
3D Face Reconstruction from RGB-D Data by Morphable Model to Point
Cloud Dense Fitting
Claudio Ferrari, Stefano Berretti, Pietro Pala and Alberto Del Bimbo
Media Integration and Communication Center, University of Florence, Florence, Italy
Keywords:
3DMM Construction, 3DMM Fitting, 3D Face Analysis.
Abstract:
3D cameras for face capturing are quite common today thanks to their ease of use and affordable cost.
The depth information they provide is mainly used to enhance face pose estimation and tracking, and face-
background segmentation, while applications that require finer face details are usually not possible due to the
low-resolution data acquired by such devices. In this paper, we propose a framework that allows us to de-
rive high-quality 3D models of the face starting from corresponding low-resolution depth sequences acquired
with a depth camera. To this end, we start by defining a solution that exploits temporal redundancy in a
short-sequence of adjacent depth frames to remove most of the acquisition noise and produce an aggregated
point cloud output with intermediate level details. Then, using a 3DMM specifically designed to support local
and expression-related deformations of the face, we propose a two-steps 3DMM fitting solution: initially the
model is deformed under the effect of landmarks correspondences; subsequently, it is iteratively refined using
points closeness updating guided by a mean-square optimization. Preliminary results show that the proposed
solution is able to derive 3D models of the face with high visual quality; quantitative results also evidence the
superiority of our approach with respect to methods that use one step fitting based on landmarks.
1 INTRODUCTION
Recent advances in 3D scanning technologies make it
possible to acquire registered RGB and depth frames
at affordable cost. The availability of depth and RGB
data greatly simplifies the design of video analysis
modules for object detection and segmentation. In
fact, discontinuities in the depth domain highlight
the presence of object boundaries that can be diffi-
cult to detect in the RGB domain especially in the
case of background clutter and/or uneven illuminat-
ing conditions. However, a common trait of these
low-cost RGB-D cameras—including the Microsoft
Kinect, the Asus Xtion and the Intel RealSense depth
cameras—is that depth data of individual frames are
badly affected by noise that prevents the accurate
reconstruction of the 3D geometry of the observed
scene. This is particularly true if the task of recon-
structing the 3D geometry of non-planar object sur-
faces is targeted, such as the case of reconstructing
the 3D geometry of faces. In the last few years, sev-
eral 3D face reconstruction approaches have been pro-
posed, also in truly uncooperative, in the wild, condi-
tions (Booth et al., 2018). However, a common trait
of these approaches is that reconstruction of the 3D
face model from data observed in a generic image
or video frame is finalized to reproduce realistic ren-
derings of the observed face in a different pose (e.g.,
frontal pose) for the purpose of boosting the accu-
racy of person or facial expression recognition. In
these solutions, smoothness of the reconstructed 3D
face model is privileged with respect to fitting to the
actual 3D geometry of the face. Indeed, this yields
pleasant and realistic face renderings, but may prove
inadequate to provide a precise reconstruction of the
3D geometry of the face and its deformations in the
presence of voluntary and involuntary expressions.
Motivated by these premises, in this paper we
propose a novel face modeling approach that start-
ing from an RGB-D low-resolution sequence of the
face is capable of reconstructing an accurate 3D face
model over time also in the presence of facial expres-
sions and generic facial deformations. This opens the
way to application scenarios that aim to analyse the
face deformations at a fine scale so as to understand
the 3D local face variations with respect to a neutral
model. For example, this can have applications in face
rehabilitation, where a subject at home (e.g., a patient
recovering after a stroke or a face surgery) can be in-
structed to perform some facial deformations in front
728
Ferrari, C., Berretti, S., Pala, P. and Bimbo, A.
3D Face Reconstruction from RGB-D Data by Morphable Model to Point Cloud Dense Fitting.
DOI: 10.5220/0007521007280735
In Proceedings of the 8th Inter national Conference on Pattern Recognition Applications and Methods (ICPRAM 2019), pages 728-735
ISBN: 978-989-758-351-3
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

of a PC. In such scenario, 3D high-resolution scan-
ners cannot be employed due to their size and cost,
and RGB data alone cannot provide the required level
of accuracy. In our proposed solution, we start by
the idea of using a 3DMM that also includes modes
of deformation associated to facial expression varia-
tions and is specifically designed to account for lo-
cal changes of the face. This is possible thanks to a
dictionary learning framework that gives the atoms of
the dictionary the capability of producing local de-
formations of the average model of the face. The
model is then fit to a point cloud as captured by a low-
resolution scanner (e.g., Kinect) through a coarse-to-
fine solution: the initial fitting is driven by the cor-
respondence of a set of landmarks; the coarsely de-
formed model is then refined by an iterative closest
points reassignment that minimizes the mean square
error between corresponding points in an ICP like
manner. Preliminary results have been obtained by
measuring the reconstruction error between the 3D
models derived by fitting the 3DMM to the target
scans of two large face datasets and the target scans
themselves used as ground truth. Results are univocal
in indicating superior accuracy for the proposed so-
lution with respect to using a one step 3DMM fitting
based on landmarks.
The rest of the paper is organized as follows:
In Section 2, we summarize the previous works on
3DMM construction and fitting that are more close to
our proposal; In Section 3, we first report on the pro-
posed method for 3DMM construction; Then, the way
the 3DMM is fit to depth scans is detailed; The de-
noising operation applied to low-resolution sequences
of face scans before 3DMM fitting is introduced in
Section 4; Experimental results are reported in Sec-
tion 5; Section 6 concludes the paper by reporting dis-
cussion and directions for future work.
2 RELATED WORK
In general, methods capable of reconstructing a 3D
model of the face from low-resolution depth data can
be categorized as either driven by the data or based
on fitting a 3D (morphable) model.
Methods in the first category build a 3D face
model by integrating tracked live depth images into
a common final 3D model. For example, a method
to produce laser scan quality 3D face models from
a freely moving user with a low-cost, low-resolution
depth camera was proposed in (Hernandez et al.,
2012). The model is initialized with the first depth
image, and then each subsequent cloud of 3D points
is registered to the reference using a GPU implemen-
tation of the ICP algorithm. This registration is robust
in that it rejects poor alignment due to facial expres-
sions, occlusions, or a poor estimation of the transfor-
mation. Temporal and spatial smoothing of the suc-
cessively incremented model is performed thanks to
the introduction of the Bump Images framework to
parameterize the 3D facial surface in cylindrical co-
ordinates. One evident limitation of this approach
is that it is not capable of reconstructing expressive
models of the face. In (Newcombe et al., 2011), the
Kinect Fusion approach was proposed to fuse all of
the depth data streamed from a Kinect sensor into a
single global implicit surface model of the observed
scene in real-time. To this end, the current pose of
the sensor is obtained by tracking the live depth frame
relative to the global model using a coarse-to-fine ICP
algorithm, which uses all of the observed depth data
available. The Kinect Fusion method was developed
for a fixed scene; in (Izadi et al., 2011) the method
was extended by considering dynamic actions of the
foreground. Though the Kinect Fusion approach is
general, its application to 3D face reconstruction re-
sults into models that reduce the noise with respect
to individual frames, but still show a quite visible
gap with respect to high-quality scans. In (Anasosalu
et al., 2013), a method is presented for producing an
accurate and compact 3D face model in real-time us-
ing an RGB-D sensor like the Kinect camera. To this
end, after initialization, Bump Images are updated in
real time by using every RGB-D frame with respect to
the current viewing direction and head pose; these lat-
ter are estimated using a frame-to-global-model reg-
istration strategy. Though this method takes a live
sequence of RGB-D images streamed from a fixed
consumer RGB-D sensor with unknown head pose,
it is assumed the relative movement of the head be-
tween two successive frames to be small, and that the
facial expression does not change during reconstruc-
tion. The work in (Zollh
¨
ofer et al., 2014) presents a
combined hardware/software solution for marker-less
reconstruction of non-rigidly deforming objects with
arbitrary shape. First, a smooth template model of
the subject as he/she moves rigidly is scanned. This
geometric surface prior is used to avoid strong scene
assumptions, such as a kinematic human skeleton or a
parametric shape model. Next, a GPU pipeline per-
forms non-rigid registration of live RGB-D data to
the smooth template using an extended non-linear as-
rigid-as-possible framework. High-frequency details
are fused onto the final mesh using a linear deforma-
tion model. However, this solution relies on a spe-
cific stereo matching algorithm to estimate real-time
RGB-D data. Other solutions were specifically de-
signed for faces with no expressions in constrained
3D Face Reconstruction from RGB-D Data by Morphable Model to Point Cloud Dense Fitting
729

scenarios (Berretti et al., 2014; Bondi et al., 2016).
Methods in the second category, i.e., methods that
use a 3DMM to reconstruct a face model from depth
data, are few. In fact, in the most practiced solutions
a 3DMM is fit to a 2D RGB target image (Blanz and
Vetter, 2003; Ferrari et al., 2017), with applications
that span from face rendering and relighting, to face
and facial expression recognition. In this work, in-
stead, we are interested to the particular case where
the target is a 3D low-resolution face scan as can be
acquired by a Kinect-like camera. The method de-
scribed in (Zollh
¨
ofer et al., 2011) employed a 3DMM
that is fit to the depth images obtained from an RGB-
D camera. The template mesh and the incoming
frame are aligned using features detected in the RGB
image as a coarse alignment step. The template is
then aligned non-rigidly to the incoming frame, and
the 3DMM is fit to the template. Unfortunately, this
approach produces results that are biased towards the
template. The work of (Kazemi et al., 2014) con-
tributes a real time method for recovering facial shape
and expression from a single depth image. The output
is the result of minimizing the error in reconstructing
the depth image, achieved by applying a set of iden-
tity and expression blend shapes to the model. A dis-
criminatively trained prediction pipeline is used that
employs random forests to generate an initial dense,
but noisy correspondence field. Then, a fast ICP-
like approximation is exploited to update these cor-
respondences, allowing a quick and robust initial fit
of the model. The model parameters are then fine
tuned to minimize the true reconstruction error using
a stochastic optimization technique.
However, none of these solutions can reconstruct
fine details of expressive faces using a 3DMM.
3 3D MORPHABLE FACE MODEL
The work in (Blanz and Vetter, 1999) first presented
a complete solution to derive a 3DMM by transform-
ing the shape and texture from a training set of 3D
face scans into a vector space representation based on
PCA. The 3DMM was further refined into the Basel
Face Model in (Paysan et al., 2009) with several other
subsequent evolutions (Patel and Smith, 2009; Booth
et al., 2016). Expressive scans were not part of the
training in all the solutions above. Indeed, two as-
pects have a major relevance in characterizing the dif-
ferent methods for 3DMM construction: (1) the hu-
man face variability captured by the model, which di-
rectly depends on the number and heterogeneity of
training scans; (2) the capability of the model to ac-
count for facial expressions; also this feature directly
derives from the presence of expressive scans in the
training. One of the few 3DMM in the literature that
exposes both these features is the Dictionary Learn-
ing based 3DMM (DL-3DMM) proposed in (Ferrari
et al., 2017). Since we mainly develop on this model,
below we first describe the peculiar features that make
the DL-3DMM suitable for our purposes, then we fo-
cus on the proposed fitting procedure.
DL-3DMM Construction. The first problem to be
solved in the construction of a 3DMM is the selection
of an appropriate set of training data. This should in-
clude sufficient variability in terms of ethnicity, gen-
der, age of the subjects so as to include a large vari-
ance in the data. Apart for this, the most difficult as-
pect in preparing the training data is the need to pro-
vide dense, i.e., vertex-by-vertex, alignment between
the 3D scans. Differently from works in the literature
that either use optical-flow (Blanz and Vetter, 1999)
or the non-rigid ICP algorithm (Paysan et al., 2009),
the dense alignment of the training data for the DL-
3DMM was obtained with a solution based on face
landmarks detection. These landmarks are then used
for partitioning the face into a set of non-overlapping
regions, each one identifying the same part of the
face across all the scans. Re-sampling the internal of
the region based on its contour, a dense correspon-
dence is derived region-by-region and so for all the
face. Such method showed to be robust also to large
expression variations as those occurring in the Bing-
hamton University 3D facial Expression (BU-3DFE)
database (Yin et al., 2006). This dataset was used in
the construction of the DL-3DMM.
Once a dense correspondence is established across
the training data, these are used to estimate a set of
M deformation components C
i
, usually derived by
PCA, that will be linearly combined to generate novel
shapes S starting from an average model m:
S = m +
|M|
∑
i=1
C
i
α
i
. (1)
In the DL-3DMM, a dictionary of deformation com-
ponents is learned by exploiting the Online Dictio-
nary Learning for Sparse Coding technique (Mairal
et al., 2009). Learning is performed in an unsuper-
vised way, without exploiting any knowledge about
the data (e.g., identity or expression labels). The av-
erage model is deformed using the dictionary atoms
D
i
in place of C
i
in Eq. (1). More details on the dic-
tionary learning procedure can be found in (Ferrari
et al., 2017). The average model m, the dictionary D
and w, constitute the DL-3DMM.
ICPRAM 2019 - 8th International Conference on Pattern Recognition Applications and Methods
730

3DMM Fitting. The 3DMM was originally de-
signed with the goal of reconstructing the 3D shape
of a face from single images (Blanz and Vetter, 2003);
the large number of different techniques to fit the
3DMM to a face image developed later on can be di-
vided in two main categories: analysis-by-synthesis,
and geometric based. Methods in the former cat-
egory perform a complex iterative procedure aimed
at generating a synthetic image as similar as possi-
ble to the input one, optimizing with respect to the
3DMM (shape and texture) and rendering (e.g., cam-
era or illumination) parameters. Despite their com-
plexity, the resulting reconstructions are rather ac-
curate. Nonetheless, given a textured rendering, it
is hard to discern if the retrieved shape resembles
the real geometry of the face; this because the same
rendering might be the result of different combina-
tions of the many involved parameters. Alternatively,
methods in the geometric-based category try to de-
form the 3DMM so as to match some geometrical fea-
tures detected on the image, like facial landmarks or
edges (Bas et al., 2016). These approaches exploit
the fact that human faces are composed of muscles—
hence facial movements involve an extended surface
rather than a single point—that are constrained to
fixed anthropometric proportions and limited variabil-
ity. Thus, when trying to deform the 3DMM to fit
a set of sparse landmarks, the surrounding surfaces
will smoothly follow the deformation in a statistically
plausible way. This motivates the coarse reconstruc-
tion of the shape of the whole face based only on few
control points. Obviously, the resulting reconstruc-
tion will be a coarse, but smooth approximation of
the real surface.
The proposed method attempts to fill this gap; it
builds upon the geometric approaches and extends
the fitting based on facial landmarks to a whole point
cloud. This extension implies a 3D scan correspond-
ing to the face image to be available, which changes
the context and the objective. In this configuration,
the goal becomes deforming a generic face shape to
match a target one, both represented as point clouds;
indeed, the problem can be seen as the non-rigid reg-
istration of point clouds, which is a well-known prob-
lem in computer vision for which many solutions have
been proposed throughout the years (Chui and Ran-
garajan, 2000; Amberg et al., 2007; Myronenko and
Song, 2010). All the approaches addressing the prob-
lem, however, are intended to work with generic point
clouds representing arbitrary objects, while in this
case the problem is bounded to human faces. The
main difficulty is that faces are highly deformable
objects, which often makes such approaches fail in
matching the two shapes. On the opposite, we can ex-
ploit this prior knowledge to leverage a statistical tool
such as the 3DMM to bound the deformation.
The proposed approach, first performs a similarity
transformation to map the target shape into the aver-
age model space, accounting for 3D rotation, transla-
tion and scale (SimilarityTransform in Algorithm 1).
This is achieved by means of a set of 49 landmarks
L
t
∈ R
49×3
, which are detected on the face image and
back-projected to the mesh. Depending on the data,
the association method to be applied might change.
To initialize the approach and account for large
shape differences that might impair the subsequent
steps, we apply the DL-3DMM fitting using the land-
marks similarly to (Ferrari et al., 2015). The av-
erage model m ∈ R
p×3
is deformed on the target
shape
e
t ∈ R
k×3
minimizing the Euclidean distance of
the landmarks, whose indices on m are indicated as
I
l
∈ N
49
(LandmarkFitting in Algorithm 1). Differ-
ently from (Ferrari et al., 2015), the fitting is per-
formed directly in the 3D space and projection on the
image plane is avoided. The deformation coefficients
α are retrieved using the dictionary atoms d
i
as:
min
α
L
t
− m(I
l
) −
|D|
∑
i=1
d
i
(I
l
)α
i
2
2
+ λ
α ◦
ˆ
w
−1
2
. (2)
In the equation, d
i
(I
l
) indicates that, for each dictio-
nary atom, only the elements associated to the vertices
corresponding to the landmarks are involved in the
minimization. The solution is found in closed form
and the average model m is deformed using Eq. (1) to
obtain an initial estimate
ˆ
m.
Then, we perform a rigid ICP registration between
ˆ
m and
e
t to refine the alignment, and compute the per-
vertex distance between the two meshes. We sub-
sequently associate each vertex of
ˆ
m to its nearest
neighbor in
e
t, obtaining a re-parametrization (Vertex-
Association in Algorithm 1) of p indices of
e
t. Note
that k 6= p in general, thus a vertex of
ˆ
m might be
associated with multiple vertices of
e
t; even if p = k,
this can still happen because of points that share the
same nearest neighbor. Once the association is done,
the DL-3DMM is fit minimizing the Euclidean dis-
tance between each pair of associated points, using
a least squares solution. The fitting method reported
in (Ferrari et al., 2015) uses a regularized formulation
(Eq. (2)), which is necessary to avoid uncontrolled de-
formations. In our case, we use all the vertices to fit
the target shape; thus the usefulness of the regulariza-
tion becomes marginal. The minimization of Eq. (2)
becomes:
min
α
e
t −
ˆ
m −
|D|
∑
i=1
d
i
α
i
2
2
. (3)
The procedure is repeated until the error between sub-
sequent iterations is lower than a threshold τ or the
3D Face Reconstruction from RGB-D Data by Morphable Model to Point Cloud Dense Fitting
731
Algorithm 1: Point Cloud Fitting (PCF).
Input: Average Model m, Dictionary D, Weights w,
Target Shape t, Landmarks L
t
, m(I
l
), Error
Threshold τ, Iterations Limit MaxIter
Output: Deformed Model
ˆ
m
e
t = SimilarityTransform(L
t
, t, m(I
l
));
ˆ
m = LandmarkFitting(L
t
, m(I
l
), D, w);
i = 0;
while i < MaxIter k err > τ do
ICP(
e
t,
ˆ
m);
e
t = VertexAssociation(
e
t,
ˆ
m);
ˆ
m = ShapeFitting(
e
t,
ˆ
m, D, w);
err = ComputeEuclideanError(
e
t,
ˆ
m);
i = i + 1
maximum number of iterations if reached. Algo-
rithm 1 reports the pseudo-code of the proposed Point
Cloud Fitting procedure (PCF).
4 DEPTH DATA DENOISING
Low cost RGB-D scanners, such as the Kinect, can
acquire multimodal video streams consisting of reg-
istered RGB and depth data at approximately 30fps.
However, since the depth data are badly affected by
noise, a pre-processing is needed for noise reduction
and reconstruction of a regularized surface that ap-
proximates the 3D geometry of the observed object
(i.e., a face in our domain of interest). Depth data are
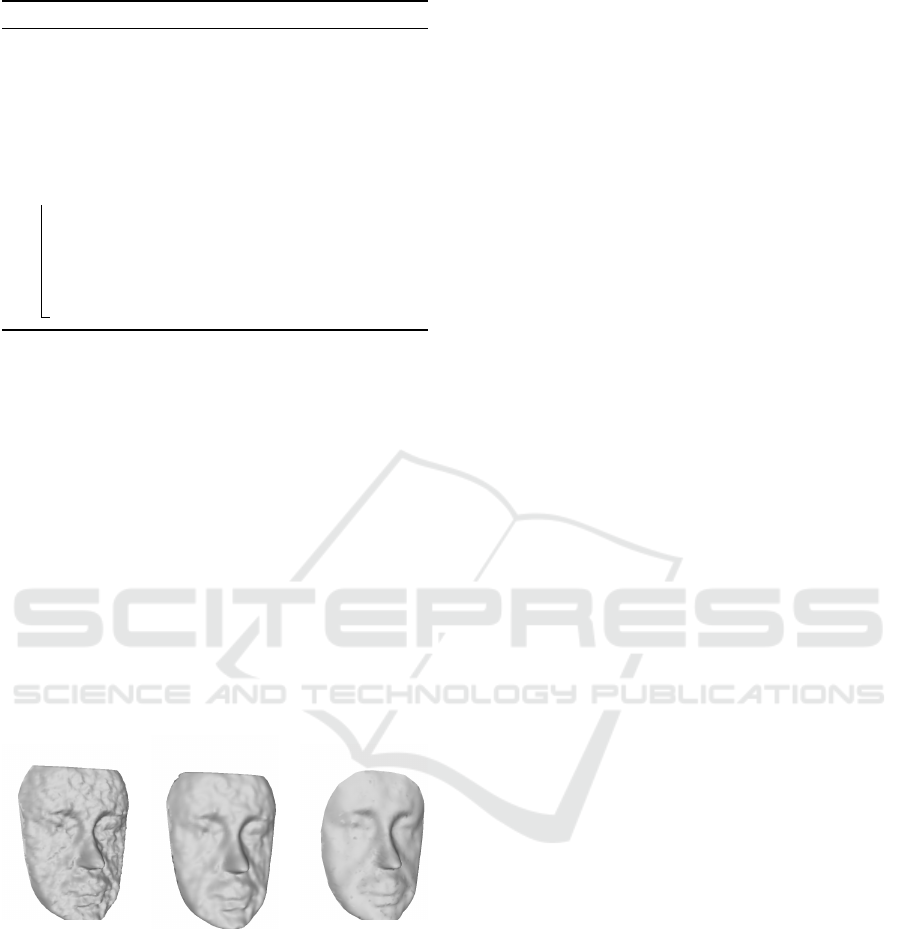
(a) (b) (c)
Figure 1: Effect of local regression filtering for depth noise
removal: (a) raw depth scan affected by noise as provided
by the Kinect; (b) depth data after smoothing through a
Laplacian operator; (c) depth scan after local regression fil-
tering ( points closer than 9cm to the nose tip are retained).
regarded as z values of a function on the (x, y) plane,
perpendicular to the line of sight of the scanner. Then,
regularization is performed through the local regres-
sion scheme described in (Cleveland, 1979): estima-
tion of the true depth value at point p
i
= (x
i
, y
i
, z
i
)
is accomplished by fitting a low-dimensional polyno-
mial to the nearest neighbors N (p
i
) of p
i
. Opera-
tively, the cardinality of N (p
i
) is controlled through
a smoothing parameter γ ∈ (0, 1). Large values of
γ produce smooth regression functions that wiggle
the least in response to fluctuations in the data. The
smaller γ is, the closer the regression function will
conform to the data, thus yielding poor robustness
to noise. The noise free estimate of point p
i
is ob-
tained by computing a least squares bilinear fit on
pairs (x
j
, y
j
) 7→ (x
j
, y
j
, z
j
), ∀(x
j
, y
j
, z
j
) ∈ N (p
i
). Fig-
ure 1 shows the effect of the application of the local
regression module for noise reduction.
5 EXPERIMENTAL RESULTS
In the following, we report on the evaluation of the
proposed approach for accurate 3D face reconstruc-
tion using the DL-3DMM and the PCF procedure.
The experiments are conceived to demonstrate that
multimodal RGB and depth data, even if affected by
noise and provided by low resolution scanners, can be
processed through the PCF procedure to reconstruct
the 3D face shape. Furthermore, fitting the morphable
model through PCF yields more accurate 3D recon-
struction compared to fitting the model to the land-
marks.
In order to quantitatively evaluate the reconstruc-
tion accuracy of the proposed approach, we iden-
tified two publicly available datasets of 3D facial
scans, namely, the Binghamton University 3D Facial
Expression database (BU-3DFE) (Yin et al., 2006)
and the Face Recognition Grand Challenge database
(FRGC) (Phillips et al., 2005).
The BU-3DFE dataset has been largely employed
for 3D expression/face recognition; it contains scans
of 44 females and 56 males, with age ranging from 18
to 70 years old, acquired in a neutral plus six different
expressions: anger, disgust, fear, happiness, sadness,
and surprise (2500 scans in total). The subjects are
distributed across different ethnic groups or racial an-
cestries. This dataset has been used to train the DL-
3DMM and a fully registered version of 1779 out of
the 2500 scans is available.
The FRGC dataset is composed of 466 individu-
als, for a total of 4007 scans collected in two sepa-
rate sessions. Approximately, the 60% of such are
in neutral expression, while the others show sponta-
neous expressions. For the experiments, we used the
“fall2003” session, comprising 1729 scans. In the fol-
lowing, we first present and discuss results on BU-
3DFE and FRGC, then for some Kinect scans. For
all the reported experiments, the regularization term
λ of Eq. 2 has been fixed to 0.01; the error threshold τ
and the maximum number of iterations in Algorithm 1
ICPRAM 2019 - 8th International Conference on Pattern Recognition Applications and Methods
732
200 400 600 800 1000 1200 1400 1600
3D Model
0
5
10
15
20
25
30
Error (mm)
BU-3DFE
Full procedure
Landmarks only
500 1000 1500
3D Model
0
5
10
15
20
25
30
35
40
45
Error (mm)
FRGC
Full procedure
Landmarks only
Figure 2: Comparison between landmark fitting (FL) with
blue color, and full point cloud fitting (FL+PCF) with red
color. BU-3DFE (left) and FRGC (right).
have been fixed to 0.001 and 50 respectively.
Reconstruction Accuracy by Nearest Neighbor As-
sociation. In this experiment, we evaluate the ac-
curacy of the vertices association by computing, for
each vertex of the deformable model, its distance to
the closest vertex of the 3D point cloud. It should
be noticed that such nearest neighbor point associa-
tion might not fully reflect the correctness of the re-
construction. Consider the case in which the 3DMM
fails to fit an open mouth; the distance between the
two models should be ideally large, while it is likely
that the error resulting from a nearest neighbor search
will be small (or at least, smaller). To highlight the
potential of the proposed solution, values of the mean
accuracy are computed with reference to two distinct
cases: i) DL-3DMM fitting based on facial landmarks
(FL), and ii) DL-3DMM fitting based on facial land-
marks and PCF (FL+PCF). The mean error and stan-
dard deviation across all the models for the BU-3DFE
and FRGC datasets are reported in Table 1.
Table 1: Reconstruction error (in mm) for the landmark
fitting (FL) and full point cloud fitting (FL+PCF).
Dataset FL FL+PCF
BU-3DFE 4.507 ± 2.809 0.802 ± 0.235
FRGC 8.272 ± 4.939 0.455 ± 0.282
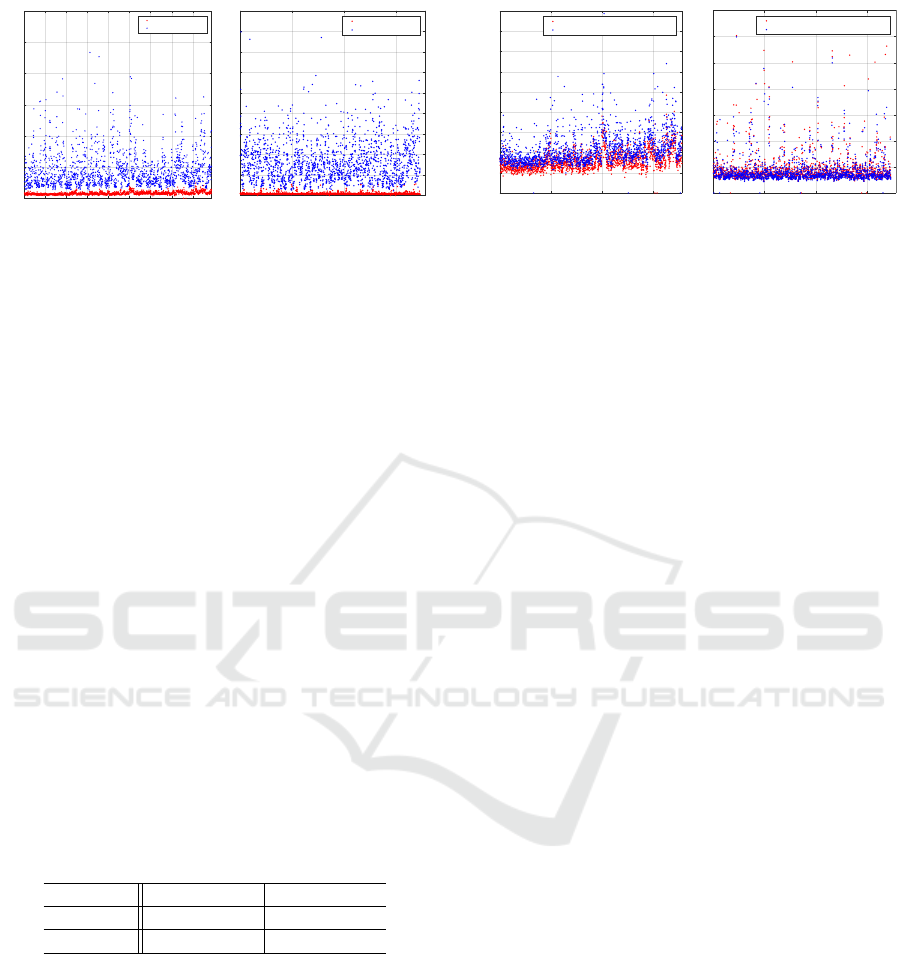
In Fig. 2 accuracy values are reported at a higher
level of detail, showing for each model of the dataset
(both BU-3DFE and FRGC are considered) the error
obtained by using FL (in blue color), and the error
obtained by using FL+PCF (in red color). Results
demonstrate a noticeable improvement is obtained
with the proposed procedure. To provide a quali-
tative yet representative description of the accuracy
of 3D face reconstruction, Fig. 4 reports some heat-
maps obtained by encoding with a chromatic value
the error associated with each vertex of the recon-
structed model; it can be appreciated how the real
500 1000 1500
3D Model
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
Error (mm)
BU-3DFE
With Landmarks Initialization
Without Landmarks Initialization
500 1000 1500
3D Model
0
0.5
1
1.5
2
2.5
3
3.5
Error (mm)
FRGC
With Landmarks Initialization
Without Landmarks Initialization
Figure 3: Comparison either using the landmark initializa-
tion or not. BU-3DFE (left) and FRGC (right).
surface is accurately reconstructed and fine details of
regions where landmarks are missing are accurately
replicated, while maintaining a smoother surface. The
higher accuracy of the proposed solution is demon-
strated by the presence of large regions with blue/cyan
colors (low error values) for models reconstructed
using FL+PCF compared to regions with red/yellow
colors (high error values) for models reconstructed
using FL.
Landmarks Initialization. Detecting facial land-
marks on face images (or 3D data) is itself a challeng-
ing task, which is not exempt from failures. In order
to assess the robustness of our approach to the initial-
ization procedure, we compared the final accuracy in
case the method is whether initialized or not. From
Fig. 3, we can observe that the approach is rather
robust and still can accurately reconstruct the shape
without landmarks initialization. For some models,
the error increases significantly; this is the case of
models with large topological differences, e.g., open
mouth, which are more difficult to handle if a seman-
tic association is not available. Note that this happens
mostly in the BU-3DFE, while for the FRGC dataset,
such behavior happens in both the cases. This is mo-
tivated by the fact that, as above mentioned, the land-
mark detection can fail; if this happens, the initialized
shape
ˆ
m might be farther from the ground truth with
respect to the average model m.
Kinect Data Reconstruction. Our approach has
been experimented also on Kinect data, processed as
expounded in Sect. 4. Because of the lack of datasets
containing RGB-depth pairs, we collected a few se-
quences where to qualitatively test our method on,
while quantitative and statistically meaningful results
were presented in the previous sections. The average
error obtained in such sequences is 35, 89 and 1, 70
mm, respectively, for the FL and FL+PCF, demon-
strating the effectiveness of the approach even for
low-resolution data. From Fig. 4, we can appreci-
3D Face Reconstruction from RGB-D Data by Morphable Model to Point Cloud Dense Fitting
733

Figure 4: Qualitative comparison between DL-3DMM fitting based on facial landmarks (FL) and DL-3DMM fitting based on
facial landmarks and PCF (FL+PCF). Three leftmost columns: reconstructions and ground truth (GT) models; two rightmost
columns: error heat-maps. From top to bottom, BU-3DFE, FRGC, Kinect models (last two rows).
ate that the sole landmarks were not sufficient to re-
produce the real shape, e.g., the nose, but it could
only coarsely capture the expression. A critical as-
pect of dealing with low-resolution data is the near-
est neighbor association; each collected Kinect scan k
has about 3K vertices, while the 3DMM has 6704, al-
most the double. If the association is performed with
respect to the average model m, then each vertex of
k will be associated, on average, to 2 vertices of m.
The other way around, if we perform the association
with respect to k, not all the vertices of m will have a
mated point. In the former case, the resulting recon-
struction will be more accurate, but some noise due
to the redundancy in the points association will be in-
troduced (Fig. 4, bottom row); in the latter, the recon-
struction would be smoother, but less accurate (Fig. 4,
third row). Moreover, since we do not have control
on the whole point cloud, the fitting needs to be per-
formed using the regularization term, i.e., Eq. (2), to
avoid excessive noise. A feasible way to solve this is-
sue is that of modifying the 3DMM formulation so as
to make the deformation components D sparse.
6 CONCLUSIONS
In this paper, we have proposed a 3DMM based so-
lution to reconstruct a highly-detailed 3D model of
the face starting from an RGB-D low-resolution face
sequence. This is obtained by the combined effect
of two specific algorithmic solutions for 3DMM con-
struction and fitting: on the one hand, we used a dic-
tionary learning based 3DMM implementation that
makes possible modeling local deformations of the
face; on the other, the model is fit to a target point
cloud by a two steps approach, where the 3DMM
is first deformed under the effect of the correspon-
dence between a limited set of landmarks, and sub-
sequently refined by an iterative local adjustment of
point correspondences. Further, a robust denoising
ICPRAM 2019 - 8th International Conference on Pattern Recognition Applications and Methods
734

solution is applied to the RGB-D sequences in order
to preprocess sets of consecutive frames before apply-
ing the 3DMM fitting. Preliminary results have been
reported that show the reconstruction errors between
the 3D models derived after 3DMM fitting and the
corresponding ground truth scans. It clearly emerges
as the proposed framework provides superior results
with respect to a landmark-based solution.
As further step in the direction of proposing our
system for face rehabilitation purposes, we are col-
lecting a face dataset that includes RGB-D sequences
of the face captured by a Kinect camera, and the
corresponding high-resolution scans acquired with a
3dMD scanner.
REFERENCES
Amberg, B., Romdhani, S., and Vetter, T. (2007). Optimal
step nonrigid ICP algorithms for surface registration.
In IEEE Conf. on Computer Vision and Pattern Recog-
nition (CVPR), pages 1–8.
Anasosalu, P. K., Thomas, D., and Sugimoto, A. (2013).
Compact and accurate 3-D face modeling using an
rgb-d camera: Let’s open the door to 3-D video con-
ference. In IEEE Int. Conf. on Computer Vision Work-
shops, pages 67–74.
Bas, A., Smith, W. A., Bolkart, T., and Wuhrer, S. (2016).
Fitting a 3D morphable model to edges: A comparison
between hard and soft correspondences. In Asian Con-
ference on Computer Vision, pages 377–391. Springer.
Berretti, S., Pala, P., and Del Bimbo, A. (2014). Face recog-
nition by super-resolved 3D models from consumer
depth cameras. IEEE Trans. on Information Forensics
and Security, 9(9):1436–1449.
Blanz, V. and Vetter, T. (1999). A morphable model for the
synthesis of 3D faces. In ACM Conf. on Computer
Graphics and Interactive Techniques, pages 187–194.
Blanz, V. and Vetter, T. (2003). Face recognition based on
fitting a 3D morphable model. IEEE Trans. on Pattern
Analysis and Machine Intelligence, 25(9):1063–1074.
Bondi, E., Pala, P., Berretti, S., and Del Bimbo, A.
(2016). Reconstructing high-resolution face models
from kinect depth sequences. IEEE Trans. on Infor-
mation Forensics and Security, 11(12):2843–2853.
Booth, J., Roussos, A., Ververas, E., Antonakos, E.,
Ploumpis, S., Panagakis, Y., and Zafeiriou, S. (2018).
3D reconstruction of ’in-the-wild’ faces in images and
videos. IEEE Trans. on Pattern Analysis and Machine
Intelligence, 40(11):2638 – 2652.
Booth, J., Roussos, A., Zafeiriou, S., Ponniahand, A., and
Dunaway, D. (2016). A 3D morphable model learnt
from 10,000 faces. In IEEE Conf. on Computer Vision
and Pattern Recognition, pages 5543–5552.
Chui, H. and Rangarajan, A. (2000). A feature registration
framework using mixture models. In IEEE Workshop
on Mathematical Methods in Biomedical Image Anal-
ysis, pages 190–197.
Cleveland, W. S. (1979). Robust locally weighted regres-
sion and smoothing scatterplots. Journal of the Amer-
ican Statistical Association, 74(368):829–836.
Ferrari, C., Lisanti, G., Berretti, S., and Del Bimbo, A.
(2015). Dictionary learning based 3D morphable
model construction for face recognition with varying
expression and pose. In Int. Conf. on 3D Vision.
Ferrari, C., Lisanti, G., Berretti, S., and Del Bimbo,
A. (2017). A dictionary learning-based 3D mor-
phable shape model. IEEE Trans. on Multimedia,
19(12):2666–2679.
Hernandez, M., Choi, J., and Medioni, G. (2012). Laser
scan quality 3-D face modeling using a low-cost depth
camera. In European Signal Processing Conf. (EU-
SIPCO), pages 1995–1999. IEEE.
Izadi, S., Kim, D., Hilliges, O., Molyneaux, D., Newcombe,
R., Kohli, P., Shotton, J., Hodges, S., Freeman, D.,
Davison, A., and Fitzgibbon, A. (2011). Kinectfusion:
Real-time 3D reconstruction and interaction using a
moving depth camera. In ACM Symposium on User
Interface Software and Technology, pages 559–568.
Kazemi, V., Keskin, C., Taylor, J., Kohli, P., and Izadi, S.
(2014). Real-time face reconstruction from a single
depth image. In IEEE Int. Conf. on 3D Vision, vol-
ume 1, pages 369–376.
Mairal, J., Bach, F., Ponce, J., and Sapiro, G. (2009). Online
dictionary learning for sparse coding. In Int. Conf. on
Machine Learning, pages 689–696.
Myronenko, A. and Song, X. (2010). Point set registration:
Coherent point drift. IEEE Trans. on Pattern Analysis
and Machine Intelligence, 32(12):2262–2275.
Newcombe, R. A., Izadi, S., Hilliges, O., Molyneaux, D.,
Kim, D., Davison, A. J., Kohi, P., Shotton, J., Hodges,
S., and Fitzgibbon, A. (2011). Kinectfusion: Real-
time dense surface mapping and tracking. In IEEE
Int. Symposium on Mixed and Augmented Reality.
Patel, A. and Smith, W. A. P. (2009). 3D morphable face
models revisited. In IEEE Conf. on Computer Vision
and Pattern Recognition, pages 1327–1334.
Paysan, P., Knothe, R., Amberg, B., Romdhani, S., and
Vetter, T. (2009). A 3D face model for pose and il-
lumination invariant face recognition. In IEEE Int.
Conf. on Advanced Video and Signal Based Surveil-
lance (AVSS), pages 296–301.
Phillips, P. J., Flynn, P. J., Scruggs, T., Bowyer, K. W.,
Chang, J., Hoffman, K., Marques, J., Min, J., and
Worek, W. (2005). Overview of the face recognition
grand challenge. In IEEE Work. on Face Recognition
Grand Challenge Experiments, pages 947–954.
Yin, L., Wei, X., Sun, Y., Wang, J., and Rosato, M. J.
(2006). A 3D facial expression database for facial be-
havior research. In IEEE Int. Conf. on Automatic Face
and Gesture Recognition, pages 211–216.
Zollh
¨
ofer, M., Martinek, M., Greiner, G., Stamminger, M.,
and S
¨
ußmuth, J. (2011). Automatic reconstruction of
personalized avatars from 3D face scans. Computer
Animation and Virtual Worlds, 22(2-3):195–202.
Zollh
¨
ofer, M., Nießner, M., Izadi, S., Rehmann, C., Zach,
C., Fisher, M., Wu, C., Fitzgibbon, A., Loop, C.,
Theobalt, C., and Stamminger, M. (2014). Real-
time non-rigid reconstruction using an RGB-D cam-
era. ACM Trans. on Graphics, 33(4):156:1–156:12.
3D Face Reconstruction from RGB-D Data by Morphable Model to Point Cloud Dense Fitting
735
