
An Evaluation of Big Data Architectures
Valerie Garises and Jos
´
e G. Quenum
Namibia University of Science and Technology, 13 Jackson Kaujeua, Windhoek, Namibia
Keywords:
Big Data, Software Architecture Analysis, Software Architecture Evaluation, Software Architectural Patterns.
Abstract:
In this paper, we present a novel evaluation of architectural patterns and software architecture analysis using
Architecture-based Tradeoff Analysis Method (ATAM). To facilitate the evaluation, we classify the Big Data
intrinsic characteristics into quality attributes. We also categorised existing architectures following architec-
tural patterns. Overall, our evaluation clearly shows that no single architectural pattern is enough to guarantee
all the required quality attributes. As such, we recommend a combination of more than one pattern. The net
effect of this would be to increase the benefits of each architectural pattern and then support the design of Big
Data software architectures with several quality attributes.
1 INTRODUCTION
The ongoing Big Data challenge brings an increas-
ing burden to software and system architects. Usually,
they select a tool/infrastrcture (e.g., Apache Hadoop,
Apache Spark) that satisfies most big data functions.
(Garises and Quenum, 2018) pondered over the sus-
tainability of this approach, whether it makes optimal
use of resources and how it deals with maintenability.
It argued the need for a reference architecture where
the tools and infrastructure are selected and assem-
bled suitably.
One critical step towards defining the reference ar-
chitecture is to identify the central components that
should make up a reference architecture as well as
their roles and responsibilities. In this paper, we re-
visit existing big data architectures and analyse them
using a software architecture evaluation method. The
IEEE standard 1471 (W. Maier et al., 2000) defines a
software architecture as the fundamental organisation
of a system embodied in its components, their rela-
tionships to each other and the environment and the
principles guiding its design and evolution. A soft-
ware architecture is generally defined as a logical con-
struct for defining and controlling the interfaces and
the integration of all the components of the system.
Similarly, (Bass et al., 2003) define it as the structure
or structures of the system, which comprise compo-
nents, their externally visible behaviour, and the rela-
tionships among them. In short, a software architec-
ture is about a structure formed by components and
the connections between them.
Furthermore, a software architecture is usually ar-
rived at following an architectural pattern. Accord-
ing to (Garlan and Shaw, 1994), a pattern describes
a problem which occurs over and over in the envi-
ronment and then describes the core of the solution
of that problem so that it can be applied a million
times over. An architectural pattern thus determines
the various components and connectors that can be
associated with the instances of that style along with
a set of constraints on their combination. Common ar-
chitecture patterns include Layers, Pipes and Filters,
Model View Controller (MVC), Broker, Client-Server
and Shared Repository.
In this work, we selected various big data architec-
tures and evaluated them using the architecture-based
trade-off analysis method (ATAM); a scenario-based
evaluation method. In order to conduct the evaluation,
we mapped each one of them to an architectural pat-
tern. Our evaluation reveals that no architectural pat-
tern fulfils the requirements for Big data systems. It
thus underscores the need for a combination of these
architectural patterns in a big data system.
The remainder of the paper is as follows. Sec-
tion 2 discusses architecture evaluation methods. Sec-
tion 3 discusses the actual evaluation of selected big
data architectures. Section 4 summarises our findings,
while Section 5 draws some conclusions and sheds
light on future work.
152
Garises, V. and Quenum, J.
An Evaluation of Big Data Architectures.
DOI: 10.5220/0007840801520159
In Proceedings of the 8th International Conference on Data Science, Technology and Applications (DATA 2019), pages 152-159
ISBN: 978-989-758-377-3
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

2 SOFTWARE ARCHITECTURE
ANALYSIS METHODS
The aim of analysing an architecture is to predict the
quality of a software system before it is built. Eval-
uating an architecture, on the other hand, is to com-
pare it with another architectural candidate or with a
set of requirements in order to minimise the risks and
provide evidence that the fundamental requirements
have been addressed (Kazman et al., 2000). There are
several software architecture evaluation methods such
as experience-based, scenario-based, mathematical
modelling, and simulation-based (Ali Babar et al.,
2004). These evaluation methods are applicable in
different phases of the software development cycle.
Overall, a software architecture can be evaluated be-
fore, during and after implementation. In this paper,
we focused on the scenario-based evaluation method.
Architecture-based Trade-off Analysis Method
(ATAM).
In this paper, we set out to evaluate multiple architec-
tures using multiple quality attributes. As such ATAM
proves to be a good fit for our evaluation. ATAM is
generally aimed at evaluating architectures after the
design phase, but before they are implemented. How-
ever, in some cases, it has been used on deployed sys-
tems. In a survey, (Al-Jaroodi and Mohamed, 2016)
identified common requirements for big data systems.
These are:
R
1
: Scalability. Big Data systems must be scal-
able, i.e., be able to increase and support different
amounts of data, processing them uniformly, al-
locating resources without impacting costs or ef-
ficiency. To meet this requirement, it is required
to distribute datasets and their processing across
multiple computing and storage nodes;
R
2
: High Performance Computing. Big Data sys-
tems must be able to process large streams of data
in a short period of time, thus returning the re-
sults to users as efficiently as possible. In addi-
tion, the system should support computation in-
tensive analytic, i.e., support diverse workloads,
mixing request that requires rapid responses with
long-running requests that perform complex an-
alytic on significant portions of the data collec-
tion (Gorton and Klein, 2015);
R
3
: Modularity. Big Data systems must offer dis-
tributed services, divided into modules, which can
be used to access, process, visualise, and share
data, and models from various domains, provid-
ing flexibility to change machine tasks;
R
4
: Consistency. Big Data systems must sup-
port data consistency, heterogeneity, and exploita-
tion. Different data formats must be also man-
aged to represent useful information for the sys-
tem (Cecchinel et al., 2014). Besides that, sys-
tems must be flexible to accommodate this mul-
tiple data exchange formats and must achieve the
best accuracy as possible to perform these opera-
tions;
R
5
: Security. Big Data systems must ensure secu-
rity in the data and its manipulation in the archi-
tecture, supporting the integrity of information,
exchanging data, multilevel policy-driven, access
control, and prevent unauthorised access (Dem-
chenko et al., 2016);
R
6
: Real-time Operations. Big Data systems must
be able to manage the continuous flow of data
and its processing in real time, facilitating deci-
sion making;
R
7
: Inter-operability. Big Data systems must be
transparently intercommunicated to allow ex-
changing information between machines and pro-
cesses, interfaces, and people (Santos et al.,
2017); Thus, it must facilitate interoperability be-
tween disparate and heterogeneous systems, both
existing and future;
R
8
: Availability. Big Data systems must ensure high
data availability, through data replication horizon-
tal scaling, i.e., spread a data set over clusters
of computers and storage nodes, avoiding bottle-
necks (Gorton and Klein, 2015)
Since all these architectural requirements are clas-
sified as non-functional requirements, we mapped
them onto a known quality model, specifically
ISO/IEC 25010 (ISO/IEC, 2010). Table 1 provides
a snapshot of this mapping.
Table 1: Mapping of Big Data Requirements to Quality At-
tributes of ISO/IEC 25010.
Requirements Quality Attributes
Consistency Not covered
Scalability Portability: adaptability
Real-time Operation Performance efficiency:
time-behavior
High Performance Computing Performance efficiency:
time-behavior
and resource utilisation
Security Security: confidentiality,
integrity and authenticity
Availability Reliability: availability and
recoverability
Modularity Maintainability: modularity
Inter-operability Compatibility: inter-operability
It should be noted that consistency is not cov-
ered by the quality model. Consistency represents
the ability of all integrated information, whether from
An Evaluation of Big Data Architectures
153
one data source or many, to be cohesive and usable.
The non-coverage of this attribute may be due to the
fact that ISO/IEC 25010 represents a quality model
for systems, while consistency represents information
quality.
Due to the exponential growth of data over the last
decade and, consequently, the increase in the number
of Big Data systems, it is necessary to resort to archi-
tectural patterns for the development of these systems.
Moreover, the Big Data requirements of software ar-
chitectures in those systems can directly impact the
outcome of the software quality challenges. Hence,
the characterisation of these architectures against the
requirements is fundamental.
3 ARCHITECTURE EVALUATION
WITH ATAM
3.1 Business Drivers
As part of the ATAM process, business drivers were
identified from the requirements. Here, we used the
context of the Namibia healthcare use case and archi-
tectural requirements outlined in Section 2. The core
business drivers are listed below and are mapped to
the Big Data architectural requirements from which
they were derived.
Modifiability is important as messaging standards
may change over time and new transactions, or-
chestrations and health information systems (HIS)
may be added over time (R
1
and R
4
);
Scalability and Performance are important as such a
system may be deployed at a national level and it
should remain functional at scale (R
1
and R
2
);
Availability is essential as the Big Data inter-
operability infrastructure needs always to be
available so that vital health data can be captured
and retrieved around the clock (R
6
and R
8
);
Inter-operability is vital as the architecture should be
able to communicate and exchange data with to a
wide variety of environments (R
3
and R
7
);
Security is important as a patient’s health informa-
tion is highly confidential and should not be tam-
pered with or viewed by unauthorised parties
(R
5
).
3.2 Big Data Architectures
We selected several known Big Data reference ar-
chitectures in the academia and industry. These in-
clude Big Data Architecture Framework, Big Data
Enterprise Model, Big Data Analytics Architecture in
Healthcare, Microsoft Big Data Ecosystem Architec-
ture, IBM Big Data Analytics Reference Architecture
and Oracle Reference Architecture. In the follow-
ing subsections we describe some of these architec-
tures. These architectures were analysed retrospective
as some are already implemented.
3.2.1 Big Data Analytics Architecture in
Healthcare
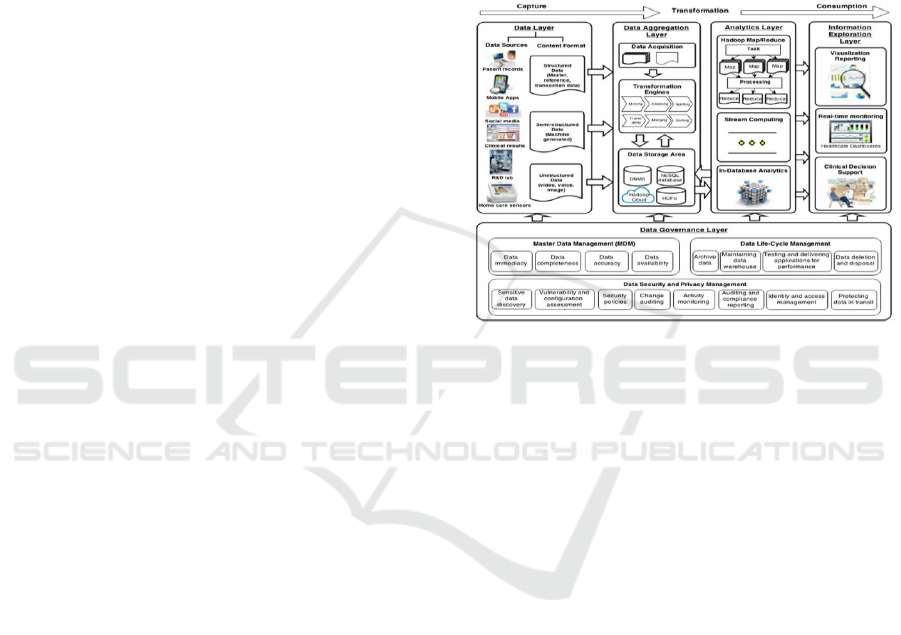
Figure 1: Big Data Analytics Architecture in Healthcare.
(Wang et al., 2018), define a Big Data analytics
architecture embedded in the concept of data lifecy-
cle framework that starts with data capture, proceeds
via data transformation and concludes with data con-
sumption. Figure 1 depicts the proposed best practice
Big Data analytics architecture that loosely comprises
five major architectural layers: (1) data, (2) data ag-
gregation, (3) analytics, (4) information exploration,
and (5) data governance. These logical layers make
up the Big Data analytics components that perform
specific functions, and will, therefore, enable health-
care managers to understand how to transform the
healthcare data from various sources into meaning-
ful clinical information through Big Data implemen-
tations.
3.2.2 IBM Big Data Reference Architecture
IBM introduces Big Data and Analytics Reference
Architecture with eleven components as depicted in
Figure 2. The reference architecture is intended to be
used by sales professionals selling IBM software and
designing end-to-end Big Data and analytics client so-
lutions.
DATA 2019 - 8th International Conference on Data Science, Technology and Applications
154

Figure 2: IBM Big Data Reference Architecture Compo-
nents.
3.3 Underlying Architectural Patterns
In Table 2, we present a summary of the architectures
above and their references and match the architectural
patterns identified in each one.
Table 2: Big Data Reference Architectures and Architec-
tural Patterns.
ID Title and Reference Architectural Pattern
A
1
Big Data Architecture Pipes and Filters
Framework (BDAF)
A
2
Big Data Enterprise Model Shared Repository
A
3
Big Data Analytics Architecture Pipes and Filters
in Healthcare
A
4
Microsoft Big Data Ecosystem Pipes and Filters
Architecture
A
5
IBM Big Data Analytics Pipes and Filters
Reference Architecture
A
6
Oracle Reference Architecture Layered
3.4 Quality Attributes and Utility Tree
Following step 5 of the ATAM process, a utility tree
was drawn up as depicted in Figure 3. The utility
tree maps scenarios derived from the architectural re-
quirement of the architecture to the quality attributes
that the scenarios fall under. To construct the util-
ity tree many scenarios that the architecture needs
to address must be elicited. The high-level require-
ments that were derived from the Namibia healthcare
use case were used to formulate these scenarios along
with known scenarios gathered. The utility tree con-
tains a list of ten scenarios that have been prioritized
and mapped to the particular quality attribute that it
addresses.
Furthermore, following Step 7 in the ATAM pro-
cess, the evaluation scenarios that appeared in the util-
ity tree were prioritized along two dimensions. The
Figure 3: Utility Tree.
first dimension is the importance of the scenarios to
the success of the architecture and the second dimen-
sion is the anticipated difficulty in achieving this sce-
nario. These ratings can be seen in brackets on the
utility tree scenarios, rated on a scale of high (H),
medium (M) and low (L). Using these priorities, the
highest rated quality attributes were identified. These
attributes are the most important to the success of
the architecture which also defines its quality. The
attributes of high importance are chosen as the at-
tributes that will be evaluated to determine the overall
quality of the architecture.
Moreover, ATAM categorises the architectural at-
tributes according to two risk categories namely run-
time (availability, performance, availability) and de-
velopment (modifiability, integration). Hence, the
total architecture quality is a function that consists
of modifiability, scalability, performance, interoper-
ability, and security attributes. In other words, the
overall HLM architecture quality can be defined as:
Q
Arch
= f (Q
Mod
, Q
Sca
, Q
per
, Q
Sec
, Q
inter
). However,
this analysis will only focus on the architecture devel-
opment quality attributes which is a subset of function
Q
Arch
.
3.5 Analysing the Architectural
Patterns
3.5.1 Pipes and Filters Pattern
In this architectural pattern data comes from an exter-
nal source or producer and is managed through sev-
eral steps, such as data collection, preparation, pro-
cessing, and visualisation. Finally, the results of such
processing are sent to consumers and or domain appli-
cations. In Table 2, four of the six architectures have
An Evaluation of Big Data Architectures
155

the Pipe and Filter (PF) architectural pattern. More
details about the PF pattern can be found in (Bass
et al., 2003).
• Scenario 1 (Context). This refers to the first
scenario under the utility tree (Figure 3) under
Scalability and Performance attribute. Big Data
systems need to “handle a massive increase in
data sizes” to extract useful value from this mas-
sive volume of data generated in real time. To
meet this requirement data extraction must pass
through several steps (e.g., data collection, data
integration, pre-processing, processing, and data
visualisation), which could support the overall
data mining process. These steps have to be ex-
ecuted in a specific order to complete the accurate
data processing and analysing.
• Problem. The Big Data architectures must sup-
port the execution of efficient data flows real-time
as well as batch processing. The communication
between the steps must be scalable, avoiding bot-
tlenecks in performance that could result in fail-
ures or delays or inconsistencies in the data min-
ing steps. Data must be processed independently
in each step, and thus sent to the next to maintain
real-time operation.
• Solution. This pattern structures the processing
of a stream of data (Geerdink, 2015). Each pro-
cessing step is implemented as a filter, with in-
formation flowing between the filters through a
pipe. Filters can be combined in many ways to
provide a family of solutions. Its importance is
justified because the sequence of data analysis is
essential. For example, it is not possible to ex-
tract value from data that have still not been pre-
processed. This pattern increases complexity and
could support data transformation, implying on
high dependence between the filters (Buschmann
et al., 2007).
• Trade-offs. This is one of the closest related pat-
terns to the Big Data context because it was pro-
posed to solve data processing issues. However,
only such data flow is not sufficient to ensure that
there will be quality in performance. Pipes and
filters implementation usually achieve scalability
and performance, but several Big Data specifici-
ties impact its execution and may minimise its
benefits. Firstly, a high volume of data is gener-
ated in real-time and should be consumed by the
filters and processed effectively. However, some
of the pipe steps require that the entire dataset be
loaded before processing and since there is no al-
ternative way, processing queues are generated,
thus impacting scalability, response time, and di-
rectly performance. The veracity of the data can
also take risks in this pattern. There are no inter-
mediary sources of input and output between the
filters, that is, the data is the input of the first, and
the extracted value of the data is the output of the
last one. This increases the complexity (i.e., vol-
ume, variety) of the data causing some failures in
the middle of the execution, and such failures can
be propagated resulting in changes or even data
loss. This indicates a central point of failure and
at the same time a liability to safety.
3.5.2 Shared Repository Pattern
In this architecture, there is a shared repository to
communicate to all the architecture components, i.e.,
components for Big Data processing, technological
modules, the broker that process data generated by
several sources, and the server connected to the do-
main applications. This repository is responsible
for receiving requests from all these components
and maintain data availability and consistency (Chen
et al., 2015).
• Scenario 2 (Context). This refers to the first and
second scenarios under the utility tree (Figure 3)
under Modifiability attribute. Also, to the massive
volumes of data which managed and processed it
must be able to handle a variety of data and mes-
saging types to transfer data to different formats,
domains and systems. These systems must be
flexible to “add or remove mediators and messag-
ing standards” while processing and storing the
vast variety of data types. The processed data
must be shared in different formats to different
consumers, devices, application, systems, people
and domains.
• Problem. In this scenario, preparing a Big Data
repository often involves more mediators and
messaging standards and challenges when such
data must be shared among different consumers,
producers and domains in real-time. Shared pro-
cessing, storage and management also increase a
control issue related to how and when data will
be available in order to be read or written in the
shared memory and storage.
• Solution. The shared repository pattern con-
sists of using a data repository as communica-
tion among different software components cross-
ing domain boundaries. Information produced by
a component is stored in the shared repository,
and other components will retrieve it if they re-
quest such data. The repository manages the com-
mon data handling application’s operation and
DATA 2019 - 8th International Conference on Data Science, Technology and Applications
156

their permissions to access and modify the repos-
itory. Thus, this pattern reduces the communica-
tion flows by allowing only requested data, which
entails a gain in performance in Big Data systems.
Reuse of data benefits the third party, who gets in-
formation from a common shared repository.
• Trade-offs. The main benefits of this pattern in-
clude the combination with different storage pat-
terns for improving the way large volumes of data
are stored using cloud and distributed systems.
However, the shared repository pattern has some
drawbacks in the performance and scalability that
can be severely affected in distributed environ-
ments by concurrent access to the data. Shared
repository transmission can fail, and the whole
system is immediately affected by losing the syn-
chronisation with other services as well as real-
time response. In addition, modifying the struc-
ture, mediators, messaging standards of the shared
repository has a negative impact on Big Data sys-
tems resulting in modifications in the interfaces
and software communication systems.
3.5.3 Layered Pattern
In this architectural pattern the architecture is divided
in the functionalities into layers according to the dif-
ferent steps of data analytics (e.g., storage, publisher,
sources, and applications). Moreover, (Santos et al.,
2017) proposed a common layer in Big Data archi-
tectures, focusing on security, management and mon-
itoring, which includes components that provide base
functionalities needed in the other layers, ensuring the
proper operation of the whole infrastructure. Com-
munication and data flow between the layers can be
implemented through interfaces and APIs.
• Scenario 3 (Context). This refers to the scenario
under the utility tree (Figure 3) under Interoper-
ability attribute. Big Data systems require the sep-
aration of roles among their components. Such
division must be established at both the module
level (i.e., data processing, data storage, data vi-
sualisation, data integration) and at the abstrac-
tion level (i.e., communication, security, man-
agement). However, these different components
must be tightly integrated and interoperable to ex-
change data and messages among the different
layers. Besides that, these systems must orches-
trate the flow of data to execute business pro-
cesses, and hence to ensure that the objectives of
the system are fulfilled and that data is not lost.
• Problem. From the above scenario, Big Data
architectures must allow the division of respon-
sibilities, by grouping them based on goals and
functionalities. Such architectures must provide
means to process data in real-time, because some-
times a specific workflow depends on the results
of the previous one. Moreover, the communica-
tion protocols must guarantee high performance
and data scalability, avoiding bottlenecks.
• Solution. The layered pattern provides a horizon-
tal division of software responsibilities by group-
ing a set of functionalities in encapsulated and in-
dependent layers. The specific partitioning crite-
ria can be defined along various dimensions, such
as abstraction, granularity, hardware distance, and
rate of change. Layers of an architecture generally
communicate with adjacent layers through imple-
mented interfaces. Therefore, one layer can make
requests to the next layer, and wait for the re-
sponse while responding to requests from the pre-
vious layer. Such interfaces must be scalable and
implement communication protocols to ensure ef-
ficiency.
• Trade-offs. The waiting time and the execution
of communication protocols may delay process-
ing and cause the response to not be as fast as
expected. Besides, these communication proto-
cols impact scalability, since the high volume of
data must be processed at the same time and can
cause a bottleneck between the layers. Finally, be-
cause data have to go through different layers, the
processing performance is directly impacted. Re-
garding Big Data requirements, this pattern sup-
ports the modularity by providing a division of
concerns in the application. The independence of
each layer enables the implementation of different
protocols for keeping the data safe to be sent only
when necessary, allowing a positive impact on the
security requirement of Big Data. Considering
weaknesses, three of the most important Big Data
requirements are minimised by this pattern (i.e.,
Real-Time Operation (R
6
), Scalability (R
1
), and
High-Performance computing (R
2
)). Big Data re-
quires the processing of data at run-time because
a specific layer depends on the result of the pre-
vious one. Hence, the wait time and the execu-
tion of communication protocols may delay pro-
cessing and cause the response not to be as fast as
expected. These communication protocols impact
scalability, since the high volume of data, must be
processed at the same time and can cause a bot-
tleneck between the layers. Finally, because data
have to go through different layers, the processing
performance is directly impacted.
An Evaluation of Big Data Architectures
157

4 EVALUATION RESULTS
From the evaluation discussed in Section 3 it is clear
that Big Data systems must be designed considering
their 5V’s intrinsic characteristics of Volume, Veloc-
ity, Variety, Veracity, and Value. From a perspective
of software architecture, it is important to define the
requirements of quality attributes that must be ful-
filled by those systems. In Table ref, we summarise
the results, mapping the Big Data characteristics into
quality attributes and therefore, indicating which ar-
chitectural patterns meet individually the Big Data re-
quirements.
Table 3: Quality Requirements vs Architectural Patterns.
Characteristics Quality Layered Shared Pipes and
of Big Data Attributes Repository Filters
Systems
Volume, Velocity Scalability - - -
Volume, Velocity Performance - - -
Volume Modularity + - +
Veracity Consistency + -
Veracity Security + + -
Velocity Real-time - - -
Variety, Value Interoperability
Value Availability -
Scalability, performance and real-time operation
are related to the velocity at which data is generated.
The system needs to be scalable to handle this veloc-
ity, as well as processing this data in real time to avoid
bottlenecks and not impact performance. In terms of
the characteristic of volume, the related attributes are
scalability, performance, and modularity. Big Data
systems need to adapt to the high and low volumes
of data that are generated at run-time. In addition,
these data need to be executed with high performance,
and if possible, in different modules, to increase the
modularity and division of responsibilities. Data ve-
racity has aspects of security and consistency. The
data processed must remain consistent throughout the
processing flow, and backups must be guaranteed so
that data can be recovered if the system fails. In ad-
dition, communication between the modules must be
secure to avoid data losses and data alteration during
this process. The variety of data is addressed by inter-
operability requirements, which must ensure that data
provided by different systems and different formats
are processed for value acquisition. Finally, availabil-
ity is related to value acquisition for ensuring that the
generated knowledge and data is available to stake-
holders and to execute desired business processes.
As expected, none of the patterns directly fulfil
all Big Data requirements. This is mostly due to the
fact that each of them was proposed to address a spe-
cific problem. Moreover, Performance, scalability,
and availability are one of the most critical require-
ments for Big Data systems. Performance and real-
time operation are not supported by any of the pat-
terns detailed in this work. This is due to the lack
of evidence in the body of work presented in Table 3
about how software architectures proposed for Big
Data systems address performance, availability, and
real-time requirements. In this perspective, it is of
utmost importance to investigate which architectural
solutions can be integrated with patterns discussed in
this work to successfully address those requirements.
The main disadvantage related to patterns offer-
ing partial solutions, is that architects must prioritize
some requirements more than others (e.g., scalabil-
ity, performance, security), causing adverse effects
between the 5V’s characteristics of Big Data system.
Therefore, it is identified that the union of more than
one of the patterns could add the benefits of each and
then support the design of Big Data software archi-
tectures with more quality. However, such a union
must be investigated carefully, in order to address the
new requirements and guarantee that the crucial re-
quirements are still considered. Moreover, the imple-
mentation of each pattern could be adapted in order to
support different characteristics.
5 CONCLUSION
The Big Data context is promising due to the fact that
data complexity is increasing, and therefore tends to
bring more challenges to software architectures. In
this paper, we investigated the applicability of archi-
tectural patterns, namely, layered, pipes and filters,
and shared repository to the Big Data context using
the ATAM evaluation method. We observed that none
of these patterns can successfully meet the expected
requirements for Big Data since each pattern was con-
ceived to solve a specific problem. Using a specific
DATA 2019 - 8th International Conference on Data Science, Technology and Applications
158

pattern to achieve some requirements, cause trade-
offs between others desired requirements for Big Data
systems. In this context, the integration of patterns to
consolidate a software architecture for those systems
must be carefully investigated. It is required to resort
to the preliminary identification of trade-offs to define
alternatives to mitigate negative impacts imposed by
architectural patterns selected to conform to the soft-
ware architecture of Big Data systems. This work can
be used as a basis for such a trade-off analysis.
As future work, we intend to design Big Data ref-
erence architecture using the combination of these es-
tablished patterns, and if necessary, propose a new
one, aiming at supporting the design and documen-
tation of software architectures for Big Data systems
in healthcare domain.
REFERENCES
Al-Jaroodi, J. and Mohamed, N. (2016). Characteristics and
requirements of big data analytics applications. In 2nd
IEEE International Conference on Collaboration and
Internet Computing, CIC 2016, Pittsburgh, PA, USA,
November 1-3, 2016, pages 426–432.
Ali Babar, M., Zhu, L., and Jeffery, D. R. (2004). A frame-
work for classifying and comparing software architec-
ture evaluation methods. 2004 Australian Software
Engineering Conference. Proceedings., pages 309–
318.
Bass, L., Clements, P., and Kazman, R. (2003). Software
Architecture in Practice. Addison-Wesley Longman
Publishing Co., Inc., Boston, MA, USA, 2 edition.
Buschmann, F., Kevlin, H., and Schmidt, D. C. (2007).
Pattern-oriented software architecture, 4th Edition.
Wiley series in software design patterns. Wiley.
Cecchinel, C., Jimenez, M., Mosser, S., and Riveill, M.
(2014). An architecture to support the collection of
big data in the internet of things. In 2014 IEEE World
Congress on Services, SERVICES 2014, Anchorage,
AK, USA, June 27 - July 2, 2014, pages 442–449.
Chen, H., Kazman, R., Haziyev, S., and Hrytsay, O.
(2015). Big data system development: An embed-
ded case study with a global outsourcing firm. In
1st IEEE/ACM International Workshop on Big Data
Software Engineering, BIGDSE 2015, Florence, Italy,
May 23, 2015, pages 44–50.
Demchenko, Y., Turkmen, F., de Laat, C., Blanchet, C., and
Loomis, C. (2016). Cloud based big data infrastruc-
ture: Architectural components and automated provi-
sioning. In International Conference on High Perfor-
mance Computing & Simulation, HPCS 2016, Inns-
bruck, Austria, July 18-22, 2016, pages 628–636.
Garises, V. and Quenum, J. G. (2018). The road to-
wards big data infrastructure in the health care sec-
tor: The case of namibia. In Proceedings of the 19
th
IEEE Mediterranean Electronical Conference, IEEE
MELECON’18, pages 98–103, Marrakech, Morocco.
IEEE.
Garlan, D. and Shaw, M. (1994). An introduction to soft-
ware architecture. Technical report, Software Engi-
neering Institute, Pittsburgh, PA, USA.
Geerdink, B. (2015). A reference architecture for big data
solutions - introducing a model to perform predictive
analytics using big data technology. IJBDI, 2(4):236–
249.
Gorton, I. and Klein, J. (2015). Distribution, data, deploy-
ment: Software architecture convergence in big data
systems. IEEE Software, 32:78–85.
ISO/IEC (2010). Iso/iec 25010 system and software quality
models. Technical report, ISO.
Kazman, R., Klein, M. H., and Clements, P. C. (2000).
Atam: Method for architecture evaluation. Technical
report, Software Engineering Institute, Pittsburgh, PA,
USA.
Santos, M. Y., e S
´
a, J. O., Costa, C., Galv
˜
ao, J., Andrade, C.,
Martinho, B., Vale Lima, F., and Eduarda, C. (2017).
A big data analytics architecture for industry 4.0. In
Recent Advances in Information Systems and Tech-
nologies - Volume 2 [WorldCIST’17, Porto Santo Is-
land, Madeira, Portugal, April 11-13, 2017]., pages
175–184.
W. Maier, M., Emery, D., and Hilliard, R. (2000). Rec-
ommended Practice for Architectural Description of
Software-Intensive Systems. Technical report, IEEE.
Wang, Y., Kung, L., Wang, W. Y. C., and Cegielski, C. G.
(2018). An integrated big data analytics-enabled
transformation model: Application to health care. In-
formation & Management, 55(1):64–79.
An Evaluation of Big Data Architectures
159
