
Generation of Multiple Choice Questions Including Panoramic
Information using Linked Data
Fumika Okuhara, Yuichi Sei, Yasuyuki Tahara and Akihiko Ohsuga
Graduate School of Informatics and Engineering, The University of Electro-Communications, Tokyo, Japan
Keywords:
Panoramic Information, Linked Data, Multiple Choice Question, Semantic Web.
Abstract:
In recent years, just about all subjects require students to learn panoramic information. Because the need
exists for cross-curriculum learning aimed at relating subject areas, it is useful for multiple-choice questions
to include panoramic information for learners. A question including panoramic information refers to content
that includes transverse related information and makes respondents grasp the whole knowledge. However, it
is costly to manually generate and collect appropriate multiple-choice questions for questioners and learners.
Therefore, in this research, we propose a method for the automatic generation of multiple-choice questions
including panoramic information using Linked Data. Linked Data is graphical data that can link structured
data, and it is used as a technology for data integration and utilization. Some attempts have been made to use
Linked Data as a resource for creating teaching material, and the possibility of using Semantic Web technology
in education has been verified. In this paper, we aim to realize a system for automatically generating two types
of multiple-choice questions by implementing an approach to generating questions and choices. An evaluation
method for the generation of questions and choices involves setting indicators for each evaluation item, such
as validity and the degree of the inclusion of panoramic information.
1 INTRODUCTION
Each school has a curriculum and students should le-
arn based on it. Regarding the importance of curri-
culum management, the Central Council for Educa-
tion mentioned the need for “improving educational
activities based on a cross-curriculum perspective”
(Ministry of Education, Culture, Sports, Science and
Technology, 2015). In other words, panoramic lear-
ning is necessary for learning all subjects.
The multiple-choice-question format is widely
used for qualification exams, certification examinati-
ons, and the like. This format is useful because it ena-
bles the quick, easy, and objective scoring of large-
scale exams. In addition, because completing these
exams simply involves “choosing the correct answer
from the choices,” responding to each question is a
highly efficient process (Ikegami, 2015). Therefore,
the format may be suitable for testing a large number
of people, helping learners to demonstrate their kno-
wledge of a wide range of fields easily, and enabling
questioners to evaluate a wide range of questions from
units.
Based on the above, multiple-choice questions
including panoramic information have been deemed
useful for both learners and questioners. Howe-
ver, manually generating and collecting appropriate
multiple-choice questions is costly. In this paper, we
propose a method for automatically generating que-
stions including panoramic information based on the
given curriculum, and evaluating them.
With our proposed method, Linked Data is used as
a knowledge base, and questions and incorrect choi-
ces for a correct answer set are generated based on the
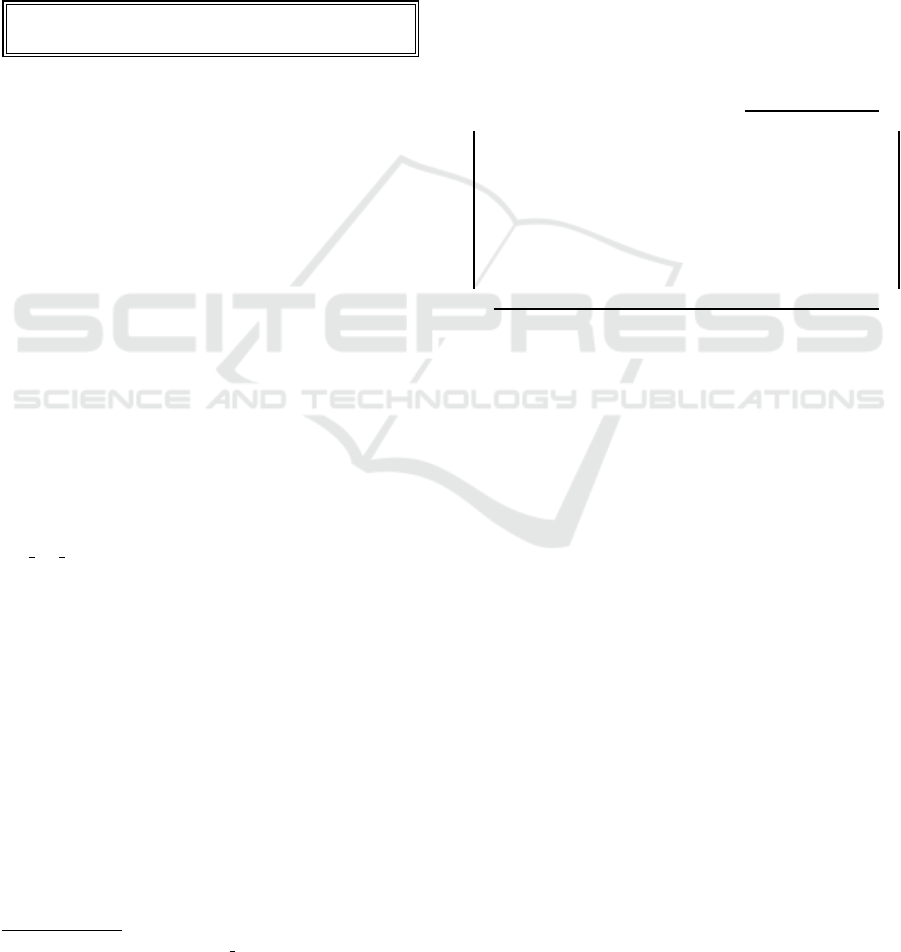
curriculum. Figure 1 displays an output image of the
proposed system. In this system, the output is gene-
rated by setting any curriculum and selection of unit
as the input, extracting the keywords included in the
curriculum, selecting the keywords to set in Answers,
and configuring questions and incorrect choices with
Wikipedia data. The output is the components of the
multiple choice question. Using the Wikipedia data
which the format expressed the relationship between
these data, the question can include relevant data and
the relationships between the answer and can be one
including panoramic information. In the current rese-
arch study for evaluation of this system, requirements
were set for the generation of questions and choices,
and evaluation experiments were conducted based on
the evaluation items. These experiments included in-
110
Okuhara, F., Sei, Y., Tahara, Y. and Ohsuga, A.
Generation of Multiple Choice Questions Including Panoramic Information using Linked Data.
DOI: 10.5220/0007259301100120
In Proceedings of the 11th International Conference on Agents and Artificial Intelligence (ICAART 2019), pages 110-120
ISBN: 978-989-758-350-6
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

dices of the degree of inclusion of the panoramic in-
formation set, and in the result of the experiment, the
questions made by proposed method tended to have
more panoramic information than one made by com-
parison method.
The article is organized as follows: Section 2 the
related research studies; Sections 3 and 4 highlight
the purpose of this research and the proposed method
used; Sections 5 and 6 provide the implementation
method, some evaluation method and the results of
the evaluation experiments; Section 7 present the dis-
cussion; and finally, Section 8 states the conclusion
and future work.
Figure 1: An Example of output image of multiple choice
questions generated by the proposed system.
2 RELATED RESEARCH
Linked Data, as an existing technology, has been used
for the generation of questions. Linked Data is struc-
tured graphical data that Tim Berners-Lee proposed;
data sets are linked with one another using the Web
mechanism. Linked open data (hereinafter referred
to as LOD) is Linked Data that is published on the
Web. LOD represents a data format that anyone can
freely use, with various kinds of open data being lin-
ked with each other through municipalities or institu-
tions. The LOD cloud
1
, representing links between
available LOD, contains more than 1,000 data sets as
of May 2018. Activities related to LOD are being
carried out in various fields. Among them is DBpe-
dia
2
which turns the well-known Wikipedia data into
a Linked Data format. DBpedia Japanese
3
which is a
Japanese version, also exists, turning the information
in the InfoBox of Japanese Wikipedia into a Linked
Data format.
1
http://lod-cloud.net
2
http://dbpedia.org
3
http://ja.dbpedia.org
Research (Iijima et al., 2016) has also proposed a
method of presenting an unexpected connection bet-
ween multiple data sets by using Linked Data techno-
logy, which can be applied to a recommendation sy-
stem. (Maillot et al., 2014) presented a method for
extracting the targeted subpart of resource descrip-
tion framework (RDF) bases, driven by a list of se-
lected resources called the seed. In addition, a rese-
arch study in the Semantic Web field, by Demarchi
F. et al. (Demarchi et al., 2018) proposed an imple-
mentation that would allow agents to access ontolo-
gies that are available on the Web so as to update their
beliefs based on significant content. A case study of
an educational quiz is also presented that used the in-
formation to formulate the questions and to validate
the answers obtained.
Several attempts have been made to use Linked
Data as a resource for generating teaching materials
in the education field.
In ASSESS (B
¨
uhmann et al., 2015), attempted to
generate questions in several formats in the specific
field of general knowledge using LOD. Based on this
attempt, it is possible to generate questions in natural
language by summarizing an entity based on DBpe-
dia and verbalizing the RDF. In addition, the choices
corresponding to each format of questions are imple-
mented by using LOD. Papasalouros et al. also pre-
sented a method of generation multiple-choice questi-
ons in natural language from Semantic Web Rule Lan-
guage rules which is interpreted so that if the antece-
dent holds, then the consequent must also hold; in the
simple form antecedent ⇒ consequent (Papasalouros
et al., 2008) (Zoumpatianos et al., 2011). Also, Rocha
et al. attempted generation questions that had resour-
ces that were relevant to a specific domain or topic
from a dataset (Rocha et al., 2018), and Afzal et al.
presented generation questions regarding the impor-
tant concepts that presented in a domain by relying on
the unsupervised relation extraction approach as ex-
tracted semantic relations (Afzal and Mitkov, 2014).
Furthermore, researchers in a study generated an
evaluation model of the incorrect choices created in
multiple-choice questions (Pho et al., 2015). The mo-
del was generated to enable the automatic evaluation
of the quality of the incorrect choices that the author
manually created. The model focuses on the syntactic
and semantic similarity between the choices, treating
them as elements related to the quality of these choi-
ces. Meanwhile, (Patra and Saha, 2018) considered
closeness between the key and the possible distractors
by using web information in their proposed system
for automatic named entity distractor generation. A
research study involved the generation of a historical
ontology that used LOD to generate history questions
Generation of Multiple Choice Questions Including Panoramic Information using Linked Data
111

(Jouault et al., 2016). In this research, a question-
setting system based on a learning scenario was in-
cluded. Specifically, Grasser’s classification method,
which classified multiple knowledge bases and ques-
tion formats, was used. Statistical data, such as the
degree of difficulty of each test item, is used when
constructing an examination test from a large num-
ber and a wide range of questions. In other words,
when evaluating learning achievement through an ex-
amination test, it is necessary to set items at difficulty
levels that are considered the preset passing marks.
As a study on the difficulty level of an examination
test, (Ikeda et al., 2013) proposed a difficulty level es-
timation method focusing on the similarity between
the question pattern and the choices of the multiple-
choice question, and evaluating this based on the dif-
ficulty parameter of the item response theory (IRT).
In these related works, the possibility of using Se-
mantic Web technology has been verified against the
theme of generating test questions. However, these
proposed systems can generate only uniform ques-
tions and choices for keywords with these methods.
As a result, the multiple-choice questions feature sim-
ple content, such as “What is {person’s name} birth
place?” and “Which work is made by {person’s
name}?”, that contains only one or two matters con-
cerning the answer in examination sentences. Also,
there is a possibility that the questions are in a narrow
field since their resource of the questions is composed
of highly relevant contents. Therefore, in this rese-
arch, we aimed to generate questions including more
panoramic information.
3 PURPOSE
The purpose of this research is to propose a method
for automatic generation of multiple choice questions
including panoramic information. Panoramic infor-
mation means comprehensive information that gives
us macro-perspective; through which us look down
at the whole learning subjects. A question including
panoramic information refers to content that includes
transverse related information and makes respondents
grasp the whole knowledge.
In the use scenario of the question generation sy-
stem, a person who sets examination questions and
learners can be seen as users of the system. The exam
preparer may be able to reduce costs such as time and
effort for creating test questions by using a system
into which a curriculum, including evaluation items,
is input. In addition, learners’ use scenarios include
self-study and exercise test questions.
Figure 1 shows an example of an output of multi-
ple choice questions generated by this method. In the
system, output is generated by setting any curriculum
and selection of unit as input, extracting the keywords
included in the curriculum, selecting the keywords to
set in Answers, and configuring questions and incor-
rect choices with Wikipedia data. The output is the
components of the multiple choice question. There
are “Question” which is a sentence of the test ques-
tion, “Answer” which is a correct answer choice and
“Distractors” which are incorrect choices. In this re-
search, a graph is taken as a Question and referred to
as the“Question Graph”. From the linked structure of
the graph and the sentence in question, it can be un-
derstood that the answer has some relationships that
include a philosopher studied in the class, a person
who had connections to peripatetic school and one
of whose notable idea was syllogism, is a person in
the era of ancient philosophy, and influenced Socra-
tes. When selecting vocabulary that corresponds to
the answer that satisfies all these relationships from
five choices, “Aristotle” becomes the correct answer,
and the remaining choices become incorrect.
4 PROPOSED METHOD
This section explains the generation approaches of
Question Graph and distractors for arbitrary answer.
Incidentally, it is possible to use DBpedia, DBpedia
Japanese, etc. as a knowledge base.
4.1 Approaches to Generating the
Question Graph
The Question Graph is generated by searching triple
structures for an answer that regards an RDF graph
visualizing the relationship between the acquired in-
formation as a question sentence. In other words, a
Question Graph is a test question format that hides
an element corresponding to the answer in the graph
and guesses it from some words around it and their
properties. Then, the graph itself is defined as a ques-
tion. Since the matter to be questioned in the Question
Graph is related to the data around Answer, there is
no need to document it, and as shown in Figure 1, it is
presented as “Question graph,” which is a graph as a
Question. There is existing research [Fionda 17] that
proposes an algorithm to search all subgraph structu-
res among multiple data sets (Fionda and Pirr
`
o, 2017).
In our approach, a searching method considering
the following requirements is devised.
ICAART 2019 - 11th International Conference on Agents and Artificial Intelligence
112

4.1.1 Requirements of Generating the Question
Graph
The requirements to be satisfied as the Question
Graph are set as follows. In particular, the items sta-
ting (Mandatory) are essential requirements.
Requirements of Question Graph
(1) (Mandatory) Each node consists of key-
words.
(2) (Mandatory) Ensure the connectivity of in-
formation around Answer.
(3) Include panoramic information as much as
possible on the entire graph.
(4) Scale of the graph can help grasp all its con-
tent.
(5) The number of vocabulary words correspon-
ding to the answer is extremely small.
4.1.2 Method of Generating a Question Graph
We devised a method to generate a Question Graph.
The requirements below are based on an RDF graph
using DBpedia.
Question Generation Algorithm for Single Se-
lection Form
The following describes the method of generating
question graphs for single choice questions. In this
format, the Answer node has one or more answer in
the graph, and respondents answer select one from
some choices.
The graph for an answer is generated by exten-
ding the link structures of data around Answer by se-
arching for neighbor nodes to the answer node, further
searching from neighbor nodes to each of their neig-
hbor nodes repeatedly. The link structure between the
nodes is formed by directed links of IN and OUT. In
the process of searching the link structures, the se-
arch range and the number of times are restricted pre-
liminarily in order to make the graph, considering the
scale based on requirement (4). Regarding the num-
ber of searches, when searching for neighbor nodes
by 1 hop with respect to the answer node, the number
of hops is determined as the search depth h. The se-
arch range defines the number of each of the directed
link structures of IN and OUT at the same depth h as
the search width w. This method generates a Question
Graph with a scale satisfying the restrictions of h and
w. In particular, considering the degree of inclusion of
panoramic information based on requirement (3), we
propose a search method in which all neighbor nodes
after the answer node are absolutely distant from the
origin.
We devised the following Algorithms 1 and 2 as
the basic algorithms for generating Question Graphs
for answers.
Algorithm 1: Main.
Input: KG G, Answer, depth h, width w
Output: KG
1: N
S
= get f ar nodes(Answer, {}, G, h,w)
2: M
S
= get all links(N
S
)
3: return (N
S
, M
S
)
Algorithm 2: get far nodes.
Input: Node target, Set of ancestor nodes Ancestors, KG G, depth
h, width w
Output: Set of nodes
1: N = {target}
2: if |Ancestors| == h then
3: return N
4: end if
5: count = 0
6: for direction ∈ {IN, OU T } do
7: B = neighbors(target, direction)
8: while count < w AND 0 < |B| do
9: f lg = True
10: n = arg max
n
0
∈B
dist(target, n
0
)
11: B = B\{n}
12: for n
j
∈ Ancestors do
13: if dist(n
j
, n) < dist(n
j
,target) then
14: f lg = False
15: end if
16: end for
17: if f lg then
18: count = count + 1
19: N = N ∪ get f ar nodes(n, Ancestors ∪
{target},G, h, w)
20: end if
21: end while
22: count = 0
23: end for
24: return N
The Main algorithm acquires all node sets rela-
ting to information around Answer, then acquires all
the node sets’ link structures and returns this infor-
mation as the subgraphs. As input, the algorithm is
given the knowledge graph KG (Knowledge Graph)
G, the correct Answer, the search depth h, the search
depth w, on the knowledge base as the output. The
subgraph consists of a set of all nodes N
s
and a set of
link structures between nodes M
s
.
The get far nodes algorithm returns all the nodes
in the subgraphs relating to the target node. A graph
on Answer can be finally obtained by specifying Ans-
wer as the default of target. From lines 6 to 23, the
graph extends searching neighbor nodes for each di-
rected link of target. In order to obtain the neighbor
node of the target, the function of neighbors that re-
turn the neighbor node set in line 7 is defined and
used. In line.10, the neighbor node whose distance to
the target is the maximum is returned by the function
Generation of Multiple Choice Questions Including Panoramic Information using Linked Data
113
dist that finds the distance between specified nodes.
In line.12, the distance comparison between the neig-
hbor node and all its ancestors and the distance bet-
ween the target and all ancestors is recursively repe-
ated up to the search depth of h. This ensures that the
distance between all nodes, from the Answer node to
the neighbor node, will always be farther away. Fi-
nally, all the node sets are returned, and a subgraph
consisting of all node sets and their link structures as
a Question Graph is obtained.
Based on the algorithm, we aim to generate a
graph with a compact scale and a high degree of pa-
noramic information inclusion.
Question Generation Algorithm for Multiple
Selection Form
The following describes the method for generating
question graphs in multiple-choice question form.
Because this question format requires answers with
multiple choices, it should be guaranteed that there
are that two or more words corresponding to Answer
nodes on the graph. Therefore, in requirement (5),
the number of words corresponding to the answer is
adjusted.
In this approach, the vocabulary corresponding to
the Answer node is necessarily greater than the spe-
cified number nA when depth h = 1. First, if there
are nA words in the knowledge base corresponding
to nodes that have all neighbor nodes acquired by the
neighbors function, adopt them as the neighbor nodes
on the graph. The algorithm keeps a panoramic de-
gree as much as possible by checking this from the
vocabulary with the largest distance in order. After
that, getting a combination of all nodes adjacent to
Answer, and acquires multiple words that can be app-
lied to the Answer node. For h = 2 and later, the graph
is completed by connecting neighbor nodes with the
get all nodes procedure.
In addition to the above basic algorithm, we also
consider the major degree of vocabulary this time. For
weighting measures, we used the Balanced Corpus of
Contemporary Written Japanese; (BCCWJ) by “Cor-
pus Development Center, NINJAL”
4
. The vocabulary
of the textbook sub-corpus (OT) was set to 1.0, the
history and social science classifications among libra-
ries and the publication sub-corpus (LB and PB) were
set to 0.5, and the other was set to 0.0. This was ap-
plied by adding it to the dist function so that the vo-
cabulary existing in the corpus could be more easily
adopted. In addition, each node of depth h = 1, is pre-
ferentially adopted when the vocabulary of corpus OT
exists in the inquiry result from the knowledge base.
From the above basic procedures, a Question
4
http://pj.ninjal.ac.jp/corpus center/bccwj/
Graph on the answer is generated.
4.2 Approach to Generating Distractors
Since distractors are nodes that do not correspond to
an answer in the Question Graph, they can be genera-
ted by searching for nodes that do not satisfy all the
link structures with the answer (even if one of them is
satisfied). Therefore, we explore the method of gene-
rating distractors using the Question Graph generated
above.
4.2.1 Requirements of Generating Distractors
The requirements to be satisfied by distractors we set
as follows.
Requirements of Distractors
(1) (Mandatory) Each node consists of key-
words.
(2) (Mandatory) Incorrect answer to the Ques-
tion.
(3) Avoid words clearly recognized as incorrect
answers.
4.2.2 Method of Generating Distractors
From requirement (3), in order to generate distrac-
tors that are not clearly recognized as incorrect ans-
wers, a vocabulary set similar to the Answer should
be selected. Vocabularies similar to the answer can be
thought that the link structures on the knowledge base
are similar to one of the Answer. From this, distractor
candidates are generated from the adjacent link struc-
tures of answers by using the Question Graph genera-
ted by the above method.
First, a set of adjacent link structures for an answer
is extracted from the Question Graph. We regard the
words corresponding to a node that satisfies a set of
other link structures only when deleting one or more
links from the extracted set as distractor candidates.
Furthermore, referring to the acquisition method
of (Pho et al., 2015), narrowing down the words
belonging to the same class as answer on DBpedia
among the candidates. If an answer belongs to more
than one class, it is immediately rated class C, which
is the lowest class; that is, the direct class C of the ans-
wer is an instance, but not an instance of that subclass.
Finally, candidates corresponding to the objects obtai-
ned as a property of class C are adopted.
As a method of adopting from a candidate to an
option, we adopt them from the one with the smallest
ICAART 2019 - 11th International Conference on Agents and Artificial Intelligence
114

difference between the distances to the neighbor no-
des and largest degree of popularity. Figure 2 shows
the generating steps.
Figure 2: Generating step of Distractors based on the met-
hod.
5 IMPLEMENTATION
The implementation of generation of Question
Graphs and distractors by the above approach is
described below. We use DBpedia Japanese as a
knowledge base and set the SPARQL endpoint to
“http://ja.dbpedia.org/sparql/”.
In this research, we set social studies subjects (ge-
ography, history, citizens etc.) especially as the dom-
ain of questions. In addition, we selected words defi-
ned as article titles or categories on Wikipedia in ad-
vance and used them as keywords for answers. For
implementation, no curriculum is set, and the voca-
bulary on DBpedia are set as the keywords.
5.1 Generating the Question Graph
As described in the previous section, a Question
Graph is generated by collecting information around
the answer via SPARQL query and then visualizing
the RDF graph.
In defining the dist function in Algorithm 2 above,
we use value of similarity based on the pre-learned
model of word2vec
5
(Suzuki et al., 2016) as a compa-
rable index between words syntactically and semanti-
cally.
In the visualization of graphs, the words around
the answer and the relationships between them are
drawn using Graphviz.
5
http://www.cl.ecei.tohoku.ac.jp/
∼
m-suzuki/
jawiki vector/
For example, the following Figure 3 shows the
Question Graph generated based on the RDF graph
for Answer = “Socrates.” Here, the Answer node is
red, the vocabulary of the corpus OT is blue, the cor-
pus’ LB and PB are green, and other items are grey.
5.2 Generating Distractors
As in the above approach, distractors are generated by
obtaining some instances belonging to the same class
C as an answer by using the link structures with the
answer node.
Table 1 summarizes distractor candidates genera-
ted by Answer =“Socrates”.
Table 1: Distractors on Answer=“Socrates”.
links Answer/Distractors candidates{total}
(0,1,2,3,4,5) Socrates {1}
(3,4) Heraclitus {1}
(0) Diogenes (cynic school) {1}
(1) Immanuel Kant {1}
(2) John Stuart Mil {1}
(3) Anakusagorasu {1}
6 EVALUATION
For the generated Question Graph and distractors, the
evaluation method corresponding to each of the above
requirements is described below. In this evaluation,
the search depth of the Question Graph was set to
h = 2 and the width to w = 2. We selected the ap-
propriate Answer, but this time, for the evaluation of
distractors, set words with Answers to which nobody
were supposed not to know the correct answer.
6.1 Evaluation Method for Question
Graph Generation
Evaluation items for the Question Graph requirements
are listed below.
Generation of Multiple Choice Questions Including Panoramic Information using Linked Data
115
Figure 3: The Question Graph on Answer=“Socrates”.
Question Graph Evaluation items
1
Consistency...[Requirement (2)]
• Answer corresponding to correct answer.
2
The degree of inclusion of panoramic infor-
mation...[Requirement (3)]
• The degree of crossing classes of each
node
• The degree of crossing units on the curri-
culum
• The degree of crossing time
3
Specificity...[Requirement (5)]
• Smallness of words corresponding to the
Answer
4
Readability...[Requirement (4)]
• Compactness of the graph scale
The following two evaluation experiments were
conducted on the second item regarding the degree of
inclusion of panoramic information, and on the third
item regarding specificity.
6.1.1 Evaluation Method for Degree of Inclusion
of Panoramic Information
Since a specific curriculum is not set, the first and
third evaluation items are implemented. The first item
is an index of how far across the classes in the know-
ledge base used to generate the Question Graph are.
In this case, we examined the classes to which vo-
cabulary belongs from Class “Thing” and below in all
classes on DBpedia. In the evaluation, only nodes that
can be acquired from DBpedia are subject to calcula-
tion for the classes.
6.1.2 Specificity Evaluation Method
For the generated graph, the number of words cor-
responding to the answer node is also evaluated. It
expresses the smallness of the number of correct al-
ternative answer from the question graph when the
choices are ignored. The number of corresponding
words becomes clear by searching nodes that have all
of the same link structure as the Answer.
6.2 Evaluating Method of Generating
Distractors
Evaluation items for the requirements of distractors
are listed below.
Distractor evaluation items
1
Incorrect answer to the Question
Graph...[Requirement (2)]
2
The validity of those who do not know the
correct answer is less than one out of the
number of choices...[Requirement (3)]
3
The magnitude of similarity to the ans-
wer...[Requirement (3)]
In particular, for the second and third evalua-
tion items, the following evaluation experiments were
conducted.
6.2.1 Comparison of Validities by Experimental
Subject
By comparing the validity to the actual generated que-
stions in subjective experiments, we verified whether
ICAART 2019 - 11th International Conference on Agents and Artificial Intelligence
116

the validity were less than one out of number of the
choices.
6.2.2 Comparison of Similarity between the
Answer and Choices
We compared similarities among the obtained distrac-
tors. From the syntactic and semantic aspects, the fol-
lowing indexes of similarity comparison are listed.
• Syntactic similarity
For both answer and distractor candidates, com-
pare both the parts of speech and the composition
patterns of the words. In this case, we used Cabo-
Cha
6
as a parsing tool and compared both depen-
dency and part of speech, verifying whether they
matched.
• Semantic similarity
There are methods of comparison based on
indexes of evaluation models in (Pho et al.,
2015) and comparison by item analysis in
(Mitkov et al., 2009); by type of vocabulary
{PersonLocationOrganization}; by “DBpedia en-
tity”, which is a semantic index using entities gi-
ven to vocabulary on DBpedia; and by calcula-
ting and comparing “wup similarity,” which is
a semantic index using the distance in WordNet
vocabulary hierarchical structure. For the time
being, similarity was calculated by a pre-learned
word2vec model.
6.3 Results
For the execution environment, we used MacBook
Pro for PC and macOS High Sierra for OS. In this
system, SPARQL ran with the library SPARQLWrap-
per
7
as the language to be used in Python. We also
measured the execution time for question genera-
tion for 10 set Answers. The Question Graph requi-
red 76.66 seconds to read the pre-learned model of
word2vec only once upon execution, and the time of
Question Graph generation for each subsequent ques-
tion was 13.09 sec. The time needed to generate dis-
tractors was on average 3.575 sec for each of the que-
stions.
In the experiment, a Question Graphs, three Dis-
tractors and an Answer were set as a question set. In
addition, we made 10 questions in a single answer for-
mat (hereinafter referred to as ”single-answer form”)
and 5 questions for multiple answer formats (herein-
after referred to as ”multiple-answer form”).
6
https://taku910.github.io/cabocha/
7
https://rdflib.github.io/sparqlwrapper/
6.3.1 Results of Question Graph: Evaluation
Method for Degree of Inclusion of
Panoramic Information
For the evaluation of the degree of inclusion of pa-
noramic information, we summarized the number of
classes in one graph as the degree of crossing classes
in Tables 2.
Table 2: The degree of crossing classes (single-answer
form).
Q. number of nodes number of classes
proposal random proposal random
1 21 21 7 5
2 21 17 5 3
3 21 21 6 5
4 21 21 6 7
5 21 21 3 8
6 21 21 8 5
7 21 19 6 7
8 21 21 6 3
9 21 21 3 3
10 21 21 6 3
Ave. 21 20.4 5.6 4.9
6.3.2 Results of Question Graph: Specificity
Evaluation Method
Regarding the 10 Question Graphs generated in
single-answer form, we queried the vocabulary set
corresponding to the Answers node on DBpedia, and
it was all empty except for Answer. In multiple-
answer form, when two answers were specified, all
the graphs were such that there were only two words
corresponding to Answer nodes. Therefore, it can be
said that the evaluation items of specificity were sa-
tisfied by this experiment.
6.3.3 Results of Distractors: Comparison of
Validities by Experimental Subject
Results by subjective experiment are shown. In Table
3 and Figure 4, results obtained from 37 subjects are
summarized, including the validity for single-answer
form. Similarly, for the multiple-answer form, the re-
sults of 23 respondents are summarized.
6.3.4 Comparison of Similarity between the
Answer and Choices
For each distractor using the dist function (proposal)
and random generation (random); random selection of
the neighbor nodes of each target node from all nodes
that have links of the target node, similarity compa-
rison by syntactic pattern (pattern) and the results of
similarity comparison by pre-learned word2vec mo-
del (word2vec) are shown in Table 4. In the table, the
Generation of Multiple Choice Questions Including Panoramic Information using Linked Data
117
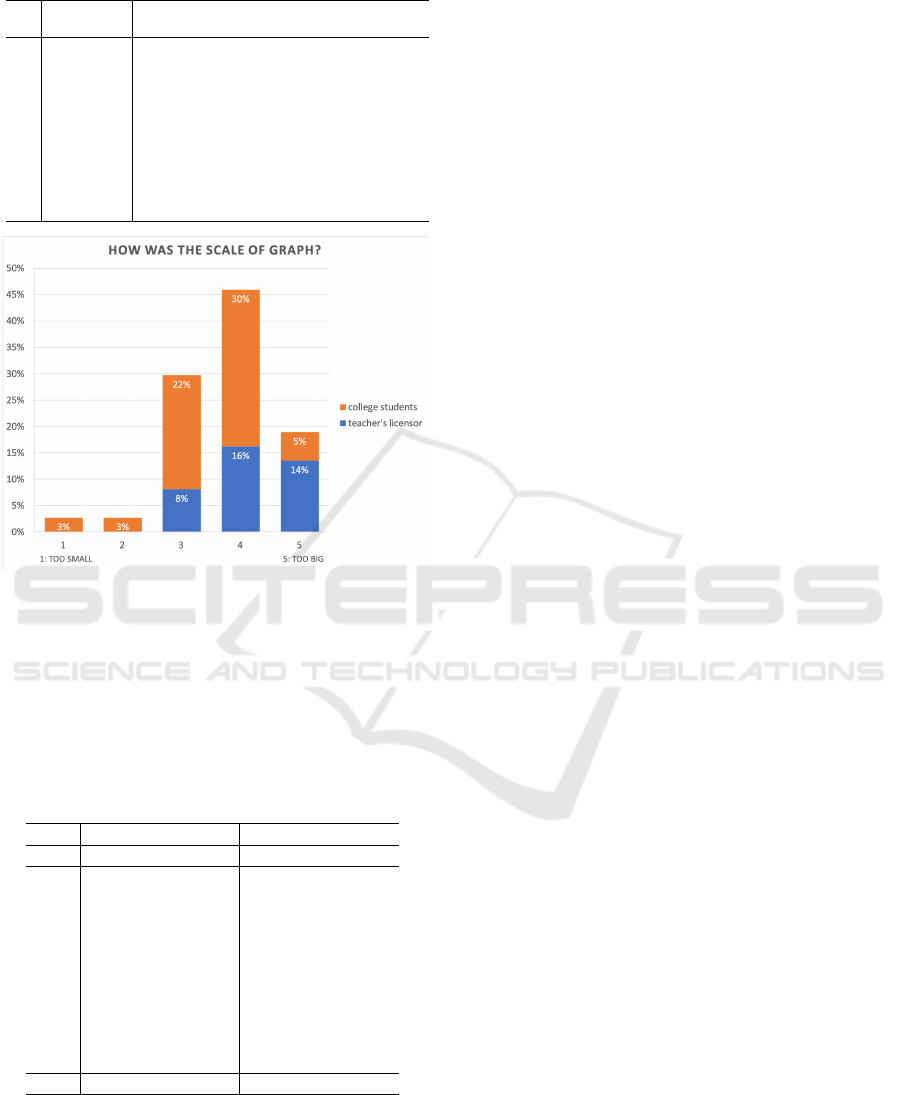
Table 3: The validity in experiment (single-answer form).
Q. validity[%] selectivity of Distractors (descending)[%]
D1 D2 D3
1 64.9 24.3 8.09 2.67
2 21.6 59.4 5.36 3.56
3 21.6 48.6 18.9 10.8
4 13.5 70.3 13.5 2.67
5 40.5 32.5 18.9 8.09
6 13.6 54.0 21.6 10.8
7 91.9 8.1 0.00 0.00
8 56.8 35.1 5.41 2.69
9 21.6 40.5 29.7 8.09
10 18.9 35.1 29.7 16.2
Figure 4: Questionnaire:“Scale of Question Graphs”.
“pattern” value is set as 1 if the pattern matches the
answer, and “word2vec” indicates the similarity with
Answer. Each value is the average of the values per
question; that is, it is the value of similarity per dis-
tractor.
Table 4: Comparison of similarity between Answer and
Distractors generated by proposed method and random
(single-answer form).
Q. pattern word2vec
proposal random proposal random
1 2 2 .613 .330
2 2 2 .305 .248
3 2 1 .451 .364
4 3 1 .359 .325
5 3 2 .801 .369
6 2 0 .438 .534
7 3 0 .354 .179
8 2 1 .557 .360
9 0 2 .475 .463
10 0 2 .671 .510
Ave. 1.9 1.3 .503 .368
7 DISCUSSION
In terms of implementation, we set the vocabulary on
DBpedia as the learned keyword without setting the
curriculum, so it was obvious that mandatory require-
ments (1), “each node consists of keywords,” and (2),
“ensure the connectivity of information around Ans-
wer,” were satisfied in the Question Graph. On the
other hand, if setting any curriculum and keywords
exist on Linked Data to be used, the requirements are
satisfied and the method can be used. Also, if the ans-
wer is a special vocabulary, there is a possibility that
any link structures may not be found and the gene-
ration will fail theoretically. However, it seems that
the major vocabulary such as those that appear in the
examination and its relationships are largely covered
by LOD like DBpedia. Regarding requirement (3),
“the degree of inclusion of panoramic information,”
the proposal was exceeded the random by an average
of 0.7 classes (as seen in Table 2).
From this, with respect to the index on the number
of classes, the degree of panoramic information was
greater by proposal than by random generation in the
experiment. Regarding “scale of the graph” in requi-
rement (4), the results of the questionnaire on subject
experiments in Figure 4 showed that 4 out of 5 eva-
luations occurred most frequently in this experiment.
Therefore, the scale was large based on the subjects
chosen. Finally, regarding “the number of words cor-
responding to Answer node” in requirement (5), the
requirement was satisfied since there were no words
corresponding to the answer nodes except on answers
in the 15 graphs.
Regarding distractors, mandatory requirement (1),
“each node consists of keywords,” and (2), “incor-
rect answer to the question,” are satisfied from the ge-
neration approach in the experiment. Regarding the
second evaluation of Requirement (3), “avoid words
that are clearly recognized as incorrect answers,” in
the case all subjects do not know the correct answer,
it is desirable that the correct answer rate for each que-
stion is one out of the number of choices; 1/4 =25%
or less. For that evaluation, six questions in single-
answer form satisfied the index. Questions 1, 5, 7 and
8 did not. Among the four unsatisfied examples, in
Q.7, only one out of the three distractors was selected,
so it was a remarkable result that did not satisfy the
requirement. Regarding the multiple formats, the dif-
ference in the selectivity between distractors is less
than 13%, and the selectivity was not biased. Next, in
Table 4, results of the random is evaluation of Distrac-
tors generated by extracting randomly from words be-
longing to the same class as the answer on DBpedia.
In these indexes, the proposal tended to have more si-
ICAART 2019 - 11th International Conference on Agents and Artificial Intelligence
118

milar Distractors with Answer than random.
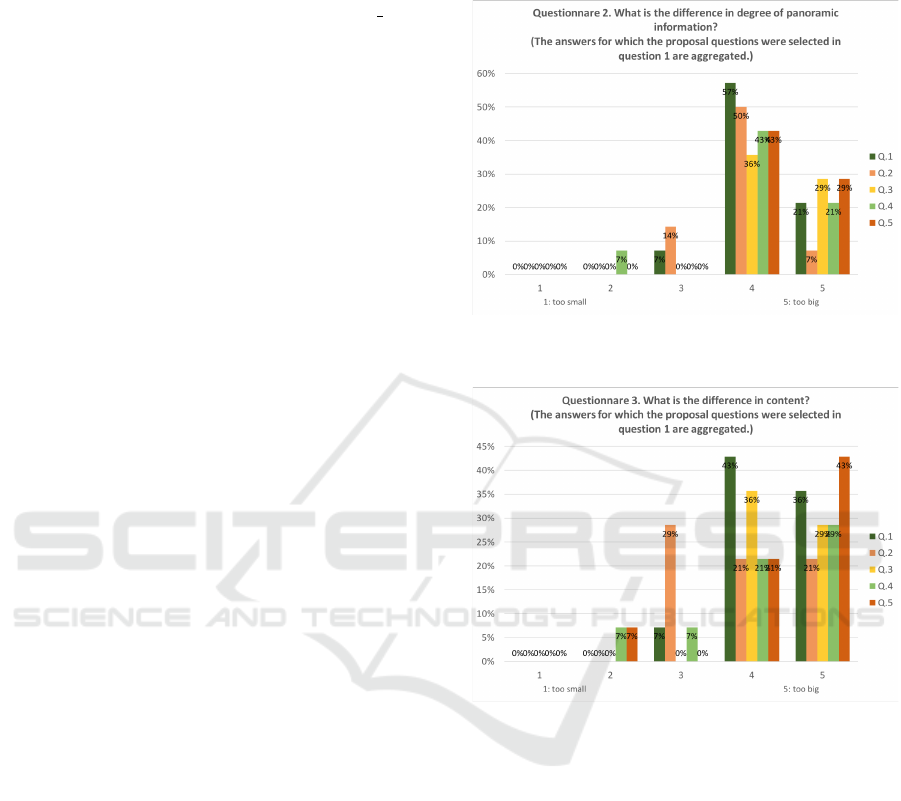
In this study, we conducted a questionnaire to
compare with existing questions (The Japanese His-
tory Aptitude Testing Foundation, 2017) (The Japa-
nese History Aptitude Testing Foundation, 2018) for
14 teachers’ license holders. For the five single-
answer forms, we got responses mainly on “degree of
panoramic information”. An average of 72.8% ans-
wered that the degree of panoramic of proposed que-
stions were higher than the random in Questionnaire
1. In addition, Figures 5 and 6 show the evaluation re-
sults of the degree of panoramic information and con-
tent. Not only the difference in degree of panoramic
information but also in content shows a big impres-
sion overall.
8 CONCLUSION
In this paper, we proposed a method of generating
multiple-choice questions including panoramic infor-
mation. Prospects are listed below.
In the proposed method, we considered the dis-
tance between nodes to generate a graph including
panoramic information, but did not consider the mea-
ning of links between nodes. To generate intentional
test questions, not only the nodes should be conside-
red, but also the types of links. In the evaluation of
the degree of inclusion of panoramic information, we
evaluated based on the three items; degree of cros-
sing classes, the degree of crossing time, which was
impossible with only these indexes. Therefore, we
should review the current evaluation indexes, clarify
the definition of the degree of panoramic information,
and set up an evaluation index based on it to conduct
experiments. Currently, it is necessary to analyze how
this index influences the degree of the whole graph. In
consequence, Distractors generated by proposed met-
hod tend to be more similar than the random as the
evaluation indexes of pattern and word2vec.
In the generation of distractors, if the class to
which an answer belongs is not unique, only one
kind of candidate apparently different from the ans-
wer may be generated, so this process should be im-
proved. Also, to deal with synonyms between choi-
ces, we will establish a verification phase using Word-
Net
8
.
Also, as a new question form application of this
proposal, a combination question is considered. The
combination question is often seen in Japanese his-
tory and world history examinations of the National
Center Test for University Admissions
9
, which is a
8
https://wordnet.princeton.edu
9
https://www.dnc.ac.jp/center/
format that answers combinations of answers in diffe-
rent questions from choices. We are considering that
there should be a demand for this format.
In the future, we aim to improve the method of
automatically generating questions considering pano-
ramic information by reviewing the approaches and
evaluation method for Question Graphs and distrac-
tors.
ACKNOWLEDGEMENTS
This work was supported by JSPS KAKENHI Grant
Numbers JJP16K00419, JP16K12411, JP17H04705,
JP18H03229, JP18H03340 and JP18K19835.
REFERENCES
Afzal, N. and Mitkov, R. (2014). Automatic generation of
multiple choice questions using dependency-based se-
mantic relations. Soft Computing, 18(7):1269–1281.
B
¨
uhmann, L., Usbeck, R., and Ngomo, A.-C. N. (2015).
Assessautomatic self-assessment using linked data. In
International Semantic Web Conference, pages 76–89.
Springer.
Demarchi, F., Santos, E. R., and Silveira, R. A. (2018). Inte-
gration between agents and remote ontologies for the
use of content on the semantic web. In Proceedings of
the 10th International Conference on Agents and Ar-
tificial Intelligence - Volume 1: ICAART,, pages 125–
132. INSTICC, SciTePress.
Fionda, V. and Pirr
`
o, G. (2017). Meta structures in know-
ledge graphs. In International Semantic Web Confe-
rence, pages 296–312. Springer.
Iijima, T., Kawamura, T., Sei, Y., Tahara, Y., and Ohsuga, A.
(2016). Sake selection support application for coun-
tryside tourism. In Transactions on Large-Scale Data-
and Knowledge-Centered Systems XXVII, pages 19–
30. Springer.
Ikeda, S., Takagi, T., Takagi, M., and Teshigawara, Y.
(2013). A proposal and evaluation of a method of es-
timating the difficulty of items focused on item types
and similarity of choices. Journal of Information Pro-
cessing, 54(1):33–44.
Ikegami, M. (2015). Comparison of strategy use bet-
ween different item format types on multiple-choice
grammar test. Studies in Language and Literature,
35(1):55–72. (in Japanese).
Jouault, C., Seta, K., and Hayashi, Y. (2016). Content-
dependent question generation using lod for history
learning in open learning space. New Generation
Computing, 34(4):367–394.
Maillot, P., Raimbault, T., Genest, D., and Loiseau, S.
(2014). Targeted linked-data extractor. In Procee-
dings of the 6th International Conference on Agents
and Artificial Intelligence - Volume 1: ICAART,, pa-
ges 336–341. INSTICC, SciTePress.
Generation of Multiple Choice Questions Including Panoramic Information using Linked Data
119
Ministry of Education, Culture, Sports, Science and
Technology (2015). The 100th primary and secondary
education subcommitteehandouts 1-1 4. necessary
measures to realize the philosophy of government gui-
delines for teaching. http://www.mext.go.jp/b menu/
shingi/chukyo/chukyo3/siryo/attach/1364319.htm.
Mitkov, R., Ha, L. A., Varga, A., and Rello, L. (2009).
Semantic similarity of distractors in multiple-choice
tests: extrinsic evaluation. In Proceedings of the
Workshop on Geometrical Models of Natural Lan-
guage Semantics, pages 49–56. Association for Com-
putational Linguistics.
Papasalouros, A., Kanaris, K., and Kotis, K. (2008). Au-
tomatic generation of multiple choice questions from
domain ontologies. In e-Learning, pages 427–434. Ci-
teseer.
Patra, R. and Saha, S. K. (2018). A hybrid approach for
automatic generation of named entity distractors for
multiple choice questions. Education and Information
Technologies, pages 1–21.
Pho, V.-M., Ligozat, A.-L., and Grau, B. (2015). Distrac-
tor quality evaluation in multiple choice questions. In
International Conference on Artificial Intelligence in
Education, pages 377–386. Springer.
Rocha, O. R., Zucker, C. F., and Giboin, A. (2018). Ex-
traction of relevant resources and questions from db-
pedia to automatically generate quizzes on specific
domains. In International Conference on Intelligent
Tutoring Systems, pages 380–385. Springer.
Suzuki, M., Matsuda, K., Sekine, S., Okazaki, N., and Inui,
K. (2016). Neural joint learning for classifying wi-
kipedia articles into fine-grained named entity types.
In Proceedings of the 30th Pacific Asia Conference
on Language, Information and Computation: Posters,
pages 535–544.
The Japanese History Aptitude Testing Foundation (2017).
The Japanese History Aptitude Testing Foundation in
2016, the 35th time, question collection of all the
grade, pp.29-pp.67.
The Japanese History Aptitude Testing Foundation (2018).
The Japanese History Aptitude Testing in 2017, the
36th time, question collection of all the grade, pp.33-
pp.75.
Zoumpatianos, K., Papasalouros, A., and Kotis, K. (2011).
Automated transformation of swrl rules into multiple-
choice questions. In FLAIRS conference, volume 11,
pages 570–575.
A Questionnaire Results in
Evaluation Experiment
Figure 5: Questionnairem 2: “Comparison of differences in
degree of panoramic information”.
Figure 6: Questionnaire 3: “Comparison of differences in
degree of information contents”.
ICAART 2019 - 11th International Conference on Agents and Artificial Intelligence
120
