
Evaluating OpenCL as a Standard Hardware Abstraction for a
Model-based Synthesis Framework: A Case Study
Omair Rafique and Klaus Schneider
Department of Computer Science, University of Kaiserslautern, Kaiserslautern, Germany
Keywords:
Model-based Design, Heterogeneous Synthesis, Parallel Computing Languages.
Abstract:
In general, model-based design flows start from hardware-agnostic models and finally generate code based
on the used model of computation (MoC). The generated code is then manually mapped with an additional
non-trivial deployment step onto the chosen target architecture. This additional manual step can break all
correctness-by-construction guarantees of the used model-based design, in particular, if the chosen architecture
employs a different MoC than the one used in the model. To automatically bridge this gap, we envisage a
holistic model-based design framework for heterogeneous synthesis that allows the modeling of a system using
a combination of different MoCs. Second, it integrates the standard hardware abstractions using the Open
Computing Language (OpenCL) to promote the use of vendor-neutral heterogeneous architectures. Altogether,
we envision an automatic synthesis that maps models using a combination of different MoCs on heterogeneous
hardware architectures. This paper evaluates the feasibility of incorporating OpenCL as a standard hardware
abstraction for such a framework. The evaluation is presented as a case study to map a synchronous application
on different target architectures using the OpenCL specification.
1 INTRODUCTION
A heterogeneous embedded system consists of differ-
ent devices including possibly single-core and multi-
core processors with application-specific hardware
and even more specific sensors and actors. At the
level of its software architecture, it may consist of
many components concurrently running on these de-
vices that interact with each other via particular mod-
els of computation (MoCs). To develop such complex
embedded systems, a new modeling and program-
ming paradigm has been introduced by model-based
design: A model-based design is generally character-
ized with a hardware-agnostic abstract model and is
supported by a complete tool chain typically provid-
ing simulators, tools for verification, code generators,
and tools for system and communication synthesis.
Apart from modeling tools, many specifica-
tion languages (Dagum and Menon, 1998; Stone
et al., 2010) have been introduced to target high-
performance computing in highly parallel and het-
erogeneous architectures. Among them, the Open
Computing Language (OpenCL) has gained a tremen-
dous amount of popularity and support by the leading
hardware vendors including Intel, Apple, AMD and
many others. In contrast to proprietary specification
languages with limited hardware choices, OpenCL
allows task-parallel and data-parallel heterogeneous
computing on a variety of modern CPUs, GPUs,
DSPs, and other microprocessor designs (Stone et al.,
2010).
The existing model-based design methodologies
are based on different models of computation (MoCs)
(Lee and Messerschmitt, 1987; Benveniste et al.,
2003; Cassandras and Lafortune, 2008). We appreci-
ate the convenient use of model-based design frame-
works, but we also address one of the major limita-
tions of their application: The final result of these de-
sign flows is essentially a set of automatically gener-
ated C files that have to be deployed in an additional
non-trivial manual step to a particular target architec-
ture. We termed this gap as the mapping/deployment
gap. To further automate the design process and
to bridge this gap, we envisage a holistic model-
based design framework that allows modeling behav-
iors with a heterogeneous combination of MoCs, and
employs the OpenCL specification to abstract from
the real hardware platforms. This way, we can au-
tomatically synthesize the modeled behavior on any
OpenCL-abstracted targeted hardware thereby bridg-
ing the aforementioned mapping/deployment gap.
This paper presents a preliminary case study to an-
386
Rafique, O. and Schneider, K.
Evaluating OpenCL as a Standard Hardware Abstraction for a Model-based Synthesis Framework: A Case Study.
DOI: 10.5220/0007470503860393
In Proceedings of the 7th International Conference on Model-Driven Engineering and Software Development (MODELSWARD 2019), pages 386-393
ISBN: 978-989-758-358-2
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

Figure 1: The basic building block diagram of the concept.
alyze the feasibility of OpenCL as a standard hard-
ware abstraction for the use in a model-based design
framework for the fully automated system synthesis.
To this end, the case study based on a computation-
intensive synchronous application is implemented us-
ing the proposed framework and the results are eval-
uated against two main features offered by OpenCL,
i.e., the cross-vendor portability and the substantial
performance acceleration in parallel architectures.
2 THE FRAMEWORK
A holistic model-based design framework for hetero-
geneous synthesis is conceived as a completely au-
tomatic design flow from a specification to a target
hardware architecture. For that reason, the framework
is designed to provide and practice two primary con-
cepts: First, the concept of modeling a system with
various MoCs (Lee and Messerschmitt, 1987; Ben-
veniste et al., 2003; Cassandras and Lafortune, 2008)
or even with a heterogeneous combination of these
MoCs (Eker et al., 2003; Kuhn et al., 2013), and sec-
ond, the concept of using vendor-neutral heteroge-
neous architectures as an integral part of the frame-
work, as realized, e.g., by means of standard abstrac-
tions like OpenCL.
2.1 Heterogeneous Modeling
Model-based design flows are based on models of
computation (MoC) that precisely determine why,
when and which atomic action of a system is exe-
cuted. Thus, a MoC specifies in general what triggers
the execution of a component and how these compo-
nents communicate with each other. Model-based de-
sign frameworks like Ptolemy II (Brooks et al., 2010)
and FERAL (Kuhn et al., 2013) also support model-
ing a system based on a heterogeneous combination
of MoCs. These frameworks provide a common plat-
form for organizing a system into different domains
characterized as directors. Each enclosing director
represents a semantic model based on a specific MoC
and triggers the execution of the contained compo-
nents in accordance to the implemented semantics.
The heterogeneous combination of MoCs is therefore
realized by coupling different directors within an ap-
plication scenario. The proposed framework there-
fore adopts and extends the concepts of these frame-
works for synthesizing a heterogeneous combination
of MoCs to real heterogeneous architectures.
2.2 OpenCL Abstraction
OpenCL is an open specification language designed
for heterogeneous parallel computing on cross-vendor
and heterogeneous architectures. The basic objective
of OpenCL can be understood from two primary ben-
efits it offers: First, OpenCL provides an abstract plat-
form model that can be exploited for substantial ac-
celeration in parallel computing. To this end, it sup-
ports both coarse-grained (task-level) as well as fine-
grained (data-level) parallelism. Second, it provides
the ability to write vendor-neutral cross platform ap-
plications. This is achieved as it provides upper-level
abstractions hiding the lower-layer implementations
(drivers and the runtime) as well as consistent mem-
ory and execution models to allow cross-vendor de-
velopment. The basic strength of this abstraction
is the ability to scale code from simple embedded
microcontrollers to multi-core CPUs, up to highly-
parallel GPU architectures, without revising the code.
Since a general discussion of OpenCL is out of
scope for this paper, we refer to (Lee et al., 2015;
Shen et al., 2013) for further details. For the proposed
framework, the basic idea is to exploit the ability of
OpenCL to write vendor-neutral cross platform appli-
cations.
Evaluating OpenCL as a Standard Hardware Abstraction for a Model-based Synthesis Framework: A Case Study
387

2.3 Heterogeneous Synthesis
The idea to amalgamate the concept of heterogeneous
modeling and the OpenCL abstraction under the su-
pervision of a common framework leads to hetero-
geneous synthesis. For heterogeneous modeling, the
proposed framework realizes a hierarchical structure
to compose different models as realized in (Eker et al.,
2003; Kuhn et al., 2013). With this approach, a com-
plex system can be effectively modeled into a tree of
nested subsystems as shown in Figure 1. Each node
(a subsystem) of the tree may be composed of exe-
cutable components, enclosed by a director/domain
that enforces the execution and communication of the
node based on the implemented semantics. These
implemented semantics actually represent the MoC.
The executable components are further composed of
workers where the actual behavior of the subsystem is
implemented. In other words, a worker is simply a C
function that implements a part of the algorithm, and
is triggered based on the MoC of the component. This
complete hierarchy from directors to components, and
up to the workers provides a common platform for
modeling a complex system with heterogeneous com-
bination of MoCs.
Apart from this openness and abstraction provided
by the framework, OpenCL also does not impose a
specific MoC. Instead, it offers an abstract and highly
diffusive execution model that provides a transparent
way of distributing an application for the acceleration
of parallel computing. The OpenCL execution model
comprises two components: the host program and
kernels. A host is connected to one or more compute
devices (CPU, GPU, DSP etc.) and is responsible for
managing resources on compute devices, including
the organization of the executions of kernel instances.
Kernels are C-like functions that actually implement
the abstract behavior of the system or part of the sys-
tem. To this end, as shown in Figure 1, the OpenCL
host as a main application scenario, can be modeled
with the composition of directors/domains, whereas
the kernels can be naturally integrated as executable
components of the used domains. Each atomic in-
stance of the kernel then represents a worker, capable
of executing in parallel, a part of the complete behav-
ior.
3 THE CASE STUDY
In this section, we present a complete case study
based on a computation-intensive synchronous appli-
cation. The basic application used as a test case is first
discussed, followed by the discussion on how the ap-
Figure 2: Face detection using minimal facial features.
plication is modeled using the proposed framework,
and finally we report about detailed evaluations to an-
alyze various mappings of the application using the
OpenCL execution model.
3.1 The Synchronous Application
Instead of utilizing the available benchmarks that are
already presented in other publications (Lee et al.,
2015; Shen et al., 2013; Grewe and O’Boyle, 2011)
for generally evaluating the OpenCL specification, we
decided to develop a 2D-image processing algorithm
namely, the face detection using minimal facial fea-
tures. Image processing algorithms naturally allow a
wide margin for parallel computing, and thus became
a natural choice for evaluating the OpenCL model.
The algorithm is composed of three different mod-
ules as shown in Figure 2, and is based on the work
presented in (Chen and Lin, 2007) where it was orig-
inally implemented in OpenCV
1
. Each module was
transformed and implemented as an OpenCL kernel,
where each module performs a specific processing
task on the image, and runs synchronously with the
preceding module. A brief discussion on each mod-
ule is given in the following.
3.1.1 Skin Detection
The skin detection module performs a pixel-by-pixel
processing of the image to decide whether a specific
pixel lies in the defined range of the skin color. In con-
trast to (Chen and Lin, 2007), the range of the skin
color is determined by the combination of the RGB
model as well the normalized RGB model. Therefore,
based on this range, this module simply tests each
pixel and replaces non-skin color pixels with black
ones. However, the final outcome (as shown in Fig-
ure 2) also replaces some of the skin color pixels with
black ones. This is then sorted out in the next stage
by the skin quantization module.
1
http://docs.opencv.org
MODELSWARD 2019 - 7th International Conference on Model-Driven Engineering and Software Development
388
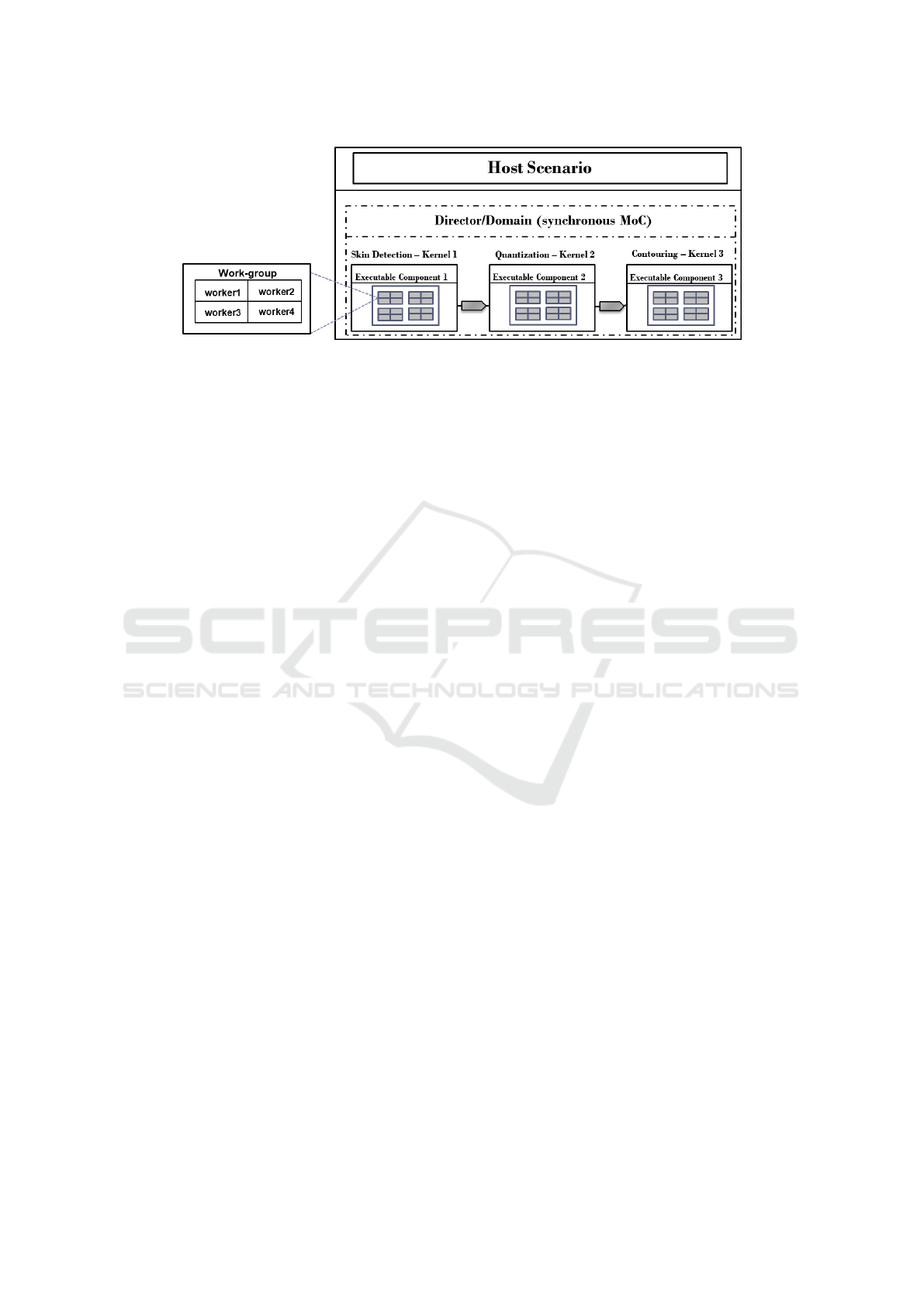
Figure 3: Application modeled under synchronous dataflow domain.
3.1.2 Skin Quantization
This module lowers the image resolution by splitting
the whole image into blocks of 10x10 pixels. The
number of black pixels within a block of hundred pix-
els are counted and if the total count is less than a
specified threshold, the block is extracted as a part of
the skin. As an example, for a 200x200 resolution
image, the module splits it into four-hundred blocks,
where each block contains 100 pixels. Each block
is then evaluated with the specified threshold. This
finally contributes in filtering out wrongly processed
black pixels that are placed by the first module.
3.1.3 Image Contouring
Image contouring or contour tracing is a common
technique applied on 2D images to extract informa-
tion about their general shape. Hence, it can simply be
applied to find out the boundaries of a digital image.
A variety of contour tracing algorithms are available
with their respective pros and cons (Seo et al., 2016).
However, the image contouring module of the pro-
posed algorithm specifically implements the Moore-
Neighbor tracing algorithm to extract the boundaries
of the quantized image, as shown in Figure 2.
3.2 Application Model using the
Framework
The design model of the application using the pro-
posed framework is depicted in Figure 3. As dis-
cussed, each module of the proposed algorithm im-
plemented as an OpenCL kernel is realized and desig-
nated as an executable component of the framework.
Each executable component denotes an abstract rep-
resentation of the module behavior. The host program
then determines the fine-grained parallelism where
the abstract executable component is defined in a set
of threads, termed as workers/work items to imple-
ment the complete behavior. These workers represent
the execution instances of the associated kernel and
can be grouped together in different work groups. Ide-
ally, each work group is assigned to a single compute
unit where a compute unit can simply be conceived as
for e.g., a logical core of a CPU or a streaming mul-
tiprocessor of a GPU. To ensure consistency with the
framework terminologies, we will use the terms exe-
cutable components and workers for OpenCL kernels
and work items respectively.
For this case study, the host provides a syn-
chronous dataflow domain for the execution of the
proposed algorithm. To this end, the algorithm com-
posed of three different modules is scheduled based
on a synchronous dataflow (SDF) MoC as shown in
Figure 3. Based on the SDF MoC, the order in which
modules are executed is specified statically at com-
pile time. Practically, the host program based on the
SDF MoC, enqueues the executable components on
the same OpenCL command queue in chronological
order. The executable components are triggered in se-
quence for execution and the final resulting image is
then retrieved by the host.
3.3 Evaluation
The case study is dedicated to observe and analyze the
two main claims associated with OpenCL namely, the
cross-vendor portability and the substantial accelera-
tion in parallel computing.
3.3.1 Cross-vendor Portabilty
The proposed framework is envisioned to support the
implementation of vendor-neutral heterogeneous ar-
chitectures. To this end, it is important to evaluate and
to collect preliminary results as a baseline to employ
OpenCL for implementing vendor-neutral heteroge-
neous architectures within the framework. There-
fore, this case study explores the ability of OpenCL
to facilitate cross-vendor portability by employing
devices of different types and from different ven-
dors. The already discussed algorithm implemented
Evaluating OpenCL as a Standard Hardware Abstraction for a Model-based Synthesis Framework: A Case Study
389
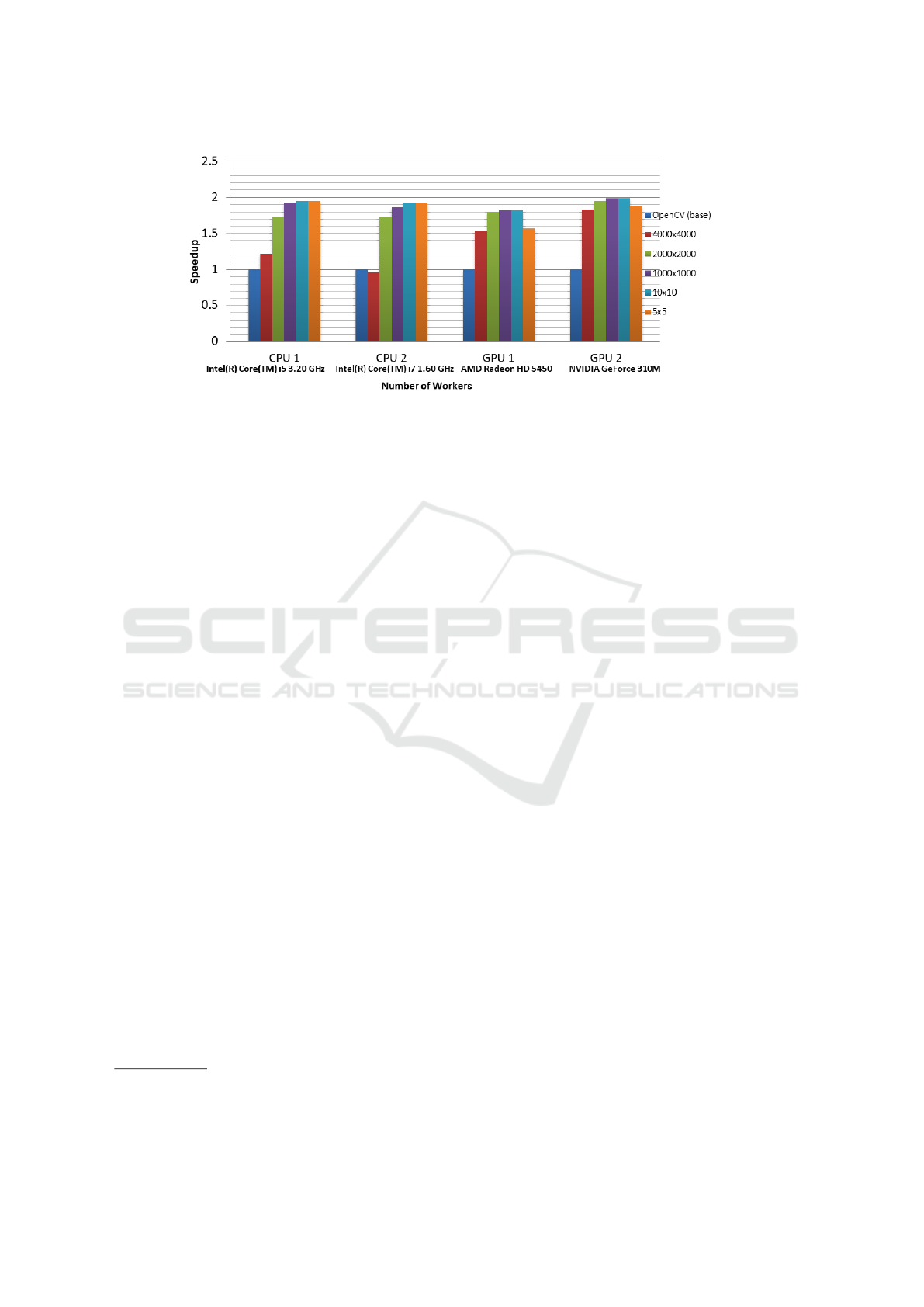
Figure 4: Workers vs Speedup.
with the OpenCL specification is evaluated on dif-
ferent devices including different CPUs and GPUs
from three different vendors, namely Intel
2
, AMD
3
and NVIDIA
4
.
3.3.2 Parallel Computation using OpenCL
The OpenCL model offers a very abstract environ-
ment for distributing and implementing an algorithm
with different levels of parallelism. The proposed
framework exploits this abstract execution model pro-
vided by OpenCL to better utilize the available hard-
ware resources and substantially accelerate the par-
allel computations. To this end, organizing and dis-
tributing executable components with different num-
ber of workers and work groups to express and to
evaluate various levels of parallelism is considered.
An executable component describes the behavior
of a single worker, and the host program then ex-
plicitly declares the number of workers to decide the
parallelism of the application. The total number of
workers represent the global work size of the compo-
nent and can further be arranged and divided in work
groups or compute units. The number of workers per
work group represents the local work size. To this
end, it is important to tune these parameters (workers
and work groups) to find the optimal level of paral-
lelism required for a particular architecture.
3.3.3 Results
We have measured the speedup factor against the to-
tal number of workers and work groups, respectively.
The speedup is basically calculated with reference to
2
https://software.intel.com
3
https://developer.amd.com/
4
https://developer.nvidia.com
the computation time (in seconds) of the OpenCV-
based naive implementation. The computation time
actually represents the total time taken by the com-
plete algorithm to finally detect the face in the given
input image.
Number of Workers. We introduced an additional
parameter namely, the block-size that allows us to
manage the amount of workload associated with each
worker. The block size actually specifies the number
of pixels that will be processed by each worker. Con-
sequently, increasing the block size implies increasing
the workload per worker and hence decreasing the to-
tal number of workers.
As shown in Figure 4, the speedup factor is mea-
sured for different global sizes ranging from the high-
est possible parallel implementation where the num-
ber of workers is equal to the total number of pixels
(4000x4000), up to the least number of just 25 (5x5)
workers. Decreasing the workers implies an increase
in the block size, where more workload is then man-
aged by each worker. The number of workers and
the block size affect performance differently on CPUs
and GPUs, based on different architectural character-
istics. Since GPUs generally accommodate a large
number of streaming cores/CUDA cores, they are ca-
pable of managing a large number of parallel threads.
On the contrary, the ability of a CPU to handle parallel
threads is just limited to the number of few available
cores.
Based on the results, first, even with the API over-
head, the OpenCL implementation clearly outper-
forms the original naive implementation with differ-
ent number of workers on different devices. Second,
on CPUs, we clearly observe a performance gain with
larger block sizes, implying less number of workers.
This is because executing a large number of workers
on few available cores results in significant schedul-
MODELSWARD 2019 - 7th International Conference on Model-Driven Engineering and Software Development
390
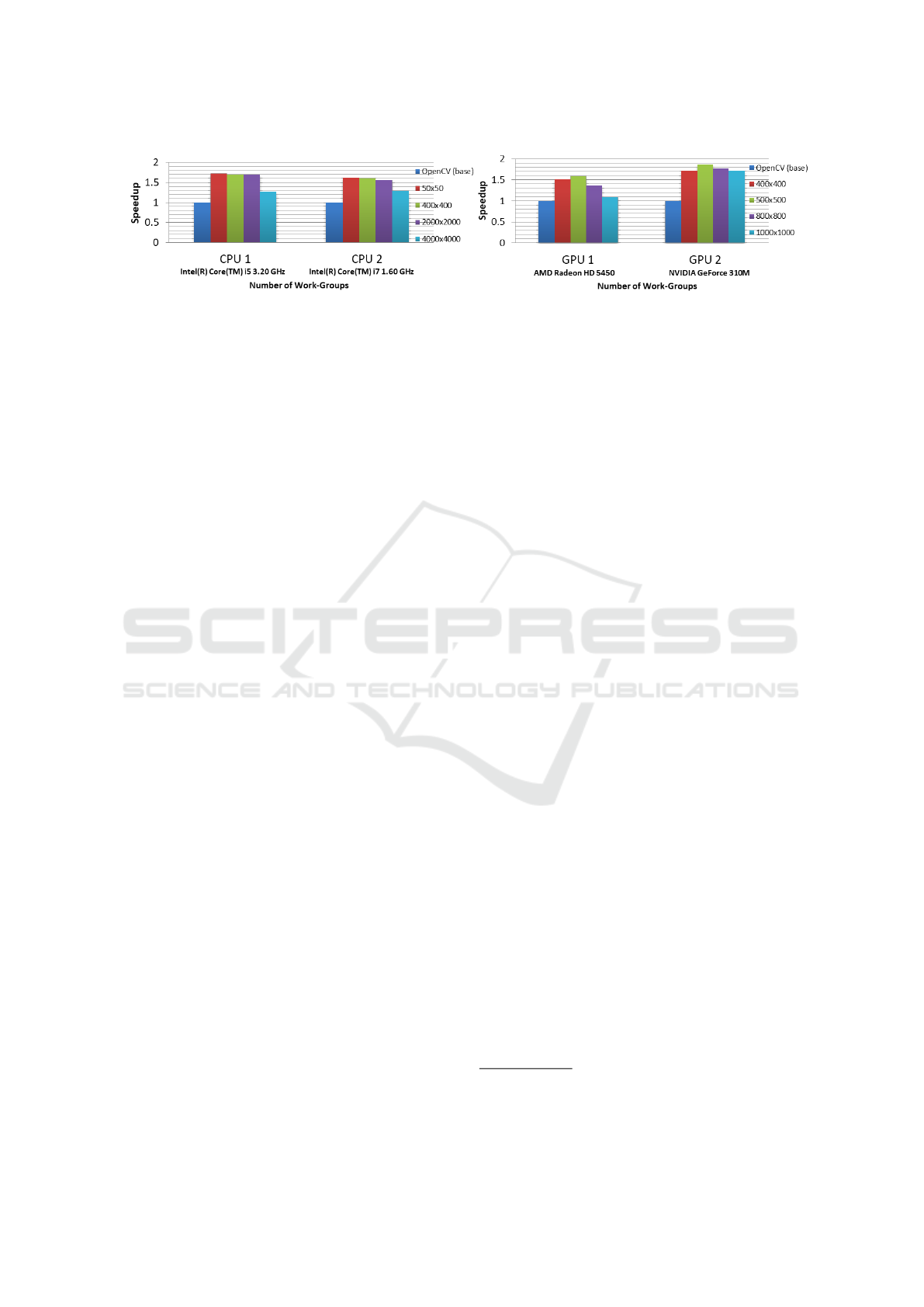
(a) CPUs (b) GPUs
Figure 5: Work-Groups vs. Speedup.
ing overhead on CPUs and thus reduces the overall
performance. Also, we observe that increasing the
block size to a certain level (after 1000x1000 work-
ers) saturates the performance gain. This is because
with each worker having sufficient workload results
in reduced the scheduling overhead.
On the contrary, GPUs outperform CPUs with
larger number of workers. However, with reduced
number of workers, especially when the size gets
lower than the available number of cores, the perfor-
mance starts to degrade substantially. This is because
the available cores are not occupied, and hence the
processing capability is not completely utilized.
Number of Work Groups. The work group size
specifies the number of workers in a group. On GPUs,
a work group or multiple work groups are executed on
a streaming multiprocessor (SM) where ideally each
worker is allocated to a streaming core/SIMD lane.
On CPUs, a work group is allocated to a logical core.
Since the employed CPUs and GPUs have a differ-
ent work group sizes limit, two separate plots are pre-
sented, one for each type of device, as shown in Fig-
ure 5.
Similar to the case of workers, even with differ-
ent work group sizes, the OpenCL implementation
outperforms the original naive implementation. As
shown in Figure 5a, on CPUs with an increasing num-
ber of work groups (decreasing work group size) the
performance decreases. With the highest number of
work groups, i.e., by 4000x4000 work groups, where
each work group is composed of a single worker, the
performance degrades substantially. This is because
with a larger number of work groups, the scheduling
overhead increases on CPUs.
As shown in Figure 5b, similar to CPUs, the per-
formance also decreases with increasing number of
work groups on GPUs. This is because with a larger
number of work groups, the work group size de-
creases, and with a smaller number of workers per
work group, the processing units of the SM are not
completely utilized. This effect can be clearly ob-
served with the highest number of work groups used
as in the case of 1000x1000 work groups.
Hence, the presented evaluations allow us to col-
lect preliminary results that can be used as a baseline
by the proposed framework to efficiently map models
based on the available resources as provided by the
target hardware. Also, it can be derived that OpenCL
can be employed as a standard abstraction for the pro-
posed framework to implement vendor-neutral het-
erogeneous architectures.
4 RELATED WORK
The related work is observed from two main aspects
as given in the following sections.
4.1 Model-based Design Frameworks
without OpenCL
Model-based design methodologies in the related
state-of-the-art mainly differ by their employed
MoCs. In (Bezati et al., 2014), the HW/SW co-
design methodology based on the CAL actor pro-
gramming language is built as an Eclipse plug-in on
top of ORCC
5
and OpenForge
6
. The open-source
tools are used as a tool chain of the framework, ca-
pable of providing simulation and the HW/SW syn-
thesis. The methodology also divulges design space
exploration techniques. A similar approach namely
System-CoDesigner is presented in (Haubelt et al.,
2008) by the University of Erlangen-Nuremberg.
The most popular and commercially recognized
model-based design tool Matlab
7
has introduced a va-
riety of supporting toolkits over time. The model-
ing toolkit Simulink provides a graphical extension
for modeling and simulation of systems. Similarly,
the Embedded Coder generates C and C++ files for
embedded software processors. The Simulink Design
5
http://orcc.sourceforge.net
6
https://sourceforge.net/projects/openforge
7
http://www.mathworks.com/matlabcentral/
Evaluating OpenCL as a Standard Hardware Abstraction for a Model-based Synthesis Framework: A Case Study
391

Verifier and Polyspace are introduced for the formal
verification of models and code, respectively. How-
ever, an interesting approach is presented in (Stefanov
et al., 2004) where the Matlab code is transformed to a
KPN specification using the Compaan compiler. The
HW backend Laura is used to map this KPN specifi-
cation to hardware.
Apart from these frameworks that support homo-
geneous modeling, Ptolemy (Eker et al., 2003) and
Ptolemy II (Brooks et al., 2010) support multiple
MoCs including dataflow process networks, discrete-
event models, synchronous/reactive models and many
more. These frameworks employ a hierarchical struc-
ture to compose different models under the supervi-
sion of software components called directors. Direc-
tors control the semantics of the execution of compo-
nents (actors) as well as the communication between
actors. Consequently, this allows modeling a system
with heterogeneous combination of MoCs.
FERAL is another framework that allows hetero-
geneous modeling and simulation (Kuhn et al., 2013).
It is developed to provide a holistic model-based de-
sign approach to enable the coupling of specialized
simulators in offline scenarios, i.e., without connect-
ing them to real hardware. This project very in-
terestingly adopts and extends some of the concepts
from the Ptolemy project. The proposed framework
adopts and further extends some of the concepts from
FERAL and Ptolemy in order to support the cause of
modeling behaviors with heterogeneous combination
of MoCs.
4.2 Model-based Design Frameworks
with OpenCL
Some of the existing model-based design frameworks
like those presented in (Boutellier and Hautala, 2016;
Lund et al., 2015; Schor et al., 2013) employ OpenCL
for better exploiting the parallelism offered by het-
erogeneous architectures. To this end, the frame-
work presented in (Schor et al., 2013) introduces a de-
sign flow for executing applications specified as syn-
chronous dataflow (SDF) graphs on heterogeneous
systems using OpenCL. The main focus of this work
is to develop and to provide features and concepts
to better utilize the parallelism and thereby improv-
ing end-to-end throughput in heterogeneous architec-
tures.
Another similar approach presented in (Boutellier
and Hautala, 2016) is aimed to provide a dataflow pro-
gramming framework not restricted to the SDF MoC
only. Hence, the framework targets modeling a sys-
tem based on dynamic dataflow and allows the map-
ping of actors with a data-dependent consumption of
inputs and a data-dependent production of outputs.
Similarly, (Lund et al., 2015) introduces a trans-
lation methodology for translating dataflow process
networks (DPNs) into programs running some of
the computations on the OpenCL platform. Conse-
quently, it allows the mapping of DPN networks de-
scribed in RVC-CAL to a data parallel architecture
consistent with the OpenCL API.
However, all the cited frameworks focus only on
mapping a system modeled with the dataflow MoC
to heterogeneous architectures using OpenCL. Con-
sequently, the ability to map heterogeneous models to
heterogeneous architectures under the supervision of
a common framework is still desired.
5 CONCLUSION AND FUTURE
WORK
In this paper, we first introduced the proposed frame-
work that enables the modeling of systems with a
heterogeneous combination of MoCs using the con-
cept of hierarchical composition of semantic domains.
Moreover, the concept of implementing portable het-
erogeneous architectures is realized by introducing
OpenCL as a standard hardware abstraction for the
model-based design of embedded systems. In this pa-
per, we presented a preliminary case study to evaluate
the use of OpenCL as an abstract hardware architec-
ture. For this reason, an application modeled by a
synchronous dataflow MoC was developed, deployed,
and evaluated using various parameter settings pro-
vided by OpenCL. The results obtained let us con-
clude that OpenCL provides a very abstract environ-
ment for implementing applications at different lev-
els of parallelism and thus became a natural choice
for facilitating the cause of automatic synthesis in the
framework. Based on this preliminary case study, fu-
ture work is aimed to use OpenCL as a standard hard-
ware abstraction to synthesize systems modeled with
a heterogeneous combination of MoCs for a hetero-
geneous target hardware platform.
REFERENCES
Benveniste, A., Caspi, P., Edwards, S., Halbwachs, N., Le
Guernic, P., and de Simone, R. (2003). The syn-
chronous languages twelve years later. Proceedings
of the IEEE, 91(1):64–83.
Bezati, E., Thavot, R., Roquier, G., and Mattavelli, M.
(2014). High-level dataflow design of signal process-
ing systems for reconfigurable and multicore hetero-
geneous platforms. Journal of Real-Time Image Pro-
cessing, 9(1):251–262.
MODELSWARD 2019 - 7th International Conference on Model-Driven Engineering and Software Development
392

Boutellier, J. and Hautala, I. (2016). Executing dynamic
data rate actor networks on OpenCL platforms. In Sig-
nal Processing Systems (SiPS), pages 98–103, Dallas,
TX, USA. IEEE Computer Society.
Brooks, C., Lee, E., and Tripakis, S. (2010). Exploring
models of computation with Ptolemy II. In Givargis,
T. and Donlin, A., editors, International Conference
on Hardware/Software Codesign and System Synthe-
sis (CODES+ISSS), pages 331–332, Scottsdale, Ari-
zona, USA. ACM.
Cassandras, C. and Lafortune, S. (2008). Introduction to
Discrete Event Systems. Springer, 2 edition.
Chen, Y.-J. and Lin, Y.-C. (2007). Simple face-detection
algorithm based on minimum facial features. In IEEE
Industrial Electronics Society (IECON), pages 455–
460, Taipei, Taiwan. IEEE Computer Society.
Dagum, L. and Menon, R. (1998). OpenMP: an industry
standard API for shared-memory programming. IEEE
Computational Science and Engineering, 5(1):46–55.
Eker, J., Janneck, J., Lee, E., Liu, J., Liu, X., Ludvig, J.,
Neuendorffer, S., Sachs, S., and Xiong, Y. (2003).
Taming heterogeneity – the Ptolemy approach. Pro-
ceedings of the IEEE, 91(1):127–144.
Grewe, D. and O’Boyle, M. (2011). A static task par-
titioning approach for heterogeneous systems using
OpenCL. In Knoop, J., editor, Compiler Construc-
tion (CC), volume 6601 of LNCS, pages 286–305,
Saarbr
¨
ucken, Germany. Springer.
Haubelt, C., Schlichter, T., Keinert, J., and Meredith, M.
(2008). SystemCoDesigner: automatic design space
exploration and rapid prototyping from behavioral
models. In Fix, L., editor, Design Automation Con-
ference (DAC), pages 580–585, Anaheim, California,
USA. ACM.
Kuhn, T., Forster, T., Braun, T., and Gotzhein, R. (2013).
FERAL - framework for simulator coupling on re-
quirements and architecture level. In Formal Meth-
ods and Models for Codesign (MEMOCODE), pages
11–22, Portland, OR, USA. IEEE Computer Society.
Lee, E. and Messerschmitt, D. (1987). Synchronous data
flow. Proceedings of the IEEE, 75(9):1235–1245.
Lee, J., Nigania, N., Kim, H., Patel, K., and Kim, H. (2015).
OpenCL performance evaluation on modern multi-
core CPUs. Scientific Programming, pages 859491:1–
859491:20.
Lund, W., Kanur, S., Ersfolk, J., Tsiopoulos, L., Lilius,
J., Haldin, J., and Falk, U. (2015). Execution of
dataflow process networks on OpenCL platforms. In
Euromicro International Conference on Parallel, Dis-
tributed, and Network-Based Processing, pages 618–
625, Turku, Finland. IEEE Computer Society.
Schor, L., Tretter, A., Scherer, T., and Thiele, L. (2013).
Exploiting the parallelism of heterogeneous systems
using dataflow graphs on top of OpenCL. In IEEE
Symposium on Embedded Systems for Real-time Mul-
timedia (ESTIMedia), pages 41–50. IEEE Computer
Society.
Seo, J., Chae, S., Shim, J., Kim, D.-C., Cheong, C., and
Han, T.-D. (2016). Fast contour-tracing algorithm
based on a pixel-following method for image sensors.
Sensors, 16(3):353:1–353:27.
Shen, J., Fang, J., Sips, H., and Varbanescu, A. (2013). An
application-centric evaluation of OpenCL on multi-
core CPUs. Parallel Computing, 39(12):834–850.
Stefanov, T., Zissulescu, C., Turjan, A., Kienhuis, B., and
Deprettere, E. (2004). System design using Kahn pro-
cess networks: The Compaan/Laura approach. In De-
sign, Automation and Test in Europe (DATE), pages
340–345, Paris, France. IEEE Computer Society.
Stone, J., Gohara, D., and Shi, G. (2010). OpenCL: A paral-
lel programming standard for heterogeneous comput-
ing systems. Computing in Science and Engineering,
12(3):66–73.
Evaluating OpenCL as a Standard Hardware Abstraction for a Model-based Synthesis Framework: A Case Study
393
