negative imag e s a nd running our previously trai-
ned face detector on the m. All detections returned are
Figure 4: A schematic overview of the active learning pro-
cess (hand symbol) manual intervention/annotation ( com-
puter symbol) fully automated processing.
Improving Open Source Face Detection by Combining an Adapted Cascade Classification Pipeline and Active Learning
399
in fact negative windows that still trigger a detection,
and are thus not assigned to the background yet by our
current model. Basically these samples contain infor-
mation that was not yet captured by the previously
collected set o f negative samples and thus provide va-
luable information to the training process.
4.3.2 Hard Positive Samples
Hard positive samples are gathered by collecting a
large set of unlabelled images containing faces. We
only know the images contain one (or more) faces,
but we do not have a labelled location. On these ima -
ges, the current face detector is executed (with a low
detection certainty threshold) and a piece of software
keeps track of images that do not trigger a detection.
In that case, an operator is asked to manually select
the face regio n for those trigge red image s and thus
provide labels. This region is stored as a hard positive
sample that can still give the model learning interface
enoug h extra valuable k nowledge on how it shou ld be
learning its model.
4.4 Halting Training when Negative
Dataset is Consumed
The original OpenCV implementation use pixel-wise
offsets in the negative sample grabbing to avoid the
training to halt w hen the original provided dataset is
completely consumed in a first run. In section 4.2 we
already describe that u sin g the se pixel shifted win-
dows is overkill and adds a lot of redundant data. We
halt the training when the negative dataset is comple-
tely consumed. Once that ha ppens we give the ope-
rator two possibilities. Either we allow to add ex-
tra images to the negative image dataset, or we re-
turn the amount of negative samples that was gr ab-
bed in the last stage before the training was halted.
This allows the operator to finalize the last stage with
this exact amount of samples and thus train a model
using every single negative sample window, comple-
tely consuming the available negative dataset.
4.5 Using the Adaptations to Train
Different Face Detection Models
By smartly comb ining all the adaptations suggested
in section 4.1, 4 .2 and 4.3 we tr ain different face de-
tection models where we iteratively try to improve the
accuracy of the obtained model. Ta ble 1 describes the
training data used for these models, in combination
with th e number of model stages and the number of
features (each forming a stump/bina ry de c isio n tree)
selected by the boosting process.
Our first model (referred to as ‘BoostedBaseline’)
can be seen as o ur baseline we iteratively tr y to im-
prove by applying th e active learning strategy. We
limit the training to only incorporate stumps, which
are single layer decision trees. One might argue that
using more co mplex decision trees is more profitable
but previous research shows that u sing mo re com plex
trees actually slows the detection process (Reyzin and
Schapire, 2006), because more features need to be
evaluated in early stages. For each boosted learning
model, the increase in performance when adding fe-
atures should outweigh the complexity and thus the
processing time. Our model training is halted when
the collecte d set of random negative background ima-
ges is completely consumed.
For the seco nd model, referred to as ‘Iterati-
veHardPositives’, we add 250 hard positive training
samples collected through the active learning proc e -
dure, tr ying to improve th e recall rate of the detector.
We also gather a limited set of hard negatives and add
those to the training set. We noticed that adding these
extra quality samples pushes the recall rate while slig-
htly incre asing the precision rate. The third and fi-
nal model, refer red to as ‘IterativeHardPositives+’, is
again improved by providing 250 extra h a rd positive
samples, in an attempt to push the reported recall even
further.
5 RESULTS
5.1 Performance of Trained Models
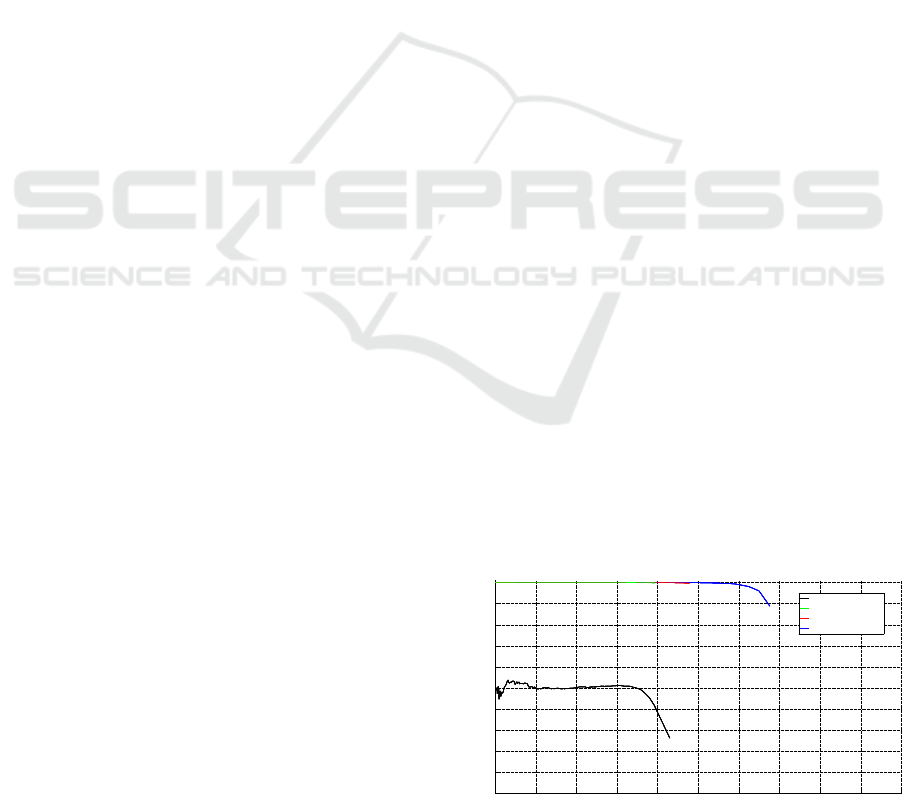
Figure 5 compares the trained models (BoostedBase-
line, IterativeHardPositives and IterativeHardPositi-
ves+) from section 4.5 to the OpenCVBaseline detec-
tor on the FDDB test da taset. Perform ance is measu-
red using p recision-recall p lots. We notice a generally
large improvement of our self trained mod e ls (green,
red and blue c urve) over the OpenCV baseline (black
curve). The OpenCV baseline model is only able to
achieve a recall of about 40% (me a ning 4 out of 10
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Recall = TP / (TP + FN)
Precision = TP / (TP + FP)
OpenCVBaseline
BoostedBaseline
IterativeHardPositives
IterativeHardPositives+
Figure 5: Precision-Recall for all models on FDDB dataset.
VISAPP 2017 - International Conference on Computer Vision Theory and Applications
400
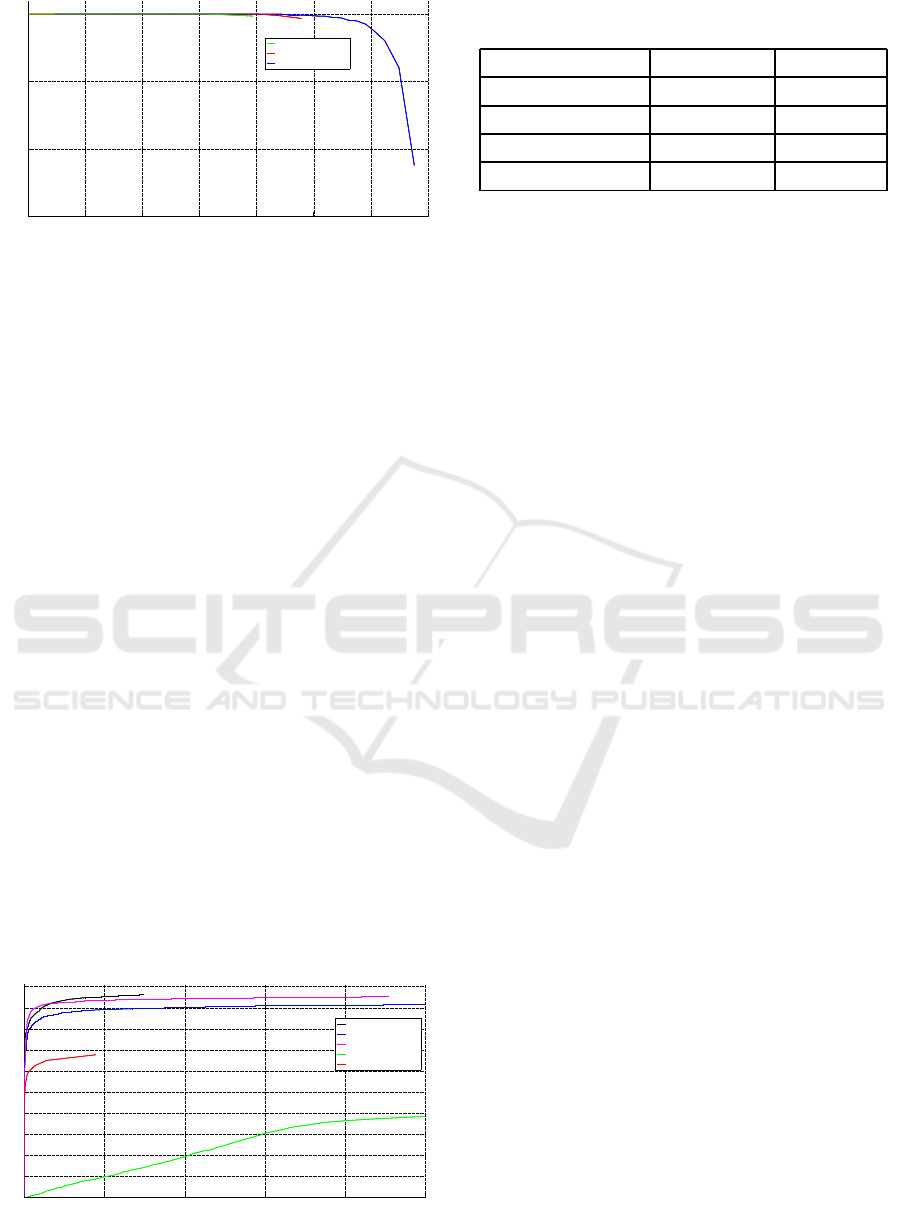
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7
0.85
0.9
0.95
1
Recall = TP / (TP + FN)
Precision = TP / (TP + FP)
BoostedBaseline
IterativeHardPositives
IterativeHardPositives+
Figure 6: Close-up of PR curves of our detection models.
objects a re dete cted) at a precision o f 40% (of all the
detections re turned, only 4 out of 10 ar e actual ob-
jects) for its optimal point. Of course one can make
a trade-off a nd decide to sacrifice recall for a higher
precision. Nonetheless the current Op e nCV model is
not able to detect objects with a certainty higher than
50% on the given FDDB dataset, containing a wild
variety of faces in very challenging conditions.
Compared to the OpenCVBaseline de te ctor, at the
optimal recall of 40% for tha t model, our BoostedBa-
seline detector a lready incre a ses the precision towards
99.5%, almost completely removing the existence of
false positive detections. Furthe rmore, each of our
subsequen t models, as seen in the close-up in Fig ure
6, increases the recall further without sacrificing the
very high pr ecision rate. At a r ecall value of 60%, a
50% increase compared to the OpenCVBaseline de-
tector, our IterativeHardPositives+ detector only has
a slight drop to 99% precision. As an optimal wor-
king point our IterativeHardPositives+ model reaches
a precision of 90% at a recall of 68%.
While many papers on face de te c tion use precision
recall curves to compar e detection models efficiently,
the official FDDB evaluation criteria is based on the
true positive rate com pared to the numbe r of false po-
sitive de te c tions. We include this comparison for both
the OpenCVBaseline detector and our IterativeHard-
Positives+ detector, as seen in Figure 7. We also
0 500 1000 1500 2000 2500
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
False Positives = #FP
True Positive Rate = TP / (TP + FN)
FastRCNN
ConvNet3D
MultiTaskCNN
OpenCVBaseline
IterativeHardPositives+
Figure 7: Evaluation for FDDB dataset, comparing our al-
gorithm to neural network based approaches.
Table 2: Timing results comparing both OpenCV baseline
and self trained models f or the FDDB dataset.
Model Whole Set Per Image
OpenCVBaseline 9 min 30 sec 0.20 sec
BoostedBaseline 6 min 8 sec 0.13 sec
IterativeHardPos 7 m in 7 sec 0.15 sec
IterativeHardPos+ 9 min 6 sec 0.19 sec
compare our technique to some state-of-the-art face
detection algorithms based on neural networks like
FastRCNN (Jiang and Learne d-Miller, 2016), Con-
vNet3D (Li et al., 2016) and MultiTaskCNN (Zhang
et al., 2016). This clearly shows that we already close
the g ap between cascade c la ssifiers and neura l net-
works a lot, while still having room for improvement.
5.2 Influence of Adaptations to
Processing Time
One must make sure that adding a ll this extra trai-
ning data does not ma ke the mode l overly complex
and slow during detection time. As shown in Table
1 we have only a limited increase in used fea tures
as stump classifiers, while adding 50% more valua-
ble positive training data. Furthermore the complex-
ity in number of stages dr ops with our models. Since
processing time is a key feature f or many computer
vision approaches applied in embedded systems, we
took the liberty of measuring processing time over the
complete FDDB test set, which can be seen in Ta-
ble 2. We average the timings to receive a timing per
image, given the average resolution of the test images
is 400 × 300 pixels. These timings are performed on
a Intel(R) Xeon(R) CPU E5-2630 v 2 system set-up.
Our OpenCV build is optimized using the Threading
Building Blocks for parallel processing. We clearly
see, although we are using more features in our mo-
del, that the pr ocessing time of our IterativeHardPo-
sitives+ model does not exceed the processing time of
the OpenCVBaseline model. Furthermore, if we use
our BoostedBaseline or IterativeHardPositives detec-
tor, we process images remarkably faster than the
OpenCVBaseline detector.
5.3 A Visual Confirmation
Figure 8 shows some visual detection output of our
algorithm . We start by selecting a low detection cer-
tainty threshold (Figure 8(a)) which clearly shows
that both models are a ble to find faces, but immedia-
tely shows the downside of th e OpenCV model, which
generates a lot of false positive detections. We incre-
Improving Open Source Face Detection by Combining an Adapted Cascade Classification Pipeline and Active Learning
401

(a) Detection results with low detection certainty threshold.
(b) Detection results with medium detection certainty threshold.
(c) Detection results with high detection certainty threshold.
(d) Cases where both detectors fail (high certainty threshold) or where OpenCV finds a detection while we do not.
Figure 8: Detection results and failures on FDDB dataset for (red) OpenCVBaseline and (green) IterHardPos+ model.
ase th e detectio n certainty threshold to a mediate level
(Figure 8(b)) and notice that both OpenCV and our
own tr ained model are able to find faces, but gradu -
ally OpenCV starts to miss faces that ar e still detected
by our model. Finally when setting a high detection
certainty threshold (Figure 8(c)), we see that OpenCV
misses a lot of faces that are still found by our model.
But even in the case that our model detects more fa-
ces than OpenCV we still find cases where both mo-
dels fail or where OpenCV actually finds a face that
our models does not capture, as seen in Figure 8(d).
These undetected faces could be used a s hard positive
training samples but then we would need to search for
a new database for evalu a tion purposes in order not to
introdu ce dataset bias.
5.4 Testing Out-of-plane Rotation
Robustness
As alre ady stated in section 4.1 r educing the annota-
tion region, which directly influence s the face region
that the detector will r e turn, helps improving the out-
of-plane rotation of the face detecto r. To test this, we
evaluated the OpenCVBaseline a nd the IterativeHard-
VISAPP 2017 - International Conference on Computer Vision Theory and Applications
402
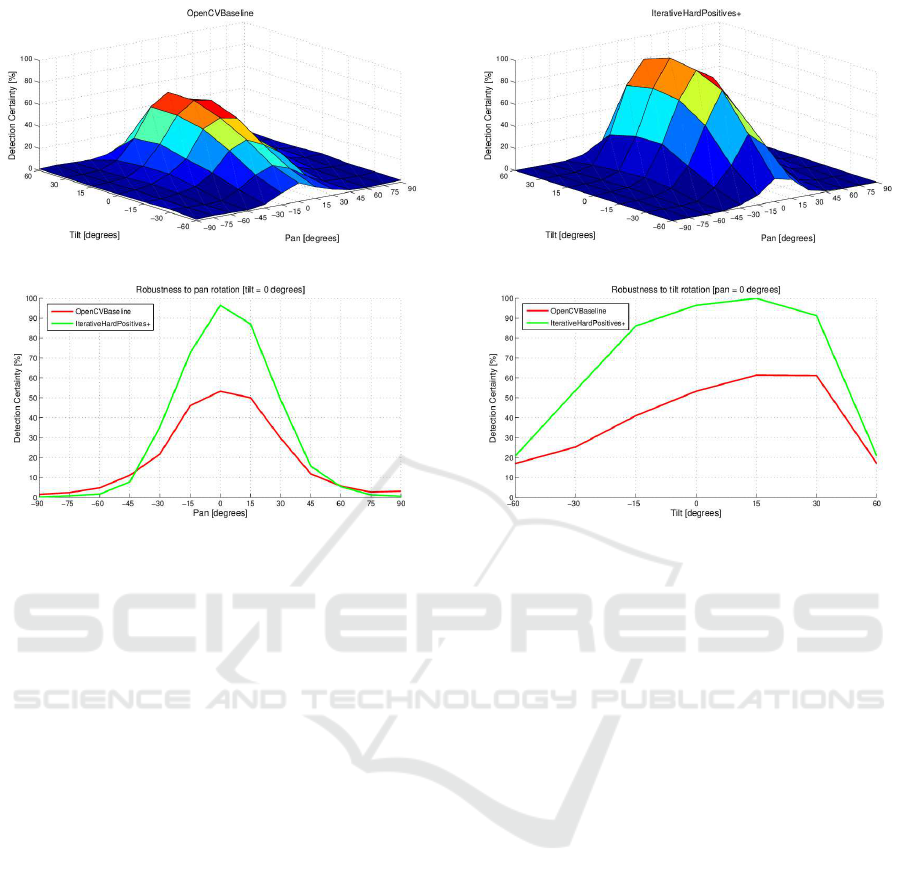
Figure 9: Testing out-of-plane rotational robustness for both OpenCVBaseline and the IterativeHardPositives+ detector.
Positives+ detector on the Head Pose Image Database
(Gourier et al., 2004), as seen in Figure 9. This data-
set contains a set of 30 sequences (15 persons, 2 se-
quences per person) where people sequentially look
at different positions, each associated w ith a pan (in
the range [-90
◦
,+90
◦
]) and a tilt angle (in the range
[-60
◦
,60
◦
]). At each position, we execute both de-
tectors and return the detection ce rtainty of the mo -
dels. averaged over the 30 sequences. We use the
highest returned detec tion sco re on the dataset as the
outer bound of our score range and normalize all ot-
her values for this maximum. We see that in b oth pan
and tilt angle evaluations o ur IterativeHardPositives+
detector clearly outperfor ms the OpenCVBaseline de-
tector. Esp e cially in the tilt angle range, we see a large
increase in efficiency. This extra test also confirms
that at a full frontal face, the IterativeHardPositives+
detector has about double the detection certainty as
the OpenCVBaseline detector, which was alread y cle-
arly noticeable in Figure 5.
6 CONCLUSIONS
The goal of this p a per is to suggest adaptations to
the current existing cascade classification pipelin e in
the open sour ce computer vision fra mework OpenCV
with the eye on improving its frontal face detection
model. We aim at reducing the huge amount of false
positive detections, by guaranteeing a high pr e cision,
while maintaining the re call as high as possible, to
detect as many faces as possible. We test our appro-
ach o n the pu blicly available FDDB face dataset and
prove th at our adaptations to the pipeline generate an
enormous increase in performance. Using our Iterati-
veHardPositives+ detector, we achieve a n increase in
recall to 68% while maintaining a hig h precision of
90%. Compared to a 40% precision at 4 0% recall for
the current implementation, this is quite impressive.
The suggested adaptations to the framework and
the model clearly have benefits over the currently
available model. Imagine a case where the output
of the face detector is used to perform face recogni-
tion. In such cases we aim at a precision that is as
high as possible, since we want to ensure that the pi-
peline fo llowing on the actual detection, is not provi-
ded with rubbish but with an actual face. Furthermore
our model is able to find more faces in the wild and is
more robust to o ut-of-plane rotations compared to the
OpenCV baseline model.
We should take into account that we will never hit
a 100% recall on datasets like FDDB, due to some
high out-o f-plane rotations, as seen in Figure 8(d).
However one c ould argue that faces with an out-of-
plane rotation of more than 45 degrees should be
found by a profile face detector and combine both de-
tectors together, as suggested in (Hulens et al., 2016).
Improving Open Source Face Detection by Combining an Adapted Cascade Classification Pipeline and Active Learning
403

7 FUTURE WORK
As future work we suggest to push the accuracy of the
face detection model in the OpenCV framework even
further. We have still r oom to increase the amount
of hard positives samples, aiming fo r an even higher
recall rate. A good start could be to run our Iterati-
veHardPositives+ detector on the FDDB dataset and
use the returned har d positive faces as training data.
However this will force us to loo k at new evaluation
datasets besides FDDB to avoid dataset bias.
At the moment the model is only evaluated on a
single in-plane rotation. Like suggested in (Puttemans
et al., 20 16a) we could build a rotational 3D matrix of
the image and app ly our IterativeHardPositives+ de-
tector several times to incorporate these in-plan e ro-
tations. This would allow us to find more faces and
push the performance of our pipeline even further.
ACKNOWLEDGEMENTS
This work is supported by the KU Leuven, Campus
De Nayer and the Flanders Innovation & Entrepe-
neurship (AIO).
REFERENCES
Berg, T. L., Berg, A. C., Edwards, J., and Forsyth, D.
(2005). Whos in the picture. A dvances in neural in-
formation processing systems, 17:137–144.
Bradski, G. et al. (2000). The opencv library. Doctor Dobbs
Journal, 25(11):120–126.
Frejlichowski, D., Go´sciewska, K., Forczma´nski, P., Nowo-
sielski, A., and Hofman, R. (2016). Applying image
features and adaboost classification for vehicle de-
tection in the sm4public system. In Image Processing
and Communications Challenges 7, pages 81–88.
Freund, Y., S chapire, R., and Abe, N. (1999). A short in-
troduction to boosting. Japanese Society For Artificial
Intelligence, 14(771-780):1612.
Gourier, N., Hall, D., and Crowley, J. L. (2004). Est imating
face orientation from robust detection of salient facial
features. In ICPR International Workshop on Visual
Observation of Deictic Gestures.
Hulens, D., Van Beeck, K., and Goedem´e, T. (2016). Fast
and accurate face orientation measurement in low-
resolution images on embedded hardware. In Procee-
dings of VISIGR APP, volume 4, pages 538–544.
Jain, V. and Learned-Miller, E. (2010). Fddb: A benchmark
for face detection in unconstrained settings. Techni-
cal Report UM-CS-2010-009, University of Massa-
chusetts, Amherst.
Jiang, H. and Learned-Miller, E. (2016). Face de-
tection with the faster r-cnn. arXiv preprint
arXiv:1606.03473.
Learned-Miller, E., Huang, G. B., RoyChowdhury, A., Li,
H., and Hua, G. (2016). Labeled faces in the wil d:
A survey. In Advances in Face Detection and Facial
Image Analysis, pages 189–248.
Li, Y., Sun, B., Wu, T., Wang, Y., and Gao, W. (2016). Face
detection with end-to-end integration of a convnet and
a 3d model. arXiv preprint arXiv:1606.00850.
Liao, S., Zhu, X., et al. (2007). Learning multi-scale block
local binary patterns for face recognition. In Advances
in Biometrics, pages 828–837.
Mathias, M., Benenson, R., Pedersoli, M., and Van Gool,
L. (2014). Face detection without bells and whistles.
In European Conference on Computer Vision, pages
720–735.
Puttemans, S., Van Ranst, W., and Goedem´e, T. (2016a).
Detection of photovoltaic installations in rgb aerial
imaging: a comparative study. In GEOBIA2016.
Puttemans, S., Vanbrabant, Y., Tit s, L., and Goedem´e, T.
(2016b). Automated visual fruit detection f or harvest
estimation and robotic harvesting. In IPTA2016.
Reyzin, L. and Schapire, R. E. (2006). How boosting the
margin can also boost classifier complexity. In Pro-
ceedings of the 23rd i nternational conference on Ma-
chine l earning, pages 753–760.
Shaikh, F., Sharma, A., Gupta, P., and Khan, D. (2016).
A driver drow siness detection system using cascaded
adaboost. Imperial Journal of Interdisciplinary Rese-
arch, 2(5).
Viola, P. and Jones, M. (2001). Rapid object detection using
a boosted cascade of simple features. In CVPR, vo-
lume 1, pages I–511.
Wolf, L., Hassner, T., and Maoz, I. (2011). Face recognition
in unconstrained videos with matched background si-
milarity. In CVPR, pages 529–534.
Zhang, K., Zhang, Z., Li, Z., and Qiao, Y. (2016).
Joint face detection and alignment using multi-task
cascaded convolutional networks. arXiv preprint
arXiv:1604.02878.
Zheng, Y., Yang, C., Merkulov, A., and Bandari, M. (2016).
Early breast cancer detection with digital mammo-
grams using haar-like features and adaboost algo-
rithm. In SPIE Commercial+ Scientific Sensing and
Imaging, pages 98710D–98710D. International So-
ciety for Optics and Photonics.
VISAPP 2017 - International Conference on Computer Vision Theory and Applications
404
