
A Method for Gathering and Classification of Scientific Production
Metadata in Digital Libraries
Elisabete Ferreira and Marcos Sfair Sunye
Department of Computer Science, Federal University of Paran
´
a, Curitiba, Brazil
Keywords:
Digital Libraries, Metadata Retrieval, Digital Repositories, Scientific Journal Publication, Open Access.
Abstract:
This paper introduces a methodology for the automatic loading of metadata and open access scientific articles,
spread out in scientific journals in Institutional Digital Repositories (IDRs), obtained through information’s
extraction from the researchers curricula. A further objective is to help the institution for planning the costs
required to support the growth of their digital environment considering the scientific data that would be stored
in it. The aggregation of scientific production in a single institutional digital environment allows institutions to
generate internal indicators of scientific and technological production, conduct studies through the application
of data mining tools as well as support the implementation of management policies. For the purpose of
implementation, a set of components was developed for collecting scientific articles free of all restrictions on
access.
1 INTRODUCTION
High education institutions are responsible for the
majority of the scientific production in the form of
published journal articles, reports, conference papers
and so forth.
Although academic institutions are the major sci-
entific knowledge producers, the tasks of aggregating
and quantifying the knowledge produced by their re-
searchers is a difficult task (Setenareski et al., 2016).
Therefore, setting specific criteria for planning and
distributing resources to encourage scientific produc-
tion by their faculties become a relevant goal.
Another issue for the institutions is monitoring
their intellectual productivity through indicators, and
the proper planning of the archiving and preservation
process of digital materials over the long term. This
situation takes place due to the lack of a tool that ef-
fectively determines the costs of implementation and
maintenance of their digital environments.
Digital Libraries, that are incontestably relevant
nowadays, are responsible for aggregating, selecting,
structuring, offering access, interpreting, distributing,
and preserving items of intellectual resources of an
institution; hence, these components are financially
accessible to the community (Langiano, 2005). In
addition, by increasing access to research results of
an institution, Digital Libraries benefit professionals
and students who use their resources in teaching and
learning tasks.
The results of the knowledge produced in the form
of scientific articles by an institution are published in
scientific journals, which are considered the fastest
and most affordable way to disseminate scientific in-
formation, the findings of research work and what
these works represent to the community (Brofman,
2012).
Nevertheless, digital libraries fail in harvesting,
selection and aggregation of items of scientific pro-
duction published in periodical journals. For instance,
many of them focus solely on providing the scientific
production of their educational programs in the form
of monographs, theses and dissertations.
There are many methods to populate IDRs, such
as self-submission and semi-automated mechanisms.
Another form is harvesting by OAI-PMH (available
at: http://www.openarchives.org/pmh/), a protocol
created to promote interoperability between libraries
and digital repositories as an effort to improve access
to e-print archives in order to increase the availability
of scholar communication. However, all of them re-
quire the involvement of the authors and/or the library
staff.
OAI-PMH defines which criteria must be met to
facilitate the efficient dissemination of content in digi-
tal environments. In its context, there are two types of
providers which require both the publishers and digi-
tal repositories to support it and have it enabled:
• data providers – which are repositories that ex-
pose their structured metadata according to OAI-
PMH and;
• service providers – which make service requests
Ferreira, E. and Sunye, M.
A Method for Gathering and Classification of Scientific Production Metadata in Digital Libraries.
DOI: 10.5220/0006358203570364
In Proceedings of the 19th International Conference on Enterprise Information Systems (ICEIS 2017) - Volume 1, pages 357-364
ISBN: 978-989-758-247-9
Copyright © 2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
357

via OAI-PMH to harvest the available metadata.
Regarding this scenario, the fact that scientific
production of institutional articles end up scattered
in scientific journals consists a serious problem. In
this sense, access and identification of this scientific
knowledge by the community (and even by the insti-
tution itself that produced it) is often hampered. Like-
wise, institutions also lack information about how
much of the teaching staff is aware of the availabil-
ity of their science production free of all restrictions
on access. Moreover, another difficulty is identify-
ing open access articles when this information is not
found on metadata.
In the field of scientific publication, open access
means publications on the Internet that allow reading,
copying, distribution or re-use for lawful purposes
without technical, financial or legal barriers—as well
as guaranteeing the author’s moral and patrimonial
rights (Open Society Institute, 2002). The philoso-
phy behind open access is a trend that has been ob-
served in recent years towards the use of tools, strate-
gies and methodologies to communicate new scien-
tific research.
In this context, this article proposes a methodol-
ogy for loading open access articles on digital repos-
itories obtained through information extraction from
curricula of an institution’s researchers.
Brazilian researchers have their scientific produc-
tion registered at an academic national database, the
Lattes Platform (available at: http://lattes.cnpq.br/).
For implementation purposes, a study divided into
4 parts was realized: (1) gathering and processing of
metadata from a researchers’ curricula database; (2)
development of a script for collecting open access sci-
entific articles; (3) selection of a software for loading
and converting metadata to the Dublin Core format;
and (4) populating a digital repository by importing
the acquired data. For this study purposes, the IDR of
a Brazilian institution was used.
This work is organized as follows: the second sec-
tion talks about metadata, its characteristics and im-
portance in indexing digital objects in digital environ-
ments; persistent identifiers like DOIs and handles,
their uses and finalities for preservation of digital ob-
jects on the long term are contextualized in the third
section; the fourth section brings the concepts about
Digital Libraries, such as their history, importance
and characteristics; the fifth section describes the pro-
posed method and analyzes its application; and, fi-
nally, the main points of this paper are summarized
and suggestions for future works are presented in the
conclusion.
2 METADATA
Metadata are information related to a stored resource,
either physical or not, that not only identify and de-
scribe it, but also document its behavior, function and
use, as well as its relationship to other digital objects
and how it should be managed. “Metadata are struc-
tured in the form of text and keywords and gener-
ally contain direct information, such as author name,
creation date, subject, but can also be complex and
harder to define, as the opinion consensus of various
people on the same book” (Langiano, 2005). Thus,
metadata prove to be essential to facilitate discovery
of relevant content in digital libraries.
Furthermore, an item or object available in dig-
ital media should survive the successive generations
of hardware and software. Given such complexity
and the importance in designing digital objects’ meta-
data, a study was proposed to categorize them into
five types (Baca, 1998):
• “Administrative: used in the management and ad-
ministration of information resources, such as ver-
sion control and copyright information;
• Technical: related to the operation or behavior
of system metadata, for example, scanning pro-
cesses;
• Descriptive: used to describe and identify re-
source information, for example, specialized in-
dexes and search aids;
• Preservation: related to the preservation of infor-
mation resources, for example, policies relating to
the backup of digital objects;
• Use: related to the level and type of use of infor-
mation resources.”
In this article, descriptive metadata are used for
identification of bibliographic content of scientific
works.
2.1 Metadata Schema
Metadata schemas are sets of elements, designed for
a specific purpose that are used to describe an infor-
mation resource. The elements’ definitions or mean-
ings are known as the schema’s semantics, and the
values of a given element are its contents. Metadata
schemas generally specify the names of elements and
the corresponding semantics (Say
˜
ao, 2007b). Meta-
data should be carefully planned and support interop-
erability with other digital libraries, hence facilitat-
ing the location and use of digital objects. Metadata
schemas and metadata standards exist to enable the ef-
fective sharing of resources between institutions and
users.
ICEIS 2017 - 19th International Conference on Enterprise Information Systems
358

2.1.1 Dublin Core - DC
Dublin Core is a metadata schema proposed in 1995
to promote metadata interoperability (DCMI, 2012).
Dublin Core uses “a set of simple but effective el-
ements that describe a wide variety of network re-
sources” and “whose semantics were established by
an international consensus of professionals from var-
ious disciplines such as library science, computing,
text markup, community museums and other related
fields” (LARA, 2002). This metadata schema uses
fifteen descriptive elements standardized by techni-
cal vocabularies and specifications maintained by
the Dublin Core Metadata Initiative (DCMI, 2012).
Dublin Core is the metadata schema adopted by the
analyzed IDR.
The Dublin Core elements are identified as “dc”
and have a single value. Since each element has
unlimited occurrence, qualifiers are used in order
to distinguish the value of each occasion, which
may have an identifier called “schema” or “modi-
fier” (Alves and Souza, 2007) according to the syn-
tax: dc.element.qualifier as shown in Figure 1. Al-
though this schema provides an element for identi-
fying rights, it is not commonly included in article’s
metadata.
Elemen t Value Lanquage
dc.contributor.author Barbosa, Eduardo Mayer
dc.contributor.author Rodrigues, Tamires Maria
dc.date.accessioned 2015 06 13T00:31:47Z
dc.date.available 2015 06 13T00:31:47Z
dc.date.issued 2015 06 12
dc.identifier.uri http://hdl.handle.net/1884/38213
dc.language.iso pt_BR pt_BR
dc.rights Attribution 3.0 United States *
dc.rights.uri http://creativecommons.org/licenses/by/3.0/us/ *
dc.subject pt_BR
dc.title pt_BR
dc.type Working Paper pt_BR
Esporte de Orientação, Leitura de Mapas,
Geografia, Ensino.
USO DO ESPORTE DE ORIENTAÇÃO EM
AMBIENTE REDUZIDO PARA O ENSINO DE
LEITURA DE MAPAS
Figure 1: Examples of Dublin Core elements.
2.2 Metadata and Interoperability
The information of digital objects stored in Digital
Libraries or Repositories is called “content” and is
divided into data and metadata. While the first cor-
responds to the generic term that describes the infor-
mation in digital format, the second is data about the
data itself (Langiano, 2005). Metadata, if carefully
constructed, bring several advantages for users of dig-
ital libraries, since a standardized representation of
the available information resources in electronic form
provides a broad and accurate access to the content
stored in these environments.
Provided that digital objects must survive succes-
sive generations of hardware, software and systems,
metadata prove to be vital by allowing them to ex-
ist independently of the system in use for storage and
search. In this sense, metadata are essentially tech-
nical, descriptive and should be preserved in order
to document the creation and maintenance of a dig-
ital object, as well as its availability and relationships
with other objects. For digital objects to remain ac-
cessible and intelligible over time, the transportation
and preservation of their metadata must be possible
(Baca, 1998). To facilitate the search and access to
the digital objects’ contents, a metadata schema is se-
lected to describe the various existing types of con-
tents (e.g. videos, sounds, images, texts, websites,
etc.) according to the library or repository’s purpose.
2.3 Metadata Harvesting
Several studies on the creation and updating of digi-
tal environments, as well as best practices to be fol-
lowed by institutions, are found in literature (Ramos
et al., 2012). Institutional digital environments pro-
mote and contribute to the dissemination of scientific
production, once they are one of the tools that guaran-
tee the visibility of the institution and its researchers.
Therefore, they should always be available and con-
stantly updated. Thus, for the success of a digital li-
brary, the effective interaction between the develop-
ment and maintenance team and the staff responsible
for its archives is a relevant issue (Leite, 2009). The
digital repositories analyzed for this work are popu-
lated by the forms below:
2.3.1 Automation by OAI-PMH
The use of the OAI-PMH for automatic update of
metadata in digital libraries is based on the metadata
extraction from national and international databases,
and faces the lack of standards for extraction of
open access scientific publications’ metadata. Fur-
thermore, just the scientific articles found in these
databases (whether open access or not), that meet the
database’s specific guidelines, are sufficient to make
the locating of all articles produced by an institution
be ineffective.
2.3.2 Automation by Self-submission
The libraries and IDRs identified in this study use
the self-submission process to collect their scientific
production. Self-submission offers, in some specific
cases, support from a library team or customized tools
for metadata retrieval, beyond the indispensable par-
A Method for Gathering and Classification of Scientific Production Metadata in Digital Libraries
359

ticipation of authors for gathering information about
the licensing of the scientific production involved.
Out of the 1,000 top institutional reposi-
tories ranked by Webometrics (available at:
http://repositories.webometrics.info/) in the sec-
ond half of 2014, 887 have scientific articles, 103
have only monographs, dissertations and theses
and 10 were unavailable. From the 887 that have
scientific articles: 764 use the process of direct self-
submission; 17 use self-submission with supporting
tools for metadata retrieval; 32 have submissions
made by the library after receiving data and metadata
sent by the authors; 27 have self-submission made
by the authors with the support of a library; 16
have automated collection by OAI-PMH; and, in
one of them, a library staff identifies the scientific
production from the authors’ email addresses and
later requests them to submit the publication in the
institution’s digital library.
The aggregation of scientific literature in a single
institutional digital environment allows the institution
to develop internal indicators of scientific and tech-
nological production, carry out research by applying
data mining tools, and support the implementation of
management policies.
3 PERSISTENT IDENTIFIERS
The archiving and preservation of digital materials
over the long term is a difficult and expensive task that
requires substantial resources and institutional com-
mitment (NISO, 2007). In the mid 1990s, with the
World Wide Web’s popularization, there were persis-
tent identifiers that corresponded to unique identifica-
tion elements added to digital objects, which, regard-
less of their location or format, ensured that they were
accessible in the long term, despite physical and tech-
nological changes (Say
˜
ao, 2007a). Persistent identi-
fiers are typically found as URNs (Uniform Resource
Name), URCs (Uniform Resource Characteristics),
and URLs (Uniform Resource Locators), among oth-
ers (Sollins and Masinter, 1994).
3.1 The Handle System
The Handle System
R
⃝
persistent identifier was devel-
oped in 1994 by the Corporation for National Re-
search Initiatives (CNRI) in the United States. It is
a component of the digital objects architecture, which
provides a safe, efficient and extensible resolution to
unique and persistent identifiers. Resolution services
are the mechanisms by which a particular persistent
identifier is linked to an URL where the digital object
is stored.
3.2 Digital Object Identifier - DOI
DOI (Digital Object Identifier) was presented for the
first time at the Frankfurt Book Fair in 1997, and, a
little further in the same year the International DOI
Foundation (IDF) was created to manage the system.
The DOI is a proprietary implementation of the Han-
dle System, originated from a joint initiative of three
trade associations in the book industry (International
Publishers Association; International Association of
Scientific, Technical and Medical Publishers; and As-
sociation of American Publishers). It emerged as a
generic framework for the content ID management
through digital networks (International DOI Founda-
tion, 2015). Since then, DOIs have been used to as-
sign and disseminate information on intellectual prop-
erty rights to the digital objects (Say
˜
ao, 2007a).
For the correct location of a digital object using
DOI, a minimum of structured metadata, such as bib-
liographic and commercial information, should exist.
Metadata assigned to a digital object give the user the
assurance that the resource found is effectively what
he or she is looking for. The data model used by
a DOI identifier provides a contextual metadata sys-
tem that supports interoperability between different
existing metadata schemas in a digital environment.
This model consists of an interoperable data dictio-
nary plus an underlying structure for applications.
4 DIGITAL LIBRARIES
The materials or digital objects available in a digital
library may derive from digital copies of existing ma-
terials in physical media (for instance, books, prints,
manuscripts, etc.) and/or from objects existing only in
digital media, such as digital photos, e-books, videos
and others.
Aiming at a reliable digital preservation process,
it is important that, in addition to using rigorous sci-
entific methodology for the generation of knowledge,
the results obtained by the academic and scientific re-
search of an institution are disseminated in open ac-
cess digital repositories linked to a persistent iden-
tifier. As a matter of fact, persistent identifier is a
unique name for a digital object that is independent
of its location or format, ensuring that the object is
accessible independent of physical and technological
changes (Say
˜
ao, 2007a).
The adoption of IDRs by universities and research
centers promotes an increase in the visibility and
ICEIS 2017 - 19th International Conference on Enterprise Information Systems
360
competitiveness of these institutions, which in its way,
contributes to scientific development (Leite, 2009).
Institutional repositories can belong to universi-
ties, laboratories and research institutes, whereas the
thematic repositories are arranged by knowledge area
without institutional boundaries. The adoption of dig-
ital repositories, when well planned and properly im-
plemented, promotes “increased visibility of research
results, the researcher and of the institution itself”
(Leite, 2009). IDRs, a fundamental element of to-
day’s digital libraries, have been heavily used to pro-
mote scientific production from research and teaching
activities (Leite, 2009).
5 ARCHITECTURE
The objective of this study was to develop a set of
components for metadata harvesting and classifica-
tion of open access scientific articles in an IDR. The
queries used DOI identifiers to retrieve information
from the publication, since this is the unique perma-
nent identifier to recover an article in the online en-
vironment. DOIs have been obtained from the re-
searchers’ curricula from an institution.
5.1 The Lattes Platform
The Lattes Platform “is the experience of CNPq in
integrating databases of r
´
esum
´
es, research groups
and institutions into a single information system”
(Plataforma Lattes, 1999).
Currently, teachers and researchers from
Brazilian institutions who produce scientific
work and participate in governmental programs
such as the Coordination for the Improvement of
Higher Education Personnel (Capes) (available at:
http://www.capes.gov.br/) and the National Coun-
cil for Scientific and Technological Development
(CNPq) (available at: http://cnpq.br/pagina-inicial)
are advised to inform their scientific productions on
this database. Furthermore, it is possible for an edu-
cational institution to access the scientific production
of its faculties through the “Lattes Extractor” system.
The data extraction is provided via XML files con-
taining all the institution’s scientific production regis-
tered on the platform, by research groups, teachers,
researchers and students.
5.2 Proposal
Each article is processed by the components in the
system and assigned to a specific stage from -1 to 5,
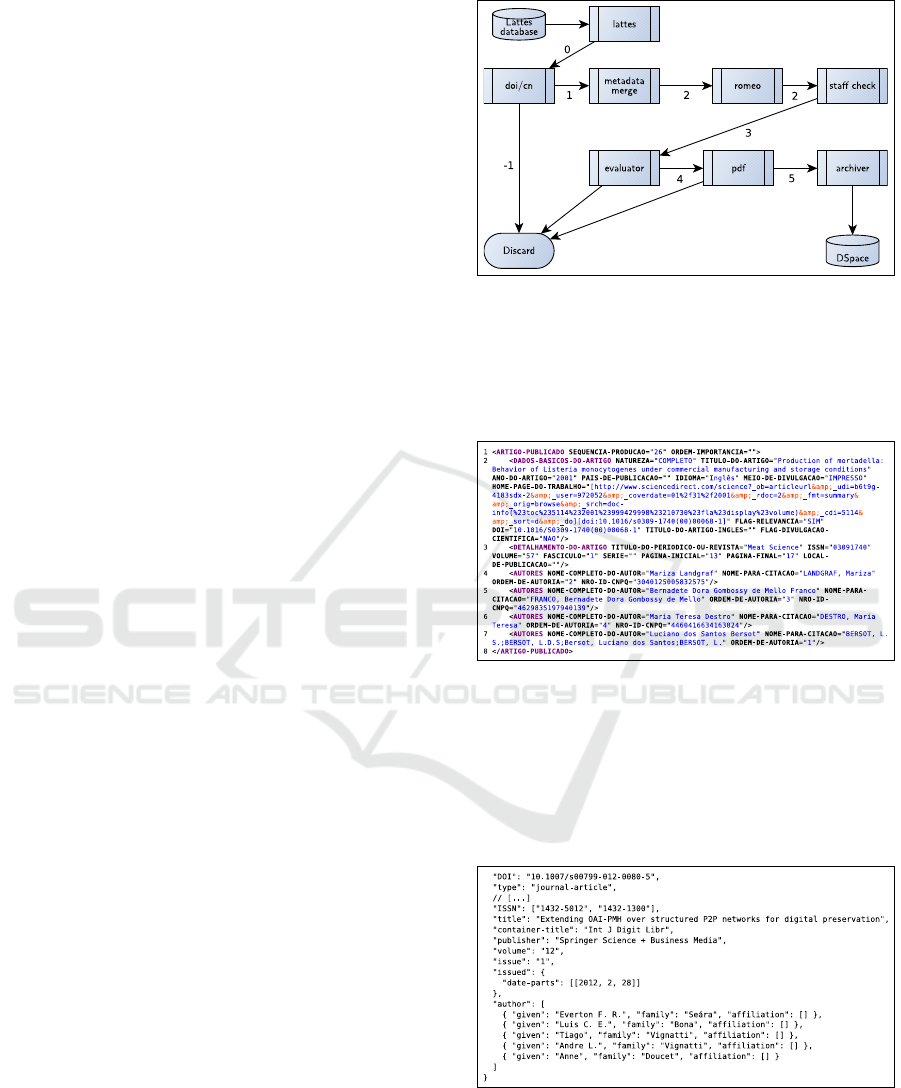
as shown in Figure 2:
Figure 2: Stage flow for article selection.
The DOIs and metadata extracted from
ARTIGO-PUBLICADO
(published article) tags in
curricula of Lattes Platform are stored in a database
with stage 0.
Figure 3: Example of an
ARTIGO-PUBLICADO
tag in the Lat-
tes XML.
Thenceforth, the metadata of each DOI is re-
quested from the dx.doi.org resolver, as shown in Fig-
ure 4. In this step the DOIs are also validated, be-
ing stored with stage 1; invalid DOIs are assigned for
deletion with stage -1.
Figure 4: DOI metadata in the citeproc format.
Thereafter, the sets of metadata retrieved from the
Lattes and DOI bases are merged, with DOI metadata
taking precedence and being marked as stage 2.
According to the site SHERPA/RoMEO (available
at: http://www.sherpa.ac.uk/romeo/), an initiative for
A Method for Gathering and Classification of Scientific Production Metadata in Digital Libraries
361
identification of scientific publications according to
the open access movement, the publishing journal’s
International Standard Serial Number (ISSN) is veri-
fied according to the open access movement, as shown
in Figure 5.
Figure 5: Result of a query to SHERPA/RoMEO.
In the case of production restricted to the institu-
tion at stage 2, there was a query to institutional staff
database. Similar names are resolved by an algorithm
for homonyms that compares initials in the author’s
name:
• “MARCIO SANTOS SILVA”, “M SANTOS
SILVA”, “MARCIO S SILVA”, “MARCIO
SILVA”, “M S SILVA”, e “M SILVA”;
• “MAURICIO SILVA” e “M SILVA”.
Given the example above, articles authored as “M
SILVA” would be discarded, since the author’s name
is ambiguous. In this step, articles with ISSN, pro-
duced by an institutional author throughout his or her
permanence at the institution and that can be pub-
lished according to the open access movement, are set
up as stage 3.
Hereafter, all articles that can be published in dig-
ital repositories are set as stage 4.
In order to obtain the articles’ full text as PDF, al-
gorithms to search the periodical’s HTML pages were
developed. Then, the articles’ PDFs are stored in a
database. In this scenario, some difficulties emerged:
while some periodicals allow the access to the PDF
only by the DOIs, others have locks by robots against
harvesting or other reasons. For each difficulty, a spe-
cific algorithm was developed.
The articles’ PDFs available for storage according
to the open access movement were stored in database
with stage 5.
Once the metadata and PDFs have been selected,
a directory structure in the Simple Archive Format
was developed for importing by DSpace software, as
shown in Figure 6.
Figure 6: Example of Metadata Archive according to the
Simple Archive Format.
Finally, the selected articles’ PDFs and their re-
spective metadata were stored at the IDR.
5.3 Case Study and Analysis
The analyzed repository, part of the Digital Libraries
of the Federal University of Paran
´
a, in Brazil, was es-
tablished in 2004 using the DSpace platform. This
digital environment presents collections of different
types of scientific output, such as theses, monographs
and dissertations, among others. However, the repos-
itory currently does not include scientific articles.
Since an article can be referenced by more than
one curriculum, these references were unified by their
DOIs (Figure 7), when available.
Figure 7: Count of normalized metadata.
In the tag “Published Article” from Lattes Plat-
form’s XML, 1,295 occurrences were obtained, which
resulted in 34,441 references to scientific articles.
From these references, 8,969 were classified with
ICEIS 2017 - 19th International Conference on Enterprise Information Systems
362
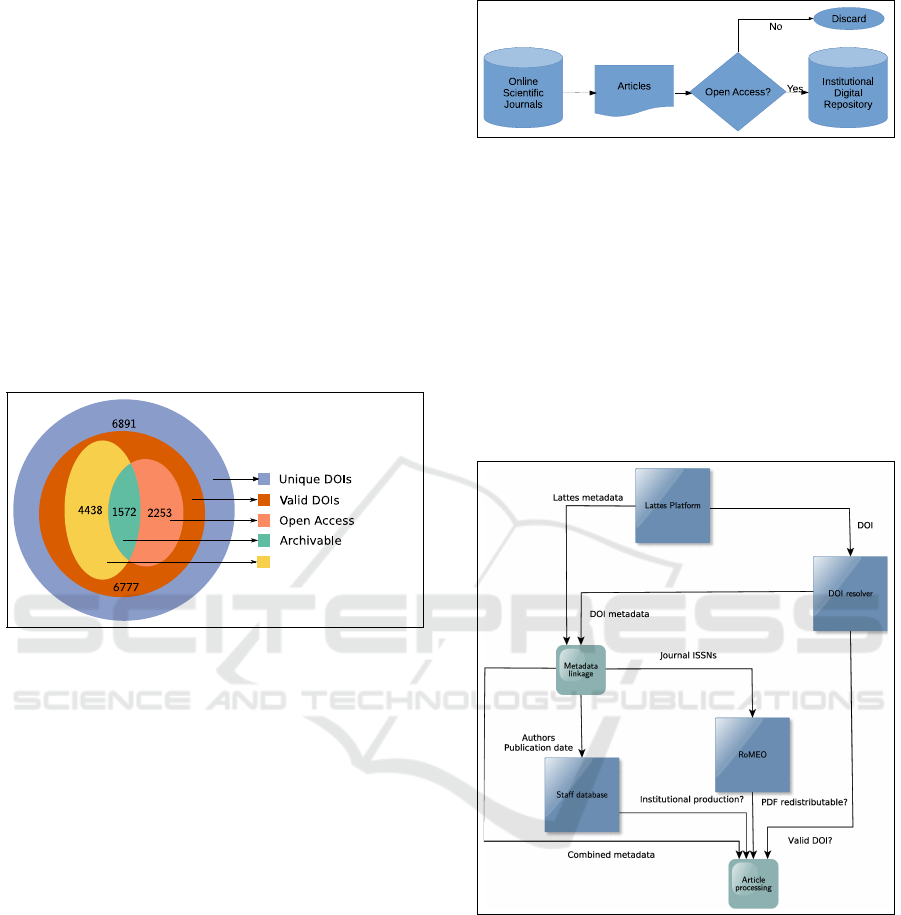
DOI attribute, 6,891 with unique DOIs and, after
DOI’s resolver submission, 6,777 with valid DOI
identifier.
The valid DOIs referenced 36,463 authors, of
whom 8,907 were researchers from the analyzed in-
stitution.
Of the 2,783 ISSNs found, 545 (19.6%) belong to
open access periodicals, 2,029 (42.9%) belong to non
open access periodicals and 209 (7.5%) are not listed
at SHERPA/RoMEO.
Of the 6,777 articles with valid DOI, 2,253 allow
archiving in digital repositories and 4,438 were pro-
duced by the institution’s researchers. 1,572 articles
meet both criteria and can be archived at the Institu-
tional Digital Repository. This scenario is illustrated
by Figure 8.
Institutional production
Figure 8: Count of open access articles identified.
In order to ensure the identification of only the
scientific production of the university’s faculties, but
also considering the possible production of a profes-
sor currently inactive but engaged in another institu-
tion, cross-references were made between the infor-
mation available on the Lattes Platform and the in-
stitution’s administrative database, which resulted in
1,241 classified professors.
Afterwards, the metadata of articles by selected
professionals were retrieved from CrossRef (available
at: http://crossref.org/), a registry authority for DOIs,
by a script, which found 2,293 journals. The metadata
were stored in a relational database.
It was necessary to check the license under
which the articles were produced. This was accom-
plished by querying the publishing journal’s ISSN on
SHERPA/RoMEO.
The article metadata obtained and stored in the
database were cross-referenced with the list of open
access journals, resulting in 2,287 articles published
under open access and whose published version could
be redistributed by the institution’s digital libraries.
Figure 9 shows the selective process of the scien-
tific production of articles classified for importation
in the digital repository.
Figure 9: Selection of scientific articles for importation.
Once a scientific article available under open ac-
cess is identified, its metadata plus a specific metadata
item, which indicates the license under which the arti-
cle is available, are collected and stored in a database
allowing the identification of these items in a digital
repository. The purpose of such action was to add
the data for subsequent metadata transference accord-
ing to the Dublin Core metadata format, as it is the
schema adopted by the IDR that is object of this study.
The diagram in Figure 10 shows the flow and the
entities and decisions involved.
Figure 10: Flow, entities and relationships in the selection
of the institution’s open access scientific articles.
The process of automated loading followed these
steps: (1) creation of a community called “Scientific
Production”; (2) creation of a sub-community called
“Articles” and; (3) population of the data and meta-
data.
5.3.1 Result Analysis
Scientific publications stem from research projects.
They “aim to disseminate scientific research to the
community in order to allow others to use it and eval-
uate it in other views” (Brofman, 2012).
A Method for Gathering and Classification of Scientific Production Metadata in Digital Libraries
363

Although the authors of scientific works are asked
to provide their work in a standardized electronic for-
mat on at least one open access repository by the
Berlin Declaration (MPG, 2003), it is still clear the
lack of awareness by many of the authors related to
this topic. This research identified that 35.4% of the
institution’s scientific production were produced in
open access format.
6 CONCLUSION
The adoption of IDRs promotes the dissemination of
technical and scientific content produced by an insti-
tution and culturally enrich those who benefit from it.
Aggregation of scientific production in one location
enables access to a great amount of information and,
therefore, encourages the transfer of knowledge. This
work also demonstrated how important it is for the
university staff to own and maintain their data updated
in a curricula database, as well as properly inform the
DOIs associated with their publications, since this is
the only permanent identifier of an article for recovery
in the web. Moreover, it was shown that the institution
could plan the costs required to maintain its digital
environment by determining the volume of scientific
production to be stored in its digital library. In this
scenario, the institution would also be able to measure
the real impact produced by their academic commu-
nity.
This study aimed at developing a set of compo-
nents for collection and classification of metadata of
scientific articles produced under open access in an
IDR without assigning to their researchers the task
of keeping their curricula data up to date in curricula
database. Thus, other kinds of scientific production
would be worth being classified and aggregated in the
Digital Library in future developments, such as the
classification and selection of metadata of: (1) scien-
tific events; (2) university extension activities.
REFERENCES
Alves, M. and Souza, M. (2007). Estudo de corre-
spond
ˆ
encia de elementos metadados: Dublin core e
marc 21. RDBCI, 4(2).
Baca, M. (1998). Introducci
´
on a los metadatos: v
´
ıas a la
informaci
´
on digital. Getty Information Institute.
Brofman, P. R. (2012). A import
ˆ
ancia das publicac¸
˜
oes
cient
´
ıficas. Cogitare Enfermagem, 17(3):419.
DCMI (2012). Dublin Core Metadata El-
ement Set, version 1.1. Available at:
http://dublincore.org/documents/2012/06/14/dces/.
Accessed in 2015-11-11.
International DOI Foundation (2015).
DOI handbook. Available at:
http://www.doi.org/doi handbook/1 Introduction.html
#1.2. Accessed in 2015-06-18.
Langiano, B. d. C. (2005). Um Mecanismo para Automati-
zar a Criac¸
˜
ao dos Metadados das Imagens de Bibliote-
cas Digitais e Prover Buscas por Conte
´
udo. Master’s
thesis, UFPR.
LARA (2002). Qu’est-ce que le dublin core? Available at:
http://lara.inist.fr/lara. Accessed in 2015-05-28.
Leite, F. C. (2009). Como gerenciar e ampliar a visibili-
dade da informac¸
˜
ao cient
´
ıfica brasileira: reposit
´
orios
institucionais de acesso aberto. IBICT.
MPG (2003). Berlin Declaration on Open Access to Knowl-
edge in the Sciences and Humanities.
NISO (2007). A framework of guidance for build-
ing good digital collections. Available at:
http://www.niso.org/publications/rp/framework3.pdf.
Accessed in 2015-06-17.
Open Society Institute (2002). Budapest
Open Access Initiative. Available at:
http://www.budapestopenaccessinitiative.org/. Ac-
cessed in 2016-10-06.
Plataforma Lattes (1999). Available at:
http://memoria.cnpq.br/web/portal-lattes/sobre-a-
plataforma. Acessado em: 2015-03-07.
Ramos, R. C., Andretta, P. I. S., and Silva, E. G. (2012).
Considerac¸
˜
oes acerca do processo de alimentac¸
˜
ao de
reposit
´
orios atrav
´
es da importac¸
˜
ao de registros de
bases de dados internacionais. RDBCI, 10:1.
Say
˜
ao, L. F. (2007a). Interoperabilidade das bibliote-
cas digitais: o papel dos sistemas de identificadores
persistentes—URN, PURL, DOI, Handle System,
CrossRef e OpenURL. TransInformac¸
˜
ao, 19(1):65–
82. doi:10.1590/s0103-37862007000100006.
Say
˜
ao, L. F. (2007b). Metadados para preservac¸
˜
ao
digital—aplicac¸
˜
ao do modelo OAIS. Available at:
http://www.documentoseletronicos.arquivonacional.
gov.br/Media/publicacoes/ctdemetadadospreservacao
digitalsayao.pdf.
Setenareski, L. E., Shima, W., Sunye, M. S., and Peres,
L. M. (2016). Open digital repositories: The move-
ment of open access in opposition to the oligopoly of
scientific publishers. In Proceedings of the 18th Inter-
national Conference on Enterprise Information Sys-
tems - Volume 2: ICEIS, pages 583–593.
Sollins, K. and Masinter, L. (1994). RFC 1737: Functional
requirements for uniform resource names. Available
at: https://tools.ietf.org/html/rfc1737. Accessed in
2017-03-03.
ICEIS 2017 - 19th International Conference on Enterprise Information Systems
364
