
Robust Human Activity Recognition based on Deep Metric Learning
Mubarak G. Abdu-Aguye
1
and Walid Gomaa
1,2
1
Computer Science and Engineering Department, Egypt-Japan University of Science and Technology, Alexandria, Egypt
2
Faculty of Engineering, Alexandria University, Egypt
Keywords:
Activity Recognition, Deep Metric Learning, Convolutional Neural Networks.
Abstract:
In the domain of Activity Recognition, the proliferation of low-cost and sensor-enabled personal devices has
led to significant heterogeneity in the data generated by users. Traditional approaches to this problem have
previously relied on handcrafted features and template-matching methods, which have limited flexibility and
performance with high variability. In this work we investigate the use of Deep Metric Learning in the domain
of activity recognition. We use a deep Triplet Network to generate fixed-length descriptors from activity
samples for purposes of classification. We carry out evaluation of our proposed method on five datasets from
different sources with differing activities. We obtain classification accuracies of up to 96% in self-testing
scenarios and up to 91% accuracy in cross-dataset testing without retraining. We also show that our method
performs similarly to traditional Convolutional Neural Networks. The obtained results indicate the promise of
this approach.
1 INTRODUCTION
Activity Recognition is aimed towards determining
the particular action a user is carrying out or the man-
ner in which said action is being performed. This is
primarily done for therapeutic purposes (Liu et al.,
2016), (De et al., 2015) and for other intelligent ap-
plications where such information may be necessary
for some action to be taken, e.g., Smart Homes (Mehr
et al., 2016), (Hoque and Stankovic, 2012), etc.
With the myriad devices carried or worn by users
today, activity data may be easily collected from and
possibly processed on the devices themselves, allow-
ing for pervasive adoption of this domain. At the same
time, this ubiquity gives rise to significant heterogene-
ity in the data generated by users. One source of this
is differences in the properties (e.g device placement,
sampling rates, sensor biases, etc) of the devices used
to collect the data (Banos et al., 2014), (Stisen et al.,
2015). Another significant source of this arises due
to differences in the wearers’ mannerisms while per-
forming such actions (Barshan and Yurtman, 2016).
Such heterogeneity, while expected, is undesirable in
practice. It complicates the problem of activity recog-
nition and must therefore be taken into consideration
when attempting to solve this problem. Therefore,
methods capable of performing well even in the pres-
ence of such heterogeneity are of no small import for
real-world scenarios.
Activity recognition is essentially a classification
problem, and as such necessitates feature extraction.
Manual feature extraction relies on the estimation
of statistical, structural or transient features of the
given data. In general, several types of features may
need to be combined to achieve good performance.
More recently, much emphasis has been placed on
Deep Learning-based methods, as they are capable
of automatic and problem-specific feature extraction,
which ultimately leads to significant improvements
over non-deep methods together with considerably
less manual input. Given the complexity of the activ-
ity recognition problem, deep methods are virtually a
necessity as a result of these desirable properties.
One intuitive way of tackling this heterogeneity is
to embed the activity samples into a semantic space
where samples of the same label are ”close” to each
other as quantified by some metric, and are ”distant”
from samples of different labels by the same metric.
One of the most successful approaches which relies
on this metric/distance approach is Dynamic Time
Warping (DTW) (Sakoe and Chiba, 1978). DTW
has shown good results on many problems (Sempena
et al., 2011), (Singhal and Dubey, 2015), (Cui and
Zhu, 2013). However, it suffers from a number of is-
sues, chief amongst which are its generally high com-
putational requirements and the difficulty in gener-
656
Abdu-Aguye, M. and Gomaa, W.
Robust Human Activity Recognition based on Deep Metric Learning.
DOI: 10.5220/0007916806560663
In Proceedings of the 16th International Conference on Informatics in Control, Automation and Robotics (ICINCO 2019), pages 656-663
ISBN: 978-989-758-380-3
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

alizing to multivariate data, a category under which
most activity recognition data falls. It does not ex-
plicitly attempt to solve the problem of heterogene-
ity and may require complex steps in order to derive
suitable class or group templates for future match-
ing/classification. In addition, it does not yield an in-
termediate representation of the input data which may
be used for any other purpose.
Metric Learning (Xing et al., 2002) aims to learn a
suitable projection of the features of some input data
into some abstract space such that data items in the
same group are similar as quantified by some mathe-
matical distance function, and data items in different
groups are dissimilar by the same function. The re-
formulation permitted through Metric Learning is a
natural and powerful paradigm which offers a num-
ber of benefits. It radically simplifies the classifica-
tion problem within the learned feature space by em-
phasizing separability between classes without rely-
ing on strict cohesion or similarity of intra-class el-
ements. This implicitly allows for heterogeneity be-
tween intra-class samples such as is found in this do-
main. In addition, its potential for generalization can
be expected to be better than regular methods which
become inherently biased/attuned to the training data
in the course of minimizing the classification error.
It also yields an output ”embedding” which is a com-
pact, fixed-length representation of the input data, and
may be used for any purpose as desired.
Traditional metric learning methods e.g (Wein-
berger and Saul, 2009) rely heavily on the solution of
nontrivial convex optimization problems, which are
computationally intensive and assume that the trans-
formation is linear. Subsequent work has extended
metric learning with nonlinear methods (Kedem et al.,
2012), leading to significant improvements in per-
formance due to their inherent flexibility. Most re-
cently, nonlinear metric learning via deep neural net-
works has been explored (Hoffer and Ailon, 2015),
enabling the learning of both suitable features and
corresponding nonlinear mappings for best results.
Some results achieved through this method (Huang
et al., 2012), (Hu et al., 2014) indicate that such Deep
Metric Learning shows immense potential in other
different scenarios.
In this vein, we explore the application of deep
metric learning to the domain of activity recogni-
tion. We consider five diverse and publicly-available
datasets of different sizes collected from different de-
vices with different characteristics i.e device place-
ment, sampling rate, etc. This is done in order to ex-
amine the robustness of this approach in the presence
of device and data heterogeneity which is a reality in
practical scenarios. We show that deep metric learn-
ing provides good classification accuracy and general-
ization ability out of the box (i.e without any retrain-
ing). The following sections introduce deep metric
learning and Triplet Networks and our experimental
methodology.
2 RELATED WORK
In this section we briefly discuss similar work that has
been done in this domain. In (Li et al., 2018), the
authors evaluate both traditional and deep methods
in activity recognition. They consider CNN, LSTM
and CNN+LSTM architectures and perform evalua-
tions on two publically-available datasets. They find
that deep architectures significantly outperform tradi-
tional approaches by a significant margin. In (Zeng
et al., 2014) the authors adopt a convolutional neu-
ral network to perform activity recognition using ac-
celerometer signals only. They consider three pub-
lic datasets. Their method was found to outperform
traditional methods. Similar findings were obtained
in (Ha et al., 2015) where the authors used convo-
lutional neural networks in a multimodal approach.
Their method was found to be comparable to state of
the art methods.
In (Margarito et al., 2016) the authors consider a
template-matching approach to sports activity recog-
nition based on accelerometer data. Several dis-
tance measures, including Euclidean and DTW dis-
tance were used, as well as different classification
methods. Their proposed matching index was found
to give the best results, suggesting that general pur-
pose distance measures may not be well suited to all
problems. Another approach is taken in (Seto et al.,
2015) where the authors use multivariate DTW for
template-matching in activity recognition for real and
simulated datasets. They report results comparable
to those obtained with traditional feature extraction
methods. However, their method is highly susceptible
to the manner in which the templates are constructed,
showing significant variance in performance based on
different approaches.
In (Che et al., 2017) the authors propose a method
for metric learning for multivariate time series. They
formulate an optimized method for aligning two mul-
tivariate time series inputs based on the average best
warping length. Subsequently they utilize a 2-layer
neural network to perform metric learning using the
largest margin approach (Weinberger and Saul, 2009)
to minimize the distance between the aligned series.
In comparison with other methods such as multivari-
ate DTW, their proposed method reportedly provides
best-in-class performance. However, their method re-
Robust Human Activity Recognition based on Deep Metric Learning
657

lies on DTW distance during its training phase, and
computes the learned distance over every timestep of
the aligned series, both of which generally add non-
trivial computational overhead to their method.
In this work we apply deep metric learning specif-
ically to activity recognition data. Our method, in
contrast to (Seto et al., 2015) does not rely on the
derivation of any templates and avoids the computa-
tional overhead of DTW-based approaches. In con-
trast to (Che et al., 2017), our proposed method does
not rely on pre-alignment of the training data. Addi-
tionally, our method yields an output representation
upon which the similarity may be directly computed
for any desired purposes. This saves the computa-
tional requirement of per-timestep similarity compu-
tation. Finally, we use convolutional filters for fea-
ture extraction and train our network as a single unit,
allowing for end-to-end optimization of the metric
learning objective.
3 THEORETICAL BACKGROUND
3.1 Metric Learning
Metric learning as a concept relies very heavily on the
notion of similarity between pairs of entities. From a
human point of view, this similarity is implicitly de-
fined in terms of the closeness of sensory inputs in-
duced by two observed phenomena. In more concrete
terms, we will introduce the concept of a distance
function or metric, which numerically quantifies the
distance/dissimilarity between two elements of some
set. To be admissible as a metric, a function must ful-
fill certain axioms. Considering the metric as a map-
ping D over two members - G
1
and G
2
- of a set, then
we have that D: G
1
× G
2
−→ R
+
for every x
i
, x
j
, x
k
which exist in some set. We may express the axioms
as:
1. Non-negativity: D(x
i
, x
j
) ≥ 0
2. Identity: D(x
i
, x
i
) = 0
3. Symmetry: D(x
i
, x
j
) = D(x
j
, x
i
)
4. Triangle Inequality: D(x
i
, x
k
) ≤ D(x
i
, x
j
) +
D(x
j
, x
k
)
In this work we consider the Mahalanobis Dis-
tance Function(Mahalanobis, 1936), which takes the
following form:
D =
q
(x
i
− x
j
)
T
M(x
i
− x
j
) (1)
This function is parameterized by M, which is a
positive semidefinite matrix and permits the function
fulfill the fourth condition described above. There-
fore, depending on M, the computed distance may be
considered to be obtained in a space whose projec-
tion is defined by M. It is noteworthy at this point
to state that Euclidean distance is a special case of
Mahalanobis distance when M is the identity matrix.
Without a loss of generality however, we may con-
sider an alternate form of the preceding function by
incorporating a function F(.), which performs some
transformation on the input space. We then obtain the
following:
D
L
=
q
(F(x
i
) − F(x
j
))
T
)(F(x
i
) − F(x
j
)) (2)
We can consider the transformation by the M ma-
trix from before to be a special case of the above
where F(.) is a linear function (since matrix multipli-
cation is equivalent to the application of some linear
function to a given input vector). The metric learning
problem as defined by (Weinberger and Saul, 2009)
can then be considered to be the learning of a suitable
function F(.) such that, given an element x
i
and two
others x
j
and x
k
such that x
i
, x
j
∈ A, x
k
∈ B (where A
and B are two different classes/groups) then:
D
L
(x
i
, x
j
) < D
L
(x
i
, x
k
) (3)
It can also be seen from this new form that such
a formulation imposes this condition in Euclidean
space, as there is no longer a need for a separate pro-
jection matrix M explicitly. The element x
i
is called
the anchor, while x
j
and x
k
are called the positive and
the negative respectively. In this vein, it can be seen
that such a transformation would lead to a feature
space where similar classes occupy the same region
and are distinct from entities from differing classes.
This implies that the decision surface becomes much
simpler to intuit as the constraint defined in (3) im-
plicitly emphasizes discriminability between classes.
In deep metric learning, a type of deep neural network
is used to find a suitable approximation for F(.). The
details by which this is achieved are discussed in the
proceeding subsection.
3.2 Triplet Networks
Triplet networks were first introduced in (Hoffer and
Ailon, 2015) with particular application to deep met-
ric learning. In practice, the distinctive feature of
such a network is not in its structure but the man-
ner by which it is trained and type of loss function
which is used in its optimization. Since they are de-
signed specifically for deep metric learning, a Triplet
Loss (Schroff et al., 2015) function is used which
aims to learn a nonlinear mapping from the input fea-
tures to the network output (which is a fixed-size vec-
tor called an embedding) that enforces the constraints
ICINCO 2019 - 16th International Conference on Informatics in Control, Automation and Robotics
658
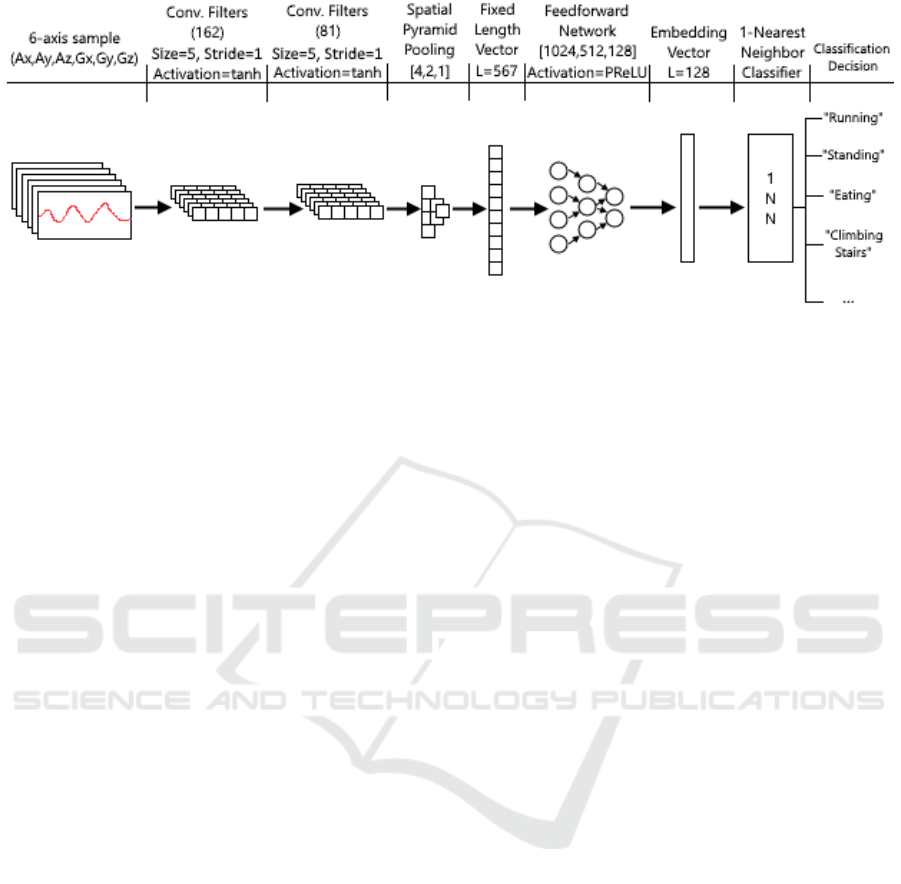
Figure 1: Structure of Proposed Method.
as described in (3). After training, the embeddings
correspondingly generated from the network inputs
are similar for data from the same class and dissim-
ilar for data from different classes, using Euclidean
distance as the metric.
During the training of this sort of network, an an-
chor is randomly selected, together with a positive
and a negative. A single tuple consisting of these
three inputs is called a triplet. The manner in which
the triplets are selected influences the eventual per-
formance of the network, and must be carefully taken
into account for best results. For further information
regarding triplet selection strategies the reader is re-
ferred to (Hermans et al., 2017). In mathematical
terms, triplet loss is defined as follows:
L
t
= argmin
∑
max(||E
a
−E
p
||
2
2
−||E
a
−E
n
||
2
2
+α, 0)
(4)
Where E
a
represents the embedding of the anchor
sample, E
p
represents the embedding of the positive
and E
n
represents the anchor of the negative (where
anchor, positive and negative retain their meanings as
described in the previous section) and the summation
of the loss is taken over all the triplets in the training
set. α represents a margin parameter that describes
the minimum desired spacing between entities of dif-
fering classes. This can be seen to be tailored achiev-
ing the objective set forth in (3).
Therefore, once suitable triplets are selected, each
triplet is passed through the network to obtain its con-
stituent embeddings. The loss is then computed as
defined by (4) and is subsequently backpropagated
through the network using standard methods.
4 PROPOSED METHODOLOGY
In this section we describe the details of our pro-
posed method. We construct a triplet network con-
sisting of two convolutional layers and three feedfor-
ward layers. We include the convolutional layers and
train the network as a whole in order to achieve op-
timized feature extraction and transformation in an
end-to-end way. As the network inputs do not have
the same length, we include a 1-D Spatial Pyramid
Pooling layer (He et al., 2014) between the convolu-
tional and the feedforward layers. This layer converts
the varying-length outputs from the convolutional lay-
ers into fixed length vectors which are required by
the feedforward layers. Batch Normalization is used
in between successive feedforward layers as it was
found to speed up training convergence significantly.
The network structure is shown in Figure 1.
The network is trained using the triplet loss func-
tion as described previously, fixing the α (i.e margin)
parameter at 1. In this work Random Negative Triplet
Selection (Hermans et al., 2017) was used as the
triplet selection strategy as it was found to achieve the
best results relative to the other methods. Stochastic
Gradient Descent with a Nesterov Momentum value
of 0.90 was used as the optimizer as it was found to
give the best performance in our evaluations.
During testing, a sample is passed through the net-
work, yielding a 128-feature embedding which is can
then be considered to be its representative feature vec-
tor/encoding. This embedding vector can then be used
as a feature vector for classification or other purposes.
Robust Human Activity Recognition based on Deep Metric Learning
659

Table 1: Summary of Datasets Considered.
Name Samples Activities
Gomaa-1 603 14
HAPT 1214 12
Daily Sports 9120 19
HAD-AW 4344 32
REALDISP 1397 33
5 EXPERIMENTAL SETUP
In this section we describe the experimental setup
and methodology which was used to investigate this
method. A brief description of the datasets consid-
ered is provided as follows.
5.1 Datasets Considered
We considered five datasets collected from different
sources with different activity sets. This was done
with a view to evaluating our proposed techniques in
terms of its flexibility and adaptability. The details of
the datasets considered as summarized in Table 1.
The Gomaa-1 dataset (Gomaa et al., 2017) con-
sists of 603 samples spread over 14 different activi-
ties. The dataset was collected from an Apple Smart-
Watch at a sampling rate of 50Hz. The data was
collected from three volunteers wearing the Smart-
watch on their right hands. The dataset consists of
accelerometer, gyroscope, magnetometer and rotary
(i.e roll, pitch and yaw) readings.
The HAPT dataset (Reyes-Ortiz et al., 2016) con-
sists of 1214 samples spread over 12 activities: 6
static activities and 6 postural transitions. It was
collected from waist-worn Android smartphones at
a sample rate of 50Hz. The samples were collected
from 30 volunteers and include only accelerometer
and gyroscope readings.
The Daily and Sports Activities dataset (Altun
et al., 2010) consists of 9120 samples spread over
a mixture of 19 daily and sports activities. It was
collected using Xsens IMU units at a sample rate of
25Hz. The samples were collected from 8 volunteers
and consist of accelerometer, gyroscope and magne-
tometer readings.
The HAD-AW dataset (Ashry et al., 2018) con-
sists of 4344 samples spread over a diverse set of 31
activities. It was collected using an Apple Smart-
Watch at a sample rate of 50Hz. The samples were
collected from 16 volunteers and are composed of
accelerometer, gyroscope, magnetometer and rotary
readings.
The REALDISP dataset (Ba
˜
nos et al., 2012) con-
sists of 4000+ samples distributed over 33 activities.
It was collected using Xsens IMU units at a sam-
pling rate of 50Hz, and consists of accelerometer,
gyroscope and magnetometer data as well as orien-
tation quaternions. The data was collected from 17
subjects in three different device-placement scenar-
ios. We consider data from all the available scenar-
ios and ignore all samples with indeterminate labels.
After preprocessing 1397 samples were found to be
usable.
Due to the varying sensor modalities available
from these datasets, we use only the accelerometer
and gyroscope data, yielding a total of six axes from
each dataset. This is because the accelerometer and
gyroscope are common across all the datasets and
therefore models constructed from such data can eas-
ily be applied across datasets.
5.2 Experimental Evaluations
In order to illustrate the efficacy of our proposed
method, we carry out a number of experiments on the
datasets described previously in order to determine
the classification accuracy obtainable from the em-
beddings generated by our method. We adopt 1-NN
classification due to its simplicity and its applicability
to similarity-based applications such as metric learn-
ing. In addition, it is the most popular benchmark
used in evaluating similarity-based techniques (Ding
et al., 2008). The PyTorch library (Paszke et al., 2017)
was used for the practical implementation of all the
experiments.
We construct and train a triplet network as de-
scribed in Section 4. 75% of the considered datasets
were used for training. After training, the embeddings
of the training samples are used as exemplars for a
1-Nearest Neighbor classifier. This classifier is then
used to obtain the classification accuracy on the em-
beddings of the remaining unseen 25% of the dataset.
We also perform cross-testing experiments to de-
termine the generalizability of our proposed method.
In this case the triplet network is trained on one of
the described datasets as before. Without any retrain-
ing, we use the pretrained network to generate embed-
dings from the other (cross-testing) datasets. 65% of
the embeddings are used as exemplars for a 1-Nearest
Neighbor classifier while the classification accuracy
is evaluated on the remaining 35% of the embeddings.
In both cases, the evaluations are each repeated 15
times i.e the network is trained and tested on different
data for 15 cycles. The mean and standard deviation
of the accuracies obtained from each cycle are then
computed. In order to provide a sense of the efficacy
of our method compared to traditional methods, we
construct a Convolutional Neural Network using an
ICINCO 2019 - 16th International Conference on Informatics in Control, Automation and Robotics
660

identical structure to our triplet network. However,
we omit the 1-NN classifier and replace the last layer
with a layer with K neurons, where K is the number
of classes in the dataset being evaluated. This way the
CNN produces a classification decision directly. We
then train the CNN in a similar way i.e using 75% of
the dataset considered for training and the remaining
25% for testing. The CNN is trained using the Adam
optimizer and Cross Entropy as the loss function. The
training and testing cycles of the CNN are also re-
peated 15 times and the mean and standard deviation
recorded.The results obtained from these evaluations
and their discussion are provided in the following sec-
tion.
6 RESULTS AND DISCUSSION
In this section we present the results from the ex-
perimental evaluations as described previously. The
results are given in Table 2 and are all reported as
percentages. The accuracies are shown together with
their standard deviations to give a sense of the stabil-
ity of the obtained results.
Accuracies obtained from training on some
dataset and testing on the same dataset are shown in
grey in the table. As can be observed, our proposed
method gives good performance on all five consid-
ered datasets, regardless of the data size or number
of classes available. The standard deviation of the
figures also indicate that our proposed method gives
consistently stable results, even with the use of a sim-
ple 1-NN classifier. This underlines the potential of
this metric learning approach in this domain.
In terms of the system’s cross-testing perfor-
mance, we see that good results can be obtained with
our proposed method for datasets with a moderate
number of classes. This is reflected in the cross-
testing results for the Gomaa-1, HAPT and Sports
dataset, where our proposed method yields a classi-
fication accuracy averagely around 85% without any
retraining at all, even though these three datasets are
collected from different devices in different scenar-
ios. A decline in performance is observed when cross-
testing on datasets with significantly more classes
than seen during training, as reflected in the results
of cross-testing on the HAD-AW dataset (32 classes)
and the REALDISP dataset (33 classes). However,
it can be observed that when training is carried out
on these datasets with many classes, the cross-testing
performance is generally good, though their perfor-
mances on each other show significant degradation.
The performance degradation in the former case
can likely be attributed to the fact that when this
method is trained on datasets with a moderate num-
ber of classes, its discriminatory ability is limited to
some degree. In this situation, testing on datasets
with many more classes would pose a significant
challenge as the model is not powerful/discriminative
enough. However, when it is trained on a dataset with
many classes, its discriminatory ability is much better
and therefore its cross-testing performance on smaller
datasets is expectedly better. This can be observed
from the results. When training on and testing on
datasets with large number of classes (i.e training on
HAD-AW, testing on REALDISP and vice-versa) de-
graded performance is also observed. This is likely
because of the severe difference in the types of activ-
ities that constitute these datasets. In spite of this, it
can be observed that the cross-performance of these
two datasets on each other still exceeds the cross-
testing performance obtained when training on the
less-diverse datasets. As such the benefit on train-
ing on datasets with many classes is clearly illus-
trated. However, from the results obtained in the
cross-testing scenarios, it can generally be surmised
that the proposed method shows the system’s robust-
ness.
Table 3 also shows the performance of an
identically-structured CNN on the same datasets. It
can generally be seen that our method provides re-
sults comparable to the CNN in general. Additionally,
the CNN cannot be used for cross-testing purposes
without network redesign and retraining. This further
helps to underline the efficacy, competitiveness and
wide applicability of our method.
7 CONCLUSION
In this work we introduce the use of Triplet Net-
works in the domain of human activity recogni-
tion. Accelerometer and gyroscope data from dif-
ferent datasets were used to train a triplet network,
which was subsequently used to generate fixed-size
vectors (embeddings) from the varying-length multi-
variate samples. A 1-Nearest Neighbor classifier was
then used to evaluate the classification performance
using the generated embeddings as feature vectors.
Additionally, cross-testing was carried out whereby
the network was trained on some dataset and used to
generate embeddings from the other datasets without
any retraining being carried out.
Our proposed method was found to yield classifi-
cation accuracies of up to 96% in the self-testing (i.e
training and testing on same dataset) scenarios. In
the cross-testing scenarios, our method showed good
performance (up to 91% accuracy) on datasets with
Robust Human Activity Recognition based on Deep Metric Learning
661
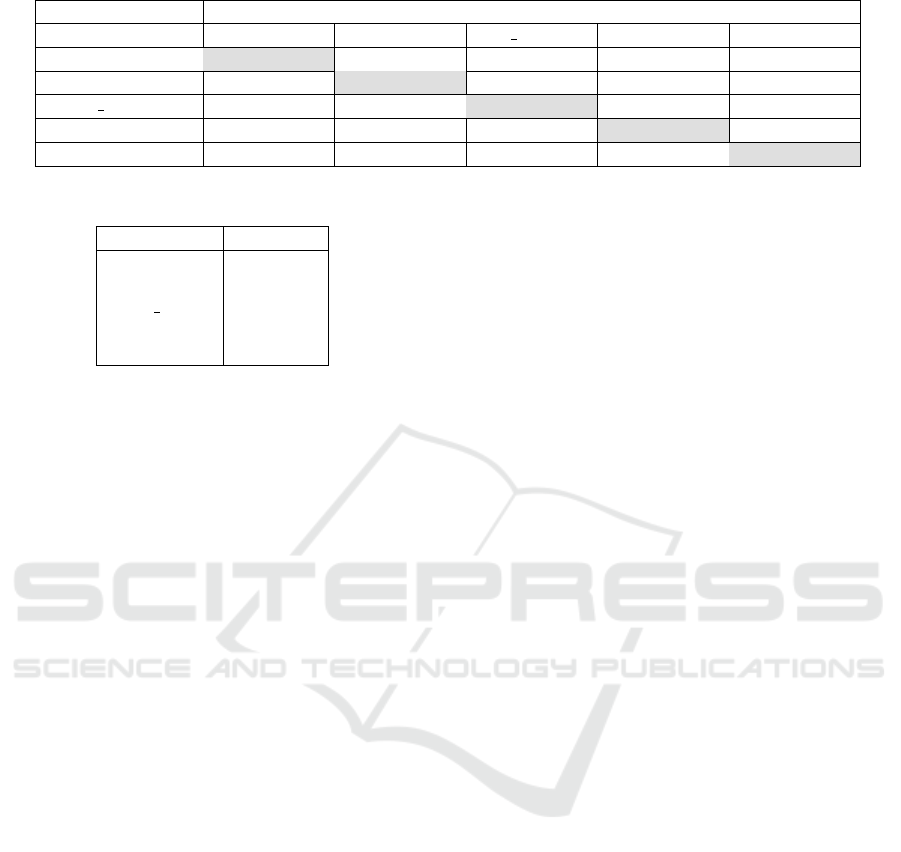
Table 2: Classification Accuracy of Embeddings generated by Proposed Method.
Training Dataset Testing Dataset
Gomaa-1 HAPT D Sports HAD-AW REALDISP
Gomaa-1 96.69 ± 1.23 89.60 ± 1.72 91.34 ± 0.41 68.67 ± 1.09 59.48 ± 2.77
HAPT 83.27 ± 2.16 96.25 ± 1.09 89.98 ± 0.74 64.46 ± 1.46 50.61 ± 2.19
D Sports 86.16 ± 2.69 88.67 ± 1.17 96.59 ± 0.39 68.62 ± 1.14 56.59 ± 2.27
HAD-AW 90.75 ± 1.42 89.10 ± 1.41 91.35 ± 0.56 85.28 ± 1.19 60.60 ± 2.00
REALDISP 91.16 ± 2.14 91.40 ± 1.38 91.63 ± 0.47 70.10 ± 1.65 75.01 ± 1.92
Table 3: Classification Accuracy using CNN.
Dataset Accuracy
Gomaa-1 96.99%
HAPT 96.00%
Daily Sports 95.31%
HAD-AW 88.36%
REALDISP 76.60%
a small to moderate number of classes even with-
out retraining. When trained on datasets with many
classes, the method shows the best performance on
both types of datasets (i.e moderate classes and many
classes), indicating the improved discriminative abil-
ity imparted by training on such type of datasets. In
both self- and cross-test scenarios, the standard de-
viations are below 3% for all datasets. These results
underscore the robustness of the proposed method.
In the future we intend to investigate the effects
of the embedding size on the classification accuracy
obtained, as well as evaluate the topological proper-
ties of the embeddings with a view to dimensional-
ity reduction. We also intend to consider network
optimization (i.e finding the best deep network ar-
chitecture and performing hyperparameter tuning for
the network and loss function) as we believe that
a carefully-designed network may yield further per-
formance gains. Additionally, we intend to explore
the efficacy of fine-tuning of pretrained triplet net-
works. This follows from the cross-testing perfor-
mance observed thus far, which suggests that addi-
tional dataset-specific training may yield better cross-
testing performance.
REFERENCES
Altun, K., Barshan, B., and Tunc¸el, O. (2010). Compara-
tive study on classifying human activities with minia-
ture inertial and magnetic sensors. Pattern Recogn.,
43(10):3605–3620.
Ashry, S., Elbasiony, R., and Gomaa, W. (2018). An lstm-
based descriptor for human activities recognition us-
ing imu sensors. In Proceedings of the 15th Interna-
tional Conference on Informatics in Control, Automa-
tion and Robotics - Volume 1: ICINCO,, pages 494–
501. INSTICC, SciTePress.
Ba
˜
nos, O., Damas, M., Pomares, H., Rojas, I., T
´
oth, M. A.,
and Amft, O. (2012). A benchmark dataset to eval-
uate sensor displacement in activity recognition. In
Proceedings of the 2012 ACM Conference on Ubiq-
uitous Computing, UbiComp ’12, pages 1026–1035,
New York, NY, USA. ACM.
Banos, O., Toth, M. A., Damas, M., Pomares, H., and Ro-
jas, I. (2014). Dealing with the effects of sensor dis-
placement in wearable activity recognition. Sensors,
14(6):9995–10023.
Barshan, B. and Yurtman, A. (2016). Investigating inter-
subject and inter-activity variations in activity recog-
nition using wearable motion sensors. The Computer
Journal, 59(9):1345–1362.
Che, Z., He, X., Xu, K., and Liu, Y. (2017). Decade: a
deep metric learning model for multivariate time se-
ries. In KDD workshop on mining and learning from
time series.
Cui, H. and Zhu, M. (2013). A novel multi-metric scheme
using dynamic time warping for similarity video clip
search. In 2013 IEEE International Conference on
Signal Processing, Communication and Computing
(ICSPCC 2013), pages 1–5.
De, D., Bharti, P., Das, S. K., and Chellappan, S. (2015).
Multimodal wearable sensing for fine-grained activity
recognition in healthcare. IEEE Internet Computing,
19(5):26–35.
Ding, H., Trajcevski, G., Scheuermann, P., Wang, X., and
Keogh, E. (2008). Querying and mining of time series
data: Experimental comparison of representations and
distance measures. Proc. VLDB Endow., 1(2):1542–
1552.
Gomaa, W., Elbasiony, R., and Ashry, S. (2017). Adl clas-
sification based on autocorrelation function of inertial
signals. In 2017 16th IEEE International Conference
on Machine Learning and Applications (ICMLA),
pages 833–837.
Ha, S., Yun, J., and Choi, S. (2015). Multi-modal con-
volutional neural networks for activity recognition.
In 2015 IEEE International Conference on Systems,
Man, and Cybernetics, pages 3017–3022.
He, K., Zhang, X., Ren, S., and Sun, J. (2014). Spatial
pyramid pooling in deep convolutional networks for
visual recognition. In Fleet, D., Pajdla, T., Schiele, B.,
and Tuytelaars, T., editors, Computer Vision – ECCV
2014, pages 346–361, Cham. Springer International
Publishing.
ICINCO 2019 - 16th International Conference on Informatics in Control, Automation and Robotics
662

Hermans, A., Beyer, L., and Leibe, B. (2017). In defense
of the triplet loss for person re-identification. CoRR,
abs/1703.07737.
Hoffer, E. and Ailon, N. (2015). Deep metric learning
using triplet network. In International Workshop on
Similarity-Based Pattern Recognition, pages 84–92.
Springer.
Hoque, E. and Stankovic, J. (2012). Aalo: Activity recog-
nition in smart homes using active learning in the
presence of overlapped activities. In 2012 6th Inter-
national Conference on Pervasive Computing Tech-
nologies for Healthcare (PervasiveHealth) and Work-
shops, pages 139–146.
Hu, J., Lu, J., and Tan, Y. (2014). Discriminative deep
metric learning for face verification in the wild. In
2014 IEEE Conference on Computer Vision and Pat-
tern Recognition, pages 1875–1882.
Huang, C., Zhu, S., and Yu, K. (2012). Large scale
strongly supervised ensemble metric learning, with
applications to face verification and retrieval. CoRR,
abs/1212.6094.
Kedem, D., Tyree, S., Sha, F., Lanckriet, G. R., and Wein-
berger, K. Q. (2012). Non-linear metric learning. In
Advances in Neural Information Processing Systems,
pages 2573–2581.
Li, F., Shirahama, K., Nisar, M. A., K
¨
oping, L., and Grze-
gorzek, M. (2018). Comparison of feature learning
methods for human activity recognition using wear-
able sensors. Sensors, 18(2).
Liu, X., Liu, L., Simske, S. J., and Liu, J. (2016). Human
daily activity recognition for healthcare using wear-
able and visual sensing data. In 2016 IEEE Interna-
tional Conference on Healthcare Informatics (ICHI),
pages 24–31.
Mahalanobis, P. C. (1936). On the generalised distance in
statistics. In Proceedings National Institute of Sci-
ence, India, volume 2, pages 49–55.
Margarito, J., Helaoui, R., Bianchi, A. M., Sartor, F.,
and Bonomi, A. G. (2016). User-independent
recognition of sports activities from a single wrist-
worn accelerometer: A template-matching-based ap-
proach. IEEE Transactions on Biomedical Engineer-
ing, 63(4):788–796.
Mehr, H. D., Polat, H., and Cetin, A. (2016). Resident ac-
tivity recognition in smart homes by using artificial
neural networks. In 2016 4th International Istanbul
Smart Grid Congress and Fair (ICSG), pages 1–5.
Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E.,
DeVito, Z., Lin, Z., Desmaison, A., Antiga, L., and
Lerer, A. (2017). Automatic differentiation in pytorch.
In NIPS-W.
Reyes-Ortiz, J.-L., Oneto, L., Sam
`
a, A., Parra, X., and
Anguita, D. (2016). Transition-aware human activ-
ity recognition using smartphones. Neurocomput.,
171(C):754–767.
Sakoe, H. and Chiba, S. (1978). Dynamic programming
algorithm optimization for spoken word recognition.
IEEE Transactions on Acoustics, Speech, and Signal
Processing, 26(1):43–49.
Schroff, F., Kalenichenko, D., and Philbin, J. (2015).
Facenet: A unified embedding for face recognition
and clustering. CoRR, abs/1503.03832.
Sempena, S., Maulidevi, N. U., and Aryan, P. R. (2011).
Human action recognition using dynamic time warp-
ing. In Proceedings of the 2011 International Con-
ference on Electrical Engineering and Informatics,
pages 1–5.
Seto, S., Zhang, W., and Zhou, Y. (2015). Multivariate
time series classification using dynamic time warping
template selection for human activity recognition. In
2015 IEEE Symposium Series on Computational In-
telligence, pages 1399–1406.
Singhal, S. and Dubey, R. K. (2015). Automatic speech
recognition for connected words using dtw/hmm for
english/ hindi languages. In 2015 Communication,
Control and Intelligent Systems (CCIS), pages 199–
203.
Stisen, A., Blunck, H., Bhattacharya, S., Prentow, T. S.,
Kjærgaard, M. B., Dey, A., Sonne, T., and Jensen,
M. M. (2015). Smart devices are different: Assess-
ing and mitigatingmobile sensing heterogeneities for
activity recognition. In Proceedings of the 13th ACM
Conference on Embedded Networked Sensor Systems,
SenSys ’15, pages 127–140, New York, NY, USA.
ACM.
Weinberger, K. Q. and Saul, L. K. (2009). Distance met-
ric learning for large margin nearest neighbor clas-
sification. Journal of Machine Learning Research,
10(Feb):207–244.
Xing, E. P., Ng, A. Y., Jordan, M. I., and Russell, S. (2002).
Distance metric learning, with application to clus-
tering with side-information. In Proceedings of the
15th International Conference on Neural Information
Processing Systems, NIPS’02, pages 521–528, Cam-
bridge, MA, USA. MIT Press.
Zeng, M., Nguyen, L. T., Yu, B., Mengshoel, O. J., Zhu,
J., Wu, P., and Zhang, J. (2014). Convolutional neural
networks for human activity recognition using mobile
sensors. In 6th International Conference on Mobile
Computing, Applications and Services, pages 197–
205.
Robust Human Activity Recognition based on Deep Metric Learning
663
