
Outdoor Scenes Pixel-wise Semantic Segmentation using Polarimetry
and Fully Convolutional Network
Marc Blanchon
1
, Olivier Morel
1
, Yifei Zhang
1
, Ralph Seulin
1
, Nathan Crombez
2
and D
´
esir
´
e Sidib
´
e
1
1
ImViA EA 7535, ERL VIBOT CNRS 6000, Universit
´
e de Bourgogne Franche Comt
´
e (UBFC),
12 Rue de la Fonderie, 71200, Le Creusot, France
2
EPAN Research Group, University of Technology of Belfort-Montbliard (UTBM), 90010, Belfort, France
Keywords:
Polarimetry, Deep Learning, Segmentation, Augmentation, Reflective Areas.
Abstract:
In this paper, we propose a novel method for pixel-wise scene segmentation application using polarimetry.
To address the difficulty of detecting highly reflective areas such as water and windows, we use the angle
and degree of polarization of these areas, obtained by processing images from a polarimetric camera. A deep
learning framework, based on encoder-decoder architecture, is used for the segmentation of regions of interest.
Different methods of augmentation have been developed to obtain a sufficient amount of data, while preserving
the physical properties of the polarimetric images. Moreover, we introduce a new dataset comprising both
RGB and polarimetric images with manual ground truth annotations for seven different classes. Experimental
results on this dataset, show that deep learning can benefit from polarimetry and obtain better segmentation
results compared to RGB modality. In particular, we obtain an improvement of 38.35% and 22.92% in the
accuracy for segmenting windows and cars respectively.
1 INTRODUCTION
Scene segmentation and understanding have been a
popular topic in the field of robotics, artificial intel-
ligence and computer vision. It has attracted a lot
of research with different aproaches: decision forest
approach (Gupta et al., 2014), deep approach for
semantic segmentation (Couprie et al., 2013), and
pixel-wise semantic segmentation (Badrinarayanan
et al., 2015). The main challenge lies in the recog-
nition and the assignment of multiple classes.
A difficult key point when addressing the problem
of segmentation is the possible presence of reflective
areas. The segmentation method should be able to
differentiate a physical object and its projection on a
reflective area.
The field of segmentation of complex scenes is
open since many applications could benefit. Some re-
search has been conducted on the detection of mud
(Rankin and Matthies, 2010a), as well as on the de-
tection of water (Yan, 2014; Nguyen et al., 2017). In-
deed, robotics and autonomous cars could take advan-
tage of these abilities. For example, if a system is able
to understand a scene with complex areas (reflective),
then it is possible to avoid them.
Figure 1: From raw polarimetric image to segmentation.
Top: left is the raw polarimetric image, right is the trans-
formed image to HSL (Hue Saturation Luminance). Middle
image is the augmented image with proper physical mea-
ning. Bottom: left is the hand made ground truth and right
is the prediction of the deep learning network for the middle
image.
328
Blanchon, M., Morel, O., Zhang, Y., Seulin, R., Crombez, N. and Sidibé, D.
Outdoor Scenes Pixel-wise Semantic Segmentation using Polarimetry and Fully Convolutional Network.
DOI: 10.5220/0007360203280335
In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2019), pages 328-335
ISBN: 978-989-758-354-4
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

To handle both the classification of so-called stan-
dard zones (or ”low complexity”) and areas of high
complexity, the introduction of a discriminant moda-
lity is considered.
The choice is oriented towards the polari-
metric imaging, giving the ability to measure
and recover the changes in the light waves.
SFP (shape-from-polarization) techniques have
been using the ability of polarimetry to ex-
tract information from highly reflective objects
(Rahmann and Canterakis, 2001; Morel et al., 2005).
Therefore, polarimetric cameras have experienced
a big development leading to better ease of use and
practicality. The Division of Focal Plane (DoFP)
allows the capture of an image using four different
polarizers. In consequence, it is similar as acquiring
four images with four polarizers.
Combining the advantages of different data types,
a polarimetric camera will process non-reflective data
as usual gray-scale portion of the image, while re-
flective areas will observe changes in the image infor-
mation. In consequence of using polarimetric images,
a set of constraints has been deduced to design a data
augmentation process.
Since the aim of this paper is to measure and qua-
lify the usefulness of a complex modality applied to a
specific task, it is unnecessary to complexify the task
at the early stage of the processing. Consequently,
a widely used and tested network is the core of this
study: SegNet (Badrinarayanan et al., 2015). The ro-
butness and modularity of this architecture makes this
network the perfect candidate for our purpose.
As shown in Figure 1, this paper allows understan-
ding and exploitation of this new type of information
in the context of deep learning.
This paper proposes the following main contributions:
• Introduction of the polarimetry in the field of fea-
ture learning to discuss the advantages and disad-
vantages of such data. In addition, a dataset has
been created for the experimental needs.
• Creation of novel techniques allowing polarime-
tric data to be augmented by preserving the phy-
sical properties from this modality.
• Detection and segmentation of reflective areas
through standard convolutional deep learning
techniques.
The various past works on which this paper is ba-
sed are presented in Section 2. Then, the different
processes of our implementation are introduced in the
Section 3. The forth section summarize all the ne-
cessary steps for the experiment. Also, this section
presents the results of the two modalities used (pola-
rimetry and RGB) and the discussions that will com-
pare the results obtained and also their interpretations.
The last section concludes on this work as well as of-
fers an opening on future work.
2 RELATED WORKS
2.1 Scene Segmentation
The pixel-wise semantic segmentation is the ability of
giving a label for each pixel of an image. This task re-
quires an accurate learning of the features on a set of
image. This leads to the creation of a generic model
which is able to classify at the pixel-level. Many re-
search proved that deep learning models tend to make
complex task learning and understanding accessible.
Computer vision has benefited from the advances in
this field to progress in general tasks. More precisely,
many applications of semantic segmentation has been
developed; among the most represented: road scene
segmentation (Oliveira et al., 2016), indoor scene un-
derstanding (Gupta et al., 2014; Qi et al., 2017).
The first remarkable deep learning based segmen-
tation is the FCN from Long et al. (Long et al., 2015),
that allows the segmentation of image of any sizes
without fully connected layers. Starting from this pre-
vious paper, as the years and the evolution of power
increased, multiple networks, each with better perfor-
mance, have been released: SegNet (Badrinarayanan
et al., 2015), DeepLab (Chen et al., 2015; Chen et al.,
2016; Chen et al., 2018), Image-to-Image (Isola et al.,
2017) , Conditional Generative Adversarial Networks
(Wang et al., 2018).
2.2 Polarimetry
Polarimetry is the science of measuring the polarized
state of the light. As a consequence, a polarimetric
camera (Wolff and Andreou, 1995) gives the expe-
rience of recovering the light changes in the captured
environment. Because of this behavior, the informa-
tion from this camera could be the perfect candidate
as a discriminant factor for complex scene semantic
understanding.
As shown in Figure 2, polarimetric images can be
used advantageously, because the reflection operates
a direct impact on the image.
For example, Kai Berger et al. proposed a method for
depth recovering from polarimetric images in urban
environment (Berger et al., 2017), treating the moda-
lity as a common RGB camera. Other polarization
based systems have been proposed for water detection
using polarized information. For example, Nguyen et
Outdoor Scenes Pixel-wise Semantic Segmentation using Polarimetry and Fully Convolutional Network
329

Figure 2: Reflection Influence on Polarimetry. (a) is a zoom
on the non-polarized area and (b) on a polarized area. Cle-
arly, on a polarized surface, the micro-grid appears and
reveals an intensity change according to the polarizer af-
fected.
al. proposed a method for water tracking with a po-
larized stereo system (Nguyen et al., 2017) achieving
an approximate accuracy of 65% exceeding the previ-
ous state of the art method accuracy of approximately
45% (Yan, 2014). Rankin and Matthies proposed an
application in recognition of mud for autonomous ro-
botics and offered a full benchmark for the segmenta-
tion processes (Rankin and Matthies, 2010b).
One of the disadvantages of these previous methods
is the lack of automation of tasks or the difficulty of
deployment. In contrast, a deep learning approach al-
lows the creation of a model that can be reused and
redesigned as it goes along.
Despite the useful and informative aspects of po-
larimetric system, the use of such cameras have been
quite restricted, due to the limitation of hardware and
automatic integration. Using the DoFP technique
(Nordin et al., 1999b; Nordin et al., 1999a; Millerd
et al., 2006), the polarimetric camera has been intro-
duced, which allow easier integration. DoFP techni-
que allows having the polarized filters in an array di-
rectly on the sensor. In this design, four polarized
filters, with unique angles, are used to capture four
different measurements instantly in one shot. Many
image processing and computer vision applications
can benefit from recent DoFP-polarimetric camera.
In this paper, we are introducing polarimetry to the
field of pixel-wise semantic segmentation for outdoor
scenes.
3 METHOD
3.1 Polarimetric Data Pre-processing
Contrary to other standard type of images (RGB,
gray-scale, etc.), the image provided by a DoFP ca-
mera is composed of 2x2 super-pixels. Consequently,
we use an interpolation method (Ratliff et al., 2009)
in order to recover polarimetry images. The key idea
behind this transformation is to extract three one-
channel images to represent three physical notions:
the Angle of Polarization (AoP), the Degree of Po-
larization (DoP) and the Intensity (I). The AoP repre-
sents the value of the angle of polarization at each
pixel while the DoP is the strength of the polarization
state of the incoming light for each pixel.
In nature, the light is mainly partially linearly polari-
zed which reduces the Stokes parameters to three pa-
rameters as bellow:
S =
s
0
s
1
s
2
0
=
P
0
+ P
90
P
0
− P
90
P
45
− P
135
0
, (1)
where s
{0,1,2}
are the three-first Stokes parameters,
and P
{0,45,90,135}
the intensity output images corre-
sponding to the orientation of the polarizer. The com-
monly used Stokes vectors can be normalized by s
0
:
¯
S =
¯s
1
¯s
2
0
=
1
s
0
s
1
s
2
0
. (2)
AoP and DoP can be deduced according to:
DoP =
p
¯s
1
2
+ ¯s
2
2
, (3)
AoP =
1
2
tan
−1
(
s
1
s
2
). (4)
The last parameter I is the intensity which is the com-
bination of all polarized states intensities:
I =
P
0
+ P
45
+ P
90
+ P
135
2
. (5)
After this computation, three gray-scale descrip-
tion images of the raw polarimetric data are obtained.
We have chosen to build an HSL (Hue Saturation Lu-
minance) image mapping the three previous sources
of information. This colorspace allows specific beha-
vior per channel which fit with the data provided by
AoP, DoP and I. The hue is commonly a 360° periodic
value, the saturation is a value between zero and one
as well as the value for the luminance. To fit the pre-
requisites of this color space, we made the adaptation
and/or normalization of our images according to each
channel and then merged them together (Wolff and
Andreou, 1995).
H −→ 2 ∗ AoP, S −→ DoP, L −→ I/255. (6)
HSL can be seen as a single 3-channel image. This
allows any RGB pre-initialized DL network to deal
with these images. It is then possible to augment the
data taking advantage of the HSL representation.
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
330

3.2 Polarimetric Data Augmentation
As previously explained, polarimetric information
characterizes the vectorial representation of light. By
consequence, any image has a unique meaning only
for these precise camera parameters and orientations.
The augmentation procedure consists in creating new
images with the application of a transformation and/or
an interpolation. The constraints induced by the type
of data are exported to any transformation applied.
The luminance and saturation channels can be rele-
ased of the constraints because their attributed values
are invariant around the optical axis. Contrarily, the
hue is affected by this transformation. It is neces-
sary to recompute the hue coherently with the phy-
sical properties of the camera. In this unique case, the
angle of polarization will have a consistent physical
meaning.
While rotating the camera counter-clockwise, the
angle of polarization is rotated clockwise. Let θ be the
applied rotation angle to the camera, R
θ
the rotation
matrix and H the hue channel of the image:
H
rotated
= R
θ
(H
prev
− θ). (7)
At the end of this computation, the image will keep
its physical properties and be rotated.
As shown in Table 1, a set of transformations has been
developed to give the ability to extend any polarime-
tric images dataset and it is remarkable that only the
hue channel needs some modifications to stick to phy-
sical properties. The translation is only a shift in the
images, which means that there is no modification in
the view point of the camera. Since a polarimetric
camera is dependent on the actual position and view
point, the hue channel remains invariant to translation.
On the other hand, if the camera lens has a wide an-
gle, then in this case an additional transformation will
be necessary (Table 1 -*).
3.3 Pixel-wise Segmentation with Deep
Learning
Deep learning shows great performances on learning
new kind of features and giving genericity to a model.
SegNet (Badrinarayanan et al., 2015) is employed
in our work because of its robustness and short trai-
ning time. The SegNet has an encoder-decoder de-
sign and an architecture composed of 36 layers. In
our application, the key point in this design lies in the
encoder part. It is composed of 13 layers, fitting per-
fectly the VGG-16 (Simonyan and Zisserman, 2014)
ConvNet configuration B. In consequence, a transfer
learning (Pan et al., 2010; Torrey and Shavlik, 2010)
method can be applied allowing pre-initialization of
the network. Considering this approach, an efficient
training can be operated, avoiding a costly end-to-end
training.
3.4 A New Dataset: PolaBot
Acquisition was conducted to provide a new multi-
modal dataset PolaBot with polarimetric images. To
the best of our knowledge, no such specific dataset
has been released yet. Moreover, in order to make
this dataset reliable for different fields (robotic, auto-
nomous navigation, etc.), the acquisitions were made
with a multi-modal system of four calibrated cameras.
Three synchronized modalities are represented, two
RGB from different angles, one NIR (Near-Infrared)
and one polarimetric camera. In addition, this col-
lection of information will allow a strong and efficient
benchmark, giving the opportunity to compare stan-
dard modality to the polarimetry for the exact same
scenes and application. This dataset is available at:
http://vibot.cnrs.fr/polabot.html.
4 EXPERIMENTS
To confirm our hypothesis of the polarimetric data
being more efficient than standard modality for our
application, experiments have been conducted, allo-
wing a comparison.
All the experiments were performed on the same
dedicated server composed of an Nvidia Titan Xp
(12GB Memory) GPU, 128GB of RAM and two CPU
accumulating a total of 24 physical cores (48 threads).
For the SegNet Network, internal parameters of
the training must be set. We had to set the loss
function and the optimizer. We decided to use Adam
(Kingma and Ba, 2014) as optimizer and as the loss
function the cross entropy loss, defined as:
CEL(p, q) = −
∑
∀x
p(x)log(q(x)), (8)
where x represents the class, p(x) is the prediction for
the x class and q(x) the ground truth. Also, for all the
training, the learning rate was initialized as 10
−4
and
a maximum of 500 epochs.
4.1 Metrics
To measure the efficiency of the training, common
metric has been employed during the process: MIoU
(Mean Intersection over Union), F1 Score, Mean
Accuracy and Overall Accuracy. The IoU is defined
as:
Outdoor Scenes Pixel-wise Semantic Segmentation using Polarimetry and Fully Convolutional Network
331
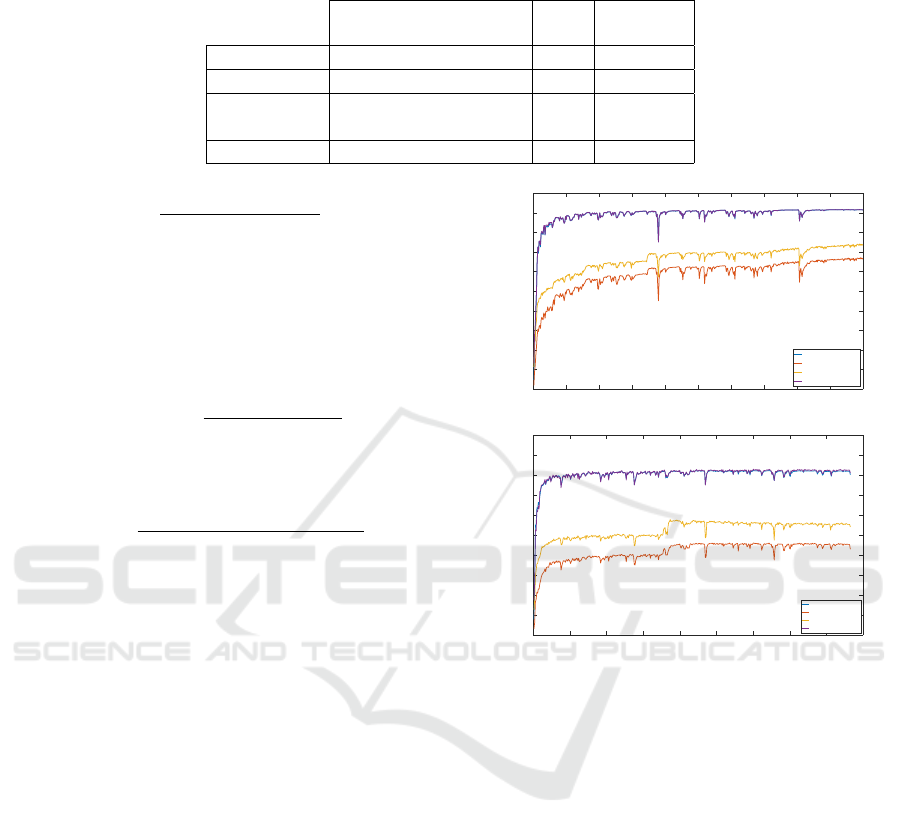
Table 1: Augmentation procedure per channels. Here ”-” represents invariant, ”*” represents that under condition this para-
meter can be modified.
AoP
(H)
DoP
(S)
Intensity
(L)
Crop - - -
Roation R
θ
(H − θ) (mod 360) - -
Symmetry
(Flip)
−H (mod 360) - -
Translation -* -* -
IoU =
Area of Intersection
Area of Union
. (9)
Another widely used metric is the F1 score. This
metric observes the same behavior as the MIoU since
the perfect score is 1. This metric is a combination
of the recall and the precision, which correspond re-
spectively to the relevance and the robustness of the
results:
F1 Score = 2 ∗
precision . recall
precision + recall
. (10)
Finally, the per-class accuracy is the measurement
of fitting for each class:
Accuracy
C
=
∑
i
[ p(i) = C ∩ GT (i) = C ]
∑
i
[ GT (i) = C ]
, (11)
where C is the class, p(i) is the predicted class of pixel
i and GT (i) the ground truth.
4.2 Results
A color chart is used, therefore, for the next ima-
ges, each area color in the image will have a meaning
shown in the Table 2.
Each class has a clear meaning except unlabeled
and None. None corresponds to zones segmented by
hand but considered non-revealing with respect to our
application. The unlabeled class, on the other hand,
comes from manual segmentation errors. This class
is the eighth class but is not necessarily consistent.
Therefore, the results for this class will be neglected
and taken into account in the conclusions drawn.
4.2.1 Training Results
Metrics for each epoch has been computed. This pro-
cedure allows seeing the fitness evolution of the mo-
del.
As shown in Figure 3, both curves are different ac-
cording to the data provided to the network. First, it
is possible to see that the two processes did not stop
at the same time. While the network with polarime-
tric data reached 500 epochs, the network processing
RGB data ended at 432 epochs. Indeed, we had put
0 50 100 150 200 250 300 350 400 450 500
Epoch
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Metrics
F1Score
IoU
Mean Accuracy
Overall Accuracy
0 50 100 150 200 250 300 350 400 450
Epoch
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Metrics
F1Score
IoU
Mean Accuracy
Overall Accuracy
Figure 3: Training Results - Top is the graph correspon-
ding to metrics estimation for the polarimetric data while
training. The bottom graph corresponds to the RGB data
training.
into place a stopping criterion to prevent the network
from decaying. This result means that the SegNet
RGB has experienced a decrease in its validation me-
trics for more than 10 epochs. However, our process
allows the recovery of the optimal state in order to
assess the so-called ”optimal” results.
In a second step, it is possible to notice the diffe-
rences in metric values. The SegNet Polarimetry re-
aches a MIoU value of 0.66, an F1 score of 0.91 and
an average accuracy of 0.73. On the other hand, the
SegNet RGB appears to be less efficient with lower
scores: MIoU of 0.42, F1 score of 0.8 and average
accuracy of 0.54.
It is possible to conclude this estimate of training
by stating that SegNet Polarimetry seems to perform
better during the learning phase.
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
332

Table 2: Color chart. This color chart allows uniformity in the visualization of results (each class has an affiliated color).
Meaning Unlabeled Sky Water Windows Road Cars Building None
Color Black Green Blue Yellow Orange Red Grey White
Table 3: Per-class Accuracy and accuracy Difference.
Sky Water Windows Road Cars Building None Mean
Polarimetry 75.34 % 75.70 % 82.85 % 77.82 % 71.40 % 87.69 % 78.95 % 78.54 %
RGB 89.57 % 78.61 % 44.50 % 78.45 % 48.48 % 67.84 % 83.4 % 69.83 %
Difference -14.23% -3.51 % 38.35 % -0.63 % 22.92 % 19.85 % -4.45 % 8.71 %
Figure 4: Polarimetry Results - Test Set Output.The top row is the input HSL image. The middle row is the ground truth
manually segmented. The bottom row is the prediction output by the SegNet Polarimetry.
4.2.2 Testing Results
The testing results correspond to the results obtained
at the output of the network. As shown in the Table
3, in order to compare the impacts of each type of
data, their respective accuracy by class was calculated
for RGB and polarimetry and followed by comparison
via difference:
Accuracy
Diff
= Accuracy
Pol
− Accuracy
RGB
. (12)
The Figure 4 shows the results obtained at the out-
put of the SegNet Polarimetry and the Figure 5 those
of the SegNet RGB. The segmentation is correct in
both cases and visually offers good results.
4.3 Discussion
As shown in the Table 3, very high accuracy can be
observed in all segmented classes using polarimetric
data. As the data set is not generic, the sky remains
on the same tone (blue), which gives a significant ad-
vantage over the RGB mode. The other classes where
the RGB model is better are: road, water and none.
These differences are minimal and can be explained
in several ways. One of our hypotheses concerns the
difference in manual segmentation for ground truth.
RGB and polarimetry were segmented independently,
increasing uncertainties. The difficulty of segmen-
tation of certain classes must be taken into account.
Another way to look at these results is to consider the
advantages and disadvantages of cameras in relation
to the dataset. For example, the road can be polarized
if there is a high temperature; therefore, polarimetry
would have an advantage over the RGB model. Since
the dataset is acquired in only one type of weather
condition, the RGB may have an advance over the ot-
her model, which may explain these results.
However, polarimetry model gives very high accu-
racy in all the classes. More precisely, when seg-
menting areas such as windows, cars and building, the
model obtain a big positive difference compared to
the RGB. The window segmentation is almost twice
more performant using polarimetry model than RGB
model. Indeed, these results can be explained by the
polarization state of such areas.
Outdoor Scenes Pixel-wise Semantic Segmentation using Polarimetry and Fully Convolutional Network
333

Figure 5: RGB Results - Test Set Output. The top row is the input RGB image. The middle row is the ground truth manually
segmented. The bottom row is the prediction output by the SegNet RGB.
5 CONCLUSION AND FUTURE
WORK
In this paper, we proposed the introduction of pola-
rimetry to pixel-wise road scenes segmentation field.
Since to our knowledge there was no dataset with out-
door scenes captured via polarimetry, we created our
own dataset. This dataset being made up of several
modalities, the key idea was to have a comparison
measure. As polarimetric data require meticulous ex-
ploitation, we have developed an augmentation met-
hod to preserve the physical properties of this moda-
lity. This approach defines the possible transformati-
ons and provides the necessary formulas for a rotation
or flipping. We then used our augmented dataset as in-
put to the SegNet Network to estimate the results. Af-
ter comparing the SegNet Polarimetry and the SegNet
RGB we can deduce that polarimetry offers a consi-
derable advantage over RGB. Indeed, reflective areas
are better detected while maintaining or improving
the segmentation performance of other areas. We can
conclude that polarimetry can provide a new type of
information usefull in many fields such as robotics,
computer vision or autonomous cars.
However, there are still some areas for impro-
vement. One area for improvement is the use of a
more complex network with deeper and more abstract
functionalities. This will then allow the results to be
compared between a simple network and a deeper net-
work. The immediate objective of improvement is
to use raw polarimetric images to eliminate any pre-
processing.
ACKNOWLEDGEMENTS
This work was supported by ANR VIPeR, ANR
ICUB. We gratefully acknowledge the support of
NVIDIA Corporation with the donation of GPUs used
for this research.
REFERENCES
Badrinarayanan, V., Handa, A., and Cipolla, R. (2015). Seg-
net: A deep convolutional encoder-decoder architec-
ture for robust semantic pixel-wise labelling. CoRR,
abs/1505.07293.
Berger, K., Voorhies, R., and Matthies, L. H. (2017). Depth
from stereo polarization in specular scenes for urban
robotics. In Robotics and Automation (ICRA), 2017
IEEE International Conference on, pages 1966–1973.
IEEE.
Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K., and
Yuille, A. L. (2015). Semantic image segmentation
with deep convolutional nets and fully connected crfs.
In ICLR.
Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K., and
Yuille, A. L. (2016). Deeplab: Semantic image seg-
mentation with deep convolutional nets, atrous convo-
lution, and fully connected crfs. arXiv:1606.00915.
Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K., and
Yuille, A. L. (2018). Deeplab: Semantic image seg-
mentation with deep convolutional nets, atrous convo-
lution, and fully connected crfs. IEEE transactions on
pattern analysis and machine intelligence, 40(4):834–
848.
Couprie, C., Farabet, C., Najman, L., and LeCun, Y. (2013).
Indoor semantic segmentation using depth informa-
tion. arXiv preprint arXiv:1301.3572.
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
334

Gupta, S., Girshick, R., Arbel
´
aez, P., and Malik, J. (2014).
Learning rich features from rgb-d images for object
detection and segmentation. In European Conference
on Computer Vision, pages 345–360. Springer.
Isola, P., Zhu, J.-Y., Zhou, T., and Efros, A. A. (2017).
Image-to-image translation with conditional adversa-
rial networks. arXiv preprint.
Kingma, D. P. and Ba, J. (2014). Adam: A method for sto-
chastic optimization. arXiv preprint arXiv:1412.6980.
Long, J., Shelhamer, E., and Darrell, T. (2015). Fully con-
volutional networks for semantic segmentation. In
Proceedings of the IEEE conference on computer vi-
sion and pattern recognition, pages 3431–3440.
Millerd, J., Brock, N., Hayes, J., North-Morris, M., Kim-
brough, B., and Wyant, J. (2006). Pixelated phase-
mask dynamic interferometers. In Fringe 2005, pages
640–647. Springer.
Morel, O., Meriaudeau, F., Stolz, C., and Gorria, P. (2005).
Polarization imaging applied to 3d reconstruction of
specular metallic surfaces. In Machine Vision Appli-
cations in Industrial Inspection XIII, volume 5679,
pages 178–187. International Society for Optics and
Photonics.
Nguyen, C. V., Milford, M., and Mahony, R. (2017). 3d
tracking of water hazards with polarized stereo ca-
meras. In Robotics and Automation (ICRA), 2017
IEEE International Conference on, pages 5251–5257.
IEEE.
Nordin, G. P., Meier, J. T., Deguzman, P. C., and Jones,
M. W. (1999a). Diffractive optical element for stokes
vector measurement with a focal plane array. In Pola-
rization: Measurement, Analysis, and Remote Sensing
II, volume 3754, pages 169–178. International Society
for Optics and Photonics.
Nordin, G. P., Meier, J. T., Deguzman, P. C., and Jones,
M. W. (1999b). Micropolarizer array for infrared ima-
ging polarimetry. JOSA A, 16(5):1168–1174.
Oliveira, G. L., Burgard, W., and Brox, T. (2016). Ef-
ficient deep models for monocular road segmenta-
tion. In Intelligent Robots and Systems (IROS), 2016
IEEE/RSJ International Conference on, pages 4885–
4891. IEEE.
Pan, S. J., Yang, Q., et al. (2010). A survey on transfer
learning. IEEE Transactions on knowledge and data
engineering, 22(10):1345–1359.
Qi, C. R., Su, H., Mo, K., and Guibas, L. J. (2017). Point-
net: Deep learning on point sets for 3d classification
and segmentation. Proc. Computer Vision and Pattern
Recognition (CVPR), IEEE, 1(2):4.
Rahmann, S. and Canterakis, N. (2001). Reconstruction of
specular surfaces using polarization imaging. In null,
page 149. IEEE.
Rankin, A. and Matthies, L. (2010a). Daytime water de-
tection based on color variation. In Intelligent Ro-
bots and Systems (IROS), 2010 IEEE/RSJ Internati-
onal Conference on, pages 215–221. IEEE.
Rankin, A. L. and Matthies, L. H. (2010b). Passive sen-
sor evaluation for unmanned ground vehicle mud de-
tection. Journal of Field Robotics, 27(4):473–490.
Ratliff, B. M., LaCasse, C. F., and Tyo, J. S. (2009).
Interpolation strategies for reducing ifov artifacts
in microgrid polarimeter imagery. Optics express,
17(11):9112–9125.
Simonyan, K. and Zisserman, A. (2014). Very deep con-
volutional networks for large-scale image recognition.
arXiv preprint arXiv:1409.1556.
Torrey, L. and Shavlik, J. (2010). Transfer learning. In
Handbook of Research on Machine Learning Applica-
tions and Trends: Algorithms, Methods, and Techni-
ques, pages 242–264. IGI Global.
Wang, T.-C., Liu, M.-Y., Zhu, J.-Y., Tao, A., Kautz, J., and
Catanzaro, B. (2018). High-resolution image synthe-
sis and semantic manipulation with conditional gans.
In IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), volume 1, page 5.
Wolff, L. B. and Andreou, A. G. (1995). Polariza-
tion camera sensors. Image and Vision Computing,
13(6):497–510.
Yan, S. H. (2014). Water body detection using two camera
polarized stereo vision. International Journal of Re-
search in Computer Engineering & Electronics, 3(3).
Outdoor Scenes Pixel-wise Semantic Segmentation using Polarimetry and Fully Convolutional Network
335
