
Improving Video Object Detection by Seq-Bbox Matching
Hatem Belhassen
1,2,3
, Heng Zhang
1
, Virginie Fresse
2
and El-Bay Bourennane
3
1
Beamtek SAS, 145 Rue Gustave Eiffel, 69330 Meyzieu, France
2
Hubert Curien Laboratory, Jean Monnet University, Saint Etienne, France
3
Univ of Burgundy - Franche-Comte, LE2I laboratory, France
Keywords:
Video Understanding, Real-time Video Object Detection, Online Object Detection.
Abstract:
Video object detection has drawn more and more attention in recent years. Compared with object detection
from image, object detection in video is more useful in many practical applications, e.g. self-driving cars,
smart video surveillance, etc. It is highly required to build a fast, reliable and low-cost video-based object
detection system for these applications. In this work, we propose a novel, simple and highly effective box-
level post-processing method to improve the accuracy of video object detection. The proposed method is
based on both online and an offline sett ings. Our experiments on ImageNet object detection from video (VID)
dataset show that our method brings important accuracy gains, especially t o more challenging fast-moving
object detection, with quite light computational overhead in both settings. Applied to YOLOv3, our system
achieves so far the best speed/accuracy trade-off for offline video object detection and competitive detection
improvements for online object detection.
1 INTRODUCTION
Despite the great success of object detec tion from
image, object detection in vid e o is still challenging
due to m otion blu r, rare pose, camera defocus, etc.
State-of-the-art works focus on utilizing contextual
and temporal information to overcome these effects.
(Zhu an d al., 2017) improved video object detection
accuracy on two levels: box level and feature le-
vel. Even though feature-level methods are gene-
rally considered to achieve a higher improvement than
box-level methods in terms of accuracy. But w e
have to consider that models optimized by feature le-
vel methods need to b e trained on vide o-based data-
sets, w hich a re more difficult to create, less available,
and usually contain fewer object categories compa-
red with image-based dataset. So , box-level meth ods
are still important as they can be used as a comple-
mentary to feature-level methods, (e.g., Flow-Guided
Feature Aggregation (Zhu and al., 2017) (FGFA for
short) use box-level methods on the basis o f their pro-
posed feature-level method to improve video object
detection accura cy). Moreover, box-level methods
can be implemented on detectors trained on more
common image-based dataset (e.g. Microsoft-COCO,
Pascal VOC, etc), which makes them more universal
and practical for industrial applications.
Existing box-level metho ds mostly rely on optical
flow, ob je ct trac king (Kang and al., 2016) or heavy
bounding box (bbox) across time sorting (Han and al.,
2016). However, op tical flow is naturally expensive
in terms of computatio nal complexity and has no di-
rect relation with th e main task of object detection.
The use of object tracking adds a heavy computatio-
nal overhead which makes the detection system less
effective. As reported by (Han and al., 2 016), bbox
across time sorting (Han and al., 2016) is more ef-
fective than other box-level methods, while it still
adds a heavy computational overhead and can not be
applied to online video object detection.
Our work aims to desig n a novel, simple and
much more e ffective box-level post-processing met-
hod. It ca n be applied to online or offline video ob -
ject detection, to replace existing box-level methods.
The principle is rescoring b boxes and linking tubelets
(which are essentially sequ e nces of associated bboxes
across time) to avoid wrong or missed detectio ns cau-
sed by low-quality f rames in videos. Our proposed
method, name d Seq-Bbox Matching, is a sim ple and
effective method to matc h bboxes across time to ge-
nerate tubelets. The proposed following steps, na-
med Frame-level Bbox Rescoring and Tubelet-level
Bbox Linking, are applied to improve offline object
detection. Then we modified our Frame-level Bbox
Rescoring to adapt it to online object detection.
Experiments on ImageNet (Russakovsky and al.,
2014) VID dataset prove the effectiven e ss of our met-
hod. It brings important accuracy gains, especially
226
Belhassen, H., Zhang, H., Fresse, V. and Bourennane, E.
Improving Video Object Detection by Seq-Bbox Matching.
DOI: 10.5220/0007260002260233
In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2019), pages 226-233
ISBN: 978-989-758-354-4
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

to more challenging fast-moving objec ts, with quite
light computational overhead in both settings. Ap-
plied to YOLOv3 (Redmon and Farhadi, 2018), our
system achieves so far the best speed/accuracy trade-
off for offline video object d e te ction and competitive
accuracy improvements f or online object detection,
e.g., 80.9% of mAP on our offline setting and 78.2%
of mAP on online setting both at 38 fps on a Titan X
GPU or at 51 fps on a GTX 1080Ti GPU.
Key contributions of this paper are:
• Our proposed box-level post-processing method
achieves important accuracy improvements to per-
frame detection baseline for both online and off-
line settings, e.g, applied to YOLOv3, our met-
hod brings 6 .9% of mAP gains (from 74% to
80.9%) for offline object detection and 4.2% of
mAP gains (fro m 74% to 78.2%) for online de-
tection on ImageNet VI D validation set;
• Quite light computational overhead in both set-
tings makes our method applicable in most practi-
cal vision applications, i.e., less than 2.5ms/frame
additional computation for both settings;
• Our proposed method could be applied to de-
tectors trained on video-based dataset or image-
based dataset, which makes it more universal and
practical for industrial app lica tions.
This paper is organized as follows. In Section
2, we sum up some representative related works on
image/video object detection. In Section 3, we ex-
plain the theoretical details of our proposed box-level
post-processing method. In Section 4 , we present our
experimental results on ImageNet VID dataset and
compare our results with other state-of-art methods.
Section 5 concludes the paper.
2 RELATED WORK
In this section we present related works for both
image and video detection and th en p osition our con-
tribution regarding the state-of-the-art works.
2.1 Object Detection from Image
Object detection fr om image is one of the most central
study areas in computer vision. Detector s based on
deep neural network greatly exceeds the accuracy of
classic object detectors based on h and-designed fea-
tures, e.g., Viola-Jones (Viola and Jones, 2004), DPM
(Felzenszwalb and al., 2010), etc. Modern convolu-
tional object de tectors can be divided into two para-
digms: Two-stage objec t detectors and Single-stage
object detectors. According to (Huang and al., 2016),
the former are generally more accurate while the latter
are usually faster.
The domina nt paradigm is b ased on a two-stage
approa c h, which firstly generates a spar se set of re-
gions of interest (RoIs) then classifies these regions
and refines their bboxes. Faster R-CNN (Ren and al.,
2015) introduces the Region Pro posal Network (RPN)
that generates RoIs and shares full-image convolutio-
nal features with Fast R-CNN (Girshick, 2015). R-
FCN (Dai and al., 2016) proposes position-sensitive
score maps to share almost a ll computation on the en-
tire ima ge.
Single-stage detectors perform objec t classifica-
tion and bounding box regression simu ltaneously on
feature maps. YOLO (Redmon and al., 2015) divides
the image in to regions and predicts bound ing boxes
and classification scores for each region. SSD (Liu
and al., 2015) predicts classification scores and bbox
adjustments of each default boxes of different aspect
ratios and scales per feature map location. RetinaNet
(Lin and al., 2017) proposes a novel loss function, Fo-
cal Loss, to address class imbalance pro blem.
While evaluating CNNs on Microsof t-COCO da-
taset, the r ecently proposed YOLOv3 (Red mon and
Farhadi, 2018) achieves competitive accur acy (60.6%
of AP
50
) with state-of-the-art more complicated ob-
ject detectors, e.g., R-FCN (51.9% of AP
50
) or Reti-
naNet (57.5% of AP
50
) and it detects at a much faster
detection sp eed (YOLOv3 at 20 fps, R-FCN at 12 fps
and RetinaNet at 5 fps on a Titan X GPU).
2.2 Object Detection in Video
Object detection in video has drawn more an d more
attention in recent years. The introduction of Ima-
geNet (Russakovsky a nd al., 2014) object detection
from video (VID) challenge made the evaluation of
CNN designed for video easier. Instead of simply
split the video into frames and perform per-frame ob-
ject detection, re cent works focus on utilizing contex-
tual and temporal information to accelerate de tection
speed or to improve detection accuracy.
In terms of improving accuracy, recent works are
designed on two levels: bo x level and feature level.
For box-level methods: T-CNN (Kang and
al., 2016) u ses pre-computed optical flow and ob-
ject tracking to p ropagate high-confidence bounding
boxes to nearby fra mes; Seq-NMS (Han and al.,
2016) uses high-scoring object detections from ne-
arby frames to boost scores of weaker detections
within the same video clip.
Feature-level methods are generally considered to
achieve a more impor tant impr ovemen t than box-level
methods. FGFA (Zhu and al., 2017) uses optical flow
Improving Video Object Detection by Seq-Bbox Matching
227

and nearby frame feature maps to reinforce current fe-
ature map and imp rove object d etection per formanc e .
Detect to Track and Track to Detect (Feichtenhofer
and al., 2017) (D&T for short) introduces a Con-
vNet architectu re th at jointly performs detection and
tracking. Scale-Time Lattice (Chen and al., 2018)
proposes a novel architecture to re a llocate the com-
putation over a scale-time space.
2.3 Contribution Positioning Regarding
the State-of-Art Works
We chose YOLOv3 as our base ob je ct detector thanks
to its good speed / accuracy tr ade-off. Our proposed
method is different from all previous works in video:
Firstly, instead of utilizing object tracking (e.g ., T-
CNN a nd D&T) or heavy bbox across time sorting
(e.g., Seq -NMS), we intr oduce Seq-Bbox Matching,
which matches detected bboxes of the same appea-
red object to generate tu belets. Secondly, apart from
tubelet rescoring (implemented in T-CNN, Seq-NMS,
D&T and Sca le-Time Lattice), we added another step,
named Tubelet-level Bbox Linking, to infer missed de-
tections and improve detection recall.
3 IMPROVING VIDEO OBJECT
DETECTION BY SEQ-BBOX
MATCHING
3.1 Overview
So far, object detection from image has achieved great
success while object detection in video is still chal-
lenging. For one thing , motio n blur, rare pose, ca-
mera defocus and other effects in videos will lead to
wrong or missed detections. For another, temporal
and contextual information can be helpful to improve
detection a c curacy.
In principle, our method can be applied to any
kind of existing object detector (e.g., YOLOv3, SSD,
RetinaNet, R-FCN, Faster-RCNN, etc). It consists of
two m ain steps: Firstly, the Frame-level Bbox Res-
coring to correct wrong detections and secondly the
Tubelet-level Bbox Linking designed to infer bboxes
of missed detections. These two steps are based on
one basic operation: Seq-Bbox Matching.
Seq-Bbox Matching aims to match detected
bboxes of the same appeared object to generate tube-
lets. To accelerate the detection speed, we implement
object detection sparsely and apply Bbox Bilinear In-
terpolation to intermedia frames.
Section 3.2 explains how Seq-Bbox Matching
works. Section 3.3 and 3.4 describes how we apply
Frame-level Bbox Rescoring and Tubelet-level Bbox
Linking respectively. In section 3.5, we modified our
Frame-level Bbox Rescoring to ad a pt it to online vi-
deo object detection . Finally, in section 3.6, we intro-
duce the application of Bbox Bilinear Interpolation to
accelerate the detection speed.
3.2 Seq-Bbox Matching
We match current-frame detected bboxes with
previous-frame detected bboxes according to their ge-
ographical closeness and semantic similarity. M at-
ched bboxes are conside red as same objects detected
in different frames. Matching distance of two bboxes
is defined as below:
distance =
1
similarity
=
1
IoU × (V ctr
i
·V ctr
j
)
(1)
Where the Intersection over Union (IoU ) b etween
two bboxes descr ibes the geographical closeness, and
the d ot product of two classification score vectors
(V ctr
i
for bbox i and V ctr
j
for bbox j) represents th e
semantic similarity of any two bboxes. Obviously, if
IoU or th e do t product equals to zero, the returned
distance would be infinity. But this hardly ever hap-
pens in videos since the IoU is g reater than 20% for
two successive images in 99.91% o f the cases, in Ima-
geNet V ID validation d ataset.
Algorithm 1: Matching algorithm for detected bboxes in
nearby frames.
Input: I bboxes detected in previous frame and
J bboxes detected in current frame
distance_matrix = create_matrix(I,J)
for i = 1 to I do
for j = 1 to J do
set distance_matrix(i,j) to distance between
i-th bbox of previous frame and j-th bbox of
current frame
end for
end for
set pairs to empty list
repeat
set i,j to line, column of minimum value in
distance_matrix
add (i,j) to pairs
set i-th line of distance_matrix to infinity
set j-th column of distance_matrix to infinity
until minimum value of distance_matrix is infinity
Output: pairs
Algorithm 1 (pseudo code) summarizes our matching
algorithm : For I bboxes detected in the previous
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
228

frame and J bboxes detected in current frame, we ge-
nerate a distance matrix where each element of coor-
donate (i, j) represents the distance betwee n i − th
bbox of previous frame and j − th bbox of c urrent
frame; We simply match the bbox pair with mini-
mal distance then cut out their connections with other
bboxes by setting the line and the column of the se-
lected element in th e distance matrix to infinity. We
repeat this step until there exists no more connections
between any two bboxes, i.e., the minimal distan ce in
the distance matrix becomes infinity.
3.3 Frame-level Bbox Rescoring
Figure 1: Frame-level Bbox Rescoring.
As shown in Figure 1, we adopt a simple rescoring
method, named Frame-level Bbox Rescoring, to avoid
object classification error c aused by motion blur, rare
pose or other reasons. As nearby frames are simi-
lar and usually contain a certain num ber of moving
objects, we consider detection results in multiple ne-
arby frames as multiple detection results of the same
objects. We match detected bboxes in previous and
current frame according to Algorithm 1 to generate
tubelets and then simply rescore all the bboxes of the
same tubelet by averaging their classification scores.
Even if there exists several wro ng detectio ns (e.g., on
the central image of Figure 1, the bird is w rongly de-
tected as zebra due to motion blur), after averaging
along the whole tubelet, these error s can be corrected.
3.4 Tubelet-level Bbox Linking
As shown in Figure 2, we add a simple tubelet lin-
king method, named Tubelet-level Bbox Linking, to
infer missed detections and improve recall. Similar as
Algorithm 1, but instead of matching previous-frame
bboxes with current-frame bboxes, we try to match
the last bbox of one tubelet and the first bbox of anot-
her. Note that we mark isolated bboxes, i.e., bbo xes
that are never matched af te r going through the whole
video, as first and last bboxes of tube lets in the same
Figure 2: Tubelet-level Bbox Linking. Zoom for details.
time, because they are considered as tu belets of length
one.
We set a thresh κ to make sure that two tubelets
are not temporally too far. Tubelets with a temporal
interval longer than κ fram es are ignored to be mat-
ched.
If the last bbox of one tubelet and the first bbox
of another match, their two tubelets are considered as
detection of a same object and there might be m issed
detections between these two tu belets. As shown in
equation (4), we infer the locations of th e intermedia
missed bboxes between matched tubelets by bilinear
interpolation of matched bboxes and the classification
scores are calculated as the averaged scores of two
matched tubelets w.r.t the lengths of tubelets.
V ctr
add
=
Cnt
f
Cnt
l
+Cnt
l
V ctr
f
+
Cnt
l
Cnt
f
+Cnt
l
V ctr
l
(2)
We use ∗
f
for former tubelet and ∗
l
for later tube-
let.
Along these lines, Tubelet-level Bbox Linking
helps to infer m issed detections and improve de-
tection recall, e.g., the missed detections of lizard (b e -
cause o f rare pose) in the central two images of Figure
2 are refound by our Tubelet-level Bbox Linking. Sup-
pressing bboxes by utilizing contextual information or
tubelet information cou ld eventually further improve
the detection accuracy, but fo r simplicity, we leave it
for future work.
3.5 Online Frame-level Bbox Rescoring
It is meaningful to propose an online object detection
method as it is a common scenario in many real-time
computer vision applications, e.g., self-driving cars.
Online video object detection asks to perform objec t
detection in an image flow witho ut access to future
frames or overall contextual information, which is not
the ca se of the previously presented two steps. So we
modified our Frame-level Bbox Rescoring to adapt it
to online video treatments.
Instead of rescoring bboxes of a tubelet after goin g
Improving Video Object Detection by Seq-Bbox Matching
229

through all th e vid eo, each time on e bbox is ma t-
ched, we update its classification scores by averaging
all historical classification scores of the same objec t.
This is realized by applying a dynamic averaging met-
hod: we add a count variable f or ea ch b box, and each
time a bbox is matched, its variable count increases.
The averaged historical classification score vector of
current bbox becomes:
V ctr
cur
=
V ctr
cur
Cnt
pre
+ 1
+
Cnt
pre
Cnt
pre
+ 1
V ctr
pre
(3)
and then:
Cnt
cur
= Cnt
pre
+ 1 (4)
We use Cnt for Count, ∗
cur
for current an d ∗
pre
for
previous.
In this way, our Frame-level Bbox Rescoring
could be performed through an online manner and the
last bbox of one tubelet holds the averaged classifica-
tion scores of the whole tubelet.
3.6 Bbox Bilinear Interpolation
If we divide the trajectory of a moving ob je ct into
many short pieces, these short pieces could be seen as
short-range nearly uniform movements. In this case,
we only need to perform detection in sparse keyfra-
mes. Object positions of interme dia frames could be
estimated by Bilinear Interpolation of positions of the
two nearby keyframes. We adopt bilinear interpola-
tion of matched bboxes for intermedia positions re-
construction to accelerate the detection. We introduce
a hyperparameter β to control the length of interme-
dia frames for Bilinea r Interpolation. β is proporti-
onal to the detection speed (in f ps), e.g., β=1 repre-
sents that our detection speed is two times faster. Ho-
wever, if β becom e s too large, the movements bet-
ween sp a rse keyframes are too complicated to be seen
as nearly uniform movements which will lead to de -
tection accuracy drop.
Adaptive Bbox Bilinear Interpolation interval
could obviou sly further improve the speed/accuracy
trade-off, which is left for future work.
4 EXPERIMENTS
4.1 Experimental Setting
4.1.1 Dataset
All experiments are conducted on the ImageNet (Rus-
sakovsky and al., 201 4) object detection from video
(VID) dataset. It is a large scale video-based dataset,
that consists of 3862 video clip s for training, 555 for
validation and 93 7 for testing. Ea c h clip is fully anno-
tated with bounding boxes of 30 different object clas-
ses. Challenges of this data set include camera defo-
cus, partial occlusion, mo tion blur, crowded instance,
backgr ound confusion, rare pose, etc. Since the an-
notations of the test set are not publicly available, we
evaluate ou r method on the evaluation set using the
mean Average Precision (mAP) metric. For motion-
specific evaluation, we use the code provided by (Zhu
and al., 2017).
4.1.2 Implementation Details
Similar as (Kang and al., 2016), (Zhu and al., 2017),
(Feichtenhofer and al., 2017) and (Chen and al.,
2018), we combine the Imagenet DET train set and
VID train set to train our base object detection model.
As DET dataset has more object classes than VID da-
taset (200 for DET vs 3 0 for VID), we suppress ima-
ges without target classes and only preserve annotati-
ons for the 30 target classes in the DET dataset. The
VID set is presented in the fo rm of videos. We do not
use these videos directly because of the redundancy
between nearby frames. We sample the VID train set
by a certain percentage to maintain a r atio of 1:1 bet-
ween DET train set and VID train set in the final train
set (55k images for each set).
Among all state-of-the-art convolutional object
detectors, we choose the recently proposed YOLOv3
(Redmon an d Farhadi, 2018) as our per-frame object
detector thanks to its good speed/accuracy trade-off.
Following (Redm on and Farhadi, 2018) and ( Redmon
and Farhadi, 20 16), we im plement k-means to deter-
mine the anchor scales and aspect ratios of each de-
tection layer. Our mode l is pre-trained on imagene t
classification task, then we fintune it on our training
set with the learning rate 0.001 for the first 80k iterati-
ons and 0.00 01 for the last 30 k iterations. All training
are performed on two GTX 1080Ti GPUs with batch
size 64. After 110k iter ations, the tr aining loss con-
verged. Note that a s YOLOv3 has a fully convolu-
tional architecture and uses m ulti-scale training, our
trained model can be evaluated at different resoluti-
ons. It achieves 74% of mAP at resolution 608 × 608
and 71.2% at 416 × 416 on VID validation set.
For inference phase, after per-frame de nse de-
tection, we first apply non-maximum suppression
(NMS) with a threshold 0.55 to select bboxes to be
matched on ea ch frame. Then we apply respecti-
vely the two settin gs of our box-level post-processing
method: For offline seting, we perform successively
Frame-level Bbox Rescoring and Tubelet-level Bbox
Linking as presented previously (Section 3 .3 an d 3.4);
For online setting, we simply apply Online Frame-
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
230
level Bbox Rescoring (Section 3.5). We use different
input image resolution s, different temporal intervals β
for Bbox Bilinear Interpolation and different thresh κ
for Tubelet-level Bbox Linking to explore the ir impact
on detection speed and accuracy.
4.2 Results
4.2.1 Speed/Accuracy Curve
We summarize the speed/accuracy curve of our met-
hod applied to our trained model at two resolutions
(608 × 608 and 416 ×416) on two settings (offline and
online) in Figure 3. Runtimes are evaluated by frame
per second (fps) on a Titan X GPU and accuracy are
evaluated by the conventional metric mean Average
Precision (mAP) on the ImageNet VID evaluation set.
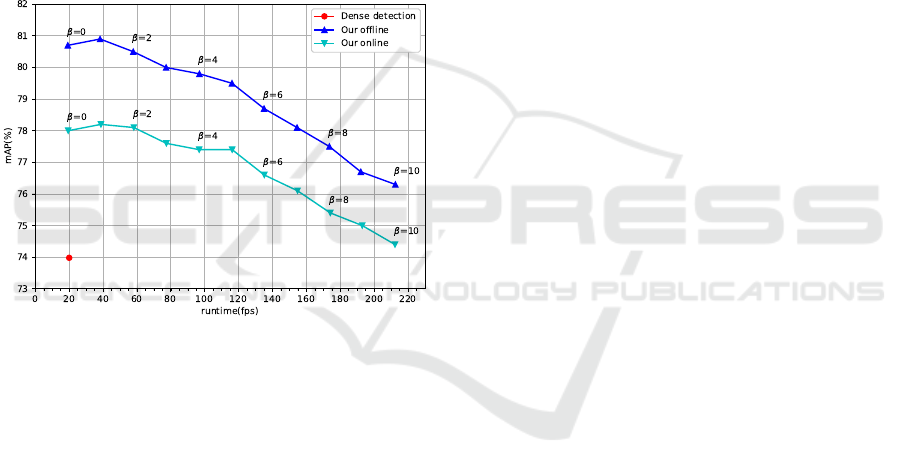
Figure 3: Speed/accuracy curves of our proposed method.
As shown in Figure 3, top left and right plots are
for the speed/accuracy trade-off of our offline and on-
line settings; bottom left and right are for the mAP im-
provements of our two settings. The speed/accuracy
trade-off was made under different Bbox Bilinear In-
terpolation intervals β and d ifferent input image reso-
lutions (416 × 416 and 608 × 608).
From Figur e 3 we observe that: Firstly, both set-
tings of our method highly improve the accuracy
of our per-frame detection baseline; Secondly, long
Bbox Bilinear Interpolation intervals will lead to tra-
gic accuracy drops, especially when β > 5; Thirdly,
for the choice of input image resolution, on both set-
tings, 608 ×60 8 achieves better accuracy when f ps <
175; Fourthly, our method achieves generally h igher
accuracy improvements for our model with the input
image resolution 416 × 416.
4.2.2 Ablation Study
For simplicity, all experiments were condu c te d o n our
trained model with input image resolution 608 × 608
with th e bilinear interpolation interval β = 1.
Step Validation. Ta ble 1 compares our proposed met-
hod with the per-frame dense detection baseline and
its variants.
Method (a) is the per-frame dense detection ba-
seline of our train ed model. We simply divide each
video in Image Net VID validation set in to f rames and
perform per-frame object detection. The only post-
processing is N MS with thresh 0.55. Without bells
and whistles, our base model achieves 74.0% of m A P
for per-frame de nse detection with 50ms of runtime
on a Titan X GPU. We find our trained model much
faster in terms of speed and competitive in terms of
accuracy with other trained baseline models in recent
works, e.g., FGFA(Zhu and al., 2017), Scale-Time
Lattice(Chen and al., 2018) and D&T (Feichtenhofer
and al., 2017).
Following FGFA(Zhu and al., 2017), we c onti-
nued to evaluate our model on three motion groups:
slow, medium and fast. It turns o ut that our model is
good at detecting slow-moving objects with mAP of
81.5% but struggling a t detecting fast-moving objects,
where the mAP drops directly to 50.5%.
Method (b) is the implementation of Seq-NM S
(Han and al., 2016). Even though it boosts the
mAP from 74.0 % to 77.8%, it takes too much time
(71.5ms/frame) for sorting sequences of bboxes.
Method (c) implements our Frame-level Bbox
Rescoring in an offline way (Section 3.3). This met-
hod improves the detectio n accuracy by 5.4% for
slow-moving object, 7.6% for medium and 11.8% for
fast, which shows th at our bbox r escoring m e thods
can largely boost the detection accur acy for more
challengin g fast-moving obje cts. Compared with (b),
same as offline video object detection, our method
requires less p ost-processing time (1.7ms/frame for
ours vs 71.5ms/frame for Seq-NMS) while achieves
a h igher mAP gains (6.6% for ours vs 3.8% for Seq-
NMS), which proves that ours outperforms Seq-NMS.
Note that up until Method (c), we do not suppress
any detected bboxes or add any extra bboxes. All
mAP g ains c ome from rescoring methods that correct
potential wrong detections. Method (d) is the offline
setting of our method , which adds the Tubelet-level
Bbox Linking (Section 3.4) on the basis of (c). The ob-
jective of Tubelet-level Bbox Linking is to infer mis-
sed detections between near by tubeletes, and this step
boosts our final mAP to 80.9%. We find the add itional
computation overhea d for matching tubelets accepta-
ble (0.6ms/frame) and this step more helpful for more
Improving Video Object Detection by Seq-Bbox Matching
231
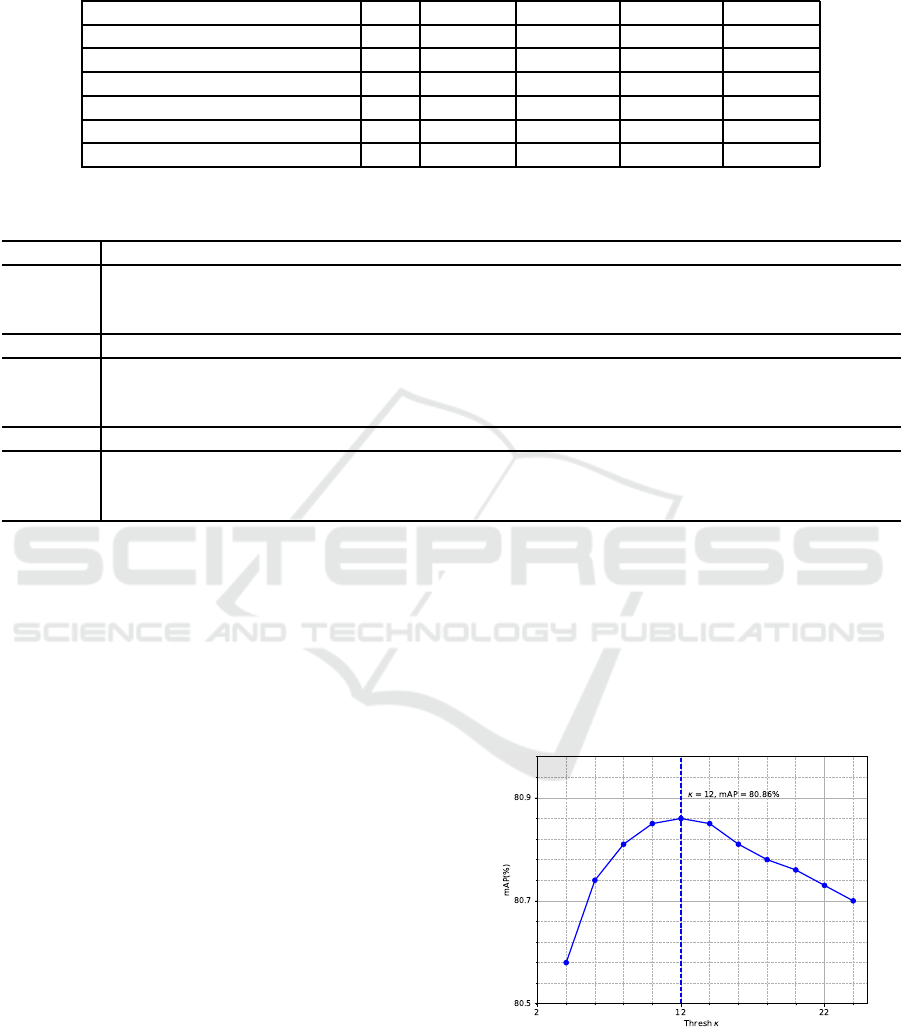
Table 1: Accuracy and runtime of different methods on ImageNet VID validation. All experiments are conducted at the
input image resolution 608 × 608, (c), (d) and (e) are results with the bilinear interpolation interval β = 1. The relative gains
compared to the single-frame baseline (a) are listed in the subscript.
method (a) (b) (c) (d) (e)
mAP(%) 74.0 77.8
↑ 3.8
80.6
↑ 6.6
80.9
↑ 6.9
78.2
↑ 4.2
mAP(%) (slow) 81.5 83.8
↑ 2.3
86.9
↑ 5.4
87.1
↑ 5.6
85.3
↑ 3.8
mAP(%) (medium) 71.7 76.6
↑ 4.9
79.3
↑ 7.6
79.6
↑ 7.9
76.3
↑ 4.6
mAP(%) (fast) 50.5 58.0
↑ 7.5
62.3
↑ 11.8
62.7
↑ 12.2
57.2
↑ 6.7
runtime(ms) (all) 50 121.5 51.7 52.3 51.7
runtime(ms) (post-processing) 0.01 71.5 1.7 2.3 1.7
Table 2: Performance comparison on the ImageNet VID validation set. All experiments are conducted at the input image
resolution 608 × 608 wit h the bilinear interpolation i nterval β = 1. The average precision (in %) for each class is shown.
Methods air plane antelope bear bicycle bird bus car cattle dog d.cat
Baseline 93.3 83.3 71.3 82.3 70.9 67.2 65.6 72.6 56.3 76.1
offline 93.2 86.4 81.5 85.2 75.3 71.2 66.7 82.4 70.1 92.3
Online
93.1 85.6 78.3 83.0 74.0 70.0 66.1 77.5 66.0 85.1
Methods elephant fox g.panda hamster horse lion lizard m onkey moto rabbit
Baseline 74.8 89.3 86.4 89.2 76.1 53.0 73.2 48.2 86.8 65.7
offline
79.3 97.0 88.0 95.8 82.7 72.8 83.6 53.7 91.7 80.0
Online 78.3 93.2 86.6 92.4 79.9 65.9 76.4 51.4 89.3 74.8
Methods r.panda sheep snake squirrel tiger train turtle watercraft whale zeb ra
Baseline 80.9 69.6 64.6 54.7 88.4 85.0 75.6 64.0 65.8 90.6
offline 96.0 78.8 70.7 64.5 90.4 86.5 78.7 67.5 68.4 95.3
Online
94.9 75.7 68.4 62.9 89.3 85.7 76.5 66.8 64.2 93.8
challengin g fast-movin g object detection.
Method (e) is the on line setting of our method.
It is realized b y our Online Frame-level Bbox Res-
coring (Section 3.5). We use dynamique averaging
method to rescore the bbox of one object according
to its historical classification scores. Compared with
(b), which is implemented in a offline manner, our on-
line method achieves a higher impr ovemen t in terms
of accuracy (4.2% for ours vs 3.8% for Seq-NMS).
Compared with(c), (e) is relatively less effective due
to the lack of future inf ormation. Note that the com-
putational overhead of (e) is quite light (1.7ms/frame)
and affordable for most real-world applications.
As to runtime of (c), (d) and (e), o nly half of the
frames in the validation set are actually detected and
others are estimated by Bbox Bilinear Interpolation.
All mentioned runtimes are for one detected frame
instead of average runtimes of a whole video.
Per-class Analyse on the ImageNet VID Validation
Set. Due to movement blur or other reasons, our
per-frame ba seline has a very poor perfo rmance for
some classes (e.g., lion with 53% of AP) as a result
of wrong or missed detections. Both our online and
offline settin gs highly improve the detection accuracy.
Some class-AP scores are improved significantly, e.g.,
for the class lion , 19.8% of gain on offline setting
and 12.8% on online setting; for the class red panda,
15.1% of gain on offline setting and 14.0% on online
setting. These AP gain s result from the rise of clas-
sification accuracy and object detection recall, which
are realized by ou r Frame-level Bbox Rescoring and
Tubelet-level Bbox Linking respectively. For the air-
plane class presenting heavy occlusions and fast mo-
vements, the matching of bboxes becam e more c hal-
lenging which leads to slight accuracy drop.
Thresh κ Analyze. In Figure 4, we show the accuracy
trends with thresh κ varying from 4 to 24.
Figure 4: Accuracy vs thresh κ on ImageNet VID dataset.
The plot shows that the accu racy rises quickly
from 80.6% to 80.9% as thresh κ rises from 4 to 12,
then the accuracy drop s slowly. This result can be
interpreted as: with the raise of κ, not only more m is-
sed detections are infered but also more false-positive
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
232
bboxes are ”made ”. Af te r exceeding a critical value,
i.e., 12 in our case, the latter becomes dominant, lea-
ding to accuracy drop.
4.3 Comparison with State-of-the-Art
Methods
According to FGFA (Zhu and al., 2017), Seq-NM S
(Han and al., 2016 ) obtains larger gain than T-CNN
(Kang and al., 2016), so we implement Seq -NMS
on our trained model with input image r esolution
608 × 608 for comp a rison. Our method achieves a
higher accuracy in bo th online and offline settings
and both re quire at least 30 times less computation
time (71.5ms for Seq-NMS vs 1.7ms and 2.3ms for
our method), which proves that our box -level post-
processing method is more effective. Moreover, Seq-
NMS can only be applied to offline video object de-
tection, while we also propose an online setting. We
further compare our results with several state of the
art video object detection methods. For fair co mpari-
son, we reported our detection speed on Titan X.
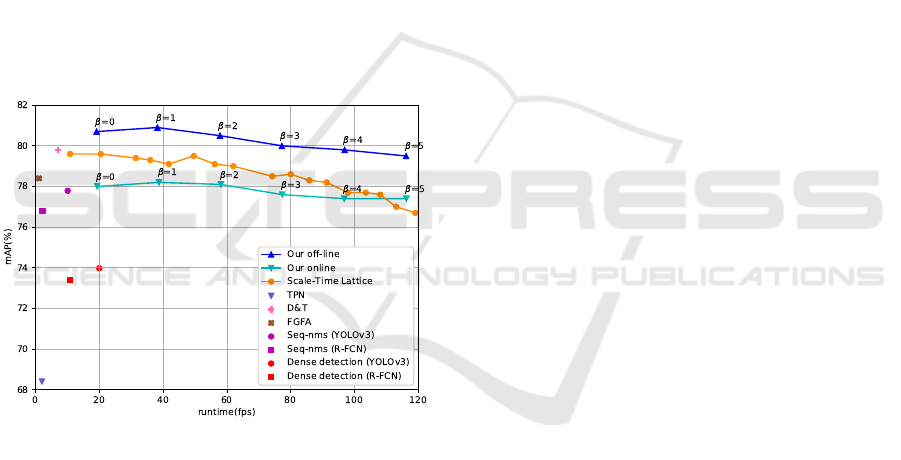
Figure 5: Speed/accuracy comparison of our proposed met-
hod applied to YOLOv3 with other state-of-the-art methods
on the ImageNet VID validation set.
As shown in Figure 5, our offline setting hits the
best speed/accuracy trade-off comp a red with other
box-level or f eature-level methods. In particular, it
achieves 80.9% of mA P at 38 fps and 79.5% of mAP
at 116 fps on a Titan X G PU. Our o nline setting
gets competitive speed/accuracy trade-off and is m ore
adaptive for m ore practical online object detection ap-
plications.
5 CONCLUSION
In this paper, we present a novel, simple an d highly
effective box-level post-processing method, na med
Seq-Bbox Matching, to improve video object de-
tection. Experiments show that, applied to YOLOv3,
our method is more effective than all existing box-
level methods and hits the best speed/accuracy trade-
off compared w ith other state-of-the-art methods. The
online setting of our method p erforms video object
detection without access to future frames and achieves
competitive accuracy improvement. Despite the large
detection accuracy improvement, the most important
advantage of o ur method is its quite light computatio-
nal overhead which makes it applicable in most real-
world computer vision applications.
REFERENCES
Chen, K. and al. (2018). Optimizing video object detection
via a scale-time lattice. CoRR, abs/1804.05472.
Dai, J. and al. (2016). R-FCN: object detection via re-
gion based fully convolutional networks. CoRR,
abs/1605.06409.
Feichtenhofer, C. and al. (2017). Detect to track and track
to detect. CoRR, abs/1710.03958.
Felzenszwalb, P. F. and al. (2010). Object detection with
discriminatively trained part-based models. IEEE
Trans. Pattern Anal. Mach. Intell., 32(9):1627–1645.
Girshick, R. (2015). Fast R-CNN. CoRR, abs/1504.08083.
Han, W. and al. (2016). Seq-nms for video object detection.
CoRR, abs/1602.08465.
Huang, J. and al. (2016). Speed/accuracy trade-offs
for modern convolutional object detectors. CoRR,
abs/1611.10012.
Kang, K. and al. (2016). T-CNN: tubelets with convolutio-
nal neural networks for object detection from videos.
CoRR, abs/1604.02532.
Lin, T. and al. (2017). Focal loss for dense object detection.
CoRR, abs/1708.02002.
Liu, W. and al. (2015). SSD: single shot multibox detector.
CoRR, abs/1512.02325.
Redmon, J. and al. (2015). You only look once: Unified,
real-time object detection. CoRR, abs/1506.02640.
Redmon, J. and Farhadi, A. (2016). YOLO9000: better,
faster, st ronger. CoRR, abs/1612.08242.
Redmon, J. and Farhadi, A. (2018). Yolov3: An incremental
improvement. CoRR, abs/1804.02767.
Ren, S. and al. (2015). Faster R-CNN: towards real-time ob-
ject detection with region proposal networks. CoRR,
abs/1506.01497.
Russakovsky, O. and al. (2014). Imagenet large scale visual
recognition challenge. CoRR, abs/1409.0575.
Viola, P. and Jones, M. J. (2004). Robust real-time face
detection. Int. J. Comput. Vision, 57(2):137–154.
Zhu, X. and al. (2017). Flow- guided feature aggregation for
video object detection. CoRR, abs/1703.10025.
Improving Video Object Detection by Seq-Bbox Matching
233
