
A Discourse Analysis
Determining the Storyboard Assets of Indonesian Environmental Public Service
Animation Scripts
Fathimah Salma Zahirah
Department of Linguistics,Universitas Pendidikan Indonesia, Bandung, Indonesia
f
s.zahirah90@gmail.com
Keywords: Script, Storyboard, Assets, Content Words, Syntax, Discourse Analysis, Mood.
Abstract: An animation can be categorized as a good media if it is created through an elaborative storyboard-making
procedure. The most important thing in the storyboard production is making the items (assets) that will be
animated based on the script. In other words, the script must contain some content words (e.g. bed, king, table,
etc.) that will be the basics on shaping the assets. Therefore, the advanced scanning process of the content
words needs to be taken into account in order to make the storyboard-making process quicker. Based on this
background, this research paper elaborates a syntactic discourse analysis, in which a mood classification as a
systemic functional grammar tool also plays a role in order to find the content words from the script. After
examining the script in that manner, the content words were interpreted as visual products. This research paper
employed ten 2017 Indonesian environmental public service animation scripts as the data. The further attempt
will lead into assessing the possibility of making a program system for creating assets visualization.
1 INTRODUCTION
Halliday (Paltridge, 2006) argues that a written
discourse tends to be more lexically dense than a
spoken discourse. Lexical density refers to the ratio
of content words to grammatical, or function words,
within a clause. Content words include nouns and
verbs while grammatical words include items such as
prepositions, pronouns, and articles. There is also a
high level of nominalization in written texts where
actions and events are presented as nouns rather than
as verbs. Written texts also typically include longer
noun groups than spoken texts.
In that sense, a public service script can be
categorized into a persuasive spoken discourse. This
kind of discourse tends to have statement sentences.
Even though it is written, the sentence structure on the
script is more into that of the spoken one. Aside from
being complex, there are more simple sentences
found on the script. It leads to an assumption that
some sentences may lack of subjects because the
nature of the script tends to employ a lot of imperative
sentences; since it is a spoken discourse.
Regarding the presence of subjects, Gerot and
Wignell (1994) state that the mood element –Subject
+ Finite– carries the burden of the clause as an
interactive event. Thus, it is plausible that the
sentences contain no mood. The mood system on the
animation script is important for determining which
scene that should be highlighted. Moreover, what
kind of effects and features are suitable for the
animation assets are also contextualized through the
mood. This consideration plays crucial matter
whether the content of the script should have a
concrete visual form or stay as texts only. Hence, not
only the syntactic feature of the sentences should be
taken into account but also the functional one.
In relation to the script representation, Hart (2008)
states that the storyboard is the premiere
preproduction, pre-visualization tool designed to give
a frame-by-frame, shot-by-shot series of sequential
drawings adapted from the script. They are concept
drawings that illuminate and augment the script
narrative and enable the entire production team to
organize all the complicated action required by the
script before the actual animating is done to create the
correct look for the finished motion.
Based on that background, this paper will discuss
the possibility of creating a program system that can
denote the content words automatically. Mason and
Charniak (2012) created a system for connecting
corpus to images based on Natural Language
Processing Systems. The system can be more precise
Zahirah, F.
A Discourse Analysis - Determining the Storyboard Assets of Indonesian Environmental Public Service Animation Scripts.
DOI: 10.5220/0007163501450148
In Proceedings of the Tenth Conference on Applied Linguistics and the Second English Language Teaching and Technology Conference in collaboration with the First International Conference
on Language, Literature, Culture, and Education (CONAPLIN and ICOLLITE 2017) - Literacy, Culture, and Technology in Language Pedagogy and Use, pages 145-148
ISBN: 978-989-758-332-2
Copyright © 2018 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
145

if it is engaged with Moeljadi’s (2017) Lexical
Functional Grammar Treebank (JATI). However,
none of both focuses on a certain type of text and
image.
2 METHODOLOGY
There are ten Indonesian scripts taken as the data. The
scripts were first analysed based on the types of the
sentences by using the mood framework. The content
words found were classified into denotative and
connotative interpretation. The verbs with affixes
were interpreted based on their lexemes. Thus, the
sentences that contain a lot of function words,
especially the one with interpersonal sense, would be
regarded as a merely text when they are realized
through the storyboard–did not need to be visualized.
2.1 Types of the Sentences
The nature of a persuasive text is to give information
and make the readers aware of their current actions
regarding the text. This type of text uses a lot of
statements to justify the purpose. The result shows
that seven scripts use statement sentences
productively (52% approximately). Meanwhile, the
other three scripts tend to be more commanding (50%
approximately).
2.2 Mood Analysis
The mood analysis, as one of the structural
framework, gives insight to the importance of
interpreting a word in relation to its context. Chaer
(2006) states that a language is a connected system,
in which each of its elements –sounds, words, etc.–
does not have any validity except within the
structured relation. However, the interpretation of the
word itself can be seen from dyadic perspective, as
proposed by Saussure (Hoed, 2014): “the relation
between sign can be syntagmatic and paradigmatic”.
Hence, the result of the mood analysis will be
connected to the interpretation of the content words
later on.
The data show that there are 31.48% of mood
elements found in the scripts. The scripts which have
more statement sentences are likely to have more
mood aspects. In contrast, the other scripts which
contain more command sentences are likely to have
more residues. Although there is such diversity, the
amounts of content words (noun, noun phrase, verb,
and verb phrase) are randomly varied within each
script.
2.2.1 Mood
In general, mood consists of a subject and finite. The
former has the higher authority in creating mood for
a static visualization of a noun. Meanwhile, the latter
is more applicable for determining certain temporal
nuances when it comes to the animated version of a
noun. If the subject is a content word (whether it is
followed by finite or not), it will be necessary to
contrast it from the other elements when it is
represented in a storyboard.
Based on the data, the main mood in the scripts is
building the awareness of maintaining our
environment. The elements that should be highlighted
visually are mostly ‘sampah (garbages)’ which occur
48 times.
2.2.2 Residue
Residues of the sentences also play important role in
interpreting the script. The residue contents help the
storyboard artist decide which elements that should
be put as the background or the visual complements.
For example, in “Sampah yang dibakar malah
melepaskan zat-zat yang berbahaya!“, the residue is
“zat-zat yang berbahaya (dangerous substances)”.
This means, the dangerous substances will have a
minor appearance.
Furthermore, the data also indicate that the more
command sentences a script has, the less likely the
intended information will be well-received.
2.2.3 Interpersonal Content
The interpersonal content may not be concretely
visualized. However, it creates a friendly tone for a
public service animation. This content is likely to be
represented typographically or via voice over. If the
script has a mascot, the interpersonal content can also
be appeared in one scene with it.
The data show that besides employing question
sentences to build interpersonal relationship with the
audiences, there are also some pragmatic fillers such
as ‘nah…(well)’, ‘jadi…(so)’, and ‘dan…(and)’.
Moreover, some of the interpersonal contents found
in the data are put separately from the previous
sentence. They tend to indicate transitions.
2.2.4 Content Words
There are 19.34% of content words found in the
scripts, from 736 total words. The amount of content
words is not necessarily positive with the amount of
the total words. It means, the script can have a lot of
CONAPLIN and ICOLLITE 2017 - Tenth Conference on Applied Linguistics and the Second English Language Teaching and Technology
Conference in collaboration with the First International Conference on Language, Literature, Culture, and Education
146
messages but they are represented through the same
assets.
Moreover, even though noun phrase and verb
phrase are syntactically regarded as content words,
there might be a problem to represent the verb phrase
in a storyboard. Especially, the one contains an action
process. Thus, most of the storyboard assets are likely
derived from noun phrases, even only nouns as
lexemes.
2.3 Determining Content Words
Visualization
The possibility of making image annotation based on
a text becomes a promising project for those who
work in an animation field. The previous studies from
Mason and Charniak (2012) and Moeljadi (2017)
already show that the idea of making contextual
image annotation is plausible. However, there are
some considerations that need to be assessed.
2.3.1 Scheme
The most important thing is one should decide which
system can perform the image annotation faster. It is
likely that a system of text scanning should employ
texts as the data bank (corpus). Moreover, the system
should also have the main library of lexical
definitions as to detect the lexeme of a morphemic
word. The crucial matter will arise when the system
should relate the targeted word with its context. The
following discussion will elaborate more on how to
scan content words as efficient as possible. The
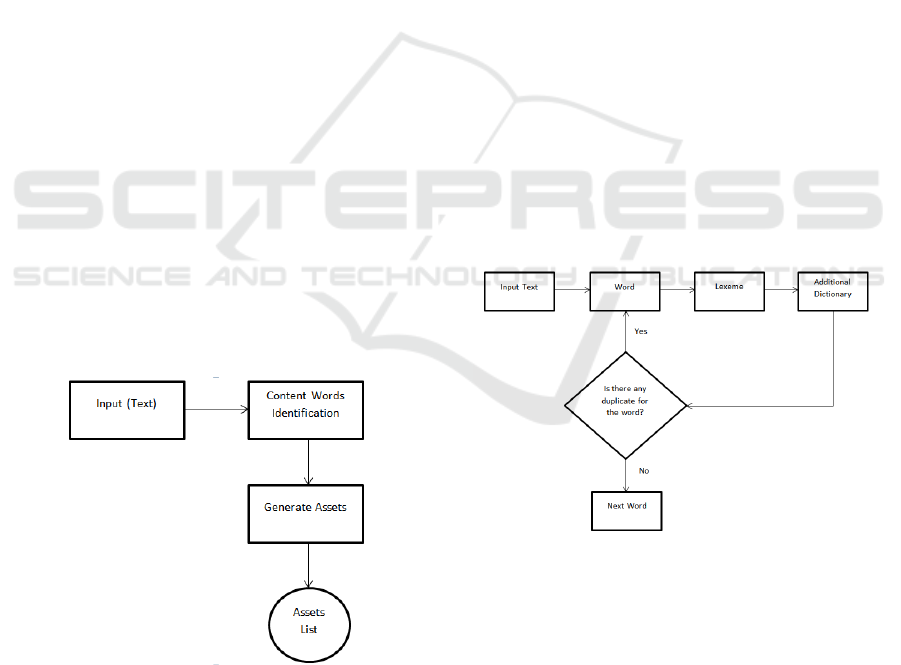
scheme of the system can be seen on Figure 1.
Figure 1: The System Scheme.
2.3.2 Text as the Input
The system should be able to detect content words
from the script that will be represented as assets on
the storyboard. If there is any Indonesian slang term,
the system should also be able to recognize it. Since
the system will only focus on words, there should be
a special treatment for numbers. It is necessary if the
numbers are represented as assets or they function as
content word adjectives (e.g. in “Denda mulai dari Rp
250.000,00”; not only ‘denda (fine)’ but also the
amount of the money is considered as a content
word).
2.3.3 Content Words Identification
The identification of Indonesian content words will
be easy if the lexeme is already stored in the metadata
of the system. However, the problem will occur if the
content words have complementary elements which
can only be tracked based on the context. Thus, the
best option for the content words fast scanning
system, in relation to a storyboard, is to determine the
assets on the lexemes. Even though it is possible to
create the contextual interpretation, there will be an
obstruction of the individual creativity.
Relying on that consideration, the safest option is
denoting the noun (without the verb) through the most
common social representation. Nevertheless, such
system still will be helpful because it decreases the
time consumption when scanning the scripts
manually for a production purpose. The content
words identification process can be seen on Figure 2
Figure 2: The Content Words Identification Process.
2.3.4 Stemming
The morpho-syntactic analysis will be the lead for
shortening the morphemic content word into its
lexeme. The reasonable process for that purpose is
word stemming. The morpheme(s) attached to the
word will be eliminated in order to find the lexeme
form. The most suitable model for this operation is
A Discourse Analysis - Determining the Storyboard Assets of Indonesian Environmental Public Service Animation Scripts
147
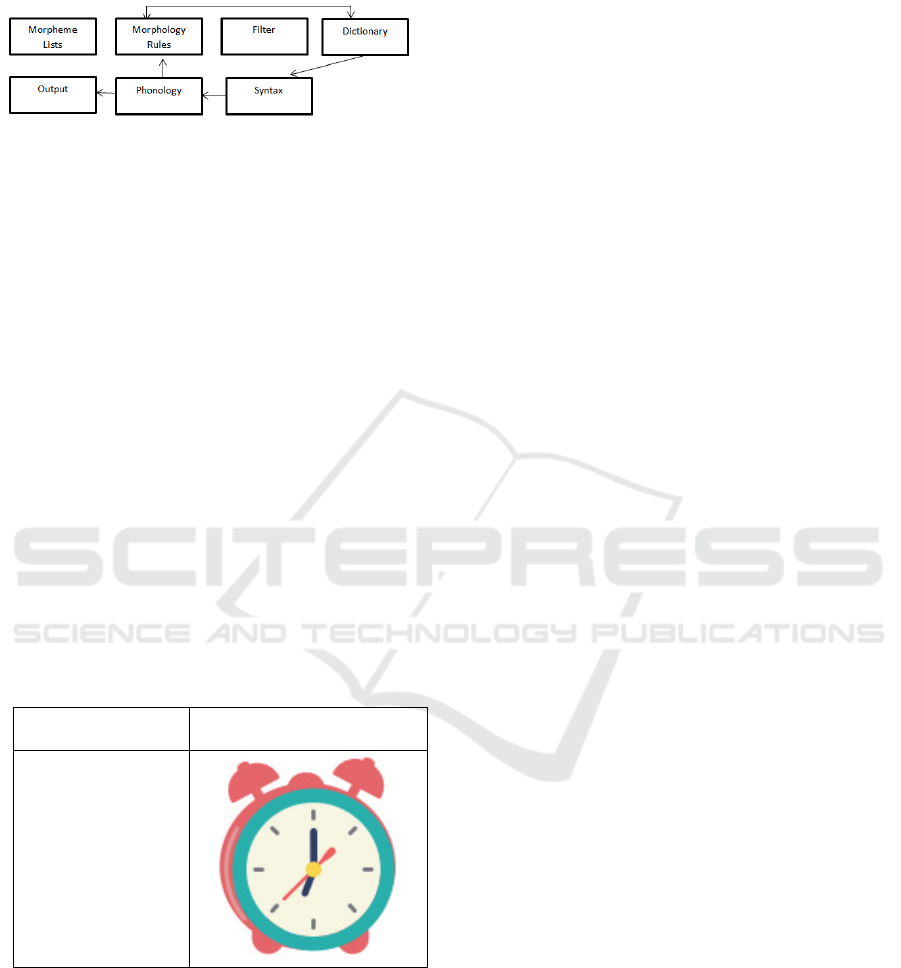
Halle’s morphological organization in Ba’dulu and
Herman (2005) as shown in Figure 3.
Figure 3: Halle’s Morphological Organization.
In order to avoid an overstemming process, the
dictionary put in the metadata should define the
words that may seem morphemic but indeed they are
lexemes. For example, the word ‘penyu (tortoise)’ is
not derived from ‘peny-u’. Moreover, a reverse logic
of a morphemic word creation should be taken into
account for eliminating allomorph. Therefore, the
system will give more credible lexeme forms. For
example, the word ‘menyapu’ has ‘sapu’ as the
lexeme, not ’nyapu’.
2.3.5 Treating Repeated Words
The repeated words found in the scripts should not be
presented more than one time from the text extraction.
Thus, there should be another ‘dictionary’ that can
add the scanned lexemes and make the system skip
the same lexemes which occur twice or more later on
(the process can be seen on Figure 2).
The system presentation sample can be seen on
Table 1.
Table 1: Content Words System Presentation Sample.
Extracted Content
Words
Visual Representation
Jam
3 CONCLUSIONS
It can be concluded that the mood analysis can help
interpreting the visual aspect of content words. Even
though it might be difficult to connect the functional
aspect to the syntactic aspect of a word in a program
system, it is still possible to employ those notions
together for determining the content words
visualization.
4 RECOMMENDATION
The system discussed in this paper is still a model. It
is recommended for the next researcher to develop the
prototype which is applicable for the storyboard-
making production. Other visual variables such as the
tone of reference and the colour schemes guidelines
for the storyboard also need to be considered.
ACKNOWLEDGEMENTS
The author would like to thank Bonbin Studio for
giving a privilege to analyse the environmental public
service animation scripts. Many regards are also sent
to Syarifuddin and Aria Dhanang for the discussion.
REFERENCES
Chaer, A., 2006. Tata Bahasa Praktis Bahasa Indonesia,
RINEKA CIPTA. Jakarta, 2
nd
edition.
Ba’dulu, A.M. and Herman, 2005. Morfosintaksis,
RINEKA CIPTA. Jakarta, 1
st
edition.
Gerot, L., Wignell, P., 1994. Making Sense of Functional
Grammar: an Introductory Workbook, Gerd Stabler.
New South Wales.
Hart, J., 2008. The Art of the Storyboard: A filmmaker’s
Introduction, Elsevier. United States of America, 2
nd
edition.
Hoed, B.H., 2014. Semiotik & Dinamika Sosial Budaya,
Komunitas Bambu. Depok, 3
rd
edition.
Mason, R., Charniak, E., 2012. Apples to Oranges:
Evaluating Image Annotations from Natural Language
Processing Systems. In 2012 Conference of the North
American Chapter of the Association for
Computational Linguistics: Human Language
Technologies. Association for Computational
Linguistics.
Moeljadi, D., 2017. Building JATI: A Treebank for
Indonesian. Proceedings of Atma Jaya Conference on
Corpus Studies. Atma Jaya.
Paltridge, B., 2006. Dicourse Analysis: an Introduction,
Continuum. New York, 1
st
edition.
CONAPLIN and ICOLLITE 2017 - Tenth Conference on Applied Linguistics and the Second English Language Teaching and Technology
Conference in collaboration with the First International Conference on Language, Literature, Culture, and Education
148
