
Facial Emotion Recognition in Presence of Speech using a Default
ARTMAP Classifier
Sheir Afgen Zaheer
1,2
and Jong-Hwan Kim
1
1
School of Electrical Engineering, KAIST, Daejeon, Republic of Korea
2
Innovative Play Lab, Goyang, Republic of Korea
Keywords:
Emotion Recognition, Fuzzy Adaptive Resonance Theory, Default ARTMAP.
Abstract:
This paper proposes a scheme for facial emotion recognition in the presence of speech, i.e. the interacting
subjects are also speaking. We propose the usage of default ARTMAP, a variant of fuzzy ARTMAP, as
a classifier for facial emotions using feature vectors derived from facial animation parameters (FAP). The
proposed scheme is tested on Interactive Emotional Dyadic Motion Capture (IEMOCAP) database. The results
show the effectiveness of the approach as a standalone facial emotion classifier as well as its relatively superior
performance on IEMOCAP in comparison to the existing similar approaches.
1 INTRODUCTION
To realize emotional intelligence in robots and arti-
ficial intelligence, ability to process emotional infor-
mation and recognize emotions is essential. People
communicate their emotions through various modes
of communication. Facial expressions are the most
dominant indicators of emotions among those com-
munication cues. Therefore analyzing facial informa-
tion for emotion recognition has attracted a lot of in-
terest as research issue various fields, such as affective
computing, social robotics and human robot interac-
tion (Liu et al., 2013; Hirota and Dong, 2008; Rozgi
et al., 2012).
In recent years, machine learning techniques for
facial emotion recognition have been very popular
(Liu et al., 2014; Li et al., 2015b). Among those
Convolutional Neural Networks (CNN) have been the
most successful and popular on the benchmark prob-
lems (Li et al., 2015a). These approaches use the im-
ages or sections of the images directly as training in-
puts. Though such approaches have been very suc-
cessful on popular facial emotion databases, such as
MMI and CKP facial expression database, they have
practical limitations with audiovisual data consisting
of multi-modal interactions. They work really well
for still image data or video data with facial expres-
sions only. However, this changes when the incom-
ing data is audiovisual and the user is speaking. The
variations in a speaking face are a compound effect
of both the facial expression (emotion) and the facial
movement to utter the words (lexicon).
Figure 1: Dependency of various factors on different areas
of the face. Darker color represents higher dependency.
To extract right features for facial emotion from
a speaking face, we first need to understand how the
emotions and lexicon affect different regions of the
face. (Mariooryad and Busso, 2016) studied this vari-
ation in different regions of the face. Their findings
are shown in Fig. 1.
In this paper, we propose a facial emotion recog-
nition scheme using supervised adaptive resonance
theory (ARTMAP). The proposed scheme formulates
a feature vector based on the facial animation pa-
rameters (FAP) corresponding to the emotional re-
gion of the face, as shown in Fig. 1, and utilizes a
default ARTMAP as a classifier for emotion recog-
nition. The database used in this paper is Interac-
tive Emotional Dyadic Motion Capture (IEMOCAP)
Zaheer S. and Kim J.
Facial Emotion Recognition in Presence of Speech using a Default ARTMAP Classifier.
DOI: 10.5220/0006572204360442
Copyright
c
2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
(Busso et al., 2008). IEMOCAP database is an acted,
multimodal and multispeaker database, developed by
Signal Analysis and Interpretation Laboratory (SAIL)
lab at the University of Southern California (USC). It
contains approximately 12 hours of audiovisual data,
including audiovisuals, motion capture of face, text
transcriptions. The motion capture information, the
interactive setting to elicit authentic emotions, and the
diversity of the actors in the data base (five males and
five females) make this database a valuable, realistic
and challenging emotion corpus.
This paper is organised as follows: Section 2 de-
scribes the facial feature extraction. Section 3 ex-
plains the facial emotion classification using default
ARTMAP, and the classification results follow in Sec-
tion 4. Finally, the concluding remarks are presented
in Section 5.
2 FACIAL FEATURE
EXTRACTION
Recent studies using audiovisual data similar to ours
have shown that Face Animation Parameters (FAP)
can be an effective feature set choice for extraction of
emotional information even when the user is speaking
(Kim et al., 2013; Mower et al., 2011).
”A Face Animation Parameter (FAP) is a com-
ponent of the MPEG-4 International Standard
developed by the Moving Pictures Experts
Group. FAP represent displacements and rota-
tions of the feature points from the neutral face
position, which is defined as: mouth closed,
eyelids tangent to the iris, gaze and head ori-
entation straight ahead, teeth touching, and
tongue touching teeth” (Petajan, 2005).
2.1 Motion Capture and FAP
As FAP are distances between two points on a face,
a prerequisite to calculating FAP is the availability of
the motion capture data for the corresponding points
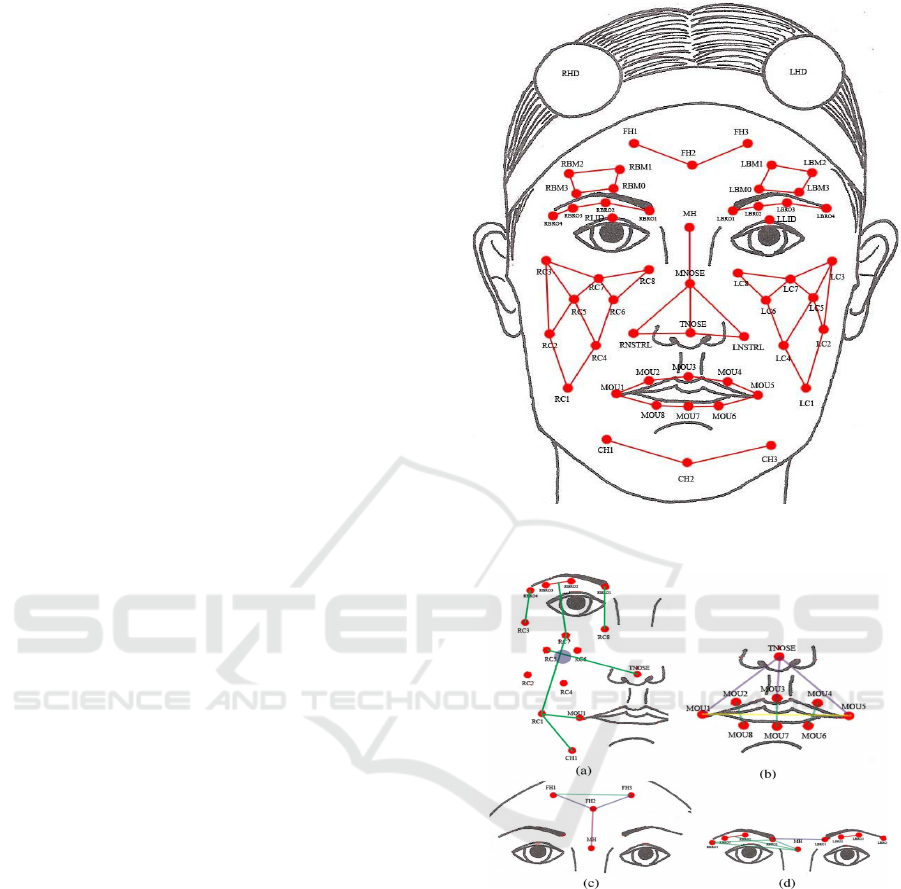
on the face. Fig. 2 demonstrates the motion capture
points available in the database. Combining the infor-
mation from Fig. 1 and Fig. 2, desirable FAP can be
calculated. Our set of 30 FAP is similar to the ones
used by (Kim et al., 2013; Mower et al., 2011), with
the exception of FAP corresponding the mouth open-
ings. These FAP are shown in Fig. 3.
Figure 2: Visual representation of the motion capture pints
on the face.
Figure 3: Visual representation of the FAP used for facial
emotion recognition.
2.2 Facial Features based on FAP
After obtaining the required FAP, the next step is to
generate the feature vector for facial emotion classifi-
cation. Ninety (x,y,z-components of each of the FAP)
FAP values are extracted from each frame of the au-
diovisual segment. The selected features for the au-
diovisual segment consists of means, standard devi-
ations, ranges, upper and lower quartiles, and quar-
tile ranges for all 90 values over the entire segment.
Consequently, the net feature vector consists of 540
features for each audiovisual segment.
2.3 Facial Feature Normalization
The database has multiple actors and they all have dis-
tinct facial features and sizes, which means that the
base values for their FAP are different. Therefore, the
FAP features need to be normalized to minimize the
effect of base value variation among different faces.
We use z-normalization for this purpose. Mean and
standard deviation for each face were calculated over
the entire spectrum of emotions expressed by the cor-
responding actor. These mean and standard deviation
values for each face are used to calculate feature val-
ues in terms of z-scores using:
FAPFeat
zscores
=
(FAPFeat − µ
FAPFeat
)
σ
FAPFeat
, (1)
where FAPFeat are the FAP-based features, µ
FAPFeat
and σ
FAPFeat
are the means and standard deviations,
respectively, of the features across the entire spectrum
of emotions.
2.4 Facial Feature Scaling
The classifier for facial emotion recognition is a
default ARTMAP neural network. Since default
ARTMAP is a variant of fuzzy ARTMAP, the inputs
to the network need to be scaled to a zero-to-one
range. (2) is used for scaling.
FAPFeat
scld
=
(FAPFeat
zscores
− FAPFeat
min
)
(FAPFeat
max
− FAPFeat
min
)
, (2)
where FAPFeat
max
and FAPFeat
min
are the maximum
and minimum values, respectively.
3 FACIAL EMOTION
CLASSIFICATION USING
ARTMAP
Even though FAP based features have been shown to
be quite effective for facial emotion, there are some
hindering issues in the choice of classifiers. These
issues stem from the way in which the feature vec-
tors are formulated. A common practice is to ac-
cumulate FAP over a segment or an utterance, and
then formulate a feature vector by applying statisti-
cal operations over the accumulated FAP. The statis-
tical operations applied in this case are: mean, stan-
dard deviation, range (max-min values), upper quar-
tile, lower quartile, and quartile range. This results
in relatively large feature vectors with a fewer train-
ing instances because each instance is sampled over
utterances/segments containing hundreds of frames.
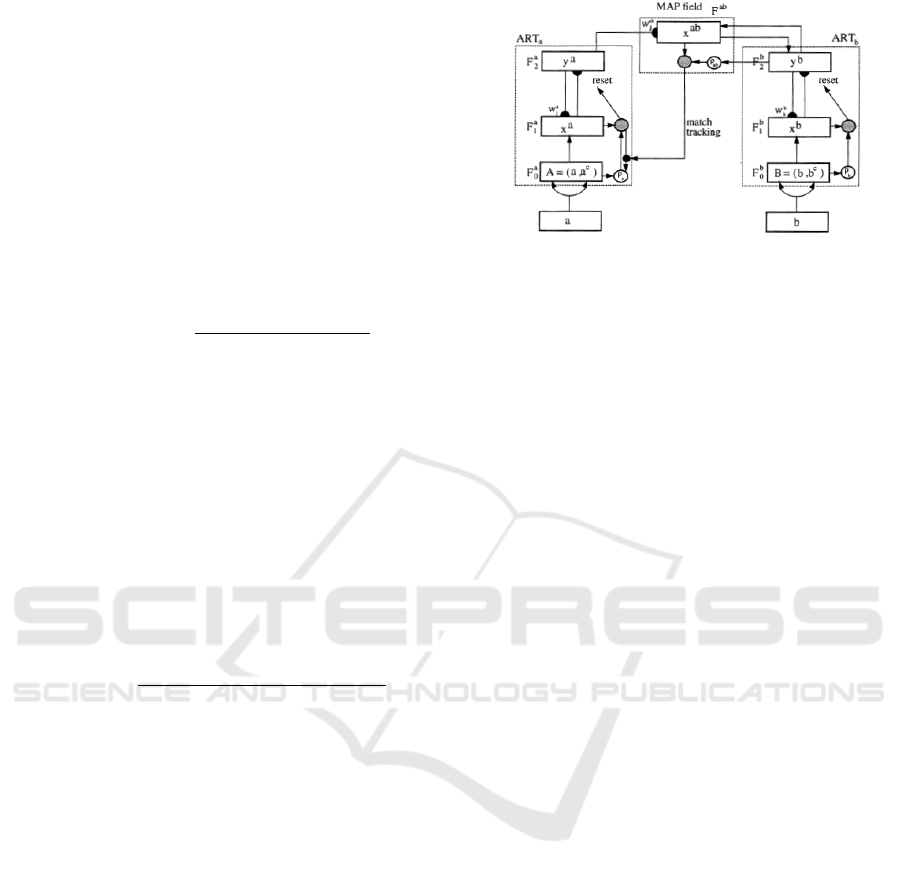
Figure 4: The architecture of Fuzzy ARTMAP.
Therefore, fewer training instances (<3000) with a
feature vector size of over 500 presents a particular
case of ’curse of dimensionality’. This issue has been
tackled in research by coupling a classifier (Neural
network or SVM) with a feature dimensionality re-
duction implemented through Information Gain (IG),
Principal Feature Analysis (PFA) , Deep Belief Net-
work (DBN), etc (Kim et al., 2013).
However, in this research, we opted for a
Fuzzy ARTMAP classifier, Default ARTMAP clas-
sifier specifically. We chose ARTMAP because
it enables fast learning by simultaneously clus-
tering/categorizing and classifying. Additionally,
ARTMAP is plastic while maintaining spasticity, i.e.,
it can learn new information without forgetting what
it already has learnt. Before explaining the De-
fault ARTMAP classifier that we employed in this
research, the following subsection will provide some
back ground on Fuzzy ARTMAP, in particular, and
Fuzzy Adaptive Resonance Theory (ART).
3.1 Fuzzy ARTMAP
Fuzzy ARTMAP, or supervised ART, is a combina-
tion of two ART neural networks that are connected
through a MAP field (shown in Fig. 4) (Carpenter
et al., 1991b). The first Fuzzy ART neural network,
ART
a
, categorizes the inputs, while the second one,
ART
b
, categorizes the output class labels. The associ-
ation between the two categorizations is mapped via
a MAP field, hence the name ARTMAP.
Fuzzy ART implements fuzzy logic into ART’s
pattern recognition, thus enhancing generalizability
(Carpenter et al., 1992). The first step in Fuzzy ART
learning is complement coding. This is done by con-
catenating fuzzy complement of the input at the end
of the input vector:
A = (a|a
c
). (3)
After complement coding the inputs, Fuzzy ART is
initialized by categorizing the first input and initializ-
ing the weights and vigilance parameter, ρ. The vigi-
lance parameter controls the level of fuzzy similarity
acceptable to be categorized into the same category
node. The higher ρ means stricter categorization and
hence more category nodes. Once the Fuzzy ART has
been initialized, the next input is selected and the ac-
tivation signals to the committed nodes:
T
j
= |A ∧ w
j
| + (1 − α)(M − |w
j
|). (4)
Then, the activated nodes are checked for template
matching, or resonance, using the following criterion:
ρ|A| − |x| ≤ 0, (5)
where x = A ∧ w
j
. If there is a match, the weights are
updated using:
w
j
= (1 − β)w
j
+ β(A ∧ w
j
), (6)
where β is the learning rate. On the other hand, if
there is no match, a new new node j associated to the
input is created:
w
j
= A. (7)
In a Fuzzy ARTMAP, as well as a Default
ARTMAP, the same ART categorization and learn-
ing scheme is used. However, in the supervised case,
the vigilance parameter for the categorization is con-
trolled via the labels coming through the ART
b
and
MAP field. Further explanation on that follows in the
next subsection.
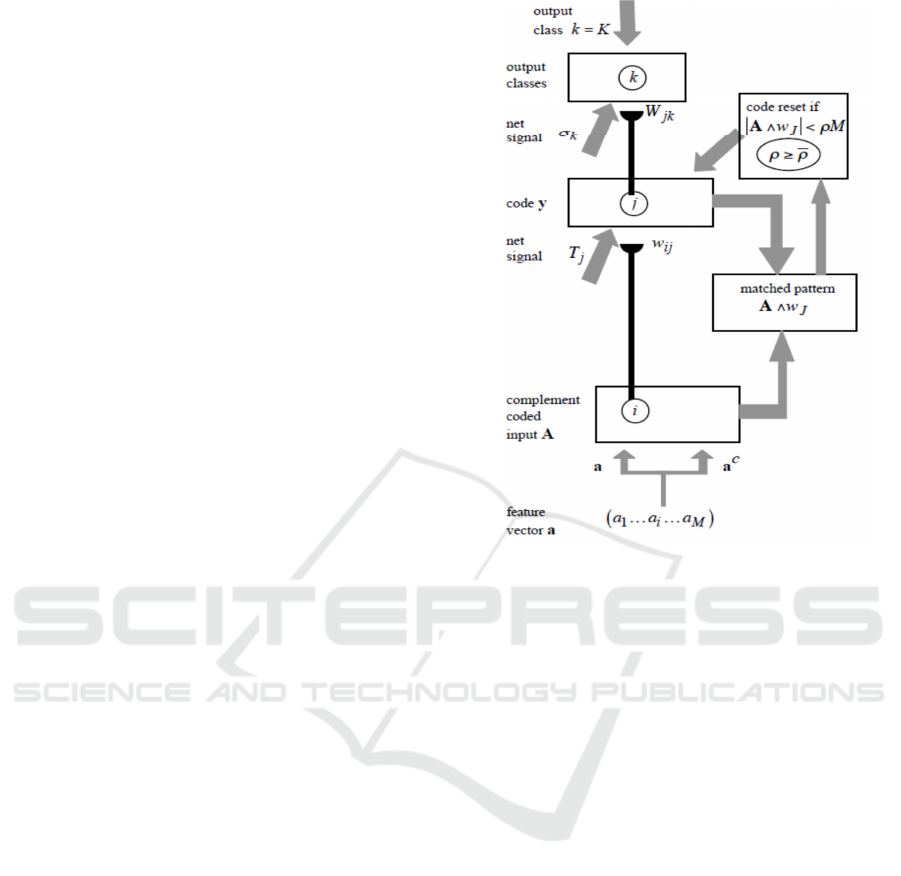
3.2 Default ARTMAP
Default ARTMAP was used as the facial emotion
classifier. The default ARTMAP (Amis and Carpen-
ter, 2007; Carpenter and Gaddam, 2010) is a fuzzy
ARTMAP with distributed coding for testing. Instead
of winner-takes-all (WTA) testing in the typical fuzzy
ARTMAP, the default ARTMAP employs the cod-
ing field activation method (CAM) (Carpenter et al.,
1991a) for distributed testing. The training process
for default ARTMAP is trained as follows (Fig. 5
(Amis and Carpenter, 2007)):
1. Complement code M-dimensional training set
feature vectors, a, to produce 2M-dimensional in-
put vectors, A
2. Select the first input vector, A, with associated ac-
tual output class, K.
3. Set initial weights.
4. Set vigilance, ρ, to its baseline value and reset the
code: y = 0.
5. Select the next input vector A, with associated ac-
tual output class, K.
6. Calculate signals to committed coding nodes
T
j
= |A ∧ w
j
| + (1 − α)(M − |w
j
|) (8)
Figure 5: Default ARTMAP notation.
7. Sort the committed coding nodes, N, in descend-
ing order of T
j
values.
8. Search for a coding node, J, that meets the match-
ing criterion and predicts the correct output class,
K.
9. For the next sorted node that meets matching cri-
teria, set y
J
= 1(W TA)
10. If the active code, J, predicts the actual output
class, K. Otherwise, increase the ρ to add a new
node and redo initializing and matching.
11. Update coding weights and go to 4.
After the default ARTMAP is trained, the testing is
performed in the following steps:
1. Complement code M-dimensional training set
feature vectors, a, to produce 2M-dimensional in-
put vectors, A
2. Select the first input vector.
3. Reset the code: y = 0.
4. Calculate signals to committed coding nodes
T
j
= |A ∧ w
j
| + (1 − α)(M − |w
j
|) (9)
5. Let Λ − {λ − 1...C : T
λ
> αM} and Λ
0
− {λ −
1...C : T
λ
− M} = {λ− 1...C : w
j
= A}.
6. Apply Increased Gradient (IG) CAM Rule to cal-
culate y
j
(Fig. 6).
λ
λ
λ
λ
λ
1
j
C
y
1/ ( )
1/ ( )
j
j
MT
y
M
T
'
'
Figure 6: Default ARTMAP testing using Increased gradi-
ent CAM.
7. Calculate distributed output predictions: σ −
∑
C
j=1
W
jk
y
j
8. Predict output classes from σ
k
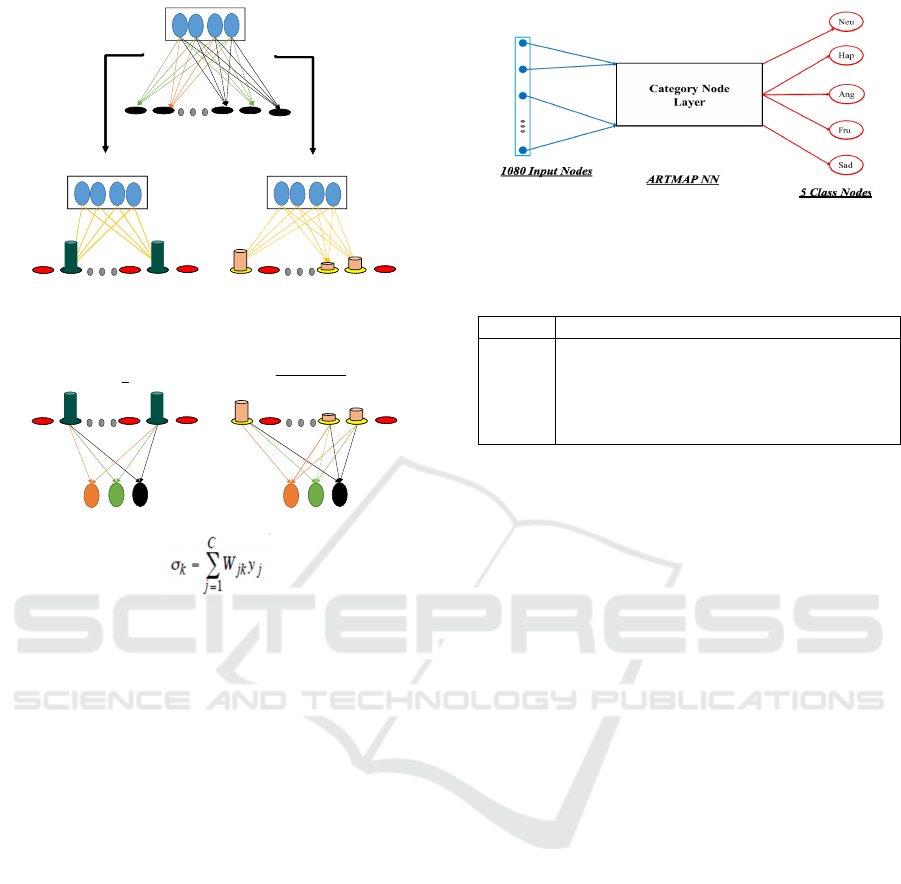
3.3 Facial Emotion Recognition using
default ARTMAP
Default ARTMAP was used as the classifier for Fa-
cial emotion recognition. The configuration of the
ARTMAP network is shown in Fig. 7.
The Default ARTMAP was trained using four-fold
cross validation using 2442 training instances from
eight actors/speakers (4 males and 4 females). The
followings are the configuration parameters used:
• Learning rate: 0.7
• Choice parameter, α: 0.27
• Base vigilance: 0.2
• CAM rule parameters: 1
After Default ARTMAP for facial parameters was
trained, we got a facial emotion ARTMAP classifier
with the following configuration: 1080 input nodes,
1112 category nodes, and five class nodes correspond-
Figure 7: Configuration of the trained ARTMAP classifier
for Facial emotion recognition.
Table 1: Confusion matrix for the FAP-based facial emotion
classifier.
Neutral Happy Angry Frust. Sad
Neutral 0.529 0.059 0.059 0.235 0.118
Happy 0.019 0.830 0.057 0.075 0.019
Angry 0.036 0.071 0.5 0.393 0
Frust. 0.024 0.072 0.241 0.590 0.072
Sad 0.027 0.108 0.054 0.243 0.568
ing to five emotion classes: neutral, happiness, anger,
frustration, and sadness.
4 TESTS AND RESULTS
After training, the classifier was tested using the train-
ing data from the remaining two actors (one male, one
female) in the IEMOCAP database. In other words,
the ARTMAP was trained using eight of the 10 ac-
tors in IEMOCAP and tested using the other two.
The classification results showed a five class classi-
fication accuracy of over 68%. The confusion ma-
trix for the Default ARTMAP body language classi-
fier is shown in Table 1. As evident from the confu-
sion matrix, the most frequent instances of misclassi-
fication/confusion occurred between angry and frus-
trated. This confusion is understandable as these two
emotions are often not easily distinguishable even for
humans.
We also compared our results with existing simi-
lar researches on IEMOCAP. These approaches used
support vector machines (SVM) preceded by feature
dimension reduction. Table 2 shows comparative re-
sults of default ARTMAP against the following:
• SVM with Reynolds Boltzman Machine (RBM-
SVM) (Shah et al., 2014)
• SVM with Principal Feature Analysis (PFA-
SVM) (Kim et al., 2013)
• SVM with Deep Belief Networks (DBN-SVM)
(Kim et al., 2013)
• Emotion profiled SVM (EP-SVM), where each
one-vs-all emotion classifiers used a feature vec-

Table 2: Comparative Results on IEMOCAP using FAP-
based features.
Classification approach Accuracy
RBM-SVM (Shah et al., 2014) 60.71%
PFA-SVM (Kim et al., 2013) 65%
DBN-SVM (Kim et al., 2013) 68%
EP-SVM (Mower et al., 2011) 71%
Default ARTMAP 72.2%
tor profiled for that particular emotion (Mower
et al., 2011)
These results are for four class (neutral, happy,
anger, as sadness) classification as those researches
used four class classification. It is evident from the
table that our approach gives the best results for FAP-
based classifier on IEMOCAP data set. Furthermore,
(Mower et al., 2011) and (Kim et al., 2013) used both
facial and vocal features. However, since they had
a similar set of facial features and they tested their
approaches on IEMOCAP, we used their results for
comparison as well.
5 CONCLUSION AND FUTURE
WORK
In this paper, we proposed facial emotion recognition
using a default ARTMAP classifier. The proposed
classification scheme along with the FAP-based fea-
tures was shown to be an effective facial emotion clas-
sifier in the presence of speech. The results show that
our approach also yielded better results than the exist-
ing state-of-the-art on IEMOCAP database.
In future, we plan to integrate our emotion recog-
nition with real time perception. Furthermore, we
also intend to investigate other configurations of
ARTMAP involving distributed training along with
the distributed testing used in this paper.
ACKNOWLEDGEMENT
This work was supported by the ICT R&D program
of MSIP/IITP. [2016-0-00563, Research on Adaptive
Machine Learning Technology Development for In-
telligent Autonomous Digital Companion]
REFERENCES
Amis, G. P. and Carpenter, G. A. (2007). Default artmap
2. In 2007 International Joint Conference on Neural
Networks, pages 777–782.
Busso, C., Bulut, M., Lee, C.-C., Kazemzadeh, A., Mower,
E., Kim, S., Chang, J. N., Lee, S., and Narayanan,
S. S. (2008). Iemocap: interactive emotional dyadic
motion capture database. Language Resources and
Evaluation, 42(4):335.
Carpenter, G. A. and Gaddam, S. C. (2010). Biased art: A
neural architecture that shifts attention toward previ-
ously disregarded features following an incorrect pre-
diction. Neural Networks, 23(3):435 – 451.
Carpenter, G. A., Grossberg, S., Markuzon, N., Reynolds,
J. H., and Rosen, D. B. (1992). Fuzzy artmap: A neu-
ral network architecture for incremental supervised
learning of analog multidimensional maps. Trans.
Neur. Netw., 3(5):698–713.
Carpenter, G. A., Grossberg, S., and Reynolds, J. H.
(1991a). Artmap: Supervised real-time learn-
ing and classification of nonstationary data by a
self-organizing neural network. Neural Networks,
4(5):565 – 588.
Carpenter, G. A., Grossberg, S., and Rosen, D. B. (1991b).
Fuzzy art: Fast stable learning and categorization of
analog patterns by an adaptive resonance system. Neu-
ral Networks, 4(6):759 – 771.
Hirota, K. and Dong, F. (2008). Development of mascot
robot system in nedo project. In Intelligent Systems,
2008. IS ’08. 4th International IEEE Conference, vol-
ume 1, pages 1–38–1–44.
Kim, Y., Lee, H., and Provost, E. M. (2013). Deep learn-
ing for robust feature generation in audio-visual emo-
tion recognition. In IEEE International Conference on
Acoustics, Speech and Signal Processing (ICASSP).
Li, H., Lin, Z., Shen, X., Brandt, J., and Hua, G. (2015a).
A convolutional neural network cascade for face de-
tection. In The IEEE Conference on Computer Vision
and Pattern Recognition (CVPR).
Li, W., Li, M., Su, Z., and Zhu, Z. (2015b). A deep-learning
approach to facial expression recognition with candid
images. In Machine Vision Applications (MVA), 2015
14th IAPR International Conference on, pages 279–
282.
Liu, P., Han, S., Meng, Z., and Tong, Y. (2014). Facial
expression recognition via a boosted deep belief net-
work. In The IEEE Conference on Computer Vision
and Pattern Recognition (CVPR).
Liu, Z.-T., Min, W., Dan-Yun, L., Lue-Feng, C., Fang-Yan,
D., Yoichi, Y., and Kaoru, H. (2013). Communi-
cation atmosphere in humans and robots interaction
based on the concept of fuzzy atmosfield generated
by emotional states of humans and robots. Journal of
Automation, Mobile Robotics and Intelligent Systems,
7(2):52–63.
Mariooryad, S. and Busso, C. (2016). Facial expression
recognition in the presence of speech using blind lex-
ical compensation. IEEE Transactions on Affective
Computing, 7(4):346–359.
Mower, E., Mataric, M. J., and Narayanan, S. (2011). A
framework for automatic human emotion classifica-
tion using emotion profiles. IEEE Transactions on Au-
dio, Speech, and Language Processing, 19(5):1057–
1070.

Petajan, E. (2005). MPEG-4 Face and Body Animation
Coding Applied to HCI, pages 249–268. Springer US,
Boston, MA.
Rozgi, V., Ananthakrishnan, S., Saleem, S., Kumar, R., and
Prasad, R. (2012). Ensemble of svm trees for mul-
timodal emotion recognition. In Signal Information
Processing Association Annual Summit and Confer-
ence (APSIPA ASC), 2012 Asia-Pacific, pages 1–4.
Shah, M., Chakrabarti, C., and Spanias, A. (2014). A multi-
modal approach to emotion recognition using undi-
rected topic models. In 2014 IEEE International Sym-
posium on Circuits and Systems (ISCAS), pages 754–
757.
