
COMPREHENSIBLE CREDIT-SCORING KNOWLEDGE
VISUALIZATION USING DECISION TABLES AND DIAGRAMS
Christophe Mues, Johan Huysmans, Jan Vanthienen
K.U.Leuven
Naamsestraat 69, B-3000 Leuven, Belgium
Bart Baesens
University of Southampton
School of Management, SO17 1BJ Southampton, UK
Keywords:
Credit scoring, neural network rule extraction, decision tables, decision diagrams.
Abstract:
One of the key decision activities in financial institutions is to assess the credit-worthiness of an applicant for a
loan, and thereupon decide whether or not to grant the loan. Many classification methods have been suggested
in the credit-scoring literature to distinguish good payers from bad payers. Especially neural networks have
received a lot of attention. However, a major drawback is their lack of transparency. While they can achieve
a high predictive accuracy rate, the reasoning behind how they reach their decisions is not readily available,
which hinders their acceptance by practitioners. Therefore, we have, in earlier work, proposed a two-step
process to open the neural network black box which involves: (1) extracting rules from the network; (2)
visualizing this rule set using an intuitive graphical representation. In this paper, we will focus on the second
step and further investigate the use of two types of representations: decision tables and diagrams. The former
are a well-known representation originally used as a programming technique. The latter are a generalization
of decision trees taking on the form of a rooted, acyclic digraph instead of a tree, and have mainly been studied
and applied by the hardware design community. We will compare both representations in terms of their ability
to compactly represent the decision knowledge extracted from two real-life credit-scoring data sets.
1 INTRODUCTION
One of the key decisions financial institutions have
to make as part of their daily operations is to de-
cide whether or not to grant a loan to an applicant.
With the emergence of large-scale data-storing facil-
ities, huge amounts of data have been stored regard-
ing the repayment behavior of past applicants. It is
the aim of credit scoring to analyze this data and
build data-mining models that distinguish good appli-
cants from bad applicants using characteristics such
as amount on savings account, marital status, purpose
of loan, etc. Many machine-learning and statistical
techniques have been suggested in the literature to
build credit-scoring models (Baesens et al., 2003c;
Thomas, 2000). Amongst the most popular are tra-
ditional statistical methods (e.g. logistic regression
(Steenackers and Goovaerts, 1989)), nonparametric
statistical models (e.g. k-nearest neighbor (Henley
and Hand, 1997) and classification trees (David et al.,
1992)) and neural networks (Baesens et al., 2003b).
However, when looking at today’s credit-scoring
practice, one typically sees that the estimated clas-
sification models, although often based on advanced
and powerful algorithms, fail to be successfully inte-
grated into the credit decision environment. One of
the key underlying reasons for this problem, is that
the extracted knowledge and patterns can not easily be
represented in a way that facilitates human interpreta-
tion and validation. Hence, properly visualizing the
knowledge and patterns extracted by a data-mining
algorithm is becoming more and more a critical suc-
cess factor for the development of decision-support
systems for credit scoring.
Therefore, in this paper, we report on the use of dif-
ferent knowledge visualization formalisms for credit
scoring. Starting from a set of propositional if-then
rules previously extracted by a powerful neural net-
work rule extraction algorithm, we will investigate
both decision tables and decision diagrams as alterna-
tive knowledge visualization schemes. The latter are
a generalization of decision trees taking on the form
of a rooted, acyclic digraph instead of a tree, and have
mainly been studied and applied by the hardware de-
sign community. We will compare both representa-
tions in terms of their ability to compactly represent
the decision knowledge extracted from two real-life
credit-scoring data sets.
226
Mues C., Huysmans J., Vanthienen J. and Baesens B. (2004).
COMPREHENSIBLE CREDIT-SCORING KNOWLEDGE VISUALIZATION USING DECISION TABLES AND DIAGRAMS.
In Proceedings of the Sixth International Conference on Enterprise Information Systems, pages 226-232
DOI: 10.5220/0002598602260232
Copyright
c
SciTePress
This paper is organized as follows. Section 2 dis-
cusses the basic concepts of decision tables. Section
3 then elaborates on how decision diagrams may pro-
vide an alternative, more concise view of the extracted
patterns. Empirical results are presented in section 4.
Section 5 concludes the paper.
2 DECISION TABLES
Decision tables (DTs) are a tabular representation
used to describe and analyze decision situations (e.g.
credit-risk evaluation), where the state of a number of
conditions jointly determines the execution of a set
of actions. A DT consists of four quadrants, sep-
arated by double-lines, both horizontally and verti-
cally. The horizontal line divides the table into a
condition part (above) and an action part (below).
The vertical line separates subjects (left) from entries
(right). The condition subjects are the criteria that are
relevant to the decision-making process. They repre-
sent the attributes of the rule antecedents about which
information is needed to classify a given applicant as
good or bad. The action subjects describe the pos-
sible outcomes of the decision-making process (i.e.,
the classes of the classification problem: applicant =
good or bad). Each condition entry describes a rele-
vant subset of values (called a state) for a given con-
dition subject (attribute), or contains a dash symbol
(‘-’) if its value is irrelevant within the context of that
column (‘don’t care’ entry). Subsequently, every ac-
tion entry holds a value assigned to the corresponding
action subject (class). True, false and unknown action
values are typically abbreviated by ‘×’, ‘-’, and ‘.’, re-
spectively. Every column in the entry part of the DT
thus comprises a classification rule, indicating what
action(s) apply to a certain combination of condition
states. E.g., in Figure 1 (b), the final column tells us
to classify the applicant as good if owns property =
no, and savings amount = high.
If each column only contains simple states (no con-
tracted or don’t care entries), the table is called an
expanded DT, whereas otherwise the table is called
a contracted DT. Table contraction can be achieved
by combining logically adjacent (groups of) columns
that lead to the same action configuration. For ease of
legibility, we will allow only contractions that main-
tain a lexicographical column ordering, i.e., in which
the entries at lower rows alternate before the entries
above them; see Figure 1 (Figure 2) for an example of
an (un)ordered DT, respectively. As a result of this or-
dering restriction, a decision tree structure emerges in
the condition entry part of the DT, which lends itself
very well to a top-down evaluation procedure: starting
at the first row, and then working one’s way down the
table by choosing from the relevant condition states,
one safely arrives at the prescribed action (class) for a
given case. The number of columns in the contracted
table can be further minimized by changing the order
of the condition rows. It is obvious that a DT with a
minimal number of columns is to be preferred since
it provides a more parsimonious and comprehensible
representation of the extracted knowledge than an ex-
panded DT (see Figure 1).
1. Owns property? yes no
2. Years client ≤ 3 >3 ≤ 3 >3
3. Savings amount low high low high low high low high
1. Applicant=good - × × × - × - ×
2. Applicant=bad × - - - × - × -
(a) Expanded DT
1. Owns property? yes no
2. Years client ≤ 3 >3 -
3. Savings amount low high - low high
1. Applicant=good - × × - ×
2. Applicant=bad × - - × -
(b) Contracted DT
1. Savings amount low high
2. Owns property? yes no -
3. Years client ≤ 3 >3 - -
1. Applicant=good - × - ×
2. Applicant=bad × - × -
(c) Minimum-size contracted DT
Figure 1: Minimizing the number of columns of a lexico-
graphically ordered DT.
1. Savings amount high - low low
2. Owns property? - yes no -
3. Years client - >3 - ≤ 3
1. Applicant=good × × - -
2. Applicant=bad - - × ×
Figure 2: Example of an unordered DT.
Note that we deliberately restrict ourselves to
single-hit tables, wherein columns have to be mutu-
ally exclusive, because of their advantages with re-
spect to verification and validation (Vanthienen et al.,
1998). It is this type of DT that can be easily checked
for potential anomalies, such as inconsistencies (a
particular case being assigned to more than one class)
or incompleteness (no class assigned). The decision
table formalism thus facilitates the expert’s assess-
ment of the knowledge extracted by e.g. a neural net-
work rule extraction algorithm. What’s more, consult-
ing a DT in a top-down manner, as suggested above,
should prove more intuitive, faster, and less prone to
human error, than evaluating a set of rules one by one.
3 DECISION DIAGRAMS
Decision diagrams are a graph-based representation
of discrete functions, accompanied by a set of graph
algorithms that implement operations on these func-
COMPREHENSIBLE CREDIT-SCORING KNOWLEDGE VISUALIZATION USING DECISION TABLES AND
DIAGRAMS
227

tions. Given the proper restrictions (cf. infra), deci-
sion diagrams have a number of valuable properties:
• they provide a canonical function representation;
• they can be manipulated efficiently;
• for many practically important functions, the corre-
sponding descriptions turn out to be quite compact.
Precisely these properties explain why various types
of diagrams have been used successfully in efficiently
solving many logic synthesis and verification prob-
lems in the hardware design domain. Especially bi-
nary decision diagrams (BDDs) have, since the work
of Bryant (Bryant, 1986), who defined the canonical
subclass of reduced ordered binary decision diagrams,
pervaded virtually every subfield in the former areas.
There are on the other hand relatively few reported
applications so far in the domain of artificial intel-
ligence (Horiyama and Ibaraki, 2002) and machine
learning (Kohavi, 1996), while their use for the vi-
sual representation of rules extracted from neural net-
works, or in the application domain of credit scoring,
has to our knowledge not been proposed before (note
that our approach differs from that presented in (Ko-
havi, 1996) in that we apply MDDs in a separate vi-
sualization step instead of during the learning itself).
Since we are dealing with general discrete (as op-
posed to binary) attributes, we will apply multi-valued
decision diagrams (MDDs), a representation similar
to BDDs but which does not restrict the outdegree
of internal nodes or the number of sink nodes (Kam
et al., 1998). An MDD is a rooted, directed acyclic
graph, with m sink nodes for every possible output
value (class). Each internal node v is labelled by a
test variable var(v) = x
i
(i = 1, ..., n), which can
take values from a finite set range(x
i
). Each such
node v has | range(x
i
) | outgoing edges, and its
successor nodes are denoted by child
k
(v), for each
k ∈ range(x
i
), respectively. An MDD is ordered
(OMDD), iff, on all paths through the graph, the test
variables respect a given linear order x
1
< x
2
< ... <
x
n
; i.e., for each edge leading from a node labelled by
x
i
to a node labelled by x
j
, it holds that x
i
< x
j
.
An OMDD is meant to represent an n-variable dis-
crete function. For a given assignment to the vari-
ables, the function value is determined by tracing a
path from the root to a sink, following the edges in-
dicated by the values assigned to the variables. The
label of the sink node specifies the function value
(class) assigned for that input. Figure 3 displays
an example of an OMDD representation for a two-
variable function, {0, 1, 2, 3} × {0, 1, 2} → {0, 1},
with respect to the variable order x
1
< x
2
.
Up to here, OMDDs are not yet uniquely deter-
mined for each function. However, by further restrict-
ing the representation, a canonical form of MDDs
is obtained, namely reduced OMDDs (ROMDD). An
OMDD is said to be reduced, iff it does not contain a
x
1
x
2
1 2
x
2
3
0
0
1
20 1 210
Figure 3: MDD example
node v whose successor nodes are all identical, and no
two distinct nodes u, v exist such that the subgraphs
rooted in u and v are isomorphic, i.e., for which:
var(u) = var(v), and child
k
(u) = child
k
(v) for
all k ∈ range(var(u)). For a given variable or-
dering, the ROMDD representation of any function
is uniquely determined (up to isomorphism), as a
result of which several properties (e.g., functional
equivalence, constant functions, etc.) become easily
testable. Conceptually, a reduced decision diagram
can be interpreted as the result of the repeated ap-
plication of two types of transformations on a deci-
sion tree or graph: one reduction rule is to bypass and
delete redundant nodes (elimination rule), the other
is to share isomorphic subgraphs (merging rule). In
Figure 4, both rules are illustrated for a simple binary
example. Note that, in practice, efficient implementa-
tions of diagram operations are used that directly pro-
duce a reduced form as the diagrams are being built.
From here on, we will use the term ‘MDD’ to denote
ROMDDs in particular.
Over the years, several BDD packages have been
developed, which implement and provide interfaces
for the manipulation of BDDs (in our experiments,
we have applied David Long’s package (Long, 2003),
developed at Carnegie Mellon University. Most often,
MDDs are implemented indirectly using these same
packages, by binary encoding multi-valued variables
(as explained in (Kam et al., 1998)). Direct MDD
implementations have also been proposed, e.g. in
(Miller and Drechsler, 1998).
4 EMPIRICAL EVALUATION
In previous research, we applied neural network rule
extraction methods to extract a set of propositional
if-then rules from a trained neural network (Baesens
et al., 2003a; Baesens et al., 2003b). The experiments
were conducted on two real-life credit-scoring data
sets and the publicly available German credit data set.
ICEIS 2004 - ARTIFICIAL INTELLIGENCE AND DECISION SUPPORT SYSTEMS
228

x
1
x
2
x
2
x
3
x
3
x
3
x
3
0 0 0 1 0 1 0 1
0 1
0
1
0 1
10 0 001 1 1
x
1
x
2
x
3
0 1
0
1
0
1
0 1
Figure 4: Decision trees (left) versus diagrams (right)
Figure 5 depicts the rule set that was extracted on the
Bene1 data set obtained from a major Benelux finan-
cial institution (3123 Obs., 33 inputs).
If Term >12 months and Purpose = cash provisioning
and Savings Account ≤ 12.40 e and Years Client ≤ 3
then Applicant = bad
If Term >12 months and Purpose = cash provisioning
and Owns Property = no and Savings Account
≤ 12.40 e then Applicant = bad
If Purpose = cash provisioning and Income > 719 e
and Owns Property = no and Savings Account ≤
12.40 e and Years Client ≤ 3 then Applicant = bad
If Purpose = second-hand car and Income > 719 e
and Owns Property = no and Savings Account ≤
12.40 e and Years Client ≤ 3 then Applicant = bad
If Savings Account ≤ 12.40 e and Economical sector
= Sector C then Applicant = bad
Default class: Applicant = good
Figure 5: Rules extracted for Bene1
It was shown that the extracted rule sets achieve a
very high classification accuracy on independent test
set data. The rule sets are both concise and easy to in-
terpret and thus provide the credit-scoring expert with
an insightful explanation. However, while proposi-
tional rules are an intuitive and well-known formal-
ism to represent knowledge, they are not necessarily
the most suitable representation in terms of structure
and efficiency of use in case-by-case decision mak-
ing. Research in knowledge representation suggests
that graphical representation formalisms can be more
readily interpreted and consulted by humans than a
set of symbolic propositional if-then rules (see e.g.
(Santos-Gomez and Darnel, 1992)).
Decision tables provide an alternative way of rep-
resenting the extracted knowledge (Wets, 1998). We
have used the PRO LOGA (Prologa, 2003) software to
construct the decision tables for the extracted rule
sets. PROLO GA is an interactive modelling tool for
computer-supported construction and manipulation of
DTs (Vanthienen and Dries, 1994). A powerful rule
language is available to help specify the DTs, and au-
tomated support is provided for several restructuring
and optimization tasks.
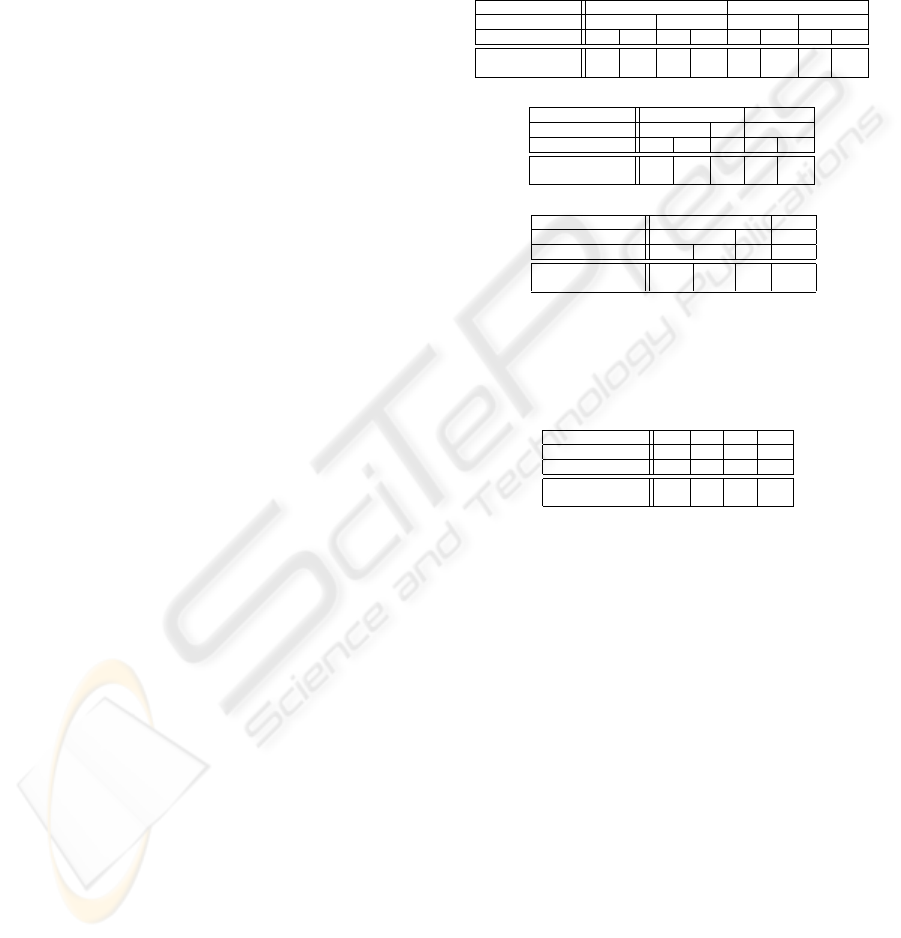
Table 1 summarizes the properties of the DTs built
from the extracted rule sets for the Bene1 and Ger-
man credit data sets. For German credit (Bene1), the
fully expanded decision table contained 6600 (192)
columns, respectively. Subsequently, we converted
each of these expanded DTs into a more compact DT,
by joining nominal attribute values that do not appear
in any rule antecedent into a common ‘other’ state,
and then performing optimal table contraction (using
a simple exhaustive search method). As a result of this
reduction process, we ended up with two minimum-
size contracted DTs, consisting of 11 and 14 columns
for the German credit and Bene1 data sets, respec-
tively (cf. right column of Table 1). Figure 6 de-
picts the resulting decision table for the Bene1 data
set. While retaining the predictive accuracy of the
original rule set, the top-down readability of such a
DT, combined with its conciseness, makes the latter
a very attractive visual representation of the extracted
knowledge. Furthermore, the DT can be easily veri-
fied: clearly, there are no missing rules or inconsis-
tencies in Figure 6.
However, a well-known property that can under-
mine the visual interpretability of decision trees, and
hence also of lexicographically ordered DTs, is the in-
herent replication of subtrees or -tables implementing
terms in disjunctive concepts (e.g. (Kohavi, 1996)).
COMPREHENSIBLE CREDIT-SCORING KNOWLEDGE VISUALIZATION USING DECISION TABLES AND
DIAGRAMS
229

Table 1: The number of columns in the expanded and mini-
mized DTs.
Data set Columns in Columns in
expanded DT minimized DT
German 6600 11
Bene1 192 14
For example, in the DT for Bene1 (cf. Figure 6),
column blocks {2, 3, 4, 5} and {9, 10, 11, 12}, though
having the same respective action values, are not eli-
gible for contraction, because they differ in more than
one condition entry (viz., with respect to the attributes
‘purpose’ and ‘term’). On the other hand, a deci-
sion diagram, which allows the sharing of one such
instance through multiple incoming edges, might be
smaller than the corresponding tree or table. There-
fore, in addition to the DT, we have built an equivalent
MDD representation based on the extracted rule set,
thereby adhering to the same ordering of attributes as
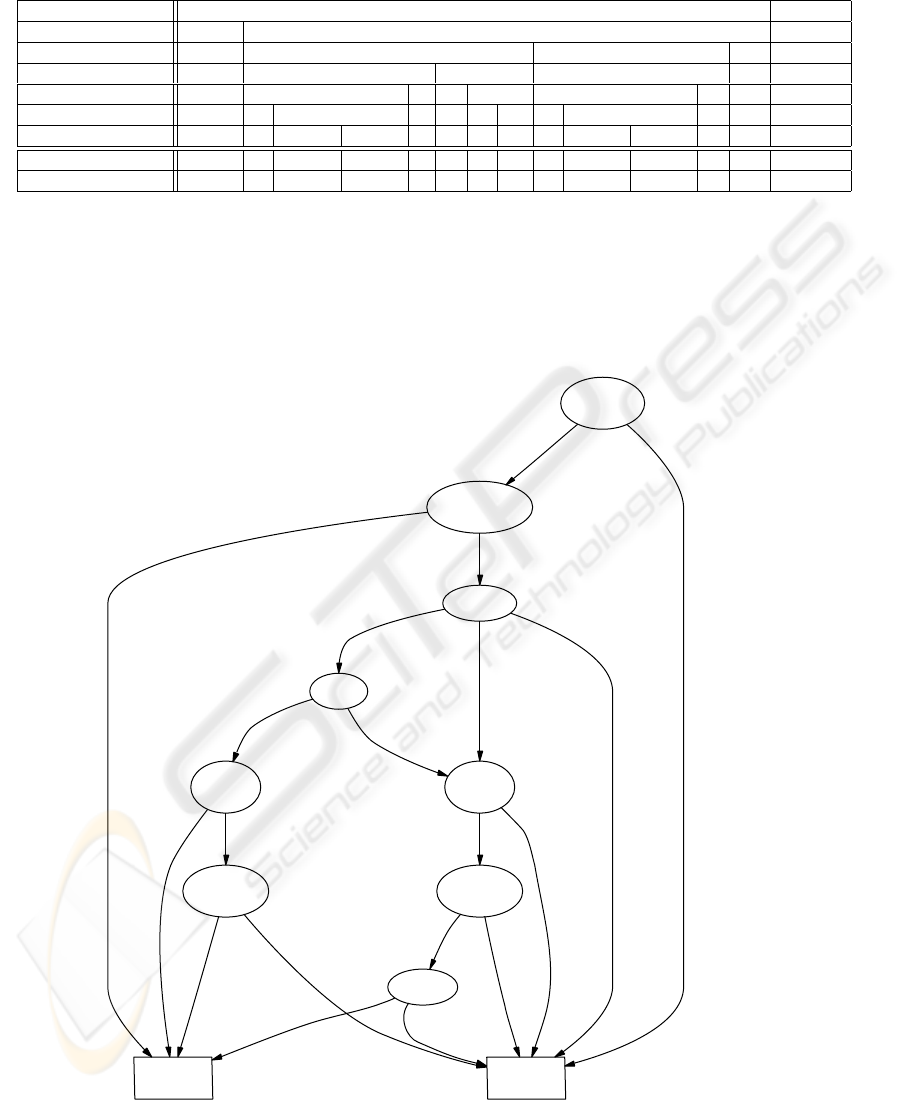
in the minimum-size DT. Figure 7 presents the re-
sulting diagram for Bene1. It was produced using
the Graphviz graph-drawing software (Gansner et al.,
1993; AT&T, 2003).
Unlike in Figure 6, the part of the MDD represen-
tation that matches the replicated table segment is in-
cluded only once: the subgraph rooted at the right-
most of the two ‘years client’-nodes is effectively
shared through its two incoming edges. Hence, de-
scribing the function in MDD format results in a more
compact representation, because the merging rule, un-
like the DT contraction rule, does apply here. This
empirically confirms why we consider a decision di-
agram to be a valuable alternative knowledge visu-
alization aid. Nevertheless, decision diagrams are so
far seldom considered in this context, despite their be-
ing a graph-based generalization of the far more fre-
quently applied decision tree representation.
We have repeated the same exercise for the Ger-
man credit data set, but in the latter case, no further
size savings could be obtained vis-`a-vis the DT rep-
resentation. In Table 2, we have summarized the re-
sults of the MDD construction process for both data
sets. Note that, because of the aforementioned rela-
tion between a decision tree and a lexicographically
ordered DT, the figures in column (2) also match the
number of splits appearing in the condition entry part
of the corresponding DT. Consequently, the final col-
umn provides a measure of the additional size gains of
MDD reduction over DT contraction (i.e., the added
effect of graph sharing).
Both decision tables and diagrams facilitate the de-
velopment of powerful decision-support systems that
can be integrated in the credit-scoring process. A DT
consultation engine typically traverses the table in a
top-down manner, inquiring the user about the con-
Table 2: MDD size results
Data set Intern. nodes Intern. nodes Size
in MDD (1) in dec. tree (2) saving
German 8 8 0%
Bene1 9 12 25%
dition states of every relevant condition encountered
along the way. A similar decision procedure is in-
duced when consulting the decision diagram repre-
sentation, and following the proper path through the
graph. Hence, both types of representations provide
efficient decision schemes that allow a system imple-
mentation to ask targeted questions and neglect irrel-
evant inputs during the question/answer-dialog. Fur-
thermore, given the availability of efficient condition
reordering operations for both types of representa-
tions, questions can be easily postponed during this
process. For example, in PRO LOG A, the available an-
swer options always include an additional ‘unknown’
option, which allows the user to (temporarily) skip the
question. When that happens, the DT’s conditions are
first reordered internally: moving the corresponding
condition to the bottom of the order and then recon-
tracting the DT may result in new don’t care entries
being formed for it. After that, the session continues
with the next question. If, at some point, a conclu-
sion is reached regarding the DT’s actions, the former
question could effectively be avoided; else, it eventu-
ally pops up again.
In the Bene1 example, suppose that we are deciding
on a particular applicant whose properties will even-
tually be found to match against the condition entries
of column 12, which tells us to accept the loan. Be-
fore arriving at that conclusion, we are required to
provide only 4 of the 7 inputs to make a classifica-
tion decision: ‘term’, ‘owns property’ and ‘income’
successively turn out to be irrelevant for this case. If,
on the other hand, we would consult the rule descrip-
tion shown in Figure 5, we would need to evaluate
every single rule, thereby testing its antecedent until a
condition is found that fails, before we may conclude
that none of the rules applies and that the default class
(applicant = good) must be chosen.
5 CONCLUSIONS
In this paper, we have shown how credit-scoring
knowledge can be compactly visualized either in the
form of decision tables or diagrams. For two real-
life cases, it was first of all shown how a set of
propositional if-then rules, extracted by a neural net-
work rule extraction algorithm, can be represented
as a decision table. The constructed decision tables
ICEIS 2004 - ARTIFICIAL INTELLIGENCE AND DECISION SUPPORT SYSTEMS
230
1. Savings Account ≤12.40 e > 12.40 e
2. Economical sector Sector C other -
3. Purpose - cash provisioning second-hand car other -
4. Term - ≤ 12 months > 12 months -
5. Years Client - ≤ 3 >3 ≤ 3 >3 ≤ 3 > 3
6. Owns Property - Yes No - - Yes No Yes No - - -
7. Income - - ≤ 719 e > 719 e - - - - - ≤ 719 e > 719 e - - -
1. Applicant=good - × × - × - × - × × - × × ×
2. Applicant=bad × - - × - × - × - - × - - -
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Figure 6: Decision table for the rules extracted for Bene1.
Savings
Account
Economical
sector
<=12.40 Euro
Applicant
:= good
>12.40 Euro
Purpose
other
Applicant
:= bad
sector C
Term
cash provisioning
Years
Client
second-hand car
other
<=12 months
Years
Client
>12 months
Owns
Property
<=3
>3
Owns
Property
>3
<=3
Income
No
Yes
YesNo
<=719 Euro>719 Euro
PSfrag replacements
e
Figure 7: MDD for the Bene1 data set
COMPREHENSIBLE CREDIT-SCORING KNOWLEDGE VISUALIZATION USING DECISION TABLES AND
DIAGRAMS
231

were then reduced in size using lexicographical order-
preserving contraction and condition row order min-
imization routines which in both cases yielded a par-
simonious representation of the extracted rules, while
preserving their predictive power. Secondly, we have
advocated the use of multi-valued decision diagrams
as an alternative visualization that can provide addi-
tional size savings compared to the former DT rep-
resentation. What’s more, we have seen empirical
confirmation of this property on one of the two data
sets. Subsequently, we have demonstrated that the
use of either decision tables or diagrams facilitates an
efficient case-by-case consultation of the knowledge
(e.g., by limiting the number of questions that the user
must answer in order to reach a conclusion). Hence,
using decision tables and/or diagrams in combination
with a rule extraction algorithm provides an interest-
ing approach for developing powerful yet transparent
credit-scoring models.
REFERENCES
AT&T Laboratories (2003). Graphviz, graph-drawing tool.
http://www.research.att.com/sw/tools/graphviz/.
Baesens, B., Mues, C., Setiono, R., De Backer, M., and
Vanthienen, J. (2003a). Building intelligent credit
scoring systems using decision tables. In Proceed-
ings of the Fifth International Conference on Enter-
prise Information Systems (ICEIS’2003), pages 19–
25, Angers, France.
Baesens, B., Setiono, R., Mues, C., and Vanthienen, J.
(2003b). Using neural network rule extraction and de-
cision tables for credit-risk evaluation. Management
Science, 49(3):312–329.
Baesens, B., Van Gestel, T., Viaene, S., Stepanova, M.,
Suykens, J., and Vanthienen, J. (2003c). Benchmark-
ing state of the art classification algorithms for credit
scoring. Journal of the Operational Research Society,
54(6):627–635.
Bryant, R. (1986). Graph-based algorithms for boolean
function manipulation. IEEE Transactions on Com-
puters, C-35(8):677–691.
David, R., Edelman, D., and Gammerman, A. (1992). Ma-
chine learning algorithms for credit-card applications.
IMA Journal of Mathematics Applied In Business and
Industry, 4:43–51.
Gansner, E. R., Koutsofios, E., North, S. C., and Vo,
K. P. (1993). A technique for drawing directed
graphs. IEEE Transactions on Software Engineering,
19(3):214–230.
Henley, W. and Hand, D. (1997). Construction of a k-
nearest neighbour credit-scoring system. IMA Jour-
nal of Mathematics Applied In Business and Industry,
8:305–321.
Horiyama, T. and Ibaraki, T. (2002). Ordered binary deci-
sion diagrams as knowledge-bases. Artificial Intelli-
gence, 136(2):189–213.
Kam, T., Villa, T., Brayton, R. K., and Sangiovanni-
Vincentelli, A. L. (1998). Multi-valued decision di-
agrams: Theory and applications. International Jour-
nal on Multiple-Valued Logic, 4(1-2):9–62.
Kohavi, R. (1996). Wrappers for Performance Enhance-
ment and Oblivious Decision Graphs. PhD thesis, De-
partment of Computer Science, Stanford University.
Long, D. (2003). OBDD package. http://www-
2.cs.cmu.edu/∼modelcheck/bdd.html.
Miller, D. and Drechsler, R. (1998). Implementing a multi-
valued decision diagram package. In Proceedings
of the International Symposium on Multiple-Valued
Logic, pages 52–57, Fukuoka, Japan.
Prologa (2003). Decision table modelling tool.
http://www.econ.kuleuven.ac.be/prologa/.
Santos-Gomez, L. and Darnel, M. (1992). Empirical evalu-
ation of decision tables for constructing and compre-
hending expert system rules. Knowledge Acquisition,
4:427–444.
Steenackers, A. and Goovaerts, M. (1989). A credit scoring
model for personal loans. Insurance: Mathematics
and Economics, 8:31–34.
Thomas, L. (2000). A survey of credit and behavioural scor-
ing: forecasting financial risk of lending to customers.
International Journal of Forecasting, 16:149–172.
Vanthienen, J. and Dries, E. (1994). Illustration of a
decision table tool for specifying and implementing
knowledge based systems. International Journal on
Artificial Intelligence Tools, 3(2):267–288.
Vanthienen, J., Mues, C., and Aerts, A. (1998). An illus-
tration of verification and validation in the modelling
phase of kbs development. Data and Knowledge En-
gineering, 27:337–352.
Wets, G. (1998). Decision Tables in Knowledge-Based Sys-
tems: Adding Knowledge Discovery and Fuzzy Con-
cepts to the Decision Table Formalism. PhD thesis,
Department of Applied Economic Sciences, Catholic
University of Leuven, Belgium.
ICEIS 2004 - ARTIFICIAL INTELLIGENCE AND DECISION SUPPORT SYSTEMS
232
