
INSTANCES NAVIGATION FOR QUERYING INTEGRATED DATA
FROM WEB-SITES
Domenico Beneventano
1
, Sonia Bergamaschi
1
, Stefania Bruschi
1
,
Francesco Guerra
2
, Mirko Orsini
1
, Maurizio Vincini
1
1
DII - Universit
`
a di Modena e Reggio Emilia
via Vignolese 905, 41100 Modena
2
DEA - Universit
`
a di Modena e Reggio Emilia
v.le Berengario 51, 41100 Modena
Keywords:
Semantic integration, wrapper HTML, query manager.
Abstract:
Research on data integration has provided a set of rich and well understood schema mediation languages and
systems that provide a meta-data representation of the modeled real world, while, in general, they do not deal
with data instances.
Such meta-data are necessary for querying classes result of an integration process: the end user typically does
not know the contents of such classes, he simply defines his queries on the basis of the names of classes and
attributes.
In this paper we introduce an approach enriching the description of selected attributes specifying as meta-data
a list of the “relevant values” for such attributes. Furthermore relevant values may be hierarchically collected
in a taxonomy. In this way, the user may exploit new meta-data in the interactive process of creating/refining a
query. The same meta-data are also exploited by the system in the query rewriting/unfolding process in order
to filter the results showed to the user.
We conducted an evaluation of the strategy in an e-business context within the EU-IST SEWASIE project. The
evaluation proved the practicability of the approach for large value instances.
1 INTRODUCTION
Integration of data from multiple sources is one of the
main problems facing the database research commu-
nity. One of the most common approach for integrat-
ing information sources is to build a mediated schema
as synthesis of them. By holding all the data collected
in a common way, such mediated schema allows the
user to pose a query following a global perception.
The system answers translating the query into a set
of sub-queries for the involved sources by means of
automatic unfolding-rewriting operations taking into
account the mediated and the sources schemas. Re-
sults from sub-queries are then unified by exploiting
data reconciliation techniques.
Research on data integration has provided a set of
rich and well understood schema mediation languages
and systems, which may be classified as the global-as-
view (where the mediated schema is defined as a set
of views over the data sources) and the local-as-view
(where the contents of data sources are described as
view over the mediated schema) formalisms (Halevy,
2003).
Following the GAV approach, we developed
MOMIS (Mediator envirOnment for Multiple Infor-
mation Sources) (Bergamaschi et al., 2001; Beneven-
tano et al., 2003), a framework to perform informa-
tion extraction and integration from both structured
and semi-structured data sources, plus a query man-
agement environment to take incoming queries and
process them through the exploitation of the mediated
schema.
Two kinds of users interact with MOMIS: the inte-
gration engineer and the end user (or client/web ser-
vice applications). The integration engineer is re-
sponsible for the integration process (the operation
is performed by means of the MOMIS - Ontology
Builder) giving rise to a Global Virtual View (GVV)
of selected information sources; the end user queries
the GVV classes (created by the integration engineer)
aiming at obtaining a unified answer from the in-
volved sources.
Several approaches emerged about the user sup-
porting in querying. Such approaches may be summa-
rized in three different schools (Broder et al., 2005):
(a) the search-centric schools that guided naviga-
tion is superfluous since users can satisfy all their
needs via simple queries; (b) the taxonomy navigation
46
Beneventano D., Bergamaschi S., Bruschi S., Guerra F., Orsini M. and Vincini M. (2006).
INSTANCES NAVIGATION FOR QUERYING INTEGRATED DATA FROM WEB-SITES.
In Proceedings of WEBIST 2006 - Second International Conference on Web Information Systems and Technologies - Internet Technology / Web
Interface and Applications, pages 46-53
DOI: 10.5220/0001247900460053
Copyright
c
SciTePress

school claims that users have difficulties expressing
informational needs; (c) the meta-data centric school
advocates the use of meta-data for large sets of results.
In this paper, we describe a method for support-
ing users in querying by providing meta-data about
attributes of integrated GVV classes. Our approach
aims at showing to the user semantic, synthesized
and meaningful information emerged directly from
the data. We claim such meta-data are necessary
for querying classes result of an integration process:
the end user typically does not know the contents
of the GVV classes, he simply defines his queries
on the basis of the names of classes and attributes.
Such labels may be generic: the synthesis opera-
tion narrows in few classes data ”semantically sim-
ilar” coming from different sources. Consequently
the name/description for a global class is often un-
specific, especially for web sources where the user is
highly involved in choosing the label for the elements
descriptions. For example the integration of two lo-
cal classes “T-Shirt” and “Trouser” could be
a unique Global Class called “Dress”. Such name
does not allow a user to know which specific kinds of
dresses are stored.
We proposed a partial solution to these issues
in (Beneventano et al., 2003) where a semantic an-
notation of all the Global Classes with respect to the
WordNet lexical database
1
provides each term with a
well- understood meaning.
Our goal is now enriching the description of se-
lected attributes specifying as meta-data a list of the
“relevant values” for such attributes. Furthermore rel-
evant values may be hierarchically collected in a tax-
onomy. In this way, the user may exploit new meta-
data in the interactive process of creating/refining a
query. The same meta-data are also exploited by the
system in the query rewriting process in order to filter
the results showed to the user.
Exploiting such new kind of meta-data is an inter-
esting challenge: the literature about integration sys-
tems mainly focuses on creating/representing struc-
tures for heterogeneous data sources (Buneman et al.,
1997; Nestorov et al., 1997; Halevy, 2004). Only
recently, some techniques for combining data struc-
ture and data management were developed (Chaud-
huri et al., 2005). The work closest to our is the “Mal-
leable Schema” (Dong and Halevy, 2005), where a
middle point between a collection of schemas/DTDs
in a domain and a single strict schema for that do-
main is offered. In contrast with malleable schemas,
our approach models a domain with a fixed semistruc-
tured model (ODM
I
3
) where meta-data derived from
extensional analysis are added.
Next section describes the MOMIS approach to
data integration, section 3 defines our technique to
1
http://wordnet.princeton.edu/
calculate relevant values for selected attributes, sec-
tion 3.2 shows the impact of relevant values in the
querying process and section 4 gives an example of
relevant values calculated for a real domain. Finally
section 5 sketches out some conclusions.
2 THE MOMIS APPROACH
The framework consists of a language and several
semi-automatic tools:
• The ODL
I
3
language is an object-oriented lan-
guage, with an underlying Description Logic; it is
derived from the standard ODMG. ODL
I
3
extends
ODL with the following relationships expressing
intra- and inter-schema knowledge for the source
schemas: SYN (synonym of), BT (broader terms),
NT (narrower terms) and RT (related terms). By
means of ODL
I
3
only one language is exploited
to describe both the sources (the input of the syn-
thesis process) and the GVV (the result of the
process). The translation of ODL
I
3
descriptions
into one of the Semantic Web standards such
as RDF, DAML+OIL, OWL is a straightforward
process. In fact, from a general perspective an
ODL
I
3
concept corresponds to a Class of the Se-
mantic Web standard, and ODL
I
3
relationships are
translated into properties.
• Information integration is performed in a semi-
automatic way, by exploiting the knowledge in
a Common Thesaurus (semi-automatically defined
from the structural and lexical analysis of the infor-
mation sources) and ODL
I
3
descriptions of source
schemas with a combination of clustering tech-
niques and Description Logics. This integration
process (performed by means of the MOMIS - On-
tology Builder) gives rise to a GVV of the un-
derlying sources. The GVV consists of a set of
Global Classes, each of them made up of Global
Attributes. Mapping rules connect the GVV with
the original information sources and integrity con-
straints are specified to handle heterogeneity.
• The MOMIS Query Manager is the coordinated set
of functions which take an incoming query, decom-
pose the query according to the mapping of the
GVV onto the local data sources relevant for the
query, send the sub-queries to these data sources,
collect their answers, perform any residual filter-
ing as necessary, and finally deliver the answer
to the requesting user. The unfolding and rewrit-
ing process is based on the full disjunction oper-
ation (Galindo-Legaria, 1994) and it is described
with details in (Beneventano and Lenzerini, 2005).
INSTANCES NAVIGATION FOR QUERYING INTEGRATED DATA FROM WEB-SITES
47
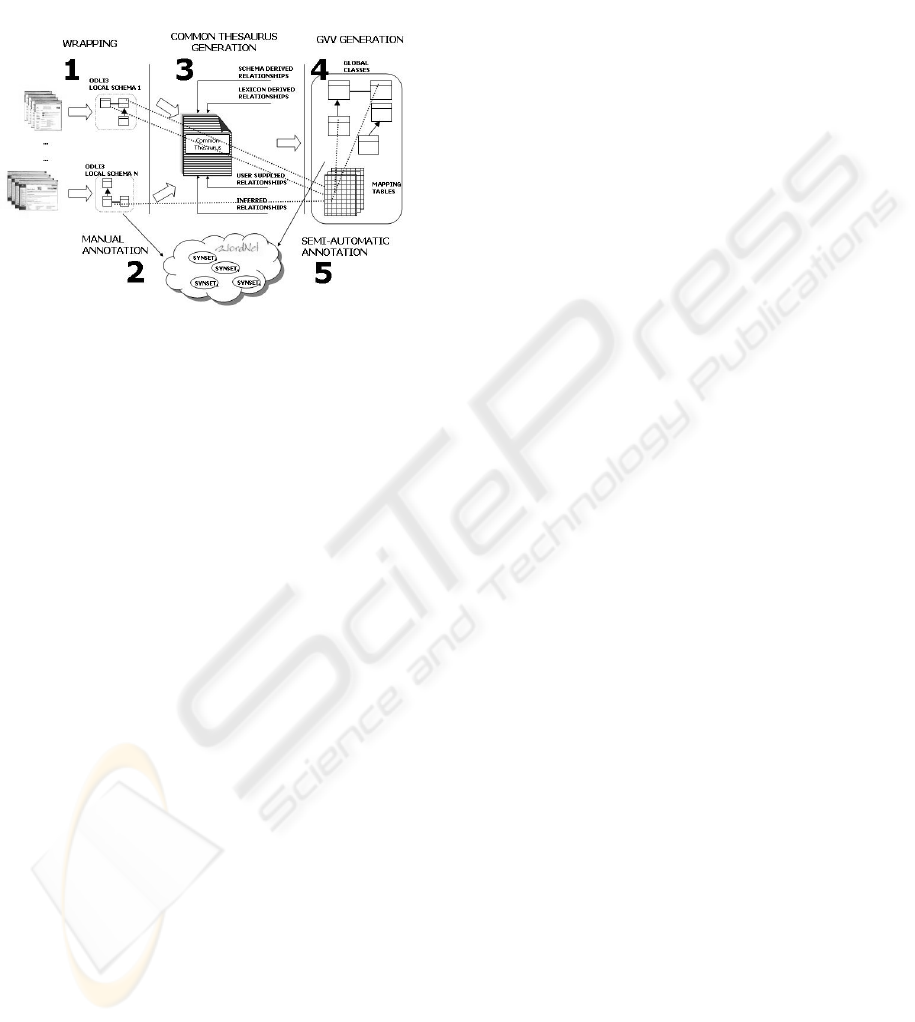
2.1 The MOMIS Ontology Builder
The MOMIS integration process, shown in Figure 1,
has five phases:
Figure 1: Functional representantion of the MOMIS Ontol-
ogy builder.
1. Local source schemata extraction. Wrappers
analyze sources in order to extract (or generate
if the source is not structured) schemas. Such
schemas are then translated into the common lan-
guage ODL
I
3
.
2. Local source annotation with WordNet. The in-
tegration designer defines a meaning for each el-
ement of a local source schema, according to the
WordNet lexical ontology. A tool supports the in-
tegration designer: some WordNet synsets are sug-
gested for each source element.
3. Common thesaurus generation. Starting from
the annotated local schema, MOMIS constructs
a set of relationships describing inter- and in-
traschema knowledge about classes and attributes
of the source schemata.
4. GVV generation. The MOMIS methodology,
applied to the common thesaurus and the local
schemata descriptions, generates a global schema
and sets of mappings with local schemata. The
Global Schema is made up of a set of global
classes. Several global attributed belong to a global
class.
5. GVV annotation. Exploiting the annotated lo-
cal schemata and the mappings between local
and global schemata, the MOMIS system semi-
automatically assigns name and meaning to each
element of the global schema.
The Ontology Builder Tool supports the integration
designer in all the GVV generation process phases.
2.2 Local Source Schemata
Extraction
To enable MOMIS to manage web pages and data
sources, we need specialized software (wrappers) for
the construction of a semantically rich representations
of the information sources by means of a common
data model. A wrapper logically converts the source
data structure into an ODL
I
3
schema. The wrapper
architecture and interfaces are crucial, because wrap-
pers are the focal point for managing the diversity
of data sources. For conventional structured infor-
mation sources (e.g. relational databases), schema
description is always available and can be directly
translated. For web content, this is mainly available
in the form of HTML documents: such documents
do not separate data from presentation and are ill-
suited for being the target of database queries and
most other forms of automatic processing. This prob-
lem has been addressed by much work on so-called
Web wrappers, programs that extract the relevant in-
formation from HTML documents and translate it into
a more machine-friendly format such as XML. The
wrapping problem has been addressed by a substantial
amount of work: in our approach we used Lixto (Got-
tlob et al., 2004) to translate the website data in XML
format. The main feature of Lixto is its graphics in-
tuitive interface that interactively guides the wrapper
designer’s intervention. The lixto wrapper is coupled
with an XML wrapper, we developed, generating for
each XML representation of a web-site the related
XML Schema (an XSD file) and loads the XML data
into a relational database. In this way, we are able
to structure and query web-site sources. Our XML
wrapper is based on MS .net framework and auto-
matically updates the data extracted from the web by
means of script daemons into the relational database.
3 PROVIDING INFORMATION
ABOUT RELEVANT VALUES
OF ATTRIBUTES
A global class contains data collected from differ-
ent local sources by means of an integration process,
and consequently its name (and the associated anno-
tations) may not perfectly fit in its contents. Thus,
a query written only on the basis of this information
name may be misleading. Moreover, ignoring the val-
ues assumed by a global attribute may generate mis-
taken queries: a user that does not know the granu-
larity of an attribute may write an exceedingly selec-
tive query, or a selection clause that does not really
produce any result because semantically improper for
that context. On the other hand, to know all the data
WEBIST 2006 - INTERNET TECHNOLOGY
48

collected from a global class is not possible for a user:
databases contain large amount of data which a user
can not deal with.
For these reasons, we present a technique to pro-
vide the end user with the knowledge of the “relevant
values” for global attributes selected by the integra-
tion designer in the GVV building phase.
Given an attribute At of a global class C,arele-
vant value RV for At is a pair RV = RV N, RV I
where RV N is the name of the relevant value and
RV I is a set of values assumed by At, i.e., RV I ⊆
A
t
(C).
A set of relevant values SRV is a set
SRV = {RV
1
,RV
2
, ..., RV
v
},n > 0, such
that
RV i∈SRV
RV
i
=
At
C
The relevant values may be classified in a taxon-
omy by means of ISA relationships: RV
1
ISA RV
2
;
a taxonomy need to be consistent:ifRV
1
ISA RV
2
then RV I
1
⊆ RV I
2
.
A relevant value RV = RV N, RV I is represen-
tative of all the associated values RV I: at the level
of query management a condition At=RV N will be
transformed in the equivalent condition At IN RV I.
Such relevant values are calculated by means of
a semi-automatic process composed of the following
steps:
1. identification of the relevant values: the set of rel-
evant values SRV is calculated by applying clus-
tering techniques to
At
C.
There are different algorithms in literature to be ap-
plied for clustering values. For example in (Gib-
son et al., 2000) a proposal for clustering values
that cannot be naturally ordered by a metric (i.e.
categorical data) is described. Nevertheless, we
claim that one single algorithm may not work in
any domain. Therefore our goal is to develop and
propose to the user a pool of techniques for se-
lecting the most suitable method (or the combi-
nation of different methods) for the specific do-
main. In MOMIS, we developed a syntactic al-
gorithm particularly customized for dealing with
classifications of services and goods. It is a typical
topic of the e-commerce, where enterprises propose
their products by means of web-sites. In such sites,
products are often grouped by means of categories
called in different sites in different ways. Moreover
categories are typically collected in taxonomies
on the basis of specific criteria.We observed that
the names of these categories are often qualified
with multiple attributes in order to describe spe-
cific products. The proposed method exploits such
features by means of the “Contains” function that
shows if a single value for the selected attribute is
contained in another one. We choose this func-
tion because typically implemented in RDBMS
and anyhow easily developed. The list of rele-
vant values is obtained by a stemming process on
the
At
C elements and applying the “Contains”
function to the attribute values repeatedly until the
achievement of a fixed point. In section 4 we show
an example of relevant values set obtained by ap-
plying the algorithm on four web-sites.
2. identification of the name of a relevant value:
the name associated to the relevant value is typi-
cally the most general value among the collected
values, i.e. given RV = RV N, RV I, RV N is
the most general value of RV I. The name choice
may be result of the clustering algorithm applied
to identify the relevant values. Otherwise, the sys-
tem proposes a name that has to be confirmed by
the user. The method proposed in MOMIS, based
on the “Contains” function, allows defining for spe-
cial string domains a set of relevant values SRV =
{RV
1
,RV
2
, ..., RV
v
}, where in each RV I
i
there
is a “most general value” which can be used as
name of the relevant value RV
i
(see section 4).
3. hierarchy definition: Relevant attributes may be
exploited for summarizing categories and classifi-
cations. In this context, data sources (e.g.: infor-
mation systems, web-sites) typically provide par-
tial/total hierarchies for supporting users in the
querying phase. Our goal is exploiting such orig-
inal hierarchies by applying to the SRV the hierar-
chical relationships being among the values RV I
i
belonging to the RV I (see section 4 for an exam-
ple). In addition, the MOMIS system provides a
graphical interface helping users in the manually
execution of this process.
3.1 Relevant Values Representation
The set of relevant values is represented according the
proposal of the Ontology Engineering and Patterns
Task Force in the Semantic Web Best Practices and
Deployment Working Group (N. Noy, 2005), where
five different approaches are suggested to represent
OWL classes as property values on the Semantic Web.
In particular, with reference to the first representa-
tion , OWL classes are directly used to describe the
different relevant values belonging to the selected
global attribute A
t
. This assumption allows model-
ing an hierarchy of relevant values by means of the
rdfs:subClassOf property. According to this
approach, we represent each RV N as an OWL Class
and the set of values v
j
,j :1, ..., k of RV I as in-
stances of RV N ; finally each RV N (i.e. an OWL
class) is then generalized by a root OWL Class (called
as the A
t
name) that becomes the property value of
the A
t
attribute.
For example, referring to the example domain de-
scribed in Section 4 (Table 1), the Moulding relevant
value is modeled as follows:
INSTANCES NAVIGATION FOR QUERYING INTEGRATED DATA FROM WEB-SITES
49
<owl:Class rdf:ID="CategoryName">
<rdfs:subClassOf
rdf:resource=
"http://www.w3.org/2002/07/owl#Class"/>
</owl:Class>
<owl:Class rdf:ID="Moulding">
<rdfs:subClassOf
rdf:resource="#CategoryName"/>
</owl:Class>
<Moulding rdf:ID="Moulding" />
<Moulding rdf:ID=
"Compression injection moulding" />
<Moulding rdf:ID="Insert moulding" />
<Moulding rdf:ID="Normal moulding" />
<Moulding rdf:ID="Intrusion moulding" />
<Moulding rdf:ID="Deep moulding" />
3.2 Querying Relevant Values
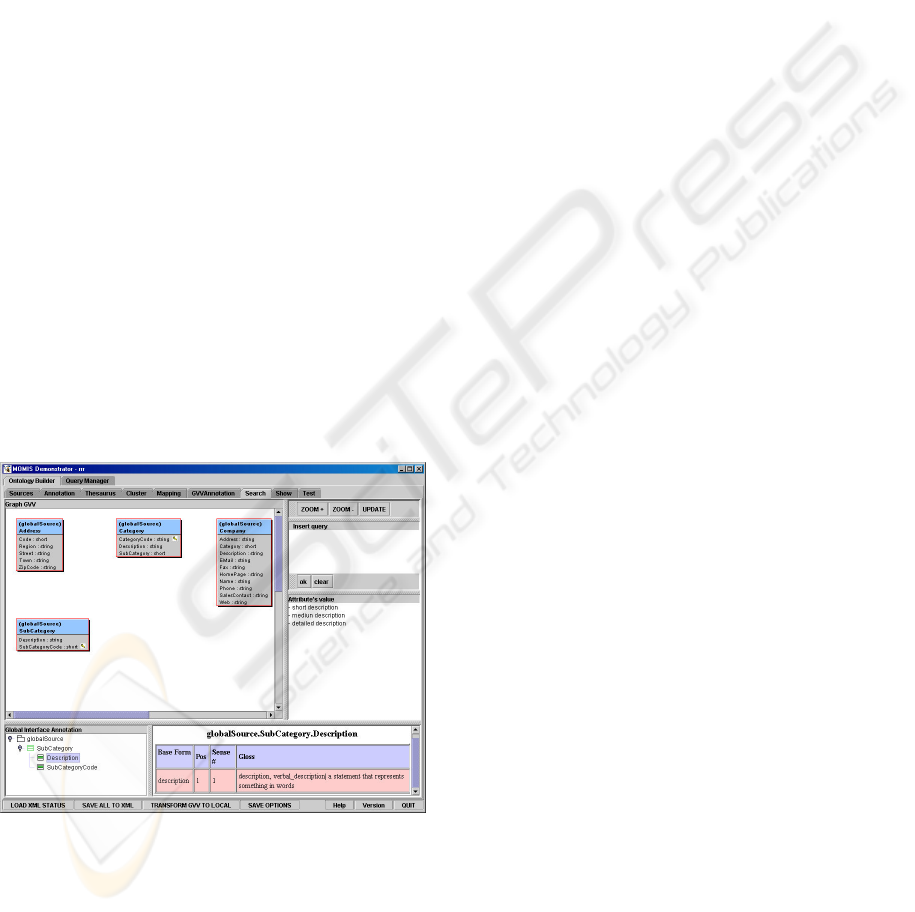
The MOMIS system provides the end user with
a graphical interface where the global classes, the
global attributes, the primary and foreign keys are
shown (see figure 2). This interface enables the end
user to write a query. The interface shows on the left
the complete GVV with an E/R like formalism and a
tree representation. By selecting a class, its WordNet
annotations (i.e. the synsets associated to the class)
are visualized on the bottom panel. Right on the top a
box allows inserting the query.
Figure 2: Screenshot of the MOMIS Query Manager.
On the basis of the knowledge about relevant val-
ues, the queries may exploit selection clauses fitting
in the data:
1. the user is interested to the instances assuming
a specific known value: relevant values do not im-
prove the querying process, but, if an attribute value
is called in different sources in different ways, the
results may not include interesting instances.
2. the user queries an attribute with relevant val-
ues: the user expresses a query, by using the graph-
ical interface, containing a relevant value, i.e. a
condition of the form At = RVN. As stated be-
fore, this condition is equivalent to the condition
At IN RVI. The discussion about how this query
is executed is out of the scope of this paper; intu-
itively:
• In a naive approach the condition At=RVNis
rewritten into a local source L (for simplicity, we
suppose that the global attribute At corresponds
to the same local attribute At in the local sources
L)as
value∈RV I
At = value.
• On the other hand, if the function Contains is
executable/supported by the local source L (this
is a frequent case if the local source is a data-
base), the condition At = RVN may be rewrit-
ten into L as Contains(At,RVN) = true.
4 EVALUATION ON A REAL
DOMAIN
Within the EU SEWASIE project (IST-2001-34825),
we collected information about enterprises working
on the mechanical sector. Our goal was to integrate
information coming from specialized web sites.
4.1 Building the GVV and a
Relevant Attribute Set
Four portals containing data about italian companies
were analyzed:
• www.subforn.net: provides access to a data-
base containing more than 6.000 subcontractors of
eight italian regions. Companies are classified on
the basis of their production. Mechanichal and
mould sectors are divided into 53 different cate-
gories. For each category, several specific kinds of
production (almost 1000) are defined.
• www.plasticaitalia.net: the plasticaitalia
database contains more than 12.000 italian compa-
nies. For each company, several kinds of produc-
tion are indicated: this classification is based on a
three levels hierarchy specializing each kind of pro-
duction in more than 300 cases.
• www.tuttostampi.com: contains 4000 italian
companies categorized in 58 different kinds of ser-
vices.
• www.deformazione.it: more than 2000
companies are catalogued on the basis of 39 dif-
ferent sectors.
WEBIST 2006 - INTERNET TECHNOLOGY
50
By means of the MOMIS system, a GVV rep-
resentative of the four web sites was built. The
simple structure of the original information sources
generates a generic GVV composed of two main
global classes: one storing data about companies, the
second one containing all the production categories
(see figure 3 where a third table allows mapping
companies into categories).
Company(id, name, address, email, fax,
telephone number, country,
foundation year, ... )
Category(id, name)
List categories(company id, category id)
Figure 3: Some of the Global Classes for the mechanical
GVV.
According with this representation, it is very diffi-
cult for a user querying for companies producing on a
specific sector: the user does not have any idea about
the more than 1000 possible categories (the union of
all the different categories used in the four web-sites)
and indicating a specific category may be misleading:
similar categories may be called in different sources
in different ways (and then the user will have no result
or a partial result from his query) or the user may be
interested to a result with a larger granularity. For ex-
ample, if the user searches for companies producing
“mould”, the result will not include companies clas-
sified as producing “Plastic castings”, that
could be interesting for the user. For these reasons,
we apply the “Contains” technique to the global at-
tribute name of the global class category. The re-
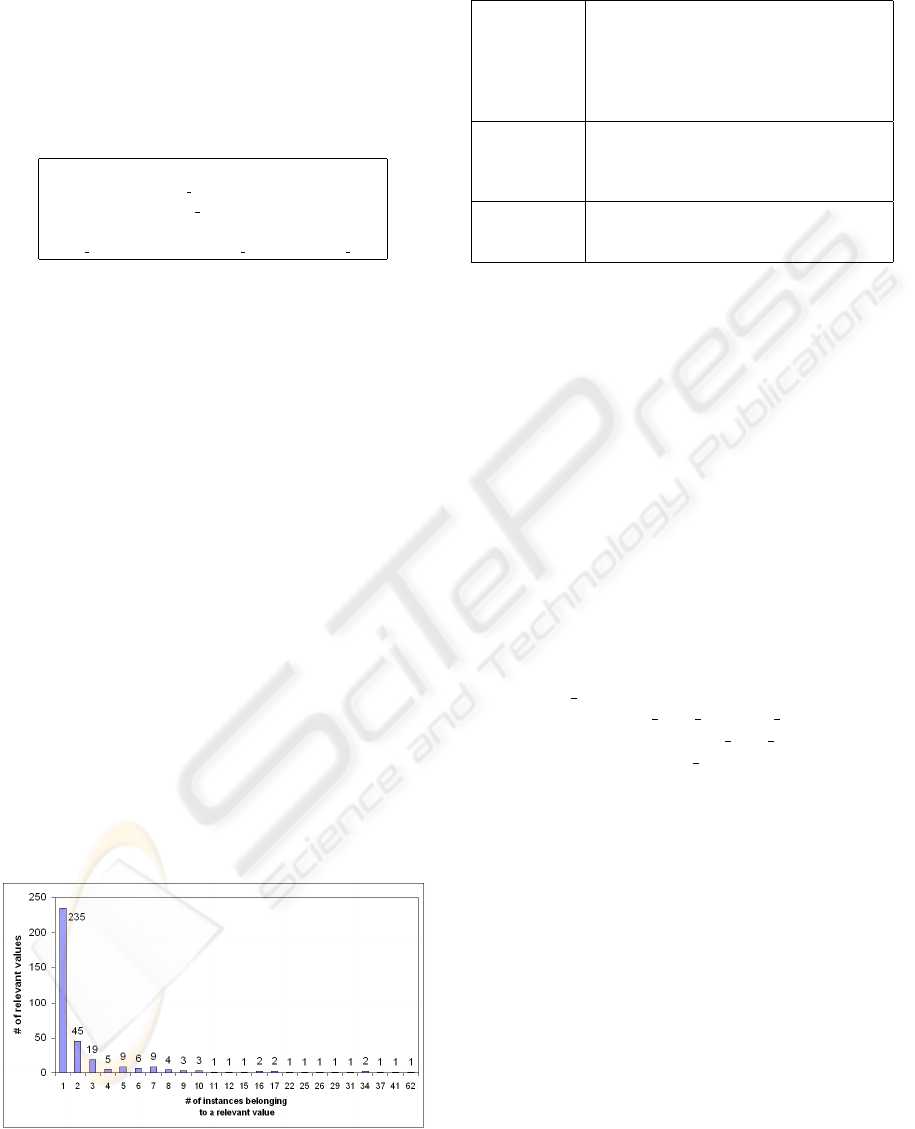
sult was a set of 355 relevant values. Figure 4 shows
the dimension of the obtained relevant values: 34%
of the relevant values (120) represents 80% (845) of
the instances of the selected attributes, while 235 rel-
evant values contain only one instance. Table 1 shows
some significant relevant values and the instances be-
longing to them.
Figure 4: Attributes distribution in the relevant values set.
Table 1: An example of some relevant values.
Castings Castings, Casting zinc and its alloys,
Casting with pouring under pressure,
Cast iron casting, Steel casting, Casting
titanium and its alloys, Aluminum and
magnesium casting, Casting copper and
its alloys, Casting other metals, ...
Moulding Moulding, Compression injection
moulding, Insert moulding, Normal
moulding, Intrusion moulding, Dip
moulding, ...
Windings Windings,Filament winding reinforced
plastic, Transformer windings, Motor
windings, Coil windings
The high number of relevant attributes made up
of only one instance suggested to us to improve our
technique by considering some semantic knowledge
extracted from the original web-sites. E-commerce
web-sites classify their products on the basis of hi-
erarchical classifications. By automatically exploit-
ing these taxonomies with customized wrappers, it
is possible to build a relevant values set taking into
account the semantic grouping of services and goods
made in the original sources. In SEWASIE, the result
was the identification of 135 relevant values. By ex-
ploiting again the original taxonomies, such relevant
values were then classified in a three levels hierarchy.
Figure 5 shows parts of the hierarchy: the first level
divides the categories in two parts: the mechanical
sector and the plastic and rubber sector; then, each
sector is specialized in specific topics. For example,
the “mould
making” relevant value is contained in
the class “plastic
and rubber processes”
that is part of the “plastic
and rubber” sec-
tor. Moreover, the “mould
making” relevant value
stands for 54 values in the local sources, for example
large size moulds, castings, mould manufacturing, ...
Figure 6 shows the dimension and the number of ob-
tained relevant values.
4.2 Querying the GVV by Means of
the Relevant Attribute Set
We suppose that an end user is searching for enter-
prises by using the MOMIS system applied to this
domain. His query may assume different forms:
• The user is looking for enterprises without specify-
ing their kinds of production. The result is a set of
almost 30,000 enterprises and the related produc-
tions (several enterprises belong to more than one
category).
• The user is looking for enterprises belonging to a
specific category (e.g.:mould). The corresponding
query is:
INSTANCES NAVIGATION FOR QUERYING INTEGRATED DATA FROM WEB-SITES
51

Figure 5: Part of the hierarchy of the relevant values for the
category name attribute.
Figure 6: Attributes distribution in the relevant values set
for the SEWASIE project.
select
*
from Company C, List_categories L,
Category Cat
where C.id = L.company_id
and L.category_id = Cat.id
and Cat.name like ’mould’
The result is a set of 89 companies.
• The user is interested to enterprises working
on a category mould manufacturing by
exploiting the relevant values set (e.g.: the
moulding relevant value). In this case he has
to simply indicate the selected relevant value and
the selection clause of the query automatically
changes including as predicate all the instances
belonging to the relevant value. The choice of the
moulding relevant attribute generates a selection
clause
”... Cat.name in (’Moulding’,
’Compression injection moulding’,
’Insert moulding’, ...)”
. The result of this
query is 943 companies if the relevant values set is
calculated by the algorithm described in section 3,
1459 companies if relevant values set is calculated
by means of the “semantic” version (i.e., by using
the mould making value).
5 CONCLUSIONS AND FUTURE
WORK
In this paper we proposed a method to identify the
relevant values of selected global attributes. These
values may be provided to the end user (classified in a
hierarchy when it possible) in order to ease him hav-
ing the knowledge about a Global Class and writing a
query. There are few critical issues to be pointed out:
• the method is based on a data analysis. Working
with instances is a limit of such technique: if data
change, relevant values and the consequent hierar-
chy has to be updated. In specific contexts (data-
bases not frequently updated, e.g. databases for e-
commerce storing the products catalog for a com-
pany), data are almost static and then the calculus
has to be only occasionally re-done. Nevertheless,
the MOMIS wrappers were modified in order to pe-
riodically check the sources for verifying the rele-
vant values consistency.
• the relevant values identification is a critical aspect:
the integration engineer has to define a set of rele-
vant values covering all the possible kinds of val-
ues, with a limited number of different values to be
easily visualized and known by the end user. Other-
wise, the end user does not know the Global Class
contents and does not find the required information
to write a query.
• the method allows a user to write specific queries
having an organized knowledge of the sources con-
tents.
The future work will be addressed on three direc-
tions:
1. to improve the relevant values selection by propos-
ing to the user a multi-strategic approach for ob-
taining the most suitable relevant values set: for
this goal, we think of it is possible to use industrial
standards for classification of services and goods
(e.g. UNSPSC, ecl@ss, NAICS, ...) inside specific
domains both for creating the most suitable set of
relevant values and for creating an automatic hier-
archy of these attributes;
2. to calculate relevant values of multiple global at-
tributes;
3. to improve the Query Manager graphical interface
allowing users to query the GVV without writing
any query.
ACKNOWLEDGMENTS
This work started in the EU SEWASIE project
(IST-2001-34825). Now the research activity
WEBIST 2006 - INTERNET TECHNOLOGY
52

continues within the Italian MIUR PRIN WIS-
DOM project (2004-2006). Further information at
http://www.dbgroup.unimo.it/wisdom.
REFERENCES
Beneventano, D., Bergamaschi, S., Guerra, F., and Vincini,
M. (2003). Synthesizing an integrated ontology. IEEE
Internet Computing Magazine, pages 42–51.
Beneventano, D. and Lenzerini, M. (2005). Final release
of the system prototype for query management. Se-
wasie, Deliverable D.3.5, Final Version, available at
http://www.dbgroup.unimo.it/pubs.html.
Bergamaschi, S., Castano, S., Beneventano, D., and
Vincini, M. (2001). Semantic integration of hetero-
geneous information sources. Data & Knowledge En-
gineering, Special Issue on Intelligent Information In-
tegration, 36(1):215–249.
Broder, A. Z., Maarek, Y. S., Bharat, K., Dumais, S. T.,
Papa, S., Pedersen, J., and Raghavan, P. (2005). Cur-
rent trends in the integration of searching and brows-
ing. In WWW (Special interest tracks and posters),
page 793.
Buneman, P., Davidson, S., Fernandez, M., and Suciu, D.
(1997). Adding structure to unstructured data. In
Proc. of ICDT 1997, pages 336–350, Delphi, Greece.
Chaudhuri, S., Ramakrishnan, R., and Weikum, G. (2005).
Integrating db and ir technologies: What is the sound
of one hand clapping? In Proceedings of the Second
Biennial Conference on Innovative Data Systems Re-
search, Asilomar, CA, USA, pages 1–12.
Dong, X. and Halevy, A. Y. (2005). Malleable schemas: A
preliminary report. In Proceedings of he Eight Inter-
national Workshop on the Web & Databases (WebDB
2005), Baltimore, Maryland, USA, pages 139–144.
Galindo-Legaria, C. A. (1994). Outerjoins as disjunctions.
In Snodgrass, R. T. and Winslett, M., editors, SIG-
MOD Conference, pages 348–358. ACM Press.
Gibson, D., Kleinberg, J., and Raghavan, P. (2000). Cluster-
ing categorical data: an approach based on dynamical
systems. VLDB Journal, 8(3-4):222–236.
Gottlob, G., Koch, C., Baumgartner, R., Herzog, M., and
Flesca, S. (2004). The lixto data extraction project -
back and forth between theory and practice. In Pro-
ceedings of the Twenty-third ACM SIGACT-SIGMOD-
SIGART Symposium on Principles of Database Sys-
tems, pages 1–12, Paris, France.
Halevy, A. (2003). Data integration: a status report. In Pro-
ceedings of the German Database Conference, BTW-
03, Leipzig.
Halevy, A. Y. (2004). Structures, semantics and statistics.
In Proceedings of the 30th International Conference
on VLDB, Toronto, Canada, pages 4–6.
N. Noy, M. Uschold, C. W. (2005). Representing classes
as property values on the semantic web. Seman-
tic Web Best Practices and Deployment Working
Group, part of the W3C Semantic Web Activity.
(http://www.w3.org/TR/swbp-classes-as-values).
Nestorov, S., Abiteboul, S., and Motwani, R. (1997). In-
ferring structure in semistructured data. SIGMOD
Record, 26(4):39–43.
INSTANCES NAVIGATION FOR QUERYING INTEGRATED DATA FROM WEB-SITES
53
