
HANDLING MULTIPLE EVENTS IN HYBRID BDI AGENTS
WITH REINFORCEMENT LEARNING: A CONTAINER
APPLICATION
Prasanna Lokuge and Damminda Alahakoon
School of Business Systems, Monash University, Australia.
Keywords: Hybrid BDI agents, Intention reconsideration, reinforcement learning, ANFIS
Abstract: Vessel berthing in a container port is considered as one of the most important application s
ystems in the
shipping industry. The objective of the vessel planning application system is to determine a suitable berth
guaranteeing high vessel productivity. This is regarded as a very complex dynamic application, which can
vastly benefited from autonomous decision making capabilities. On the other hand, BDI agent systems have
been implemented in many business applications and found to have some limitations in observing
environmental changes, adaptation and learning. We propose new hybrid BDI architecture with learning
capabilities to overcome some of the limitations in the generic BDI model. A new “Knowledge Acquisition
Module” (KAM) is proposed to improve the learning ability of the generic BDI model. Further, the generic
BDI execution cycle has been extended to capture multiple events for a committed intention in achieving
the set desires. This would essentially improve the autonomous behavior of the BDI agents, especially, in
the intention reconsideration process. Changes in the environment are captured as events and the
reinforcement learning techniques have been used to evaluate the effect of the environmental changes to the
committed intentions in the proposed system. Finally, the Adaptive Neuro Fuzzy Inference (ANFIS) system
is used to determine the validity of the committed intentions with the environmental changes.
1 INTRODUCTION
Shipping applications are heterogeneous, distributed,
complex, dynamic, and large which, essentially
requires cutting edge technology to yield
extensibility and efficiency. One of the important
applications in container terminals is the vessel
berthing system. Vessel berthing application handles
assigning berths to vessels, allocation of cranes,
labor, trucks (loading and discharging) of containers
assuring maximum utilization of resources and
finally guaranteeing the high productivity of the
terminal.
Most research papers carried out so far focus on
th
e static berth allocation problem where the central
issue is to allocate vessels waiting and arriving
within the schedule window. Brown et al. (1994)
used integer programming, Lim (1998) addressed
the issue with fixed berth time, Chen and Hsieh
(1999) used heuristic time space network model,
Tong Lau and Lim (1999) used ant colony
optimization approach, Yongpei Guan (2003) used
heuristic worst-case analysis, Kim has used
simulated annealing (Kim & Moon, 2003), but still
fixed times are assigned to vessel operations and
learning of data patterns are not considered in the
decision making process.
On the other hand, intelligent agents are being
use
d for modeling rational behaviors in a wide rage
of distributed application systems. Intelligent agent
receives various, if not contradictory, definitions; by
general consensus, they must show some degree of
autonomy, social ability and combine pro-active and
reactive behaviors (Wooldridge, 1995). An obvious
research problem is to devise software architecture
that is capable of minimally satisfying the above
requirements.
One solution in particular, that is currently the
subject
of much ongoing research, is the belief-
desire-intention (BDI) approach (
Georgeff, 1998). In
some instances the criticism regarding BDI model
has been that it is not well suited to certain types of
behaviors. In particular, the basic BDI model
appears to be inappropriate for building complex
systems that must learn and adapt their behavior and
such systems are becoming increasingly important in
today’s context in the business applications. Further,
83
Lokuge P. and Alahakoon D. (2005).
HANDLING MULTIPLE EVENTS IN HYBRID BDI AGENTS WITH REINFORCEMENT LEARNING: A CONTAINER APPLICATION.
In Proceedings of the Seventh International Conference on Enterprise Information Systems, pages 83-90
DOI: 10.5220/0002518600830090
Copyright
c
SciTePress

the generic BDI execution cycle will observe only
one change or one event before it starts its intention
reconsideration process. We believe if an agent
could look ahead all the pending events which could
cause any effect to the current intention, would
essentially improve the autonomous behavior of the
present BDI agent. Further, our proposed hybrid
BDI agent architecture with improved learning
capabilities would extend the learning and
adaptability features of the current BDI agents. In
this paper, we describe how dynamic changes in the
environment are captured in the hybrid BDI agent
architecture for the intention reconsideration
process. Use of Adaptive Neuro Fuzzy Inference
system (ANFIS) in the Hybrid BDI framework has
indicated improved learning and decision-making
capabilities in a complex, dynamic environment.
The research is carried out at the School of
Business Systems, Monash University, Australia, in
collaboration with the Jaya Container Terminal at
the port of Colombo, Sri Lanka. The rest of the
paper is organized as follows: Section 2 provides an
introduction to berthing system in container
terminals. Section 3 describes generic BDI agent
architecture. Section 4 describes Plans used in the
vessel berthing. Section 5 describes the hybrid BDI
architecture. Section 6 describes reinforcement
learning for the execution of plans. A test case is
described in section 7 and conclusion is in section 8.
2 AN INTRODUCTION TO
VESSEL BERTHING SYSTEM
Competition among container ports continues to
increase as there are many facilities offered to
improve the productivity of the calling vessels.
Terminal operators in many container terminals are
providing various services such as automating
handling equipments, minimum waiting time at the
outer harbor, improved target archiving mechanisms
and bonus schemes etc, to attract many carriers. It is
essential to adopt intelligent systems in identifying
the appropriate ways of carrying vessel operations
and most importantly in finding alternative plans and
accurate predictions. In view of the dynamic nature
of the application, we have enhanced the generic
BDI model to behave as an intelligent agent with
reasonably good prediction ability in handling vessel
operations.
Shipping lines will inform the respective port the
Expected Time of Arrival (ETA) and other vessel
details. Changes to the original schedule are updated
regularly in the Terminal. Arrival Declaration sent
by shipping lines generally contains the Date of
arrival, Expected Time of Arrival, Vessel details,
Number of containers to be discharged, Number of
containers to be loaded, any remarks such as Cargo
type, Berthing and Sailing draft requirements, etc.
Vessel berthing application system of a container
terminal should able to assign a suitable berth,
cranes, people etc for the operations of the calling
vessel. One of the primary objectives of the terminal
operators is to assure the highest productivity,
minimum waiting time at the outer harbor, earliest
expected time of completion (ETC), earliest
expected sailing time (EST), better utilization of
resources such as Cranes, Trucks, labor etc in
serving the new vessel.
Port of Colombo has been used as the test bed
for our experiments, which handled approximately
1.8 million container boxes annually. The main
container terminal is called the “Jaya container
terminal” (JCT) which has four main berths called
jct1, jct2, jct3 and jct4.
3 GENERIC BDI ARCHITETCURE
One of the most popular and successful agent based
concepts is Rao and Georgeff [Rao and Georgeff,
1991], where the notions of Beliefs, Desires and
Intentions are centrally focused and often referred to
as BDI agents (
Rao, 1991). Information about world
is described in beliefs, such as ETC, ETB etc.
Desires indicate the set of goals that an agent could
achieve at a given in point in time. Agent would like
all its desires achieved, but often desires are
mutually exclusive. Therefore, agent should commit
to certain desires called intentions.
BDI model has pre-defined library of plans.
Sequence of plans is then executed in achieving the
committed intention in the agent model. Changes to
the environment are reflected in terms of events.
Event-queue stores the sequence of events occurred
during the execution of plans in the agent model.
Generic BDI interpreter is shown in Figure 1
(
Wooldridge, 1995). Algorithm indicated many
limitations, in particular, it has assumed that the
environment does not change after it observed the
environment at step 3 (Wooldridge, 1995).
Another
limitation of the above algorithm is that the agent
has overcommitted to its intention. i.e. all the plans
which are belonged to the commiitted intention will
be executed by the agents regardless of the
envionmental chnages.
1. B=B
0
; I=I
0
;
2. While true do
3. get next percept p;
4. B:= update beliefs ;
ICEIS 2005 - ARTIFICIAL INTELLIGENCE AND DECISION SUPPORT SYSTEMS
84

5. D:= option ( B,I) ; /* get desires */
6. I:= select intentions ( B,D,I)
7.
π
:= plan ( B,I) /* plan to be executed */
8. execute (
π
) ;
9. end while
Figure 1: generic BDI interpreter
Wooldridge (1995) has shown improvements to the
above limitations, but obseving many events at a
given time was not described. In our paper we
describe a extended algorithm with intelligent
learning capabilities for improved decision making
in complex applications. Plans required in a generic
berthing application are described in the next
section.
4 PLANS IN A VESSEL BERTHING
SYSTEM.
Agents in the vessel berthing system require
identifying what state of affairs that they want to
achieve and how to achieve these states of affairs
according to environmental changes. Set of desires
are visible for an agent at a given time and should
commit to one of the desires to achieve, which is
called as an intention. Plans are recipes for achieving
intentions. For example, when an event ETA-
received ( ) is observed by the agent, its desire
should be to assign a suitable berth for the calling
vessel assuring highest vessel productivity. There
may be many desires that an agent could think of:
assign-berth (jct1), assign-berth (jct2), assign-berth
(jct3) or assign-berth (jct4). But practically agent
would not be able to assign the calling vessel to all
berths since all desires are mutually exclusive.
Agent deliberation process should decide the most
appropriate berth for the vessel operations and
commit to it.
Option selected or intention should be achieved
by executing a set of plans in the agent model.
Figure 2 above shows a simple scenario of an
example of such situation. Generic plans required in
achieving the agent committed intentions in vessel
berthing application are described in the next sub
sections.
4.1 Sailing and Berth Drafts
Sailing and the berthing drafts of the new vessel (
) should be less than equal to
draft of the respective berths (
), that is
vivi
vsdandvbd
bj
bdr
(
)
(
)
[
]
bj
vi
bj
vi
bdrvsdvbrvbdji ≤∧≤∀ :,
(1)
where,
.4,1
≤
≤
ji
4.2 Outreach of the Cranes in the
Berth
Length of the cranes in the berth ( ) should be
equal or more to the vessel crane requirement (
vi
) i.e.
ci
bj
len
vcr
(
)
ci
bj
vi
lenvcrji ≤∀ :,
Where, (2)
4,1 ≤≤ ji
4.3 Average Crane Productivity of
Berths
Individual berth should maximize the average crane
productivity for calling vessels to gain the
competitive advantage over other berths. Expected
gross crane productivity of crane i in berth j for the
new vessel vi is
vi
ji
gcp
,
()
vi
ji
vi
ji
vi
i
vi
ji
cpocmo
nob
gcp
,,
,
−
=
(3)
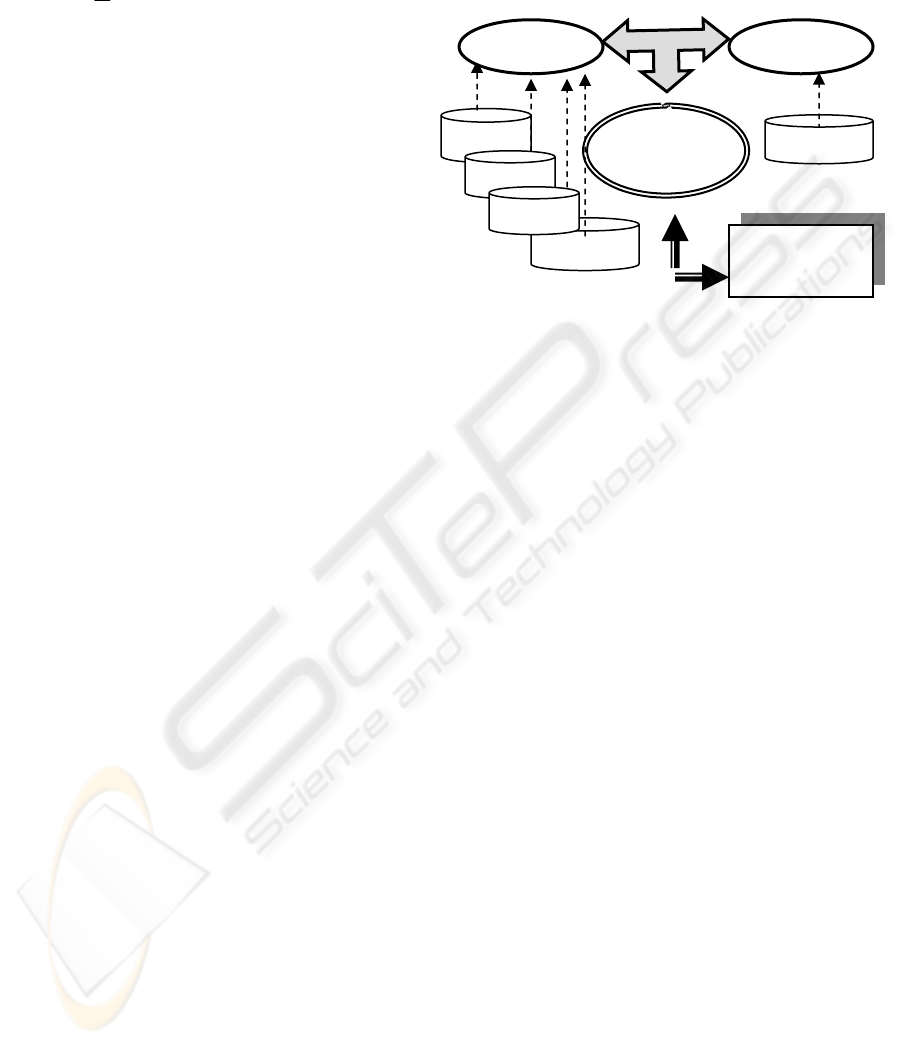
Agent
Eta-received ( )
Vessel-arrival( )
Eta-received( )
Assign
Jct2
Assign
Jct3
Assign
Jct1
Execution
Plans
Plan library
Commitment process
Committed
Intention
Check-draft( )
Crane-outreach ( )
……..
Figure 2: Execution of plans in the agent model.
HANDLING MULTIPLE EVENTS IN HYBRID BDI AGENTS WITH REINFORCEMENT LEARNING: A
CONTAINER APPLICATION
85
Average Crane productivity of the berth j for the
vessel vi is given as
∑
=
=
n
i
vi
ji
vi
j
gcp
n
acp
1
,
1
(4)
Where and indicates the
commencement and completion times of the crane i
in berth j for the vessel vi.
and
indicates the number of boxes handled by
crane i and expected average carne productivity in
berth j for vessel vi. We have described few cases of
plans required for the assignment of vessels in this
paper due to the space limitation to describe our
experimental results. Hybrid architecture proposed
to improve the intelligent behavior of the BDI agents
is described in the next section.
vi
ji
cmo
,
vi
ji
cpo
,
vi
i
nob
vi
j
acp
5 HYBRID BDI ARCHITECTURE
Intelligent learning while interacting with the
environment is one of the primary objectives in
developing hybrid BDI agents in our research. This
would essentially minimize some of the limitations
exists in the current BDI agents especially in
complex dynamic application systems. It is also
interesting to improve the agent behavior when
observing environmental changes with uncertain
data or information.
Two modules proposed in the hybrid BDI
architecture are shown in Figure 3. “Generic BDI
Module” (GBM) will execute the generic BDI
interpreter as shown in Figure 1. “Knowledge
Acquisition module” (KAM) provides the necessary
intelligence for the execution of plans and finally to
decide when to reconsider the committed intentions
in the agent model (lokuge & Alahakoon, 2004).
This would essentially assure dynamism in the
allocation and reconsideration of committed
intentions in the agent behavior.
A trained neural network in the KAM module
enable agent to initially select the viable intention
structures according to the beliefs and events in the
environment. During the execution of plans for the
committed intention, changes in the beliefs and their
impact are investigated with the use of
reinforcement learning techniques. ANFIS in the
KAM module will finally decide whether it is
required to reconsider the committed intentions or to
continue with the same in achieving the desires of
the system.
5.1 BDI Control Loop with Intention
Reconsideration
Generic BDI execution cycle given in Figure 1
should be extended for the actual use in real time
application systems. Wooldridge(2000) has extended
the generic BDI execution cycle in number of ways
which improves agent ability in replanting and
intention reconsideration with the environmental
changes. But agent ability in intelligent learning and
use of intelligent knowledge in the generic BDI
model are still not addressed in the literature. Agent
should use previous experience in making rational
decisions when ever it determines that its plans are
no longer appropriate in order to achieve the current
intentions, then it should engage further reasoning to
find alternative ways to handle the situations.
Present BDI agent will always observe only the
next available event before it commence the
intention reconsideration process. This is a limitation
in the present architecture which leads to delays in
making correct decisions quickly. Ability to capture
all the available events related to the committed
intention would essentially help agent to look
forward in many steps ahead before it proceeds with
the intention reconsideration process. Also it does
not say the agent ability to work with vague data sets
and the implementation of present BDI model in
such environments.
Proposed hybrid BDI architecture in this paper
would address the above short comings in the
present model and observed improved performances
in the vessel berthing application. Extended hybrid
BDI control loop with intelligent tools and observing
multiple events is described in the next section.
Hybrid
BDI
Plans
Intentions
Desires
Beliefs
Knowledge
GBM KAM
Figure 3: Main modules in the hybrid architecture
Environment
ICEIS 2005 - ARTIFICIAL INTELLIGENCE AND DECISION SUPPORT SYSTEMS
86
5.2 Extended Hybrid BDI Control
Loop
Hybrid BDI control loop with intelligence and
leaning behavior is given in Figure 5. Intelligent
tools such as neural networks and ANFIS in the
proposed “KAM” module are used in choosing
intentions and reconsideration of the committed
intentions. Reinforcement learning techniques
improve the interactive behavior of the proposed
agent in executing plans for achieving the committed
intentions. Most importantly, the above algorithm
demonstrates the observation of multiple events
which are related to the committed intention.
Let
{
nisS
i
≤≤= 1
}
denotes n number of states
in the environment. Any state s
i
is described as a set
of beliefs
for an intention I. Execution of
plans in various states results the change of state
from one to another in the environment. Figure 4
above shows an example of states to be followed in
achieving the committed intention “assign-berth” at
a given time.
I
i
bel
1. B=B
0
;I=I
0
;
2. Define Belief-Impact-Matrix;
3. While true do
4. get next percept p;
5. B:= update beliefs( ) ;
6. D:= option ( B,I) ; /* get desires */
7. INT:= KAM-intention ( B,D,I) /* neural networks */
8. I:= Filter-intentions( INT); /* select an intention */
9.
π
I
:= plan ( B,I) /* plan to be executed */
10. Initialize-motivation matrix;
11. While not (empty-plan or intention-succeeded
12. or impossible-intention) do
13.
α
= head-of-the-plan( );
14. execute(
α
);
15.
()
()
()
()
⎪
⎭
⎪
⎬
⎫
⎪
⎩
⎪
⎨
⎧
==×= ppssA
E
E
A
tt
m
ps
m
ps
tI
ps
tI
ps
,
,
,
,
,
,
,
16.
() ()
()
()
⎥
⎥
⎦
⎤
⎢
⎢
⎣
⎡
−
+
+←
++
t
I
t
ItI
t
t
I
t
I
sV
sVA
sVsV
1
,
1
γ
β
17. event-filter ( ); /* observe multiple events */
18. B:= update beliefs ( ) ;
19.
(
)()
[
]
tt
n
ttt
sVRsV −=∆
β
20. Construct-vigilant-factor ( );
21. If (( vigilant-factor)
≥T) then
22. IRT:= KAM-Intention-reconsideration ( )
23. end-if
24. If NOT( IRT) then
25.
π
I
:= tail-of-plans ( );
26. end-if
27. end-while
28. end-while
Where
{
}
10
≤
≤
α
β
is the learning rate and
γ
is
the discount factor.
Belief-Impact-Matrix mentioned (BIM) in line 3,
Figure 5 is required to analyze the effect of the
belief changes for the execution of plans. BIM is
given as :
⎥
⎥
⎥
⎦
⎤
⎢
⎢
⎢
⎣
⎡
=
pI
kl
pI
l
pI
l
pI
k
pIpI
BIM
,
,
,
2,
,
1,
,
,1
,
2,1
,
1,1
ααα
ααα
L
LL
L
(5)
pI
ji
,
,
α
( ) shows the impact factor or
influence of the j
10
,
,
≤≤
pI
ji
α
th
belief in state i in the execution of
plan p for the intention I. For example, change in
expected time of completion of a berth (etc) does not
have any effect on the execution of the plan berth-
draft( ) in states S2, and therefore,
should be
zero for that instance in sate S2. . Some belief
changes have higher impact on the committed
intentions than others, which will be assigned values
more closer to the upper bound of the
. Line 7
indicates the use of a supervised neural network in
the “KAM” module, which identify all the possible
options in achieving the agent desire. Selection of
the most viable option to commit is given line 8 of
the algorithm. Calculation of rewards and the value
of states due to the execution of plans will be
described in the next section with the reinforcement
learning techniques.
pI
ji
,
,
α
pI
ji
,
,
α
Figure 5: extended Hybrid BDI loop
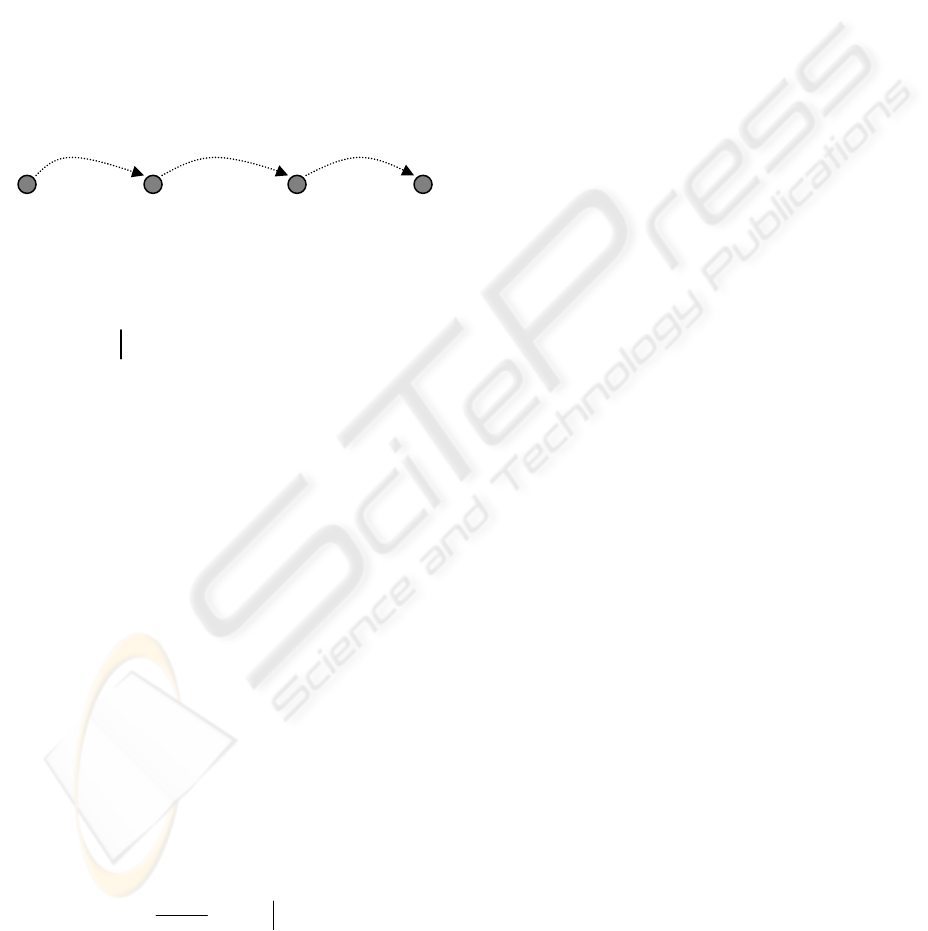
P1:waiting-time ( ) P2: berth-drafts( ) P3: crane-
Productivity( )
State S0 State S1 State S2 Goal Sate S3
Beliefs: Beliefs : : Beliefs:
eta,etc, bdr, vbd, vsd.. nob, gcp, cmo, cpo
Figure 4: Plans in a committed intention
HANDLING MULTIPLE EVENTS IN HYBRID BDI AGENTS WITH REINFORCEMENT LEARNING: A
CONTAINER APPLICATION
87

Event-filter ( ) in line number 17, will observe all
the events occurred which have any impact on the
committed intention that the agent is currently
working with. This would enable hybrid agent to
look forward in time to all the future belief changes
for various states and then to decide the intention
reconsideration process. Agent ability to observe
multiple events in the environment and their effect
to the committed intention is computed with n-step
backup method in reinforcement learning as given in
line 19. This enables event-filter ( ) to look forward
in time to all future events in the event queue and
estimate the distance change.
Since intention reconsideration process is a
costly process, we have defined a vigilant-factor to
avoid agent to reconsider its intentions at every
possible moment. Also this would be used to control
the sensitivity of the agent to environmental
changes. Lower values for the threshold T make
agent more sensitive to the environmental changes
and vise versa. Use of reinforcement techniques for
the execution of agent plans are described in the next
section.
6 REINFORCEMENT LEARNING
FOR AGENT PLANS
Temporal difference learning is a method to
approximate the value function of states. The value
of the present state can be expressed using the next
immediate reinforcement and the value of the next
state (Sutton, 1988). We use the temporal difference
learning method to calculate the rewards receive and
the value of states when executing plans for
achieving the committed intentions in the hybrid
model.
Lets assume,
and are the
expected and actual motivation values for the
execution of plans p in state s,
is the actual
distance or reward computed based on the beliefs in
the environment for the plans p in state s for the
intention I and
()
m
ps
E
,
()
m
ps
A
,
(
tI
ps
A
,
,
)
() ()
(
)
10
,
,
,
,
≤≤
tI
ps
tI
ps
EE
is the expected
distance according to the motivation value in state s
for the plan p. Then actual reward or distance due to
execution of plan p in state s for a given intention I
is given as:
()
()
()
()
⎪
⎭
⎪
⎬
⎫
⎪
⎩
⎪
⎨
⎧
==×==
+
ppssA
E
E
rA
tt
m
ps
m
ps
tI
ps
t
tI
ps
,
,
,
,
,
1
,
,
(6)
Therefore the value of a state s, after the execution
of plan p for the intention I could be written as:
(
)
{
}
⎭
⎬
⎫
⎩
⎨
⎧
===
====
∑
∞
=
++
0
,
1
,
,,
k
tt
tI
kt
kI
ttt
I
I
sI
ppssEE
ppssREDpsV
γ
π
π
π
(7)
Once a plan has been executed, event-filter ( )
process observe all the events in the event queue
before the next plan is executed. BIM indicates the
degree of the effect of the environment changes to
the present state and agent then use ANFIS in the
KAM module for the intention reconsideration
process. Decision making power of the hybrid agent
is improved as the estimation of value changes are
dependent on all the belief changes in the
environment.
Five layered adaptive neuro fuzzy inference
system (Jang, 1993) is used in the proposed agent
model to finalize the intention reconsideration
process. Four linguistic variables are used in the
decision making process of proposed model,
namely, percentage of the distance change between
time t and t+1 due the environment changes (
θ
1
),
Number of plans to be executed in achieving the
committed intention (
θ
2
), number of plans already
executed for the committed intention (
θ
3
) and
finally, the effect or the criticality of the
environmental changes (
θ
2
) for achieving the current
intention. Past data of the decisions being made are
used in the ANFIS in producing the membership
functions for the above linguistic variables
mentioned. A test case scenario in the next section
describes the agent ability to handle multiple events
in the intention reconsideration process in producing
better results compared to the traditional BDI agent
architecture.
7 A TEST CASE SCENARIO
Assume, that a vessel declaration event for the
vessel Zim,”ETA-received ( )” is received at the JCT
terminal, Port of Colombo, which minimally
includes: vessel berth draft ( vbd
Zim
)=12m, vessel
sailing draft (vsd
Zim
)=12.1m, vessel crane
requirement (vcr
Zim
)=13m, number of boxes (nob
Zim
)=752, expected time of arrival (eta
Zim
)=1300,
length of the vessel (vln
Zim
)=292m etc.. JCT
terminal has four main berths namely, jct1, jct2, jct3
and jct4. Beliefs at a given time in the environment
are shown in the table 1. Expected operation time of
vessels is denoted as ‘eot’ in the table.
ICEIS 2005 - ARTIFICIAL INTELLIGENCE AND DECISION SUPPORT SYSTEMS
88

Beliefs Sea.L Orient Hanjin Nord.L
Berth Jct1 Jct2 Jct3 Jct4
brd 11.3m 12.3m 14m 4m
len 13m 13m 18m 18m
acp 32.5mh 33.5mh 30.5mh 35.2mh
eot 22.9hrs 22.2hrs 24.4hrs 21.1hrs
etc 14:00 11:20 15:00 14:20
Berth Jct2 has been selected by the agent as it
shows the highest productivity for the calling vessel
and the set of plans executed and their state values
computed from the reinforcement learning is shown
the in table 2 below.
Plans Rewards
P1 : Berth-drafts ( )
0.066
P2 : Vessel-distance-requirement ( )
1.0
P3: Waiting-time-vessels ( )
1.0
P4: Average-crane-productivity ( )
0.418
P5: Get-expected-operations-time ( )
0.18
value - state to goal - D
s
2.664
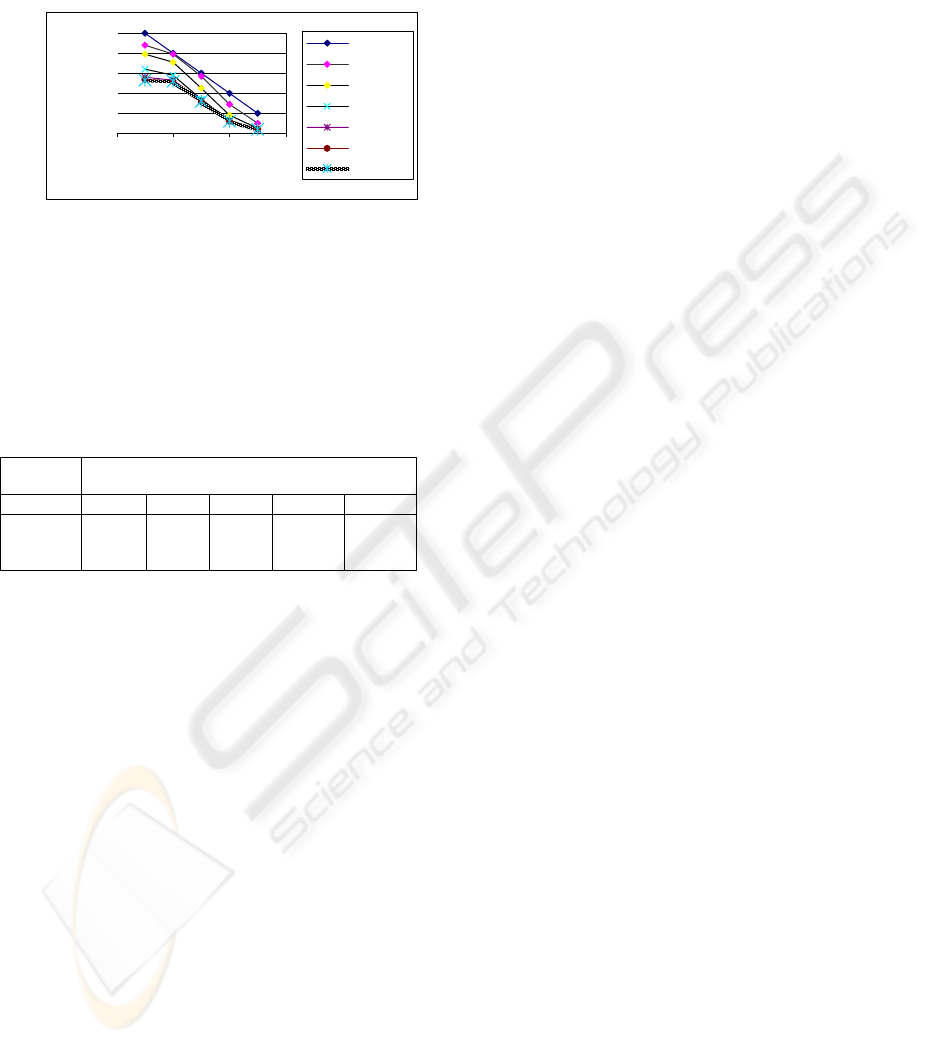
Value learned by temporal differential method in
reinforcement learning for committed intention in
assigning the vessel in Jct2 is given below in Figure
6. Figure shows the values approaches the actual
state values when several time steps are used in the
training.
One of the membership functions produced and
the decision surface produced from the ANFIS are
shown in figure 7. Extended BDI algorithm given in
the Figure 5 indicates that agent will observe events
in the event queue before the execution of the next
plan in the plan library.
Events in the event queue in a chronological
order at a given time are shown below:
@ t - E1: “vessel-delay ( Zim, eta=14.20, …);
@ t+1 - E2:”change-in-etc (jct2, etc=12.30...);
@t+2 -E2: “sailing-draft-changed (Zim, vsd=14m.);
@t+3 - E4: “carne-productivity ( jct1, 55.3mph…);
@t+4-E5:”crane-otreach(Zim,vcr=16m…).
State values produced against the number of
events considered are shown in Figure 8. When
agent considers only the immediate event, i.e. E1, it
does not indicate a strong impact on the committed
intention and it may decide not to reconsider the
current intention committed. But, actual scenario
may be quite different to this. It is noted that the
distance is largely changed when agent considers
several future events. Observing the effects of all the
available environmental changes before the next
intention reconsideration process makes agents
behavior more futuristic and dynamic.
Finally, the state values produced and the other
three linguistic variables mentioned in the section 6
have been used in the ANFIS for the final intention
reconsideration process. Table 3 indicates the
intention reconsideration decision made by the
ANFIS in the hybrid BDI model, where agent’s
prediction towards intention reconsideration is given
as a percentage. Agent’s ability to make more
accurate decisions is improved with the increased
number of events it observes in the environment.
When agent considers the environmental changes
due the occurrence of only event E1, ANFIS based
KAM module indicate that only 12% support to drop
the committed intention. But, if agent ever had a
change to observe all the environmental chances due
to the events in the event queue, its decision to
continue with the current intention is deteriorated
and indicates a 87.4% support that the current
intention should be dropped. This is true as event E4
indicates that crane outreach requirement of the
vessel Zim has now changed to 16m, where the new
requirement can not be fulfilled in the present berth
Table 1: Beliefs of the environment
Figure 7 (a):
membership function
for percentage of
distance change
Figure 7 (b): Decision
surface produced for
percentage of distance
change and criticality
of the environment
change
Table 2: Rewards computed for plans in Jct2
0.00
0.50
1.00
1.50
2.00
2.50
0246
State Values
Distance
Init. Values
E1 only
E1,E2
E1-E3
E1-E4
E1-E5
Figure 6: learning curves for states in Jct2
HANDLING MULTIPLE EVENTS IN HYBRID BDI AGENTS WITH REINFORCEMENT LEARNING: A
CONTAINER APPLICATION
89
Jct2 (impossible to achieve). Therefore the current
intention committed to assign the vessel Zim to berth
Jct2 should be dropped as indicated in the table.
ANFIS output produced for events E1-E3 and E1-E4
given the same results as event E4 does not have any
impact on the current intention and therefore agent
has not considered that event in the intention
reconsideration process.
Events considered in the Intention
econsideration R
E1 E1,E2 E1-E3 E1-E4 E1-E5
ANFIS
put Out
produced
12.4% 24.4% 85.3% 85.3% 87.4%
8 CONCLUSION
n extended BDI control
REFERENCES
C., 2003. “Berth Scheduling by
simulated annealing”, Transportation research part B.,
Geo
esire-Intention
Rao
f the second
Wo
ss, London.
ry for vessel berthing in
Sut
an Introduction”, The MIT Pres.
, Man and
Wo
knowledge
Chi
eeding
Sch
ceeding of the
In this paper we presented a
loop that enable to observe many events prior to
decision making instead of one event which is the
case in the present BDI architecture. Results of the
intention reconsideration process have largely
changed when agent observes many events trigged
in the environment, which is found to be better and
accurate. Agent decision making process has
become faster and accurate compared to the present
BDI architecture.
Also the agent ability to handle vague or
uncertain data sets is also improved with the
introduction of ANFIS in our “KAM” module. We
believe that the intention reconsideration process
could be further improved if agent could remember
previously excluded options in the environment.
This would enable agent to speedily work out the
possibility of adopting those dropped options when
ever the current one no longer valid in the present
environment. Our future research work plans to
further extend the BDI control loop enabling agent
to compare different options in the intention
reconsideration process.
Kim, K.H and Moon, K.
V.37, 541-560, Elsevier Science Ltd.
rgeff, M, B. Pell, M. Pollack, M. Tambe, and M.
Wooldridge.,1998. “The Belief-D
Model of Agency”, Springer Publishers.
A.S and Georgeff ,1991, ”Modeling Rational agents
with a BDI Architecture”, In proceeding o
international conference on principles of knowledge
representation and reasoning, p. 473-484, Morgan
Kaufmann.
oldridge M, 2000, “Reasoning about Rational Agents”,
The MIT Pre
Lokuge D.P.S and Alahakoon D, 2004, “BDI Agents with
fuzzy associative memo
container ports”, In proceeding of the Sixth
international conference on enterprise information
systems, INSTICC press, V2,p. 315-320, Porto,
Portugal.
ton R.S and Barto, 1988, A.G, “Reinforcement
Learning,
Jang, J.S.R., 1993, “Adaptive network based fuzzy
inference systems," IEEE Trans. on system
Cybernetics, Vol. 23, No. 3, p. 665-685.
oldridge M. and Jennings N.R, 1995. “ Intelligent
agents: Theory to practice”, The
engineering review, V. 10, no 12, p. 115-152.
a, J.T., Lau, H.C and Lim, A. 1999. “Ant Colony
optimization for ship berthing problem”, In proc
of ASIAN99, 359-370, LNCS 1742.
ut, M and Wooldridge M. 2001, “Principles of
Intention reconsideration “, In pro
AGENTS’01, Montreal, Quebec, Canada, ACM 1-
58113-326-X.
0.00
1.00
2.00
3.00
4.00
5.00
0246
states
Error
steps:0
steps:10
steps:25
steps:50
steps:75
steps:100
Actual
Figure 8: learning curves for states in Jct2
Table 3: ANFIS output produced
ICEIS 2005 - ARTIFICIAL INTELLIGENCE AND DECISION SUPPORT SYSTEMS
90
