
Axiom-based Probabilistic Description Logic
Martin Unold
a
and Christophe Cruz
b
Laboratoire d’Informatique de Bourgogne, EA 7534, 9 Avenue Alain Savary, BP 47870, 21078 Dijon Cedex, France
Keywords:
Probabilistic Description Logic, Uncertainty, Knowledge Base.
Abstract:
The paper proposes a new type of probabilistic description logics (p-DLs) with a different interpretation of
uncertain knowledge. In both approaches (classical state of the art approaches and the approach of this paper),
probability values are assigned to axioms in a knowledge base. While In classical p-DLs, the probability value
of an axiom is interpreted as the probability of the axiom to be true in contrast to be false or unknown, the
probability value in this approach is interpreted as the probability of an the axiom to be true in contrast to
other axioms being true. The paper presents the theory of that novel approach and a method for the treatment
of such data. The proposed description logic is evaluated with some sample knowledge bases and the results
are discussed.
1 INTRODUCTION
The management of uncertainty in description logics
has received a lot of attention, due to the development
of the semantic web. There should be a level of trust
for every piece of information found online and when
combining this information to gain further implicitly
stored knowledge, the involved uncertainty should be
taken into account. Therefore probabilistic descrip-
tion logics have been developed in a couple of vari-
ants. Usually they see each probabilistic axiom within
the same knowledge base separately from all others,
i.e. the probability of that axiom should be valid in
any scenario.
Nevertheless, in some cases, the probability is
only estimated or the source of uncertainty allows
only to state a general value for the uncertainty of all
the information gained from that source. For exam-
ple, the two statements
• A is true with a probability of 90%
• A is false with a probability of 10%
work perfectly together and would result in a consis-
tent knowledge base. If the statements are changed
to
• A is true with a probability of 90%
• A is false with a probability of 50%
a
https://orcid.org/0000-0003-2913-2421
b
https://orcid.org/0000-0002-5611-9479
they do not hold in a probabilistic knowledge base.
Only some possibilistic approaches would be able to
handle them. However, the two statements
• A is true with a probability of 90%
• A is false with a probability of 90%
would not work together in any case. Even though
this looks like a huge contradiction, such cases might
appear in several scenarios. For instance, when merg-
ing two crisp knowledge bases K
1
and K
2
, K
1
might
contain one of these statements and K
2
the other one.
For sure, they are inconsistent together and therefore
at least one of the knowledge bases must contain false
information. If it is known, that approximately 90%
of the knowledge in K
1
and K
2
is correct, respec-
tively, one might not have any other choice than as-
signing 90% to each axiom of both knowledge bases
to express the probability. The trust of 90% could be a
result from earlier observations about the knowledge
from the same source.
Generally, it might be a more realistic assump-
tion that there exists only one correct world and not
several possible worlds, each with a certain probabil-
ity or possibility. Indeed, it is the knowledge about
the correct world, which might be wrong sometimes,
rather than the world itself being true only with a cer-
tain probability or possibility. For instance, a pater-
nity testing has an accuracy of 99.99%. This value
is determined by observations when applying the test
to people with known paternity. Hence, a statement
like ”John is the father of Mary with a probability of
99,99%” does not state, that in 9999 of 10000 a paral-
Unold, M. and Cruz, C.
Axiom-based Probabilistic Description Logic.
DOI: 10.5220/0008351103830389
In Proceedings of the 11th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2019), pages 383-389
ISBN: 978-989-758-382-7
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
383

lel universes the statement is true and in 1 it is false. It
rather states, that 9999 of 10000 comparable parent-
ing testings are correct and 1 is incorrect. But there is
only one world.
In such cases, the probability does not state the
probability of a statement to be true in contrast to be-
ing false or unknown. It rather states the probabil-
ity of a statement to be true in contrast to the other
statements in the same environment or from the same
source. This type of interpretation is neither handled
by probabilistic nor by possibilistic description log-
ics. This paper presents a different way of dealing
with knowledge in such situations. It starts with a
related work and a preliminaries section, where ba-
sically other ways of creating probabilistic or possi-
bilistic knowledge bases are presented, respectively.
The novel approach is then explained in section 4 and
section 5 shows in which cases it is more useful. Fi-
nally, a conclusion summarizes the paper and gives an
outlook to further developments.
2 RELATED WORK
A description logic is used as a formalism to represent
knowledge about a special domain. It easily allows to
link other information to knowledge in the semantic
web, as explained in (Baader et al., 2005). Reason-
ing programs allow to infer implicitly stored infor-
mation from explicit knowledge and inference rules.
These programs can also decide if a specific part of
the knowledge is logically consistent or not. Common
decision problems also include those, that are typi-
cally used for queries on relational databases, such as
instance or relation checking.
There exists a huge variety of description logics
with different expressiveness. An overview about this
variety is shown in (Zolin, 2013). The expressiveness
is determined by the amount of symbols allowed in
the syntax of a particular description logic. In this sec-
tion, the most common and the ones that are relevant
in the following chapters are explained. A more de-
tailed introduction to description logics can be found
in (Baader et al., 2003).
The extension of a description logic by the man-
agement of uncertainty results in a probabilistic de-
scription logic. In contrast to a classical one, which
is also called crisp. Regardless of the expressiveness,
each type of description logic could be extended to a
probabilistic one. When modeling a probabilistic de-
scription logic, the knowledge about the validity of
the axioms is limited, i.e. it is unknown if an axiom
is true or false, yet the axioms themselves are clearly
true or false and nothing in between. An introduction
to probabilistic logic can be found in (Nilsson, 1986).
Probability and fuzziness (also called vagueness)
seem very similar on first sight, since both contain
values in the range between 0 and 1 attached to crisp
axioms in the knowledge base of a description logic.
Nevertheless, they both work completely different
and a detailed clarification about the differences is
done in (Dubois and Prade, 2001). An introduction to
both types of extensions of description logics is done
in (Lukasiewicz and Straccia, 2008). The structure
of a probabilistic description logic is rather the same
as in the crisp case and the probabilistic interpreta-
tion maps all possible crisp interpretations to a certain
probability.
A major problem with probabilistic description
logics is the complexity (Lukasiewicz, 2008), in gen-
eral cases computations require exponential time, be-
cause many possible worlds need to be taken into ac-
count. Hence, a lot of research focused on the re-
duction of complexity, such as (Klinov, 2008), or to
find more efficient solutions for more specific cases,
such as (Riguzzi et al., 2015). The latter approach as-
sumes that all axioms within a knowledge base are in-
dependent of each other, while in this paper all axioms
within a knowledge base are assumed to be highly de-
pendent. In (Niepert et al., 2011) a log-linear model
is used to do reasoning on uncertain knowledge.
One of the first attempts to add the management
of uncertainty to description logics is done by (Koller
et al., 1997), which was developed further by (Giugno
and Lukasiewicz, 2002), where the complexity of rea-
soning algorithms has been analyzed. The develop-
ment of reasoning programs has been subject of sev-
eral studies (Lukasiewicz, 2007) and also the devel-
opment of standards for the semantic web is of im-
portance for applications. The management of un-
certainty could be integrated to the semantic web by
extensions of OWL or RDF. Examples are found in
(Ding et al., 2006). Unfortunately, there is no W3C-
standard available till now (Carvalho et al., 2017).
Anyway, the solution for dealing with probabilities
in description logics presented in this paper should
be treated carefully when combining with other data,
that use a different understanding of uncertainty.
3 PRELIMINARIES
Each description logic allows the existence of knowl-
edge bases, where all the information about a specific
domain is stored. Typically, the knowledge is divided
into two parts, which are called the terminological ax-
ioms (TBox) and the assertional axioms (ABox). The
TBox consists of general rules, such as ”Each City
KEOD 2019 - 11th International Conference on Knowledge Engineering and Ontology Development
384

has a Location”. The ABox consists of specific infor-
mation for single instances, such as ”Paris is a City”.
The reasoner should then be able to infer the implicit
information, that ”Paris has a Location”.
A knowledge base K is a collection of axioms.
Usually, they are divided into two parts, so that a
knowledge base becomes a tuple K = (T , A). It con-
sists of a TBox T and an ABox A. A TBox T is a set
of general concept inclusions and an ABox A is a set
of assertional axioms. A general concept inclusion is
an expression of the format C v D, where C,D ∈ C
are concepts. An assertional axiom is either an ex-
pression of the format a : C (concept assertion) or of
the format (a,b) : R (role assertion), where a,b ∈ N
I
are named individuals, C ∈ C is a concept and R ∈ N
R
is a role.
In this context, an ordered triple of arbitrary pair-
wise disjoint sets (N
C
,N
R
,N
I
) is called a signature.
The sets contain named concepts, named roles and
named individuals, respectively. The set of concepts
C over a signature (N
C
,N
R
,N
I
) is the smallest possi-
ble set, that fulfills some of the following conditions.
C ∈ N
C
=⇒ C ∈ C
> ∈ C
⊥ ∈ C
C
1
,C
2
∈ C =⇒ C
1
tC
2
∈ C
C
1
,C
2
∈ C =⇒ C
1
uC
2
∈ C
C ∈ C =⇒ ¬C ∈ C
C ∈ C,R ∈ N
R
=⇒ ∀R.C ∈ C
C ∈ C,R ∈ N
R
=⇒ ∃R.C ∈ C
Each element C ∈ C is called a concept and it de-
pends on the expressiveness of the description logic, if
even more conditions must be fulfilled, i.e. more sym-
bols are allowed. The description logic ALC allows
only atomic roles and the introduced concepts. The
basic version of ALC neither allows role inclusion
axioms nor general concept inclusions, i.e. only as-
sertional axioms are allowed. Description logics with
more expressiveness could allow further roles, con-
cepts and even an entirely different additional formal-
ism.
So far, it is only a collection of symbols. The in-
teresting part is the semantics of these axioms. The
meaning of each axiom is expressed by stating the
membership to each concept and role. These state-
ments are done by an interpretation, which maps the
signature to some elements of the universe of dis-
course, which is the domain of the knowledge, that
is modeled in a particular knowledge base.
Formally, an interpretation I = (∆
I
,·
I
) over a
signature (N
C
,N
R
,N
I
) consists of a set ∆
I
, which is
called domain or universe of discourse, and a func-
tion ·
I
, that maps ...
• ... each named individual a ∈ N
I
to an element of
the domain a
I
∈ ∆
I
.
• ... each concept C ∈ C to a subset of the domain
C
I
⊆ ∆
I
.
• ... each role R ∈ R to a set of tuples of domain
elements R
I
∈ ∆
I
× ∆
I
.
The interpretation function ·
I
must also fulfill the
following conditions.
δ ∈ >
I
⇐⇒ δ ∈ ∆
I
δ ∈ ⊥
I
⇐⇒ δ /∈ ∆
I
δ ∈ (C
1
tC
2
)
I
⇐⇒ δ ∈ C
I
1
∨ δ ∈ C
I
2
δ ∈ (C
1
uC
2
)
I
⇐⇒ δ ∈ C
I
1
∧ δ ∈ C
I
2
δ ∈ (¬C)
I
⇐⇒ δ /∈ C
I
δ ∈ (∀R.C)
I
⇐⇒
∀δ
0
∈ ∆
I
,(δ,δ
0
) ∈ R
I
: δ
0
∈ C
I
δ ∈ (∃R.C)
I
⇐⇒
∃δ
0
∈ ∆
I
,(δ,δ
0
) ∈ R
I
: δ
0
∈ C
I
Of course, the conditions depend on the existence
of the corresponding type of concepts and roles, i.e.
only those conditions must be fulfilled, where the cor-
responding type of concepts and roles are allowed by
the description logic.
A knowledge base K is free of contradictions, if
there exists an interpretation I , which is a model for
all axioms of the knowledge base. An interpretation
I is a model of a general concept inclusion C v D
(denoted: I |= (C v D)) if and only if C
I
⊆ D
I
. An
interpretation I is a model of a role assertion (a,b) : R
(denoted: I |= ((a, b) : R)) if and only if (a
I
,b
I
) ∈ R
I
.
An interpretation I is a model of a concept assertion
a : C (denoted: I |= (a : C)) if and only if a
I
∈ C
I
.
An interpretation I is a model of a TBox T (denoted:
I |= T ) if and only if I |= φ for all general concept
inclusions φ ∈ T . An interpretation is a model of an
ABox A (denoted: I |= A) if and only if I |= φ for
all assertional axioms φ ∈ A. An interpretation I is a
model of a knowledge base K , if I is a model of all
its boxes. Sometimes the phrase ”in I holds” is used
instead of ”I is a model of”.
For a probabilistic description logic, the set of
possible worlds
W =
{
I | I is an interpretation over (N
C
,N
R
,N
I
)
}
consists of all interpretations over a given signature
(N
C
,N
R
,N
I
). An element of this set I ∈ W is called a
possible world. A mapping π : W → [0, 1] with
∑
I ∈W
π(I ) = 1
Axiom-based Probabilistic Description Logic
385

is called a probability distribution of possible worlds
over (N
C
,N
R
,N
I
). It has to be noted, that the defini-
tion of W and π is not dependent on a given interpre-
tation or knowledge base, only an elementary descrip-
tion is necessary. This is important, especially when
it comes to the development of algorithms, since there
are a lot of possible worlds on first attempt.
An uncertain knowledge base will be intro-
duced later to restrict π. Sometimes π is not de-
fined as a probability distribution and the constraint
∑
I ∈W
π(I ) = 1 is replaced by max
I ∈W
π(I ) = 1. With
that constraint, one gets a possibility value for each
world to be the true one.
A probabilistic knowledge base K is a collection
of axioms. They could be probabilistic, but also crisp
axioms, i.e. with a probability of 1. As in the crisp
case, the knowledge base is divided into two parts
K = (T ,A). It consists of a TBox T and an ABox A.
A TBox T is a set of (probabilistic) general concept
inclusions and an ABox A is a set of (probabilistic)
assertional axioms. A probabilistic general concept
inclusion is an expression of the format p :: C v D,
where C,D ∈ C are concepts and p ∈ [0,1] is the
probability of the axiom to be true. A probabilistic
assertional axiom is either an expression of the for-
mat p :: (a : C) (concept assertion) or of the format
p :: ((a,b) : R) (role assertion), where a,b ∈ N
I
are
named individuals, C ∈ C is a concept, R ∈ N
R
is a
role and p ∈ [0,1] is the probability of the axiom to be
true. For p = 1, an axiom has exactly the crisp mean-
ing. An axiom with p = 0 is obsolete because it does
not contain any information.
The set of concepts C is defined in exactly the
same way as in the crisp case. Also the interpreta-
tion I is defined in exactly the same way. The only
difference is, that it is called a possible world in the
context of probabilistic description logics.
A probabilistic knowledge base K is free of con-
tradictions, if there exists a probability distribution
of possible worlds π, which is a model for all ax-
ioms of the probabilistic knowledge base. A proba-
bility distribution of possible worlds π is a model of
a model of a probabilistic general concept inclusion
p :: C v D (denoted: π |= p :: C v D) if and only if
∑
I |=CvD
π(I ) = p. It is a model of a probabilistic role
assertion p :: (a,b) : R (denoted: π |= p :: (a, b) : R) if
and only if
∑
I |=(a,b):R
π(I ) = p. And it is a model
of a probabilistic concept assertion p :: a : C (de-
noted: I |= p :: a : C) if and only if
∑
I |=a:C
π(I ) = p.
A probability distribution of possible worlds π is a
model of a TBox T (denoted: π |= T ) if and only if
π |= p :: φ for all (probabilistic) general concept in-
clusions p :: φ ∈ T . And it is a model of an ABox
A (denoted: π |= A) if and only if π |= p :: φ for all
(probabilistic) assertional axioms p :: φ ∈ A. A prob-
ability distribution of possible worlds π is a model of
a probabilistic knowledge base K , if it is a model of
all its boxes.
It has to be noted, that there are also other options
to define a probabilistic description logic. There is
also the similar possibilistic logic, which allows to
state possibilities and necessities for each axiom and
the probability distribution is replaced by the maxi-
mum possibility for each world. These options are
not part of further discussion at this point, since the
proposal of this paper is another option, anyway.
4 PROPOSAL
In contrast to the probabilistic description logics in-
troduced in the previous sections, the probability at-
tached to an axiom p :: φ is interpreted differently in
this proposal. Here, p is the probability of φ being
true not in contrast to being false or unknown other-
wise, but to be true as compared to other axioms of
the same knowledge base.
An axiom-based probabilistic knowledge base is a
tuple K = (T ,A), that consists of probabilistic gen-
eral concept inclusions (p :: C v D) ∈ T , probabilistic
concept assertions (p :: a : C) ∈ A and probabilistic
role assertions (p :: (a, b) : R) ∈ A. To ease the no-
tation, φ is denoted for any type of crisp axiom and
(p :: φ) ∈ K is used to state that an axiom is part of a
knowledge base, although the axioms are members of
T or A.
The basic idea of this proposal is, that within an
axiom-based probabilistic knowledge base, the ratio
between correct and incorrect axioms should be ac-
cording to their probability, respectively. Therefore,
the sum of all remaining probabilities of all correct
statements should be equal (or greater than) the sum
of all probabilities of all incorrect statements, which
is measured as confidence. A confidence function
σ : W → R assigns to every possible world I ∈ W a
value that states the confidence of the world to be the
true one.
σ(I ) =
1
|K |
·
∑
p::φ∈K
I |=φ
(1 − p) −
∑
p::φ∈K
I 6|=φ
p
(1)
The value for confidence of an interpretation
ranges from −1, which indicates a totally wrong in-
terpretation, to 1. A value of around 0 or maybe a bit
higher indicates an interpretation, that is very likely
to be the true one. If the value is very high, i.e. close
KEOD 2019 - 11th International Conference on Knowledge Engineering and Ontology Development
386

to 1, this is rather an indicator of a not well designed
knowledge base, that is not restrictive enough.
As an example, consider the knowledge base K =
(T ,A) with the following axioms.
T = {0.75 :: C v D}
A = {0.75 :: a : C,
0.75 :: a : C tD,
0.75 :: a : ¬D}
The knowledge base consists of 4 axioms. To each
a probability of 0.75 is assigned, which means that
in average one of these axioms is false in the way of
interpreting probability within this paper. It has to
be noted, that each probability could be any value be-
tween 0 and 1. For the example knowledge base, there
exist four different interpretations.
I
1
: a
I
1
∈ C
I
1
,a
I
1
∈ D
I
1
I
2
: a
I
2
∈ C
I
2
,a
I
2
/∈ D
I
2
I
3
: a
I
3
/∈ C
I
3
,a
I
3
∈ D
I
3
I
4
: a
I
4
/∈ C
I
4
,a
I
4
/∈ D
I
4
The confidence of each interpretation in W =
{I
1
,I
2
,I
3
,I
4
} can be calculated in the following way.
σ(I
1
) =
1
4
(0.25 + 0.25 + 0.25 −0.75) = 0
σ(I
2
) =
1
4
(−0.75 +0.25 + 0.25 +0.25) = 0
σ(I
3
) =
1
4
(0.25 − 0.75 + 0.25 −0.75) = −0.25
σ(I
4
) =
1
4
(0.25 − 0.75 − 0.75 +0.25) = −0.25
This solution shows that either I
1
or I
2
are very likely
to be the correct worlds. It also gives a hint to which
axioms might be the wrong ones in the knowledge
base (here it is C v D or a : ¬D). In a classical proba-
bilistic description logic, this example would be con-
sidered inconsistent. Also, a possibilistic logic would
either suffer from the drowning problem and remove
all axioms from the knowledge base or if other strate-
gies are used still not find a totally possible world.
There are several algorithms to handle probabilis-
tic logics. The consideration of all possible worlds
is very time consuming, since the amount of possible
worlds increases exponentially in the amount of ax-
ioms in the knowledge base. Therefore some more ef-
ficient algorithms have been designed, they have dis-
advantages sometimes and might not work for an ar-
bitrary knowledge base. For the proposed description
logic, an optimization problem has to be solved, since
the goal is to find the possible world with the highest
confidence. Therefore the development of suitable al-
gorithms, such as evolutionary algorithms, is subject
to future work. Nevertheless, it might be easier to find
an efficient solution for an optimization problem as
compared to solve a huge linear system of equations,
which is required for (classical) probabilistic descrip-
tion logics.
If all possible worlds have a negative confi-
dence, the knowledge base might be inconsistent, i.e.
the information within the axiom-based probabilistic
knowledge base is wrong with respect to the probabil-
ity values. A small negative value for the highest con-
fidence might still be called consistent, since an op-
timal designed axiom-based probabilistic knowledge
base should have a confidence value of σ(I ) ≈ 0.
5 EVALUATION
To test the quality of this approach, a crisp knowledge
base is used, which is called ”the solution” in this
section. The knowledge bases are generated by an
own software developed for this purpose, available
at https://github.com/unold/fcdc. Such a generated
knowledge base is called complete, i.e. there is
no further information inferable and it contains a
lot of redundant knowledge. From this complete
knowledge base, each axiom is changed to its nega-
tion with a probability of (1 − p) and p ∈ [0,1] is
assigned to each crisp axiom φ, so that it becomes a
probabilistic axiom p :: φ. The result is a damaged
knowledge base, where the probability of an axiom to
be false is p. By that, the knowledge base becomes a
probabilistic one, that exactly meets the requirements
to use the proposed approach.
For the requirements of this test, a simple random
optimization algorithm is used, which tries to find a
good solution by randomly assuming some axioms as
true or false. It works in the following way.
maximumConfidenceApprox(KB) {
I = empty();
c = confidence(I);
repeat {
axiom = KB.getRandomAxiom();
I.add|I.remove(axiom);
if (I.consistent() & KB.confidence(I) > c)
c = KB.confidence(I);
else
I.remove|I.add(axiom);
} until c did not changed for all axioms
return c;
}
For very small knowledge bases, an exact algorithm
that determines the confidence for every possible
world, is also used.
maximumConfidenceExact(KB) {
c = -1;
Axiom-based Probabilistic Description Logic
387
for (I subset KB) {
if (I.consistent() & KB.confidence(I) > c)
c = KB.confidence(I);
}
return c;
}
The aim of these algorithms is to find an interpretation
I with the highest confidence value for the damaged
knowledge base KB. The hope is, that this interpreta-
tion is also an interpretation for the correct solution.
However, in many cases there exists another interpre-
tation with a higher confidence value.
The algorithms are executed on knowledge bases
with varying parameter p ∈ (0.5, 1). The parameter
p is only assigned to all assertional axioms of the
knowledge base and not to general concept inclusions,
since the assignment to general concept inclusions in-
volves many other axioms at the same time and there-
fore it is more likely to be considered false if its prob-
ability is less than 1. Also, the value p is only dis-
played in a range down to 50%, since a knowledge
base that contains only axioms that are more likely
to be false than to be true is rather useless, anyway.
The assumed correct solution, i.e. the solution be-
fore damaging the knowledge base, is always set to a
confidence value of 0, since differences only appear
randomly.
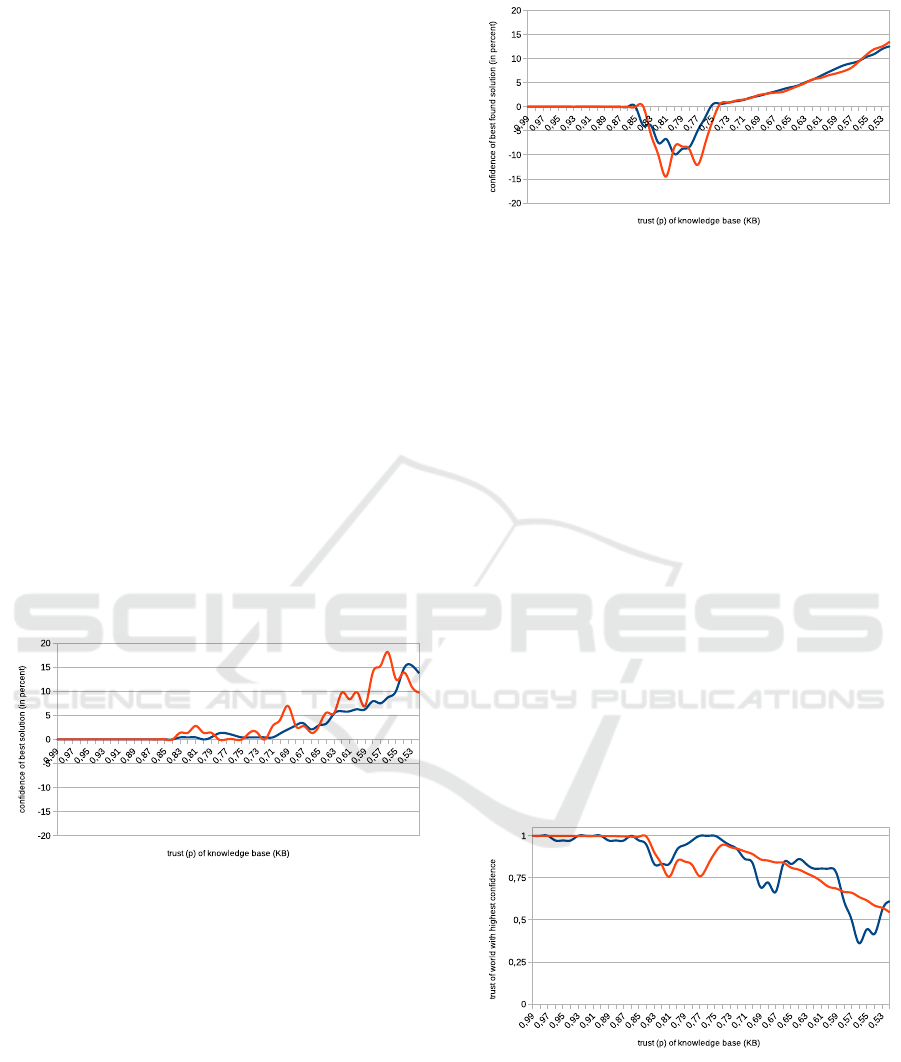
Figure 1: The difference of confidence (in percent) between
best and correct solution for different probabilities in small
knowledge bases of 100 (red) and 200 (blue) axioms.
Figure 1 depicts the difference between the cor-
rect solution and the one with the highest confidence
value. It is determined by the exact algorithm, since
the knowledge bases consist of only 100 and 200 ax-
ioms, respectively. Therefore the best solution is al-
ways at least as good as the correct one. The horizon-
tal axis holds the value p for an axiom of the knowl-
edge base to be true. For instance, if p = 0.9 for a
knowledge base of 100 axioms, then in average 90 of
these 100 axioms are correct and 10 are incorrect.
A different result is depicted in figure 2, where
larger knowledge bases with 10000 and 20000 ax-
ioms are used, respectively. The exact algorithm is
Figure 2: The difference of confidence (in percent) between
best and correct solution for different probabilities in large
knowledge bases of 10000 (red) and 20000 (blue) axioms.
not able to terminate within an appropriate time, thus
the heuristic algorithm has to be used. One can no-
tice, that it has more difficulties finding a good solu-
tion if there are many false axioms in the knowledge
base, which results in a confidence value even worse
than the one of the correct solution, although there
might be even a solution with higher confidence than
the correct one. Nevertheless, the results show that
the approach might work well for knowledge bases
with high trust, i.e. only a little amount of incorrect
information. In this case, it can detect the wrong in-
formation quite well.
For large knowledge bases with little trust, the
results show an increasing confidence for the best
solution. Therefore it might be very likely that there
exist even better solutions in many cases, which are
simply not found by the algorithm. More sophisti-
cated heuristics should be developed to improve the
results. Nevertheless, unfortunately the correct world
is very likely to not be found, since there are other
worlds with higher confidence.
Figure 3: The level of trust for the best solution for different
probabilities in knowledge bases of 100 (blue) and 10000
(red) axioms.
Another interesting aspect of this evaluation is
shown in figure 3. It depicts the amount of correct
information compared to the assumed correct solu-
tion for the solution with the highest confidence value.
It clearly shows, that if a solution with higher confi-
KEOD 2019 - 11th International Conference on Knowledge Engineering and Ontology Development
388

dence than the correct one is found, at least the trust of
this new knowledge base is higher than for the start-
ing point. Especially for an intermediate trust value
of around 60% to 75%, the improvement in trust is
noticeable. Probably the improvement is also better
for higher trust values p, if a better algorithm for the
optimization problem is used. An additional obser-
vation is, that the stability of values for large knowl-
edge bases is higher as compared to smaller knowl-
edge bases, i.e. the experimental results suffer from
high volatility for small datasets.
6 CONCLUSION
The paper presented a novel approach to deal with
probabilistic description logics. By not interpreting
each axiom separately, but a whole knowledge base
together, it enables results for cases, where other ap-
proaches would consider the knowledge base as in-
consistent. Also the computation time can be highly
reduced as compared to probabilistic description log-
ics by using optimization algorithms, which should be
subject to further research.
The disadvantage of the presented approach is,
that axioms can not be treated independently, i.e. the
whole knowledge base must be kept together. An-
other problem is that the probabilities of all axioms
are assumed to be independent of each other, i.e. there
is no space for redundancy. Nevertheless, the as-
sumption of having only one correct world instead
of assuming the existence of several possible worlds
seems more appropriate and realistic in many appli-
cation scenarios. Therefore a further development of
the presented idea seems useful.
For the evaluation, another interesting aspect
might be to consider also T-Box axioms to be uncer-
tain. Therefore another strategy for evaluation should
be developed, e.g. a different or separate treatment of
A-Box and T-Box axioms (Van Asch, 2013). For this
purpose, it might also be useful to change or param-
eterize formula (1) to determine the confidence of an
interpretation for a given knowledge base in a differ-
ent way.
ACKNOWLEDGEMENTS
We would like to thank the Deutsche Forschungs-
gemeinschaft (DFG) and the agence nationale de la
recherche (ANR) for the support of the TEXTELSEM
project, in which this work has been done.
REFERENCES
Baader, F., Calvanese, D., McGuinness, D., Patel-
Schneider, P., and Nardi, D. (2003). The description
logic handbook: Theory, implementation and applica-
tions. Cambridge university press.
Baader, F., Horrocks, I., and Sattler, U. (2005). Description
logics as ontology languages for the semantic web.
In Mechanizing mathematical reasoning, pages 228–
248. Springer.
Carvalho, R. N., Laskey, K. B., and Costa, P. C. (2017).
Pr-owl–a language for defining probabilistic ontolo-
gies. International Journal of Approximate Reason-
ing, 91:56–79.
Ding, Z., Peng, Y., and Pan, R. (2006). Bayesowl: Uncer-
tainty modeling in semantic web ontologies. In Soft
computing in ontologies and semantic web, pages 3–
29. Springer.
Dubois, D. and Prade, H. (2001). Possibility theory, prob-
ability theory and multiple-valued logics: A clarifi-
cation. Annals of mathematics and Artificial Intelli-
gence, 32(1-4):35–66.
Giugno, R. and Lukasiewicz, T. (2002). P-shoq (d): A prob-
abilistic extension of shoq (d) for probabilistic ontolo-
gies in the semantic web. In JELIA, volume 2, pages
86–97. Springer.
Klinov, P. (2008). Pronto: A non-monotonic probabilistic
description logic reasoner. In European Semantic Web
Conference, pages 822–826. Springer.
Koller, D., Levy, A., and Pfeffer, A. (1997). P-classic: A
tractable probablistic description logic. AAAI/IAAI,
1997(390-397):14.
Lukasiewicz, T. (2007). Probabilistic description logic pro-
grams. International Journal of Approximate Reason-
ing, 45(2):288–307.
Lukasiewicz, T. (2008). Expressive probabilistic descrip-
tion logics. Artificial Intelligence, 172(6-7):852–883.
Lukasiewicz, T. and Straccia, U. (2008). Managing uncer-
tainty and vagueness in description logics for the se-
mantic web. Web Semantics: Science, Services and
Agents on the World Wide Web, 6(4):291–308.
Niepert, M., Noessner, J., and Stuckenschmidt, H. (2011).
Log-linear description logics. In Twenty-Second Inter-
national Joint Conference on Artificial Intelligence.
Nilsson, N. J. (1986). Probabilistic logic. Artificial intelli-
gence, 28(1):71–87.
Riguzzi, F., Bellodi, E., Lamma, E., and Zese, R. (2015).
Probabilistic description logics under the distribution
semantics. Semantic Web, 6(5):477–501.
Van Asch, V. (2013). Macro-and micro-averaged evaluation
measures [[basic draft]]. Belgium: CLiPS, pages 1–
27.
Zolin, E. (2013). Complexity of reasoning in description
logics.
Axiom-based Probabilistic Description Logic
389
