
A Containerized Tool to Deploy Scientific Applications over SoC-based
Systems: The Case of Meteorological Forecasting with WRF
Luiz Angelo Steffenel
1
, Andrea Schwertner Char
˜
ao
2
and Bruno da Silva Alves
2
1
CReSTIC Laboratory, Universit
´
e de Reims Champagne-Ardenne, Reims, France
2
LSC Laboratory, Universidade Federal de Santa Maria, Santa Maria, Brazil
Keywords:
Application Containers, High Performance Computing, Systems-on-a-Chip.
Abstract:
Container-based virtualization represents a flexible and scalable solution for HPC environments, allowing a
simple and efficient management of scientific applications. Recently, Systems-on-a-Chip (SoC) have emerged
as an alternative to traditional HPC clusters, with a good computing power and low costs. In this paper, we
present how we developed a container-based solution for SoC clusters, and study the performance of WRF
(Weather Research and Forecasting) in such environments. The results demonstrate that although the peak
performance of SoC clusters is still limited, these environments are more than suitable to scientific application
that have relaxed QoS constraints.
1 INTRODUCTION
High Performance Computing (HPC) is a generic
term to applications that are computationally inten-
sive or data intensive in nature (Somasundaram and
Govindarajan, 2014). While most HPC platforms rely
on dedicated and expensive infrastructures such as
clusters and computational grids, other technologies
like cloud computing and systems-on-a-chip (SoC)
are becoming interesting alternatives for HPC.
Indeed, cloud computing has brought a non-
negligible flexibility and scalability for most users
(Marathe et al., 2014), and a smaller maintenance
cost. One drawback, however, is that the widespread
of cloud computing forced a paradigm shift as appli-
cations are no longer executed directly on bare-metal
but instead must be executed on top of a virtualization
layer. While the performance overhead of virtualiza-
tion is being rapidly reduced, it is still perceptible and
may compromise some applications (Younge et al.,
2011). Another inconvenience of cloud computing
is that not all applications are prone to a distant exe-
cution. Latency-sensitive applications or applications
executed in remote locations with limited Internet ac-
cess may be penalized by a remote execution, as well
as applications relying on sensitive data that cannot
be transmitted to a third-part facility.
Systems-on-a-chip (SoC), on the other hand, rep-
resent a rupture on the traditional HPC infrastructure
as SoC encapsulate CPU, GPU, RAM memory and
other components at the same chip (Wolf et al., 2008).
Most of the times, the SoC technology is used as a
way to reduce the cost of single-board computers, like
Raspberry Pi, ODroid or Banana Pi. These systems
are currently used for a large range of applications,
from Computer Science teaching (Ali et al., 2013)
to Internet of Things (Molano et al., 2015). Being
mostly based on ARM processors, SoCs also benefit
from the improvements to this family of processors.
Indeed, if the choice for ARM processors was initially
driven by energy and cost requirement, nowadays this
family of processors presents several improvements
that allow the construction of computing infrastruc-
tures with a good computing power and a cost way
inferior to traditional HPC platforms (Weloli et al.,
2017; Cox et al., 2014; Montella et al., 2014).
SoC also have an active role in Fog and Edge com-
puting (Steffenel and Kirsch-Pinheiro, 2015), bring-
ing computation closer to the user and therefore of-
fering proximity services that otherwise would be en-
tirely deployed on a distant infrastructure. Further-
more, a SoC cluster can substitute a traditional HPC
cluster in some situations, as SoC are relatively inex-
pensive and have low maintenance and environmental
requirements (cooling, etc.). Of course, this is only
valid as long as the SoC infrastructure provides suffi-
cient Quality of Service (QoS) to the final users.
In this context, the association of SoC and vir-
tualization represents also an interesting solution to
deploy scientific applications for educational pur-
Steffenel, L., Charão, A. and Alves, B.
A Containerized Tool to Deploy Scientific Applications over SoC-based Systems: The Case of Meteorological Forecasting with WRF.
DOI: 10.5220/0007799705610568
In Proceedings of the 9th International Conference on Cloud Computing and Services Science (CLOSER 2019), pages 561-568
ISBN: 978-989-758-365-0
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
561

poses (Alvarez et al., 2018). Indeed, if virtualization
(and especially container-based virtualization) con-
tributes to simplify the administrative tasks related to
the installation and maintenance of scientific applica-
tions, it also enables a rich experimental learning for
students, which can test different software and per-
form hands-on exercises without having to struggle
with compilers, operating systems, and DevOps tasks.
Furthermore, by focusing on SoC, we try to minimize
the material requirements to execute an application,
enabling the deployment of applications on personal
computers, classrooms, dedicated infrastructures or
even the cloud, seamlessly.
This work is structured as follows: Section 2 re-
views some elements of virtualization, while Section
3 presents how HPC applications can be challeng-
ing in a Docker environment, specially when they
are based on the Message Passing Interface (MPI)
standard. Section 4 introduces the WRF forecasting
model and the adaptions we made to develop WRF
Docker images for SoCs. Section 5 presents some
benchmarking results obtained and finally Section 6
presents the conclusions obtained from this study and
our plans for future works.
2 BACKGROUND
The development of OS-level virtualization is increas-
ingly popular. This virtualization approach relies
on OS facilities that partition the physical machine
resources, creating multiple isolated user-space in-
stances (containers) on top of a single host kernel.
Another advantage of such container-based virtual-
ization approach is that there is no execution over-
head, as OS-level virtualization does not need a hy-
pervisor (Felter et al., 2014).
One of the most popular container solutions is
Docker
1
. Docker allows the creation of personal-
ized images that can be used as a base to the deploy-
ment of many concurrent containers. While the ini-
tial releases of Docker made use of LXC as execution
driver, it eventually implemented its own execution
driver (Morabito et al., 2015). Docker also provides
a registry-based service named Docker Hub
2
that al-
lows users to share their images, simplifying the de-
ployment of virtual images. Also, Docker provides a
basic orchestrator service called Docker Swarm that
enables the deployment of a cluster of docker nodes.
While Docker Swarm is not as rich as other orchestra-
tors like Kubernetes (Burns et al., 2016), it is simple
1
https://www.docker.com/
2
https://hub.docker.com/
to use, and Swarm services can be easily adapted to
operate under Kubernetes.
If traditionally the HPC community was reluctant
to virtualization because of the performance penal-
ties it could incur, the dissemination of container vir-
tualization is changing this view. More and more
HPC centers favor the use of containers to simplify
the resources management and to guarantee compat-
ibility and reproducibility for the users’ applications
(Ruiz et al., 2015). For example, the NVidia DGX
servers
3
, dedicated to Deep Learning and Artificial
Intelligence applications, use Docker containers to
deploy the user’s applications.
Although Docker was initially developed for x86
platforms, its adaption to other processor architec-
tures like ARM started around 2014, with an ini-
tial adaption made by Hypriot
4
for Raspberry Pi ma-
chines. More recently, Docker started to officially
support ARM, and several base images on Docker
Hub are now published with both x86 and ARM ver-
sions.
3 HPC ON DOCKER:
LEVERAGING MPI
When considering large-scale HPC applications, they
mostly rely on MPI for data exchange and task co-
ordination across a cluster, grid or cloud. In spite of
recent advances in its specification, the deployment of
an MPI application can be quite rigid as it requires a
well-known execution environment. Indeed, the start-
ing point for an MPI cluster is the definition of a list of
participating nodes (often known as the hostfile),
which imposes a previous knowledge of the comput-
ing environment.
Deploying an MPI cluster over containers is a
challenging task as the overlay network on Docker is
designed to perform load balancing, not to address
specific nodes as in the case of MPI. Most works
that propose Docker images for MPI fail to develop
a self-content solution, requiring manual or external
manipulation of MPI elements to deploy applications.
Indeed, (d. Bayser and Cerqueira, 2017) automates
the deployment of the MPI application over a Docker
Swarm cluster but requires the user to provide the list
of available nodes (and cores) as a command-line pa-
rameter.
The external management of containers is fre-
3
https://www.nvidia.com/content/dam/en-zz/
Solutions/Data-Center/dgx-1/dgx-1-rhel-centos-datasheet-
update-r2.pdf
4
https://blog.hypriot.com/
CLOSER 2019 - 9th International Conference on Cloud Computing and Services Science
562
quently cited as a possible solution for accommodat-
ing MPI over containers. (Yong et al., 2018) briefly
describes two architectural arrangements that could
be used with Docker, all relying on external automa-
tion with scripts and SSH connections to the con-
tainers. This is indeed the case of (Higgins et al.,
2015), where the container orchestration is replaced
by a combination of a resource manager (PBS) and a
set of scripts that deploy individual container images
then set them together. A similar approach is used by
(Azab, 2017), who uses Slurm as orchestrator.
Another example of “external management” is the
case of Singularity (Kurtzer et al., 2017), a container
manager specifically designed for the HPC commu-
nity although compatible with Docker images. Sin-
gularity developed a specific solution for MPI deploy-
ments, where an external tool deploys and set up the
MPI hostfile, as well as copying the required appli-
cation and data to the containers. In (Chung et al.,
2016), MPI is not even part of the container but is
mounted from the host OS, making their solution to-
tally dependent on the execution platform.
Finally, (Nguyen and Bein, 2017), propose a
generic service for the deployment of MPI applica-
tions on Docker in one machine or in a cluster, with
Docker Swarm. Based on the Alpine Linux distribu-
tion, this platform automatizes most of the deploy-
ment of the Docker Swarm service, and the list of
working nodes for the hostfile is obtained through the
surveillance of active connections (using netstat).
The choice of using netstat proved to be too unsta-
ble, and we were unable to make it work properly on
a SoC.
As the existing solutions either require too much
manual intervention or are not reliable enough, we de-
cided to develop our own solutions to deploy an MPI
on a Docker Swarm cluster made of SoC. Therefore,
using the work from (Nguyen and Bein, 2017) as a
starting point, we tried to automate the deployment of
MPI as follows.
3.1 Hostfile
As explained before, most works proposing MPI over
Docker delegate the task of defining the hostfile to the
users. The only exception is the work from (Nguyen
and Bein, 2017), who present an automated process
that unfortunately does not work reliably enough.
The main reason for such difficulty is the fact
that Docker presents two different execution modes
that are quite dissimilar: in the “individual” mode,
a container instance is launched as a standalone ap-
plication, requiring no additional interconnections to
other instances (although this is possible). In the “ser-
vice” mode, different instances are bound together by
a routing mesh and a naming service whose main pur-
pose is to load balance messages to a given service
and to easily redirect messages in case of failures.
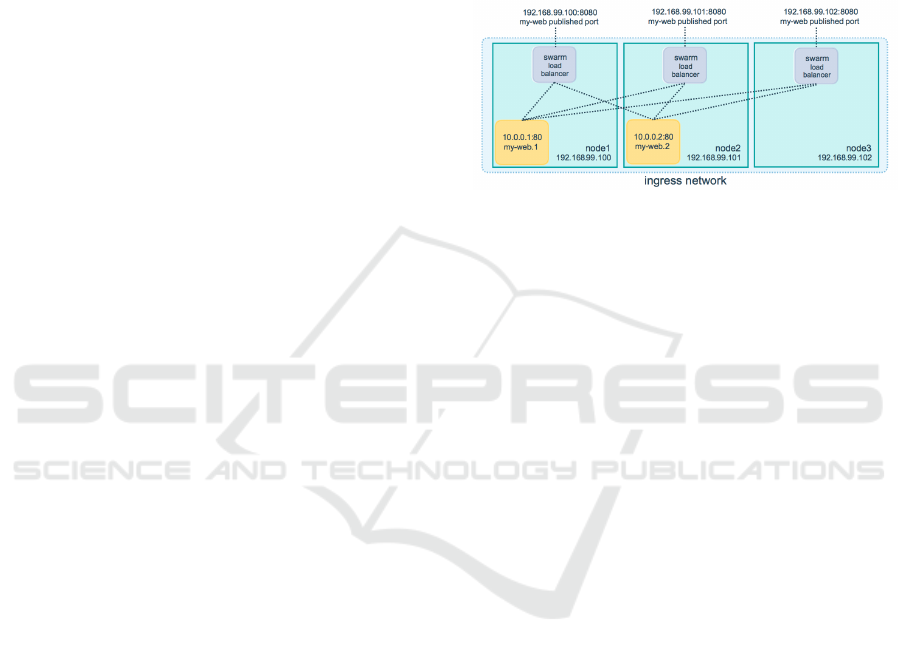
As illustrated by Figure 1, different instances can be
addresses by the same name (my-web, in the exam-
ple), simplifying the development of application that
do not need any more to keep a trace of the servers’
IP addresses.
Figure 1: Docker routing mesh.
Unfortunately, the MPI hostfile requires the list of
the servers. In both cases, there is no simple way to
address a list of nodes as in a regular cluster, where
machines are often named according to a defined pat-
tern (e.g. node-X ). Instead, we need a discovery
service to find out which IP addresses correspond to
the instances in our network. Contrarily to (Nguyen
and Bein, 2017), however, we decided to exploit the
own naming service of Docker by making “low level”
DNS calls using dig. By making specific queries for
the name of a service, we obtain a list of the corre-
sponding IP addresses of the instances. As the host-
file also indicates the number of process (or slots) a
node can run simultaneously, we call the nproc appli-
cation on each machine, obtaining therefore the num-
ber of available processing cores. This simple “hack”
is presented below, where we obtain the list of all
worker nodes (i.e., instances of the “worker” service
on Swarm).
iplists=‘dig +short tasks.workers A‘
for i in $iplists; do
np=‘ssh $i "nproc --all"‘
echo "$i:$np" >> hostfile
done
3.2 Roles and External Access
In addition to the list of nodes, MPI strongly relies
on the nodes’ rank. For instance, the most important
node in an MPI execution is the one tagged with rank
0, who usually starts the MPI community and gathers
the results at the end. As this “master” node has some
more responsibilities than a regular “worker” node, it
is important to allow users to access this node using
A Containerized Tool to Deploy Scientific Applications over SoC-based Systems: The Case of Meteorological Forecasting with WRF
563
SSH, for example. Indeed, several applications re-
quire an access to a frontend node where the user can
execute preprocessing steps, setup the application pa-
rameters or simply verify the code is running before
deploying it over the cluster. Therefore, we looked for
ways to launch the master together with the workers.
As we need to publish the master service’s port di-
rectly from the Swarm node, this node cannot simply
use the ingress routing network, but needs to be exe-
cuted under the special global deployment mode.
Additional attributes ensure that the master will
be easily located (on the manager node from the
Swarm cluster), simplifying the access (using SSH)
and also guaranteeing that at least this node mounts
correctly all external volumes required for the appli-
cation. Listing 1 presents the main elements of the
docker-compose.yaml file used to define and deploy
the Swarm service for our application.
Listing 1: Excerpt of the Swarm Service definition.
versi o n : "3 .3 "
ser vic es :
ma ste r :
im age : XXX XX
de plo y :
mo de :
gl oba l
pla cem e nt :
con s tra i nts :
- n od e . role == man age r
po rts :
- pu b lis h ed : 2 02 2
ta rge t : 22
mo de : host
vo l um e s :
- "./ W P S_G EOG :/ WP S _GE OG "
- "./ w r fin put :/ wr f inp ut "
- "./ w r fou t pu t :/ wrf o utp ut "
net wor ks :
- w rfn et
wo r ke r s :
im age : XXX XX
de plo y :
rep lic as : 2
pla cem e nt :
pre f ere n ces :
- s pre ad : n od e . l ab els . d ata c ent er
vo l um e s :
- "./ W P S_G EOG :/ WP S _GE OG "
- "./ w r fin put :/ wr f inp ut "
- "./ w r fou t pu t :/ wrf o utp ut "
net wor ks :
- w rfn et
net wor ks :
wr fne t :
dr ive r : ove rla y
att a ch a ble : t ru e
4 THE WRF MODEL
In order to experiment our virtualized cluster plat-
form, we adapted the Weather Research and Forecast-
ing (WRF) model (Skamarock et al., 2008), a well-
known numerical weather prediction model. WRF
has over 1.5 million lines in C and Fortran, as well as
many dependencies on external software packages for
input/output (I/O), parallel communications, and data
compression, that are not trivial to satisfy. Hence,
compilation and execution can be challenging for be-
ginners or for users that do not have administration
rights on their computing infrastructures.
Running the model can also be difficult for new
users. WRF is composed by several steps to gen-
erate computational grids, import initialization data,
produce initial and boundary conditions, and run the
model (Hacker et al., 2017).
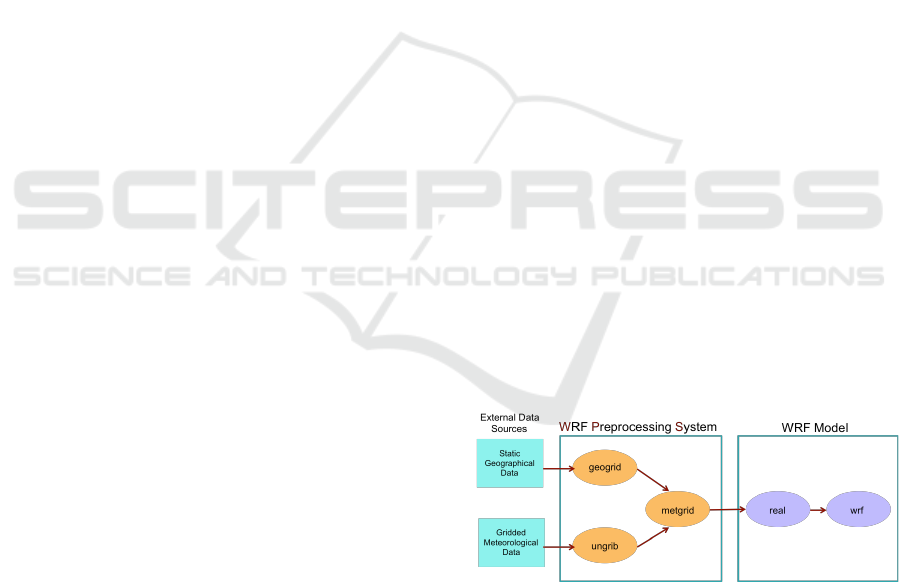
The typical workflow to execute the WRF model
(Figure 2) is made of 5 phases, as indicated below.
These steps do not include the additional access to ex-
ternal data sources, neither the analysis/visualization
of the results.
1. Geogrid - creates terrestrial data from static geo-
graphic data
2. Ungrib - unpacks GRIB meteorological data ob-
tained from an external source and packs it into
an intermediate file format
3. Metgrid - interpolates the meteorological data
horizontally onto the model domain
4. Real - vertically interpolates the data onto the
model coordinates, creates boundary and initial
condition files, and performs consistency checks
5. WRF - generates the model forecast
Figure 2: WRF workflow.
The three first steps are part of the WRF Prepro-
cessing System (WPS), that is configured and com-
piled separately from the WRF Model. The WPS
configuration allows two execution modes: serial or
dmpar (distributed memory parallelism through MPI).
In the case of the WRF Model configuration, four
modes are proposed: serial, smpar (shared mem-
ory parallelism), dmpar (distributed memory paral-
lelism) and sm+dmpar. The smpar option depends
CLOSER 2019 - 9th International Conference on Cloud Computing and Services Science
564

on OpenMP, while the dmpar lies on MPI. The last
option (sm+dmpar) combines OpenMP and MPI, but
several works point out that the pure dmpar usu-
ally outperforms the mixed option (Council, 2010;
Langkamp and B
¨
ohner, 2011).
Software containers, which are becoming an es-
sential part of modern software development and de-
ployment, offer a way for mitigating or eliminating
many of the problems cited above, and simplify the
deployment of computing infrastructures for both ed-
ucation and research. Containers allow the packaging
of a working (and validated) WRF instance, ready to
be used, preventing the user from having to install and
to set up all dependencies.
4.1 WRF Containers for ARM
Although a non-official container for WRF on x86
platforms
5
developed by NCAR researchers exists al-
ready, this image is not adapted for cluster deploy-
ment and has not evolved since its launching, despite
the intentions of the authors (Hacker et al., 2017).
When we started developing a version compatible
with the SoCs under the ARM platform, we had to ad-
dress a few issues related to the availability of some
libraries and compiling options. Indeed, the origi-
nal container image from NCAR is based on CentOS,
which does not support ARM processors yet. This
forced us to move to Ubuntu as our new base image.
Not only Ubuntu supports ARM but most libraries re-
quired by WRF are available as packages, simplifying
the installation (this reason also motivated us to avoid
alpine, a popular image for containers).
The other issue is related to the pre-configuration
of the parameters for WRF compiling. While WRF
supports several compilers (gcc, Intel, Portland, etc.)
and architectures, ARM processors are not listed
among the supported ones. Fortunately, a few re-
searchers have faced the same problem before
6
and
we were able to apply their instructions. While the
adaption requires the editing of the configuration files
in order to find a match to the ARM platform, the con-
figuration differences for both ARM or x86 are min-
imal, and most of the process is simple and straight-
forward.
In addition, we modified the way input data is
accessed, moving from a fixed Docker volume to a
mounted file system. We believe that this gives more
flexibility to develop workflows to execute the ap-
plication regularly, like for example in a daily fore-
cast schedule. This also helps to fix a storage prob-
lem that may touch many SoC boards. Indeed, the
5
https://github.com/NCAR/container-wrf
6
http://supersmith.com/site/ARM.html
first step on the WRF workflow (Geogrid) depends
on a large geographical database (WPS GEOG). Without
careful pruning, the full database reaches 60GB when
uncompressed, which is too voluminous for most SoC
boards. By allowing the use of external volumes, we
allow the users to attach external storage drives to
their nodes. As demonstrated later in Section 5.2,
only a single node requires this database, so we can
minimize the costs and the management complexity
in the SoC cluster.
Finally, we also updated the WRF version to
3.9.1.1, as the version present on the NCAR image
dates back to 2015. As WRF 4.0 has recently been
launched, we are planning to develop new images for
this version.
As a result, WRF containers for both ARM and
x86 architectures are now available at Docker Hub
7
and the scripts and Docker files are available at
GitHub
8
.
5 PERFORMANCE
BENCHMARKING
In order to assess the interest of using SoC based on
ARM for meteorological simulations with WRF, we
conducted a series of benchmarks to evaluate the per-
formance of the application. The next sessions de-
scribe the experiments and the platforms we com-
pared.
5.1 Definitions
For the benchmarks we used a dataset for a 12-hour
forecasting on October 18, 2016 and concerning an
area covering Uruguay and the south of Brazil. Al-
though small, this dataset is often used as training ex-
ample for meteorology students at Universidade Fed-
eral de Santa Maria, who can modify the parameters
and compare the results to the ground truth observa-
tions. The entire dataset is accessible at our github
repository.
In the benchmarks we compared different SoC
models and a x86 computers. The SoC boards
include a Raspberry Pi 2 model B (Broadcom
BCM2835 processor, ARM Cortex-A7, 4 cores,
900MHz, 1GB RAM) and two Raspberry Pi 3
(Broadcom BCM2837 processor, ARM Cortex-A53,
4 cores, 1.2GHz, 1GB RAM). The x86 computers
7
https://hub.docker.com/r/lsteffenel/wrf-container-
armv7l/
8
https://github.com/lsteffenel/wrf-container-armv7l-
RaspberryPi
A Containerized Tool to Deploy Scientific Applications over SoC-based Systems: The Case of Meteorological Forecasting with WRF
565
were represented by a server with an Intel Xeon
E5-2620v2 processor (2.10 GHz, 12 cores, 48GB
RAM). We also experimented with other SoC boards
like NanoPi NEO (Allwinner H3, ARM Cortex-A7,
4 cores, 1.2GHz, 512MB RAM), an NTC C.H.I.P.
(AllWinner R8 processor, ARM Cortex-A8, 1 core,
1GHz, 512MB RAM) and a Banana Pi (Allwinner
A83T processor, Arm Cortex-A7 8 cores, 1.8 GHz,
1GB RAM), but their poor performances or incompat-
ibilities with Docker forced us to exclude these plat-
forms from the subsequent tests.
All measures presented in this section correspond
to the average of at least 5 runs. For the Docker
Swarm clusters, we interconnected the devices via a
1 Gbps switch over RJ45, to avoid unreliable results
due to the wireless connections.
Furthermore, as the WRF workflow is composed
by 5 steps, we computed the execution time of
each step individually, in order to assess the best
deployment strategy. Therefore, the next sections
present the separate analysis of the preprocessing
steps (WPS+real) and the forecast step (WRF).
5.2 WPS and Real
As explained in Section 4.1, the size of the geograph-
ical database used by the Geogrid step on WPS often
poses a problem for typical SoC internal storage. In-
deed, in our experiments, we had to attach an external
USB storage device to a Raspberry Pi node to accom-
modate the WPS GEOG database.
Because WPS can be compiled with the dmpar op-
tion, we first tried to identify whether the use of MPI
would benefit each one of the WPS steps (as well as
the real step). For such, we measured the execution
time of each step when varying the number of com-
puting cores (using the mpirun -np option).
0
50
100
150
200
250
300
1 2 3 4
Time (s)
Number of Cores
WRF preparation steps in a Raspberry Pi 3
Geogrid Ungrib Metgrid Real
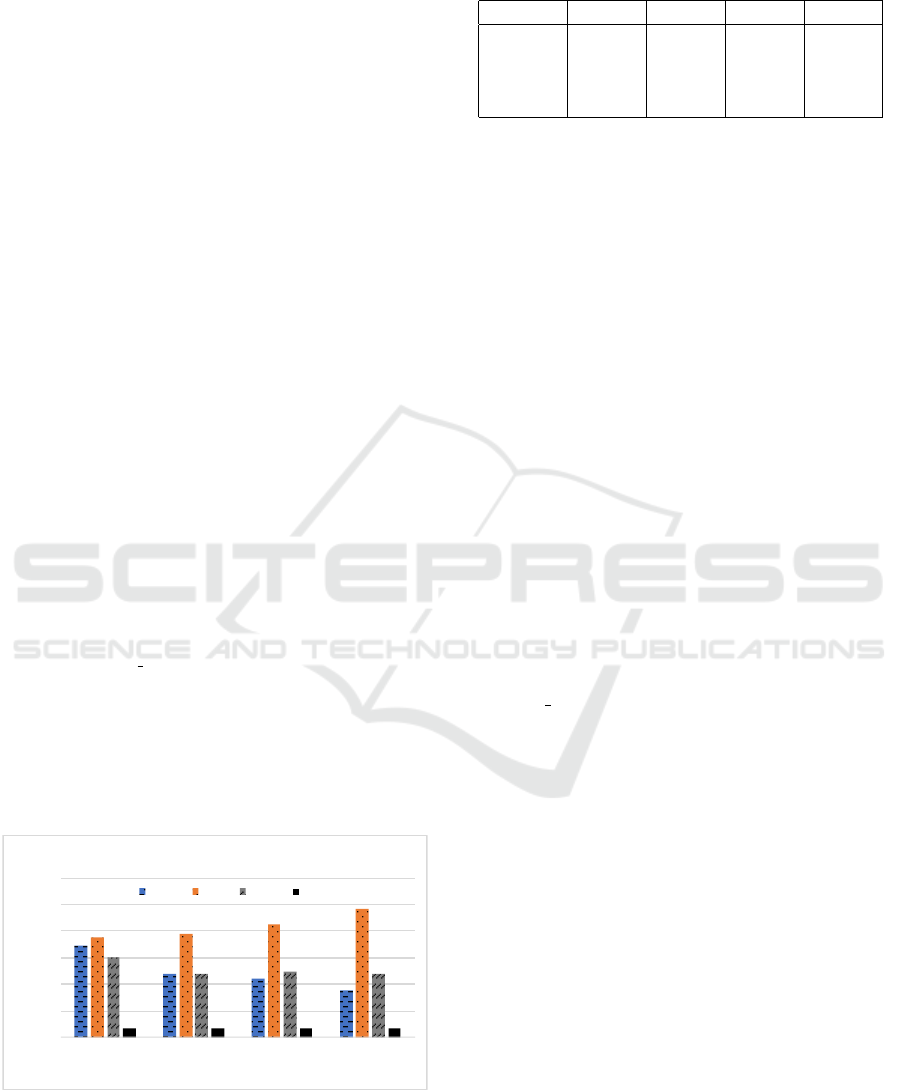
Figure 3: Performance of WPS steps when varying the
number of cores.
The result of this benchmark, illustrated in Figure
3 and detailed in Table 1, indicates that only the Ge-
Table 1: Relative performance of WPS steps on a single
machine (in seconds).
Cores 1 2 3 4
Geogrid 173.81 119.59 111.56 88.54
Ungrib 188.78 196.15 212.97 241.57
Metgrid 151.42 120.47 123.56 119.26
Real 16.437 16.54 16.59 16.69
ogrid step effectively benefits from a multi-core exe-
cution. In the case of Ungrib, the parallel execution
even penalizes the algorithm. The Metgrid step shows
a small performance gain when parallelizing but the
execution time stabilizes for 2 or more cores, and the
Real step shows no evidence of improvements. Addi-
tional benchmarks on the network performance, such
as those conducted by (Yong et al., 2018), may also
help tuning the different steps.
Even if Geogrid presents some performance im-
provements when run in parallel, the acceleration is
under-optimal (we need 4x cores to obtain only a 50%
performance improvement). Associated with the stor-
age limitations cited before and its relatively small
impact to the overall execution time (when compar-
ing with the forecast step, see Section 5.3), we ad-
vise against running Geogrid cluster-wide. Instead,
we suggest assigning a single node (the master) who
can preprocess the data for the forecast model.
From these results, we suggest organizing the de-
ployment of the preprocessing steps as follows:
• Geogrid - parallel execution with mpirun, pref-
erentially only in the machine hosting the
WPS GEOG database (the master node);
• Ungrib - serial execution in a single core;
• Metgrid - serial execution or at most parallel exe-
cution with mpirun in a single machine;
• Real - serial execution in a single core.
5.3 WRF
Contrarily to the preprocessing steps that finally rep-
resent only a small computing load, the WRF fore-
cast is the main workload of the workflow. This is
even more important on “production” environments,
where more than a simple 12-hour forecast need to be
computed.
Indeed, the forecasting step of WRF can benefit
from multicore and cluster scenarios. Figure 4 indi-
cates the average execution time when executing the
WRF step on a single Raspberry Pi 3 (1 to 4 cores),
on a cluster with two Raspberry Pi 3 (summing up 8
cores) and on a Swarm cluster with two Raspberry Pi
3 and one Raspberry Pi 2 (summing up 12 cores).
CLOSER 2019 - 9th International Conference on Cloud Computing and Services Science
566
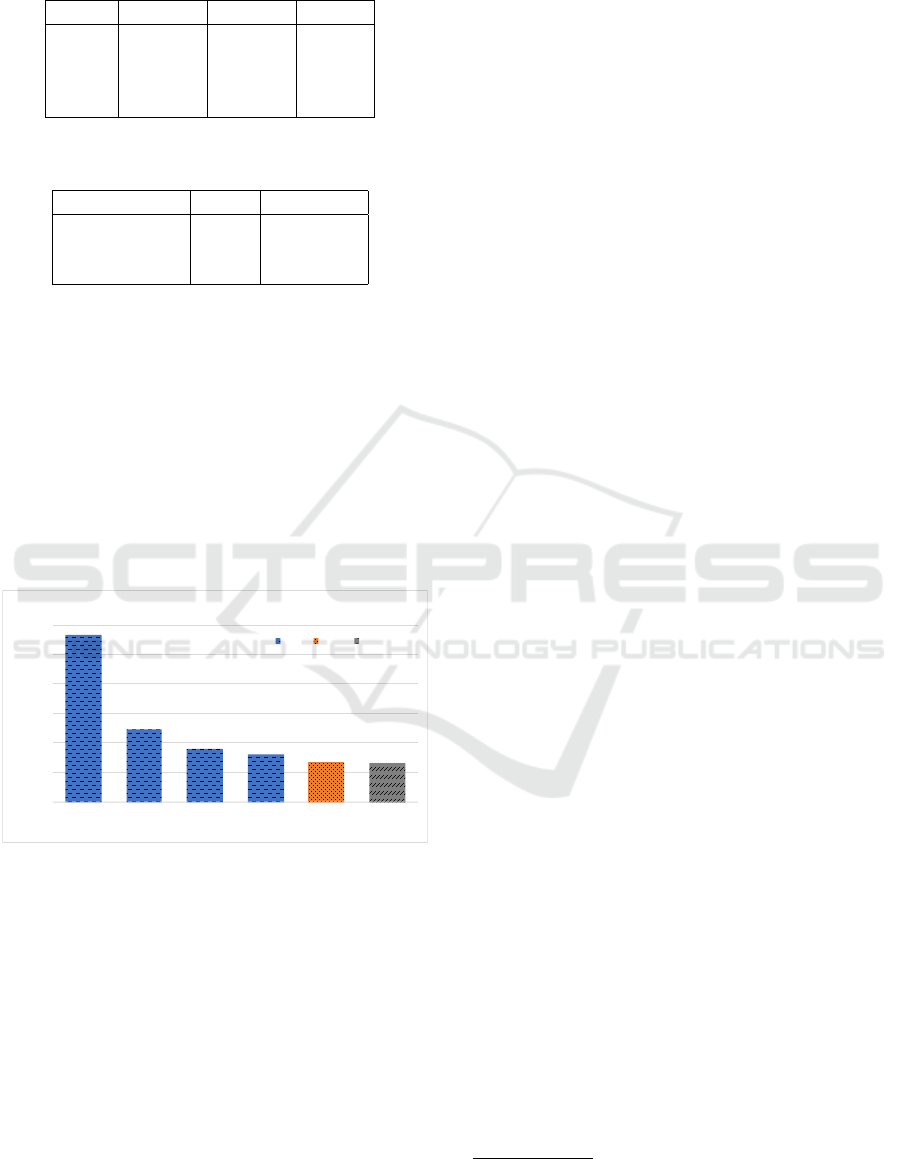
Table 2: WRF relative performance on a single machine (in
seconds).
Cores R Pi 2 R Pi 3 Xeon
1 6268.96 5647.47 539.05
2 3280.34 2473.89 314.69
3 2468.89 1801.18 264.53
4 2075.88 1602.68 173.55
Table 3: Performance on a Raspberry Pi swarm cluster (in
seconds).
Machines Cores Pi Swarm
1 x Pi 3 4 1602.68
2 x Pi 3 8 1322.42
2 x Pi 3 + Pi 2 12 1306.10
If multicore execution allows an important perfor-
mance gain, the Swarm cluster executions show more
mitigated results. As WRF is regularly executed in
production clusters with the dmpar mode (MPI) and
that the Docker overlay network imposes little over-
load, we suspect that the reduced performance gain is
related to the network performance on the Raspberry
Pis. Indeed, as observed by (Beserra et al., 2017), the
access to the communication bus is a recurrent prob-
lem on SoC, and the Raspberry Pi suffer from a “low”
speed interconnection card (10/100 Mbps only).
0
1000
2000
3000
4000
5000
6000
1 2 3 4 8 12
Execution Time (s)
Number of cores
WRF Multicore and Swarm Mode Performances
1 node 2 nodes 3 nodes
Figure 4: Performance of WRF in multicore and swarm
cluster mode.
Tables 2 and 3 detail these results, and also present
a performance comparison with a Xeon processors.
While the x86 processors are faster, the execution
time on the Raspberry Pis is still acceptable, enough
to deliver forecasts on a daily or even hourly basis, or
for education and training. If we consider the mate-
rial and environmental cost of the SoC solution, it is
indeed an interesting alternative for scientific applica-
tions like WRF.
6 CONCLUSIONS
This work focuses on the deployment of containerized
scientific applications over a cluster of SoC-based
systems. Most System-on-a-Chip (SoCs) are based on
the ARM architecture, a flexible and well-known fam-
ily of processors that now started to infiltrate the HPC
(High Performance Computing) domain. Container-
based virtualization, on the other side, enables the
packaging of complex applications and their seamless
deployment. Together, SoC and containers represent
a promising alternative for the development of com-
puting infrastructures, associating the low cost and
minimal maintenance of SoCs and the flexibility of
containers.
Nonetheless, most traditional scientific applica-
tions rely on MPI for scalability, and popular con-
tainer managers like Docker do not offer a proper sup-
port for MPI. We therefore propose, in a first moment,
a service specification to deploy a Docker Swarm
cluster that is ready for MPI applications. Later, we
study how to adapt the WRF meteorological forecast
model to run on ARM-based SoCs. Benchmarks on
different SoC platforms are used to evaluate the per-
formance and the interest of using containers over
SoC clusters. These results indicate that if popular
SoCs such as Raspberry Pi cannot compete in per-
formance with x86 processors, they still are able to
deliver results within an acceptable delay.
Future improvements to this work include the de-
velopment of a generic platform capable of accom-
modating other MPI applications, as well as the sup-
port for recent versions of WRF and its integration on
more elaborated frameworks.
ACKNOWLEDGEMENTS
This research has been partially supported by the
French-Brazilian CAPES-COFECUB MESO project
9
and the GREEN-CLOUD project
10
(#16/2551-
0000 488-9), from FAPERGS and CNPq Brazil, pro-
gram PRONEX 12/2014.
REFERENCES
Ali, M., Vlaskamp, J. H. A., Eddin, N. N., Falconer, B., and
Oram, C. (2013). Technical development and socioe-
conomic implications of the Raspberry Pi as a learn-
ing tool in developing countries. In Computer Sci-
9
http://meso.univ-reims.fr
10
http://www.inf.ufrgs.br/greencloud/
A Containerized Tool to Deploy Scientific Applications over SoC-based Systems: The Case of Meteorological Forecasting with WRF
567

ence and Electronic Engineering Conf. (CEEC), pages
103–108. IEEE.
Alvarez, L., Ayguade, E., and Mantovani, F. (2018).
Teaching HPC systems and parallel programming
with small-scale clusters. In 2018 IEEE/ACM Work-
shop on Education for High-Performance Computing
(EduHPC), pages 1–10.
Azab, A. (2017). Enabling Docker containers for high-
performance and many-task computing. In 2017
IEEE International Conference on Cloud Engineering
(IC2E), pages 279–285.
Beserra, D., Pinheiro, M. K., Souveyet, C., Steffenel, L. A.,
and Moreno, E. D. (2017). Performance evaluation of
os-level virtualization solutions for HPC purposes on
SoC-based systems. In 2017 IEEE 31st International
Conference on Advanced Information Networking and
Applications (AINA), pages 363–370.
Burns, B., Grant, B., Oppenheimer, D., Brewer, E., and
Wilkes, J. (2016). Borg, omega, and kubernetes. Com-
mun. ACM, 59(5):50–57.
Chung, M. T., Quang-Hung, N., Nguyen, M., and Thoai, N.
(2016). Using docker in high performance computing
applications. In 2016 IEEE Sixth International Con-
ference on Communications and Electronics (ICCE),
pages 52–57.
Council, H. A. (2010). Weather research and fore-
casting (WRF): Performance benchmark and
profiling, best practices of the HPC advisory
council. Technical report, HPC Advisory Coun-
cil, http://www.hpcadvisorycouncil.com/pdf/
WRF Analysis and Profiling Intel.pdf.
Cox, S. J., Cox, J. T., Boardman, R. P., Johnston, S. J., Scott,
M., and O’brien, N. S. (2014). Iridis-pi: a low-cost,
compact demonstration cluster. Cluster Computing,
17(2):349–358.
d. Bayser, M. and Cerqueira, R. (2017). Integrating mpi
with docker for hpc. In 2017 IEEE International Con-
ference on Cloud Engineering (IC2E), pages 259–265.
Felter, W., Ferreira, A., Rajamony, R., and Rubio, J. (2014).
An updated performance comparison of virtual ma-
chines and linux containers. IBM technical report
RC25482 (AUS1407-001), Computer Science.
Hacker, J. P., Exby, J., Gill, D., Jimenez, I., Maltzahn, C.,
See, T., Mullendore, G., and Fossell, K. (2017). A
containerized mesoscale model and analysis toolkit to
accelerate classroom learning, collaborative research,
and uncertainty quantification. Bulletin of the Ameri-
can Meteorological Society, 98(6):1129–1138.
Higgins, J., Holmes, V., and Venters, C. (2015). Orches-
trating docker containers in the HPC environment. In
Kunkel, J. M. and Ludwig, T., editors, High Perfor-
mance Computing, pages 506–513, Cham. Springer
International Publishing.
Kurtzer, G. M., Sochat, V., and Bauer, M. W. (2017). Singu-
larity: Scientific containers for mobility of compute.
PLOS ONE, 12(5):1–20.
Langkamp, T. and B
¨
ohner, J. (2011). Influence of the com-
piler on multi-CPU performance of WRFv3. Geosci-
entific Model Development, 4(3):611–623.
Marathe, A., Harris, R., Lowenthal, D., de Supinski, B. R.,
Rountree, B., and Schulz, M. (2014). Exploiting re-
dundancy for cost-effective, time-constrained execu-
tion of HPC applications on Amazon EC2. In 23rd Int.
Symposium on High-Performance Parallel and Dis-
tributed Computing, pages 279–290. ACM.
Molano, J. I. R., Betancourt, D., and G
´
omez, G. (2015).
Internet of things: A prototype architecture using a
Raspberry Pi. In Knowledge Management in Organi-
zations, pages 618–631. Springer.
Montella, R., Giunta, G., and Laccetti, G. (2014). Virtu-
alizing high-end GPGPUs on ARM clusters for the
next generation of high performance cloud comput-
ing. Cluster computing, 17(1):139–152.
Morabito, R., Kjallman, J., and Komu, M. (2015). Hyper-
visors vs. lightweight virtualization: a performance
comparison. In Cloud Engineering (IC2E), IEEE Int.
Conf. on, pages 386–393. IEEE.
Nguyen, N. and Bein, D. (2017). Distributed MPI cluster
with Docker Swarm mode. In 2017 IEEE 7th Annual
Computing and Communication Workshop and Con-
ference (CCWC), pages 1–7.
Ruiz, C., Jeanvoine, E., and Nussbaum, L. (2015). Perfor-
mance evaluation of containers for HPC. In Hunold,
S., Costan, A., Gim
´
enez, D., Iosup, A., Ricci, L.,
G
´
omez Requena, M. E., Scarano, V., Varbanescu,
A. L., Scott, S. L., Lankes, S., Weidendorfer, J., and
Alexander, M., editors, Euro-Par 2015: Parallel Pro-
cessing Workshops, pages 813–824, Cham. Springer
International Publishing.
Skamarock, W. C., Klemp, J. B., Dudhia, J., Gill, D. O.,
Barker, D. M., Duda, M. G., Huang, X.-Y., Wang,
W., and Powers, J. G. (2008). A description of the
advanced research WRF version 3, NCAR techni-
cal note. National Center for Atmospheric Research,
Boulder, Colorado, USA.
Somasundaram, T. S. and Govindarajan, K. (2014).
CLOUDRB: A framework for scheduling and manag-
ing high-performance computing (HPC) applications
in science cloud. Future Generation Computer Sys-
tems, 34:47–65.
Steffenel, L. and Kirsch-Pinheiro, M. (2015). When the
cloud goes pervasive: approaches for IoT PaaS on a
mobiquitous world. In EAI International Conference
on Cloud, Networking for IoT systems (CN4IoT 2015),
Rome, Italy.
Weloli, J. W., Bilavarn, S., Vries, M. D., Derradji, S., and
Belleudy, C. (2017). Efficiency modeling and explo-
ration of 64-bit ARM compute nodes for exascale. Mi-
croprocessors and Microsystems, 53:68 – 80.
Wolf, W., Jerraya, A. A., and Martin, G. (2008).
Multiprocessor system-on-chip (MPSoC) technology.
Computer-Aided Design of Integrated Circuits and
Systems, IEEE Transactions on, 27(10):1701–1713.
Yong, C., Lee, G.-W., and Huh, E.-N. (2018). Proposal of
container-based hpc structures and performance anal-
ysis. 14.
Younge, A. J., Henschel, R., Brown, J. T., von Laszewski,
G., Qiu, J., and Fox, G. C. (2011). Analysis of virtu-
alization technologies for high performance comput-
ing environments. In IEEE 4th International Confer-
ence on Cloud Computing, CLOUD ’11, pages 9–16,
Washington, DC, USA. IEEE Computer Society.
CLOSER 2019 - 9th International Conference on Cloud Computing and Services Science
568
