
RJDBC: A SIMPLE DATABASE REPLICATION ENGINE
∗
Javier Esparza Peidro, Francesc D. Mu
˜
noz-Esco
´
ı, Luis Ir
´
un-Briz, Josep M. Bernab
´
eu-Aub
´
an
Instituto Tecnol
´
ogico de Inform
´
atica
Universidad Polit
´
ecnica de Valencia
46071 Valencia, SPAIN
Keywords:
Replication, fault tolerance, reliability, distributed systems, databases, middleware, systems integration
Abstract:
Providing fault tolerant services is a key question among many services manufacturers. Thus, enterprises
usually acquire complex and expensive replication engines. This paper offers an interesting choice to orga-
nizations which can not afford such costs. RJDBC stands for a simple, easy to install middleware, placed
between the application and the database management system, intercepting all database operations and for-
warding them among all the replicas of the system. However, from the point of view of the application, the
database management system is accessed directly, so that RJDBC is able to supply replication capabilities in
a transparent way. Such solution provides acceptable results in clustered configurations. This paper describes
the architecture of the solution and some significant results.
1 INTRODUCTION
Reliable systems are becoming more and more valu-
able nowadays. At present, customers demand quality
services and unavailability or data losses due to unex-
pected failures are not accepted. On the other hand,
the blowing up of service demands is causing annoy-
ing bottlenecks due to non-scalable systems. Thus,
enterprises must spend substantial amounts of money
and efforts in order to improve the availability and
performance of their services. Common solutions
consist on deploying complex and expensive systems
which frequently imply the reengineering of the soft-
ware products that use such systems. However, many
companies can not afford such costs, and other low-
cost solutions are required.
Enterprise applications implemented in Java, and
also most of J2EE services, need to interact with a
JDBC driver in order to access their data, commonly
stored in a relational DBMS. The aim of our Repli-
cated JDBC (RJDBC, hereafter) driver is to provide
transparent support for database replication, without
needing any modification in the underlying database
schema, nor in the applications that have to access
these replicated data. In order to achieve this, a sec-
∗
This work has been partially supported by the EU grant
IST-1999-20997 and the Spanish grant TIC2003-09420-
C02-01.
ond JDBC driver is needed, placed on top of the na-
tive one. This second driver intercepts all the oper-
ations requested by the user applications and, when
needed, broadcasts them to the rest of replicas using
total order (i.e., with a uniform atomic broadcast pro-
tocol (Hadzilacos and Toueg, 1993)). This will ensure
that all database replicas process all update operations
in the same order, guaranteeing database consistency.
Although there are other kinds of database repli-
cation protocols with better performance features and
that require less replica interaction (Wiesmann et al.,
2000), the RJDBC solution offers other interesting
features that are appealing for small and medium en-
terprises. First, it does not require any schema modi-
fication; usually, other database replication protocols
require that some metadata are added to the database
being managed, for instance, data item versions, or
owner replica numbers (J.Esparza Peidro et al., 2002;
Rodrigues et al., 2002). Such metadata prevent repli-
cation transparency, since they force that all applica-
tions access the database using the replication sup-
port. Accesses made by-passing it, may get undesir-
able results. In RJDBC this problem is not present.
The second feature is that the needed replication sup-
port can be easily and unexpensively implemented us-
ing a broadcast toolkit, and it does not need many re-
sources. So, RJDBC can be deployed in computers
with less memory and less powerful processors than
587
Esparza Peidro J., D. Muñoz-Escoí F., Irún-Briz L. and M. Bernabéu-Aubán J. (2004).
RJDBC: A SIMPLE DATABASE REPLICATION ENGINE.
In Proceedings of the Sixth International Conference on Enterprise Information Systems, pages 587-590
DOI: 10.5220/0002637805870590
Copyright
c
SciTePress
most other database replication protocols.
The rest of the paper is structured as follows. Sec-
tion 2 describes the structure of RJDBC. Section 3 ex-
poses some results of the developed prototype, com-
paring it with other systems. Related work is de-
scribed in section 4. Finally, section 5 concludes this
paper.
2 ARCHITECTURE OF RJDBC
A database replicated by means of the RJDBC mid-
dleware is composed by multiple replicas accessible
via JDBC. In each node where a client application ex-
ists, there will be a RJDBC driver on top of RJDBC
core and the usual JDBC driver. As stated previously,
this RJDBC core uses a uniform atomic broadcast
protocol in order to intercommunicate the replicas.
Basically, each node pursues two main targets:
1. To spread all significant operations performed on
each node among all the nodes of the system, in the
same order. The operations are codified, packed in
some ready-to-transmit way and finally applied on
actual database objects.
2. To ensure database consistency among all the repli-
cas. Notice that all the operations arrive to each
node through an atomic broadcast protocol, so that
the same operation delivery order is guaranteed in
all nodes.
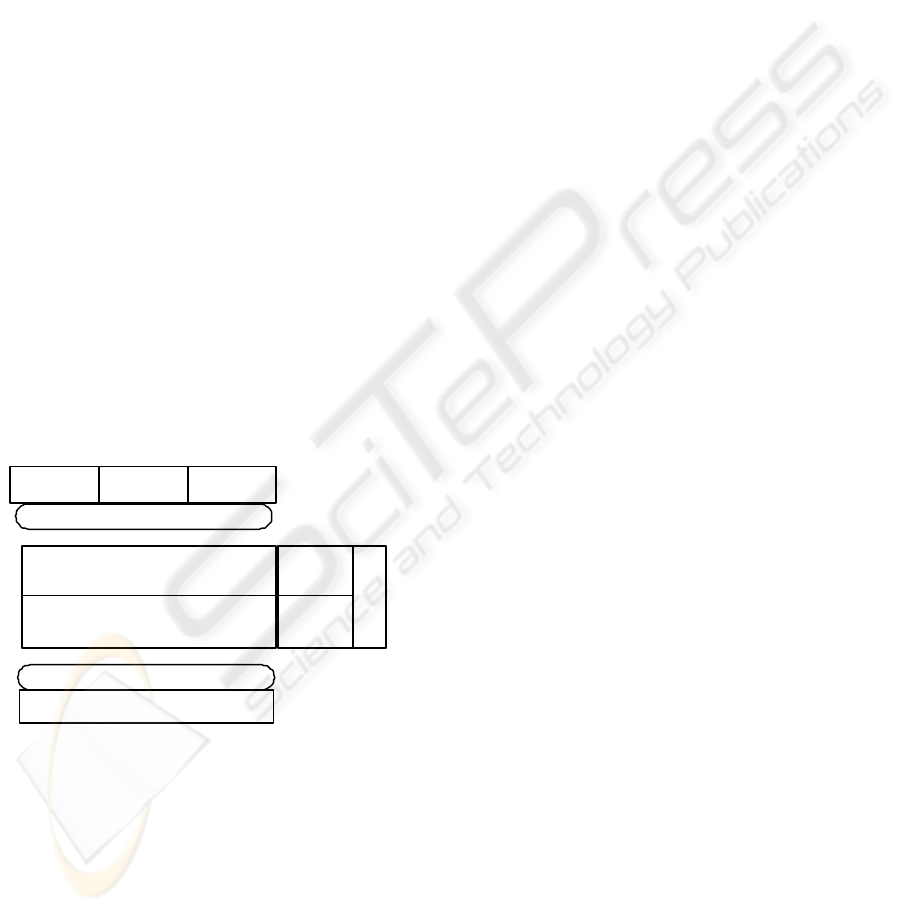
OPERATIONS FORWARDING ENGINE
OPERATIONS EXECUTION ENGINE
DBMS
APPLICATION
DISPATCHING
SERVICE
COMMUNICATIONS
JDBC
JDBC
RECEPTION
SERVICE
APPLICATION APPLICATION
Figure 1: RJDBC global architecture.
So, in order to reach these goals, each RJDBC node
can be roughly split up into two main components,
connected by means of a third one, the communica-
tions subsystem (figure 1):
1. The operations forwarding engine has the job of
broadcasting all the operations performed over the
local node among all the nodes of the RJDBC en-
vironment, including itself. It provides a JDBC in-
terface to the application layer and we refer to it as
RJDBC driver.
2. The operations execution engine feeds on the oper-
ations delivered by the communications subsystem.
It sequentially applies all received operations to the
underlying DBMS.
3. The communications subsystem consists of two
different elements, the dispatching service, which
broadcasts all the operations provided by the for-
warding engine, and the reception service, which
admits the broadcast operations and delivers them
to the operations execution engine.
The latter two components constitute the RJDBC
core.
Going into further details, the applications interact
with the RJDBC node through standard JDBC invo-
cations, using our RJDBC driver. Such driver com-
plies with the JDBC specification and provides all
the objects required for database accessing. These
objects wrap JDBC invocations and forward them to
the RJDBC core. These objects are named wrappers.
They stand for proxies of the actual JDBC database
objects. Thus, all database operations requested by
the client applications are immediately packed and
forwarded by the wrappers to the RJDBC core. This
communication takes place using Java RMI.
When the RJDBC core is notified about a new op-
eration, it promptly sends it towards all the system
nodes, including itself, using a uniform atomic broad-
cast (this implies total order). Not all operations are
required to be broadcast but only those affecting the
database management system state. For instance, if
the underlying database uses multi-version concur-
rency control, read-only accesses may not be trans-
mitted.
When a RJDBC node receives a new operation
from the communications protocol, it is enqueued for
subsequent processing. Each RJDBC node contains
an Operations Execution Thread (OET), in charge
of executing sequentially all enqueued operations.
This feature, plus the total order delivery, ensure the
database inter-replica consistency.
On the other hand, the OET does not apply oper-
ations over the database directly either. Instead, it
executes them over exact copies of the final JDBC
database objects, called adapters. These elements
allow fine grained control of operation execution re-
sults. They maintain a reference to the actual JDBC
database objects and execute the requested operations
on them, collecting the results and communicating
them to the OET.
In essence, each node consists of five components
arranged as figure 2 states. These components are:
the wrappers layer, the manager, the communications
layer, the operations execution thread and the adapters
layer.
• The wrappers layer provides access to the un-
derlying database management system, hiding the
ICEIS 2004 - DATABASES AND INFORMATION SYSTEMS INTEGRATION
588
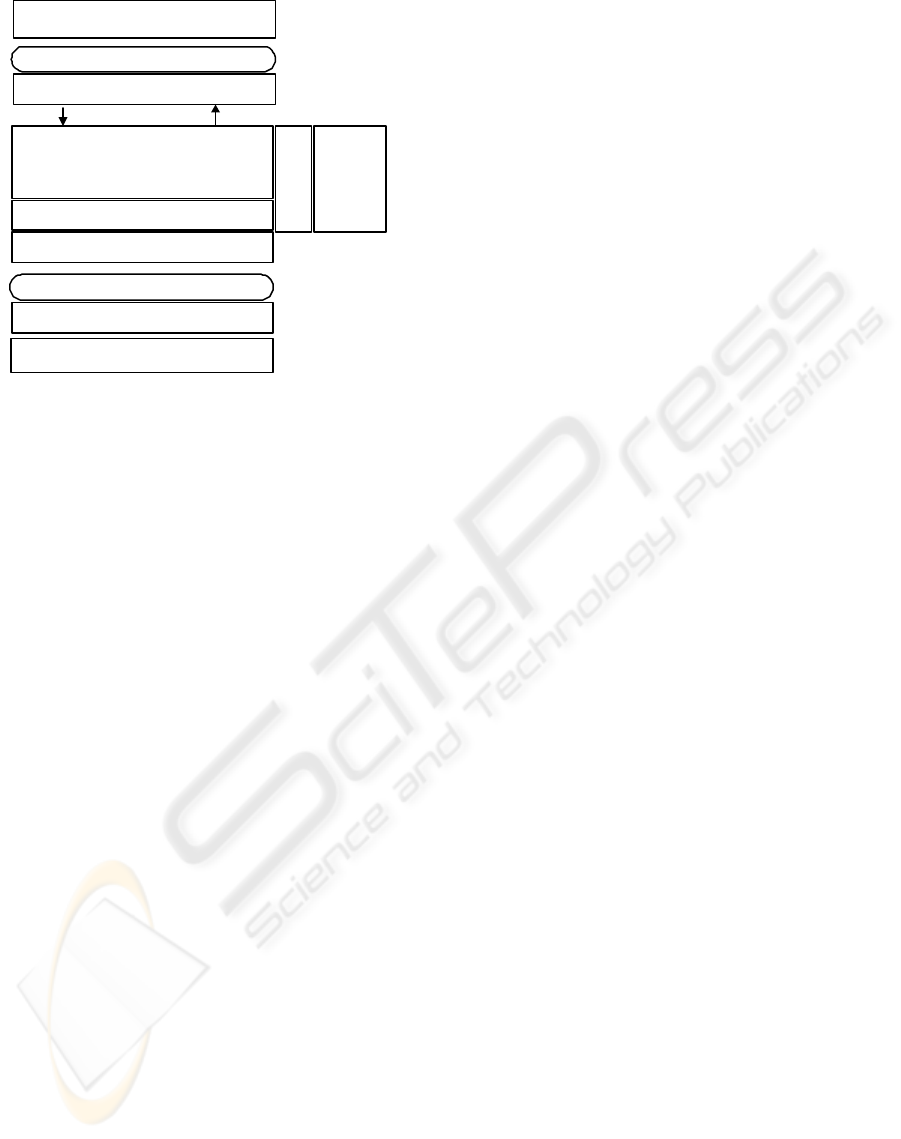
MANAGER
WRAPPERS
OPERATIONS EXECUTION THREAD
ADAPTERS
DBMS
APPLICATION
JGROUPS
COMMUNIC.
JDBC
JDBC
DRIVER
Figure 2: RJDBC architecture.
RJDBC replication engine. Thus, applications ac-
cess to regular JDBC objects, but these objects do
not operate directly on the database. Instead, they
act as proxies of the actual JDBC objects, placed
on the adapters layer.
• The manager is the core of the RJDBC middle-
ware. When the wrappers layer forwards an opera-
tion, the manager determines if it must be broad-
cast or not. To this end, the manager contains
a forwards table. For instance, in multi-version
based DBMSs (PostgreSQL is a sample), read-only
queries may not lead to any transaction lock, and
they are not forwarded.
If the forwards table states that the operation must
be broadcast, it is transferred to the communica-
tions layer. But if the operation does not need to
be broadcast, it is immediately applied on the local
database.
• The communications layer is the component that
implements the atomic broadcast services needed
in RJDBC. Currently, this component has been
implemented using an open-source toolkit called
JGroups (JavaGroups, 2004), although other simi-
lar toolkits could be easily integrated in our system.
• The operations execution thread serves sequen-
tially all the operations received via atomic broad-
cast, once they have been delivered by the commu-
nications layer. Note that these operations are not
applied directly to the underlying database, but to
the RJDBC adpters layer.
Concurrent transactions may get locked if they try
to access the same data items in conflicting modes
(write-write, for instance). Since only one opera-
tions execution thread exists in RJDBC, a lock of
this kind could imply a system deadlock. To pre-
vent this, a timeout-based mechanism exists that,
once a given time has ellapsed, starts a new thread
that will serve the remaining enqueued operations.
• The adapters layer is the lowest layer of RJDBC
and directly uses the services provided by the “na-
tive” JDBC driver.
Whilst the wrappers provide an image of the JDBC
object to the application, the adapters represent the
JDBC object to the RJDBC replication engine.
3 RESULTS
One of the advantages of RJDBC when it is compared
to other database replication mechanisms is its sim-
plicity, both in its design and in its resource use. So,
in our tests, we have used a COPLA (J.Esparza Pei-
dro et al., 2002; Ir
´
un et al., 2003) prototype, a replica-
tion engine that uses constant interaction, instead of
the linear interaction approach used in RJDBC, but
COPLA requires that some metadata are written in
the replicated database. So, we have tested there the
differences between a full-featured replication engine
and RJDBC. Additionally, another system used in the
tests is a non-replicated database, accessed directly
using JDBC.
Tests results are shown in figure 3. The first sub-
figure shows the productivity rate of each system,
measured in transactions per second. The best re-
sults correspond to directly accessing the DBMS via
JDBC, executing up to four times more transactions
than the RJDBC system. The overload of RJDBC is
evident, although not excessive, since two communi-
cations layers (RMI and JavaGroups) are being used.
However, RJDBC throughput is substantially higher
than COPLA, standing for an alternative in clustered
systems.
The second subfigure shows the abort rate of each
system. As it can be found the RJDBC engine beats
COPLA, providing a much lower abort rate. As ex-
pected, RJDBC and JDBC throw similar abort rates,
since in both systems operations should be executing
in a similar order.
In conclusion, RJDBC provides higher perfor-
mance than more complex systems in not very big
controlled environments, with negligible deployment
effort. It also supplies similar abort rate than access-
ing the database directly, via JDBC, obviously with
lower performance.
RJDBC: A SIMPLE DATABASE REPLICATION ENGINE
589
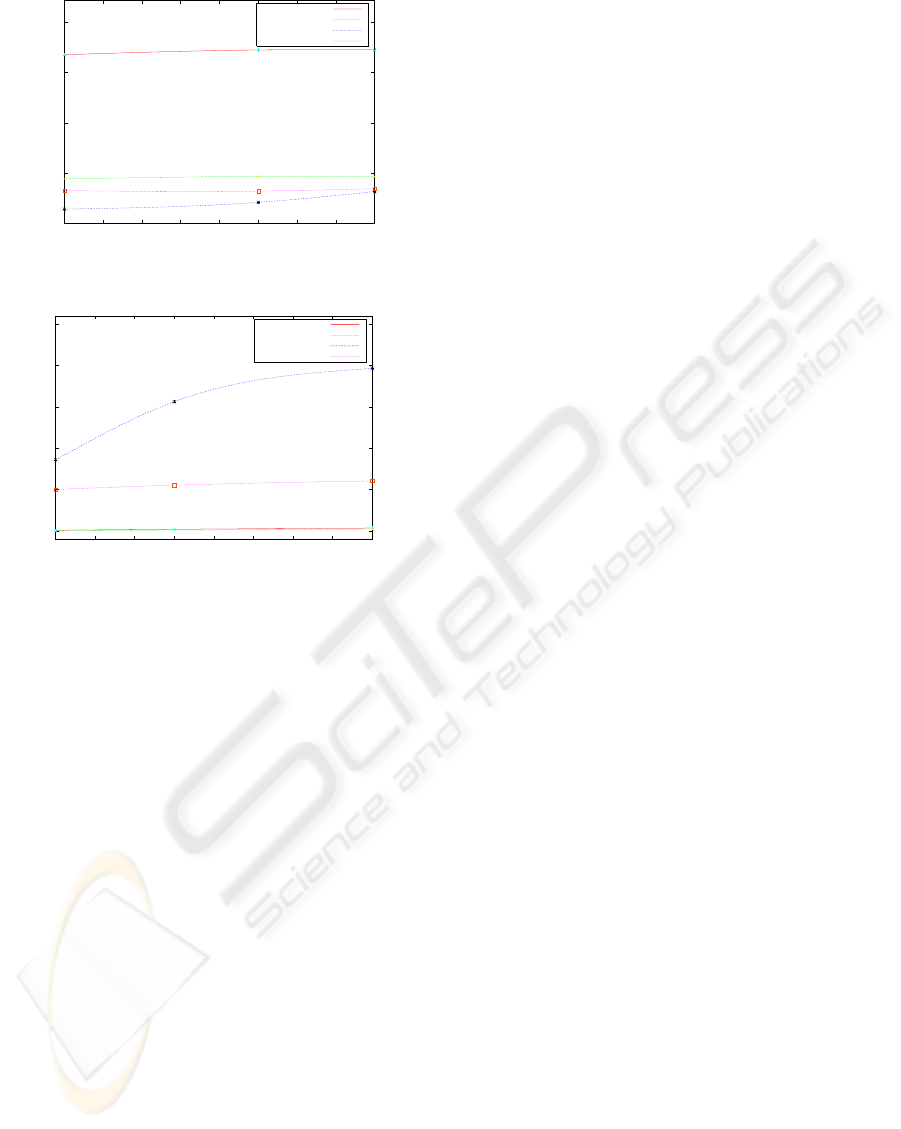
0
50
100
150
200
50 55 60 65 70 75 80 85 90
Transactions per second
Conflict probability (%)
JDBC
RJDBC
COPLA lazy
COPLA eager
(a) Transactions per second results
0
10
20
30
40
50
10 15 20 25 30 35 40 45 50
Abort rate (%)
Conflict probability (%)
JDBC
RJDBC
COPLA lazy
COPLA eager
(b) Abort rate results
Figure 3: Systems performace results
4 RELATED WORK
Much work about database replication is based on
the use of efficient atomic broadcast primitives (Gray
et al., 1996; Pedone et al., 1998; Pati
˜
no et al., 2000).
However, most of this work uses a constant interac-
tion approach, only needing update propagation at
the transaction commit phase. This is a very good
approach to enhance the replication protocol perfor-
mance, but usually it also implies a more ellaborated
protocol which may require more resources. RJDBC
uses linear interaction to propagate the updates, but
it does not require any metadata information on disk,
nor in memory, in order to decide about transaction
completion. Thus, RJDBC may be an adequate so-
lution when the available memory and processor are
limited.
5 CONCLUSIONS
RJDBC claims to be a simple solution for enterprises
which require database replication capabilities but do
not want to invest much money and time in deploy-
ing complex, full-featured systems. On the contrary,
RJDBC is extremely easy to install and setup, and fits
comfortably into the Java database accessing architec-
ture.
RJDBC provides an extensible lightweight plat-
form, with tolerable performance results in clustered
environments. Besides, depending on the underlying
database management system, RJDBC fine-tunning
could improve such results, resolving every instant if
an operation must be spread over all the nodes or not.
The current RJDBC prototype does not integrate
fault tolerance, but only replication capabilities.
However, it contains all required services for easy in-
tegration with a recovery protocol. In fact, an alpha
version of it is currently being developed.
REFERENCES
Gray, J., Helland, P., O’Neil, P., and Shasha, D. (1996).
The dangers of replication and a solution. In Proc.
of the 1996 ACM SIGMOD International Conference
on Management of Data, pages 173–182, Canada.
Hadzilacos, V. and Toueg, S. (1993). Fault-tolerant broad-
casts and related problems, chapter 5, pages 97–145.
Addison Wesley, 2nd edition.
Ir
´
un, L., Mu
˜
noz, F., Decker, H., and Bernab
´
eu, J. M. (2003).
Copla: A platform for eager and lazy replication in
networked databases. In 5th Int. Conf. Enterprise In-
formation Systems (ICEIS’03), volume 1, pages 273–
278.
JavaGroups (2004). JGroups web site. Accessible in URL:
http://www.javagroups.com.
J.Esparza Peidro, A.Calero, J.Bataller, F.Mu
˜
noz, H.Decker,
and J.Bernab
´
eu (2002). Copla - a middleware for dis-
tributed databases. In 3rd Asian Workshop on Pro-
gramming Languages and Systems, pages 102–113.
Pati
˜
no, M., Jim
´
enez, R., Kemme, B., and Alonso, G. (2000).
Scalable replication in database clusters. In Proc. of
14th IEEE DISC, pages 315–329.
Pedone, F., Guerraoui, R., and Schiper, A. (1998). Exploit-
ing atomic broadcast in replicated databases. In Proc.
of EuroPar’98.
Rodrigues, L., Miranda, H., Almeida, R., Martins, J., and
Vicente, P. (2002). The GlobData fault-tolerant repli-
cated distributed object database. In Proc. of the First
Eurasian Conference on Advances in Information and
Communication Technology, Teheran, Iran.
Wiesmann, M., Schiper, A., Pedone, F., Kemme, B., and
Alonso, G. (2000). Database replication techniques:
A three parameter classification. In Proc. of the 19th
IEEE SRDS, pages 206–217.
ICEIS 2004 - DATABASES AND INFORMATION SYSTEMS INTEGRATION
590
