
Multimodal Sentiment Analysis: A Multitask Learning Approach
Mathieu Pag
´
e Fortin and Brahim Chaib-draa
Department of Computer Science and Software Engineering, Laval University, Qu
´
ebec, Canada
Keywords:
Multimodal, Sentiment Analysis, Emotion Recognition, Multitask Learning, Text and Image Modalities.
Abstract:
Multimodal sentiment analysis has recently received an increasing interest. However, most methods have
considered that text and image modalities are always available at test time. This assumption is often violated
in real environments (e.g. social media) since users do not always publish a text with an image. In this
paper we propose a method based on a multitask framework to combine multimodal information when it is
available, while being able to handle the cases where a modality is missing. Our model contains one classifier
for analyzing the text, another for analyzing the image, and another performing the prediction by fusing both
modalities. In addition to offer a solution to the problem of a missing modality, our experiments show that this
multitask framework improves generalization by acting as a regularization mechanism. We also demonstrate
that the model can handle a missing modality at training time, thus being able to be trained with image-only
and text-only examples.
1 INTRODUCTION
Using a computational method, sentiment analysis
aims to recognize whether a given source of data con-
veys a positive or a negative sentiment. A more fine-
grained version of this problem aims to predict subtle
categories of emotions such as anger, sadness, excite-
ment, etc (Duong et al., 2017). Sentiment analysis has
important applications for the study of social media,
where billions of messages are published everyday
1
.
They often contain opinions and are thus a very rich
source of information.
Multimodal sentiment analysis has received an in-
creasing level of attention recently (Soleymani et al.,
2017). On social media, users are encouraged to post
images with a text description, and these two modal-
ities can offer complementary information to better
guide the analysis and reduce the classification error.
However, most recent methods still consider that both
modalities are always available at test time. This as-
sumption is often violated in real environments (e.g.
social media) as users do not always publish a text
with an image.
Late-fusion can be used as a solution to the prob-
lem of missing modality by training two monomodal
models and by producing the multimodal prediction
by weighting each score (Atrey et al., 2010). If a
modality is absent, the other monomodal classifier
1
https://www.socialpilot.co/blog/social-media-statistics
can still make a prediction. However, the performance
of late-fusion generally suffers from its simplicity, as
it considers each modality independently and cannot
learn discriminative multimodal interactions (Glodek
et al., 2011).
Another approach is to develop a method that is
robust to a missing modality, for instance with a gen-
erative model (Ngiam et al., 2011) or by minimizing
a metric over multimodal representations (Sohn et al.,
2014; Duong et al., 2017). However, such method
requires much more complex training strategies.
Additionally, these methods cannot easily be
trained with monomodal data. Collecting and espe-
cially labelling multimodal datasets with sentiment or
emotion are laborious tasks. These datasets are there-
fore very often either noisy or small. A fraction of the
dataset can even be composed of image-only or text-
only examples. For instance, You et al. (2016) pub-
lished a dataset in which each example has been anno-
tated by at least five people. However, from the total
of 22K images, only 8K of them are paired with a text.
With typical multimodal methods, only the image-
text pairs are used for training and the image-only ex-
amples are wasted (Duong et al., 2017). This draw-
back has been neglected in previous work, whereas it
is an important issue for small datasets.
In this paper we propose a new method to tackle
the problem of missing modality at test time and
training time. It leverages a multitask framework to
combine multimodal information when it is available,
368
Fortin, M. and Chaib-Draa, B.
Multimodal Sentiment Analysis: A Multitask Learning Approach.
DOI: 10.5220/0007313503680376
In Proceedings of the 8th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2019), pages 368-376
ISBN: 978-989-758-351-3
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

while being able to handle the cases where a modal-
ity is missing. Our model contains one classifier for
each task: one that only analyzes the text, another that
only analyzes the image, and another that performs
predictions based on the fusion of both modalities.
This method overcomes the simplicity of late-fusion
and the problem of a missing modality for two rea-
sons. First, the multimodal classifier can use any fu-
sion technique to learn complex multimodal interac-
tions. Second, the monomodal classifiers enable the
model to perform accurate predictions even in situa-
tions where image-text pairs are not always present.
Similarly to Vielzeuf et al. (2018), our approach is
multitask in the sense that it considers a multimodal
and two monomodal classification problems at the
same time.
We also show that, compared to training different
models on each task individually, some benefits arise
from multitask learning. In addition to being more
simple to develop (only one model is trained end-to-
end), our experiments support that it also presents two
other advantages. First, the results show that the mul-
timodal classification can generalize better compared
to when each classifier is trained individually. Sec-
ond, it becomes easy to train a multimodal model with
additional monomodal data. This enables the feature
extractors and the monomodal classifiers to be trained
with image-only or text-only examples, which can im-
prove the performances. Therefore we differ from
Vielzeuf et al. (2018) as we do not only consider the
monomodal classifiers as a regularization mechanism.
We also leverage their potential to deal with a missing
modality.
2 RELATED WORK
Textual Sentiment analysis is a very active area of re-
search in Natural Language Processing (Soleymani
et al., 2017). Typically, the approaches in this area
can be divided in two groups: lexicon-based and ma-
chine learning-based sentiment analysis. Recently,
machine learning approaches gained more interest
since they showed a real potential for automatically
learning rich text representations from data, which
are then used to classify the sentiment. Several tech-
niques based on machine learning have been pro-
posed, including classification by using word em-
beddings (Mikolov et al., 2013), the use of Recur-
rent Neural Networks (RNN) (Camacho-Collados and
Pilehvar, 2017) or the use of Convolutional Neural
Networks (CNN) (Kim, 2014).
Visual sentiment analysis is a more recent research
avenue (Campos et al., 2015). The challenge of bridg-
ing the affective gap (Machajdik and Hanbury, 2010)
makes this avenue more complex than the detection of
concrete objects. Still, various approaches have been
proposed by using state-of-the-art visual models. For
instance, You et al. (2015) proposed a CNN inspired
by AlexNet (Krizhevsky et al., 2012). Wang et al.
(2016) used two parallel AlexNets to predict the ad-
jective and noun labels of the image, and then used
both representations to predict the sentiment. Simi-
larly, You et al. (2017) proposed an attention mecha-
nism based on the adjective label that weights the fea-
ture maps extracted by VGG-16 (Simonyan and Zis-
serman, 2014). Their weighted sum is then used for
the sentiment classification.
Multimodal sentiment analysis combines innova-
tions from both textual and visual sentiment analysis.
Chen et al. (2017) used the CNN from (Kim, 2014) to
extract a representation of texts, together with a net-
work similar to AlexNet to analyze the images. The
two representations are then fused and classified by a
small neural network. Xu and Mao (2017) proposed
to use the representations given by a VGG model pre-
trained on ImageNet (Deng et al., 2009) and another
VGG model pre-trained on a place dataset. These rep-
resentations are then used to guide an attention mech-
anism on top of an LSTM that extracts a representa-
tion of the text.
One drawback of these previous multimodal
methods is that, although they provide more accu-
rate results than monomodal models, they are limited
to multimodal data and cannot process image-only or
text-only inputs at test time. In real situations and es-
pecially on social media, it is common to only have
access to one of the two modalities. Few work has
been done to solve this issue.
Sohn et al. (2014) proposed to minimize the
variation of information between modality represen-
tations. By reducing such metric, the model learns
to be more robust to a missing modality. Duong et
al. (2017) developed a model that applies a simi-
lar idea to sentiment analysis. The model learns to
minimize the distance between the representations of
a text-image pair while maximizing the distance be-
tween the representations of an image and a randomly
chosen text of another class.
Perhaps the most similar work to ours is the
CentralNet (Vielzeuf et al., 2018). The architecture
also contains two monomodal classifiers and a cen-
tral multimodal classifier. However, this approach is
mainly presented as a multimodal fusion technique
where the authors leverage a multitask learning only
to benefit from the implicit regularization that it intro-
duces. In this paper, we also support that such mul-
titask learning improves generalization, but we em-
Multimodal Sentiment Analysis: A Multitask Learning Approach
369
phasize that the monomodal classifiers are important
to further augment the training set with monomodal
data and to deal with a missing modality at test time.
3 MULTIMODAL MULTITASK
LEARNING
In this section, we describe the problem more for-
mally, the model proposed to tackle it and the spe-
cific training procedure to handle a missing modality
at train and test time.
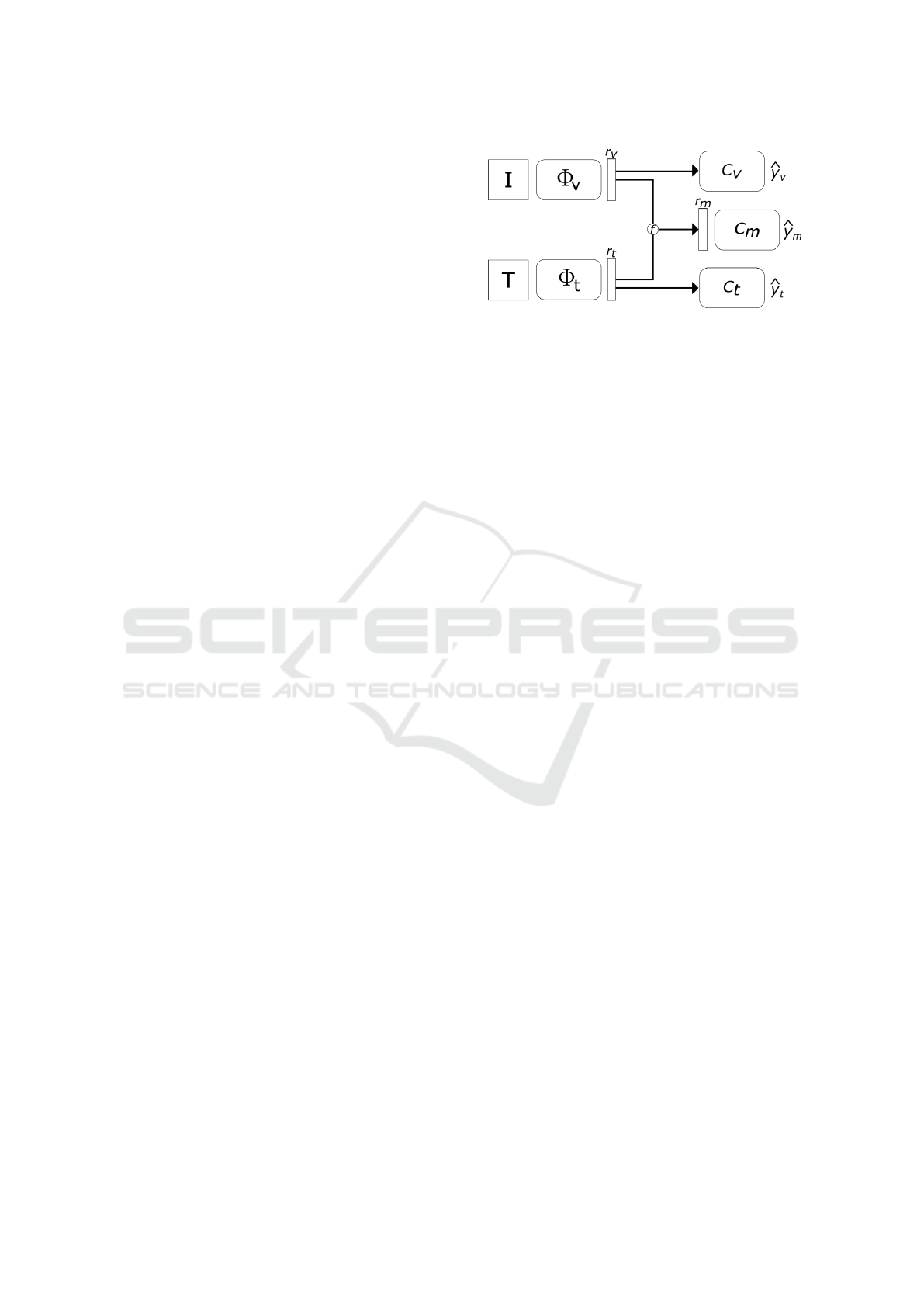
3.1 Problem Formulation and Overview
of the Proposed Framework
Given a dataset X composed of image-text pairs (I
p
,
T
p
), unpaired images I
u
, and unpaired texts T
u
, with
their corresponding labels y ∈ Y , we aim to learn a
model that can predict the label y
i
of an instance x
i
.
We tackle the problem where the label is a sentiment
or an emotion. We want the model to be able to handle
the three following cases: the instance x
i
at training
and test time can be either a pair (I
i
p
, T
i
p
), an image I
i
u
,
or a text T
i
u
.
We propose to solve this problem with a multi-
task learning framework as shown in Figure 1. The
whole model is composed of two features extractors:
a Visual network Φ
v
, a Textual network Φ
t
; and three
auxiliary classifiers: a Visual classifier C
v
, a Textual
classifier C
t
, and a Multimodal classifier C
m
. The Vi-
sual network and the Textual network respectively ex-
tract a representation of the image and the text, while
each classifier specializes itself either in the classifica-
tion of the image representation, the text representa-
tion, or the multimodal representation. During train-
ing, when an instance is a text-image pair, the whole
model is updated, whereas when an instance is an im-
age or a text, only the corresponding features extrac-
tor and classifier are trained. Similarly, at test time the
prediction is done with the corresponding classifier.
3.2 Modules
Visual Network. The objective of the Visual net-
work Φ
v
is to extract a representation of the input
image. In our experiments, we use the DenseNet-
121 (Huang et al., 2017) pretrained on ImageNet.
The classification layer is replaced by a fully-
connected layer of 300 neurons to produce the im-
age representation r
v
∈ R
300
.
Textual Network. Similarly to Chen et al. (2017),
we use a slight variation of the simple CNN from
Figure 1: Overview of our multimodal multitask approach.
The image I is analyzed by the CNN Φ
v
to produce a repre-
sentation r
v
. Similarly, a representation r
t
is extracted from
the text T by Φ
t
. Then, three tasks are considered: 1) the
prediction of r
v
by the classifier C
v
, 2) the prediction of r
t
by
C
t
, and 3) the prediction of the multimodal fusion f (r
v
, r
t
)
by C
m
.
(Kim, 2014) that we present here. First, the in-
put text is embedded using pre-trained representa-
tions of words in 300 dimensions (Mikolov et al.,
2013). Then Dropout is applied with a probabil-
ity of 0.25 to reduce overfitting. A convolutional
layer of 100 filters extracts features with a window
size of h
i
×300. The nonlinear activation ReLU is
used. Finally, global max, average and min pool-
ing are used, such that:
p
i
= [max(c
i
), avg(c
i
), min(c
i
)] ∈ R
100×3
, (1)
where c
i
is the feature maps given by the convolu-
tional layer i.
The process for one layer with filters of size
h
i
× 300 has been described. For our Textual net-
work, three parallel layers are used with h
1
=
3, h
2
= 4, h
3
= 5 to capture different n-gram pat-
terns. The three resulting p
i
are concatenated and
a fully-connected layer with 300 neurons is used
to obtain the text representation r
t
∈ R
300
.
Visual Classifier. The Visual classifier aims to pre-
dict the sentiment expressed by the image. It
learns to predict the class by taking an image rep-
resentation r
v
. In our experiments, this classifier
is made of two fully-connected layers of 224 and
128 neurons, followed by a classification softmax
layer.
Textual Classifier Similarly, the Textual classifier
only depends on the text information to make its
prediction. It uses the text representation r
t
and is
trained to recognize the class. Its architecture is
similar to the Visual classifier.
Multimodal Classifier. Finally, this central classifier
leverages both representations of the modalities
r
v
and r
t
to make predictions. An initial step is
to perform the fusion of representations with a
function f (r
v
, r
t
). To this end, several techniques
ICPRAM 2019 - 8th International Conference on Pattern Recognition Applications and Methods
370

have been proposed, ranging from simple (e.g.
concatenation, summation) to more complex ones
(Hori et al., 2017; Zadeh et al., 2017; Vielzeuf
et al., 2018). In our experiments, we use the con-
catenation for its simplicity and let sophisticated
fusion techniques for future work. A classifier
made of two fully-connected layers and a softmax
layer is used to predict the class.
3.3 Training Procedure
We consider three tasks that are each performed by
a different classifier. One task is to predict the senti-
ment ˆy
v
from the visual information only:
r
v
= Φ
v
(I),
ˆy
v
= C
v
(r
v
),
(2)
where Φ
v
is the Visual network and C
v
is the Visual
classifier.
Another task is to predict the sentiment ˆy
t
from the
text only:
r
t
= Φ
t
(T ),
ˆy
t
= C
t
(r
t
),
(3)
where Φ
t
is the Textual network and C
t
is the Textual
classifier
Finally the main task is to predict the sentiment ˆy
m
from the fusion of the image and text representations:
r
m
= f (r
v
, r
t
),
ˆy
m
= C
m
(r
m
),
(4)
where f (·, ·) is the fusion function and C
m
is the Mul-
timodal classifier.
For each of the three tasks j ∈ {v, t, m}, its auxil-
iary loss L
j
( ˆy
j
, y) is defined by the cross-entropy. The
whole model is trained to minimize:
L = α
v
L
v
( ˆy
v
, y) + α
t
L
t
( ˆy
t
, y) + α
m
L
m
( ˆy
m
, y),
(5)
where α
v
, α
t
and α
m
are hyperparameters to weight
the loss of each task. In this work we set them all to
1, but in future work we plan to investigate how we
can learn them from data.
Furthermore, we remind that we consider the
problem where a training instance can be either an
image-text pair, an image (only), or a text (only).
When an image-text pair is available, the two fea-
tures extractors Φ
v
and Φ
t
and the three classifiers C
are trained according to the multitask loss defined in
equation 5.
When the instance is an unpaired image, the loss
function only includes the prediction of the Visual
classifier:
L = α
v
L
v
( ˆy
v
, y). (6)
Similarly, when the instance is a text the loss func-
tion only includes the prediction made by the Textual
classifier:
L = α
t
L
t
( ˆy
t
, y) (7)
4 EXPERIMENTS AND RESULTS
We conducted experiments to evaluate our proposed
approach for multimodal sentiment analysis. We now
describe the datasets that are used, the experiments
and the baselines. Then we present and discuss the
results.
4.1 Datasets
Flickr Emotion. (You et al., 2016). This dataset con-
tains images that have been annotated by at least 5
workers from Amazon Mechanical Turks. For each
image, they were asked to attribute a label between
eight emotions: amusement, anger, awe, content-
ment, excitement, disgust, fear, and sadness. We used
the given URLs to download, with the Flickr API
2
,
the texts associated with the images. We only used
the examples where the majority of workers agreed
for a particular label. Since some examples can be
ambiguous, we kept the top 20% of examples that re-
ceived all the votes for the same emotion and we ran-
domly divide it equally to form the validation and the
test sets. The remaining 80% is used for training. Ta-
ble 1 shows the statistics for each dataset and each
class.
VSO. (Borth et al., 2013). Visual Sentiment Ontol-
ogy (VSO) is widely used for sentiment analysis ex-
periments due to its large number of examples. How-
ever, the way VSO was collected makes it very noisy.
It has been built by querying Flickr with adjectives
and nouns, which are then used to label the data as
expressing positive or negative sentiment. Similarly
to Chen et al. (2017), we downloaded the images
and used the Flickr API to collect the texts associ-
ated with the images. We removed the examples with
less than 5 words and more than 150 words, resulting
in 301,042 pairs of images and texts. We randomly
splitted the dataset into 80% training, 10% validation
and 10% test.
4.2 Experimental Setting
We conduct two experiments and compare our results
with 6 variants as baselines.
2
www.flickr.com
Multimodal Sentiment Analysis: A Multitask Learning Approach
371

Table 1: Statistics of datasets.
VSO
Sentiment Quantity
positive 187,402
negative 113,640
Total 301,042
Flickr Emotion
Emotion Quantity Quantity
(I-T pairs) (I-only)
amusement 1,485 3,270
anger 422 762
awe 1,165 1,789
contentment 1,872 3,312
disgust 676 929
excitement 1,266 1,482
fear 367 613
sadness 910 1,755
Total 8,163 13,912
4.2.1 Experiments
We consider two variants of experiments to evalu-
ate our model. We first compare the performance of
baselines and our model trained with multitask learn-
ing. Then, we experiment the possibility of leveraging
monomodal examples to improve multimodal classi-
fication.
Experiment 1. Previous work have shown that
multitask learning can improve generalization by in-
troducing regularization mechanisms (Ruder, 2017;
Vielzeuf et al., 2018). In our framework, multitask
learning regularizes the network by introducing a rep-
resentation bias and an inductive bias as described by
Ruder (2017). By training monomodal and multi-
modal classifiers, the image and text representations
are learned with the objective of being discrimina-
tive. On the one hand this improves the quality of the
monomodal representations before their fusion, and
on the other hand it has less tendency to overfit since
each monomodal representation is shared by two clas-
sifiers (i.e. the monomodal and the multimodal clas-
sifiers).
In this first setup, we evaluate the effects of reg-
ularization introduced by multitask learning and the
ability of our model to handle a missing modality. We
also reuse the text-based and image-based classifiers
to perform late-fusion as a baseline. We remove the
unpaired images and texts, and the examples in which
the text contains less than five words. The architec-
tures, hyperparameters and train/val/test splits are the
same for each experimentation. Each experimentation
is repeated at least three times (to reduce the variance)
and the average is reported. For the multitask model,
early stopping is performed on the basis of the main
task: multimodal classification.
Experiment 2. One benefit of the multitask ap-
proach in the context of multimodality is that we can
leverage monomodal training data. We experiment
how the generalization of each task is affected by this
additional training data. We first evaluate the per-
formance of our model when enriching the training
set of Flickr Emotion dataset with unpaired images.
Then, to further demonstrate the advantage of lever-
aging unpaired data, we experiment this training pro-
cedure on VSO with different amounts of paired data
(0.1%, 1%, 5%, 25%, 100%), while the rest is used as
monomodal examples.
4.2.2 Baselines
We compare our model trained with multitask learn-
ing to the following variants:
1. Image-based classifier (SI): Visual network Φ
v
with Visual classifier C
v
.
2. Text-based classifier (ST): Textual network Φ
t
with Textual classifier C
t
.
3. Single-task multimodal classifier (SM): Visual
network Φ
v
and Textual network Φ
t
with Multi-
modal classifier C
m
.
4. Late-fusion: Trained Image-based classifier and
Text-based classifier are reused and their predic-
tions are averaged.
5. Multimodal-text only (SM
T
): Single-task multi-
modal classifier is reused but the images are ab-
sent at test time.
6. Multimodal-image only (SM
I
): Single-task multi-
modal classifier is reused but the texts are absent
at test time.
4.3 Results and Discussion
4.3.1 Experiment 1: Regularization and Missing
Modality
We evaluated the benefits of our multitask framework
on the generalization of each three tasks: text, image,
ICPRAM 2019 - 8th International Conference on Pattern Recognition Applications and Methods
372

Figure 2: Confusion matrices for (from left to right) the multimodal, text and image classifiers (C
m
, C
t
, C
v
) trained with
multitask learning on Flickr Emotion.
and multimodal classification. The accuracy and F1-
score on Flickr Emotion and VSO datasets are shown
in Table 2 and Table 3. The macro-averaged F1 (F1-
Macro) is the F1-score averaged over all classes.
First, our results confirm the benefits of multi-
modal classification. The multimodal classifiers out-
perform the text-based and the image-based classi-
fiers on both datasets by a large margin. The baselines
SM
I
and SM
T
show the performances that the single-
task multimodal classifier obtains on Flickr Emotion
dataset with image-only and text-only examples, re-
spectively. The results clearly show that this classifier
is not robust to a missing modality, since the accuracy
drops to 47.92% and 79.90%. The monomodal clas-
sifiers (C
v
and C
t
) of our model obtain an accuracy of
70.34% and 83.99% with text-only and image-only
examples, respectively. These results show that our
model is more robust to a missing modality.
Interestingly, the results shown in Table 2 sup-
port that training our model with multitask learning
improves generalization for the task of multimodal
classification. On Flickr Emotion dataset, the model
trained with multitask learning improves the accuracy
by 1.24%. We performed a t-test that supported a
significant increase (p-value = 0.016). The accuracy
scores obtained by C
v
and C
t
are similar to those ob-
tained by the single-task models SI and ST. However,
the macro-averaged F1-scores are higher by 2.59%
and 1.13% on Flickr Emotion dataset for the Visual
and Textual classifiers trained with multitask learning.
These improvements are consistent with the experi-
ments performed by Vielzeuf et al. (2018), in which
they used a similar multitask learning as a regulariza-
tion mechanism.
Late-fusion obtains significantly lower perfor-
mances on Flickr Emotion dataset due to the lack of
interactions between multimodal features. Surpris-
ingly, late-fusion and SM obtain similar performances
to our model on VSO (see Table 3). A t-test sug-
Table 2: Results of experiment 1 for the proposed multi-
task model and baselines on Flickr Emotion dataset. (See
Section 4.2.2 for baselines).
Method Classifier Accuracy F1-Macro
Baselines
SI 70.59 0.5808
ST 83.70 0.7982
L-Fus 89.09 0.8564
SM 89.93 0.8659
SM
I
47.92 0.4064
SM
T
79.90 0.7486
Ours
C
v
70.34 0.6067
C
t
83.99 0.8095
C
m
91.17 0.8803
Table 3: Results of experiment 1 for the proposed multitask
model and baselines on VSO dataset.
Method Classifier Accuracy F1-score
Baselines
SI 69.91 0.7767
ST 84.15 0.8779
L-fus 85.73 0.8913
SM 85.79 0.8868
Ours
C
v
69.73 0.7648
C
t
83.79 0.8775
C
m
86.35 0.8894
gests that the superior accuracy of C
m
is not signifi-
cant (p-value = 0.09). We speculate that since VSO
is noisy, the upper-bound that any algorithm can ap-
proach on this dataset is relatively low. On the other
hand, since the dataset is very large, it is possible that
simple models – such as late-fusion or even a text-
based classifier – are already able to obtain perfor-
mances that approach it. This would explain why the
multimodal classifier only improves the accuracy by
2% over a text-based classifier, and why a multimodal
fusion technique does not outperform by a significant
margin a simple late-fusion.
We also report in Figure 2 the confusion matri-
Multimodal Sentiment Analysis: A Multitask Learning Approach
373
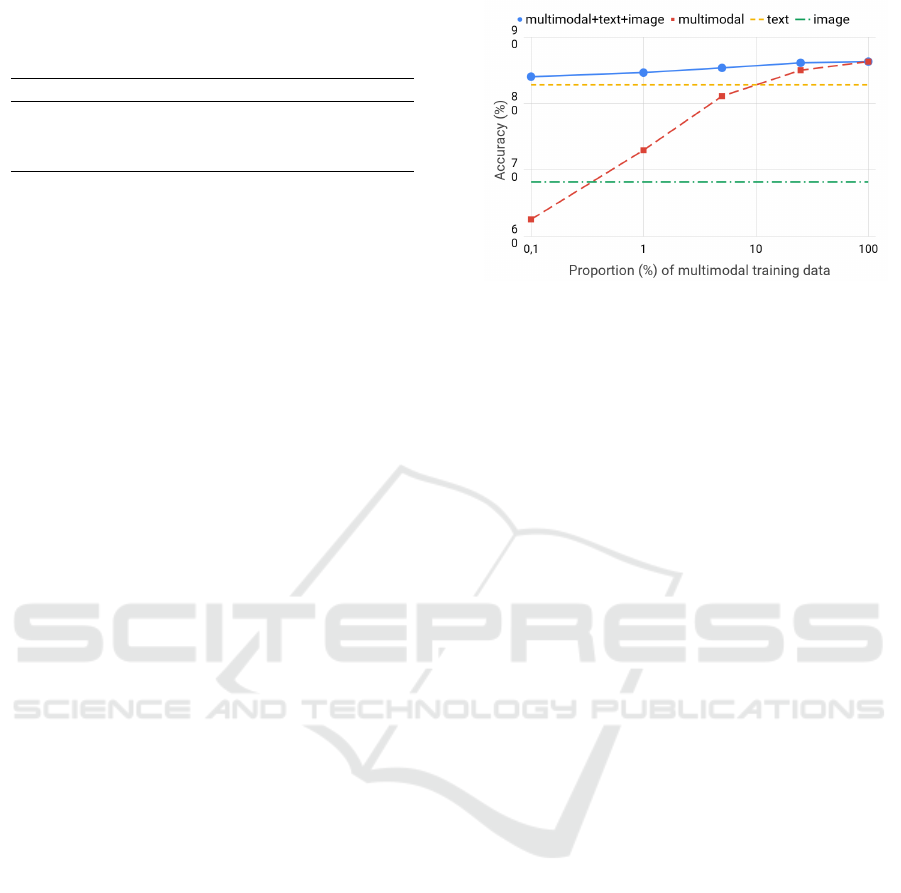
Table 4: Results of the experiment 2 for the proposed mul-
titask model trained with more image-only examples on
Flickr Emotion dataset.
Training Classifier Accuracy F1-Macro
Multitask
C
v
75.47 0.6507
+ images
C
t
83.92 0.8063
C
m
91.59 0.8810
ces for the three classifiers of our model trained on
Flickr Emotion dataset. They offer some insights on
the monomodal and multimodal classifications. For
instance, we observe that the Visual classifier hardly
recognizes the negative emotions, especially fear and
anger (0.13 and 0.26 respectively). This problem is
mostly solved by multimodality (0.87 and 0.81 for
fear and anger).
4.3.2 Experiment 2: Monomodal Training Data
As discussed in Section 3.3, our multitask framework
enables the model to be trained with monomodal data.
This is particularly useful for Flickr Emotion dataset
which is limited to 8,163 image-text pairs, but actu-
ally contains 13,912 image-only examples (see Table
1).
We trained our model with these additional im-
ages and we report the results in Table 4. When com-
pared to the results obtained in the first experiment,
the accuracy of the Visual classifier now significantly
improves by 5%. This also slightly increases the per-
formance of the multimodal classifier by 0.42%. This
observation can be explained by the fact that the Vi-
sual network Φ
v
is trained with more data and thus
the quality of the visual representation is improved.
Finally, we further evaluated the ability of the
model to be trained with few multimodal data on VSO
dataset. More specifically, a given fraction of the
training set is kept as multimodal data, while the re-
maining portion is divided in two: the texts are re-
moved from the first half and the images from the
second. The validation and test sets are 100% mul-
timodal. As a comparison, the same model is trained
only with the multimodal split.
Figure 3 shows the accuracy for different propor-
tions of multimodal data. As expected, a model only
trained with few multimodal data generalizes very
poorly with an accuracy of 62.56%. In that case, the
advantage of performing multimodal classification is
only visible when the model can be trained with a
large amount of image-text pairs. On the contrary,
when our model can also be trained with monomodal
data, the multimodal classifier always performs better
than a text-based classifier even with very few training
image-text pairs. The superiority of multimodal clas-
Figure 3: Classification accuracy on VSO dataset for differ-
ent proportions of multimodal training data. The results ob-
tained by the monomodal text-based and image-based clas-
sifiers are also shown as baselines.
sification improves with the amount of multimodal
data, but even when 0.1% (n = 230) of the training
set is multimodal, it performs 1.24% better than the
text-based classifier with an accuracy of 84.07%.
4.3.3 Discussion
The previous results highlighted three benefits of our
multitask approach. First, it offers a simple solution
to the problem of missing modality at test time. As
discussed above, this is an important feature for so-
cial media analysis. Second, we observed empiri-
cally that training the model with multitask learning
improves the performances of the multimodal classi-
fier. This regularization mechanism is an additional
tool that can easily be used in any multimodal mod-
els. Third, the multitask approach enables to leverage
monomodal training data. We showed that our model,
when trained with monomodal data, already outper-
forms the other baselines with as few as 230 mul-
timodal training examples. Since datasets are often
hard to collect, and even more for multimodal ones,
the ability to learn with monomodal data can be a very
useful feature.
Our results also confirmed that sentiment analysis
and emotion recognition are harder tasks with images
than with texts. This is due to the problem of affective
gap (Machajdik and Hanbury, 2010), which means
that there is a large conceptual distance between low-
level information contained in the input and the ab-
stract concept of human sentiment that we aim to pre-
dict. This gap is larger in images than in texts, since
words are more expressive and at a higher level of ab-
straction than pixels. The combination of text and im-
age information certainly helps to bridge the affective
gap.
We investigated the use of multitask mostly as a
solution to the problem of missing modality. How-
ICPRAM 2019 - 8th International Conference on Pattern Recognition Applications and Methods
374

Table 5: Examples of predictions for the three classifiers on Flickr Emotion test set.
Image
Text ”since we knew what to
expect or how comfortable
we would feel we brought
our rack and a single rope”
”not my idea of fun, each
to their own”
”love between a boy and
his best friend”
Ground Truth awe amusement contentment
C
m
prediction awe amusement contentment
C
t
prediction contentment fear contentment
C
v
prediction excitement amusement sadness
ever, there can also be value in the monomodal clas-
sifications. Multimodal classification relies on the as-
sumption that both modalities convey the same mes-
sage, which is not always true. Table 5 shows exam-
ples of image-text pairs and the predictions made by
the three classifiers of our model. We can observe that
the text and the image can express emotions that are
ambiguous or different. For instance, the image of a
carousel with the text ”not my idea of fun, each to
their own” can at the same time express amusement
and fear. In those cases, the monomodal and multi-
modal classifiers can together give a more complete
description of the message posted by a user, which is
not measured by common quantitative metrics such as
accuracy and F1-score.
5 CONCLUSION
In this paper, we proposed a multitask approach for
multimodal sentiment analysis and emotion recogni-
tion. Our approach adds two auxiliary image-based
and text-based classifiers to the traditional multi-
modal framework, which enables to handle a missing
modality at test time and training time. Our experi-
ments show that, not only it offers a viable and simple
solution to a missing modality, but also that multitask
learning acts as a regularization mechanism that can
improve generalization.
To the best of our knowledge, we are also the
first to explore the use of monomodal training data to
improve multimodal classification. We showed that
when a sufficient amount of monomodal data is avail-
able, very few multimodal data is necessary to ob-
tain excellent results. These observations suggest that
by simply extending the multimodal framework with
auxiliary monomodal classifiers, the training set can
easily be augmented with additional monomodal data
to improve its performances.
REFERENCES
Atrey, P. K., Hossain, M. A., El Saddik, A., and Kankan-
halli, M. S. (2010). Multimodal fusion for multimedia
analysis: a survey. Multimedia systems, 16(6):345–
379.
Borth, D., Ji, R., Chen, T., Breuel, T., and Chang, S.-F.
(2013). Large-scale visual sentiment ontology and de-
tectors using adjective noun pairs. In Proceedings of
the 21st ACM international conference on Multime-
dia, pages 223–232. ACM.
Camacho-Collados, J. and Pilehvar, M. T. (2017). On the
role of text preprocessing in neural network architec-
tures: An evaluation study on text categorization and
sentiment analysis. arXiv preprint arXiv:1707.01780.
Campos, V., Salvador, A., Giro-i Nieto, X., and Jou, B.
(2015). Diving deep into sentiment: Understanding
fine-tuned cnns for visual sentiment prediction. In
Proceedings of the 1st International Workshop on Af-
fect & Sentiment in Multimedia, pages 57–62. ACM.
Chen, X., Wang, Y., and Liu, Q. (2017). Visual and tex-
tual sentiment analysis using deep fusion convolu-
tional neural networks. In Image Processing (ICIP),
2017 IEEE International Conference on, pages 1557–
1561. IEEE.
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-
Fei, L. (2009). ImageNet: A Large-Scale Hierarchical
Image Database. In CVPR09.
Duong, C. T., Lebret, R., and Aberer, K. (2017). Multi-
modal classification for analysing social media. arXiv
preprint arXiv:1708.02099.
Multimodal Sentiment Analysis: A Multitask Learning Approach
375

Glodek, M., Tschechne, S., Layher, G., Schels, M., Brosch,
T., Scherer, S., K
¨
achele, M., Schmidt, M., Neumann,
H., Palm, G., et al. (2011). Multiple classifier sys-
tems for the classification of audio-visual emotional
states. In Affective Computing and Intelligent Interac-
tion, pages 359–368. Springer.
Hori, C., Hori, T., Lee, T.-Y., Zhang, Z., Harsham, B.,
Hershey, J. R., Marks, T. K., and Sumi, K. (2017).
Attention-based multimodal fusion for video descrip-
tion. In Computer Vision (ICCV), 2017 IEEE Interna-
tional Conference on, pages 4203–4212. IEEE.
Huang, G., Liu, Z., Weinberger, K. Q., and van der Maaten,
L. (2017). Densely connected convolutional networks.
In Proceedings of the IEEE conference on computer
vision and pattern recognition, volume 1, page 3.
Kim, Y. (2014). Convolutional neural networks for sentence
classification. arXiv preprint arXiv:1408.5882.
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). Im-
agenet classification with deep convolutional neural
networks. In Advances in neural information process-
ing systems, pages 1097–1105.
Machajdik, J. and Hanbury, A. (2010). Affective image
classification using features inspired by psychology
and art theory. In Proceedings of the 18th ACM in-
ternational conference on Multimedia, pages 83–92.
ACM.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., and
Dean, J. (2013). Distributed representations of words
and phrases and their compositionality. In Advances in
neural information processing systems, pages 3111–
3119.
Ngiam, J., Khosla, A., Kim, M., Nam, J., Lee, H., and Ng,
A. Y. (2011). Multimodal deep learning. In Proceed-
ings of the 28th international conference on machine
learning (ICML-11), pages 689–696.
Ruder, S. (2017). An overview of multi-task learn-
ing in deep neural networks. arXiv preprint
arXiv:1706.05098.
Simonyan, K. and Zisserman, A. (2014). Very deep con-
volutional networks for large-scale image recognition.
arXiv preprint arXiv:1409.1556.
Sohn, K., Shang, W., and Lee, H. (2014). Improved multi-
modal deep learning with variation of information. In
Advances in Neural Information Processing Systems,
pages 2141–2149.
Soleymani, M., Garcia, D., Jou, B., Schuller, B., Chang, S.-
F., and Pantic, M. (2017). A survey of multimodal sen-
timent analysis. Image and Vision Computing, 65:3–
14.
Vielzeuf, V., Lechervy, A., Pateux, S., and Jurie, F. (2018).
Centralnet: a multilayer approach for multimodal fu-
sion. arXiv preprint arXiv:1808.07275.
Wang, J., Fu, J., Xu, Y., and Mei, T. (2016). Beyond object
recognition: Visual sentiment analysis with deep cou-
pled adjective and noun neural networks. In IJCAI,
pages 3484–3490.
Xu, N. and Mao, W. (2017). Multisentinet: A deep seman-
tic network for multimodal sentiment analysis. In Pro-
ceedings of the 2017 ACM on Conference on Informa-
tion and Knowledge Management, pages 2399–2402.
ACM.
You, Q., Jin, H., and Luo, J. (2017). Visual sentiment anal-
ysis by attending on local image regions. In AAAI,
pages 231–237.
You, Q., Luo, J., Jin, H., and Yang, J. (2015). Robust image
sentiment analysis using progressively trained and do-
main transferred deep networks. In AAAI, pages 381–
388.
You, Q., Luo, J., Jin, H., and Yang, J. (2016). Building a
large scale dataset for image emotion recognition: The
fine print and the benchmark. In AAAI, pages 308–
314.
Zadeh, A., Chen, M., Poria, S., Cambria, E., and Morency,
L.-P. (2017). Tensor fusion network for multimodal
sentiment analysis. arXiv preprint arXiv:1707.07250.
ICPRAM 2019 - 8th International Conference on Pattern Recognition Applications and Methods
376
