
Explicit Control of Dataflow Graphs with MARTE/CCSL
Jean-Vivien Millo, Amine Oueslati, Emilien Kaufman, Julien DeAntoni,
Frederic Mallet and Robert de Simone
Universit
´
e Nice Cote d’Azur, CNRS, Inria, I3S, Sophia Antipolis, France
Keywords:
Dataflow, Platform based Design, Scheduling.
Abstract:
Process Networks are a means to describe streaming embedded applications. They rely on explicit representa-
tion of task concurrency, pipeline and data-flow. Originally, Data-Flow Process Network (DFPN) representa-
tions are independent from any execution platform support model. Such independence is actually what allows
looking next for adequate mappings. Mapping deals with scheduling and distribution of computation tasks
onto processing resources, but also distribution of communications to interconnects and memory resources.
This design approach requires a level of description of execution platforms that is both accurate and simple.
Recent platforms are composed of repeated elements with global interconnection (GPU, MPPA). A parametric
description could help achieving both requirements.
Then, we argue that a model-driven engineering approach may allow to unfold and expand an original DFPN
model, in our case a so-called Synchronous DataFlow graph (SDF) into a model such that: a) the original
description is a quotient refolding of the expanded one, and b) the mapping to a platform model is a grouping
of tasks according to their resource allocation.
Then, given such unfolding, we consider how to express the allocation and the real-time constraints. We do
this by capturing the entire system in CCSL (Clock Constraint Specification Language). CCSL allows to
capture linear but also synchronous constraints.
1 INTRODUCTION
Synchronous Data Flow (SDF) (Lee and Messer-
schmitt, 1987b) graphs are a popular model of choice
to support Platform-Based Design approaches (also
called Y-Chart flow). There are obvious reasons for
that: SDF makes explicit the (in)dependences of data-
flow and the potential concurrency, it abstracts data
values while preserving sizes for bandwidth consid-
erations; it is architecture-agnostic. Like most Pro-
cess Network models it enjoys conflict-freeness prop-
erties, ensuring functional determinism. Then the one
single issue remaining for efficient model-level ab-
stract compilation is to find a best-fit mapping onto
a provided architecture model. Mapping here refers
both to spatial allocation of both computations and
communications onto processing, memory and inter-
connect resources, and the temporal scheduling in
case some resources need to be shared.
While the original SDF model is rightfully in-
dependent from the architecture and inherent map-
ping constraints, these have to be included and de-
cided upon, possibly incrementally, as design goes
down the flow. In a sense the application model has
to be taken step-by-step from architecture-agnostic
to architecture-aware. There, SDF shows of course
limitations, as additional information of different na-
ture must enter the modeling framework. This can
be achieved in essentially two ways: either the SDF
model itself is refined and complexified (usually out
of SDF syntax stricto sensu), so that the architectural
structure and the temporal organization transpire be-
low it; or, in a modular fashion, additional constructs
are added on the side, with precise links to the existing
models. The former approach is appropriate when the
extension of the expressiveness is limited. Otherwise,
the latter way has to be preferred.
Going down the latter way, we suggest that an
SDF graph can be augmented with 1/an Occurrence
Flow Graph (OFG) where every occurrence of SDF
agents are explicit
1
. OFG shows the agent concur-
rency in addition to the pipeline; 2/ a parametric ar-
chitecture model in order to elegantly capture mod-
ern architectures composed of repeated tiles such as
in MPPA or GPU. Such a model comes with the asso-
ciated parametric allocation model.
1
Similarly to the transformation of SDF in HSDF
542
Millo J., Oueslati A., Kaufman E., Mallet F. and de Simone R.
Explicit Control of Dataflow Graphs with MARTE/CCSL.
DOI: 10.5220/0006269505420549
In Proceedings of the 5th International Conference on Model-Driven Engineering and Software Development (MODELSWARD 2017), pages 542-549
ISBN: 978-989-758-210-3
Copyright
c
2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

If we move apart the problem of finding the best
binding of computation and communication of the ar-
chitecture, the next problem is to find the best sched-
ule of the application that satisfies the execution con-
straints imposed by application functionality, the exe-
cution platforms and the real time requirements. The
scheduling algorithms are often tailored for a given
optimization criteria (e.g., max throughput, single ap-
pearance) whereas every case study would have its
own objective. It must be possible to reuse the same
design flow (Stuijk et al., 2006; Bamakhrama and Ste-
fanov, 2011; Karczmarek et al., 2003) on different
case studies with each time an original optimization
criteria.
There is a lack for a dedicated model of the control
which is able to represent all the acceptable sched-
ules of the application according to constraints of dif-
ferent nature ranging from performance requirements
to platform allocation (or any other hardware related
concerns).
In the current paper we show how a wide range
of constraints inherited from the architecture could be
formally expressed in a language that describes map-
ping conditions (and scheduling constraints) that will
further restrict the potential schedules of the origi-
nal SDF description. For this we use the Clock Con-
straint Specification Language (CCSL) (Andr
´
e, 2009)
formalism. CCSL is specifically devoted to the tempo-
ral annotation of relevant scheduling patterns on top
of classical behavioral models. It allows to deal with
such scheduling constraints as formal parts of the de-
sign, to conduct formal proofs of schedule validity as
well as high-level simulation. Even automatic synthe-
sis of optimal schedules can be achieved in some case,
using techniques borrowed from model-checking au-
tomatic verification.
By exploiting the explicit control in CCSL, it is
still possible to find a scheduling that optimizes a
original criteria, this time after an explicit consider-
ation of assumptions. It is also possible to drive anal-
ysis, directly on the CCSL structure or by using a pro-
jection to an existing analysis model as in (Mallet and
de Simone, 2015; Yu et al., 2011).
The paper is organized as follows: Section 2
browses the state of the art of design flows for many
core architectures based on DFPN. Section 3 intro-
duces Occurrence Flow Graph and a parametric archi-
tecture model. Section 4 shows how allocations con-
straints of different natures can be captured in CCSL.
Section 5 concludes this article.
2 RELATED WORK
Abstract representation of streaming applications
as dataflow graph models goes a long way back
in time, to Kahn process networks (Kahn, 1974),
Commoner/Holt’s marked graphs (Commoner et al.,
1971), or even Karp et al. systems of uniform recur-
rence equations (Karp et al., 1967).
There was a renewal of interest in the 1980’s
for the class of so-called Dataflow Process Networks
(DFPNs), starting with SDF(Lee and Messerschmitt,
1987a) and successive variants (boolean(Buck, 1993),
cycloStatic(Bilsen et al., 1995).
More recently, the emergence of many-core archi-
tectures has polarized DFPNs as natural concurrent
models to design embedded applications for (hetero-
geneous) parallel architectures. The Holy Grail is a
methodology considering a description of the appli-
cation and a description of the target architecture that
computes automatically the best allocation according
to some optimization criteria. Here allocation has to
be taken into its widest sense: (i) binding computa-
tions on processing elements, FIFO on memory, and
data flows on communication topology, (ii) schedul-
ing computations and memory accesses, (iii) routing
communications in space and time. Such a methodol-
ogy has been approached through different angles.
SDF3 (Stuijk et al., 2006) provides SDFG-based
MP-SoC design flow (Stuijk, 2007) based on succes-
sive refinements and iterations of the original SDF
model. It implements self time scheduling and two
scheduling policies: list scheduling and single appear-
ance scheduling (minimizes code size).
Streamit experiments different scheduling policies
(Karczmarek et al., 2003) of a dataflow graph. Pro-
vided a balanced input dataflow graph and a schedul-
ing policy, a static schedule that achieves one period
of the graph is generated. These policies are not con-
strained but they result in different buffer sizes, code
sizes and latencies.
Syndex (Grandpierre et al., 1999) also provides a
complete environment using allocation and schedul-
ing heuristics.
In some cases, the optimisation criteria is known
but the scheduling algorithm is not described. For in-
stance the sigmaC toolchainallows static scheduling
and routing decisions on a network on chip architec-
ture.
These methodologies are often couple with a spe-
cific platform as in streamIt with Raw/ Tilera (Kar-
czmarek et al., 2003), SDF3 with COMPSoC/ Aelite
(Goossens and Hansson, 2010), sigmaC with Kalray/
MPPA
2
, and PEDF with SThorM (Melpignano et al.,
2
http://www.kalray.eu/products/mppa-manycore
Explicit Control of Dataflow Graphs with MARTE/CCSL
543

2012).
The TIMES tool (Amnell et al., 2004) allows
modeling a dataflow process network and adding con-
straints caused by shared resources and deadlines for
each task. The scheduling policy is provided to check
if the constraints are satisfied. On the contrary, we
provide a structure that allows deriving a schedule
which satisfies the constraints, either a static sched-
ule or a schedule or a policy that would cause a valid
schedule.
These design flows have the only restriction to
focus on predefined optimization criteria conducting
the allocation decisions. We think that the binding
between the design methodology and the optimiza-
tion criteria is artificial and unwelcome. This article
proposes a framework to capture the application, the
architecture and the allocation constraints to enable
the user to explore all the possible schedules match-
ing the constraints. Thus, any optimization criteria
can be applied to select the best scheduling accord-
ing to the specific needs of the designer (time, mem-
ory, consumption, end to end latency). We offer our
framework to enrich existing design flows with the
freedom to select original optimization criteria. In
our approach, we consider the binding of communi-
cations and computations onto architectural elements
to be given. Routing is not (yet) considered.
3 SDF, OCCURRENCE FLOW
GRAPH AND ALLOCATION
This section has three parts: First, we provide a de-
scription of the SDF model. Note that the place are
explicitly represented. Second, we show how the
agent concurrency can be explicitly extracted from a
SDF graph by representing every instance of an SDF
agent over a period of execution, this is the Occur-
rence Flow Graph (OFG). Last, we present a simple
parametric model of an architecture and the associ-
ated parametric allocation model.
3.1 SDF
The Synchronous Data Flow model (Lee and Messer-
schmitt, 1987b) (SDF) is a bipartite graph where
edges can be divided in two disjoint sets named
Agents and Places. An agent is a functional block
that consumes and produces a static amount of data
(or tokens) in places. The arcs are weighted and relate
agents with places and vice-versa but two edges from
the same set are never linked together. The marking
associates tokens with each place, the initial marking
is the initial number of tokens in all places.
The constraint on the number of inputs and out-
puts of every place guarantees that a token can be used
by only one agent; the fact that an agent uses tokens to
fire (or run) never disables another agent. Thus SDF is
said to be conflict-free in the sense of Petri net (Petri,
1962) or monotonic in the sense of Kahn Process Net-
work (Kahn, 1974) or confluent in the sense of CCS
(Milner, 1982).
The operator
•
can be applied to any edge e (agent
or place) to designate either the preset (
•
e) or the post-
set (e
•
). Note that the preset and the postset of a place
are composed of a single agent.
An agent is said fireable when every place in its
preset has a marking greater than the input weight of
the agent.
When an agent is fired, it consumes tokens in ev-
ery input place and produces tokens in every output
places.
In the scope of this article, an SDF graph models
an application where the agents represent the different
filters (or actors) that compose the application. The
agents can be triggered concurrently. The places rep-
resent locations in memory
3
. The arcs give the flows
of data, i.e., data dependencies among agents. The
presence of a token in a place represents the availabil-
ity of a data element in memory. An agent without
incoming (resp. outgoing) arc represents a global in-
put (resp. output) of the application.
For instance, Figure 1 gives the SDF representa-
tion of a parallel sorting algorithm where n <= k. A
set of 2
n
elements are sorted by 2
n−k
sorters.
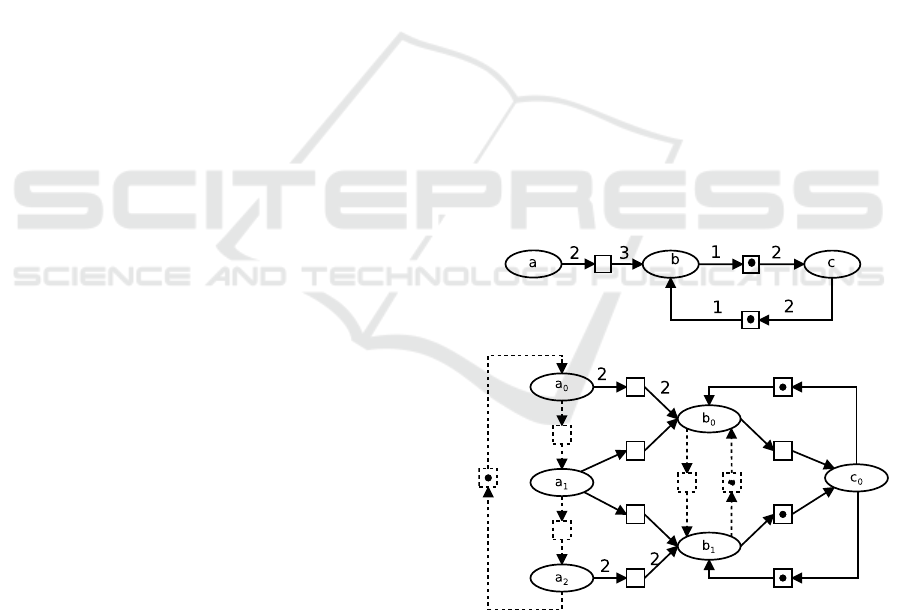
Figure 1: An SDF graph of a parallel sorting algorithm.
Flow Preservation, Repetition Vector and Period.
The flow preservation condition is a necessary con-
dition for the existence of an infinite bounded execu-
tion. On the contrary, when it is not, the SDF graph
is called pathological or inconsistent. Consequently,
any infinite execution is either unbounded or leading
to starvation (deadlock).
As explained in E. Lee and D. Messerschmitt’s
original work on SDF (Lee and Messerschmitt,
1987b), any SDF graph G can be represented as a
matrix Γ(G), called the topology matrix, assigning a
column to each agent and a row to each place. An en-
3
the notion of memory used here is generic. It could
be any kind of memory: e.g., central memory (RAM),
CPU/GPU register, scratch-pad, communication buffer
MODELSWARD 2017 - 5th International Conference on Model-Driven Engineering and Software Development
544
try in the topology matrix gives the width of the arc
relating the agent to the place (or vice versa).
An SDF graph is flow preserving (or balanced) if
and only if the rank of the topology matrix is equals
to |N| − 1. Thus pathological cases occur when the
rank of the topology matrix is |N|.
When G is flow preserving, the equation Γ(G) ∗
X = 0 has a solution and X is the repetition vector
of G of size |N|. X provides the number of firing
(activations) of every agent so that the flows are bal-
anced. When G is flow preserving, the repetition vec-
tor of the sorting algorithm is [sample = 1, sorter =
2
n−k
, f usion = 1, store = 1].
A sequence of execution of an SDF graph such
that every agent a is fired (or run) X(a) times is called
a period. The pipelined execution of an SDF graph is
the interleaving of periods.
3.2 Occurrence Flow Graph (OFG)
The OFG of a flow preserving SDF graph G is the ex-
plicit representation of agent concurrency. An OFG is
based on the decomposition of SDF agents into sev-
eral occurrences over a period of execution similarly
to the decomposition of SDF into HSDF (or Marked
Graph (Commoner et al., 1971)) (de Groote et al.,
2013). In Figure 1, all the (2
n−k
) occurrences of the
agent sorter can be run concurrently. The OFG of this
SDF graph makes explicit this freedom.
In an OFG, every agent a is decomposed into X(a)
instances representing the different occurrences dur-
ing a period of execution. The i
th
instance (denoted
a
i
) represents the class of all the (k ∗ X(a) + i)
th
oc-
currences of the agent.
The instances of the OFG are related with control
flows indicating causes or precedences between firing
of the instances. There are two kinds of flows in the
OFG according to the two following rules.
First rule: the X(a) instances of every agent a
are ordered so that the i + 1
th
instance of a cannot
be fired before the i
th
instance. Formally, a
i
causes
a
i+1modX(a)
(One cannot restart if it has not started
before). Note that a cause allows the simultaneous
execution of successive instances.
Second rule: the flows are derived from the places
in the SDF graph. If the i
th
firing of an agent a pro-
duces n tokens that are consumed by the j
th
firing of
an agent a
0
then a
i
precedes a
0
j
in the OFG. Note that a
precedence does not allow the simultaneous execution
of successive instances (on the same token however
a pipeline execution is still possible). The input and
output weights of the flows are n. When the tokens
produced by an instance of an agent are used by many
instances of the successor, the partition is made on the
flows. Similar partitioning is made for the instances
of an agent consuming tokens from many instances of
its predecessor.
The initial marking of the OFG is computed as fol-
lows: if the produced tokens are present initially, the
corresponding control flow has these tokens. More-
over, the control flow relating a
X(a)−1
and a
0
contains
a token whereas every other control flow a
i
to a
i+1
has
no token.
The OFG is by nature an SDF graph where in-
stances are the agents and control flows are sequences
of arc→place→arc between pairs of agents. How-
ever, the distinction between cause (first rule) and
precedence (second rule) cannot be captured in SDF
whereas this distinction is natural in CCSL.
Figure 2 shows a flow preserving SDF graph and
its corresponding OFG (omitted weights are 1). Dot-
ted lines represent Causes whereas plain lines are for
Precedences. The repetition vector is X = [a = 3, b =
2, c =1]. Agent a must be fired twice before b is and
one token remains. The third firing of a enough to-
kens for b to be fired a second time.
There is initially one token in the place between
b and c meaning that the last instance of b (b
2
) has
provided a token for the execution of the first instance
of c (c
1
). Similarly, the last instance of c (still c
1
) has
provided a token for the execution of the first instance
of b (b
1
).
a)
b)
Figure 2: An SDF graph and its corresponding OFG.
Converting SDF Graphs into OFG. As a first ap-
proximation, we convert an SDF graph into an Homo-
geneous SDF (multi)-graph as described in (Sriram
and Bhattacharyya, 2012) (p.45). Note that the major
drawback of HSDF is the explosion of the number of
arcs. Our actual implementation avoids that problem
Explicit Control of Dataflow Graphs with MARTE/CCSL
545
but due to space limitation, we leave the algorithm out
of this paper.
3.3 Parametric Architecture Model
To model correctly the upcoming parallel and embed-
ded architectures, we need to take advantage of their
regular nature. For example, an MPPA-256 (Kalray,
2014) is the two dimensional repetition on a simpler
tile composed of sixteen processors. The architecture
is complemented with a NoC interconnecting the six-
teen tiles. It is thus convenient to use a parametric ar-
chitecture model where a tile is uniquely defined and
explicitly declared to be repeated.
Let us consider a simple model of components
with ports. To capture different types of constraints,
we distinguish three types of components: computa-
tion resources, memories, and interconnects.
Each component is indexed by its number of rep-
etitions belonging to a finite domain. When two re-
peated components are connected together, a func-
tion maps the indices of the first domain to the in-
dices of the second. The simplest function is f (i) = i
that maps the i components together when the two do-
mains are identical. This function can be used either
to expand this model or to perform analysis without
expansion.
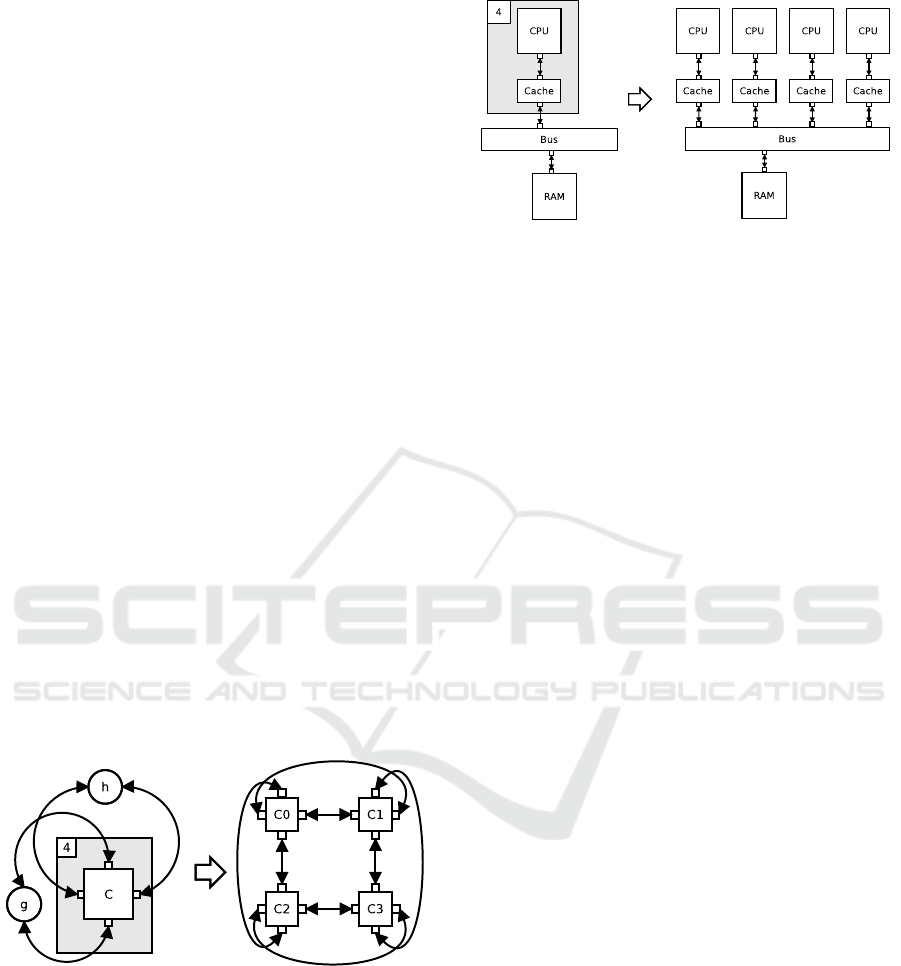
Figure 4 shows how to build a mesh using the two
following functions:
h(i)
(
i + 1 if i%2 = 0 g(i) = i + 2 mod 4
i − 1 otherwise
Figure 3: A torus expressed in a parametric way.
Let us consider a generic multi-core with one level
of cache and a simple repeated pattern 4. The cache
memory can be read/written as a regular memory (this
is a ”scratchpad memory”). It is admitted that this ar-
chitecture does not scale much because of the shared
interconnect and memory. Our approach allows to ex-
plore the possible schedules and for instance to de-
termine at which point some given real time require-
ments cannot be met (whatever the scheduling pol-
icy).
Figure 4: A generic multi-core architecture.
Parametric Allocation Model. Allocating directly
the agents on processing elements would mean that
every instance of this agent runs on the same pro-
cessing element. This limits the potential parallelism.
However, the OFG shows instances of the same agent
that can run concurrently (w.r.t. data flow constraints).
Thus we map instances to repeated processing ele-
ments.
Definition 1. Let Pe be the set of P processing ele-
ments indexed from 0 to P-1. For each agent, the map-
ping function allocates every instance of an Agent to
processing elements. The agent mapping M is the set
of the mapping functions for each agent.
M = M
a
(i), M
b
(i), ... where a, b are agents
M
agent
: i ∈ [0..X(a) − 1] → p ∈ [0..P − 1]
Consider the SDF in Figure 2 mapped on a plat-
form with three processing elements, an acceptable
mapping is:
M
A
= (M
a
, M
b
, M
c
)
M
a
(i) = i mod 2 == 1; M
b
(i) = i; M
c
(i) = 2
The OFG also gives all the data exchanges (the
places in the OFG) between instances. Each physical
memory Mem
i
is bounded with its size mem
i
. The
place mapping function takes the list of places and
returns the allocated list of physical memories.
The user specifies an SDF graph which is unfolded
into its OFG, then specifies an architecture model
with repeated components, and finally allocates the
instances and places on the different components of
the architecture. The allocation is potentially the re-
sult of an automated method. The following section
explains how the whole system is captured into a set
of CCSL constraints and enriched with real time con-
straints. Later, the state space representing all the con-
forming schedules is explored.
MODELSWARD 2017 - 5th International Conference on Model-Driven Engineering and Software Development
546

4 ENCODING DATA AND
CONTROL FLOW
CONSTRAINTS IN CCSL
The Clock Constraint Specification Language
(CCSL) (Andr
´
e, 2009) is a declarative language to
build specifications of systems by accumulation
of constraints that progressively refine what can
be expected from the system under consideration.
The specification can be used and analyzed with
our tool TimeSquare (Deantoni and Mallet, 2012).
CCSL mainly targets embedded systems and was
then designed to capture constraints imposed by the
applicative part, the execution platform or also exter-
nal requirements from the users, like non-functional
properties. Constraints from the application and
the execution platform are bound together through
allocation constraints also expressed in CCSL. The
central concept in CCSL are the logical clocks, which
have been successfully used for their multiform
nature by synchronous languages to build circuits and
control-oriented systems, to design avionic systems
with data-flow descriptions or design polychronous
control systems (Benveniste et al., 2003)). They have
also been used outside the synchronous community
to capture partial orderings between components in
distributed systems (Lamport, 1974). We promote
their use here both for capturing the concurrency
inherent to the application, the parallelism offered
by the execution platform and synchronization
constraints induced by the allocation.
Logical clocks are used to represent noticeable
events of the system, e.g., starting/finishing the ex-
ecution of an agent, writing/reading a data from a
place/memory, acquiring/releasing a resource; Their
ticks are the successive (totally ordered) occurrences
of the events.
In CCSL, the expected behavior of the system is
described by a specification that constrains the way
the clocks can tick. Basically, a CCSL specification
prevents clocks from ticking when some conditions
hold.
A CCSL specification denotes a set of schedules.
If empty, there is no solution, the specification is in-
valid. If there are many possible schedules, it leaves
some freedom to make some choices depending on
additional criteria. For instance, some may want to
run everything as soon as possible (ASAP), others
may want to optimize the usage of resources (proces-
sors/memory/bandwidth).
Given a clock c, a step s ∈ N and a schedule σ,
c ∈ σ(s) means that clock c ticks at step s for this par-
ticular schedule.A schedule σ satisfies a specification
if it satisfies all of its constraints.
Note that there are usually an infinite number of
schedules that satisfy a specification, we only con-
sider the ones that do not have empty steps.
4.1 Library of CCSL Constraints
New CCSL constraints can be defined from kernel
ones (see (Andr
´
e, 2009)) in dedicated libraries. Be-
fore presenting newly-defined constraints, we intro-
duce here some of the kernel constraints needed.
Some constraints are stateless, i.e., the constraint im-
posed on a schedule is identical at all steps; others
are stateful, i.e., they depend on what has happened
in previous steps.
Two examples of simple stateless CCSL con-
straints are Union (u , a + b), where u ticks when
either of a or b tick, and Exclusion (a # b), which pre-
vents a and b from ticking simultaneously. Note that
Union is commutative and associative, we use in next
sections an n-ary extension of this binary definition.
For stateful constraints, we use the history of
clocks for a specific schedule, i.e., the number of
times each clock has ticked at a given step.
A simple example of a primitive stateful CCSL
clock constraint is Causality (a 4 b). When an event
causes another one, the effect cannot occur if the
cause has not, i.e., the cause must be at least as fre-
quent as its effect.
A small extension of Causality includes a notion of
temporality and is called Precedence a ≺ b, which
means that the effect cannot occur simultaneously
with its cause.
A bounded version of Precedence forces the effect
to occur within n steps after its cause (a ≺
n
b). An-
other example of a stateful constraint used in this pa-
per is the DelayFor constraint. Such constraint delay
a ‘base’ clock by counting the ticks of a ‘reference’
clock. A delayed clock res , base $ N on re f ticks
simultaneously with base but with a delay of N steps
of re f .
4.2 Encoding Occurrence Flow Graphs
in CCSL
In our proposal, the occurrence flow graph produced
in Section 3.2 is encoded in CCSL to represent the
acceptable schedules with respect to data dependen-
cies. It is further refined with additional CCSL con-
straints to take into account the allocation and the
characteristics of the resources. The resulting spec-
ification gives the opportunity to explore the possi-
ble schedules according to an explicit representation
of the constraints from the platform or performance
Explicit Control of Dataflow Graphs with MARTE/CCSL
547

requirements. Based on this representation it is still
possible to apply (ad-hoc and/or efficient) analysis or
synthesis tools as the ones already developed in the
literature.
Let us consider first the agent instances. Each
given agent Ais unfolded into X(a) instances
(a
i
)
i∈{1..X(a)}
(see Section 3). For each instance a
i
,
we associate two clocks, a
s
i
that denotes the start of
the execution of this instance and a
e
i
that denotes the
execution end. During the start of the instance, at
least one of the input ports is synchronously read.
The other ones are either synchronously read or se-
quentially read (to allow further concurrency limita-
tion imposed by the allocation on the hardware plat-
form). In the same spirit, at the end of the instance
execution at least the last output port is synchronously
written. The execution cannot end before it starts, it is
non re-entrant but it can be instantaneous. This is de-
noted in CCSL by ∀i ∈ {1..X(a)}, a
s
i
4
1
a
e
i
. Also,
different instances of a same agent denote succes-
sive occurrences and are thus causally dependent. In
CCSL, it becomes ∀i ∈ {1..X(a) − 1}, a
s
i
4 a
s
i+1
and
a
s
1
4
1
a
s
X(a)
.
The places of the occurrence flow graph can also
be captured in CCSL. This can be done with kernel
CCSL operators but here we use the Precedence con-
straint previously introduced. This encoding is not
safe (not bounded) but will be bounded by the capac-
ity of the memory after allocation. Let us consider the
place p such that it connects the instance a
i
and the in-
stance b
j
with an initial number of tokens M(p). Such
a place is encoded by the constraint a
e
i
M(p) ≺ b
s
j
.
4.3 Introducing Allocation Constraints
Allocating Instances on Processors. Let use con-
sider a processor P with a non-preemptive scheduler,
instances allocated on P can not be executed concur-
rently. We must consequently capture the acquisi-
tion and release of the resource. This is done with
two clocks P
acq
and P
rel
. We consider for P that
only one instance can be executed at a time, this is
captured in CCSL by P
rel
≺
1
P
acq
. Then the re-
source is acquired when one of the allocated instance
starts its execution and released any time an execut-
ing instance finishes its execution. This is captured in
CCSL with a union constraint: P
acq
, a
s
i
+ b
s
j
+ . . .
for all the instances allocated on this resource (here
only a
i
and b
j
). Similarly for releasing the resource,
P
rel
, a
e
i
+ b
e
j
+ . . . Additionally, one must for-
bid the simultaneous acquisition of a single resource
by two concurrent instances. This is done by adding
exclusion constraints, pairwise, on each start of al-
located instance and each end. In our example this
means (a
s
i
# b
s
j
) ∧ (a
e
i
# b
e
j
). Finally, the allocation
of an agent instance on a specific processor gives the
information about the execution time (let say a
ET
for
the instances of agent instances a) of the associated
code. This is also captured by a constraint represent-
ing that the end of an agent instance is equal to (i.e.,
synchronous with) the start of the agent delayed for
an execution time computed according to execution
cycle of the processor: a
e
i
= a
s
i
$ a
ET
on P
exec
. These
constraint allow restricting the concurrency of the ap-
plication according to the parallelism provided by the
platform with respect to a specific allocation.
Allocating Places on Memories. The allocation of
the places on a memory is encoded by using a con-
straint similar to the Precedence constraint. In our
case, we want a memory with m0 data at the start
of the system and a capacity cap ∈ N, in which we
can write several tokens nW in a single write and read
several tokens nR in a single read. As usual, read-
ings (resp. writing) are captured with a logical clock
r (resp. w). This definition has been written in CCSL
but the formal definition is not given here due to space
limitations.
This memory is such that, reading is never allowed
if there are not at least nR tokens available, consider-
ing the initial number of tokens (m0) and all those
that were written and read (δ(n)). Simultaneous read
and write are possible if the memory capacity is not
reached and considering that tokens are read before
new tokens are written (causally in the same logical
instant).
5 CONCLUSION
We provided a framework in which architectural con-
straints of various sorts can be translated into ex-
tra constraints, to be applied onto a SDF application
model that should be mapped to this architecture (so
that solving the constraints indeed guarantees the ex-
istence of a mapping). We also argued that SDF de-
scriptions should, to some extend, be expanded so that
mapping can be applied to occurrences of tasks, dif-
ferent instances being then mapped differently. The
range of further transformations applicable to original
process network models to ease (and extend the range
of admissible) mappings could further be studied.
Our approach could be compared and contrasted
to other schedulability techniques. Most consider
a very abstract description of architecture (identi-
cal multiprocessors for instance), and add real-time
MODELSWARD 2017 - 5th International Conference on Model-Driven Engineering and Software Development
548

scheduling requirements on the application side in-
stead (periodicity, deadlines. . . ). Then for each
fixed choice of a class of constraints a given ad-
hoc scheduling algorithm is established as optimal
(Rate Monotonic, Earliest Deadline First). Instead,
we choose to provide a constraint language power-
ful as CCSL to express a broad variety of constraints,
and to let a general method (reachability analysis
and model-checking basically) search for a candidate
”best” schedule. This does not avoid the usual NP-
completeness syndroma hidden behind many schedul-
ing approaches, but works relatively well in practice
due to symbolic representation techniques. Schedu-
lability analysis by exhaustive model-checking has
been attempted elsewhere (Amnell et al., 2004; Sun
et al., 2014), but with assumptions quite different
from ours in CCSL.
REFERENCES
Amnell, T., Fersman, E., Mokrushin, L., Pettersson, P., and
Yi, W. (2004). Times: A tool for schedulability anal-
ysis and code generation of real-time systems. In For-
mal Modeling and Analysis of Timed Systems, volume
2791 of Lecture Notes in Computer Science, pages
60–72. Springer Berlin Heidelberg.
Andr
´
e, C. (2009). Syntax and Semantics of the Clock Con-
straint Specification Language (CCSL). Research Re-
port RR-6925, INRIA.
Bamakhrama, M. and Stefanov, T. (2011). Hard-real-
time scheduling of data-dependent tasks in embedded
streaming applications. In ACM Int. Conf. on Embed-
ded software, pages 195–204. ACM.
Benveniste, A., Caspi, P., Edwards, S., Halbwachs, N.,
Le Guernic, P., and de Simone, R. (2003). The syn-
chronous languages 12 years later. Proceedings of the
IEEE, 91(1):64–83.
Bilsen, G., Engels, M., Lauwereins, R., and Peperstraete, J.
(1995). Cyclo-static data flow. In Int. Conf. on Acous-
tics, Speech, and Signal Processing, ICASSP’95, vol-
ume 5, pages 3255–3258.
Buck, J. T. (1993). Scheduling Dynamic Dataflow Graphs
with Bounded Memory Using the Token Flow Model.
PhD thesis, University of California, Berkeley, CA
94720.
Commoner, F., Holt, A. W., Even, S., and Pnueli, A. (1971).
Marked directed graph. Journal of Computer and Sys-
tem Sciences, 5:511–523.
de Groote, R., H
¨
olzenspies, P. K. F., Kuper, J., and
Broersma, H. (2013). Back to basics: Homogeneous
representations of multi-rate synchronous dataflow
graphs. In MEMOCODE, pages 35–46. IEEE.
Deantoni, J. and Mallet, F. (2012). TimeSquare: Treat your
Models with Logical Time. In Carlo A. Furia, S. N.,
editor, TOOLS, volume 7304 of LNCS, pages 34–41.
Springer.
Goossens, K. and Hansson, A. (2010). The aethereal
network on chip after ten years: Goals, evolution,
lessons, and future. In Design Automation Conference
(DAC’10), pages 306–311. ACM/IEEE.
Grandpierre, T., Lavarenne, C., and Sorel, Y. (1999). Opti-
mized rapid prototyping for real-time embedded het-
erogeneous multiprocessors. In Int. W. on Hard-
ware/Software Co-Design, CODES’99, Rome, Italy.
Kahn, G. (1974). The semantics of a simple language for
parallel programming. In Inform. Process. 74: Proc.
IFIP Congr. 74, pages 471–475.
Kalray (2014). Mppa manycore. http://www.kalray.eu/
products/mppa-manycore.
Karczmarek, M., Thies, W., and Amarasinghe, S. (2003).
Phased scheduling of stream programs. ACM SIG-
PLAN Notices, 38(7):103–112.
Karp, R. M., Miller, R. E., and Winograd, S. (1967). The
organization of computations for uniform recurrence
equations. J. ACM, 14(3):563–590.
Lamport, L. (1974). The parallel execution of do loops.
Commun. ACM, 17(2):83–93.
Lee, E. A. and Messerschmitt, D. G. (1987a). Static
scheduling of synchronous data flow programs for
digital signal processing. IEEE transactions on com-
puters, C-36(1):24–35.
Lee, E. A. and Messerschmitt, D. G. (1987b). Synchronous
data flow. Proceeding of the IEEE, 75(9):1235–1245.
Mallet, F. and de Simone, R. (2015). Correctness issues on
MARTE/CCSL constraints. Sci. Comput. Program.,
106:78–92.
Melpignano, D., Benini, L., Flamand, E., Jego, B., Lepley,
T., Haugou, G., Clermidy, F., and Dutoit, D. (2012).
Platform 2012, a many-core computing accelerator for
embedded socs: performance evaluation of visual an-
alytics applications. In DAC’12, pages 1137–1142.
Milner, R. (1982). A Calculus of Communicating Systems.
Springer-Verlag New York, Inc., Secaucus, NJ, USA.
Petri, C. A. (1962). Kommunikation mit Automaten. PhD
thesis, Bonn: Institut f
¨
ur Instrumentelle Mathematik,
Schriften des IIM Nr. 2. Technical Report RADC-TR-
65–377, Vol.1, 1966, English translation.
Sriram, S. and Bhattacharyya, S. S. (2012). Embedded mul-
tiprocessors: Scheduling and synchronization. CRC
press.
Stuijk, S. (2007). Predictable Mapping of Streaming Ap-
plications on Multiprocessors. PhD thesis, Faculty
of Electrical Engineering, Eindhoven University of
Technology, The Netherlands.
Stuijk, S., Geilen, M., and Basten, T. (2006). Sdf3: Sdf for
free. In ACSD, volume 6, pages 276–278.
Sun, Y., Soulat, R., Lipari, G., Andr, ., and Fribourg, L.
(2014). Parametric schedulability analysis of fixed
priority real-time distributed systems. In FTSCS, vol-
ume 419 of Communications in Computer and Infor-
mation Science, pages 212–228. Springer.
Yu, H., Talpin, J.-P., Besnard, L., Gautier, T., Marchand, H.,
and Guernic, P. L. (2011). Polychronous controller
synthesis from Marte CCSL timing specifications. In
MEMOCODE, pages 21–30. IEEE.
Explicit Control of Dataflow Graphs with MARTE/CCSL
549
