
An Extended Case Study about Securing Smart Home Hubs through
N-version Programming
Igor Zavalyshyn, Nuno O. Duarte and Nuno Santos
INESC-ID / Instituto Superior T
´
ecnico, Universidade de Lisboa, Lisbon, Portugal
Keywords:
Smart Home, Internet of Things, Privacy and Security, Smart Hub, N-version Programming.
Abstract:
Given the proliferation of smart home devices and their intrinsic tendency to offload data storage and pro-
cessing to cloud services, users’ privacy has never been more at stake than today. An obvious approach to
mitigate this issue would be to contain that data within users’ control, leveraging already existing smart hub
frameworks. However, moving the storage and computation indoors does not necessarily solve the problem
completely, as the pieces of software handling that data should also be trusted. In this paper, we present a
thorough study to assess whether N-version programming (NVP) is a valid approach in bootstrapping trust in
these data handling modules. Because there are considerable complexity differences among the modules that
process home environment data, our study addresses less complex modules that strictly follow exact specifi-
cations, as well as complex and looser modules which although not following an exact specification, compute
the same high level function. Our results shed light on this complexity and show that NVP can be a viable
option to securing these modules.
1 INTRODUCTION
In recent years, several smart home platforms have
become mainstream, such as Samsung SmartThings,
Apple HomeKit and Amazon Echo. However, the
threat of privacy breaches constitutes a major source
of concern for users. Device misconfiguration is fre-
quent, which can lead to leakage of sensitive data,
e.g., camera feeds (Kelion, 2012), or unauthorized
home device monitoring (Forbes, 2013). Poor de-
sign and/or implementation of the software behind
these devices is also a major security issue (Com-
puterworld, 2016). SmartApps are often overprivi-
leged and can abuse permissions to leak sensitive user
data (Fernandes et al., 2016a).
A major difficulty in preventing unwanted sensor
data exfiltration lies in the fact that many IoT applica-
tions, even if they were to execute entirely at the home
environment, require both permissions to access sen-
sor data (e.g., IP camera’s frames) and to access the
network. These permissions are required to allow the
application to read and process the data, and send the
results to the cloud. However, unless the application
is correctly specified and implemented, its behavior
can deviate from the expected, e.g., due to a bug, or an
exploit, in order to release raw data over to the cloud,
thus potentially causing a privacy breach.
Our goal is to investigate the adoption of N-
version programming (NVP) as part of the design of
smart hub platforms as a way to enhance security and
prevent leaking raw sensor data to the cloud. Building
on the shoulders of systems like FlowFence (Fernan-
des et al., 2016b) or Privacy Mediators (Davies et al.,
2016), we consider a smart hub where IoT applica-
tions run and process sensor data locally under the
constraint that applications cannot access such data
directly, but through a mediation interface consisting
of a set of trusted functions (TFs). TFs consist of
extensions to the base hub platform that are imple-
mented by third-party developers and that are deemed
to correctly implement common data handling oper-
ations (e.g., face recognition, anonymization func-
tions, etc.). The problem, however, is that if buggy
or even malicious TF implementations are installed
on the hub, serious security breaches can take place.
NVP can help alleviate this problem by leveraging N
different implementations of a single TF.
By using NVP, rather than depending on a single
implementation, each trusted function depends on N
different implementations (versions) that must con-
cur to produce the final result. The smart hub feeds
sensor data as input to each of the N function ver-
sions, and determines the overall output result based
on a particular decision policy. For example, with to-
Zavalyshyn, I., Duarte, N. and Santos, N.
An Extended Case Study about Securing Smart Home Hubs through N-version Programming.
DOI: 10.5220/0006854001230134
In Proceedings of the 15th International Joint Conference on e-Business and Telecommunications (ICETE 2018) - Volume 2: SECRYPT, pages 123-134
ISBN: 978-989-758-319-3
Copyright © 2018 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
123
tal agreement policy, all partial outputs must be equal
otherwise no output is released. A quorum policy re-
quires only a quorum of equal partial responses to be
reached. We envision different versions to be devel-
oped independently by an open community of devel-
opers. Insofar as the developers do not collude, N-
version trusted functions are no longer dependent on
the correctness of any specific function implementa-
tion as it is the case for existing smart hub solutions.
Although applying NVP to the smart hub architec-
ture is relatively straightforward, the degradation of
utility and performance can undermine the viability of
this technique. The utility is penalized if an N-version
module too often blocks any output to the applica-
tion due to result divergence reasons. Performance
of an N-version module tends to be bound by the
slowest sub-module involved in the output decision.
In our context, the impact to utility and performance
will greatly depend upon how sub-modules are imple-
mented. If sub-modules are developed from scratch,
we expect most of the negative effects to be caused
by implementation or performance bugs introduced
by the developers. On the other hand, if sub-modules
are built upon pre-existing code (e.g., libraries) such
effects may also stem from incoherent specifications.
The decision policy employed also plays a critical role
in determining the behavior of modules.
In this paper, we provide an extended case study
about the feasibility of NVP for securing smart home
hubs. It seeks to characterize the impact of NVP to
utility and performance of trusted functions. To this
end, we perform an in-depth study focusing primarily
on two main causes: software flaws and specification
incoherence. We built multiple test modules perform-
ing a variety of privacy-sensitive functions, such as
image blurring, voice scrambling, k-anonymization,
face recognition, and speech recognition, among oth-
ers. Then we tested them extensively in different N
settings and under different decision policies.
Our in-depth study reveals that NVP has consider-
able potential for practical application within a smart
home environment. In particular, we found that: (1)
for N-versions that implement the same algorithm and
follow the algorithm specification, it is possible to
provide an N-module offering high utility as long as
the number of software flaws is residual, (2) for N-
versions that do not follow the same algorithm but
perform the same task, we observe that although mod-
ule utility can be negatively affected by output diver-
gence, it can be increased leveraging decision poli-
cies tailored to the problem domain space, and (3) N-
version trusted function module performance is typ-
ically bound by its slowest version, a condition that
can be mitigated by leveraging versions redundancy.
TellWe at he r
Home App
Home Hub
Weather
Web Service
Sensors
Actuators
Hub
Admin
Home Environment
Hub
Proxy
Figure 1: Appified privacy-preserving home hub.
Next, we provide a more extensive overview of
our motivation, approach, and goals. In Section 3,
we introduce a smart hub architecture based on NVP.
Then, we present the main contributions of this work:
a comprehensive study of the impact of NVP on TF
utility (Sections 4 and 5) and performance (Section 6).
2 OVERVIEW
2.1 Privacy-preserving Home Hubs
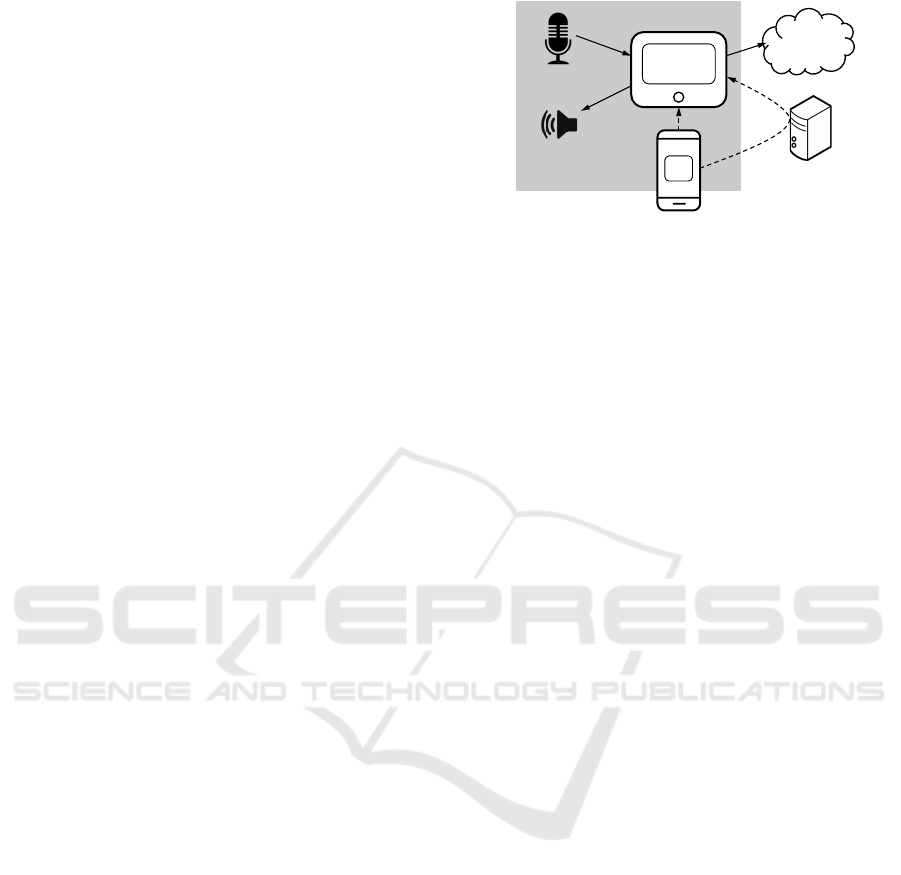
Figure 1 represents a privacy-preserving home hub
platform (Davies et al., 2016; Fernandes et al., 2016b)
in which security-sensitive sensor data can be aggre-
gated and processed according to the privacy prefer-
ences of the user. The home hub is designed as an “ap-
pified” platform that allows for third-party developers
to write home apps which users install on the home
hub. In the figure, a home app called TellWeather
waits for an audio command (e.g., “Tell weather in
LA”), issues an HTTP request to a weather service,
converts the response into audio signal, and forwards
it to a speaker. The home hub provides an admin-
istration interface through which the homeowner can
access the hub directly or tunneled through a proxy
and manage it, e.g., install or uninstall apps, register
devices, and set up privacy policies.
The hub platform provides app developers with
API functions to interact with the devices. This API
allows a home app to perform numerous operations,
such as collecting data from sensor devices (e.g., au-
dio from microphones, images from cameras), send-
ing data to actuators (e.g., audio signal to speak-
ers, or video streams to displays), accessing Internet
services, and performing various data computations
(e.g., speech or face recognition, or data anonymiza-
tion). The operations that a home app is allowed to
execute are controlled by a security policy: the home
app must explicitly request the hub administrator for
permissions to perform certain operations, in particu-
lar access to device APIs.
SECRYPT 2018 - International Conference on Security and Cryptography
124

2.2 Trusted Functions: Goods and Ills
To prevent unlimited access to sensor devices,
privacy-preserving home hubs allow their APIs to be
extended with trusted functions (TFs) aimed to im-
plement high-level operations that mediate access be-
tween the application and the raw data. In some cases
a TF interposes between the application and a data
source, e.g., a camera device. The motivation for such
a TF can be, for instance, to provide a face recogni-
tion service over raw image data collected from the
camera without revealing the raw data to client home
apps. TFs can also mediate access to data sinks, for
example to encrypt or anonymize sensitive data be-
fore sending it to a remote server. Some home hub
solutions support TFs at data sources (Davies et al.,
2016), others at data sinks (Mortier et al., 2016), and
others in both (Fernandes et al., 2016b). Once in-
stalled into the hub, trusted functions can be invoked
by local home apps running on the hub. TFs must be
developed by third-parties and installed by the hub ad-
ministrator. TF developers are fully trusted to imple-
ment them correctly. As long as TFs are correctly im-
plemented, they constitute an effective approach to se-
curely processing sensitive data. However, malicious
TF implementations can perform serious attacks:
A1. Incomplete results: during processing, a mali-
cious TF could intentionally omit parts of the results
in an effort to disturb users’ actions, e.g., hide the part
“and B” when recognizing the user voice command
“record game A and B”.
A2. Incorrect results: similarly to the previous at-
tack, a malicious TF could introduce incorrect re-
sults or replace correct with incorrect results, in order
to trick the user into performing harmful operations,
e.g., replace the name of the person the user wants
to call with a premium number, when recognizing the
user call request voice command.
A3. Data inferences: in collusion with a malicious
application, a malicious TF could not only perform
the operation it intended but also make inferences on
the raw data and disclose it to the application, e.g.,
identify the people in the room in addition to recog-
nizing the user voice command.
A4. Raw data leakage: the most devastating attack
is the one where a malicious TF colludes with a mali-
cious application and leaks raw data, e.g., send a raw
camera frame as face recognition output.
2.3 Leveraging N-Version Programming
While the effects of attacks A1 and A2 can also stem
from naive implementations, which are difficult to
distinguish, we argue that attacks A3 and A4 are the
sole product of lack of platform control over TF out-
puts. As a result we seek to understand whether re-
lying on multiple TF implementations can mitigate
these attacks. In particular, we aim to investigate the
feasibility of N-version programming (NVP) to pre-
vent malicious TF implementations from exfiltrating
sensitive data outside of the home premises without
the user’s knowledge or consent.
TF implementations are expected to follow a TF
specification. We assume that the TF specification is
publicly available among home app developers and
home hub users. As for a TF implementation, the TF
binary needs to be publicly released, possibly even
after being properly obfuscated. An NVP-based TF
system must be able to detect the deviations in the
functions outputs and react accordingly.
The N-version decision algorithm used to merge
the outputs of multiple trusted function implemen-
tations must be efficient in terms of execution time
and utility. Too strict algorithm will render the func-
tion useless, while the relaxed one might alter the se-
curity guarantees. Overall, the overhead introduced
by employing N-version technique should not be sig-
nificantly higher compared with a single version of
trusted function execution.
Our main adversary consists of the potentially
buggy or malicious code of a trusted function imple-
mentation. This implementation may try to output the
sensitive user data as is without processing it but such
a result will not be consistent across the outputs of all
other implementations of the function, and will be ig-
nored by the decision algorithm. We assume that var-
ious implementations of the same trusted function do
not collude and are developed independently. We also
assume that the software and hardware platform of the
hub where the trusted function executes is secure, and
that home apps and TFs execute in sandboxed envi-
ronments. It is not our primary goal to secure against
side-channel attacks. The capabilities of the attacker
consist only of the ability to write arbitrary code as
part of trusted function implementations.
3 TRUSTED FUNCTION
MODULES
In this section, we present a general security archi-
tecture for smart home hub platforms based on N-
version programming. In this architecture, home hub
extensions consist of N-version trusted function mod-
ules (henceforth called “modules”). A module pro-
vides the functionality of a single TF implemented
internally in a N-version fashion, with each of the N
An Extended Case Study about Securing Smart Home Hubs through N-version Programming
125
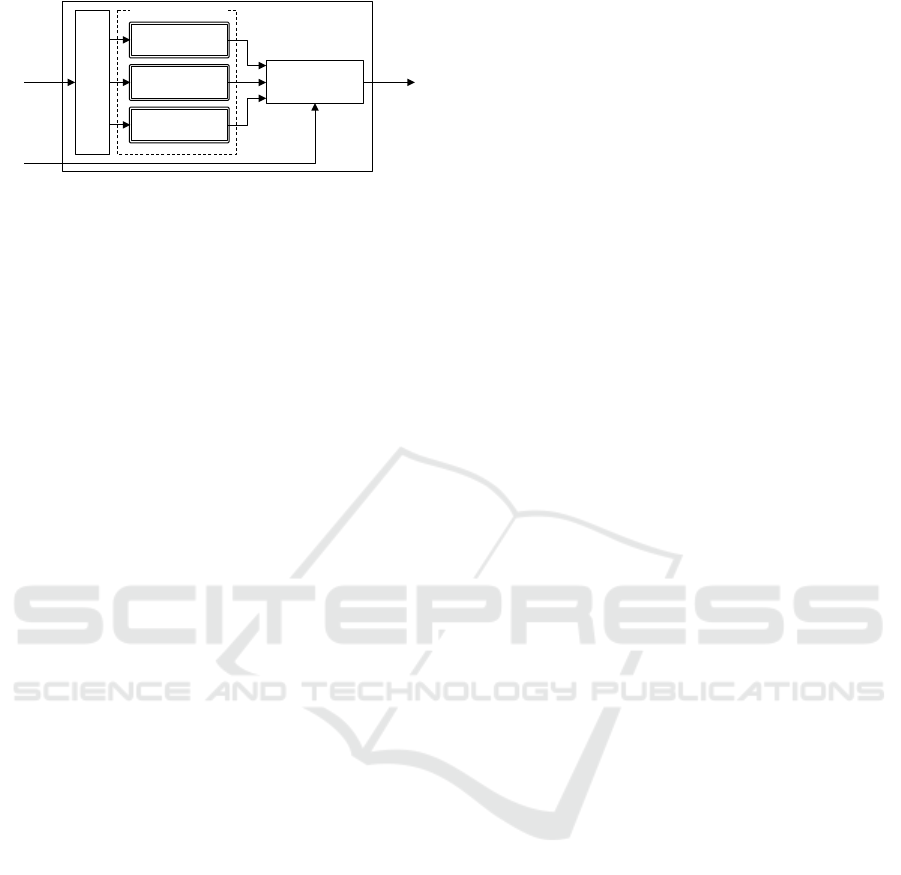
Unit 2
Decision
Block
Unit 3
Unit 1
Input Preprocessor
3-Version Units
Input
Arguments
Decision
Policy
Output
Results
Figure 2: N-version trusted function module (with N=3).
versions being provided by independent developers.
Each of these versions, called units, are required to
implement the same trusted function specification.
Whenever an application issues a request, the in-
put parameters are forwarded to all N units and their
outputs are compared with each other before a final
output is returned back to the application. Deciding
whether or not a final output result is provided and
what that output result will be depends on a decision
policy defined by configuration. In a particular pol-
icy, all N units must produce the same result, which is
then returned as output result, otherwise the applica-
tion is informed that no result was generated. Thus, if
any single unit implementation produces a malicious
output, this output will differ from the remaining N-1
units (assuming no collusion) causing the final result
to be suppressed, preventing the malicious unit from
propagating its effects to the application.
Figure 2 shows the internals of a module imple-
mented by 3 units. The input arguments are passed
by the client application and the output results are
returned to the application. The input preprocessor
feeds the input arguments to each unit and the deci-
sion block implements a decision algorithm according
to the provided decision policy. The decision policy is
a configuration parameter decided by the hub admin-
istrator. Each unit is implemented by a program that
runs in an independent sandbox. The input processor
and the decision block logic must belong to the hub
platform, which must also be responsible for setting
up the units’ sandboxes and the datapaths represented
by arrows in Figure 2.
3.1 Module Lifecycle
The lifecycle of each module comprises four stages.
In the specification stage, a cooperation between the
platform and community developers results in the
production and public release of module TF specifi-
cations. The decision on the creation of new modules
is based on the community user needs. A specification
features either the algorithm or high level function to
be implemented, the input and output data formats, as
well as a group of custom decision policies.
Once the specification is out, the module enters
the development stage in which third-party develop-
ers independently implement their TF versions. This
approach is similar to existing community-based soft-
ware projects, e.g. Debian, where the members define
task requirements and control the development pro-
cess. Each TF version must be packaged and signed
by the developer, and uploaded to the platform repos-
itory. By using a key that is certified by a certificate
authority, it will be possible to assess the identity of
the developer and prevent Sybil attacks, i.e., the same
developer releasing and signing multiple malicious
versions of the module’s TF. Once authenticated the
TF version is packaged in the TF module and subse-
quently either made available for users to install in
case of a new module or automatically pushed for
subsequent platform module update.
The next stage is installation of the module on the
home hub. Users can download the latest version of
the module from the repository and instantiate it lo-
cally on the hub. Default module settings work out
of the box, however experienced users may add or
remove module units, and redefine the decision pol-
icy according to their needs. Once the module is in-
stalled, the module enters the execution stage in which
applications running on the hub are allowed to issue
requests to the module. Note that modules may be-
come temporarily out of service in order to perform
software updates (e.g., installing a new unit or updat-
ing an existing one) and may also be permanently re-
moved from the hub.
3.2 Detection of Unit Result Divergence
The decision taking process is at the core of what
makes N-version programming effective at counter-
ing adversarial units. In the perfect scenario, each
unit is assumed to execute one of two possible ver-
sions: benign or adversarial. A version is benign if it
consists of a flawless implementation of the module’s
trusted function specification. A version is adversarial
if it deviates from the intended specification in order
to tamper with or leak sensitive data. Thus, if de-
viations exist between unit outputs, then at least one
adversarial version is present. Since different security
properties can be attained depending on the number of
units in agreement, we define three decision policies
providing three agreement conditions:
Total agreement (TA) policy: This policy offers the
strongest security guarantees. All N units must agree
on the same output result in order for an output to be
returned. If this condition holds, the resulting value
is returned, otherwise an error is yielded. Thus, 1 be-
nign version only is required to exist in order to sup-
SECRYPT 2018 - International Conference on Security and Cryptography
126

press the return of a corrupted result. In fact, for an
attacker to be successful, all N versions must be both
adversarial and collude in producing the same output.
Quorum agreement (QA) policy: Only a quorum
Q = bN/2c + 1 units (i.e., a majority) needs to reach
consensus on a common return value. If Q is found,
the module returns the agreed upon value, otherwise it
reports failure. The QA policy is weaker than the TA
policy because Q > 1 benign units need to be present
to thwart an attack. Furthermore, a successful attack
requires Q < N colluding adversarial units.
Multiplex (Mux
i
) policy: This policy is the weak-
est of all and can no longer be considered to provide
N-versioning security benefits. Under a Mux
i
policy
the decision block simply selects one unit output to
be fed to the module output. The unit selection is pa-
rameterized by a number 1 < i < N. This policy is
useful mostly for debugging purposes during the test-
ing stage of the module’s lifecycle.
Ideally, the divergence between unit outputs in a
module should occur due to the rational behavior of a
malicious developer who intentionally had not imple-
mented some version according to the trusted function
specification of the module. However, other causes
may lead to undesired output divergence that may
cause undesired side-effects, namely: software flaws,
and module incoherence.
3.3 Nondeterministic Inputs
One cause of unit divergence is operational and oc-
curs whenever a specific trusted function depends on
nondeterministic inputs, e.g., a random number, the
system time or date, etc. If different units obtain
different readings for the same intended input value,
units’ computations will likely return different results
which may lead to failure in reaching a total or quo-
rum agreement conditions and harm module’s utility.
To avoid this problem, all nondeterministic inputs
must be provided by the preprocessor. Sandboxes
must prevent units from issuing nondeterministic sys-
tem calls. If the version code depends on such calls,
the input preprocessor can execute those upon request
and pass the same value to all units. A request is de-
clared by overriding the init method of the class of
input parameters. The init method of this class is in-
voked by the input preprocessor and can be inherited
by a subclass with the purpose of prefetching non-
determistic values. To prefetch an input value in a
module, the trusted function specification only needs
to assign this subclass to the type of the respective
input argument. By constraining all units to receive
the same input, this approach prevents the aforemen-
tioned operational causes for divergence.
Description
Image Blurring Module Specification
Pseudocode
To blur an image, compute the
average of the RGB channels of the
pixels surrounding each of the
image's pixels. The pixel area
affected by the blurring process
depends on the input vicinity factor.
For example, for factor 1 the average
includes the pixel itself and the 8
immediately surrounding pixels.
1
2
3
Factor 1 Factor 2 Factor 3
Interface
Testing
Func BLUR(imgname, factor)
imageIn = inputImage(imgname)
Foreach px In imageIn
pxs = getNear(px, factor)
rgb = RGBAvg(pxNeigbors)
setPixel(imageOut, rgb)
End For
outputImage(imageOut)
End Func
Input arguments:
imageIn: ArrayList<Integer[]>
factor: Integer
Output results:
imageOut: ArrayList<Integer[]>
Download BlurTest.jar
To test the blur implementation My:
java –jar BlurTest.jar –fn My
Figure 3: Image blurring module specification.
3.4 Software Flaws
A second unintended cause for internal result discrep-
ancy is accidental in nature, and is caused by flaws
in versions’ software that cause the actual unit exe-
cution to deviate from the expected value as defined
in the trusted function specification. In addition to
harming module utility, flaws may negatively affect
the correctness of the module. As shown in past stud-
ies, programmers tend to commit the same flaws in
the same code regions, which may end up resulting
in the generation of incorrect results that can eventu-
ally appear at the module’s output depending on how
many units have reached consensus on the same in-
correct value and on the decision policy in place.
To reduce these negative effects, we define a for-
mat for trusted function specifications that aims to be
both unambiguous and human readable so as to re-
duce the change of software flaws. Figure 3 depicts a
simplified version of the specification for an image
blurring trusted function. The specification format
comprises: a description of the intended functional-
ity, an algorithm representation in the form of pseu-
docode, the interface of the module indicating the in-
put and output parameters and respective types, and a
testing procedure which may include specific testing
code. While the description and the algorithm repre-
sentation aim to clarify misunderstandings about the
specification, the testing parts aim to help debugging.
Since the specification is public, the source code of
the testing classes and types of input arguments / out-
put results must be provided.
3.5 Module Incoherence
Module incoherence occurs if two or more units in-
side a module implement different trusted function
An Extended Case Study about Securing Smart Home Hubs through N-version Programming
127

algorithms. For example, a face recognition module
may be based on software that implements face recog-
nition using different techniques. As a result, one ver-
sion may be able to identify a face that a second ver-
sion cannot. Speech recognition is another example
in which different algorithms may yield very diverse
outputs, for instance being able to detect some words
in a whole sentence, but not others.
A natural question that arises when the module is
incoherent is whether it can be used for countering
malicious version implementations. In fact, even as-
suming the absence of software flaws, it will be dif-
ficult to determine whether the divergence of results
is due to a malicious version or due to semantic dif-
ferences between versions themselves. Faced by this
challenge, we take two decisions.
First, we require the modules must be explicitly
specified as strict or loose. A strict module is one
in which all versions must implement the same al-
gorithm. For this reason, all versions are expected
to strictly implement the algorithm described by the
trusted function specification. In contrast, a module
is loose if the implemented algorithm does not sat-
isfy the specification. Version developers must clearly
indicate the type of a given version. Otherwise, in-
stalling a loose version on a strict module will cause
internal unit output divergence thereby severely de-
grading the module utility.
Second, to improve the utility of loose modules,
we allow for replacing the standard decision algo-
rithm of the decision block by a customized deci-
sion algorithm (which could be provided along with
the trusted function specification). Since the stan-
dard decision algorithm simply tests the equality of
units’ outputs, algorithms that generate slightly dif-
ferent outputs will immediately fail the test which will
considerably impair the module utility. On the other
hand, a customized decision algorithm may perform
domain-specific tests that may overcome small differ-
ences between outputs. The side-effect, however, is
that by relaxing the equality requirement, an adver-
sary may attempt to exploit that degree of freedom,
e.g., to encode sensitive data to a remote party. Thus,
by deciding whether or not to adopt a customized de-
cision algorithm, an end-user can choose between the
modules’ utility and security.
Until now, we have presented an architecture for
home hub based on N-version trusted function mod-
ules. We have also seen that the utility and security of
each module can be affected by other factors, namely
software flaws and module incoherence. The next
sections focus on studying the impact of both these
factors and on performance evaluation.
4 IMPACT OF SOFTWARE
FLAWS
In this section we study the impact of version software
flaws on the overall behavior of modules. We specifi-
cally focus on strict modules performance. Since they
implement the same algorithm, it allows us to concen-
trate on discrepancies due to software faults. For our
study, we implemented several test strict modules that
feature common privacy-preserving algorithms for a
smart home sensor data.
4.1 Experimental Methodology
We picked five different algorithms, and gathered
three different implementations for each of them, with
the help of five different volunteer developers. The
versions for each algorithm were developed indepen-
dently by different developers. For each developer,
we provided a complete specification and a testing
tool. The code was to be written in Java. Given the
simplicity of the algorithms involved, we requested
developers to submit their implementations before
and after using the testing tool for debugging. While
the implementations after testing recorded no bugs,
the implementations before testing feature some bugs.
Considering the purpose of this study, here we focus
on the pre-testing implementations. The algorithms
to implement were as follows:
Image Blurring Algorithm: An image blurrer can be
used to protect users’ privacy, namely by anonymiz-
ing the video data gathered by cameras (see Figure 3).
We ran a simple battery test consisting of the blurring
of 10 different pictures over vicinity factors of 1, 2
and 3. Afterwards, we made a byte-wise comparison
between the expected result and the implementation
produced files, in order to assess the implementations’
correctness. In total, we executed 30 tests.
Voice Scrambling Algorithm: A voice scrambler
can be useful in mitigating attempts to identify the
speaker and other nearby individuals. This algorithm
receives an audio clip as input, and after applying
pitch shifting and distortion, it outputs a modified au-
dio clip where the voice sounds robotized. With re-
spect to testing, we exercised each implementation
with 30 different audio clips.
Data Encryption Algorithm: RC4 is a stream cipher
algorithm that can be used in encrypting certain home
environment data before transferring it to a certain
recipient. The final testing tool features 153K tests
comprising tuples hmessage, key,cyphertexti, where
both message and key were randomly generated with
increasingly longer sizes.
SECRYPT 2018 - International Conference on Security and Cryptography
128

Table 1: Evaluation results of strict modules under total agreement (TA) and quorum agreement (QA) decision policies. For
each decision policy, the resulting output can be: correct (3), incorrect (7), or silent (–).
Module Function
Image Blurring Voice Scrambling Data Encryption Data Hashing K-Anonymization
V1 V2 V3 V1 V2 V3 V1 V2 V3 V1 V2 V3 V1 V2 V3
Single Tests Passed
30
30
30
30
30
30
30
30
0
30
0
30
153K
153K
0
153K
153K
153K
41K
41K
41K
41K
0
41K
0
210
210
210
210
210
Number of Bugs 0 0 0 0 4 4 0 1 0 0 0 1 1 0 0
N-mode Tests TA: 3, QA: 3 TA: –, QA: 7 TA: –, QA: 3 TA: –, QA: 3 TA: –, QA: 3
Data Hashing Algorithm: MD5 is a well-known
hashing function useful in assessing the integrity of
data. The final testing tool featured 41K tests. These
tests consist of tuples hmessage,hashi, where every
message was randomly generated with increasingly
longer sizes.
K-anonymity Algorithm: Lastly, Mondrian is a top-
down greedy algorithm for strict multidimensional
partitioning, with the goal of achieving K-anonymity.
Such an algorithm could be used in anonymizing
home environment data (e.g., power consumption
readings), so that the user could, for example, supply
that information to an interested third party. The test-
ing tool features 210 tests. These tests comprise tu-
ples hdataTuples, k, qids,resulti, where dataTuples
are statically grouped in 5 files each comprising 1
million entries, and k and qids are automatically gen-
erated and increased anonymity factors and quasi-
identifiers respectively.
4.2 Main Findings
Table 1 summarizes the N-version study results,
where V1, V2 and V3 correspond to three different
version implementations. We highlight three main
findings. First, under the TA decision policy, only
the image blurring module yields an output. This is
possible because all unit implementations passed the
30 tests. Since they produced the same result, the TA
policy concurs on outputting the same result. This
finding is consistent with the lack of bugs found in
the code which could compromise the resulting out-
put. For the remaining modules, however, faults have
caused some versions to fail individual tests thus un-
dermining the overall result.
Second, under the more relaxed QA decision pol-
icy, we observe that four modules can successfully
reach a consensus and produce an output: the image
blurring module—whose individual implementations
output consistent results—and three additional mod-
ules in which two out of three implementations gen-
erate the same result, thereby allowing a consensus
to be reached. In these cases, functional divergence
occurred due to the existence of bugs. In the data
encryption module, we identified a bug in V2 that
consisted of a wrong value swap between two vari-
ables. Regarding the data hashing module, we de-
tected one bug in V3 which was later found to be a
variable poorly initialized. In the K-anonymization
module, V1 contained a coding error stemming from
a wrong pseudocode interpretation of the scope of a
variable. Specifically, a global variable used by sev-
eral functions was supposed to be initialized in a cer-
tain function, but V1’s developer declared the vari-
able as local to that function, leading to issues in the
other functions handling it. Lastly, in one case, the
voice scrambling module produced an incorrect re-
sponse under QA. This happened because two ver-
sions, namely V2 and V3 experienced the same 4 bugs
each. More specifically, the bugs originated from the
wrong interpretation of a loop upper bound.
Given these numbers, we conclude that when ver-
sions yield different results, NVP actually detects
(except for side-channels) implementation deviations
created with rational intent. The exception being
when the majority of the versions output the same er-
roneous result. Accidental mistakes can cause a re-
duction in the utility of the module. If a very conser-
vative decision policy is employed (TA) this loss will
be considerable (up to 80%). On the other hand, un-
der QA, the utility drop is smaller, as four out of five
modules can still produce the same result.
5 IMPACT OF MODULE
INCOHERENCE
This section studies the impact of module incoherence
on the modules’ overall behavior and utility. For our
study, we implement two test loose modules which
do not strictly follow the same specification, yet com-
pute the same high level function: face recognition
and speech recognition.
The module implementing the face recognition
function uses three existing open source face recog-
nition libraries as building blocks: OpenCV (with
Face module), OpenBR, and OpenFace. The libraries
code remained unchanged but was wrapped around
An Extended Case Study about Securing Smart Home Hubs through N-version Programming
129
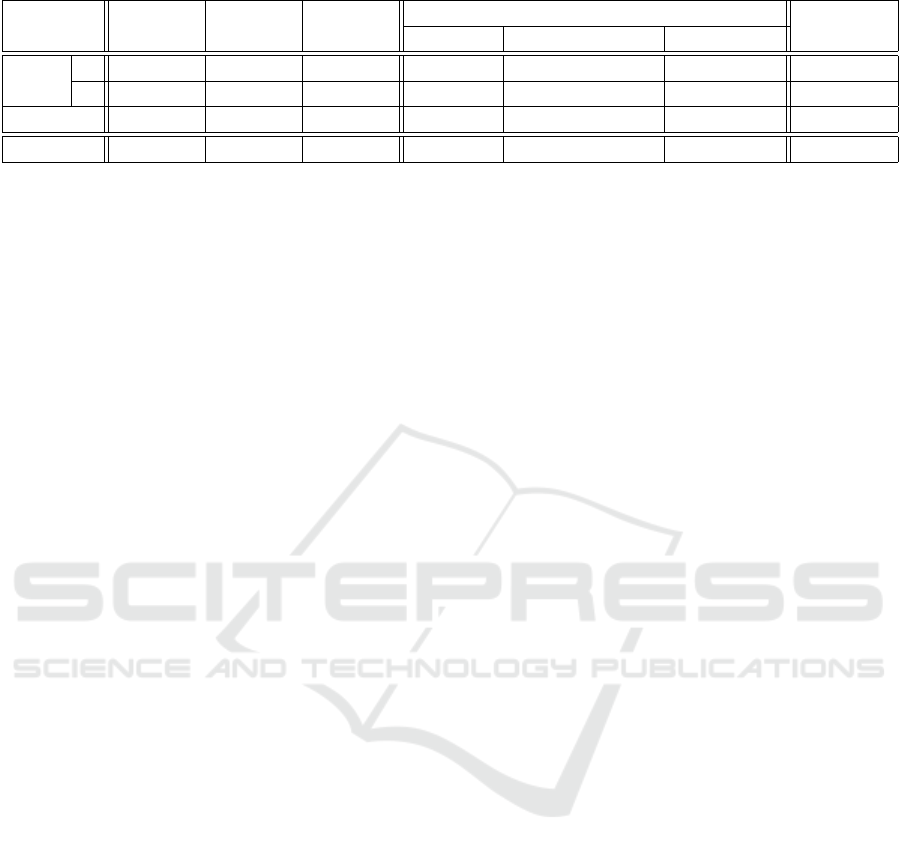
Table 2: Success rates of face recognition (Recogn) measured in correct (3), incorrect(7) and no recognition (No Recogn).
OpenCV OpenBR OpenFace
Decision Policy
MS Face API
Total Agree. OpenFace ∩ OpenBR Quorum Agree.
Recogn
3 156 (≈62%) 219 (≈88%) 228 (≈91%) 137 (≈55%) 202 (≈81%) 220 (88%) 249 (≈99%)
7 1 (≈1%) 1 (≈1%) 0 (0%) 0 (0%) 0 (0%) 1 (1%) 0 (0%)
No Recogn 93 (≈37%) 30 (≈11%) 22 (≈9%) 113 (≈45%) 48 (≈19%) 29 (11%) 1 (≈1%)
Total 250 (100%) 250 (100%) 250 (100%) 250 (100%) 250 (100%) 250 (100%) 250 (100%)
the N-version module’s API. Based on these libraries,
we defined several module configurations. We tested
the effectiveness of the face recognition module when
trained with a training set of 2250 images and a test-
ing set of 250 images. In total, we trained the recogni-
tion of 250 different people with 9 pictures each. All
these images where extracted from the UFI dataset.
Microsoft Face API was used as state of the art face
recognition implementation. It was trained and tested
using the same dataset.
The speech recognition module uses three inde-
pendent speech recognition libraries—Sphinx, Julius,
and Kaldi—and was also tested in different module
settings. Every configuration was exercised with 130
sentence tests from CMU’s AN4 speech recognition
dataset. As with face recognition libraries, we devel-
oped an API wrapper for all the speech recognition li-
braries. We use Google Speech API as state of the art
speech recognition system which requires no training.
5.1 Face Recognition Module Study
Table 2 presents the success rate of our tests for the
three face recognition functions evaluated individu-
ally, and the representative three module configura-
tions, namely total agreement, quorum agreement and
an intersection of the two functions that showed the
best recognition results.
The first important observation is that the efficacy
of the open source libraries is smaller than Microsoft
Face’s, which reaches 99% success rate. OpenCV
stands out as the least effective library (only 62%
success rate). The difference between OpenCV and
OpenBR stems from the algorithms they implement,
namely Eigenfaces and 4SF respectively. The small
difference between OpenBR and OpenFace comes
as a surprise, given that OpenFace implementation
uses neural networks for face recognition, theoreti-
cally more effective than OpenBR’s 4SF.
Table 2 then shows the success rate for three face
recognition module configurations. Configuration to-
tal agreement consists of a module that employs all
three libraries—OpenCV, OpenBR, and OpenFace—
and yields “success” if and only if all libraries iden-
tify the same individual. Here we can see that the face
recognition accuracy drops considerably to only 55%,
which is explained by the significant differences that
exist between the algorithms implemented by each li-
brary. In a second configuration, we used only two
libraries—OpenFace and OpenBR—and in this case
the success rate increased substantially to 81%. The
best results were achieved when we used three li-
braries, but with a merging policy function that out-
puts success every time at least two libraries produce
the same response. In this configuration (quorum), the
success rate reaches 88%, which represents a reduc-
tion of only 3% when compared to OpenFace alone.
Considering these results, we argue that the best
mechanism in merging face recognition results in an
N-version setting is to gather the majority of the re-
sults given by a module’s units. Note, however, that
result intersection is not always a sound solution. If
we consider the case where a module has fewer hon-
est units than intentionally ineffective ones, e.g., units
that produce wrong results with the goal of prevent-
ing face recognition, then the success and consequent
effectiveness of the module is compromised. In order
to address this issue, we believe a reputation based
approach for unit selection could be used.
5.2 Speech Recognition Module Study
Although, word error rate (WER) is the metric gener-
ally used to measure the accuracy of speech recogni-
tion, it cannot be applied to the situation where there
are multiple recognition results. Moreover, in a smart
home scenario, voice commands can still be inter-
preted correctly even if some words are not recog-
nized or come in a wrong order. We, therefore, opted
for a sentence match and word intersection merg-
ing functions as the main performance parameters for
speech recognition modules.
Table 4 shows the results for each library evalu-
ated based on two criteria: sentence match and word
intersection. Sentence matching consists of the ex-
act match between the entire original sentence and the
recognized result returned by each library. Word in-
tersection counts the number of words that exist in the
original sentence and are also present in the recogni-
tion results returned by the library (902 is the total
SECRYPT 2018 - International Conference on Security and Cryptography
130
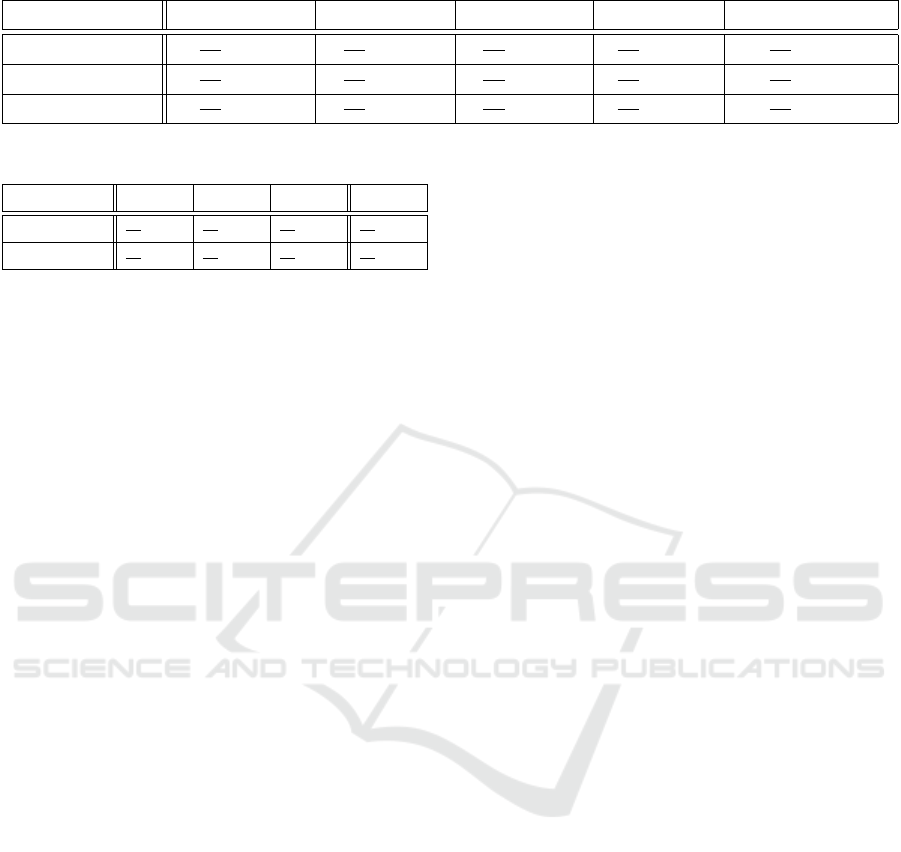
Table 3: N-version speech recognition confidence.
Decision Policy Total Agreement Sphinx ∩ Julius Sphinx ∩ Kaldi Julius ∩ Kaldi Quorum Agreement
Sentence Match
13
130
(≈10%)
13
130
(≈10%)
19
130
(≈15%)
34
130
(≈26%)
40
130
(≈31%)
Word Intersection
455
902
(≈50%)
455
902
(≈50%)
554
902
(≈61%)
557
902
(≈62%)
666
902
(≈74%)
Word Union
753
902
(≈83%)
706
902
(≈78%)
745
902
(≈83%)
735
902
(≈81%)
753
902
(≈83%)
Table 4: Speech recognition confidence.
Implementation Sphinx Julius Kaldi Google
Sentence Match
20
130
(≈15%)
36
130
(≈28%)
88
130
(≈68%)
103
130
(≈79%)
Word Intersection
578
902
(≈64%)
570
902
(≈63%)
719
902
(≈80%)
722
902
(≈80%)
number of words present in all sentences). Table 4
shows that across both these dimensions, Sphinx and
Julius clearly fall behind Kaldi, which offers the high-
est success rates (68% sentence match and 80% word
intersection). At the same time, Kaldi’ numbers are
not far off Google Speech’s.
Table 3 lists multiple module configurations that
we used to produce speech recognition functions
based on these libraries. Each entry of the table cor-
responds to a specific module configuration. The
columns indicate which libraries constitute the units
of the module, and the lines indicate the merging
function that was used to produce a successful speech
recognition output. We adopted three merging ap-
proaches: sentence match, which is similar to the cri-
teria used for the individual solutions and issues an
output if all units identified the same sentence; word
intersection, which returns only the words that all
units identified successfully; and union, which returns
the union of all words identified by all units.
As shown in Table 3, sentence match tends to yield
very poor results, displaying a success rate between
10% and 26% between any pair of units. Even when
we consider quorum agreement, i.e., when at least two
out of the three units return the same result, the suc-
cess rate only reaches 31%, which is very far from
Kaldi’s 68%. Still, given that most speech controlled
devices, e.g., Amazon Echo, use a grammar based ap-
proach, where they ask users to repeat words when
they cannot recognize some, sentence match is an un-
reasonable speech recognition metric.
With word intersection, the results improve sig-
nificantly up to 62% between any pair of units, and
up to 74% when we consider the quorum for the re-
sults produced among them. Because of the intersec-
tive nature of the merging functions sentence match
and word intersection, the adoption of an increasing
number of units does not necessarily yield better re-
sults. This happens because the overall success rate is
always bound to the performance of the worst units.
This can be seen in the last column of the table. For
instance, although the pair Julius and Kaldi yields a
62% success rate for the word intersection function,
the addition of Sphinx bounds the three units over-
all success to the result yielded by the worst Sphinx
pairing result, i.e., the result of the pair Sphinx and
Julius (50%). The table also shows that for this type of
functions the best approach is to use a quorum policy,
i.e., the consensus between at least two units, which
yielded success rates of 31% and 74% for sentence
match and word intersection respectively.
Overall the highest success rate is achieved when
word union is employed. As can be seen in the ta-
ble, the function word union yields success rates of
at least 78%, and 83% in the best case, surpassing
even Google Speech. Contrary to sentence match and
word intersection, the success rate of this function is
the same for the combination of all three units and
the quorum consensus (83%). This happens because
quorum also implies the output of all three units. As a
result, both functions produce the same output. Still,
we argue that union is not a fair result merging func-
tion for two reasons. On one hand, semantically, the
union of the output of two or more speech recogni-
tion units may differ significantly from a speech rec-
ognizer expected result. On the other hand, this union
function can potentially endanger the privacy of the
user. For instance, as long as there is one rogue unit
that extracts information from the audio source, e.g., a
voice detector that derives the number of people in the
room based on the background sound, the whole mod-
ule could be compromised, as its result would feature
that information.
After analysing these numbers we can draw three
conclusions: (1) exact sentence match is a poor
speech recognition N-version result merging func-
tion, (2) word intersection recognition success rates
are limited by the worst unit, but are reasonable
when used in a quorum consensus approach, and (3)
although word union success rates are the highest
among the configurations studied, its semantics and
privacy limitations render it unusable in merging N-
version results. Consequently, we argue that quorum-
based word intersection is the best approach of the
three in merging this type of results. Similarly to the
face recognition case, it can also be complemented
An Extended Case Study about Securing Smart Home Hubs through N-version Programming
131

0
25
50
75
100
Image
Bluring
Voice
Scrambling
Data
Encryption
Data
Hashing
K-Anonymity Speech
Recognition
Face
Recognition
Normalized execution time (%)
V1 V2 V3 QA
1.1s 294ms 341ms 19.5ms 648ms 2.2s 274ms
99.92%
96.16%
98.92%
99.97%
98.74%
94.7%
99.56%
101.29%
99.99%
99.98%
99.99%
100.01%
89.78%
75.76%
99.99%
100.58%
69.76%
71.34%
97.95%
98.97%
25.99%
49.35%
99.99%
99.99%
39.95%
99.98%
32.25%
99.99%
Figure 4: Strict and loose modules performance.
with a reputation based approach, in order to address
the issue of the intentionally ineffective sub-modules.
6 PERFORMANCE EVALUATION
This section aims at assessing the performance over-
head introduced by our approach as opposed to run-
ning a single instance of these algorithms.
6.1 Experimental Methodology
The performance evaluation comprises the execution
time measurements of each of the aforementioned N-
modules. These measurements feature the execution
time of each of the three units comprising these mod-
ules, and the execution time of the quorum and to-
tal agreement merges. Each of these measurements
consisted of computing the average of 50 tests, each
with the same input. More specifically, we chose a
1280x720 pixel image and a factor of 2 for the image
blurrer; a 10 second voice clip for the voice scram-
bler; a randomly generated 256-byte key and 1MB
plaintext for the data encryption module; 1MB worth
of randomly generated text for the data hashing mod-
ule; and a set of 100000 tuples and a K-anonymity of
500 for the K-Anonymization module. For the face
recognition module, we provided a training dataset of
150 pictures of three different people, and an addi-
tional picture as test input; and for speech recogni-
tion, we provided a general acoustic and custom lan-
guage models as knowledge base, and a voice clip as
input. The experiments were conducted on a laptop
equipped with an Intel i3-3217U 1.80GHz CPU and
4GB of RAM. Similar computing resources can be
provided by popular smart home hubs, e.g. Google
OnHub or Google Home, that feature dual- or quad-
core 1.5GHz CPUs with 512MB of RAM, which is
enough for running multiple versions of TFs.
6.2 Main Findings
Figure 4 presents the performance results of the strict
and loose modules. This figure shows the normalized
execution time of each of the modules’ units, as well
as the two merging approaches. For a matter of con-
sistency we take the TA policy as baseline. Note that
the most significant performance differences among
the different strict modules’ units relate to either inef-
fective loop implementations, or recurrent use of data
type casts. However, for the loose modules, the main
performance difference stems from units’ underlying
algorithms diversity and implementations.
The first finding is the confirmation that the paral-
lel execution nature of our approach bounds the two
merging approaches’ execution times to the slowest
unit’s execution time. This is most evident for the
strict K-anonymization V3 unit. For loose modules
the difference between unit execution times is even
more noticeable. For the speech recognition module,
V1’s execution took a quarter of the time needed to
execute V3. The same is observed for the face recog-
nition module, where V3 outperformed V2.
Secondly, there is a significant execution time dif-
ference between loose module units. Note again that
loose modules rely on heterogeneous versions. As
a result, the underlying algorithms of units and their
complexity may vary, leading to performance differ-
ences. Unlike strict modules, where the performance
of units is usually similar, the impact of the slowest
units on loose modules’ performance is higher.
The third finding relates to the cost of the merging
approaches. While we defined the TA policy as base-
line to compare the performance of the three units and
merging approaches, we can see that quorum agree-
ment is sometimes more expensive than total agree-
ment. This happens because, total agreement implies
at most two comparisons, i.e., between V1 and V2,
and between V2 and V3, while quorum agreement,
in the worst case, requires three comparisons to yield
a result. On the other hand, in the best case, quorum
agreement can be achieved with one comparison only.
SECRYPT 2018 - International Conference on Security and Cryptography
132

7 DISCUSSION
Traditionally, NVP has raised two main objections.
First, N-version is regarded as demanding significant
human resources to implement the N different soft-
ware versions. However, considering our targeted
scenario, this concern may be alleviated by relying
on open source communities for the development
of TF implementations. In fact, such communities
have shown good results in maintaining large scale
projects, e.g., Debian packages, python modules, and
IoT specific ones, e.g., apps and automation recipes.
A second objection to NVP is the connotation
of poor failure diversity among independent ver-
sions (Knight and Leveson, 1986). With this respect,
it has also been shown (Knight and Leveson, 1986)
that statistically, the number of common errors is rela-
tively low and the diversity of implementations makes
the overall system robust to failures. Therefore, it
is hard for an adversary to exploit a common flaw
across all the N-version modules. Although at a small
scale, our software flaw study seems to confirm this
idea, since in five different TFs, common flaws oc-
curred only once. Even so, although this occurrence
was detected by simple debugging tools, another rea-
son behind it could be our specification effectiveness,
which was not experimentally tested. Nevertheless,
NVP considerably raises the bar for adversaries since
the number of latent vulnerabilities would be smaller
compared to single version executions.
Our approach’s open source nature may also hin-
der TF utility, as the number of naive or malicious
TF units outputting incorrect results may be higher
than that of correct units. We propose two approaches
to address this issue. First, a TF developer reputa-
tion scheme could provide insights regarding the ef-
fectiveness of a TF unit. This information could then
be used to filter unwanted units when packaging mod-
ules. Second, at least for loose modules, their ef-
fectiveness could benefit from commercial software,
which from our experience, requires little adaptation
effort with our approach.
Performance-wise, the QA policy’s positive re-
sults seem to suggest that the impact of the slowest
unit for both loose and strict modules can be elimi-
nated by taking advantage of unit redundancy. Instead
of waiting for the slowest unit to finish, the decision
block may process unit outputs up until a majority
is formed. This approach addresses the performance
problem and provides a reasonable tradeoff between
module performance and user privacy.
As for malicious behaviour it is not in our scope
to prevent malicious application attacks. This holds
true for both attacks targeting hub security mecha-
nisms, e.g., sandboxing, and TF module security, e.g.,
bug exploitation by sending crafted inputs to modules.
Nevertheless, to address TF module security, our de-
sign could be complemented with unit address space
randomization techniques (Cox et al., 2006).
8 RELATED WORK
NVP (Chen and Avizienis, 1978) has originally been
used to reduce the likelihood of errors and bugs in-
troduced during the software development. Multiple
independent teams of programmers developed several
versions of the same software and then ran these im-
plementations in parallel.
Since then, NVP has been used in several fields.
Veeraraghavan et al. (Veeraraghavan et al., 2011) pro-
pose multiple replicas of a program to be executed
with complementary thread schedules to identify and
eliminate data race bugs that can cause errors at run-
time. DieHard (Berger and Zorn, 2006) uses ran-
domized heap memory placement for each replica to
protect the software from memory errors, e.g. buffer
overflow or dangling pointers. Imamura et al. (Ima-
mura et al., 2002) applies N-version programming
in the context of genetics to reduce the number and
variance of errors produced in genetic programming.
Some systems (Cadar and Hosek, 2012; Giuffrida
et al., 2013), apply N-version to the process of updat-
ing software, in order to detect and recover from er-
rors and bugs introduced by the new versions. While
these approaches assume there is only one developer
of multiple software versions, we assume multiple in-
dependent developers and versions.
CloudAV (Oberheide et al., 2008) provides an-
tivirus capabilities as a network service and leverages
NVP to achieve better detection of malicious soft-
ware. However, nothing prevents it from exploiting
private user data. Demotek (Goirizelaia et al., 2008)
employs N-version to enhance the reliability and se-
curity of several components comprising an e-voting
system. Still, it assumes the modules are honest, and
its main goal is to make it difficult for an attacker to
compromise the whole system. Overall, none of the
aforementioned systems rely on N-version to boot-
strap trust in system components, focusing instead on
improving reliability and availability.
Additionally, NVP has been used to detect and
prevent system security attacks such as inadvertent
memory access (Cox et al., 2006; Salamat et al.,
2009). This, however, requires a custom memory al-
location manager and modifications to the OS kernel.
Moreover, these systems trust multiple versions of the
same software and assume only the input data to be
An Extended Case Study about Securing Smart Home Hubs through N-version Programming
133

potentially malicious. NVP has also been leveraged to
ensure personal information confidentiality and pre-
vent information leaks. Most of these systems employ
techniques in which two replicas of the same soft-
ware are executed with different inputs (Yumerefendi
et al., 2007), under different restrictions (Capizzi
et al., 2008) or on different security levels (Devriese
and Piessens, 2010). To the best of our knowledge,
our work is the first to study the feasibility of NVP in
securing smart hub platforms.
9 CONCLUSIONS
In this paper, we performed an extensive study on
the use of NVP in order to enhance the security of
TF-based smart hub platforms, which deal with home
sensitive data. Our work comprises a thorough study
on both strict and loose trusted function specifica-
tions. The results provide insights on our approach’s
effectiveness, and foster discussion surrounding util-
ity, performance, and security issues associated with
naive and malicious implementation output results.
ACKNOWLEDGEMENTS
We thank the anonymous reviewers for their com-
ments and suggestions. This work was partially
supported by Fundac¸
˜
ao para a Ci
ˆ
encia e Tecnolo-
gia (FCT) via projects UID/CEC/50021/2013 and
SFRH/BSAB/135236/2017.
REFERENCES
Berger, E. D. and Zorn, B. G. (2006). Diehard: probabilis-
tic memory safety for unsafe languages. In Proc. of
PLDI.
Cadar, C. and Hosek, P. (2012). Multi-version software up-
dates. In Proc. of ICSE.
Capizzi, R., Longo, A., Venkatakrishnan, V., and Sistla,
A. P. (2008). Preventing information leaks through
shadow executions. In Proc. of ACSAC.
Chen, L. and Avizienis, A. (1978). N-version programming:
A fault-tolerance approach to reliability of software
operation. In Proc. of FTCS-8.
Computerworld (2016). Chinese Firm Admits Its Hacked
Products Were Behind Friday’s DDOS Attack.
http://www.computerworld.com/article/3134097. Ac-
cessed May 2018.
Cox, B., Evans, D., Filipi, A., Rowanhill, J., Hu, W., David-
son, J., Knight, J., Nguyen-Tuong, A., and Hiser, J.
(2006). N-variant systems: A secretless framework
for security through diversity. In Proc. of Usenix Se-
curity.
Davies, N., Taft, N., Satyanarayanan, M., Clinch, S., and
Amos, B. (2016). Privacy Mediators: Helping IoT
Cross the Chasm. In Proc. of HotMobile.
Devriese, D. and Piessens, F. (2010). Noninterference
through secure multi-execution. In Proc. of SP.
Fernandes, E., Jung, J., and Prakash, A. (2016a). Security
Analysis of Emerging Smart Home Applications. In
Proc. of SP.
Fernandes, E., Paupore, J., Rahmati, A., Simionato, D.,
Conti, M., and Prakash, A. (2016b). FlowFence: Prac-
tical Data Protection for Emerging IoT Application
Frameworks. In Proc. of USENIX Security.
Forbes (2013). When ’Smart Homes’ Get Hacked.
http://www.forbes.com/sites/kashmirhill/2013/07/26/
smart-homes-hack. Accessed May 2018.
Giuffrida, C., Iorgulescu, C., Kuijsten, A., and Tanenbaum,
A. S. (2013). Back to the future: Fault-tolerant live
update with time-traveling state transfer. In Proc. of
LISA.
Goirizelaia, I., Selker, T., Huarte, M., and Unzilla, J.
(2008). An Optical Scan E-Voting System Based on
N-Version Programming. IEEE Security & Privacy,
6(3):47–53.
Imamura, K., Heckendorn, R. B., Soule, T., and Foster, J. A.
(2002). N-Version Genetic Programming via Fault
Masking. In Proc. of EUROGP.
Kelion, L. (2012). Trendnet security flaw exposes
video feeds. http://www.bbc.com/news/technology-
16919664. Accessed May 2018.
Knight, J. C. and Leveson, N. G. (1986). An Experimen-
tal Evaluation of the Assumption of Independence in
Multiversion Programming. IEEE Transactions on
Software Engineering, pages 96–109.
Mortier, R., Zhao, J., Crowcroft, J., Wang, L., Li, Q., Had-
dadi, H., Amar, Y., Crabtree, A., Colley, J. A., Lodge,
T., Brown, T., McAuley, D., and Greenhalgh, C.
(2016). Personal Data Management with the Databox:
What’s Inside the Box? In Proc. WCAN CoNEXT.
Oberheide, J., Cooke, E., and Jahanian, F. (2008). CloudAV:
N-Version Antivirus in the Network Cloud. In Proc.
of USENIX Security.
Salamat, B., Jackson, T., Gal, A., and Franz, M. (2009).
Orchestra: intrusion detection using parallel execution
and monitoring of program variants in user-space. In
Proc. of EuroSys.
Veeraraghavan, K., Chen, P. M., Flinn, J., and
Narayanasamy, S. (2011). Detecting and surviving
data races using complementary schedules. In Proc.
of SOSP.
Yumerefendi, A. R., Mickle, B., and Cox, L. P. (2007).
Tightlip: Keeping applications from spilling the
beans. In Proc. of NSDI.
SECRYPT 2018 - International Conference on Security and Cryptography
134
