
AUTOMATIC DISCOVERY OF SEMANTIC RELATIONSHIPS
BETWEEN SCHEMA ELEMENTS
Nikos Rizopoulos
Imperial College
London, England
Keywords:
Automatic schema matching, semantic relationships, data integration.
Abstract:
The identification of semantic relationships between schema elements, or schema matching, is the initial step
in the integration of data sources. Existing approaches in automatic schema matching have mainly been con-
cerned with discovering equivalence relationships between elements. In this paper, we present an approach
to automatically discover richer and more expressive semantic relationships based on a bidirectional compar-
ison of the elements data and metadata. The experiments that we have performed on real-world data sources
from several domains show promising results, considering the fact that we do not rely on any user or external
knowledge.
1 INTRODUCTION
The integration of heterogeneous data sources is a
well-known research subject. Its key issue is the iden-
tification of semantic relationships between schema
elements (Kashyap and Sheth, 1996), which is a
labor-intensive and time-consuming process when
performed manually. Automatic schema matching re-
solves this problem by automatically discovering se-
mantic relationships between schema elements.
Several approaches can be found in the literature
concerned with automatic schema matching. Most
of them are focused on discovering equivalence rela-
tionships between elements. However, in many cases
more expressive relationships exist. For example, ele-
ment person subsumes student and the elements post-
graduate and undergraduate can be merged into stu-
dent. Such matches are called indirect (Xu and Emb-
ley, 2003).
Example: Figure 1 illustrates cut-down represen-
tations of two databases of the Computing Depart-
ment at Imperial College, London.
Schema S
1
shows that staff members tutor under-
graduate students and supervise PhD students. In S
1
,
the element course represents all the non-laboratory
courses, i.e. all the courses that have lectures in
theatres. Undergraduate students register on these
courses and members of staff teach them. In the
college, PhD students assist in both tutorials and lab
demonstrations. This is depicted in schema S
2
, where
course describes both laboratory courses and courses
that have tutorials. Element staff in S
2
represents the
members of staff that supervise tutorials and labora-
tories and can be both lecturers or teaching assistants.
We have asserted the constraints that each PhD stu-
dent has to assist in at least one course and each
lecturer has to teach at least one non-laboratory
course and supervise one laboratory course. Also,
non-laboratory courses might not have any tutorials.
These constraints implicitly express that the phd el-
ements in S
1
and S
2
represent identical sets of PhD
students (direct match), that the concept of staff in S
2
subsumes the concept of staff in S
1
(indirect match)
and that the two course elements intersect since both
include those non-laboratory courses that have tutori-
als (indirect match).
In this paper, we describe a framework to automat-
ically discover matches like the ones in the example.
Our goal is to identify semantic relationships between
elements without relying on external knowledge, like
ontologies, user-knowledge or schema structure. We
adopt a composite approach that exploits several types
of information (element names, data instances, statis-
tical information on the data) to discover incompati-
ble, disjoint, intersecting, subsumming and equiv-
alent elements. Our methodology performs a bidirec-
tional comparison of the elements, which proves to be
indicatory of these types of semantic relationships.
3
Rizopoulos N. (2004).
AUTOMATIC DISCOVERY OF SEMANTIC RELATIONSHIPS BETWEEN SCHEMA ELEMENTS.
In Proceedings of the Sixth International Conference on Enterprise Information Systems, pages 3-8
DOI: 10.5220/0002611900030008
Copyright
c
SciTePress

ug
ug login
ugname
phd
phd login
pname
course
course id
cname
tch
staff
staff login
sname
tut
sup
reg
S
1
staff
staff login
sname
phd
phd login
assist
course
course id
cname
hours
date
activity
S
2
Figure 1: Source Schemas S
1
and S
2
This paper contributes in the formal definition of
semantic relationships between schema elements and
the automatic discovery of these relationships. As far
as we know, no other automatic schema matching ap-
proach discovers disjointness and intersection rela-
tionships without relying on external knowledge. In
addition, this paper proposes an innovative compos-
ite architecture which differentiates between modules
that identify schema matches and modules that clarify
the type of the relationship in each match.
The structure of this paper is as follows. In Sec-
tion 2, we define the five types of semantic relation-
ships that our methodology identifies. Section 3 ex-
plains the way a bidirectional comparison of schema
elements can assist in the clarification of their se-
mantic relationship. Section 4 shows the architecture
of our framework and describes the implemented re-
lationship identification and relationship clarification
modules. In Section 5 the results of the experiments
we have conducted to evaluate our approach are pre-
sented. Section 6 describes related schema match-
ing approaches and Section 7 gives our concluding
remarks and directions for further work.
2 SEMANTIC RELATIONSHIPS
Various types of semantic relationships between
schema elements have been defined in the literature.
In (Larson et al., 1989), a non-automated approach
for schema integration is proposed, based on man-
ually identified semantic relationships between ele-
ments. We adopt similar relationship definitions, ex-
cept from disjointness and incompatibility. We de-
fine Inst
ext
(x) to be the instances of an element
x that are currently stored in the data source, and
Dom
ext
(x) the extentional domain of the element,
i.e. all its possible valid instances. We also define as
Ent
int
(x) the intentional entities of x, i.e. the real-
world entities that map to the instances of Inst
ext
(x),
and Dom
int
(x) the intentional domain of x, i.e. the
real-world entities that map to Dom
ext
(x).
Five types of semantic relationship between
schema elements are identified based on the compari-
son of their intensional domains. These relationships
are:
1. equivalence: Two schema elements A and B are
equivalent, A = B, iff
Dom
int
(A) = Dom
int
(B)
2. subsumption: Schema element A subsumes
schema element B, B ⊂ A, iff
Dom
int
(B) ⊂ Dom
int
(A)
3. intersection: Two schema elements A and B are
intersecting, A ∩ B, iff
Dom
int
(A) ∩ Dom
int
(B) 6= ∅,
∃C : Dom
int
(A) ∩ Dom
int
(B) = Dom
int
(C)
4. disjointness: Two schema elements A and B are
disjoint, A
/
∩B, iff
Dom
int
(A) ∩ Dom
int
(B) = ∅,
∃C : Dom
int
(A) ∪ Dom
int
(B) ⊆ Dom
int
(C)
5. incompatibility: Two schema elements A and B
are incompatible, A 6= B, iff
Dom
int
(A) ∩ Dom
int
(B) = ∅,
¬∃C : Dom
int
(A) ∪ Dom
int
(B) ⊆ Dom
int
(C)
The notation ∃C : condition means that there is
a real-world concept that can be represented by an
existing or non-existing schema element C that sat-
isfies the condition. The notation ¬∃C : condition
in the definition of incompatibility means that there is
no real-world concept that would be represented by a
schema element C to satisfy the specified condition.
Throughout this paper, we are going to use the term
semantically compatible schema elements when ele-
ments are related with a semantic relationship other
than incompatibility.
There are four pairs of compatible elements in the
example of the previous section. The phd elements
in S
1
and S
2
are equivalent because they represent
identical sets of PhD students based on the constraint
that each PhD student in S
1
must assist in at least one
course, i.e. each entity of S
1
.phd belongs to the set
of entities represented by S
2
.phd and vice versa. The
elements ug and phd in S
1
and S
2
respectively are
disjoint because each student in this particular exam-
ple can be either an undergraduate or a PhD student.
Thus, there is a concept (student) that subsumes the
union of ug and phd. Element staff in S
2
subsumes
staff in S
1
, because S
2
.staff represents all the lectur-
ers, i.e. all the entities of S
1
.staff, in addition to teach-
ing assistants. The two course elements intersect
because they have a common set of entities that can
be represented by the concept courses
with tutorials;
ICEIS 2004 - DATABASES AND INFORMATION SYSTEMS INTEGRATION
4

some courses of S
1
have tutorials, i.e. they belong
to the entities represented by S
2
.course, and the lab
courses of S
2
.course are not included in S
1
.course.
3 DISCOVERING SEMANTIC
RELATIONSHIPS
In order to discover the semantic relationships de-
fined in the previous section, we perform a bidirec-
tional comparison of the schema elements. Suppos-
ing that there are two schema elements X and Y , we
define as d(X, Y ) the similarity degree produced by
the comparison of element X against Y and d(Y, X)
the similarity degree produced by the comparison of
Y against X. We call d(X, Y ) and d(Y, X) bidirec-
tional similarity degrees. Intuitively, the more similar
X is to Y , the higher the similarity degree d(X, Y )
will be. Essentially, d(X, Y ) indicates to what extent
X, with Dom
int
(X) 6= ∅, is a subset of Y , ranging
from 0, if none of the entities of X are entities of Y ,
to 1, if the set of entities of X is a proper subset of
the entities of Y . This can also be described by the
following formula:
d(X, Y ) =
|Dom
int
(X)∩Dom
int
(Y )|
|Dom
int
(X)|
,
where |S| defines the number of entities in set S.
The above formula will give high bidirectional sim-
ilarity degrees for equivalent elements, high d(X, Y )
and low d(Y, X) when Y subsumes X and average-
high bidirectional degrees when the elements inter-
sect. The problems arising when using this formula
are: (a) it cannot be computed automatically since
the comparison of the elements’ real-world entities
(Dom
int
(X)) is required, and (b) it cannot differen-
tiate between incompatibility and disjointness, since
in both of these cases the intensional domains of the
elements are disjoint, producing bidirectional similar-
ity degrees with values equal to 0. A more detailed
description of the problems arising when an idealized
approach, like the above formula, is used to discover
semantic relationships between schema elements can
be found in (Rizopoulos, 2003).
In our framework, we attempt to resemble the
same formula by examining the elements instances
(Inst
ext
(X)) and their metadata, e.g. data types,
names, lengths, etc. Based on this information, even
disjoint elements exhibit similarity, which arises from
their relationship with the same super element C
(see definition in the previous section). For exam-
ple, usernames of PhD (phd
login) and undergradu-
ate (ug login) students follow the same format as any
student username (login). Therefore, our approach re-
solves the problems mentioned previously: (a) auto-
matic computation of the similarity degrees is feasi-
ble because element instances and metadata are freely
6
-
X 6= Y
X = YX ⊂ Y
Y ⊂ X
X ∩ Y
X
/
∩Y
1
1
0 d(Y, X)
d(X, Y )
equivalence
threshold
intersection
threshold
disjointness
threshold
disjointness
threshold
intersection
threshold
equivalence
threshold
equivalence pair
subsumption pair
intersection pair
disjointness pair
incompatibility pair
Figure 2: Bidirectional Similarity Comparison Graph
available and (b) disjointness and incompatibility can
be distinguished because disjoint pairs of elements
will have higher bidirectional similarity degrees than
incompatible pairs. In the case of intersecting ele-
ments, their common set of entities in their intensional
domains defines a common set of instances in their
extensional domains, i.e. the relationship is preserved
across the domains. Thus, intersecting pairs of ele-
ments are going to display higher similarity degrees
than disjoint pairs. Relationship preservation also ap-
plies to subsumption and equivalence, which suggests
that the same bidirectional similarity degrees should
be expected whether the intensional or the extensional
domains of the elements are examined.
Based on these observations, our insight on the way
the bidirectional comparison can be applied in the
identification of semantic relationships between ele-
ments is illustrated in Figure 2, the bidirectional com-
parison graph. The graph shows the areas where we
expect the bidirectional degrees to position each pair
of elements based on their semantic relationship. It is
important to notice that the defined areas in the graph
are fuzzy areas because they only represent an esti-
mation of the expected results. For the same reason
some areas of the graph are not covered.
4 ARCHITECTURE
In this section, we describe our framework’s architec-
ture (Figure 3) and present each implemented compo-
nent.
Our framework consists of several comparison
modules that exploit different types of information to
determine the similarity of schema elements. These
modules take as input the source schemas and their
data instances and work independently to produce
partial bidirectional similarity degrees. Partial in the
sense that they are produced by just comparing partial
AUTOMATIC DISCOVERY OF SEMANTIC RELATIONSHIPS BETWEEN SCHEMA ELEMENTS
5

-
S
A
-
S
B
m
6
. . .
m
6
. . .
m
6
. . .
m
6
. . .
partial bidirectional similarity degrees
Filter
6 6
. . .
6 6
. . .
bidirectional similarity degrees of compatible elements
Aggregator
6
aggregated bidirectional
similarity degrees
Degree Combinator
-
thresholds
6
semantic relationships
¾
¾
clarification
similarity degrees
relationship identification modules
µ
relationship clarification modules
K
Figure 3: Architecture
information, e.g. element names only, and are there-
fore partially correct. These degrees are later com-
bined to provide the final bidirectional similarity de-
grees, which indicate (according to the discussion in
the previous section) the semantic relationships be-
tween the schema elements.
In our framework, there are two types of modules:
relationship identification and relationship clarifica-
tion modules. Relationship identification modules at-
tempt to discover compatible pairs of elements and
relationship clarification modules attempt to specify
the type of the semantic relationship in each compat-
ible pair.
Initially, the bidirectional similarity degrees pro-
duced by the modules are examined by the Filter com-
ponent to separate the compatible from the incompati-
ble pairs of elements. Then, the Aggregator combines
the similarity degrees of the compatible elements and
indicates their semantic relationships. It achieves this
by mapping the compatible pairs onto the bidirec-
tional graph. The output of the Aggregator becomes
the input of the Degree Combinator, which based on
the relationship clarification modules and the fuzzy
areas defined in the bidirectional graph outputs the
discovered semantic relationships. The user is then
able to validate or reject these relationships and pro-
ceed to the data integration process.
All the components of the architecture that have
been implemented in the prototype tool are now
briefly described. More details can be found in (Ri-
zopoulos, 2003).
The Element Name Module performs a case-
insensitive comparison of element names. When el-
ement X has exactly the same name with Y then
d(X, Y ) = d(Y, X) = 1 and if X’s name is a sub-
string of Y ’s then d(X, Y ) = 0.2 and d(Y, X) = 1.
The similarity degrees have been chosen so that when
two elements have the same names, then their bidi-
rectional similarity degrees are going to map them in
the equivalence area of the graph. If one element is a
substring of another, e.g. login and phd login, then this
is an indication of a subsumption relationship, there-
fore the pair is mapped in the subsumption areas of
the graph.
The rest of the modules operate in a similar way.
The Data Type Module compares element data types.
The Numerical Statistics Module compares numer-
ical elements on their average value, medium value
and the standard deviation of their instances. The
Non-numerical Statistics Module compares non-
numerical elements based on the average number of
appearances of special characters (@, $, -, etc) in their
instances. The Instances Module uses a Naive Bayes
classifier to identify similarities between elements by
comparing their instances. The Number of Instances
Module is a naive module that is used for relation-
ship clarification and compares the number of distinct
instances of the elements. The Precision Module
is a relationship clarification module that compares
the range of each element’s instances and the Length
Module compares the range of the elements’ lengths.
The Existence Module is a relationship clarification
module that examines the existence of instances in el-
ements.
The Filter component separates the compatible
from the incompatible pairs of elements. For each
pair, it computes the average bidirectional similarity
degrees and compares them to a user-defined thresh-
old. The Aggregator component indicates the type
of the semantic relationship for each pair of compati-
ble elements by computing the product bidirectional
similarity degrees. Modules in both the Filter and
the Aggregator can have auxiliary roles, i.e. they can
only increase the similarity degrees produced by other
modules. The Degree Combinator uses the output of
the relationship clarification modules and the Aggre-
gator to determine the semantic relationships between
the elements.
5 EXPERIMENTS
We have evaluated our prototype tool on three schema
matching tasks of real-world data sources that come
from three different domains.
The first task, called Pop&Geo, is between two data
sources with geography and population data. The sec-
ond task, University, is on two relational databases
that store information about tutorials and students,
and the third task, Real-Estate, in on two real-estate
ICEIS 2004 - DATABASES AND INFORMATION SYSTEMS INTEGRATION
6
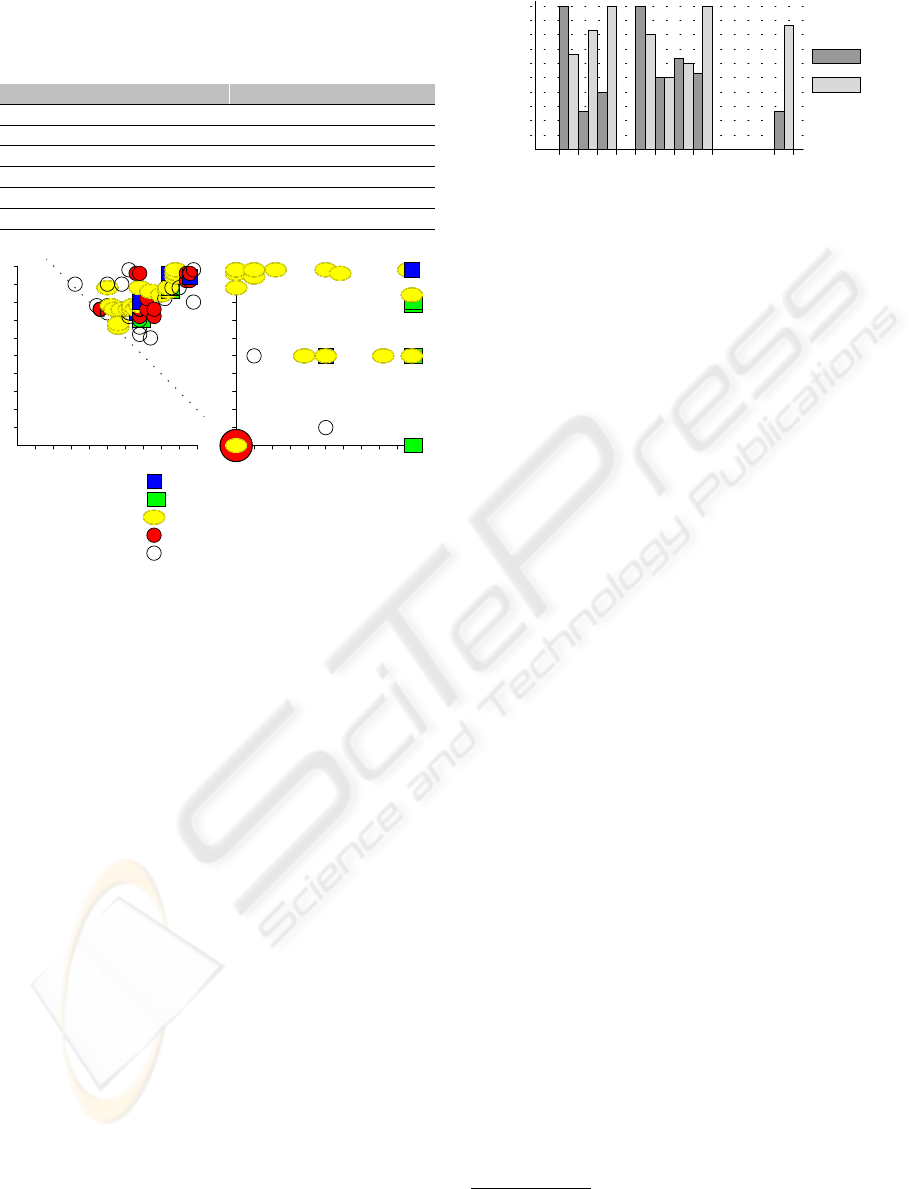
Table 1: Problem Size and Schema Similarity in each Inte-
gration Task
Pop&Geo University Real-Estate
#pairs 897 4389 868
#equivalents 0 7 0
#subsets 12 6 0
#intersections 8 46 0
#disjoints 18 57 18
#incompatibles 859 4273 850
threshold
0
.1 .2 .3 .4 .5 .6 .7 .8 .9 1
.1
.2
.3
.4
.5
.6
.7
.8
.9
1
equivalence pair
subsumption pair
intersection pair
disjointness pair
incompatibility pair
(a) Filter
0
.1 .2 .3 .4 .5 .6 .7 .8 .9 1
.1
.2
.3
.4
.5
.6
.7
.8
.9
1
(b) Aggregator
Figure 4: Filter and Aggregator Results
data sources that list houses for sale.
Table 1 presents the problem size and the schema
similarity in each matching task. It shows the number
of all possible pairs of elements between the schemas
and for each type of semantic relationship the number
of its appearances manually detected. The semantic
relationships discovered by the tool are compared to
these manually identified relationships.
Figure 4 illustrates the results of the Filter and Ag-
gregator components for the University task. Each
pair of elements is plotted using the appropriate sum-
bol based on the manually identified relationship of
the pair. The position where each pair is plotted de-
pends on the bidirectional degrees produced by the
tool. In Figure 4(a), the pairs of elements below the
user-defined threshold have been omitted for clarity.
As it can be seen, the Filter discards most of the in-
compatible pairs and the Aggregator attempts to map
the compatible ones onto the correct areas of the com-
parison graph.
To examine the reliability and the cover of the tool,
i.e. how many relationships are identified correctly
and how many relationships are indeed identified, we
have used precision and recall. If C is the number
of the correctly identified relationships, F the num-
ber of the incorrectly identified relationships and A
all the manually identified relationships, then preci-
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
⊂ ∩
/
∩
Pop&Geo
= ⊂ ∩
/
∩
University
/
∩
Real-Estate
Precision
Recall
Figure 5: Precision and Recall
sion is the fraction C/(C + F ) and recall is C/A.
Figure 5 shows the precision and recall of the tool for
each type of semantic relationship in each task. In the
first task, the precision and recall bars for the equiv-
alence relationship are missing because there do not
exist any equivalent elements between the schemas.
The same applies in the third task where there are not
any equivalent, subsuming or intersecting elements.
In the first experiment, the low precision for in-
tersection and disjointness comes from incompatible
pairs of elements with intersecting ranges. The high
recall in the first experiment means that very few rela-
tionships are lost and therefore the user will only have
to reject the wrongly identified ones.
In the second experiment the main problems are
caused by (a) elements that are sequences of numbers,
in particular automatically incremented primary key
attributes, (b) elements that have a small number of
distinct instances, and (c) character elements whose
instances are small strings.
In the third experiment, the precision for disjoint-
ness is affected by incompatible pairs of elements that
should have been discarded by the Filter. The prob-
lems are caused by composite elements that contain
multiple values in each one of their instances, and el-
ements with small numerical instances.
Overall in the three experiments, the average preci-
sion for each semantic relationship is 100% for equiv-
alence, 75% for subsumption, 46% for intersection
and 39% for disjointness. The average recall is 77%
for equivalence, 58% for subsumption, 71% for inter-
section and 96% for disjointness
1
. These results are
encouraging, considering the fact that there was no
user intervention on the data or the data sources. In
addition, no external knowledge was used, like user-
supplied training data, user-defined concept hierar-
chies, synonym tables, online ontologies, dictionar-
ies, etc, neither any assumptions were made about the
data instances or the sources.
1
The average values for the equivalence relationship
come from the University task, but in general we expect
high precision and recall for equivalence in all tasks.
AUTOMATIC DISCOVERY OF SEMANTIC RELATIONSHIPS BETWEEN SCHEMA ELEMENTS
7

6 RELATED WORK
Several approaches concerned with automatic schema
matching exist in the literature. Most of the ap-
proaches are focused in discovering equivalence re-
lationships (A. Doan and Halevy, 2002; Madhavan
et al., 2001), some of them also identify subsumption
relationships (Bergamaschi et al., 1998) and some in-
tersection (Hakimpour and Geppert, 2002). How-
ever, subsumption and intersection are discovered us-
ing external knowledge, like ontologies and thesauri,
or user-knowledge. Our approach identifies equiva-
lence, subsumption, intersection and disjointness re-
lationships by only examining element metadata and
data instances, without any user-intervention.
The work most related to ours is the one presented
in (Xu and Embley, 2003), where direct and indi-
rect matches between elements are discovered. Di-
rect matches are identified between equivalent ele-
ments and indirect matches are identified between
(a) subsuming elements, (b) boolean elements and
elements whose instances contain the boolean ele-
ments’ names, and (c) elements whose instances can
be merged or splitted. These relationships are dis-
covered based on schema information, ontologies and
regular expressions defined to match the instances of
elements.
Our framework covers all the relationships of (Xu
and Embley, 2003), except from the last one (c) which
in some cases is similar to our disjointness relation-
ship. In the case of boolean elements, our methodol-
ogy replaces their true and false instances with the
elements’ names and the concatenation of not and
their names, respectively, since the actual instances
do not provide much information. Therefore, if one
element contains the name of a boolean element in
its instances, this relationship will be identified. In
our framework, we also identify intersecting elements
that are not considered in (Xu and Embley, 2003).
GLUE (A. Doan and Halevy, 2002) is also similar
to our work. It proposes a bidirectional comparison
of schema elements, but it produces a single similar-
ity degree which takes the lowest value when the el-
ements do not have any common instances and the
highest when the elements are equivalent. Therefore,
the semantic relationships described in this paper can-
not be discovered by this approach.
7 CONCLUSIONS
In this paper, we have presented our approach to au-
tomatically discover semantic relationships between
schema elements. Based on a bidirectional compari-
son of the elements metadata and instances and with-
out any user or external knowledge, we are able to
discover equivalence, subsumption, intersection, dis-
jointness and incompatibility relationships. We have
shown our framework’s architecture and described the
components that we have implemented in the pro-
totype tool. Our experimental results are promising
with a 66% average precision and 75% average recall.
In the future, we are going to focus in the filtering
process, since low precision has been mainly caused
by incompatible pairs of elements that have not been
discarded. We can consider assinging weights to
modules based on their importance and reliability.
Precision can also be improved by detecting automat-
ically incremented elements and elements with small
domains. A brute-force module can assist in this pro-
cess and it would only impose a small overhead to
exhaustively compare a small number of instances.
Additionally, in the future we are going to extend
our prototype tool with a graphical user interface,
which will permit the user to validate or reject the se-
mantic relationships identified by our methodology,
and a component which will integrate the input data
sources based on the validated relationships.
REFERENCES
A. Doan, J. Madhavan, P. D. and Halevy, A. (2002). Learn-
ing to map ontologies on the Semantic Web. In Pro-
ceedings of the World-Wide Web Conference (WWW-
02), pages 662–673.
Bergamaschi, S., Castano, S., di Vimercati, S., Montanari,
S., and Vincini, M. (1998). An intelligent approach
to information integration. In In International Con-
ference on Formal Ontology in Information Systems
(FOIS’98), Italy, 1998, pages 253–267.
Hakimpour, F. and Geppert, A. (2002). Global schema
generation using formal ontologies. In Proceedings
of ER02, volume 2503 of LNCS, pages 307–321.
Springer-Verlag.
Kashyap, V. and Sheth, A. (1996). Semantic and schematic
similarities between database objects: a context-
based approach. VLDB Journal, 5(4):276–304.
Larson, J., Navathe, S., and Elmasri, R. (1989). A theory of
attribute equivalence in databases with application to
schema integration. IEEE Transactions on Software
Engineering, 15(4):449–463.
Madhavan, J., Bernstein, P. A., and Rahm, E. (2001).
Generic schema matching with Cupid. In Proc. 27th
VLDB Conference, pages 49–58.
Rizopoulos, N. (2003). Discovery of semantic relationships
between schema elements. Technical report, AutoMed
Project.
Xu, L. and Embley, D. W. (2003). Discovering direct and
indirect matches for schema elements. In 8th Interna-
tional Conference on Database Systems for Advanced
Applications (DASFAA ’03), Kyoto, Japan, March 26–
28, 2003, pages 39–46.
ICEIS 2004 - DATABASES AND INFORMATION SYSTEMS INTEGRATION
8
