
Malicious PDF Documents Detection using Machine Learning
Techniques
A Practical Approach with Cloud Computing Applications
Jose Torres and Sergio De Los Santos
Telef
´
onica Digital Espa
˜
na, Ronda de la Comunicaci
´
on S/N, Madrid, Spain
Keywords:
PDF, Malware, JavaScript, Machine Learning, Malware Detection.
Abstract:
PDF has been historically used as a popular way to spread malware. The file is opened because of the confi-
dence the user has in this format, and malware executed because of any vulnerability found in the reader that
parses the file and gets to execute code. Most of the time, JavaScript is involved in some way in this process,
exploiting the vulnerability or tricking the user to get infected. This work aims to verify whether using Ma-
chine Learning techniques for malware detection in PDF documents with JavaScript embedded could result in
an effective way to reinforce traditional solutions like antivirus, sandboxes, etc. Additionally, we have devel-
oped a base framework for malware detection in PDF files, specially designed for cloud computing services,
that allows to analyse documents online without needing the document content itself, thus preserving privacy.
In this paper we will present the comparison results between different supervised machine learning algorithms
in malware detection and a overall description of our classification framework.
1 INTRODUCTION
Since the PDF format creation by Adobe in 1994,
malformed PDF documents to compromise systems
(exploiting vulnerabilities in the reader), has been a
very popular attack vector and still is. Specifically,
most of significant attacks related with PDF format
have been associated with vulnerabilities in Adobe
software such as Adobe Reader and Adobe Acrobat.
According to several studies, in 2009, approximately
52.6% of targeted attacks used PDF exploits and by
2011, it got to 76%.
PDF is a very popular and trusted extension, while
Adobe Reader is the most used program for opening
these kind of files. These factors encourage attackers
to research and seek for vulnerabilities and new ways
of creating exploits that will execute arbitrary code
when opened with this specific software. There are
some vulnerabilities examples that (even today) are
popular as an attack vector, like a vulnerability found
in 2008 in Adobe (Adobe, 2008) that would allow the
attacker to execute arbitrary code in Adobe Reader
and Acrobat 8.1.1 and earlier versions. The extended
use of this type of documents, especially for docu-
ment sharing via email, makes it possible form mal-
ware to spread effectively. Users are prone to open re-
ceived PDF files and interact with the document with-
out noticing any associated danger, as it would occur
with executable files.
JavaScript presence into PDF documents provides
extra functionalities to the document and makes it in-
teractive. An example of that extra features are forms,
which usually include check-boxes, text inputs, action
buttons, etc. that provides the document with the typ-
ical behavior of an application. Since Acrobat Reader
included support for JavaScript (Wikipedia, 2017)
(Version 3.02, year 1999) the use of JavaScript in PDF
files to execute malicious actions has been very pop-
ular, even prior to the inclusion of PDF format as an
Open Standard (ISO/IEC 32000-1:2008). Sometimes,
the malicious JavaScript code into the document is
not the final malware itself, but rather a mechanism to
download and execute an instance of certain malware
or even a helping code to exploit a certain vulnera-
bility in the reader. Although since at least version
6, JavaScript can be disabled in Adobe Reader, the
risks of JavaScript code included in PDF format has
been historically advised: In 2006 David Kierznowski
provided sample PDF files illustrating JavaScript vul-
nerabilities. And even (but less frequent) without us-
ing JavaScript: In 2010, Didier Stevens was able to
execute arbitrary code from a PDF file processed by
Adobe Reader without even exploiting anything but
the PDF specifications themselves.
Torres, J. and Santos, S.
Malicious PDF Documents Detection using Machine Learning Techniques - A Practical Approach with Cloud Computing Applications.
DOI: 10.5220/0006609503370344
In Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP 2018), pages 337-344
ISBN: 978-989-758-282-0
Copyright © 2018 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
337

The number of (in)famous vulnerabilities in
Adobe that, still today, are used to execute ar-
bitrary code and spread malware is significant:
CVE-2016-4190, CVE-2014-0496, CVE-2013-3346,
CVE-2016-6946, CVE-2009-0658, CVE-2009-0927,
CVE-2007-5659, CVE-2007-5020, CVE-2010-1297,
CVE-2010-2883... Most of them use JavaSCript lan-
guage inside to execute its payload.
After some really serious security problems dur-
ing 2007-2011 period, Adobe Reader tried to improve
its security adding a sandbox (called Protected View)
to Adobe Reader 10.1 and disabling more potential
attacks vectors by default.
1.1 Paper Organization
The rest of the present article is organized as follows.
Section two analyses the technical structure of PDF
documents and provides a historical introduction; sec-
tion three shows the background both in terms of re-
lated studies and existing tools, introducing the prob-
lem; section four describes and extends the develop-
ment of the proposal; section five presents the results
obtained; section six briefly introduces the analysis
framework developed as continuation of the presented
classifier; finally, section seven describes the conclu-
sions and possible future work.
2 BACKGROUND
PDF files are plain text files with magic number
”%PDF” (hex 25 50 44 46) and composed by a static
set of sections (Figure 1). Sections included into a
PDF document are the following (in order of appear-
ance):
• PDF Header: Contains the PDF format version,
e.g. ”%PDF-1.4”
• PDF Body: Composed by a set of objects used to
define the contents of the document. There can be
of different types, such as images, fonts, etc. This
section can also contain another type of objects
related with features like animations or security.
• Cross-Reference Table (xref Table): The cross-
reference table target purpose to link all existing
objects into the document. The xref table allows
to find and locate content into the document, e.g
between different pages. If the document changes,
the table is automatically updated.
• Trailer: Is the last section into the document and
contains the FDF file EOF indicator (%%EOF)
and links to the cross-reference that allow users
to navigate into the document.
JavaScript code can be included as objects into the
document, which implies that (as an object) the code
can be found, referenced, etc. The usual attack vector
is using JavaScript code as a payload to take advan-
tage of the PDF reader, exploiting some vulnerability.
The use of JavaScript in PDF documents was in-
troduced in the PDF 1.2 format together with Adobe
Acrobat Version 3.02 (1999) as part of AcroForms
(Appligent, 2013) feature, so all later versions are po-
tentially able to be affected by malicious JavaScript
because of this feature enabled by default. As Table 1
shows, this implies more than seven PDF and Adobe
Acrobat versions.
Figure 1: PDF document basic structure. Source:
http://infosecinstitute.com.
Table 1: Adobe and PDF format versions.
Year PDF Version Adobe Acrobat Version
1993 PDF 1.0 Acrobat 1.0
1994 PDF 1.1 Acrobat 2.0
1996 PDF 1.2 Acrobat 3.0
1999 PDF 1.3 Acrobat 4.0
2001 PDF 1.4 Acrobat 5.0
2003 PDF 1.5 Acrobat 6.0
2005 PDF 1.6 Acrobat 7.0
2006 PDF 1.7 Acrobat 8.0 / ISO 32000
2008 PDF 1.7, Adobe Extension Level 3 Acrobat 9.0
2009 PDF 1.7, Adobe Extension Level 5 Acrobat 9.1
2017 (Exp) PDF 2.0 Acrobat XI (or later)
2.1 Code Components
Aside from the sections, the general structure of a
PDF file is composed of different code components
(types of objects). Components are mostly used into
the PDF Body section as part of the different ob-
jects disposed as illustrated in Figure 2. The eight
basic code components defined by the PDF standard
are Boolean values, String, Names, Arrays, Dictionar-
ies, the null object and Streams. From these, Streams
are specially interesting from the security standpoint,
since they allow to store large amount of data. Usually
Stream components are used to store executable code
in order to run it after a certain event, such as pressing
ICISSP 2018 - 4th International Conference on Information Systems Security and Privacy
338

a button. The way code execution is performed in a
PDF document is through launching actions included
into objects. Legitimately, launch actions should be
used for opening or printing documents, for instance.
However it is possible to use them as an attack vector.
Figure 2: Example of body section in PDF documents.
Source: http://infosecinstitute.com.
2.2 PDF Metadata
PDF documents can contain two types of metadata.
Firstly, standard document metadata, which contains
the expected regular information for documents (e.g.
author, access and modification date, etc.); secondly,
specific metadata, containing specific info such as
versions info (with individualized information), cre-
ation application, etc. This specific metadata is stored
into the Trailer section of the document.
When researching about malware in PDF docu-
ments, a combination of both (standard and specific
metadata) allows to extract valuable information in
order to detect malicious documents if combined with
a deep analysis of the document content by human an-
alysts or an intelligent system in this case.
3 STATE OF THE ART
Regarding PDF malware detection, antivirus industry
has made great efforts over the last years in this mat-
ter. Aside, Adobe Acrobat has improved security in
its products significantly, including an internal sand-
box (Adobe, 2017) to mitigate the execution of mal-
ware. This sandbox drastically reduces the chance
to impact the operative system once the vulnerability
is exploited. Analysing PDF files searching for mal-
ware has been an important topic in both academics
and independent studies. Many different approaches
and techniques related with malware detection in PDF
are easy to find. As a consequence, there are a few
quite known tools for PDF documents analysis, that
allow to inspect the content of the document and asily
check for the presence of potentially dangerous ele-
ments such as ULRs, JavaScript code, launch actions,
etc. Some of the most relevant tools are the following:
• PeePDF: Is one of the most complete tools for
PDF documents analysis. It joins together most
of the necessary components that a security re-
searcher could need when performing a deep PDF
analysis. It parses the entire document show-
ing the suspicious elements, detects obfuscation
presence and provides a specific wrapper for
JavaScript and shellcode analysis.
• PDF Tools (Stevens, 2017): A complete set of
tools for analysing PDF files, such as parsers,
dumpers, etc. One of the most useful included
tool is PDFID, a light Python tool for scanning
PDF files seeking for certain PDF keywords that
allows to identify (for instance) if the document
contains JavaScript or executes some action when
opened. The advantage of PDFID over other tools
is its simplicity and efficiency. It does not need to
completely parse the document.
• PDF Examiner (Tylabs, 2017): Is an online so-
lution able to scan a document for several known
exploits. It also offers the possibility of inspect-
ing the structure of the file, as well as examining,
decoding and dumping PDF object contents.
• O-checker: A tool developed by Otsubo et al. as
part of an study (Otsubo, 2016) of malware detec-
tion in PDF documents, based on the identifica-
tion of malformed documents.
As related work, different approaches for static
malware detection in PDF documents has been de-
scribed in recent literature. From these, one of the
most frequently adopted is the use of machine learn-
ing techniques, based in particular features of the
document itself to improve malware detection. The
main advantage of this approach is a high effective-
ness against new attacks or malware families never
seen before, in contrast with the traditional solutions
like signature based systems, which mostly is effec-
tive against known malware.
Regarding to the use of the PDF file structure as a
detection vector, (Otsubo, 2016) represents an imple-
mentation where this approach has been taken to its
extremes. Thus, only features related with how PDF
has been crafted are taken into account, such as unref-
erenced objects, camouflaged streams, camouflaged
filters, etc. The basic premise of this approach is that,
Malicious PDF Documents Detection using Machine Learning Techniques - A Practical Approach with Cloud Computing Applications
339

if the structure of a PDF document has been altered,
malware presence in the document is very likely. In
this case, the presented system does not rely on ma-
chine learning, but just uses predefined rules for de-
termining whether the document is malformed (which
implies malware) or not. From our perspective, this
solution is very interesting as an additional source of
information for a machine learning implementation
together with others. In our work, we have included
this information as a feature to create the feature vec-
tor of our system.
When using machine learning approaches, the
success depends on the multiple areas of the docu-
ments or strategies for extracting information that will
allow the algorithms to be more accurate. For exam-
ple, in (Laskov and
ˇ
Srndic, 2011), Laskov et al. pur-
pose the use of lexical analysis of JavaScript code as
the input for the machine learning system. However,
if the JavaScript code has been designed to look like
legitimate code, e.g. blending the malicious one with
a big portion of legitimate code, as described in (los
Santos, 2016), the lexical analysis of the code may not
be effective enough for malware detection. Another
popular approach is the use of document metadata as
an input for the features vector used for predictions.
For example, (Smutz and Stavrou, 2012) uses mainly
the properties of documents metadata in combination
with what they called ”Structural features” of the doc-
ument. Those features are closely related with the
document content, e.g. number of included images,
strings size, etc. The use of metadata is an interesting
approach, but usually this metadata is counterfeited
by the attacker, so it’s necessary take into account not
only the typical metadata in malicious documents but
rather the counterfeited one. Furthermore, evaluating
the content of the document could be an effective so-
lution for detecting a specific set of malware types
(such as phishing attacks, where the attacker emulates
the appearance of an official document of an specific
organization) but may not be effective enough when
the attacker attaches the malicious content into a le-
gitimate document.
As a downside of these aforementioned cases,
samples for both training and test datasets have been
selected from public malware repositories which usu-
ally implies that the system will be trained with old
and very known samples and malware families. This
situation implies losing the focus in the main advan-
tage of machine learning use, that is, get a step ahead
to the signature based systems in new malware detec-
tion.
4 DESCRIPTION OF THE
PROPOSAL
The presented proposal is based on the application of
machine learning techniques for detecting fresh and
real malware, focusing in PDF format and determin-
ing if it is possible to improve regular and typical
static solutions and become more effective. Specifi-
cally, the aim is to get ahead to these solutions in de-
tection of new types/families of malware, developing
a solution as a complement for them. This solution
may be used as an isolated framework for malware
detection that does not need the PDF document con-
tent itself to work. This framework can be easily in-
troduced in cloud computing architectures to analyse
users documents preserving their privacy.
4.1 Samples Identification and
Collection
The main goal at this stage of the study is to get an ini-
tial dataset which represents (as realistic as possible)
the final environment where the classifier will operate.
For this purpose we have collected PDF malware sam-
ples from different sources and different types (PDF
document format versions). We have used a signifi-
cant percentage of recent samples (about 80% of the
PDF samples collected were created in 2016 or 2017).
JavaScript presence is a required characteristic for all
collected samples.
Regarding to the sources where samples were ob-
tained, we have selected them taking into account we
wanted to represent the best possible real world sce-
nario. We have used email accounts that usually re-
ceive spam or malicious attached documents, pub-
lic malware repositories (malwr.com, Contagio, etc)
and document repositories in general (P2P networks,
search engines, etc.). In addition, in order to collect as
much recent malware samples in the wild as possible,
most of included samples have been obtained from
the Cyber Threat Alliance (CTA, 2017), a dedicated
threat data sharing platform based on the cooperation
between companies in the industry. From all these
sources, we have collected a total of 1712 samples.
For samples identification and classification, we
have defined two different classes or sets:
• Goodware: Samples with JavaScript extracted
from trusted sites (public document repositories
of public entities, universities, etc) without sus-
picious characteristics detected by heuristics, e.g.
obfuscation, suspicious calls to API, etc. As a fi-
nal layer to ensure that these samples were benign,
we used a set of antivirus engines to verify that no
sample was detected as malware.
ICISSP 2018 - 4th International Conference on Information Systems Security and Privacy
340

• Malware: Samples downloaded from different
sources (email honeypots, public and private mal-
ware repositories, etc). To ensure that all collected
samples are considered malware (not fully con-
firmed), aside only the ones detected by more than
three reputed antivirus engines have been consid-
ered.
4.2 Feature Selection and Extraction
As mentioned in section 3, there are different ap-
proaches for the extraction of features from a PDF
document (metadata features, document structure,
content analysis, etc). In our implementation, we have
selected a combination of these approaches. We have
collected features from the document metadata such
as number of versions, edition time, size, etc. Re-
garding to the document structure, we took into ac-
count both presence of possible anomalies in the in-
ternal structure of the file (with regard to the PDF for-
mat specification) and features related with how the
document and its components (objects) are organized.
Anomalies in the file format are detected using (Ot-
subo, 2016) and encoded as a binary predictor. Re-
garding to the document structure we have selected
features from the whole document (number of ob-
jects, strings, references, etc.) and a significant num-
ber of features related specifically with the JavaScript
code embedded in the document. From JavaScript
code, we have extracted features usually linked with
malware presence that can be considered as ”suspi-
cious”, e.g. IPs, calls to functions related with auto-
execution, obfuscation presence, etc.
Extracting and processing features from a hetero-
geneous set of inputs with a high level of granular-
ity, implies a higher processing time than other ap-
proaches, so we have to focus in performance but in
balance with getting maximum accuracy, reducing the
false negative ratio. The average processing time for
the dissection of a document and it classification is
less than one second for all collected samples. In
exceptional cases, if the sample processing time re-
quired is greater than 2 minutes, the sample is auto-
matically rejected.
Once all documents features were selected and ex-
tracted, a dimensionality reduction was applied using
PCA. As a result, we obtained a final set of 28 final
features which compose a predictors vector as the in-
put for the Machine Learning algorithms. Figure 3
shows these features sorted by importance descending
in Random Forest model. As observed, some features
are significantly valuable in the model (from F1 to F8)
with regard to others. Even a subset of features are
not being taken into account by the model, however
it does not necessarily mean that this same weights
distribution persists over time. The presented imple-
mentation has been designed to work with a dynamic
set of samples sources, allowing to incorporate new
sources and retrain the model to adapt it to the typical
features of these new samples, which usually implies
changes in the model, such as the importance of each
feature (e.g. samples from academic sources contains
substantially different features with respect to sam-
ples collected from the Internet in general). The sys-
tem also allows to use different prediction algorithms
interchangeably.
In order to preserve the documents author privacy,
no feature related with the author or the documents
private content have been used as a predictor.
4.3 Classifier Design and Basic
Functioning
For our implementation we have chosen a supervised
strategy to address the problem as a binary classifica-
tion one, since the analysed samples could be only
”malware” or ”goodware” (not-malicious). There-
fore, as usual, we have divided the total amount
of recovered samples into three datasets: training,
test and validation. Those three dataset are struc-
tured according to the form
X
i
, y
i
i=1
Nv
where y
i
∈
{
Goodware, Malware
}
is the categorical variable and
X
i
= [X
i1
, ..., X
iN
]|X
i
∈
{
0, 1
}
represents each of the N
v
vectors of N predictors, contained in the dataset.
The collected samples were divided into training
set, test set and validation set as follows:
• Training Set: 995 samples
• Validation Set: 217 samples
• Test Set: 500 samples (Collected from private
shared malware samples repository)
In order to select the best possible subset of clas-
sification algorithms in terms of performance, after
an initial pre-selection stage, the selected algorithms
were Support Vector Machine, Random Forest and
Multilayer Perceptron. These three algorithms were
trained with the same training set and evaluated using
the aforementioned test and validation sets. As per-
formance estimators we have selected four different
metrics to evaluate the strengths and weaknesses of
each algorithm.
Accuracy =
T P + T N
T P + T N + FP + FN
(1)
Recall =
T P
T P + FN
(2)
Malicious PDF Documents Detection using Machine Learning Techniques - A Practical Approach with Cloud Computing Applications
341
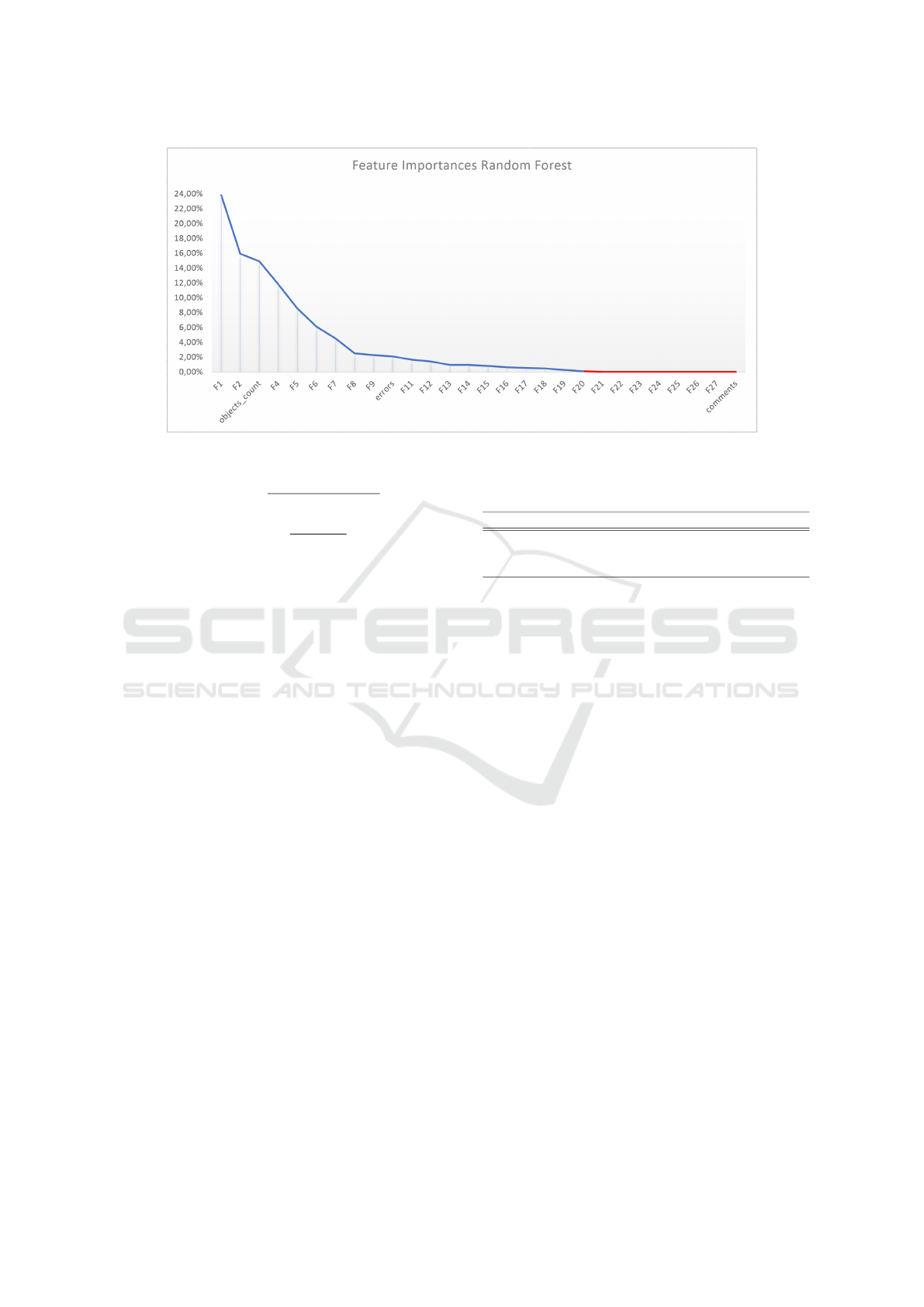
Figure 3: Selected document features sorted by importance descending in the RF model.
F1 − Score =
precision · recall
precision + recall
Precision =
T P
T P + FP
(3)
ROC − AUC =
Z Z
∞
−∞
T PR(T )(−FPR
0
(T ))dT
T PR = TruePositiveRate
FPR = FalsePositiveRate
T = T hreshold parameter
(4)
Additionally we use confusion matrices (where
Malware is the positive class) to compare the pres-
ence of false positives (FP) and false negatives (FN)
in all possible cases.
5 RESULTS
5.1 Validation Results
In order to select a subset of the most promising su-
pervised Machine Learning algorithms and as a first
evaluation of our proposal, the system was tested us-
ing different algorithms over the aforementioned val-
idation set. After a first selection, particularly tak-
ing into account time consumption, the selected algo-
rithms were: Support Vector Machine, Random For-
est and Neural Networks (in our case a Multilayer Per-
ceptron).
As Table 2 shows, Random Forest presents the
best classification results over the validation set. On
the other hand, SVM gets significant worse results
Table 2: Algorithms performance comparison in validation
phase.
Algorithm Accuracy Recall F1-Score ROC-AUC
SVM 0.75 1 0.85 0.86
RF 0.92 0.95 0.94 0.95
MLP 0.91 0.95 0.94 0.95
than the rest, with an accuracy of 0.75. Despite poor-
performance of SVM with respect to Random Forest
and MLP, we kept it in order to measure its perfor-
mance in test phase.
5.2 Test Results
For testing, samples have been collected from dif-
ferent sources than training and test validation. Us-
ing different sources for this phase allows us to em-
ulate the worst case in malware classification and
the real environment where de classifier will operate.
To achieve that, we have collected malware samples
from private shared repositories and goodware from
the eDonkey/Kad networks using eMule, where the
presence of malicious PDF is virtually discarted by
(eMule, 2016). Goodware samples in this work have
been downloaded using the same procedure and after
that, examined by different antivirus engines to dis-
card any suspicious sample.
Training the model with the most heterogeneous
possible set of samples and testing it with real and re-
cent samples, allows us to ensure that our model will
still work fine over time in a real life situation. In
addition, the framework were the classifier will oper-
ate, allows to easily retrain it using new samples and
updating the models according to the new eventual
possible malware landscape.
As expected, performance results (Table 3) for the
ICISSP 2018 - 4th International Conference on Information Systems Security and Privacy
342

selected algorithms in test phase, show that SVM be-
haviour has worsened drastically. However, RF and
MLP are even better in most cases. Because of that,
we will mainly focus our analysis in these two algo-
rithms.
Table 3: Performance comparison in test phase.
Algorithm Accuracy Recall F1-Score ROC-AUC
SVM 0.50 0 0 0.70
RF 0.92 0.94 0.92 0.98
MLP 0.96 0.967 0.96 0.98
Though performance results in both RF and MLP
are quite similar, MLP gets betters results in each
evaluated metric as Table 3 shows. Even though Area
Under Curve ROC (ROC-AUC) is the same for both
classifiers, in Figure 5 is possible to appreciate how
ROC curve for MLP is closer to an ideal ROC curve.
Figure 4: Confusion matrices of RF and MLP in test phase.
In addition to the metrics above, what happens
when the classifier fails in prediction needs to be
taken into account. In malware detection case, we are
specially interested in False Negative cases, because
it implies malware going undetected. Nevertheless,
it is also necessary to be taken into account that a
high False Positives ratio would mean that the clas-
sifier will often detect legitimate samples as malware,
which could result in an unreliable system.
Regarding to False Positives and Negatives, MLP
has shown much better results than RF. As Figure 4
displays, in False Negative terms, MLP a 1.8% with
regard to RF (3%). For False Positives, MLP results
are even better, where MLP obtains approximately a
third party of RF False Positives.
Besides above, in our tests, MLP have also
achieved slightly better results in time consumption
for prediction, with an average (over 1000 simula-
tions) of 15% less than RF.
6 ANALYSIS FRAMEWORK
Implementation details of the final framework where
the classification system works, are out of the scope
of this paper. However, it is necessary to explain its
target and main functioning in order to understand the
importance of malware detection using the classifier
presented in this paper.
As stated above, our classifier system does not
need any feature related with the content of the doc-
ument nor the author information. Thus, the classi-
fier can be embedded into the framework in server
side, using just an anonymous representation (that we
called vectorized form) of a document for predicting.
In client side, the document analysed by the user is
processed, vectorized an then sent to the server.
The advantage of using the vectorized form of the
document is that it is possible to uniquely identify a
document with a hash transmitted with the vector and
after that, recover the prediction result (requesting a
hash) without the necessity of transmitting the whole
document itself. Of course, the vectorized form of a
document, does not allow to uniquely identify a doc-
ument.
Due to the possibility of using dynamically dif-
ferent classifications algorithms and even versions of
these algorithms, all trained models are stored and
tagged using and algorithm ID and a creation times-
tamp. Hence, the developed framework can use dif-
ferent classifiers instances, retraining them periodi-
cally with new collected samples and generating new
“classifier snapshots” if the new trained model im-
proves prediction results.
Because of the above, when clients request the
analysis results of a document, the server will send a
prediction together with the classifier and its version.
7 CONCLUSION AND FUTURE
WORK
The aim of this project is to demonstrate if Machine
Learning techniques could be used as a good ap-
proach for PDF malware detection, using characteris-
tics from the document that could help to determine
when a samples is malicious while respecting doc-
ument and user privacy. This kind of experiments
does not seek to replace traditional solutions, such
as antivirus engines, but to complement them and if
needed, assists analysts who design and update them.
During the preparation of this work, we have de-
veloped tools for PDF document dissection and analy-
sis, also improving some existing others. Using these
tools, we have designed a set of document features
and built a classifier which uses them for malicious
PDF document detection, as the result of a compar-
ison of several previously trained classification algo-
rithms.
As a consequence, we have built a framework that
integrates the classifier and adds an extra value to the
Malicious PDF Documents Detection using Machine Learning Techniques - A Practical Approach with Cloud Computing Applications
343
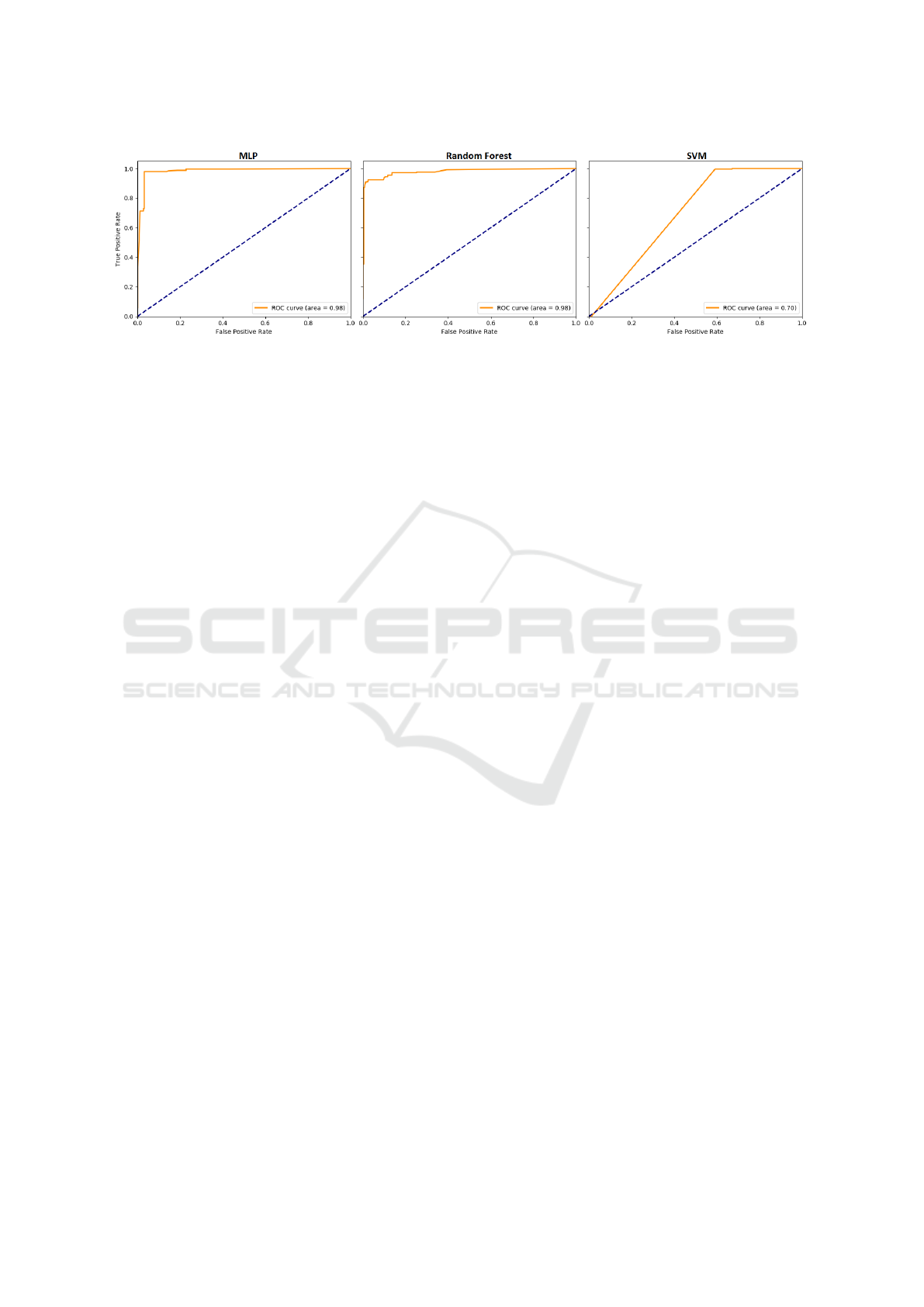
Figure 5: ROC curves for the studied classification algorithms with the test set.
results achieved, allowing any malware analyst or re-
searcher to improve, experiment and research further
with new data and algorithms.
However, there is still some room for further im-
provement. Below is a summary of several of these
chances.
We have to remark that using antivirus engines
as previous classification systems to train the algo-
rithms, implies that the classifier could inherit their
successes and advantages but also their mistakes and
disadvantages. In other words, using this approach,
the classifier may learn from antivirus false positives
and negatives as correct inputs. To minimize the pres-
ence of this fact, we have considered as malware sam-
ples collected from reputed malware repositories and
honeypots, not focusing on antivirus detection level.
For goodware samples, aside antivirus validation, we
have taken into account another factors as a semi-
automated search for malware indicators.
Futhermore, the use of a most detailed syntactic
analysis of the JavaScript code included into the doc-
ument, as described in (Laskov and
ˇ
Srndic, 2011),
could improve the results of our system if combined
with the existing solution. However it could affect the
system performance in terms of time consumption.
In addition, our system completely parses the doc-
ument, which implies complex operations, increasing
the mean processing time for samples. However, it
allow us to extract most of the possible features of
the document. This makes it possible to apply a wide
variety of existing approaches for malware detection
using machine learning.
Regardless of the aforementioned risk factors (al-
ready mitigated as much as possible), we has demon-
strated that using the presented approach produces
promising results in malware detection, reaching ac-
curacy above 96%, with a false positive and negative
rate below 1.8%, which is an acceptable rate in an-
tivirus industry.
All of this demonstrates that using anonymous
properties from PDF documents mainly focused in
how the document have been created could result in
an effective approach for malware classification.
REFERENCES
Adobe (2008). Adobe security bulletin. https://www.
adobe.com/support/security/bulletins/apsb08-13.
html. [Online; accessed 12-July-2017].
Adobe (2017). Adobe acrobat protected mode. https://
www.adobe.com/devnet-docs/acrobatetk/tools/
AppSec/ protectedmode.html. [Online; accessed
17-July-2017].
Appligent (2013). Sa quick introduction to acrobat
forms technology. http://www.appligent.com/wp-
content/uploads/2013/02/Acroforms+WhitePaper.pdf.
[Online; accessed 12-July-2017].
CTA (2017). Cyber threat alliance. https://cyberthreat
alliance.org/about/. [Online; accessed 05-August-
2017].
eMule (2016). emule: is it always a source of malicious
files? http://blog.elevenpaths.com/2016/08/nuevo-
informe-emule-siempre-una-fuente.html. [Online; ac-
cessed 05-August-2017].
Laskov, P. and
ˇ
Srndic, N. (2011). Static detection of mali-
cious javascript-bearing pdf documents.
los Santos, S. D. (2016). Camufladas, no ofus-
cadas: Malware de macro creado en espaa?
http://blog. elevenpaths.com/2016/05/camufladas-no-
ofuscadas-malware-de.html. [Online; accessed 17-
July-2017].
Otsubo, Y. (2016). O-checker: Detection of malicious doc-
uments through deviation from file format specifica-
tions. Blackhat, page 16.
Smutz, C. and Stavrou, A. (2012). Malicious pdf detection
using metadata and structural features. In Proceed-
ings of the 28th annual computer security applications
conference, pages 239–248. ACM.
Stevens, D. (2017). Pdf tools. https://blog.didierstevens.
com/ programs/pdf-tools/. [Online; accessed 17-July-
2017].
Tylabs (2017). Pdf examiner. https://pdfexaminer.com/.
[Online; accessed 17-July-2017].
Wikipedia (2017). Adobe acrobat — wikipedia, the free
encyclopedia. https [Online; accessed 12-July-2017].
ICISSP 2018 - 4th International Conference on Information Systems Security and Privacy
344
