
A Methodological Framework for Dictionary and Rule-based Text
Classification
Jennifer Abel and Birger Lantow
a
Institute of Computer Science, University of Rostock, Albert-Einstein-Str. 22, 18059 Rostock, Germany
Keywords: Dictionary-based, Rule-based, Method Engineering, Text Classification.
Abstract: Recent research on dictionary- and rule-based text classification either concentrates on improving the
classification quality for standard tasks like sentiment mining or describe applications to a specific domain.
The focus is mainly on the underlying algorithmic approach. This work in contrast provides a general
methodological approach to dictionary- and rule-based text classification based on a systematic literature
analysis. The result is a process description that enables the application of these technologies on specific
problems by guidance through major decision points from the definition of the classification goals to the
actual classification of texts.
1 INTRODUCTION
Communication via social media and online
platforms is steadily rising (Mandal and Gupta 2016).
Social networks are a rich source of information,
based on opinions freely shared by individuals on
specific topics (Walha et al., 2015). The proportion of
spoken communication is reduced and is increasingly
being replaced by writing in text form. For example,
the current user numbers of social media are 2.14
billion people with a rising tendency (eMarketer
2016). As early as 2011, a survey (DHL 2017)
confirmed the inclusion of product reviews in
purchase decisions. 64% of customers said that their
purchase decisions were influenced by reviews and
advice from other customers. The increasing
popularity of the Internet and social media highlights
the need for computer-aided linguistic analysis (Stede
2016).
In companies, this information can be used to
identify product enhancements or to fill Product
Recommender systems. Similarly, social media
provides companies with a good platform to connect
with and place advertisements for their customers
(Kharde and Sonawane 2016). In order to filter out
the relevant content, approaches to text classification
such as sentiment mining have been developed
Although the literature deals with different
approaches to text classification, it does not offer a
a
https://orcid.org/0000-0003-0800-7939
uniform reference model or a standardized procedure
that support their application. The existing
approaches often describe individual cases based on
text corpora, which were specifically created for the
respective domain. Such resources are difficult to
translate to other domains because words in different
domains and languages have different meanings.
Additionally, there are also domain specific terms
that are not covered by standard vocabularies. Thus,
there is a need to create new dictionaries and rules for
text classification unless machine learning
approaches can be applied. However, the latter rely
on large annotated datasets for training.
This work aims at providing guidance for the
application of dictionary- and rule-based text
classification approaches. For this purpose, a
systematic literature analysis has been performed
which is described in Section 2. The goal of this
literature analysis was to identify activities that are
described for the implementation of the various
presented approaches as well as decisions that have
been made with regard to implementation
alternatives. Based on the found commonalities, a
general process for dictionary- and rule based text
classification has been developed. This process is
roughly sketched in Section 3. The concluding
section 4 provides an overview of the current status
of the developed methodological support based on
this process and possible future directions.
330
Abel, J. and Lantow, B.
A Methodological Framework for Dictionary and Rule-based Text Classification.
DOI: 10.5220/0008121503300337
In Proceedings of the 11th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2019), pages 330-337
ISBN: 978-989-758-382-7
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

2 LITERATURE ANALYSIS
This section documents the conducted systematic
literature analysis. It is based on the work of
Kitchenham (Kitchenham 2014). There, the selection
of studies in connection with a quality control is
suggested. The selection process has been performed
by means of the snowballing method according to
Wohlin (Wohlin 2014). Section 2.1 describes the
proposed steps of a literature analysis while Section
2.2 describes the search process and its outcomes in
detail. The following Section 2.3 provides an analysis
of the found sources with respect to implementation
decisions such as the application context and used
text classification approaches.
2.1 Snowballing
Wohlin recommends to use Google Scholar
2
for the
implementation of snowballing. Google Scholar has
widest coverage of scientific literature among
available search platforms (Alexander 2016). This
avoids the use of biased or subjective research or
databases. The advantage of snowballing is that the
use of reference lists and citations reduces the noise
of non-relevant articles compared to a term based
database search as it is suggested by other approaches
to systematic literature analysis.
Snowballing initially needs a start set of good
quality, relevant publications. The start set should not
be too small and if possible cover different clusters,
research areas, years and authors in order to bring in
a variety of perspectives (Wohlin 2014).
Before starting the snowballing process, inclusion
and exclusion criteria have to be defined in order to
ensure a consistent selection of literature sources.
After the identification of the start set, two phases are
distinguished during actual snowballing. These are
the backward and the forward snowballing.
Backward snowballing uses the reference list of
an already selected publication to identify further
relevant publications. Forward snowballing identifies
new papers by examining which publications have
cited the research paper at hand. In both steps, the
selection of candidate publications for the inclusion
in the resulting set of the literature analysis is based
on author and title first. Then the abstracts are
screened. The final decision about inclusion or
exclusion should be based on full-text. The next
iteration is based on the newly included publications.
The search process ends when no new publications
are included in an iteration step. (Wohlin 2014)
2
scholar.google.com
2.2 Literature Selection Process
Criteria for inclusion or exclusion of publications into
the analysis process have been based on publication
time (from 2008), publication process (scientific
review process mandatory), and content. Publications
whose content did not contribute to the goals of this
work have been excluded. The start set has been
found based on a search on Google Scholar querying
for dictionary, rule, and lexicon each in combination
with “text classification”. 25 publi-cations have been
selected for the start set out of the 703 search results.
Table 1 shows the progress of the snowballing
iterations that followed.
Table 1: Snowballing Iterations.
Iteration
# Forward
# Backward
# Included
-
-
-
25
1
2652
1066
10
2
245
231
4
2897
1297
39
The first iteration resulted in 10 publications that
have been added to the analysis set. The second
iteration based on this 10 publication lead to 4
additions. A third iteration did not provide further
relevant publications. Thus, the final set for literature
analysis contains 39 publications. The following
discussion is based on them.
2.3 Data Extraction
This section describes the findings with regard to the
used text classification approaches and usage
contexts.
2.3.1 Classification Approaches
As shown in Figure 1, most of the found approaches
are dictionary-based. There are also approaches that
combine a rule-based classification with a dictionary.
Two publications (Afzaal and Usman 2015, Lee et al.,
2011) concentrate on text and document frequencies
in a text corpus for text classification. However, they
start with an initial dictionary. One publication
(Appel et al., 2015) provides a comparison of
different approaches including machine learning.
Thus, it is separated.
A Methodological Framework for Dictionary and Rule-based Text Classification
331
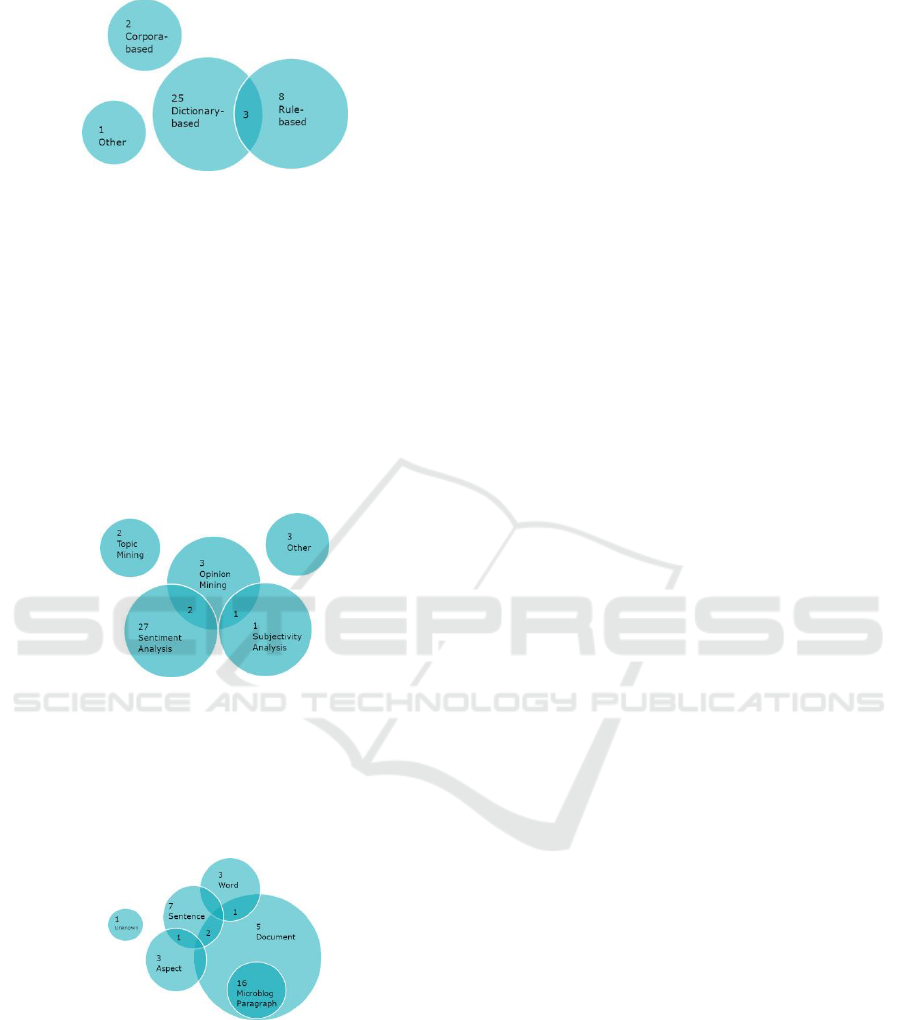
Figure 1: Approaches from Literature.
2.3.2 Application Area
Figure 2 gives an overview of the areas of application
that are the subject of research. In addition to the main
research areas of sentiment analysis, opinion mining
and subjectivity analysis, there are two papers
addressing topic mining. The remaining three
publications deal with named entity recognition
(Yerva et al., 2012), side effects of medication
(Nikfarjam and Gonzalez 2011) or just generally
describe text classification without a specific
application (Darwish et al., 2015).
Figure 2: Applications from Literature.
2.3.3 Level of Analysis
There are several possibilities at which level a text
analysis could be carried out. Figure 3 shows which
levels are addressed by the found publications.
Figure 3: Level of Analysis.
2.3.4 Data Sources
Another important factor in text classification is the
quality of the used sources. Microblogging services
like Twitter do only provide small pieces of text,
using special idioms and sometimes not containing
sentences at all. For example, the latter does not allow
an analysis at sentence level. Looking at the literature
found, Twitter is the most prominent data source (16
publications), followed by web site content (12
publications). 9 publications use special research data
sets for text analysis.
With regard to the language of the used sources
English has a clear majority (24 publications),
followed by Spanish (3 publications). Other language
do not have more than 2 occurrences.
3 PROCESS CONSTRUCTION
As shown in the first data extraction from literature
analysis (cf. Section 2.3), there are several variance
or decision points when implementing a dictionary-
or rule-based text classification. Different
applications and different text sources require
different approaches. The goal of this work was to
investigate the possibility of a methodological
support for the application of text analysis. In addition
to the previous analysis, all selected publications have
been screened for activities and alternatives in the
implementation of a text analysis. In total, this
screening identified 29 activities. None of the
publications considered all of them. This underlines
the need of an overview of the process, which has
been created in this investigation. For reasons of
brevity only parts of the complete process can be
discussed here. Thus, we concentrate on the parts that
are most specific to dictionary- and rule-based text
classification compared to text classification in
general. These are [1] Scope Definition (Section 3.1),
[2] Dictionary Creation (Section 3.2), and [3] Rule
Definition (Section 3.3).
3.1 Scope Definition
Not all phases of a text analysis implementation are
discussed to the same extent in literature. Above all,
the scope definition is not adequately described. The
suggested activities are shown in Figure 4b.
Goal Definition: The definition of the analysis
objective is the basis for all further steps. When
defining the goal, its complexity must be considered.
If a classification feature is too complex the rules are
complex. Dictionary and rules may become
ambiguous (Carstensen et al., 2010). In consequence,
there is ambiguity with regard to the actual target
question of classification.
Analysis Timeframe Definition: The creation time
of texts a crucial criterion for ensuring traceability. To
analyze the current market situation, the latest
comments, often not more than one month, are to be
evaluated.
KDIR 2019 - 11th International Conference on Knowledge Discovery and Information Retrieval
332
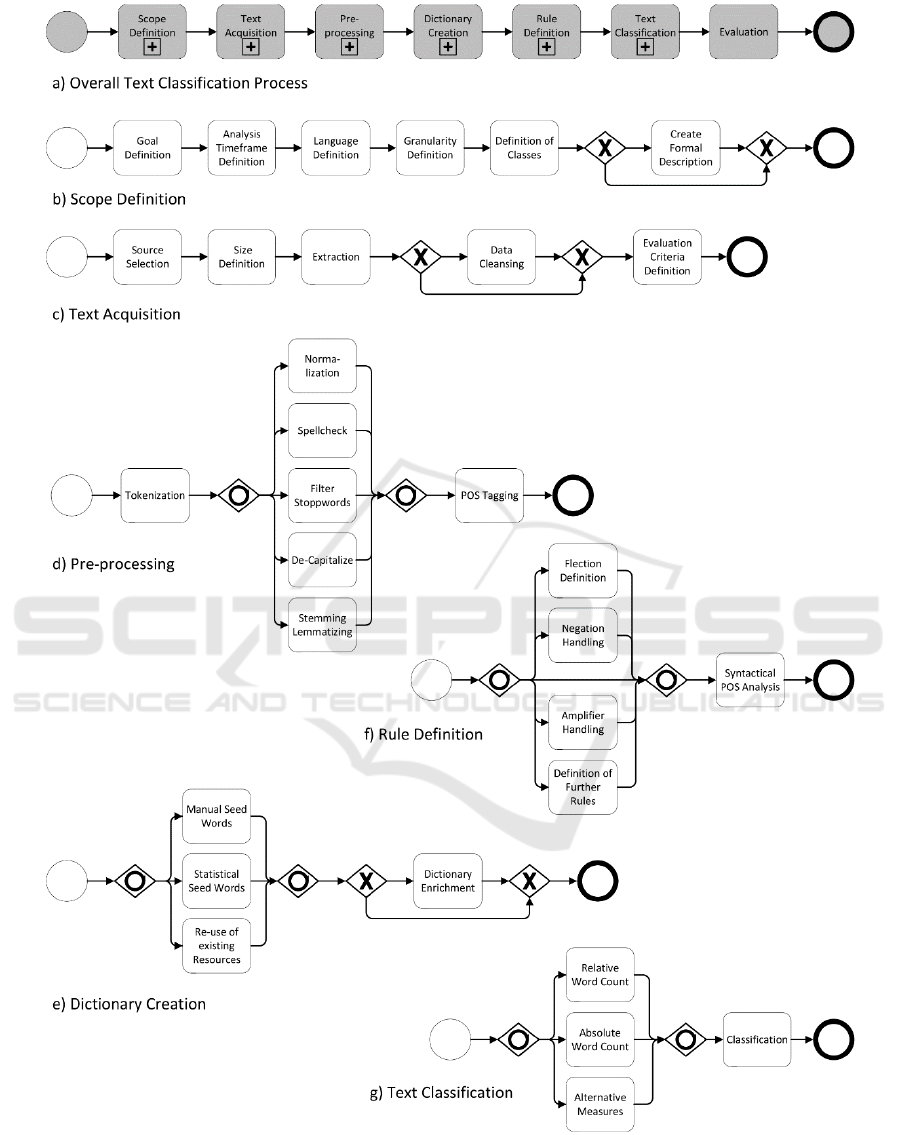
Figure 4: Text Classification Process.
A Methodological Framework for Dictionary and Rule-based Text Classification
333

The analysis period is thus derived from the analysis
goal.
Language Definition: Language has a great
influence on the availability of existing text analysis
resources. As shown in Section 2.3.4, a major share
of the research concentrates on English language. In
the newer language typology, attempts are made to
formulate generalizations by means of uniform
speech patterns. This can be used to express things
expressed in one language in another language
(Gunkel et al., 2017). Furthermore attempts are made,
to translate texts and to use existing text analysis
resources for English language for instance. This
approach cannot deal with specific characteristics of
a certain language. Furthermore, it is hard to handle
domains with a specific vocabulary.
Granularity Definition: As shown in Section 2.3.2
text analysis can be performed at different levels of
granularity. Depending on the sources and the goal,
the desired level of granularity has to be defined.
Definition of Classes: It needs to be defined which
classes and hence how many classes are used to
classify the input data. One possibility would be a
binary classifier (Stede 2016, Sun et al., 2017).
However, there might also be a residual class required
(Yerva et al., 2012). When choosing the number of
classes, it should be noted that the more classes are
used the harder it is to find characteristics for these
individual classes and to use them for analysis
(Gomez et al., 2016). According to Gräbner et al.,
(2012) a reduction in the number of classes is always
recommended. In conjunction with a larger text set
and a larger dictionary, general classification
performance can be improved (Gräbner et al., 2012).
Create Formal Description: Some authors (Appel et
al., 2015, Noferesti and Shamsfard 2015, Yerva et al.,
2012), define a formal framework for the definition
of the text classification outcome for further
processing.
3.2 Dictionary Creation
The suggested activities for Dictionary Creation are
shown in Figure 4e. Dictionaries are domain-
specific. Otherwise, differences in the ratings of the
affiliation of words to a class, can occur. The domain-
specific dictionary is also referred to as the global
context (Muhammad et al., 2016). It has to be
distinguished from the local context that defines the
word meaning or class based on the words in the
immediate environment in the text.
The creation of dictionaries can be done in three
ways. The first is a purely manual identification of
words from the text corpus. The second possibility is
a statistical approach in which the individual words
are assigned to a class according to their frequency.
As a third alternative, it is possible to search for
existing dictionary resources and reuse them. The last
two options represent an at least partially automated
creation approach (Abdulla 2013, Taboada et al.
2011). Despite the time-consuming preparation of
dictionaries, especially in the presence of a large
body, the dictionaries can later be reused and possibly
used in various other domains (Kesharvarz and
Abadeh 2017).
In addition, it has to be decided whether the class
labels are of a qualitative or quantitative nature. In
contrast to the quantitative assessment, qualitative
labels do not distinguish degree of class membership.
In the case of quantification of labels, a scale must be
defined (Asghar et al., 2017). Basically, the choice of
a quantitative measure is based on the assumption of
statistical linearity. This is necessary so that the
results can also be compared in the evaluation phase
(Klein et al., 2011) and deviations of extreme values
are important.
Depending on the classification scheme, some
grammatical parts of speech provide stronger
evidence for the class. In the case of sentiment
analysis in texts, these are typically adjectives. In an
entity classification, the identification of nouns is
important (Afzaal and Usman 2015).
Manual Seed Words: Seed words are created based
on randomly selected texts by identifying class-
specific words from them (Bidulya and Brunova
2016). The first step is to identify relevant content
words and assign the associated known class values
or labels (Al-Twairesh et al., 2016, Neviarouskaya et
al., 2011).The manual approach is very time
consuming.
Statistical Seed Words: If classes have already been
labelled, a statistical approach that evaluates the word
frequencies in the classes can be applied.
Re-use of existing Resources: Depending on the
context it might be possible to use a domain
independent dictionary for classification. For
example, a first seed set of words for sentiment
analysis can be derived from SentiStrength (Abdulla
2013). Even foreign language resources can be
considered here. In this case a translation of the
dictionary to the target language is required (Al-
Twairesh et al., 2016, Avanco et al., 2016).
Dictionary Enrichment: This activity describes the
possibilities of enriching the dictionary with words
that were not previously included in it (Dollmann and
Geierhos 2014). The seed words are checked in a
dictionary and their synonyms and antonyms
identified (Banea et al., 2008, Bidulya and Brunova
KDIR 2019 - 11th International Conference on Knowledge Discovery and Information Retrieval
334

2016, Kolchyna et al., 2015, Kontopoulos et al., 2013,
Sun et al., 2017) and included in the dictionary. An
enrichment of the dictionary is recommended
according to (Abdulla 2013). Various experiments
were carried out here and found that the results are
noticeably worse if the dictionary is too small.
3.3 Rule Definition
The suggested activities for Rule Definition are
shown in Figure 4f. Each rule that is created can be
represented as a pattern of lexical or syntactic
structures of a sentence (Bidulya and Brunova 2016).
With the help of rules, the local context given by the
text data set is taken into account.
Flection Definition: Based on word flection and
grammatical function of words in general, certain
aspects of a text can be filtered. For example, (Klein
et al., 2011) considers sentiment regarding various
financial performance indicators on the financial
market. The main concern and goal of the work is,
based on the moods, to determine future prices. It is
not of interest how these indicators behaved in the
past. For this reason, sentences with this grammatical
tense form are filtered out. Likewise, conditional
clauses are not relevant to their consideration. They
often contain no sentiment, but only a condition for
the situation. Noferesti and Shamsfard (2015) assume
that in addition to conditional clauses, imperative
sentences also do not provide sentiment.
Negation Handling: Negations are characterized by
words that reverse the polarity of a sentence
(Asgarnezhad and Mohebbi 2015, Kolchyna et al.,
2015a). Words whose sentiment was originally
positively affected are shifted into the negative or
vice versa (Tan et al., 2015). A careful handling of
negations is important e.g. in sentiment mining.
Amplifier Handling: Considered here are words that
have a weighting influence on subsequent words
(Anta et al., 2013). This is true both in the positive
sense of amplification and in the negative sense of
attenuation (Vilares 2013). The advantage of
handling amplifiers and attenuators separately is that
it is a limited set of words that can be easily identified
(Silva et al., 2012).
Definition of Further Rules: Besides the already
discussed types of rules, more ideas for rule definition
are suggested in the literature. Mao et al., (2015)
discuss the idea of including rules such as the number
of nouns, exclamation marks, question marks,
adjectives and the length of a document in the
evaluation. In some publications Dependency Parsing
is presented as a kind of basic form for the
identification of further rules. Here, a dependency
tree is created that reflects the grammatical-syntactic
structure of a sentence with the relationships between
features (Asgarnezhad and Mohebbi 2015, Sun et al.,
2017). In Noferesti and Shamsfard (2015) a
dependency tree was used to split up the individual
clauses and to analyse the conjunctive structure of the
sentences.
Syntactical PoS Analysis: In addition to the
previously discussed rules, it is possible to define
rules based on grammatical patterns based on the PoS
tagging. For example, rules can be defined based on
a combination of nouns and adjectives in order to
determine the stance towards certain entities.
4 CONCLUSION AND OUTLOOK
This work presents a process for the implementation
of a text classification using dictionary- and rule-
based approaches. This process has been derived
from a systematic literature analysis. Although it was
possible to collect general consideration for such an
endeavour, at some points literature research does not
provide clear decision rules. The use of certain
techniques for classification depends on the context.
However, the context is not described to an extent that
would allow the definition of clear decision rules.
Still, the range of implementation options and
influence factors for their selection can be described.
A part of the presented research project that has not
been discussed here is a worksheet that guides
through the process and helps to document decisions
which might be used in future for some deeper
investigation with regard to design decisions for text
classification implementations.
From a methodological perspective, roles and
cooperation forms in the process should also be
described. However, this topic is barely addressed in
the literature. Still, when applying the presented
approaches in specific domains, the integration of
domain experts in the process seems to be an
important issue. This should be considered for future
research.
REFERENCES
Stemming and lemmatization, 2008. Online at
https://nlp.stanford.edu/IR- book/html/htmledition/
stemming-and-lemmatization-1.html; accessed 24.07.
2017.
Nawaf A Abdulla, Nizar A Ahmed, Mohammed A Shehab,
and Mahmoud Al-Ayyoub, 2013. Arabic sentiment
analysis: Lexicon-based and corpus-based. In Applied
A Methodological Framework for Dictionary and Rule-based Text Classification
335

Electrical Engineering and Computing Technologies
(AEECT), 2013 IEEE Jordan Conference on, pages 1–
6. IEEE.
Muhammad Afzaal and Muhammad Usman, 2015. A novel
framework for aspect-based opinion classification for
tourist places. In Digital Information Management
(ICDIM), 2015 Tenth International Conference on,
pages 1–9. IEEE.
Nora Al-Twairesh, Hend Suliman Al-Khalifa, and
Abdulmalik Alsalman. Arasenti, 2016. Large-scale
twitter-specific arabic sentiment lexicons.
Daniel Graziotin Alexander, Humboldt, 2016. Foundation,
and Software Engineering View. The Evolution of
Sentiment Analysis - A Review of Research Topics,
Venues, and Top Cited Papers.
Orestes Appel, Francisco Chiclana, and Jenny Carter, 2015.
Main concepts, state of the art and future research
questions in sentiment analysis. Acta Polytechnica
Hungarica, 12(3):87–108.
Razieh Asgarnezhad and Keyvan Mohebbi, 2015. A
Comparative Classification of Approaches and
Applications in Opinion Miningy. International
Academic Journal of Science and Engineering,
2(5):1– 13.
Muhammad Zubair Asghar, Aurangzeb Khan, and Shakeel
Ahmad, 2014. Lexicon-based sentiment analysis in the
social web. Journal of Basic and Applied Scientific
Research, 4(6):238–48.
Muhammad Zubair Asghar, Aurangzeb Khan, Shakeel
Ahmad, Maria Qasim, and Imran Ali Khan, 2017.
Lexicon-enhanced sentiment analysis framework using
rule-based classification scheme. PLoS One, 12(2).
Lucas V Avanço, Henrico B Brum, and Maria GV Nunes,
2016. Improving opinion classifiers by combining
different methods and resources. XIII Encontro
Nacional de Inteligência Artificial e Computacional
(ENIAC), 25-36.
Yolanda Raquel Baca-Gomez, Alicia Martinez, Paolo
Rosso, Hugo Estrada, and Delia Irazu Hernandez
Farias, 2016. Web Service SWePT: A Hybrid Opinion
Mining Approach. Journal of Universal Computer
Science, 22(5):671–690.
Carmen Banea, Janyce M Wiebe, and Rada Mihalcea, 2008.
A bootstrapping method for building subjectivity
lexicons for languages with scarce resources.
Yuliya Bidulya and Elena Brunova, 2016. Sentiment
Analysis for Bank Service Quality: a Rule-based
Classifier. In 2016 IEEE 10th International Conference
on Application of Information and Communication
Technologies (AICT) (pp. 1-4). IEEE.
Kai-Uwe Carstensen, Christian Ebert, Cornelia Ebert,
Susanne Jekat, Ralf Kalbunde, and Hagen Langer,
2010. Computerlinguistik und Sprachtechnologie -
Eine Einführung. Spektrum Akademischer Verlag,
Heidelberg, 3 edition.
Saad M Darwish, Adel A EL-Zoghabi, and Doaa B Ebaid,
2015. A novel system for document classification using
genetic programming. Journal of Advances in
Information Technology Vol, 6(4).
Geeta G Dayalani and BK Patil, 2014. Emoticon-based
unsupervised sentiment classifier for polarity analysis
in tweets. International Journal of Engineering
Research and General Science, 2(6).
DHL Deutsche Post, 2011. Wie stehen Sie zu den folgenden
Aussagen zu Produktbewertungen im Internet? 2011.
Online at https://de.statista.com/statistik/daten/studie
/217981/umfrage/bedeutung- von-kaeufer-be
wertungen-fuer-kaufentscheidung/; last access 18.04.
2017.
Xiaowen Ding, Bing Liu, and Philip S Yu, 2008. A holistic
lexicon-based approach to opinion mining. In
Proceedings of the 2008 international conference on
web search and data mining, pages 231–240. ACM.
Markus Dollmann and Michaela Geierhos. Sentiba, 2014.
Lexicon-based sentiment analysis on german product
reviews. In Workshop Proceedings of the 12th Edition
of the KONVENS Conference, pages 185–191.
eMarketer. Anzahl der Nutzer sozialer Netzwerke weltweit
in den Jahren 2010 bis 2015 sowie eine Prognose bis
2020 (in Milliarden), 2016. Online at
https://de.statista.com/statistik/daten/studie/219903/u
mfrage/prognose- zur-anzahl-der-weltweiten-nutzer-
sozialer-netzwerke/; last access18.04. 2017.
Antonio Fernández Anta, Luis Núñez Chiroque, Philippe
Morere, and Agustín Santos, 2013. Sentiment analysis
and topic detection of Spanish tweets: A comparative
study of NLP techniques. Procesamiento del Lenguaje
Natural, 50:45–52.
Dietmar Gräbner, Markus Zanker, Gunther Fliedl, Matthias
Fuchs, et al., 2012. Classification of customer reviews
based on sentiment analysis. Citeseer.
Lutz Gunkel, Adriano Murelli, Susan Schlotthauer, Bernd
Wiese, and Gisela Zifonun, 2017. Grammatik des
Deutschen im europäischen Vergleich. Das Nominal.
Bd. 2: Nominalflexion, Nominale Syntagmen.
Li Im Tan, Wai San Phang, Kim On Chin, and Patricia
Anthony, 2015. Rule-based sentiment analysis for
financial news. In Systems, Man, and Cybernetics
(SMC), 2015 IEEE International Conference on, pages
1601–1606. IEEE.
Hamidreza Keshavarz and Mohammad Saniee Abadeh,
2017. ALGA: Adaptive lexicon learning using genetic
algorithm for sentiment analysis of microblogs.
Knowledge-Based Systems, 122:1–16.
Vishal A Kharde and S S Sonawane, 2016. Sentiment
Analysis of Twitter Data: A Survey of Techniques.
International Journal of Computer Applications,
139(11):975–8887.
Barbara Kitchenham, 2004. Procedures for Performing
Systematic Reviews. Online at http://csnotes.upm.
edu.my/kelasmaya/pgkm20910.nsf/0/715071a8011d4c
2f482577a700386d3a/$FILE/10.1.1.122.3308[1].pdf;
last access 15.95. 2017.
Achim Klein, Olena Altuntas, Tobias Hausser, and Wiltrud
Kessler, 2011. Extracting investor sentiment from
weblog texts: a knowledge-based approach. In
Commerce and Enterprise Computing (CEC), 2011
IEEE 13th Conference on, pages 1–9. IEEE.
KDIR 2019 - 11th International Conference on Knowledge Discovery and Information Retrieval
336

Olga Kolchyna, Tharsis TP Souza, Philip Treleaven, and
Tomaso Aste, 2015a. Twitter sentiment analysis:
Lexicon method, machine learning method and their
combination.
Olga Kolchyna, Thársis TP Souza, Philip C Treleaven, and
Tomaso Aste, 2015. Methodology for twitter sentiment
analysis.
Efstratios Kontopoulos, Christos Berberidis, Theologos
Dergiades, and Nick Bassiliades, 2013. Ontology-based
sentiment analysis of twitter posts. Expert systems with
applications, 40(10):4065–4074.
Kathy Lee, Diana Palsetia, Ramanathan Narayanan, Md
Mostofa Ali Patwary, Ankit Agrawal, and Alok
Choudhary, 2011. Twitter trending topic classification.
In Data Mining Workshops (ICDMW), 2011 IEEE 11th
International Conference on, pages 251–258. IEEE.
Santanu Mandal and Sumit Gupta, 2016. A novel
dictionary-based classification algorithm for opinion
mining. 2016 Second International Conference on
Research in Computational Intelligence and
Communication Networks (ICRCICN), pages 175–
180.
Kaili Mao, Jianwei Niu, Xuejiao Wang, Lei Wang, and
Meikang Qiu, 2015. Cross-Domain Sentiment Analysis
of Product Reviews by Combining Lexicon-Based and
Learn-Based Techniques. In High Performance
Computing and Communications (HPCC), 2015 IEEE
7th International Symposium on Cyberspace Safety and
Security (CSS), 2015 IEEE 12th International Conferen
on Embedded Software and Systems (ICESS), pages
351–356. IEEE.
Aminu Muhammad, Nirmalie Wiratunga, and Robert
Lothian, 2016. Contextual sentiment analysis for social
media genres. Knowledge-based systems, 108:92–101.
Alena Neviarouskaya, Helmut Prendinger, and Mitsuru
Ishizuka, 2011. Sentiful: A lexicon for sentiment
analysis. IEEE Transactions on Affective Computing,
2(1):22–36.
Azadeh Nikfarjam and Graciela H Gonzalez, 2011. Pattern
mining for extraction of mentions of adverse drug
reactions from user comments. In AMIA Annu Symp
Proc, volume 2011, pages 1019–1026.
Samira Noferesti and Mehrnoush Shamsfard, 2015.
Resource construction and evaluation for indirect
opinion mining of drug reviews. PloS one,
10(5):e0124993.
Briony J. Oates, 2005. Researching information systems
and computing. Sage.
Hille Pajupuu, Rene Altrov, Krista Kerge, et al., 2012.
Lexicon-based detection of emotion in different types
of texts: Preliminary remarks. Eesti akenduslingvistika
Ühingu aastaraamat, (8):171–184.
K Raj, G Sujitha, R Karthikaeyan, and C Kumar, 2016.
Survey of Methods in Sentiment and Emotional
Analysis. British Journal of Mathematics & Computer
Science, 18(2):1–16.
Kumar Ravi and Vadlamani Ravi, 2015. A survey on
opinion mining and sentiment analysis : tasks ,
approaches and applications, volume 89.
Nurul Fathiyah Shamsudin, Halizah Basiron, and Zurina
Sa’aya, 2016. Lexical based sentiment analysis-verb,
adverb & negation. Journal of Telecommunication,
Electronic and Computer Engineering (JTEC),
8(2):161–166.
Mário J Silva, Paula Carvalho, and Luís Sarmento, 2012.
Building a sentiment lexicon for social judgement
mining. In International Conference on Computational
Processing of the Portuguese Language, pages 218–
228. Springer.
Manfred Stede, 2016. Computerlinguistische Werkzeuge
zur Analyse meinungsorientierter Texte: Eine
Fallstudie. Germanistische Linguistik - Persuasionsstile
in Europa III, (232-233):91–113.
Shiliang Sun, Chen Luo, and Junyu Chen, 2017. A review
of natural language processing techniques for opinion
mining systems. Information Fusion, 36:10–25.
Maite Taboada, Julian Brooke, Milan Tofiloski, Kimberly
Voll, and Manfred Stede, 2011. Lexicon-based methods
for sentiment analysis. Computational linguistics,
37(2):267–307.
Katerina Veselovská and Aleš Tamchyna. Úfal, 2014.
Using hand-crafted rules in aspect based sentiment
analysis on parsed data. SemEval 2014, page 694.
David Vilares, 2013. Sentiment analysis for reviews and
microtexts based on lexico-syntactic knowledge. In
FDIA’13, pages 38–43.
David Vilares, Miguel A Alonso, and Carlos Gómez-
Rodríguez, 2015. A linguistic approach for determining
the topics of spanish twitter messages. Journal of
Information Science, 41(2):127–145.
David Vilares, Miguel A Alonso, and Carlos Gómez-
Rodríguez, 2015. On the usefulness of lexical and
syntactic processing in polarity classification of twitter
messages. Journal of the Association for Information
Science and Technology, 66(9):1799–1816.
A Walha, F Ghozzi, and F Gargouri, 2016. ETL Design
Toward Social Network Opinion Analysis. Computer
and Information Science 2015.
Claes Wohlin, 2014. Guidelines for Snowballing in
Systematic Literature Studies and a Replication in
Software Engineering. 18th International Conference
on Evaluation and Assessment in Software Engineering
(EASE 2014), pages 1–10.
Surender Reddy Yerva, Zoltán Miklós, and Karl Aberer,
2012. Entity-based classification of twitter messages.
International Journal of Computer Science &
Applications, 9:88–115.
Lili Zhao and Chunping Li, 2009. Ontology based opinion
mining for movie reviews. In International Conference
on Knowledge Science, Engineering and Management,
pages 204–214. Springer.
A Methodological Framework for Dictionary and Rule-based Text Classification
337
