
MINING ANOMALIES IN OBJECT-ORIENTED
IMPLEMENTATIONS THROUGH EXECUTION TRACES
Paria Parsamanesh, Amir Abdollahi Foumani
IBM Rational Software Group
Montreal, Quebec, Canada
Constantinos Constantinides
Department of Computer Science and Software Engineering, Concordia University
Montreal, Quebec, Canada
Keywords:
Software quality, anomalies, program comprehension, aspect mining, dynamic programming.
Abstract:
In the context of a computer program, the term “anomaly” is used to refer to any phenomenon that can neg-
atively affect software quality. Examples of anomalies in object-oriented programs include low cohesion of
modular units, high coupling between modular units and the phenomenon of crosscutting. In this paper we
discuss the theoretical component of a technique to identifying anomalies in object-oriented implementations
based on observation of patterns of messages (invoked operations). Our technique is based on the capturing of
execution traces (paths) into a relational database in order to extract knowledge of anomalies in the system, fo-
cusing on potential crosscutting concerns (aspects). In order to resolve ambiguities between candidate aspects
we deploy dynamic programming to identify optimal solutions.
1 INTRODUCTION
In the context of object-oriented development, the
term “anomaly” refers to any phenomenon that can
negatively affect the quality of software. Examples
include low cohesion of modular units, and high cou-
pling between modular units. Another example which
sometimes lies at the root of the previous two quality
problems is the phenomenon of crosscutting, whereby
the implementation of certain concerns is not well lo-
calized but it cuts across the class hierarchy of the sys-
tem, resulting in scattering of behavior and tangling of
code.
In this paper, we discuss the theoretical compo-
nent of a technique to identifying anomalies in object-
oriented implementations. Our proposal is based on
running use-case scenarios and capturing the corre-
sponding execution traces in a relational database
where we can then make observations over cer-
tain patterns of messages (invoked operations). The
knowledge we extract can provide information on po-
tential crosscutting concerns (aspect candidates). In
order to identify an optimal solution while choosing
an aspect among a collection of aspect candidates, we
deploy dynamic programming algorithms.
The rest of this paper is organized as follows: In
Section 2 we discuss the necessary theoretical back-
ground to this research. In Section 3 we discuss the
problem and motivation behind this research. In Sec-
tion 4 we present our proposal and in Section 5 we
present our methodology. In Section 6 we discuss
related work and comparisons to our proposal. We
conclude our work in Section 7 with a summary, dis-
cussion and pointers to future research directions.
2 THEORETICAL BACKGROUND
The principle of separation of concerns (Parnas,
1972; Dijkstra, 1976) refers to the realization of sys-
tem concepts into separate software units and it is a
fundamental principle to software development. The
associated benefits include better analysis and un-
derstanding of systems, readability of code, a high-
level of design-level reuse, easy adaptability and good
maintainability. To this end, the notions of cohesion
and coupling are the fundamental measures of qual-
ity in an object-oriented software system. Cohesion
is the degree to which a module performs a single re-
sponsibility (i.e. it addresses a single concern). Cou-
pling (or dependency) is the degree to which each pro-
gram module relies on another module. Two objects
are said to be coupled if they act upon one another
(Chidamber and Kemerer, 1991). While structuring
object-oriented programs, aiming for high-cohesion
and low coupling are two general goals in order to
177
Parsamanesh P., Abdollahi Foumani A. and Constantinides C. (2006).
MINING ANOMALIES IN OBJECT-ORIENTED IMPLEMENTATIONS THROUGH EXECUTION TRACES.
In Proceedings of the First International Conference on Software and Data Technologies, pages 177-189
DOI: 10.5220/0001321101770189
Copyright
c
SciTePress

support separation of concerns, thus providing sys-
tems which are easier to understand and maintain.
Despite the success of object-orientation in the ef-
fort to achieve separation of concerns, certain proper-
ties cannot be directly mapped in a one-to-one fash-
ion from the problem domain to the solution space,
and thus cannot be localized in single modular units.
Their implementation ends up cutting across the in-
heritance hierarchy of the system. Crosscutting con-
cerns (or “aspects”) include persistence, authentica-
tion, synchronization and logging. The “crosscutting
phenomenon” creates two implications: 1) the scatter-
ing of concerns over a number of modular units and 2)
the tangling of code in modular units. As a result, de-
velopers are faced with a number of problems includ-
ing a low level of cohesion of modular units, strong
coupling between modular units and difficult compre-
hensibility, resulting in programs that are more error
prone.
Aspect-Oriented Programming (AOP) (Kiczales
et al., 1997; Elrad et al., 2001) explicitly addresses
those concerns which “can not be cleanly encapsu-
lated in a generalized procedure (i.e. object, method,
procedure, API)” (Kiczales et al., 1997) by introduc-
ing the notion of an aspect definition, which is a mod-
ular unit of decomposition. There is currently a grow-
ing number of approaches and technologies to support
AOP. One such notable technology is AspectJ (Kicza-
les et al., 2001), a general-purpose aspect-oriented
language, which has influenced the design dimen-
sions of several other general-purpose aspect-oriented
languages, and has provided the community with a
common vocabulary based on its own linguistic con-
structs. In the AspectJ model, an aspect definition is
a new unit of modularity providing behaviour to be
inserted over functional components. This behaviour
is defined in method-like blocks called advice blocks.
However, unlike a method, an advice block is never
explicitly called. Instead, it is activated by an associ-
ated construct called a pointcut expression. A point-
cut expression is a predicate over well-defined points
in the execution of the program which are referred to
as join points. When the program execution reaches
a join point captured by a pointcut expression, the as-
sociated advice block is executed. Even though the
specification and level of granularity of the join point
model differ from one language to another, common
join points in current language specifications include
calls to methods and execution of methods. Most
aspect-oriented languages provide a level of granu-
larity which specifies exactly when an advice block
should be executed, such as executing before, after,
or instead of the code defined at the associated join
point. Furthermore, much like a class, an aspect def-
inition may contain state and behavior. It is also im-
portant to note that AOP is neither limited to object-
oriented programming nor to the imperative program-
ming paradigm. However, we will restrict this discus-
sion to the context of object-oriented programming.
3 PROBLEM AND MOTIVATION
As the complexity of software systems increases, it
becomes more challenging to build software that is
free of certain quality problems, collectively referred
to as “anomalies.” Given an object-oriented program,
we would like to be able to achieve program com-
prehension in order to identify anomalies at specific
points over the implementation so that we can then
make decisions about possible transformations such
as refactoring or reengineering activities.
4 PROPOSAL
In this section we discuss our proposal to aid in the
provision of high-quality systems. Several techniques
have already been proposed in the literature for de-
tecting low cohesion, high coupling and crosscutting
in object-oriented implementations (Robillard and
Murphy, 2001; Robillard and Murphy, 2002; Krinke
and Breu, 2004; Breu and Krinke, 2004; Moldovan
and Serban, 2006). In this work we build on current
proposals by discussing the theoretical component of
a technique to identify anomalies in object-oriented
programs based on the monitoring of execution traces
and the identification of patterns of invoked opera-
tions. More specifically, our proposal is based on run-
ning use-case scenarios and capturing the correspond-
ing execution traces into a relational database. We can
then apply certain strategies which can help us iden-
tify anomalies. In cases of the existence of several
candidate aspects, we can deploy dynamic program-
ming to resolve ambiguities.
5 METHODOLOGY:
EXTRACTING KNOWLEDGE
In this section we discuss how our proposal is being
realized.
Consider the relational database schema in Figure 1
which can store message sequences at run time. The
main entities of the schema are defined as follows:
• Class: A class encapsulates state and behavior.
Class instances (objects) send and receive mes-
sages.
• Method: Methods collectively make the behavior
of a class. In this model we only consider those
methods which appear in execution paths.
ICSOFT 2006 - INTERNATIONAL CONFERENCE ON SOFTWARE AND DATA TECHNOLOGIES
178

• Message: A message is an invocation of a method
involving a caller (sender) object and a callee (re-
ceiver) object. A message is received and acted
upon by a method inside a class definition, i.e.
< message >::= object − name.operation −
name. A message implements a partial responsi-
bility of a system operation and it forms part of a
use-case scenario.
• Execution path: A use-case scenario is described as
a sequence of interactions between entities. During
requirements analysis, this sequence is described
at a high-level of abstraction in terms of the inter-
action between an actor and the system where the
latter is viewed as a black box. During design, a
fine grained model captures sequences of interac-
tions between class instances through an ordered
sequence of message passing. We define this or-
dered sequence of message passing as an execution
path, i.e. < executionpath >::=< message
+
>.
ExecutionPath
PKPATH_ ID
NUMBER_OF_EXECUTION
Message
PK MESSAGE_ID
FK1 PATH_ID
FK2 METHOD_ID
MESSAGE_ORDER
Class
PKCLASS_ID
CLASS_NAME
Method
PK METHOD_ID
FK1 CLASS_ID
METHOD_NAME
Figure 1: Relational database schema for storing execution
paths.
Main idea: Our technique to identify anomalies in
object-oriented implementations is based on captur-
ing execution paths as data from the runtime environ-
ment and populating a relational database. Data can
then be analyzed in order to provide information in
the form of meaningful statistics. In doing so, we can
proceed as follows:
1. Generate data: Execute all possible use-case sce-
narios. Each use-case scenario is comprised by a
sequence of execution paths.
2. Capture data: Capture execution traces as data and
store them into a relational database schema.
3. Analyze data: We identify patterns of messages
in execution paths. By applying certain strategies
which we have developed (to be discussed next),
we can identify anomalies based on the result sets.
In the next subsections we will describe the three
different types of knowledge on anomalies we wish to
acquire from the relational database schema, namely
low cohesion, high coupling and crosscuttings. We
define algorithms to identify the three types of anoma-
lies.
5.1 Identifying Low Cohesion
We provide the following definitions:
Definition 5.1 The term “fanin” is used to define the
number of messages that a given object receives over
a single execution path. The term is also defined for
methods.
Definition 5.2 The term “fanout” is used to define
the number of messages that a given object sends to
other objects over a single execution path. The term
is also defined for methods.
Definition 5.3 A class is defined to be independent
in the context of a use-case scenario, if 1) the class
forms an integral part of the use-case scenario and 2)
the class is not dependent on any other classes within
the use-case scenario. We can consider independent
classes as potential aspects (Foumani and Constan-
tinides, 2005a; Foumani and Constantinides, 2005b).
We would like to obtain the following knowledge:
• Classes that are involved in (short length) scenarios
that have large fanin and low fanout can be consid-
ered as having low-cohesion or having an indepen-
dent role in a use-case scenario.
• Methods that are involved in (short length) sce-
narios that have large fanin and low fanout can
be considered as having low-cohesion or having
an independent role in a use-case scenario. These
methods can be separated from their original class
through refactoring and they can be captured as ad-
vice blocks inside aspect definitions.
Definition 5.4 We define “class independency fac-
tor” (CIF ) as
CIF =
(class fanin)
(class fanout)
In the case where class f anout = 0 (in which
case CIF → ∞), the class is considered as one with
an independent role and it can be a candidate aspect.
To calculate this factor we need to execute statements
to measure class fanin, and class fanout which is de-
scribed in the subsequent subsections.
5.1.1 Measuring Class Fanin
In the following query we iterate over all messages
in all execution paths where a unique identifier for a
given class, CLASS
ID, is provided, and we count the
number of references to the class:
MINING ANOMALIES IN OBJECT-ORIENTED IMPLEMENTATIONS THROUGH EXECUTION TRACES
179

Select count(mth.CLASS_ID)
From Message msg
Join Method mth
On mth.METHOD_ID = msg.METHOD_ID And
mth.CLASS_ID = [CLASS ID]
5.1.2 Measuring Class Fanout
In the following query we count the number of classes
referenced by a given class.
Select count(Distinct mth_out.CLASS_ID)
From Message msg
Join Message msg_out
On msg_out.PATH_ID = msg.PATH_ID
And msg_out.MESSAGE_Id <> msg.MESSAGE_ID
And msg_out.MESSAGE_ORDER = msg.MESSAGE_ORDER + 1
Join Method mth
On mth.METHOD_ID = msg.METHOD_ID
And mth.CLASS_ID = [CLASS ID]
Join Method mth_out
On mth_out.METHOD_ID = msg_out.METHOD_ID
And mth_out.CLASS_ID <> [CLASS ID]
The queries in 5.1.1 and 5.1.2 enable the calcu-
lation of the CIF factor for any given class. We are
interested in classes with high CIF values (percent-
ages). These classes can be considered as a bottle-
neck in an object-oriented system for the following
two reasons:
1. They may have many responsibilities (low cohe-
sion). In this case we can follow a refactoring
strategy to break the responsibilities and achieve a
higher separation of concerns.
2. They may have an independent role (and can be po-
tential aspects).
Definition 5.5 We define “method independency fac-
tor” (MIF), as
MIF =
(method fanin)
(method fanout)
In the case where method fanout = 0 (in which
case M IF → ∞), the method can be modeled as an
advice block inside an aspect definition as this is an
independent entity. In order to calculate this factor
we need to execute similar queries to those we de-
scribed above to calculate the fanin and fanout values
of each method. We are interested in methods with
high MIF values (percentages). These methods can
also be considered as a bottleneck for the same rea-
sons described above for classes. As in the case with
classes, object-oriented refactoring or migration to an
aspect-oriented context can provide a viable solution.
Definition 5.6 To identify classes with low cohesion,
we define class cohesion factor (CCH),
CCH =
(number of classes in execution path)
(number of methods in execution path)
The CCH factor defines the distribution of invoked
methods in an execution path between classes. In
other words, CCH defines the distribution of respon-
sibilities between classes. According to this definition
we may have the following cases:
• CCH ≪ 1: Many methods of a few classes are
called in a given execution path. This implies that
we have classes with low cohesion.
• CCH ≈ 1: Logical distribution of responsibility
between methods of classes. To maintain high co-
hesion we need to have a CCH value very close
to 1. This would imply that the number of in-
voked methods and the number of classes involved
in a use-case scenario should be very close to each
other. We can identify an exception when there is
only one class and one method referenced in the ex-
ecution path. In this case, even though CCH = 1,
we would still have low cohesion of the given class
and its corresponding method.
Table 1 provides different illustrative cases for cal-
culating and interpreting CCH.
5.2 Identifying High Coupling
To investigate coupling and identify classes with high
coupling we need to calculate two factors:
1. CCH: class cohesion factor. Recall that CCH ≪
1 implies that many methods of a few classes are
invoked in a given execution path.
2. The fanin of each method. This can be provided by
the count of the number of invocations originated
from (methods of) other classes.
Definition 5.7 For two classes C
i
and C
j
with meth-
ods M
i
and M
j
respectively, we define “class cou-
pling” factor (CCP ) as
CCP =
P
Ci.fanin(M
i
, C
j
)
P
Cj.fanin(M
j
, C
i
)
or
CCP =
P
fanin(Ci, Cj)
P
fanin(Cj, Ci)
The term C
i
.fanin(M
i
, C
j
) refers to the number
of invocations for method C
i
.M
i
that are originated
from C
j
. The term f anin(C
i
, C
j
) refers to the num-
ber of messages received in C
i
from C
j
. If CCP ≈ 1
(the summation of fanin of methods of class Ci is
very close to the summation of fanin of methods of
class Cj) we can say that the degree of coupling be-
tween these two classes is high. If one of these sum-
mations is zero, then we will have low coupling. If
C
i
.fanin(M
i
, C
j
) ≫ 0, or Cj.f anin(M
j
, C
i
) ≫ 0,
then we identify another type of anomaly which we
call a “high dependency” of C
j
over C
i
or vice versa.
Table 2 provides different illustrative cases for calcu-
lating and interpreting CCP .
Example: Consider Figure 2 which illustrates an
example execution path. Initially, we need to obtain
CCH to see whether many methods of few classes
ICSOFT 2006 - INTERNATIONAL CONFERENCE ON SOFTWARE AND DATA TECHNOLOGIES
180
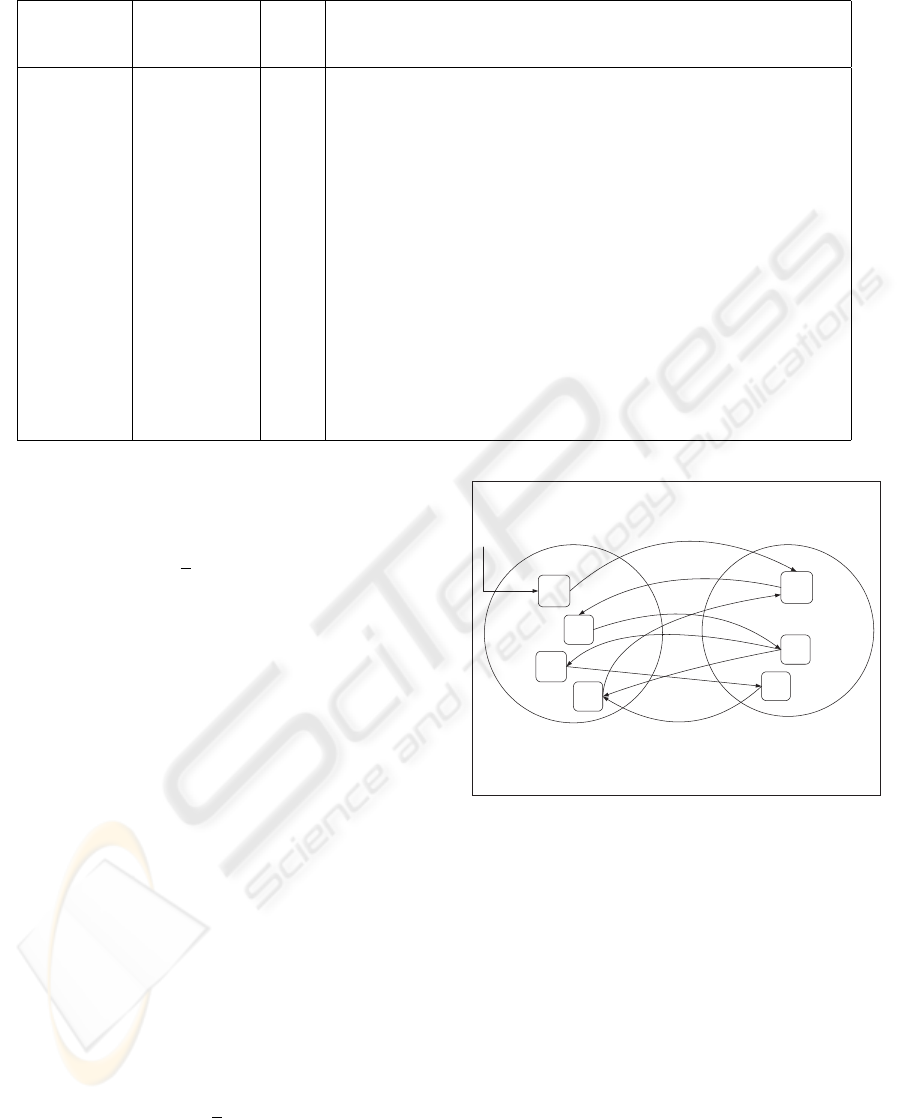
Table 1: Examples of class cohesion through the CCH factor with interpretations.
# of classes # of methods CCH Interpetation
1 1 1 Since this is the only class in the execution path, this implies
that the class has low cohesion.
1 5 0.2 Low cohesion at the class level.
2 20 0.1 Low cohesion at the class level.
4 4 1 High cohesion at the class level; Logical distribution of
responsibilities between classes.
5 7 0.7 High cohesion at the class level. In this case we still may have
low cohesion at the method level; To identify low cohesion at
the method level we need to calculate the MIF factor for each
method. We consider methods with high M IF value as
candidate methods with low cohesion.
are invoked during execution. CCH is obtained as
follows:
CCH =
2
8
= 0.25 ≪ 1
The very small value of CCH indicates a potential
high coupling between the involved classes. To inves-
tigate high coupling further, we must read the CCP
value, which can be obtained as follows:
X
C
i
.fanin(M
i
, C
j
) = fanin(C
i
.M
1
, C
j
) +
fanin(C
i
.M
2
, C
j
) +
fanin(C
i
.M
3
, C
j
) +
fanin(C
i
.M
4
, C
j
)
= 0 + 1 + 1 + 2
= 4
X
C
j
.fanin(M
j
, C
i
) = fanin(C
j
.M
5
) +
fanin(C
j
.M
6
) +
fanin(C
j
.M
7
)
= 2 + 1 + 1
= 4
CCP =
4
4
= 1
The value of CCP indicates that there is indeed
high coupling between the two classes C
i
and C
j
.
M4
M5
M6
M7
Class Ci Class Cj
M3
M2
M1
Figure 2: Illustration of high coupling.
5.3 Identifying Crosscutting
To identify crosscutting we first need to obtain a set
of execution paths. Consider the following:
<path1> ::=
<...,obj2.op2,obj3.op3,obj4.op4,obj5.op5,...>
<path2> ::=
<...,obj2.op2,obj3.op3,obj4.op4,obj5.op5,...>
<path3> ::=
<...,obj2.op2,obj3.op3,obj4.op4,obj5.op5,...>
<path4> ::=
<...,obj1.op1,obj2.op2,...>
<path5> ::=
<...,obj1.op1,obj2.op2,...>
<path6> ::=
MINING ANOMALIES IN OBJECT-ORIENTED IMPLEMENTATIONS THROUGH EXECUTION TRACES
181
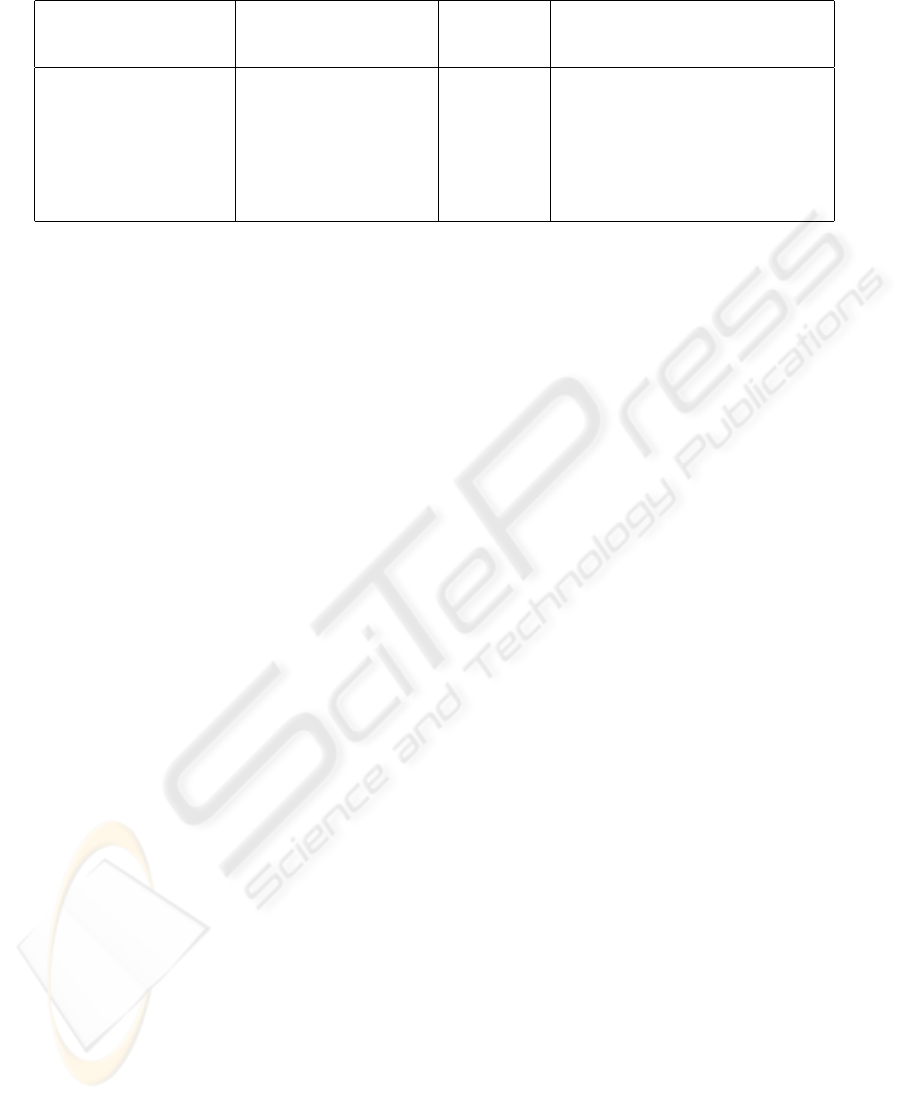
Table 2: Interpretation of class dependency.
P
C
i
.fanin(M
i
, C
j
)
P
C
j
.fanin(M
j
, C
i
)
CCP Interpretation
0 ≫ 1 ∞ High dependency of C
i
over C
j
.
0 1 ∞ Low coupling.
6 7 ≈ 1 or > 1 High coupling.
<...,obj1.op1,obj2.op2,...>
<path7> ::=
<...,obj4.op4,obj5.op5,obj6.op6,...>
<path8> ::=
<...,obj4.op4,obj5.op5,obj6.op6,...>
<path9> ::=
<...,obj3.op3,obj4.op4,obj5.op5,obj6.op6,...>
<path10> ::=
<...,obj3.op3,obj4.op4,obj5.op5,obj6.op6,...>
A crosscutting path, indicated by S
k
, is one whose
sequence of messages occurs in several execution
paths. Consider the following crosscutting paths
based on the above execution paths S
1−10
:
Sa(path 1,2,3):
<obj2.op2, obj3.op3, obj4.op4, obj5.op5>
Sb(path 4,5,6):
<obj1.op1, obj2.op2>
Sc(path 7,8):
<obj4.op4, obj5.op5, obj6.op6>
Sd(path 9,10):
<obj3.op3, obj4.op4, obj5.op5, obj6.op6>
We define S as the set of all sequences S
k
. Essen-
tially S is a set of candidate aspects. Aspect candi-
dates should not contain common operations because
this will violate the semantics (logic) of the initial
object-oriented system. As a result, intersections be-
tween the aspect candidate sets constitute redundan-
cies. We, therefore, need to identify which one among
those sets (or subsets of them) can constitute better
candidate aspect sets. In the following subsections we
describe an algorithm in order to identify aspect can-
didates in situations when selecting aspect candidates
is ambiguous.
5.3.1 Identifying Orthogonal Aspect Candidate
Sets
This subsection presents an algorithm to address the
issue of redundancies and the identification of strong
candidate aspects. The goal is to eliminate redun-
dancies by identifying aspect candidate sets that do
not have common operations. The algorithm has two
steps. In the first step the algorithm eliminates the
longest common sets from the list of message se-
quences. The longest common set (there could be
more than one) is one which can be obtained by the
union of others. As a result, we can remove the
longest common sets from S, the set of aspect candi-
dates. In the second step the algorithm finds orthogo-
nal sets. An orthogonal set is one which does not have
any common element with any other set.
Suppose S = {S
1
, S
2
, S
3
, . . . , S
x
, . . . , S
n
} is a set
of message sequences and we suppose S
x
is a mes-
sage sequence in the set with the longest common set.
Step 1: Eliminating longest common sets. In order
to identify a longest common set, we define S
′
= S −
S
x
. S
x
is the longest common set if the following
conditions hold:
∃ S
i
∈ S
′
: S
x
\
S
i
6= ∅
m
[
i=1
S
i
= S
x
, ∀ S
i
∈ S
′
The first condition satisfies that a given set has
common elements with some of the other message se-
quences. The second condition satisfies that S
x
can
be covered by the union of some of the other message
sequences. We can now define set S
′
as a new set
of aspect candidates by removing S
x
from set S. We
repeat this process for all the other members of the as-
pect candidate set until there is no member that can be
covered by a union of other members. In the example,
we identify S
d
as the longest common set (Figure 3),
since:
S
d
\
S
a
6= ∅
S
d
\
S
b
= ∅
S
d
\
S
c
6= ∅
S
d
= S
a
[
S
c
Figure 4 illustrates S, the set of all message se-
quences and set of candidate aspects, after having re-
moved S
d
, the longest common message sequence.
ICSOFT 2006 - INTERNATIONAL CONFERENCE ON SOFTWARE AND DATA TECHNOLOGIES
182

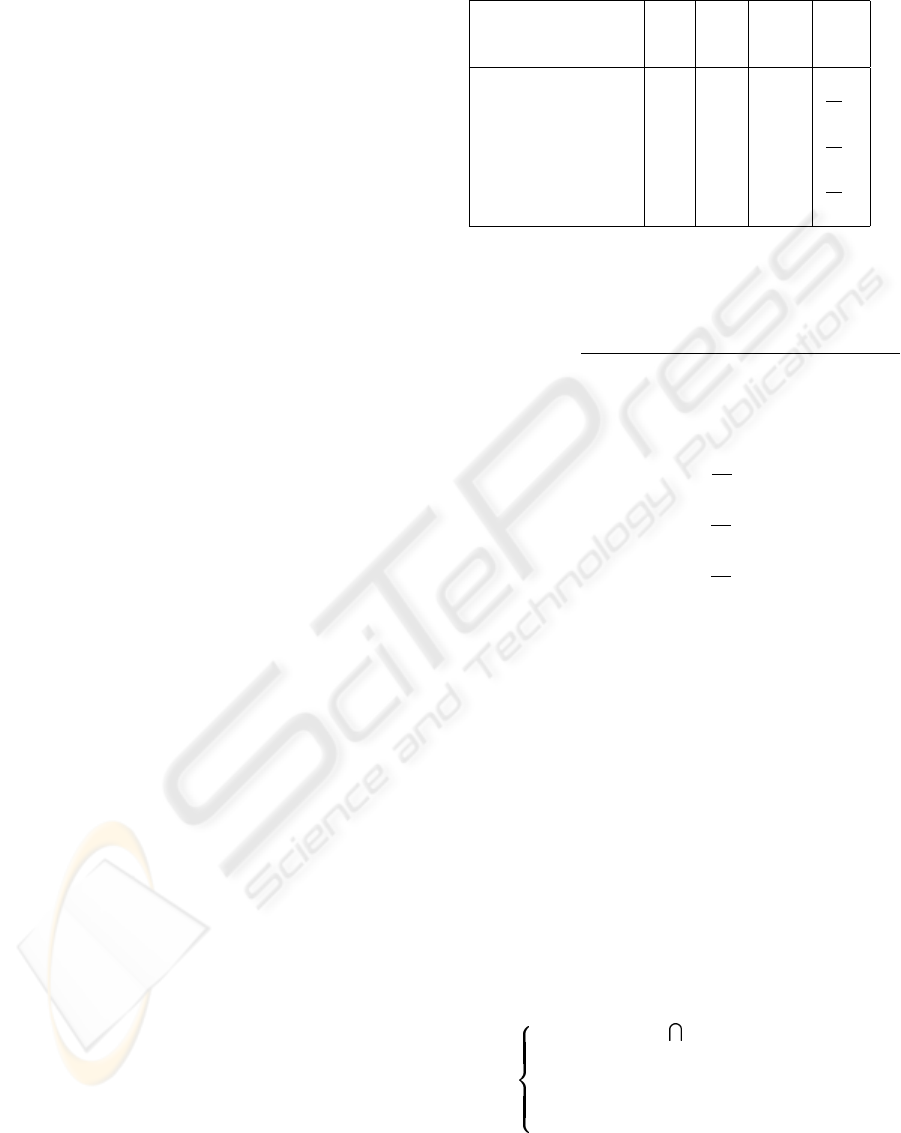
op2
Sa
op3 op4 op5
op2
Sa
op3 op4 op5
op2
Sa
op3 op4 op5
op1
Sb
op2
op1
Sb
op2
Sc op4 op5 op6
Sc op4 op5 op6
Sd op4 op5 op6op3
Sd op4 op5 op6op3
op1
Sb
op2
Figure 3: Illustration of execution paths. S
d
is the longest
common message sequence.
op2
Sa
op3 op4 op5
op2
Sa
op3 op4 op5
op2
Sa
op3 op4 op5
op1
Sb
op2
op1
Sb
op2
Sc op4 op5 op6
Sc
op4 op5 op6
A1 A2 A3 A4 A5
op1
Sb
op2
Figure 4: Orthogonal sets.
Step 2: Find orthogonal sets. This would imply
eliminating the vertical redundancies of operations in
Figure 4. We define S
′
= S − S
x
such that S
x
is
one of the longest message sequence and the follow-
ing conditions hold:
∃ S
i
∈ S
′
: S
x
\
S
i
6= ∅
m
[
i=1
S
i
6= S
x
, ∀ S
i
∈ S
′
The first condition satisfies that a given set has
common elements with at least one other set. The
second condition satisfies that S
x
cannot be defined
by the union of other sets. We can use the following
algorithm to identify orthogonal sets (which are con-
sidered aspect candidates):
1. Find common members of S
x
with S
i
as C
i
set
∃ S
i
∈ S
′
: S
x
\
S
i
= C
i
2. Define C
′
i
as a set of all members of S
x
that are
not in S
i
.
S
i
− C
i
= C
′
i
, ∀ S
i
∈ S
′
3. Define S
′
x
as a set of S
x
members except the
members that belong to C
i
s
S
′
x
= S
x
−
m
[
i=1
C
i
, ∀ S
i
∈ S
′
4. Replace set S with a new set of aspect candidates
such that each S
i
in S is replaced by C
i
and C
′
i
and
also S
a
replace with S
′
a
.
5. We repeat steps 1 to 4 until we have reached the
following condition:
S
i
\
S
j
= ∅, ∀ S
i
, S
j
∈ S and i 6= j
This condition satisfies that there are no two sets
with common members in S. In this case, the mem-
bers of S can be defined as aspect candidates.
Applying this algorithm to the example (Figure 4)
where S = { S
a
, S
b
, S
c
}, and starting with sequence
S
a
, we obtain the following:
1. Find common members of S
a
with S
b
and S
c
as
C
b
and C
c
sets:
C
b
= S
a
\
S
b
= {op2}
C
c
= S
a
\
S
c
= {op4, op5}
2. Define C
′
b
and C
′
c
as sets of all members of S
b
and S
c
that are not in S
a
.
C
′
b
= S
b
− C
b
= {op1}
C
′
c
= S
c
− C
c
= {op6}
3. Define S
′
a
as a set of S
a
members except the
members that belong to C
b
and C
c
S
′
a
= S
a
− (C
b
\
C
c
) = {op3}
4. Replace set S with a new set of aspect candidates
such that each S
b
in S is replaced by C
b
and C
′
b
, S
c
in
S is replaced by C
c
and C
′
c
and S
a
replace with S
′
a
.
S = {S
′
a
, C
b
, C
′
b
, C
c
, C
′
c
}
5. Since S holds orthogonal sets, we do not need to
repeat the algorithm.
In Figure 4 we identify A
1−5
as orthogonal sets,
all these being potential aspects. In general, it is
highly unlikely that aspects are completely orthogo-
nal of each other. When aspects affect the same join
point in one particular sequence, then the order of
aspect (advice) execution is important, as this must
preserve the semantics of the original object-oriented
MINING ANOMALIES IN OBJECT-ORIENTED IMPLEMENTATIONS THROUGH EXECUTION TRACES
183
system. For example for the aspect candidates in Fig-
ure 4, aspects should be defined with the following
precedence:
A
1
−→ A
2
−→ A
3
−→ A
4
−→ A
5
This algorithm identifies a set of aspects by break-
ing down the clone message sequences into the lowest
level of their method invocations such that there are
no conflicts between these sets. However, we believe
that this cannot be an optimal solution for the problem
since it does not consider the following parameters:
1. Number of identified aspects.
2. Number of different types of concerns addressed by
each aspect definition. An aspect definition may be
defined with low cohesion.
3. Number of messages in a given execution path.
4. Number of execution paths in a given use-case sce-
nario.
5. Number of runs of all execution paths.
In order to provide optimal solution for the second
step of the algorithm, we deploy dynamic program-
ming which is discussed in the next subsections.
5.3.2 Redundancy of Adjacent Invocations (Rai)
In this subsection we introduce a dynamic program-
ming algorithm to identify aspect/advice candidates
based on a set of given parameters. Dynamic pro-
gramming (Cormen et al., 2002) is typically applied
to optimization problems. In such problems there can
be many possible solutions. Each solution has a value,
and we wish to find a solution with the optimal (mini-
mum or maximum) value. In this example, we wish to
define parts of message sequences as an aspect (such
that the selected operations can be modeled as an ad-
vice block) in such a way that the message sequence
satisfies the following conditions:
1. It is used in the maximum number of paths.
2. It has the maximum RAI value.
3. It contains the minimum number of classes.
4. It contains the minimum number of operations.
We believe this strategy can identify a stronger set
of aspect candidates since it selects the most utilized
operations. By minimizing the number of classes and
operations we achieve a better modularity. We ini-
tially define two new factors to detect clone message
sequence and also we introduce new algorithms to
identify aspect candidates.
Definition 5.8 We define “redundancy of adjacent in-
vocations” (RAI) of a given execution path to be the
Table 3: Statistics for message sequences in Figure 3.
Message Sequence NC NO NX RAI
S
a
4 4 1000
3
10
S
b
2 2 100
2
10
S
c
2 3 100
2
10
ratio of the recurrence of a sequence S
k
of adjacent
messages, over the total number of execution paths.
RAI(path) =
(recurrence of a message sequence)
(total number of paths)
As a result, for each execution path in the example
of Section 5.3 we have the following RAI measures:
RAI(S
a
) =
3
10
RAI(S
b
) =
3
10
RAI(S
c
) =
2
10
From the set S = {S
a
, S
b
, S
c
}, we need to select
a message sequence or sequences that will be the best
candidate for an aspect. Table 3 provides illustrative
cases for the following parameters:
NC: Number of classes in a given execution path.
NO: Number of different operations in a given exe-
cution path.
NX: Number of execution times of given execution
paths.
We define the following recurrence equation to se-
lect the next aspect candidate from set S and we de-
fine S
′
as a new set of aspect candidates. Each time
we will add S
x
that is selected from the following
equation into set S
′
.
S
x
=
S
i
S
i
S
j
= ∅, ∀ S
i
, S
j
∈ S.
Max(NX),
Max(RAI),
Min(NC),
Min(NO)
otherwise.
According to this recurrence equation, we select
S
x
that does not have any common member with
the other S
i
’s in set S. For S
i
’s that have common
ICSOFT 2006 - INTERNATIONAL CONFERENCE ON SOFTWARE AND DATA TECHNOLOGIES
184

members we recursively select S
x
that has a max-
imum NX value, maximum RAI value, minimum
NC value and minimum OP value. For the selected
S
x
we apply the following formula to identify aspect
candidates:
S
x
= S
x
−
m
[
i=1
S
i
, ∀ S
i
∈ S
′
In the example, by applying this algorithm we
select S
a
as the first candidate aspect (as it has
MAX(N X)). The second aspect candidate accord-
ing to Table 3 would be S
b
and since there is no in-
tersection between S
a
and S
b
, we identify the latter
as a new aspect candidate. The last aspect candidate,
S
c
, has an intersection with both S
a
and S
b
. For this
reason we apply the above formula for S
c
to obtain a
strong aspect candidate, i.e.
S
c
= S
c
− (S
a
[
S
b
) = op3
Our RAI optimization strategy has decreased the
number of candidate aspects from five down to three.
5.3.3 Family Related Dependency (Frd)
Consider the following paths that contain method in-
vocations in the same class, disregarding any possible
gaps between them:
<path1> ::=
<...,obj1.op1,...,obj1.op2,...,obj1.op3,...>
<path2> ::=
<...,obj1.op1,...,obj1.op2,...>
<path3> ::=
<...,obj1.op1,...,ob1.op2,...,obj1.op3,...>
<path4> ::=
<...,obj2.op1,...,obj2.op2,...>
<path5> ::=
<...,obj2.op1,...,obj2.op2,...,obj2.op3,...>
<path6> ::=
<...,obj1.op5,...,obj1.op6,...,obj1.op7,...,obj1.op8,...>
<path7> ::=
<...,obj1.op5,...,obj1.op6,...,obj1.op7,...,obj1.op8,...>
<path8> ::=
<...,obj1.op5,...,obj1.op6,...,obj1.op7,...,obj1.op8,...>
<path9> ::=
<...,obj1.op9,...,obj1.op10,...,obj1.op111,...>
<path10> ::=
<...,obj1.op9,...,obj1.op10,...,obj1.op111,...>
We define S
k
as a sequence of messages that occurs
in several paths. For example,
Sa(path 1, 3): <obj1.op1, obj1.op2, obj1.op3>
Sb(path 1, 2, 3):<obj1.op1, obj1.op2>
Sc(path 4, 5):<obj2.op1, obj2.op2>
Sd(path 6, 7, 8):<obj1.op5, obj1.op6, obj1.op7, obj1.op8>
Se(path 9, 10):<obj1.op9, obj1.op10, obj1.op111>
Definition 5.9 We define “family-related depen-
dency” (FRD) on a given execution path as the ratio
of the recurrence of a sequence S
k
of messages sent
to the same class, over the total number of execution
paths.
F RD(path) =
(number of selected paths)
(total number of paths)
As a result, for each execution path we have the
following F RD measures:
F RD(S
a
) =
2
10
F RD(S
b
) =
3
10
F RD(S
c
) =
2
10
F RD(S
d
) =
3
10
F RD(S
e
) =
2
10
From the set S = {S
a
, S
b
, S
c
, S
d
, S
e
}, we need to
select a sequence or sequences that will be the best
aspect candidate. Identifying orthogonal aspect algo-
rithm as mentioned before cannot find the optimal set
of aspects. In the case of family independent depen-
dency, we introduce another dynamic programming
algorithm that uses the following parameters. Table 4
provides illustrative cases for these parameters:
1. Number of different classes in each message se-
quence (NC)(this parameter in F RD is always
equal to 1).
2. Number of different operations in each message se-
quence (NO).
3. F RD value for message sequences.
We define the following recurrence equation to se-
lect the next aspect candidate from Set S and we de-
fine S
′
as a new set of aspect candidates. Each time
we will add S
x
that is selected from the following for-
mula into Set S
′
.
S
x
=
S
i
S
i
.obj /∈ S
j
.obj, ∀ S
j
∈ S, j 6= i.
Max(FRD),
Min(NO)
otherwise
This algorithm selects all the message sequences
that use an object that is not used in any other mes-
sage sequences; For example, S
c
in Table 4 uses obj2
that is not used in the other message sequences. For
the other message sequences we recursively select the
MINING ANOMALIES IN OBJECT-ORIENTED IMPLEMENTATIONS THROUGH EXECUTION TRACES
185
Table 4: Parameters for F RD.
Message Sequence NC NO FRD obj
S
a
1 3
2
10
obj1
S
b
1 2
3
10
obj1
S
c
1 2
2
10
obj2
S
d
1 4
3
10
obj1
S
e
1 3
2
10
obj1
message sequence with maximum F RD and mini-
mum number of OP . For each selected S
x
we apply
the following formula to identify advice candidates:
S
x
= S
x
−
m
[
i=1
S
i
, ∀ S
i
∈ S
′
In the example, by applying this algorithm we se-
lect S
c
as the first candidate aspect (as S
c
.obj(=
obj2) /∈
S
(S.obj − S
c
.obj)(= obj1)). The second
aspect candidate according to Table 4 would be S
b
.
We apply the above formula for S
b
to obtain a strong
aspect candidate:
S
b
= S
b
− S
c
= {obj1.op1, obj1.op2}
As the third aspect candidate we identify S
d
that
has MAX(F RD):
S
d
= S
d
− (S
c
[
S
b
)
= {obj1.op5, obj1.op6, obj1.op7, obj1.op8}
Nest aspect candidate is S
a
or S
e
since both has the
same F RD and N O, In this case, we will select one
of the message sequences randomly. for example, we
select S
e
:
S
e
= S
e
− (S
c
[
S
b
[
S
d
)
= {obj1.op9, obj1.op10, obj1.op111}
and finally we apply the above formula for S
a
,
since S
a
has some common members with S
b
, we just
select the memebers in S
a
that are not in S
b
.
S
a
= S
a
− (S
c
[
S
b
[
S
d
[
S
e
)
= {obj1.op3}
5.3.4 Combining Strategies: Rai and Frd
In Section 5.3.2 we described that with the calculation
of the RAI metric we are able to identify aspects by
detecting clones based on method invocations. These
methods belong to the different classes and are called
one after another in order to play a specific part of
the algorithms in the different scenarios. We claim
that we can extract these methods, and model them
as an aspect. In Section 5.3.3, we discussed how to
detect clones based on method invocations such that
the methods belong to the same class but can be called
in different scenarios in the same order and pattern.
Family-related dependency methods can be modeled
as different advices of an aspect. In this subsection
we combine RAI and FRD. Consider the execution
paths illustrated in Table 5 (the result of calculating
RAI values) and in Table 6 (the result of calculating
F RD values). In Table 7 we show F RD and RAI as
well as certain other parameters such as the number
of classes, and the number of operations.
<path1> ::=
<..., obj1.op1, obj2.op2,
..., obj1.op11,
..., obj2.op22, obj1.op111, obj3.op3,
...>
<path2> ::=
<..., obj1.op1, obj2.op2,
..., obj2.op22, obj1.op111,
...>
<path3> ::=
<..., obj1.op1, obj2.op2,
..., obj1.op11,
..., obj2.op22, obj1.op111, obj3.op3,
...>
We introduce a three-step algorithm to identify as-
pects in these cases:
Step 1: We deploy the F RD algorithm to identify
aspects and their corresponding advices. In our exam-
ple, we identify the following aspect/advices:
Aspect{Advice{obj3.op3}}
Aspect{Advice{obj2.op2}}, Advice{obj2.op22}}
Aspect{Advice{obj1.op1}}, Advice{obj1.op111}}
Aspect{Advice{obj1.op11}}
Step 2: We remove operations selected in the first
step from sets identified for RAI. In this case we will
have three different situations:
1. Selected operations at the beginning of a message
sequence in the RAI set. In this case we can re-
move them from the set. The remaining operations
in the set will define a new set.
ICSOFT 2006 - INTERNATIONAL CONFERENCE ON SOFTWARE AND DATA TECHNOLOGIES
186

Table 5: RAI metric for paths.
Path Recurring Sequence RAI
{path1, path2, path3} S1:{obj1.op1, obj2.op2}
3
3
{path1, path2, path3} S2:{obj2.op22, obj1.op111}
3
3
{path1, path3} S3:{obj2.op22, obj1.op111, obj3.op3}
2
3
Table 6: F RD metric for paths.
Path Recurring Sequence FRD
{path1, path2, path3} S4:{obj1.op1, obj1.op111}
3
3
{path1, path3} S5:{obj1.op1, obj1.op11, obj1.op11}
2
3
{path1, path3} S6:{obj3.op3}
2
3
{path1, path2, path3} S7:{obj2.op2, obj2.op22}
3
3
Table 7: RAI & F RD metrics for paths.
Path RAI FRD NC NO Obj
S1:{obj1.op1, obj2.op2}
3
3
- 2 2 -
S2:{obj2.op22, obj1.op111}
3
3
- 2 2 -
S3:{obj2.op22, obj1.op111, obj3.op3}
2
3
- 3 3 -
S4:{obj1.op1, obj1.op111} -
3
3
1 2 obj1
S5:{obj1.op1, obj1.op11, obj1.op11} -
2
3
1 3 obj1
S6:{obj3.op3} -
2
3
1 1 obj1
S7:{obj2.op2, obj2.op22} -
3
3
1 2 obj1
MINING ANOMALIES IN OBJECT-ORIENTED IMPLEMENTATIONS THROUGH EXECUTION TRACES
187

2. Selected operations at the end of a message se-
quence in the RAI set. In this case we can remove
them from the set the same as case 1
3. Selected operations are in the middle of a message
sequence in the RAI set. In this case we can divide
the RAI set into two sets (or more) by removing
selected operations from step 1.
Step 3: We deploy the RAI algorithm to the new
set of message sequences. Here, we stress the impor-
tance of maintaining the precedence of aspect execu-
tion in order to preserve the semantics of the original
object-oriented system.
6 RELATED WORK
A number of studies of software metrics such as cou-
pling and cohesion to evaluate the complexity of soft-
ware have been carried out. However, none of these
proposals directly address the calculation software
metrics at run-time in order to identify aspects.
In (Gupta and Rao, 2001), the authors measure
module cohesion in legacy software. They compared
statically calculated metrics against a program execu-
tion based approach of measuring the levels of mod-
ule cohesion. In (Mitchell and Power, 2003), the au-
thors adapt two common object-oriented metrics, cou-
pling and cohesion, and apply them at run-time. In
(Moldovan and Serban, 2006), the authors describe
a new approach in aspect mining that uses clustering
to identify the methods that have the code scattering
symptom. In this method, for a method, they consider
a large numbers of calling methods and a large num-
bers of calling classes as indications of code scatter-
ing. In order to group the best methods (candidates)
they use a vector-space model for defining the similar-
ity between methods. In (Breu and Krinke, 2004), the
authors describe an automatic dynamic aspect min-
ing approach which deploys program traces gener-
ated in different program executions. These traces
are then investigated for recurring execution patterns
based on different constraints, such as the requirement
that the patterns have to exist in a different calling
context in the program trace. In (Krinke and Breu,
2004), the authors describe an automatic static as-
pect mining approach, where the control flow graphs
of a program are investigated for recurring execu-
tions based on different constraints, such as the re-
quirement that the patterns have to exist in a differ-
ent calling context. In (Robillard and Murphy, 2002),
the authors introduce a concern graph representation
that abstracts the implementation details of a con-
cern and it makes explicit the relationships between
different elements of the concern for the purpose of
documenting and analyzing concerns. To investigate
the practical tradeoffs related to this approach, they
developed the Feature Exploration and Analysis tool
(FEAT) that allows a developer to manipulate a con-
cern representation extracted from a Java system, and
to analyze the relationships of that concern to the code
base. In (Robillard and Murphy, 2001), the authors
describe concerns based on class members. This de-
scription involves three levels of concern elements:
use of classes, use of class members, and class mem-
ber behavior elements (use of fields and classes within
method bodies). Use of classes is expressed by the
class-use production rules. The rules specify that
a concern either uses the entire class to implement
its behavior or only part of a class, as well as what
parts of the class participate in the implementation of
the particular concern. In (Bruntink, 2004), the au-
thors define certain clone class metrics that measure
known maintainability problems such as code dupli-
cation and code scattering. Subsequently, these clone
class metrics are combined into a grading scheme
designed to identify interesting clone classes for the
purpose of improving maintainability using aspects.
In (Baxter et al., 1998), the authors use an abstract
syntax tree (AST) to detect duplicated code (clones).
This technique uses parsers to first obtain a syntac-
tical representation of the source code, typically an
AST. The clone detection algorithms then search for
similar subtrees in the AST. In (Jr., 2002), the au-
thors introduce a general-purpose, multidimensional,
concern-space modeling schema that can be used to
model early-stage concerns.
7 CONCLUSION AND FUTURE
WORK
In this paper we described the theoretical component
of an approach to identifying anomalies in object-
oriented implementations based on observations of
patterns of messages in a legacy object-oriented sys-
tem. The term “anomaly” is used to refer to any phe-
nomenon that can negatively affect software quality
such as low cohesion, high coupling and crosscutting.
Our technique is based on the capture of execution
traces (paths) into a relational database in order to ex-
tract knowledge of anomalies in the system. We de-
veloped strategies to identify anomalies. In the case of
ambiguities in the presence of multiple candidate as-
pects, we deployed dynamic programming to identify
optimal solutions in order to group the strongest as-
pect candidates. We believe that our work can aid de-
velopers to find potential anomalies in object-oriented
systems. Equally, the work can aid maintainers.
For future work, we intend to provide an imple-
mentation through a case study. A tracing mecha-
nism (perhaps deploying AOP) can be used to capture
execution traces into a relational database schema.
ICSOFT 2006 - INTERNATIONAL CONFERENCE ON SOFTWARE AND DATA TECHNOLOGIES
188

SQL queries executed over the relational database
schema should be used to calculating the parameters
of the various algorithms. We also plan to investigate
the use of multidimensional schema, data warehouse,
and data mining techniques to discover knowledge by
considering different dimensions.
REFERENCES
Baxter, I. D., Yahin, A., Moura, L., Sant’Anna, M., and
Bier, L. (1998). Clone detection using abstract syntax
trees. In International Conference on Software Main-
tenance.
Breu, S. and Krinke, J. (2004). Aspect mining using event
traces. In IEEE International Conference on Auto-
mated Software Engineering.
Bruntink, M. (2004). Aspect mining using clone class met-
rics. In WCRE Workshop on Aspect Reverse Engineer-
ing.
Chidamber, S. R. and Kemerer, C. F. (1991). Towards a
metrics suite for object-oriented design. In Object-
Oriented Programming: Systems, Languages and Ap-
plications.
Cormen, T. H., Leiserson, C. E., Rivest, R. L., and Stein, C.
(2002). Introduction to Algorithms. The MIT Press.
Dijkstra, E. W. (1976). A Discipline of Programming. Pren-
tice Hall, Englewood Cliffs, NJ.
Elrad, T., Filman, R. E., and Bader, A. (2001). Aspect-
oriented programming. Communications of the ACM,
44(10):29–32.
Foumani, A. A. and Constantinides, C. (2005a). Aspect-
oriented reverse engineering. In World Multiconfer-
ence on Systemics, Cybernetics and Informatics.
Foumani, A. A. and Constantinides, C. (2005b). Reengi-
neering object-oriented designs by analyzing depen-
dency graphs and production rules. In IASTED In-
ternational Conference on Software Engineering and
Applications.
Gupta, N. and Rao, P. (2001). Program execution based
module cohesion measurement. In International Con-
ference on Automated Software Engineering.
Jr., S. M. S. (2002). Early-stage concern modeling. In
AOSD Workshop on Early Aspects.
Kiczales, G., Hilsdale, E., Hugunin, J., Kersten, M., Palm,
J., and Griswold, W. G. (2001). An overview of As-
pectJ. Lecture Notes in Computer Science, 2072:327–
355.
Kiczales, G., Lamping, J., Menhdhekar, A., Maeda, C.,
Lopes, C., Loingtier, J.-M., and Irwin, J. (1997).
Aspect-oriented programming. In Aks¸it, M. and Mat-
suoka, S., editors, Proceedings of the 11th Euro-
pean Conference on Object-Oriented Programming
(ECOOP), volume 1241, pages 220–242. Springer-
Verlag.
Krinke, J. and Breu, S. (2004). Control-flow-graph-based
aspect mining. In WCRE Workshop on Aspect Reverse
Engineering.
Mitchell, A. and Power, J. F. (2003). Toward a definition of
run-time object-oriented metrics. In ECOOP Work-
shop on Quantitative Approaches in Object-Oriented
Software Engineering.
Moldovan, G. S. and Serban, G. (2006). Aspect mining
using a vector-space model based clustering approach.
In AOSD Workshop on Linking Aspect Technology and
Evolution Revisited.
Parnas, D. L. (1972). On the criteria to be used in decom-
posing systems into modules. Communications of the
ACM, 15:1053–1058.
Robillard, M. P. and Murphy, G. C. (2001). Analyzing
concerns using class member dependencies. In ICSE
Workshop on Advanced Separation of Concerns in
Software Engineering.
Robillard, M. P. and Murphy, G. C. (2002). Concern graphs:
Finding and describing concerns using structural pro-
gram dependencies. In International Conference on
Software Engineering.
MINING ANOMALIES IN OBJECT-ORIENTED IMPLEMENTATIONS THROUGH EXECUTION TRACES
189
