
AN E-LIBRARIAN SERVICE THAT YIELDS PERTINENT
RESOURCES FROM A MULTIMEDIA KNOWLEDGE BASE
Serge Linckels
Hasso-Plattner-Institut (HPI), University of Potsdam
Postfach 900460, D-14440 Potsdam
Christoph Meinel
Hasso-Plattner-Institut (HPI), University of Potsdam
Postfach 900460, D-14440 Potsdam
Keywords:
Multimedia, semantic search engine, natural language, information retrieval, performance, e-Learning.
Abstract:
In this paper we present an e-librarian service which is able to retrieve multimedia resources from a knowledge
base in a more efficient way than by browsing through an index or by using a simple keyword search. We
explored the approach to allow the user to formulate a complete question in natural language.
Our background theory is composed of three steps. Firstly, there is the linguistic pre-processing of the user
question. Secondly, there is the semantic interpretation of the user question into a logical and unambiguous
form, i.e. ALC terminology. The focus function resolves ambiguities in the question; it returns the best
interpretation for a given word in the context of the complete user question. Thirdly, there is the generation of
a semantic query, and the retrieval of pertinent documents.
We developed two prototypes: one about computer history (CHESt), and one about fractions in mathematics
(MatES). We report on experiments with these prototypes that confirm the feasibility, the quality and the
benefits of such an e-librarian service. From 229 different user questions, the system returned for 97% of the
questions the right answer, and for nearly half of the questions only one answer, the best one.
1 INTRODUCTION
Our vision is to create an e-librarian service which is
able to retrieve multimedia resources from a knowl-
edge base in a more efficient way than by brows-
ing through an index or by using a simple keyword
search. Our premise is that more pertinent results
would be retrieved if the e-librarian service had a se-
mantic search engine which understood the sense of
the user’s query. This requires that the user must
be given the means to enter semantics. We explored
the approach to allow the user to formulate a com-
plete question in natural langauge (NL). Linguistic
relations within the user’s NL question and a given
context, i.e. an ontology, are used to extract precise
semantics and to generate a semantic query. The e-
librarian service does not return the answer to the
user’s question, but it retrieves the most pertinent doc-
ument(s) in which the user finds the answer to her/his
question.
The results of our research work are, firstly, a
founded background theory that improves domain
search engines so that they retrieve fewer but more
pertinent documents. It is based on the semantic in-
terpretation of a complete question that is expressed
in NL, which is to be translated into an unambigu-
ous logical form, i.e. an ALC terminology. Then, a
semantic query is generated and executed. Secondly,
we provide empirical data that prove the feasibility,
and the effectiveness of our underlying background
theory. We developed two prototypes: CHESt (Com-
puter History Expert System) with a knowledge base
about computer history, and MatES (Mathematics Ex-
pert System) with a knowledge base about fractions in
mathematics. We report on experiments with these
prototypes that confirm the feasibility, the quality and
the benefits of such an e-librarian service. From 229
different user questions, the system returned for 97%
of the questions the right answer, and for nearly half
of the questions only one answer, the best one.
In this paper we focus on the translation of a com-
plete NL question into a semantic query. This process
is done in three steps: the linguistic pre-processing
(section 2), the mapping of the question to an on-
tology (section 3), and the generation of a semantic
query (section 4). We present an algorithm (the focus
function) that resolves ambiguities in the user ques-
tion. The outcomes of the experiments are described
in section 5. We present related projects in section 6,
and conclude with some (dis)advantages in section 7.
208
Linckels S. and Meinel C. (2006).
AN E-LIBRARIAN SERVICE THAT YIELDS PERTINENT RESOURCES FROM A MULTIMEDIA KNOWLEDGE BASE.
In Proceedings of the International Conference on Signal Processing and Multimedia Applications, pages 208-215
DOI: 10.5220/0001571302080215
Copyright
c
SciTePress

2 LINGUISTIC
PRE-PROCESSING
The objective of the linguistic pre-processing step
is to convert a stream of symbols into a structured
stream of words, and to retrieve linguistic informa-
tion about these words and the complete sentence.
A search mechanism returns better results if the in-
ference is done over a complete sentence by consid-
ering the relations between words — the syntax —
than by only considering the isolated words. In fact,
the syntactic structure of a sentence indicates the way
words are related to each other, e.g. how the words
are grouped together into phrases, which words mod-
ify which other words, and which words are of central
importance in the sentence.
In our prototypes, the linguistic pre-processing is
performed with a part-of-speech (POS) tagger; we
use TreeTagger (IMS Stuttgart). The linguistic pre-
processing step contributes in three points. Firstly,
the word category of each word is made explicit,
e.g. article, verb. Secondly, the tagger returns the
canonical form (lemma) for each word (token). This
considerably reduces the size of the ontology dic-
tionary. Thirdly, the sentence is split into linguistic
clauses. A linguistic clause is a triple of the form
<subject;verb;object>. Each triple is then processed
individually, e.g. the question q = ”Who invented
the transistor and who founded IBM?” is split into the
two clauses:
q
′
1
= [Who invented the transistor?]
conj = [and]
q
′
2
= [Who founded IBM?]
3 ONTOLOGY MAPPING
In this section, we present the elaborated background
theory for translating a linguistic pre-processed user
question into a computer readable and unambiguous
form w.r.t. a given ontology.
3.1 Ontology Preliminaries
The e-librarian service masters a domain language
L
H
over an alphabet Σ
∗
, which may or may not con-
tain all the possible words L used by the user to for-
mulate his question, so that L
H
⊆ L ⊆ Σ
∗
. The
semantics are attached to each word by classification
in the knowledge source, e.g. a dictionary, which
is structured in a hierarchical way like hyperonym,
hyponym, synonym, and homonyms. In most of the
related projects (section 6), an existing knowledge
Clip
Creator
Person Firm
Software
Language OS
EComponent
Hardware
Computer
Thing
Figure 1: Example of a concept taxonomy about computer
history.
source is used, normally WordNet. The major prob-
lem of such a knowledge source is that it is not ded-
icated to a domain. Like other large scale dictionar-
ies, WordNet on the one hand lacks of specific do-
main expressions, but on the other hand contains too
much knowledge about other domains. This increases
the problem of ambiguous interpretations for a given
word. We created our own dictionary, which is orga-
nized in a hierarchical way, similar to WordNet, and
w.r.t. our ontology. Furthermore, the size of the dic-
tionary is considerably reduced by the fact that it con-
tains all words from the domain language L
H
only in
their canonical form. This reduces also the possibility
of ambiguous interpretations.
Definition 1 (Concept taxonomy) A concept taxon-
omy H = (V, E, v
0
) is a directed acyclic graph where
each node, except the root-node (v
0
), has one or more
parents. E is the set of all edges and V is the set of all
nodes (vertices) with V = {(s, T ) | s ∈ S} where s is
a unique label, S the set of all labels in the ontology,
and T is a set of words from L
H
that are associated
to a node so that T ⊆ L
H
.
An example of a concept taxonomy about computer
history is given in figure 1. Here, a document de-
scribing the transistor would be placed in the concept
”EComponent” (electronic components), which is a
hyponym of ”Hardware”.
A node v
i
represents a concept. The words that re-
fer to this concept are regrouped in T
i
. We assume
that each set of words T
i
is semantically related to
the concept that the node v
i
represents. The exam-
ple in figure 2 shows that words like ”Transistor”,
”Diode” or ”LED” semantically refer to the same con-
cept, namely electronic components. Therefore, these
three words are synonyms in the given ontology. Of
course, a certain word can refer to different concepts,
e.g. ”Ada” is the name of a programming language
but also the name of a person. Not all words in L
H
must be associated with a concept. Only words that
are semantically relevant are classified. In general,
nouns and verbs are best indicators of the sense of a
question. The difference between words that are se-
mantically irrelevant and words that are not contained
AN E-LIBRARIAN SERVICE THAT YIELDS PERTINENT RESOURCES FROM A MULTIMEDIA KNOWLEDGE
BASE
209

Electronic components
s = EComponent
T = {Transistor, Diode, LED}
Figure 2: Example of a node in the taxonomy about the
concept EComponent (electronic components).
Clip
.
= ∃hasName.String ⊓ Creator ⊔ T hing
Creator
.
= P erson ⊔ F irm
P erson
.
= ∃wasBorn.Date ⊓
∃isDeceased.Date
T hing
.
= F irm ⊔ Software ⊔ Hardware ⊔ N et
⊓ ∃wasInventedBy.Creator
Sof tware
.
= Language ⊔ OS
Hardware
.
= EComponent ⊔ Computer
Figure 3: Example of a concept taxonomy (TBox) about
computer history as ALC terminology.
in L
H
is that for the second ones, the system has ab-
solutely no idea if they are relevant or not.
3.2 Semantic Interpretation
The representation of context-independent meaning
is called the logical form, and the process of map-
ping a sentence to its logical form is called seman-
tic interpretation (Allen, 1994). The logical form is
expressed in a certain knowledge representation lan-
guage; we use Description Logics (DL). Firstly, DL
have the advantage that they come with well defined
semantics and correct algorithms. Furthermore, the
link between DL and NL has already been established
(Schmidt, 1993). Finally, translating the user question
into DL allows direct reasoning over the OWL-DL en-
coded knowledge base (section 4).
A DL terminology is composed, firstly, of con-
cepts (unary predicates), which are generally nouns,
question words (w-words) and proper names, and sec-
ondly, of roles (binary predicates), which are gen-
erally verbs, adjectives and adverbs. We use the
language ALC (Schmidt-Schauß and Smolka, 1991),
which is sufficiently expressive for our purposes.
ALC concepts are built using a set of concept names
(NC) and role names (NR). Valid concepts (C) are
defined by the following syntax,
C ::= A | ⊤ | ⊥ |
¬
A | C
1
⊓C
2
| C
1
⊔C
2
| ∀R.C | ∃R.C
with A ∈ NC is a concept name and R ∈ NR is a
role name (figure 3).
A core part of the semantic interpretation is a map-
ping algorithm. This step — commonly called non-
standard inference (K
¨
usters, 2001) — maps each
word from the user question to one or more ontology
concepts, and resolves the arguments of each role by
analyzing the syntactic structure of the sentence.
Definition 2 (Word equivalence) The function π :
L, L → R quantifies the similarity of two given words
π(a, b) so that a and b are said to be equivalent w.r.t.
a given tolerance ε, written a ≡ b, iff π(a, b) ≤ ε.
Technically, for a given lemma from the user ques-
tion, the equivalence function π uses the Levenshtein
function to check if this word is contained in the ontol-
ogy dictionary L
H
given a certain allowed tolerance
ε. That tolerance is calculated relative to the length of
the lemma.
Definition 3 (Mapping) The meaning of each word
w
k
∈ L is made explicit with the mapping function
ϕ : L → V over an ontology dictionary L
H
⊆ L ⊆
Σ
∗
and an ALC concept taxonomy H = (V, E, v
0
) so
that ϕ(w
k
) returns a set of interpretations Φ defined
as follows,
Φ = ϕ(w
k
) = {v
i
| ∃x ∈ f t(v
i
) : w
k
≡ x}.
The function ft(v
i
) returns the set of words T
i
as-
sociated to the node v
i
(definition 1), and w
k
≡ x
are two equivalent words. This solution gives good
results even if the user makes spelling errors. Fur-
thermore, only the best matching is considered for the
mapping, e.g. the word ”comXmon” will be consid-
ered as ”common”, and not as ”uncommon”. Both
words, ”common” and ”uncommon”, will be consid-
ered for the mapping of ”comXXmon”. The ambigu-
ity will be resolved in a further step (focus function).
Definition 4 (Semantic relevance) A word w
k
is se-
mantically relevant if there is at least one concept in
the ontology H to which w
k
can be mapped so that
ϕ(w
k
) 6= ∅.
It is possible that a word can be mapped to different
concepts at once, so that |Φ| > 1. We introduce the
notion of focus to resolve this ambiguity. The focus
is a function (f), which returns the best interpretation
for a given word in the context of the complete user
question.
Definition 5 (Focus) The focus of a set of interpreta-
tions Φ is made explicit by the function f which re-
turns the best interpretation for a given word in the
context of the complete question q. The focus, written
f
q
(ϕ(w
k
∈ q)) = v
′
, guarantees the following,
1. v
′
∈ ϕ(w
k
); The focused word is a valid interpre-
tation.
2. |f
q
(ϕ(w
k
))| = [0, 1]; The focus function returns 0
or 1 result.
3. ⊤ ≤ v
′
≤ ⊥, if f
q
(ϕ(w
k
)) 6= ∅; If the focusing
is successful, then the word is inside the context of
the domain ontology.
SIGMAP 2006 - INTERNATIONAL CONFERENCE ON SIGNAL PROCESSING AND MULTIMEDIA
APPLICATIONS
210

4. π(w
k
, x ∈ ft(v
′
)) ≤ π(w
k
, y ∈ ft(v
i
∈
ϕ(w
k
))); The returned interpretation contains the
best matching word of all possible interpretations.
Let us consider as illustration the word ”Ada”,
which is called a multiple-sense word. In fact, in the
context of computer history, ”Ada” can refer to the
programming language named ”Ada”, but it can also
be the name of the person ”Augusta Ada Lovelace”.
The correct interpretation can only be retrieved ac-
curately by putting the ambiguous word in the con-
text of a complete question. For example, the context
of the sentences ”Who invented Ada?” and ”Did the
firms Bull and Honeywell create Ada?” reveals that
here Ada is the programming language, and not the
person Ada.
Technically, the focus function uses the role’s sig-
nature. A role r ∈ NR has the signature r(s
1
, s
2
),
where s
1
and s
2
are labels. The signature of each
role defines the kind of arguments that are possible.
For example wasInventedBy(T hing, Creator) is
the role r = wasInventedBy that has the arguments
s
1
= T hing and s
2
= Creator.
In the question q = ”Who invented Ada?”, ”in-
vented” is mapped to the role w asInventedBy, and
”Who” is mapped to the concept Creator. The sys-
tem detects an ambiguity for the word ”Ada”, which
is mapped to an instance of the concept P erson, but
also to an instance of the concept Language, so that
ϕ(”Ada”) = {P ers on, Language}.
The focus function computes the following combina-
tions to resolve the ambiguity:
1. Was Ada invented by who?*
2. Was Ada invented by Ada?
3. Was who invented by Ada?*
4. Was who invented by who?*
Cyclic combinations like (2) and (4) are not al-
lowed. As for (3), it does not match the role’s sig-
nature because s
1
= Creator (”Who”), but T hing
is required. As for (1), s
1
can be P erson or
Language. The role’s signature requires Creator,
therefore Language is excluded as valid interpreta-
tion because Language 6⊑ Creator. As P erson ⊑
Creator, a valid interpretation is found, and in the
context of this question the word ”Ada” refers to the
person Ada. Finally, the result of the focus function
is:
f
q
(ϕ(”Ada”)) = P erson.
Indeed, (1) represents the question ”Who invented
Ada?”.
It is still possible that the focus function cannot re-
solve an ambiguity, e.g. a given word has more inter-
pretations but the focus function returns no result:
|Φ| > 1 and f(ϕ(w)) = ∅.
In a such case, the system will generate a semantic
query for each possible interpretation. Based on our
practical experience we know that users generally en-
ter simple questions where the disambiguation is nor-
mally successful.
Definition 6 (Semantic interpretation) Let q be the
user question, which is composed of linguistic
clauses, written q = {q
′
1
, ..., q
′
m
}, with m ≥ 1.
The sematic interpretation of a user question q is the
translation of each linguistic clause into an ALC ter-
minology w.r.t. a given ontology H written,
q
H
i
=
n
l
k=1
f
q
′
i
(ϕ(w
k
∈ q
′
i
))
with q
′
i
a linguistic clause q
′
i
∈ q, and n the number
of words in the linguistic clause q
′
i
.
If a user question is composed of several linguis-
tic clauses, then each one is translated separately.
The logical concatenation of the different interpreted
clauses q
H
i
depends on the conjunction word(s) used
in the user question, e.g. ”Who invented the transis-
tor and who founded IBM?”. If no such conjunction
word is found, then the ”or” operator is preferred over
the ”and” operator.
4 QUERY GENERATION
We will start with the assumptions that firstly, all doc-
uments in the knowledge base K are semantically
described with OWL-DL metadata, w.r.t. an ontol-
ogy H, and that secondly the user question q was
translated into a DL terminology w.r.t. the same on-
tology H (section 3). Even if we currently do not
profit from the full expressivity of OWL-DL, which
is SHOIN (D+), it allows to have compatible se-
mantics between the OWL-DL knowledge base, and
the less expressive ALC user question. Logical in-
ference over the non-empty ABox from K is possible
by using a classical DL reasoner; we use Pellet (Sirin
and Parsia, 2004). The returned results are logical
consequences of the inference rather than of keyword
matchings.
An interpretation I = (∆
I
, ·
I
) consists of a non-
empty set ∆
I
, the domain of the interpretation, and
an interpretation function ·
I
that maps each concept
name to a subset of ∆
I
and each role name to a binary
relation r
I
, subset of ∆
I
× ∆
I
.
Definition 7 (Semantic query) A semantic query
over a knowledge base K w.r.t. an ontology H, and
an user question q is an ABox query, which means to
search for models I of K, written K |= q
H
.
In other words, all documents from the knowledge
base that satisfy the expression q
H
are potential re-
AN E-LIBRARIAN SERVICE THAT YIELDS PERTINENT RESOURCES FROM A MULTIMEDIA KNOWLEDGE
BASE
211

q = ”Wer hat den Transistor erfunden?”
?
Linguistic pre-processing
q
′
=
Wer
[wer]
WPRO
hat
[haben]
VHFIN
den
[der]
ART
Transistor
[T ransistor]
NN
erfunden
[erf inden]
VVpast
?
Semantic interpretation
q
H
= Creator(x1)
∧
wasInventedBy(x2, x1)
∧
EComponent(x2) ∧ hasName(x2, ”T ransistor”)
?
Semantic query generation
SELECT ?x1 WHERE (?x2 rdf:type chest:EComponent) (?x2 chest:hasName ?x2hasName)
(?x2 chest:wasInventedBy ?x1) AND (?x2hasName =˜/Transistor/i) USING chest for
<...> rdf for <...>
Figure 4: Complete example for the generation of a semantic query from the user question ”Who invented the transistor?”.
sults. An individual α in I that is an element of (q
H
)
I
is a pertinent resource according to the user question.
Technically, an ABox query (in Pellet) is expressed
in a query language; we use RDQL (Miller et al.,
2002) via the Jena framework (Carroll et al., 2004).
Firstly, for a complete question, each semantic inter-
pretation, that is each translated linguistic clause, is
transformed into a semantic query. Secondly, the na-
ture of the question (open or close) reveals the miss-
ing part. An open question contains a question word,
e.g. ”Who invented the transistor?”, whereas a close
question (logical- or yes/no question) does not have a
question word, e.g. ”Did Shockley contribute to the
invention of the transistor?”. As for the first kind of
questions, the missing part — normally not an indi-
vidual but a concept — is the subject of the question
and therefore the requested result. The result of the
query is the set of all models I in the knowledge base
K. As for the second kind of questions, there is no
missing part. Therefore, the answer will be ”yes” if
K |= q
H
, otherwise it is ”no”. A complete example is
shown in figure 4.
5 IMPLEMENTATION AND
EXPERIMENTS
Our background theory was implemented prototypi-
cally in two educational tools; one about computer
history (CHESt), and one about fractions in mathe-
matics (MatES). Both prototypes can be used at home
or in a classroom either as Web application, or as
stand-alone application (e.g. from a DVD/CD-ROM).
The user can freely formulate a question in NL, and
submit it to the e-librarian service. Then, the e-
librarian service returns one (or more) document(s)
which explain(s) the answer to the user’s question
(figure 5). The knowledge base is composed of short
multimedia documents (clips), which were recorded
with tele-TASK (http://www.tele-task.de) (Schillings
and Meinel, 2002). Each clip documents one sub-
ject or a part of a subject. The duration of each clip
varies from several seconds to three or four minutes.
This has two reasons, firstly, the younger the user, the
shorter the time during which (s)he will concentrate
on the information displayed on the screen (Williams
et al., 2001). Secondly, it is not easy to find the ap-
propriate information inside a large piece of data, e.g.
in an online lesson that lasts 90 minutes.
In a first experiment made in a secondary school
with CHESt, we aimed to investigate, firstly, how use-
ful our e-librarian service is as an e-learning tool, and
secondly, in how far students accept to enter complete
questions into a search engine instead of only key-
words. Some 60 students took part in the assessment.
In the first place, let us point out that nearly all stu-
dents approved of the appealing multimedia presen-
tations. They agreed that the explanations were suf-
ficiently complete to understand the subject. Several
appreciated the short length of the clips; a few stated
that the clips were too long. Some added that they
appreciated the short response time of the system. Fi-
nally, asked if they accepted to enter complete ques-
tions into a search engine, 22% of the students an-
swered that they would accept, 69% accepted to enter
complete questions instead of keywords only if this
yielded better results, and 8% disliked this option.
In a second experiment we used MatES to mea-
sure the performance of our semantic search engine.
A testing set of 229 different questions about this
topic was created by a mathematic teacher, who was
not involved in the development of the prototype. The
teacher also indicated manually the best possible clip,
as well as a list of further clips, that should be yielded
as correct answer. The questions were linguistic cor-
rect, and short sentences like students in a secondary
school would ask, e.g. ”How can I simplify a frac-
tion?”, ”What is the sum of
2
3
and
7
4
?”, ”What are
SIGMAP 2006 - INTERNATIONAL CONFERENCE ON SIGNAL PROCESSING AND MULTIMEDIA
APPLICATIONS
212
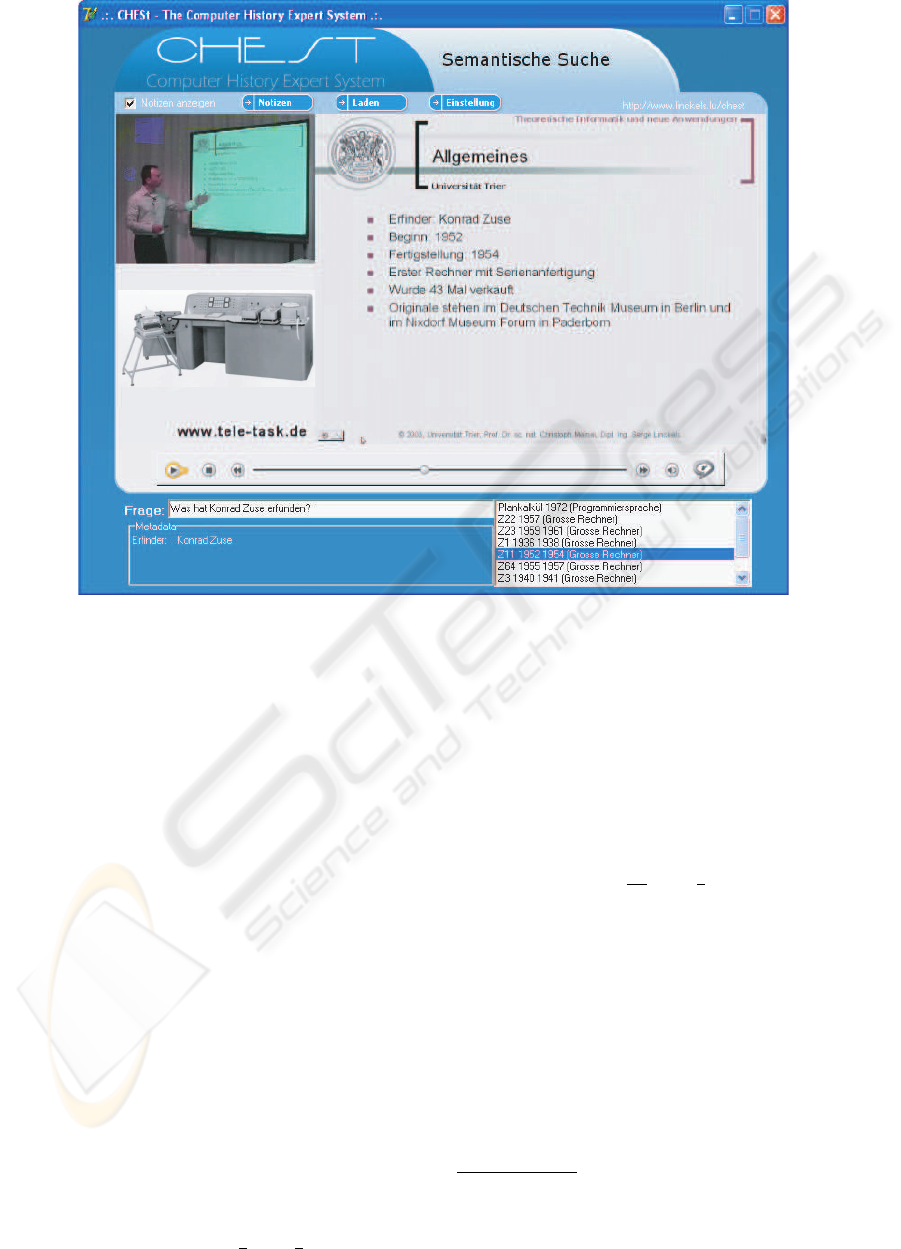
Figure 5: CHESt with the question: ’What has Konrad Zuse invented?’.
fractions good for?”, ”Who invented the fractions?”,
etc. This benchmark test was compared with the
performance of a keyword search engine. The key-
word search was slightly optimized to filter out stop
words (words with no relevance, e.g. articles) from
the textual content of the knowledge base and from
the questions entered. The semantic search engine
answered 97% of the questions (223 out of 229) cor-
rectly, whereas the keyword search engine yielded
only a correct answer (i.e. a pertinent clip) in 70%
of the questions (161 out of 229).
It is also interesting to notice that for 86 questions,
the semantic search engine yielded just one – the se-
mantically best matching – answer (figure 6). For
75% of the questions (170 out of 229) the semantic
search engine yielded just a few results (one, two or
three answers), whereas the keyword search yielded
for only 14% of the questions less than 4 answers;
mostly (138 questions out of 229) more than 10 an-
swers. Our e-librarian service returned always at least
one result. This is important because we learned from
former experiments in school that students dislike get-
ting no result at all.
For example, the semantic interpretation of the
question ”What is the sum of
2
3
and
7
4
?” is the fol-
lowing valid ALC terminology:
F raction(x1) ⊓ ∃hasO peration(x1, x2) ⊓
Operation(x2, sum).
Then the semantic query retrieves one clip, which
explained how to add two fractions. This was the best
clip that could be found in the knowledge base
1
. This
means also that questions like ”How can I add two
fractions”, ”What is
11
0.5
plus
5
5
, etc. would yield the
same clip. The keyword search engine yields all clips,
in which keywords like ”sum” are found, e.g. a clip
that explains how to represent a complex function in
terms of additions, and a clip that explain how to de-
scribe situations with simple fractions.
The experiments revealed also two major weak-
nesses of our e-librarian service that should be im-
proved in future. Firstly, the system is not able to
make the difference between a question, where there
is no answer in the knowledge base, and a ques-
tion that is out of the topic, e.g. ”Who invented
penicillin?”. Secondly, in its current state, the e-
1
Remember that the system returns clips that explain the
answer to the student’s question, but they do note give the
precise answer, e.g. it does not compute the sum of the two
fractions.
AN E-LIBRARIAN SERVICE THAT YIELDS PERTINENT RESOURCES FROM A MULTIMEDIA KNOWLEDGE
BASE
213

19
7
14
12
39
47
16
7
68
0
10
20
30
40
50
60
70
80
w ith 0
answ er
w ith 1
answ er
w ith 2
answ ers
w ith 3
answ ers
[4..10]
answ ers
[11..20]
answ ers
[21..30]
answ ers
[31..40]
answ ers
> 40
answ ers
0
86
34
50
31
4
7
11
6
0
10
20
30
40
50
60
70
80
90
100
with 0
ans wer
with 1
ans wer
with 2
ans wers
with 3
ans wers
with 4
ans wers
with 5
ans wers
with 6
ans wers
with 7
ans wers
> 7
ans wers
Figure 6: Number of results yielded by a (1) keyword and by a (2) semantic search engine with a set of 229 questions.
librarian service does not handle number restrictions,
e.g. ”How many machines did Konrad Zuse invent?”.
The response will be the list of Zuse’s machines, but
not a number. Furthermore, the question ”What is the
designation of the third model of Apple computers?”
will yield a list of all models of Apple computers.
6 RELATED WORK
START (Katz, 1997) is the first question-answering
system available on the Web. Several improvements
have been made since it came online in 1993 (Katz
and Lin, 2002; Katz et al., 2002) which make of
START a powerful search engine. However, the NLP
is not always sound, e.g. the question ”What did Jodie
Foster before she became an actress?” returns ”I don’t
know what Jodie fostered before the actress became
an actress”. Also, the question ”Who invented the
transistor?” yields two answers: the inventors of the
transistor, but also a description about the transistor
(the answer to the question: ”What is a transistor”).
AquaLog (Lopez et al., 2005) is a portable
question-answering system which takes queries ex-
pressed in NL and an ontology as input, and returns
answers drawn from one or more knowledge bases.
User questions are expressed as triples: <subject,
predicate, object>. If the several translation mech-
anisms fail, then the user is asked for disambiguation.
The system also uses an interesting learning compo-
nent to adapt to the user’s ”jargon”. AquaLog has
currently a very limited knowledge space. In a bench-
mark test over 76 different questions, 37 (48.68%)
where handled correctly.
The prototype PRECISE (Popescu et al., 2003) uses
ontology technologies to map semantically tractable
NL questions to the corresponding SQL query. It was
tested on several hundred questions drawn from user
studies over three benchmark databases. Over 80%
of the questions are semantically tractable questions,
which PRECISE answered correctly, and recognized
the 20% it could not handle, and requests a para-
phrase. The problem of finding a mapping from the
tokenization to the database requires that all tokens
must be distinct; questions with unknown words are
not semantically tractable and cannot be handled.
FALCON is an answer engine that handles questions
in NL. When the question concept indicating the an-
swer type is identified, it is mapped into an answer
taxonomy. The top categories are connected to several
word classes from WordNet. Also, FALCON gives a
cached answer if the similar question has already been
asked before; a similarity measure is calculated to see
if the given question is a reformulation of a previous
one. In TREC-9, FALCON generated a score of 58%
for short answers and 76% for long answers, which
was actually the best score.
LASSO relies on a combination of syntactic and se-
mantic techniques, and lightweight abductive infer-
ence to find answers. The search for the answer is
based on a form of indexing called paragraph index-
ing. The advantage of processing paragraphs instead
of full documents determines a faster syntactic pars-
ing. The extraction and evaluation of the answer cor-
rectness is based on empirical abduction. A score of
55.5% for short answers and 64.5% for long answers
was achieved in TREC-8.
Medicine is one of the best examples of applica-
tion domains where ontologies have already been de-
ployed at large scale and demonstrated their utility.
The generation, maintenance and evolution of a Se-
mantic Web-based ontology in the context of an in-
formation system for pathology is described in (Bon-
tas et al., 2004). The system combines Semantic Web
and NLP techniques to support a content-based stor-
age and retrieval of medical reports and digital im-
ages.
The MKBEEM (Corcho et al., 2003) mediation
system allows to fill the gap between customers
queries (possibly expressed in NL) and diverse spe-
cific providers offers. They provide a consensual
representation of the e-commerce field allowing the
SIGMAP 2006 - INTERNATIONAL CONFERENCE ON SIGNAL PROCESSING AND MULTIMEDIA
APPLICATIONS
214

exchanges independently of the language of the end
user, the service, or the content provider. The dy-
namic discovery mechanism converts the user query
into an ontological formula, then into a concept de-
scription using DL. Finally, the relevant e-service is
selected. The MKBEEM prototype has been vali-
dated with the languages Finnish, English, French,
and Spanish, in two fields: business to consumer on-
lines sales, and Web based travel/tourism services.
7 CONCLUSION
In this paper we presented an e-librarian service that
allows the user to communicate by means of complete
questions in NL, and that retrieves pertinent multi-
media resources from a knowledge base. The back-
ground theory is composed of three steps: the linguis-
tic pre-processing of the user’s NL input, the semantic
interpretation of the NL sentence into a logical form,
and the generation of a semantic query. It uses De-
scription Logics and Semantic Web technologies like
OWL for the semantic interpretation of NL questions.
We also presented an algorithm to resolve ambiguities
in the user question. Experiments with two prototypes
confirmed that this background theory is reliable and
can be implemented, e.g. in an educational tool.
In our further work, we will try to improve the
translation from the NL question into an ALC termi-
nology, e.g. use number restrictions. We also want to
investigate if a more precise grammatical analyze of
the user question can help in the interpretation step,
or if this would reduce the users liking of the inter-
face (because of the smaller tolerance of the system).
Another important topic is the maintenance facilities;
how can unknown words from the user query (i.e.
the user’s ”jargon”) be included in the dictionary, and
how can external ”thrusted” knowledge sources been
accessed by the e-librarian service?
REFERENCES
Allen, J. (1994). Natural Language Understanding. Addi-
son Wesley.
Bontas, E. P., Tietz, S., Tolksdorf, R., and Schrader, T.
(2004). Engineering a semantic web for pathology.
In Web Engineering - 4th International Conference,
ICWE 2004, Munich, Germany, pages 585–586.
Carroll, J. J., Dickinson, I., Dollin, C., Reynolds, D.,
Seaborne, A., and Wilkinson, K. (2004). Jena: imple-
menting the semantic web recommendations. In 13th
international conference on World Wide Web - Alter-
nate Track Papers & Posters, New York, NY, USA, May
17-20, pages 74–83.
Corcho,
´
O., G
´
omez-P
´
erez, A., Leger, A., Rey, C., and
Toumani, F. (2003). An ontology-based mediation
architecture for e-commerce applications. In Intel-
ligent Information Processing and Web Mining (IIS:
IIPWM), Zakopane, Poland, pages 477–486.
Katz, B. (1997). Annotating the world wide web using nat-
ural language. In 5th RIAO conference on computer
assisted information searching on the internet, Mon-
treal, Canada.
Katz, B., Felshin, S., Yuret, D., Ibrahim, A., Lin, J. J.,
Marton, G., McFarland, A. J., and Temelkuran, B.
(2002). Omnibase: Uniform access to heterogeneous
data for question answering. In 6th International Con-
ference on Applications of Natural Language to In-
formation Systems (NLDB), Stockholm, Sweden, June
27-28, 2002, Revised Papers, pages 230–234.
Katz, B. and Lin, J. (2002). Annotating the semantic web
using natural language. In 2nd Workshop on NLP and
XML (NLPXML-2002) at COLING.
K
¨
usters, R. (2001). Non-Standard Inferences in Description
Logics, volume 2100 of Lecture Notes in Artificial In-
telligence. Springer-Verlag. Ph.D. thesis.
Lopez, V., Pasin, M., and Motta, E. (2005). Aqualog: An
ontology-portable question answering system for the
semantic web. In The Semantic Web: Research and
Applications, Second European Semantic Web Con-
ference, ESWC 2005, Heraklion, Crete, Greece, pages
546–562.
Miller, L., Seaborne, A., and Reggiori, A. (2002). Three
implementations of squishql, a simple rdf query lan-
guage. In 1st International Semantic Web Conference
(ISWC), Sardinia, Italy, June 9-12, pages 423–435.
Popescu, A.-M., Etzioni, O., and Kautz, H. A. (2003). To-
wards a theory of natural language interfaces to data-
bases. In 8th International Conference on Intelli-
gent User Interfaces, January 12-15, Miami, FL, USA,
pages 149–157.
Schillings, V. and Meinel, C. (2002). tele-task: teleteaching
anywhere solution kit. In 30th annual ACM SIGUCCS
conference on User services, Providence, Rhode Is-
land, USA, November 20-23, pages 130–133.
Schmidt, R. A. (1993). Terminological representation, nat-
ural language & relation algebra. In 16th German AI
Conference (GWAI), volume 671 of Lecture Notes in
Artificial Intelligence, pages 357–371.
Schmidt-Schauß, M. and Smolka, G. (1991). Attributive
concept descriptions with complements. Artificial In-
telligence, 48(1):1–26.
Sirin, E. and Parsia, B. (2004). Pellet: An owl dl rea-
soner. In International Workshop on Description Log-
ics (DL2004), Whistler, British Columbia, Canada,
June 6-8, volume 104 of CEUR Workshop Proceed-
ings. CEUR-WS.org.
Williams, W. M., Markle, F., Sternberg, R. J., and
Brigockas, M. (2001). Educational Psychology. Allyn
& Bacon.
AN E-LIBRARIAN SERVICE THAT YIELDS PERTINENT RESOURCES FROM A MULTIMEDIA KNOWLEDGE
BASE
215
