
Reconfigurable and Adaptive Spark Applications
Bilal Abi Farraj, Wael Al Rahal Al Orabi, Chadi Helwe, Mohamad Jaber,
Mohamad Omar Kayali and Mohamed Nassar
American University of Beirut, Computer Science Department, Beirut, Lebanon
Keywords:
Big Data, Spark, Hadoop, Quality of Service, Cloud.
Abstract:
The contribution of this paper is two-fold. First, we propose a Domain Specific Language (DSL) to easily
reconfigure and compose Spark applications. For each Spark application we define its input and output inter-
faces. Then, given a set of connections that map outputs of some Spark applications to free inputs of other
Spark applications, we automatically embed Spark applications with the required synchronization and commu-
nication to properly run them according to the user-defined mapping. Second, we present an adaptive quality
management/selection method for Spark applications. The method takes as input a pipeline of parameterized
Spark applications, where the execution time of each Spark application is an unknown increasing function of
quality level parameters. The method builds a controller that automatically computes adequate quality for each
Spark application to meet a user-defined deadline. Consequently, users can submit a pipeline of Spark appli-
cations and a deadline, our method automatically runs all the Spark applications with the maximum quality
while respecting the deadline specified by the user. We present experimental results showing the effectiveness
of our method.
1 INTRODUCTION
Since 2003, big data has become the new trend after
Google started working with its project Google File
System (GFS) (Ghemawat et al., 2003), and now big
data has become a necessity of most new technolo-
gies. Processing big data requires implicit distribution
of computation and new programming paradigm. To
this end, MapReduce programming model was pro-
posed in (Dean and Ghemawat, 2004; Dean and Ghe-
mawat, 2010) to efficiently process data on a cluster.
Some of the drawbacks of MapReduce are: (1) lack
of expressiveness: does not support iterative jobs and
only support two functions map and reduce; (2) not
interactive: only used for batch applications; (3) ef-
ficiency: in order to implement iterative applications,
intermediate results must be written and replicated on
the disk (i.e., through Hadoop Distributd File System
- HDFS). For instance, machine learning algorithms
cannot efficiently benefit from MapReduce since they
require iterative jobs to be executed. For this, Spark
was proposed in (Zaharia et al., 2010) to allow in-
teractive and iterative jobs. Spark uses resilient dis-
tributed datasets (RDD) which are a read-only collec-
tion of objects stored in the RAM. RDDs are big par-
allel collections that are distributed across the cluster.
RDDs are created through parallel transformations
(e.g., map, group by, filter, join, create from HDFS
block). Moreover, RDDs can be cached by allowing
to keep data sets of interest in Memory across oper-
ations and thus contribute to a substantial speedup.
Additionally, after creating RDDs, it is possible to do
analytics on them by running actions on them such as
count, reduce, collect and save. Note that all opera-
tions/transformations are lazy until you run an action.
Then, the Spark execution engine pipelines operations
and finds an execution plan. In this paper, we consider
Spark applications.
The contribution of this paper is two-fold.
• Reconfigurable Component-based Spark. We
define a high-level specification language to de-
velop Spark applications independently and au-
tomatically compose them. For each application,
we export its input and output interfaces, then we
define a configuration file to compose those inter-
faces. Then, applications are automatically aug-
mented with the proper code to wait data/notifi-
cation from other applications or notify/send data
to other applications. This allows to simplify the
development of complex system consisting of sev-
eral dependent Spark applications. Moreover, for
the same set of Spark applications, several sys-
tems may be built depending on the input config-
uration file. For instance, in the case of bioinfor-
84
Jaber, M., Nassar, M., Orabi, W., Farraj, B., Kayali, M. and Helwe, C.
Reconfigurable and Adaptive Spark Applications.
DOI: 10.5220/0006289901120119
In Proceedings of the 7th International Conference on Cloud Computing and Services Science (CLOSER 2017), pages 84-91
ISBN: 978-989-758-243-1
Copyright © 2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
matics applications several ordering of pipelines
on other applications may be defined (e.g., index-
ing, alignment, etc.).
• Adaptive Execution of Spark Applications.
Several companies provide services to deploy and
run Spark applications on the cloud (e.g., Ama-
zon Web Services, Microsoft Azure). The pricing
generally depends on the power of the allocated
nodes and the execution time needed to run the
applications. However, execution times may con-
siderably vary over time as they depend on the ap-
plication. Furthermore, non predictability of the
underlying platform and operating systems are ad-
ditional factors of uncertainty. For this, we pro-
pose a method to run a sequence of parameterized
(Quality of Service) Spark applications within a
specified time. Parameterized applications are
those that can be augmented with an extra param-
eter denoting the quality level. For example, ma-
chine learning and graph analytics are good ex-
amples of parameterized applications, since their
quality depend on the number of rounds (the more
rounds the better quality). Consequently, using
our method, cloud services can provide users with
the ability to specify a deadline/price and a se-
quence of Spark applications to be executed us-
ing the best quality levels possible. A controller
iteratively selects the best quality for each Spark
application depending on the remaining deadline
and time already used.
The remaining of this paper is structured as fol-
lows. Section 2 defines a language to easily com-
pose Spark applications. Section 3 defines a method
to adapt the quality levels to execute Spark applica-
tions while respecting a given deadline. Sections 4
discusses related work. Finally, Sections 5 and 6 draw
some conclusions and perspectives.
2 RECONFIGURATION OF
SPARK APPLICATIONS
Given a set of dependent Spark applications, we de-
fine a method to automatically compose them. Each
spark application takes a set of inputs (e.g., files) and
produces a set of outputs. An input can be either free
or direct. A free input should be mapped to an out-
put of a different spark application. A direct input is
mapped to a direct path.
Formally, a spark application is defined as fol-
lows:
Definition 1 (Spark Application). A spark applica-
tion SA is defined as a set of tuple (ins, outs), where:
SA
2
SA
1
SA
3
SA
4
SA
5
o
1
o
2
i
1
i
1
o
1
i
1
o
1
i
2
i
1
o
1
i
1
o
1
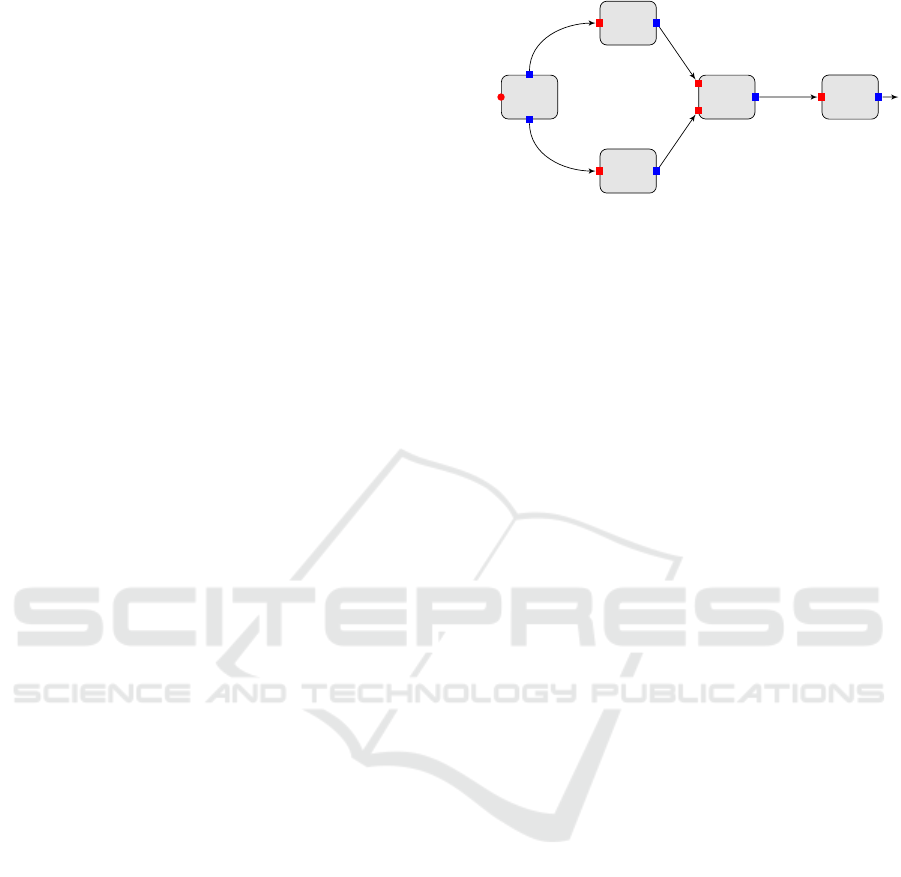
Figure 1: Representation of dependencies between sub-
jobs.
• ins = f reeIns ∪ directIns is the set of inputs;
• outs is the set of outputs.
Given a user-specified configuration, spark appli-
cations are composed by mapping free inputs of spark
applications to outputs of other applications. For-
mally a configuration is defined as follows:
Definition 2 (Configuration). Given a set of spark ap-
plication {SA
i
}
i∈I
, a configuration C is a function de-
fined by C : FreeInput → Out put, where:
• FreeInput =
S
i∈I
SA
i
. f reeIns;
• Out put =
S
i∈I
SA
i
.outs.
Example 1. Figure 1 shows an example of composing
spark applications. The system consists of five Spark
applications SA
1
, . . . , SA
5
. SA
1
has one direct input i
1
and two outputs o
1
and o
2
. SA
2
has one free input i
1
and one output o
1
. First output o
1
of SA
1
is mapped
to the free input i
1
of SA
2
.
Given a set of spark applications {SA
i
}
i∈I
, a con-
figuration C must be valid. A configuration is valid
iff:
• Free inputs are mapped to outputs of different ap-
plications. That is, if C(SA
i
. f i
1
) = SA
j
.o
1
, then
i 6= j, where f i
1
is a free input in SA
i
and o
1
is an
output in SA
j
.
• The graph directed G obtained from {SA
i
}
i∈I
and C does not contain cycles, where the set
of vertices of G represents Spark applications
and the set of edges represents the mapping be-
tween them. Formally, G = ({SA
i
}
i∈I
, E), where
E = {(SA
i
, SA
j
) | ∃ f reeIn ∈ SA
i
. f reeIns ∧ out ∈
SA
j
.outs : C( f reeIn) = out}.
Example 2. The system defined in Figure 1 is valid
since (1) all free inputs are mapped to outputs of dif-
ferent applications; and (2) the graph obtained by
connecting outputs to free inputs is acyclic.
2.1 Semantics and Code Generation
Given a set of Spark applications and a configuration
C, we first check the validity of configuration C, then
Reconfigurable and Adaptive Spark Applications
85

we automatically synthesize the glue of each Spark
application that corresponds to configuration C. A
glue surrounds each Spark application by the corre-
sponding synchronization and communication primi-
tives. The code generation is depicted in Listing 1. It
mainly consists of the following five steps:
Listing 1: Automatic Glue Generation of a Spark Applica-
tion.
Step 1: Fill Inputs
f o r ( i n pu t ∈ SAi . i ns ) {
i f ( i sF r e e I n p u t ( in p ut ) ) {
so u rc e = i np u t . f rom ;
in d ex = in p ut . i nd e x ;
in p ut s . a d d ( s ou r ce . ge tI n p u t ( inde x )) ;
} e l s e {
in p ut s . a d d ( i npu t . v al u e ) ;
}
}
Step 2: Wait Signals
f o r ( i n pu t ∈ SAi . fre e In s ) {
wa it Si gn al ( inp ut . from ) ;
}
Step 3: Fill Outputs
f o r ( o u tp ut ∈ SAi . o uts ) {
ou t p u ts . a d d ( o ut p ut );
}
Step 4: Run Spark Application
run ( " p a th " , inpu t s , ou tp ut s );
Step 5: Send Signals
f o r ( o u tp ut ∈ SAi . o uts ) {
free - i n pu t s = C
−1
( o u tp ut )
f o r ( free - in put ∈ free - in p ut s ) {
se nd Si gn al (free - i np u t . id ) ;
}
}
1. Fill input: inputs are mapped to their correspond-
ing paths. In case of a free input, an output of dif-
ferent Spark application is filled. In case of direct
input a direct path is filled.
2. Wait signals: Spark applications with free inputs
f reeIns wait for signals from other Spark appli-
cations with outputs mapped to f reeIns. This
phase may require a setup phase to set the con-
nections between processes (e.g., sockets, shared
semaphores, signals).
3. Fill outputs: outputs are mapped to their corre-
sponding paths.
4. Run: Run Spark application.
5. Send signals: Upon completion, Spark applica-
tions, with outputs mapped to free inputs f reeIns,
send signals to the Spark applications correspond-
ing to f reeIns.
2.2 DSL Implementation
We define a Domain Specific Language (DSL) using
JSON representation that defines Spark applications
and a configuration to connect them. Each Spark ap-
plication is identified by an identifier id, a path where
the Spark program exists path, number of inputs ni,
and number of outputs no. Then, the configuration
maps inputs to direct locations or to output of other
Spark applications (in case of free inputs). Listing 2
depicts the general structure to specify a set of Spark
applications and a configuration. It mainly consists of
two parts:
• The first part defines the set of Spark applications
with their corresponding interfaces (i.e., an iden-
tifier, location, number of inputs and number of
outputs).
• The second part defines the configuration which
connects Spark applications (i.e., connect output
to free inputs).
Listing 2: General shape of a configuration file.
{ " s park - app li ca ti on s " : [
{ " i d " : " id " , " p a th " : " pa t h " , " n i " : " n" , " no " : " n "} ,
{ " i d " : " id " , " p a th " : " pa t h " , " n i " : " n" , " no " : " n "} ,
...
{ " i d " : " id " , " p a th " : " pa t h " , " n i " : " n" , " no " : " n "} ,
]}
{ " co n f ig ur at i o n " : [
{ " id " :" id " ,
" i " : [ " i1 " , " i2 " , . . . ] ,
" o " : [ " o1 " , " o2 " , . . . ] ,
} ,
{ " id " :" id " ,
" i " : [ " i1 " , " i2 " , . . . ] ,
" o " : [ " o1 " , " o2 " , . . . ] ,
} ,
...
{ " id " :" id " ,
" i " : [ " i1 " , " i2 " , . . . ] ,
" o " : [ " o1 " , " o2 " , . . . ] ,
}
]}
Listing 3 shows an example of system that cor-
responds to Figure 1. It consists of two parts: (1)
spark applications, and (2) configuration. Spark ap-
plication SA
1
has one input, which is a direct input,
and two outputs. Spark application SA
2
has one in-
put and one output. The first input is mapped to the
output of Spark application SA
1
(i.e., #SA1.o1).
CLOSER 2017 - 7th International Conference on Cloud Computing and Services Science
86

Listing 3: Configuration File Corresponding to Figure 1.
{ " s park - app li ca ti on s " : [
{ " i d " : " SA 1 ", " p a th " : " p a th 1 " , " ni " : " 1 " ," n o " : " 2 " } ,
{ " i d " : " SA 2 ", " p a th " : " p a th 2 " , " ni " : " 1 " ," n o " : " 1 " } ,
{ " i d " : " SA 3 ", " p a th " : " p a th 3 " , " ni " : " 1 " ," n o " : " 1 " } ,
{ " i d " : " SA 4 ", " p a th " : " p a th 4 " , " ni " : " 2 " ," n o " : " 1 " } ,
{ " i d " : " SA 5 ", " p a th " : " p a th 5 " , " ni " : " 1 " ," n o " : " 1 " } ,
]}
{ " co n f ig ur at i o n " : [
{ " id " :" S A1 " ,
" i " : [ " pat h in 1 " ] ,
" o " : [ " path o1 " , " path o2 " ] ,
} ,
{ " id " :" S A2 " ,
" i " : [ " # SA 1 .o1 " ] ,
" o " : [ " path o1 " ] ,
} ,
{ " id " :" S A3 " ,
" i " : [ " # SA 1 .o2 " ] ,
" o " : [ " path o1 " ] ,
} ,
{ " id " :" S A4 " ,
" i " : [ " # SA 2 .o1 " , " # SA3 . o 1 " ] ,
" o " : [ " path o1 " ] ,
} ,
{ " id " :" S A5 " ,
" i " : [ " # SA 4 .o1 " ] ,
" o " : [ " path o1 " ] ,
}
]}
3 REAL-TIME ADAPTIVE QoS OF
SPARK APPLICATION
It is difficult to predict the execution time of a set of
Spark applications and can vary between two differ-
ent runs. Moreover, deploying a set of Spark appli-
cations on the cloud can be very expensive and can
vary on-demand, i.e., depending on the needed time.
In this section, we propose a novel technique that al-
lows users to submit a set of Spark applications with a
deadline to execute all of them. For this, we consider
quality-based Spark applications, i.e., each Spark ap-
plication can be executed using different quality lev-
els. We build a controller that adaptively selects the
maximum quality levels for each Spark application
while respecting the given deadline. This approach
would be a great fit for Quality of Service applica-
tions. For the sake of simplicity, we consider a sub-
set of CBS where Spark application defines a pipeline
(i.e., the output of Spark application i is connected to
the input of Spark application i + 1).
Quality of Service (QoS) applications such as ma-
chine learning and graph analytics, iteratively process
the data. That is multiple rounds of computation are
performed on the same data. Therefore, the number
of rounds can be easily tuned to achieve a better qual-
ity of the end result. In general, the quality is pro-
portional to the number of rounds, and the execution
times of applications are unknown increasing func-
tions with respect to quality level parameters (i.e., in-
crease the quality implies increase of execution time).
In case of big data, these applications can be easily
and efficiently implemented using Spark which pro-
vides: (1) scalability; (2) implicit distribution; (3)
fault tolerance.
We introduces the adaptive method for QoS man-
agement of sequence of Spark applications. Given a
sequence of parameterized spark applications and a
deadline to be met, the method allows adapting the
behavior of each application by adequately setting
its quality level parameter while respecting the given
deadline. The objective is to not miss the deadline and
to select the maximum quality levels.
We consider Spark applications for which it is
possible, by using timing analysis and profiling tech-
niques, to compute estimate of worst-case execution
times and average execution times for different qual-
ity levels. Worst case and average execution times
will be used to estimate the execution times of Spark
applications, and hence select the best quality while
not exceeding the deadline.
We implement a controller that iteratively takes as
input the current Spark application SA
i
to be executed
and the actual time
1
of the previously executed Spark
applications, and it selects the quality level q to exe-
cute SA
i
so that we would be able to execute the re-
maining applications while not exceeding the dead-
line. Then, the new deadline will be computed with
respect to the actual execution time of SA
i
(q). The
controller must maximize the overall quality levels.
For this, it may follow several strategies. For instance,
it may select the maximum quality level of the cur-
rent application, however, this will end up by giving
priority for first applications (i.e., selecting maximum
quality) and low priority last applications (i.e., select-
ing minimum quality). Another option is to make
the selected quality levels smooth (i.e., low deviation
of quality levels with respect to the average quality).
Consequently, we implement three different policies
that are supported by the controller: (1) safe; (2) sim-
ple; (3) mixed.
1
Note that the actual execution times will be only known
after executing the application and will be used to adapt the
remaining deadline.
Reconfigurable and Adaptive Spark Applications
87

3.1 Controller - Proposed Policies
We consider parameterized Spark applications, i.e.,
their execution times depend on the input quality.
Moreover, non-predictability of the underlying cluster
is another factor of uncertainty. For this, we consider
that the execution times are unknown but bounded. A
parameterized application can be defined as follows.
Definition 3 (Parameterized Spark System). A pa-
rameterized Spark system PSS is a tuple PSS =
(SA, av, wc, D), where
• SA is a sequence of Spark applications SA =
[SA
1
, . . . , SA
n
].
• t
av
: SA × Q → R
+
, is a function that returns the
average execution time, t
av
(SA
i
, q) for a given
Spark application SA
i
and a quality level q. Q =
[q
min
;q
max
] is a finite interval of integers denoting
quality levels. We assume that, for all SA
i
∈ SA,
q 7→ t
av
(SA
i
, q) is a non-decreasing function.
• t
wc
: SA × Q → R
+
, is a function that returns the
worst-case execution time, t
wc
(SA
i
, q) for a given
Spark application SA
i
and a quality level q. We
assume that, for all SA
i
∈ SA, q 7→ t
wc
(SA
i
, q) is a
non-decreasing function.
• D ∈ R
+
is the global deadline to be met.
Let t
i−1
be the actual execution time to execute
SA
1
, . . . , SA
i−1
. That is, the time to execute the re-
maining Spark applications (i.e., SA
i
, . . . , SA
n
) is D −
t
i−1
. The controller must select the maximum qual-
ity levels for the remaining Spark applications while
respecting the new deadline. We define t
x
e
to be an es-
timation of the execution time of a sequence of Spark
applications for a given quality, t
x
e
([SA
i
, . . . , SA
n
], q).
Since our goal is not to exceed the deadline, our es-
timation should be an over-approximation (i.e., based
on worst-case execution times) of the actual execu-
tion time. We distinguish several policies to estimate
execution times of the remaining applications.
Safe Policy (t
s f
e
): this defines an obvious pol-
icy to ensure safety (deadline is met) but gives
more priority/time (i.e., higher quality) to first
applications. Given a sequence of Spark ap-
plications and a quality level q, t
s f
e
is defined
as follows: t
s f
e
([SA
i
, . . . , SA
n
], q) = t
wc
(SA
i
, q) +
∑
n
k=i+1
t
wc
(SA
k
, q
min
).
Simple Policy (t
sp
e
): this defines another policy to
ensure safety and improves smoothness (distributed
quality over all the remaining applications) by com-
bining worst-case and average case execution times.
t
sp
e
is defined as follows: t
sp
e
([SA
i
, . . . , SA
n
], q) =
Max
t
s f
e
([SA
i
, . . . , SA
n
], q), t
av
e
([SA
i
, . . . , SA
n
], q)
,
where t
av
e
([SA
i
, . . . , SA
n
], q) =
∑
k=n
k=i
t
av
(SA
i
, q).
Mixed Policy (t
mx
e
): the mixed policy
defines a generalization of the simple pol-
icy to improve smoothness by taking into
account all possible sequences. t
mx
e
is de-
fined as follows: t
mx
e
([SA
i
, . . . , SA
n
], q) =
Max
k=n
k=i−1
{t
av
e
([SA
i
, . . . , SA
k
], q) +
t
s f
e
([SA
k+1
, . . . , SA
n
], q)}.
Theorem 1. Given a pipeline of Spark applications
[SA
1
, . . . , SA
n
] and a deadline D. The controller will
not exceed D for all the defined policies (i.e., Safe,
Simple and Mixed) provided that the worst execution
time is always greater than the actual time.
Proof. For a given quality q, the mixed policy
has a higher over-estimation of the execution time
than the simple policy. Moreover, the latter has
a higher over-estimation of the execution time than
the safe policy. Formally, the above policies sat-
isfy the following property: t
mx
e
([SA
i
, . . . , SA
n
], q) ≥
t
sp
e
([SA
i
, . . . , SA
n
], q) ≥ t
s f
e
([SA
i
, . . . , SA
n
], q).
Moreover, as the safe policy is based on worst-
case execution times, it clearly satisfies the safety
requirement (i.e., deadline not exceeded at all itera-
tions). Consequently, all the policies satisfy the safety
requirement.
3.2 Controller - Quality Manager
Algorithm
The controller as depicted in Figure 2 must iter-
atively select maximum quality levels (optimality)
while guaranteeing safety (deadline must be met). For
this, at each iteration i, it selects (depending on the
policy used) the quality level of the next Spark appli-
cation according to the following:
Max {q | t
x
e
([SA
i
, . . . , SA
n
], q) + t
i−1
≤ D}
Where t
i−1
is the actual execution time after execut-
ing SA
1
, . . . , SA
i−1
, SA
i
is the current application to be
executed and t
x
e
is an estimation of the execution time
to execute the reaming applications, i.e., SA
i
, . . . , SA
n
.
This estimation can be computed using one of the
three policies defined in Subsection 3.1 (i.e., average,
simple, mixed).
Example 3. Given a sequence of three Spark applica-
tions SA
1
, SA
2
, SA
3
with deadline equals to 9, where
the average (avet), worst case (wcet) and the actual
(acet) execution times are given in the following ta-
ble.
quality wcet avet acet
1 1 1 1
2 5 2 2
3 6 3 3
4 7 4 4
CLOSER 2017 - 7th International Conference on Cloud Computing and Services Science
88
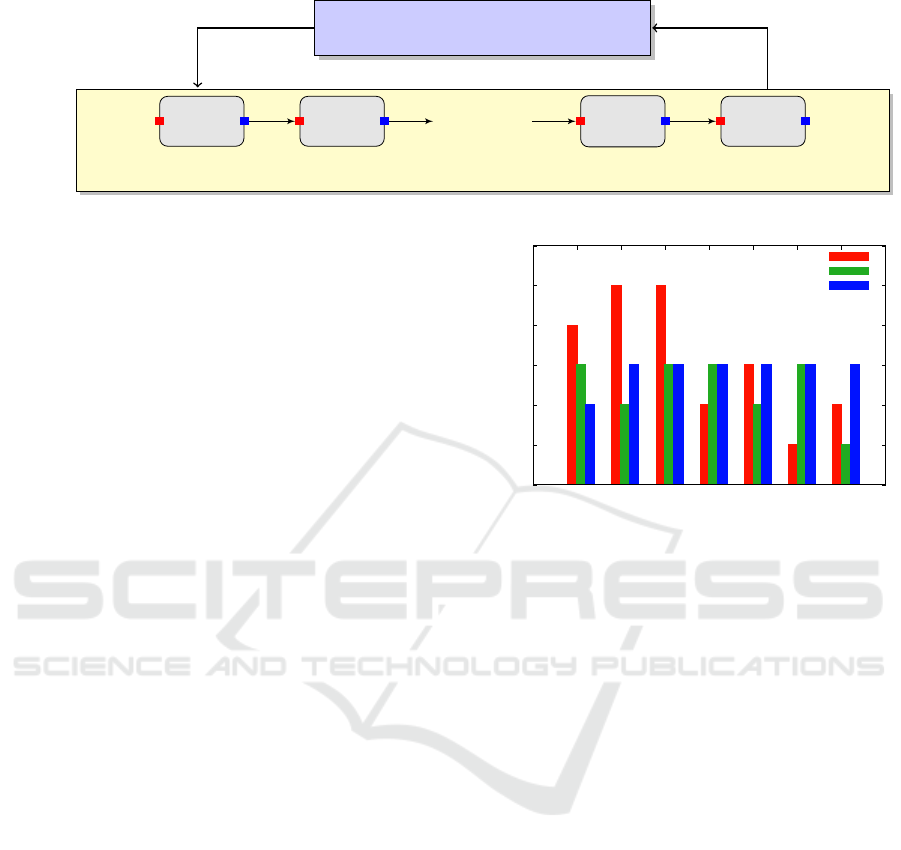
Pipeline of Spark Applications
SA
1
SA
2
. . .
SA
n−1
SA
n
i o i o i o i o
Controller
Max {q | t
x
e
([SA
i
, . . . , SA
n
], q) +t
i−1
≤ D}
Actual execution time t
i−1
after executing SA
1
, . . . , SA
i−1
Next quality, i.e., q, to
execute SA
i
Figure 2: Adaptive Spark.
• In case of safe policy, the quality levels 4, 1, 1 will
be selected for applications SA
1
, SA
2
, SA
3
, respec-
tively.
• In case of simple policy, the quality levels 3, 2, 1
will be selected for applications SA
1
, SA
2
, SA
3
, re-
spectively.
• In case of mixed policy, the quality levels 2, 2, 2
will be selected for applications SA
1
, SA
2
, SA
3
, re-
spectively.
3.3 Experimental Results
We consider three built-in Spark applications using
MLlib (Meng et al., 2015; Spark MLlib, 2016) (1)
K-means clustering; (2) Logistic Regression; and (3)
Support Vector Machine (SVM). We adapt these ap-
plication to run in five different quality levels from 1
to 5 (highest quality). Each quality represents a spe-
cific number of iterations (higher quality more iter-
ations). For example, quality level 4 and 5 in case
of SVM correspond to 50 and 100 iterations, respec-
tively.
We compute the average and worst-case execution
times by running several benchmarks. Tables 1 and
2 depicts the average and worst-case execution times
for specific number of instances and features. Note
that these execution times depend on the parameters
of each algorithm (e.g., number of features, size of
training set). For this, in the general case, the average
and worst-case execution times are functions with re-
spect to input parameters. For the sake of simplicity,
we only consider fixed value of parameters. More-
over, we consider that the deadline is greater than the
summation of worst case execution times of the low-
est quality.
We test our implementation by considering a se-
quence of seven Spark applications: SA
1
(SVM), SA
2
(Logistics Regression), SA
3
(K-means), SA
4
(Logis-
tics Regression), SA
5
(K-means), SA
6
(SVM) and SA
7
(SVM). The deadline is 1000 seconds. Figure 3 de-
picts the quality levels selected by the controller using
safe, simple and mixed policies, respectively. Clearly,
0
1
2
3
4
5
6
1 2 3 4 5 6 7
Quality
Spark Applications
Safe Policy
Simple Policy
Mixed Policy
Figure 3: Selected Quality by the Controller using Safe,
Simple and Mixed Policies.
the quality levels selected using the safe policy gives
more priority to first applications. The simple pol-
icy provides a small smoothness of quality levels.
The mixed policy provides a fair distribution (good
smoothness) of quality levels between all applica-
tions.
4 RELATED WORK
4.1 Data-Parallel Pipeline
Cascading (Cascading, 2016) and FlumeJava (Cham-
bers et al., 2010) are Java libraries that simplify the
development of data-parallel pipelines. Unlike our
method: (1) the proposed frameworks/libraries are
not compatible with Spark applications; (2) they al-
low pipelines/graph modeling within an application
and not between applications. Note that, our method
can be combined with those frameworks to give more
composition expressiveness.
4.2 Large Scale Graph Processing
Pregel (Malewicz et al., 2010) and Giraph (Giraph,
2016) are systems for large scale graph process-
Reconfigurable and Adaptive Spark Applications
89

Table 1: Worst case running time.
Algorithms Q1 Q2 Q3 Q4 Q5
K-means 115s 125s 135s 140s 145s
Logistic Regression 120s 135s 140s 150s 155s
SVM 130s 170s 190s 235s 345s
Table 2: Average case running time.
Algorithms Q1 Q2 Q3 Q4 Q5
K-means 95s 115s 125s 130s 135s
Logistic Regression 110 125s 130s 145s 150s
SVM 90s 140s 160s 205s 315s
ing. The two systems are inspired by the Bulk Syn-
chronous Parallel BSP model (Valiant, 2011). Such
systems take as input a directed graph and they de-
fine programs to express a sequence of iterations (re-
ceive messages, send messages, local computation)
depending on the vertex identifier. Our approach dif-
fers from this work in the following aspects. First,
they are not applicable to Spark. Second, they are
only specific to graph processing. Note also that our
approach can be applied on top of these systems.
4.3 High-Level Specific Big Data
Library
Several high-level specific libraries were proposed to
process big data. For example, MLlib (Meng et al.,
2015; Spark MLlib, 2016) provides machine learning
library on top of Spark. Apache Mahout (Mahout,
2016) allows to build an environment for quickly cre-
ating machine learning applications. Our high-level
specific language allows to compose different appli-
cations written using different high-level libraries.
Thus, developers can easily build a complex system
consisting of several applications using several li-
braries.
4.4 Adaptive QoS
In (Wust et al., 2004; Buttazzo et al., 1998; R.I.Davis
et al., 1993), they proposed solutions to achieve a soft
real-time execution multimedia applications based on
several techniques such as Markov decision process,
reinforcement learning and Earliest Deadline First
(EDF).
In (Combaz et al., 005b), they proposed a method
where the quality levels can be set adequately in
case of multimedia applications so that the follow-
ing QoS requirements are respected: (1) Safety - No
deadline is missed; (2) Optimality - Maximize the
available time; and (3) Smoothness of quality lev-
els. Our method is a variation of the method pre-
sented in (Combaz et al., 2008) where we apply it on
a sequence of Spark applications. To the best of our
knowledge, we have not seen major work that allows
the cloud to be parameterized to dynamically allocate
maximum quality levels for a sequence of submit-
ted jobs while respecting a user-input deadline (i.e.,
price/cost).
4.5 Dynamic Partitioning
In (Gounaris et al., 2017), they introduce an algorithm
for dynamic partitioning of RDDs with a view to min-
imizing resource consumption. The algorithm uses
analytical models for expressing the running time as
a function of the number of machines employed. Un-
like our method, it allows to dynamically select qual-
ity levels for a whole Spark application. Note that the
two methods may be combined to tune the granularity
of dynamism.
5 CONCLUSION
We have presented a new approach for linking Spark
applications to build a complex one based on a user-
defined configuration file. Given a set of Spark appli-
cations, a configuration file defines a directed graph
between the applications, where each edge is a de-
pendency between two applications. Dependency de-
notes order of execution and data dependency (e.g.,
the input of an application requires the output of a dif-
ferent application). We have implemented a Domain
Specific Language (DSL) to easily define interfaces
as well as connections between them. Our framework
automatically build the final system with respect to
the input configuration.
Furthermore, we have defined a method that al-
lows clusters to be augmented with controllers in or-
der to automatically manage quality levels of a se-
quence of Spark applications. Thus, our method al-
lows users to run a set of applications with the best
CLOSER 2017 - 7th International Conference on Cloud Computing and Services Science
90

possible quality without violating time constraints
(e.g., deadline). We discussed several policies in or-
der to either give more priority for early applications
or to obtain a fair quality between all the applications.
6 FUTURE WORK
The future work goes into several directions. First, we
consider to define a unified DSL that combines sev-
eral frameworks and not only Spark. Second, we will
introduce interface place holders within a Spark appli-
cation to allow more expressive composition. Third,
we will support several clusters and hence efficiently
transfer data at synchronization points become a chal-
lenging task. Another direction is to extend the con-
troller to take as input a graph of Spark applications
(not only a sequence). For this, the controller should
be augmented with a scheduler to select the best next
Spark application in addition to the next quality level.
REFERENCES
Buttazzo, G. C., Lipari, G., and Abeni, L. (1998). Elastic
task model for adaptive rate control. RTSS, pages 286–
295.
Cascading (2016). Cascading. http://www.cascading.org.
Chambers, C., Raniwala, A., Perry, F., Adams, S., Henry,
R. R., Bradshaw, R., and Weizenbaum, N. (2010).
Flumejava: easy, efficient data-parallel pipelines. In
Proceedings of the 2010 ACM SIGPLAN Conference
on Programming Language Design and Implementa-
tion, PLDI 2010, Toronto, Ontario, Canada, June 5-
10, 2010, pages 363–375.
Combaz, J., Fernandez, J., Sifakis, J., and Strus, L. (2008).
Symbolic quality control for multimedia applications.
Real-Time Systems, 40(1):1–43.
Combaz, J., Fernandez, J.-C., Lepley, T., and Sifakis, J.
(2005b). Qos control for optimality and safety. Pro-
ceedings of the 5th Conference on Embedded Soft-
ware.
Dean, J. and Ghemawat, S. (2004). Mapreduce: Simplified
data processing on large clusters. In 6th Symposium on
Operating System Design and Implementation (OSDI
2004), San Francisco, California, USA, December 6-
8, 2004, pages 137–150.
Dean, J. and Ghemawat, S. (2010). Mapreduce: a flexible
data processing tool. Commun. ACM, 53(1):72–77.
Ghemawat, S., Gobioff, H., and Leung, S. (2003). The
google file system. In Proceedings of the 19th ACM
Symposium on Operating Systems Principles 2003,
SOSP 2003, Bolton Landing, NY, USA, October 19-
22, 2003, pages 29–43.
Giraph (2016). Apache giraph. http://giraph.apache.org.
Gounaris, A., Kougka, G., Tous, R., Tripiana, C., and Tor-
res, J. (2017). Dynamic configuration of partitioning
in spark applications. IEEE Transactions on Parallel
and Distributed Systems, PP(99):1–1.
Mahout (2016). Apache mahout. http://mahout.apache.org.
Malewicz, G., Austern, M. H., Bik, A. J. C., Dehnert,
J. C., Horn, I., Leiser, N., and Czajkowski, G. (2010).
Pregel: a system for large-scale graph processing. In
Proceedings of the ACM SIGMOD International Con-
ference on Management of Data, SIGMOD 2010, In-
dianapolis, Indiana, USA, June 6-10, 2010, pages
135–146.
Meng, X., Bradley, J. K., Yavuz, B., Sparks, E. R.,
Venkataraman, S., Liu, D., Freeman, J., Tsai, D. B.,
Amde, M., Owen, S., Xin, D., Xin, R., Franklin, M. J.,
Zadeh, R., Zaharia, M., and Talwalkar, A. (2015).
Mllib: Machine learning in apache spark. CoRR,
abs/1505.06807.
R.I.Davis, K.W.Tindell, and A.Burns (1993). Scheduling
slack time in fixed priority pre-emptive systems. Pro-
ceeding of the IEEE Real-Time Systems Symposium,
pages 222–231.
Spark MLlib (2016). Spark mllib.
http://spark.apache.org/mllib/.
Valiant, L. G. (2011). A bridging model for multi-core com-
puting. J. Comput. Syst. Sci., 77(1):154–166.
Wust, C. C., Steffens, L., Verhaegh, W. F., Bril, R. J., and
Hentschel, C. (2004). Qos control strategies for high-
quality video processing. Euromicro Conference on
Real-Time Systems, pages 3–12.
Zaharia, M., Chowdhury, M., Franklin, M. J., Shenker, S.,
and Stoica, I. (2010). Spark: Cluster computing with
working sets. In 2nd USENIX Workshop on Hot Topics
in Cloud Computing, HotCloud’10, Boston, MA, USA,
June 22, 2010.
Reconfigurable and Adaptive Spark Applications
91
