
IMPROVING MULTISCALE RECURRENT PATTERN IMAGE
CODING WITH DEBLOCKING FILTERING
Nuno M. M. Rodrigues
1,2
, Eduardo A. B. da Silva
3
, Murilo B. de Carvalho
4
,
S
´
ergio M. M. de Faria
1,2
, Vitor M. M. da Silva
1,5
1
Instituto de Telecomunicac¸
˜
oes, Portugal;
2
ESTG, Instituto Polit
´
ecnico Leiria, Portugal;
3
PEE/COPPE/DEL/Poli, Univ. Fed. Rio de Janeiro, Brazil;
4
TET/CTC, Univ. Fed. Fluminense, Brazil;
5
DEEC, Universidade de Coimbra, Portugal.
Keywords:
Multidimensional Multiscale Parser, MMP-Intra, Deblocking Filter, Image Coding.
Abstract:
The Multidimensional Multiscale Parser (MMP) algorithm is an image encoder that approximates the image
blocks by using recurrent patterns, from an adaptive dictionary, at different scales. This encoder performs well
for a large range of image data. However, images encoded with MMP suffer from blocking artifacts. This
paper presents the design of a deblocking filter that improves the performance the MMP.
We present the results of our research, that aims to increase the performance of MMP, particularly for smooth
images, without causing quality losses for other image types, where its performance is already up to 5 dB
better than that of top transform based encoders. For smooth images, the proposed filter introduces relevant
perceptual quality gains by efficiently eliminating the blocking effects, without introducing the usual blurring
artifacts. Besides this, we show that, unlike traditional deblocking algorithms, the proposed method also
improves the objective quality of the decoded image, achieving PSNR gains of up to about 0.3 dB. With
such gains, MMP reaches an almost equivalent performance to that of the state-of-the-art image encoders
(equal to that of JPEG2000 for higher compression ratios), for smooth images, while maintaining its gains
for non-smooth images. In fact, for all image types, the proposed method provides significant perceptual
improvements, without sacrificing the PSNR performance.
1 INTRODUCTION
The success of the current state-of-the-art transform-
quantisation based encoders results from their excel-
lent performance in the compression of natural im-
ages. Nevertheless, the relative performance of these
encoders decreases noticeably when we deviate from
the smoothness assumption, as is the case for images
like text, compound (text and graphics), computer
generated, texture, medical, among others. Indeed,
it is a well known fact that most of the encoders that
achieve top results for these image classes have poor
performances for smooth images.
The Multidimensional Multiscale Parser (MMP)
(de Carvalho et al., 2002) is a lossy multidimen-
sional signal encoder, that, unlike most state-of-the-
art image encoders, is not based on the transform-
quantisation paradigm. It is a multiscale recurrent
pattern matching method, that uses an adaptive dictio-
nary for approximating blocks of the original signal.
Using the same pattern matching paradigm, a new
image encoding method, that combines MMP with
the prediction techniques of H.264/AVC (Joint Video
Team (JVT), 2005), was proposed in (Rodrigues
et al., 2005). MMP-Intra is able to achieve quality
gains over the original MMP algorithm for all im-
age types, but particularly for smooth images, where
the performance of MMP is inferior to that of the
top transform-quantisation based encoders. Experi-
mental results show that, when combined with con-
venient dictionary design techniques, the rate distor-
tion (RD) performance of MMP-Intra becomes only
marginally inferior (about 0.2 to 0.5 dB) to that of
the JPEG2000 (Taubman and Marcelin, 2001) and
H.264/AVC high profile (Joint Video Team (JVT),
2005) image encoders, for the coding of smooth im-
ages (Rodrigues et al., 2006). For other types of im-
ages, MMP-Intra consistently maintains its excellent
performance, achieving gains over standardised state-
of-the-art encoders that range from 1 to 5 dB.
MMP-Intra, as MMP, uses the concatenation of the
approximations of the original image blocks, at differ-
ent scales. This process introduces blocking artifacts
in the decoded image, that are particularly evident for
higher compression ratios.
This paper presents a new deblocking scheme for
118
M. M. Rodrigues N., A. B. da Silva E., B. de Carvalho M., M. M. de Faria S. and M. M. da Silva V. (2006).
IMPROVING MULTISCALE RECURRENT PATTERN IMAGE CODING WITH DEBLOCKING FILTERING.
In Proceedings of the International Conference on Signal Processing and Multimedia Applications, pages 118-125
DOI: 10.5220/0001572701180125
Copyright
c
SciTePress

MMP-Intra, that improves the performance of this
image encoder for smooth images, without compro-
mising its compression performance for other image
types. The proposed method is based on a deblocking
method, originally proposed for MMP and a matching
pursuit based multiscale algorithm (de Carvalho et al.,
2002)(de Carvalho et al., 2000), but introduces new
adaptive features, that allow it to optimise the percep-
tual results, as well as the objective performance of
the encoded image.
The experimental results presented in this paper
demonstrate that when the new method is combined
with proper strategies to control the deblocking filter’s
parameters, it is able to consistently improve the ob-
jective results for smooth images, achieving gains that
go up to about 0.3 dB. For smooth images, these gains
in PSNR correspond to obvious improvements in the
perceptual quality, resulting from the reduction of the
blocking effects introduced by the encoding process.
For non smooth images, like text and compound im-
ages, the new filtering strength control procedure is
able to attenuate, or even eliminate, the smoothing ef-
fects of the deblocking process, that result in a loss of
objective quality.
In the next section we briefly present the MMP and
MMP-Intra image encoding methods. Section 3 de-
scribes a recently proposed dictionary design tech-
nique and explains its importance in increasing the
performance of the MMP-Intra encoder. Section 4
presents the new deblocking strategies proposed in
this paper and is followed by section 5 where the ex-
perimental results of this method are presented . Sec-
tion 6 ends the paper with some closing remarks and
conclusions.
2 IMAGE CODING WITH MMP
A brief discussion of the application of the MMP and
MMP-Intra algorithms to image coding is presented
in this section. More information about these methods
can be found respectively in (de Carvalho et al., 2002)
and (Rodrigues et al., 2005).
2.1 The Mmp Algorithm
MMP is an multiscale approximate pattern matching
algorithm. It approximates an original square im-
age block, or its successive binary segmentations, us-
ing a vector from an adaptive dictionary D. Scale
transformations are used to adapt the dimensions of
blocks with different sizes. The successively seg-
mented blocks, X
l
, are represented by a binary seg-
mentation tree, where each original square block is
segmented first in the vertical, then in the horizontal
direction. The superscript l means that the block X
l
belongs to scale l or level l of the segmentation tree
(with dimensions (2
⌊
l+1
2
⌋
× 2
⌊
l
2
⌋
)).
A simple definition of the MMP algorithm can be
given by the following main steps.
For each block of the original image, X
l
:
1. find the dictionary element S
l
i
that minimises the
Lagrangian cost function of the approximation,
given by: J (T ) = D(X
l
, S
l
i
) + λR(S
l
i
), where
D(.) is the sum of square differences (SSD) func-
tion and R(.) is the rate needed to encode the ap-
proximation;
2. parse the original block into two blocks, X
l−1
1
and
X
l−1
2
, with half the pixels of the original block;
3. apply the algorithm recursively to X
l−1
1
and X
l−1
2
,
until level 0 is reached;
4. based on the values of the cost functions deter-
mined in the previous steps, decide whether to seg-
ment the original block or not;
5. if the block should not be segmented, use vector S
l
i
of the dictionary to approximate X
l
;
6. else
(a) create a new vector S
l
new
from the concatenation
of the vectors used to approximate each half of
the original block: X
l−1
1
and X
l−1
2
;
(b) use S
l
new
to approximate S
l
;
(c) use S
l
new
to update the dictionary, making it
available to encode future blocks of the image.
i0
i1
i2
i4
i3
0
2
6
13
i0
i1
i4
i2 i3
Figure 1: Segmentation of a block and corresponding binary
tree: the root corresponds to a original 4×4 block (level 4),
while nodes i
2
and i
3
(1×1 blocks) belong to level 0.
This algorithm results in a binary segmentation tree
that represents each original image block. This tree,
represented in figure 1, is encoded using a top-bottom
preorder approach. In the final bit-stream, each leaf
is encoded using a binary symbol ’1’ and followed by
an index, that identifies the vector of the dictionary
that should be used to approximate the corresponding
sub-block. Each tree node is encoded using the binary
symbol ’0’. The string of symbols that represents the
segmentation tree is encoded using an adaptive arith-
metic encoder.
Unlike conventional vector quantisation (VQ) algo-
rithms, MMP uses approximate block matching with
scales and an adaptive dictionary.
IMPROVING MULTISCALE RECURRENT PATTERN IMAGE CODING WITH DEBLOCKING FILTERING
119

Every concatenation of two dictionary blocks of
level l − 1 results in a new block, that corresponds
to a pattern that did not exist in the dictionary and is
used to update it, becoming available to encode future
blocks of the image, independently of their size. This
updating procedure efficiently adapts the dictionary,
by using only information that can be inferred by the
decoder, since it is based exclusively in the encoded
segmentation flags and dictionary indexes.
MMP uses a separable scale transformation T
M
N
to
adjust the vectors’ sizes before attempting to match
them, allowing for the matching of vectors of different
dimensions. For example, in order to approximate an
original block X
l
using one block S
k
of a different
scale of the dictionary, MMP first determines S
l
=
T
l
k
[S]. Detailed information about the use of scale
transformations in MMP is presented in (de Carvalho
et al., 2002).
2.2 The Mmp-intra Algorithm
MMP-Intra combines the original MMP algorithm
with predictive coding. For each original block, X
l
,
MMP-Intra determines a prediction block, P
l
m
, us-
ing previously encoded image pixels and then it de-
termines a residue block, given by R
l
m
= X
l
− P
l
m
.
This residue block is then encoded using MMP.
MMP-Intra uses essentially the same prediction
modes defined by H.264/AVC for Intra coded blocks
(Joint Video Team (JVT), 2005)(Rodrigues et al.,
2005). Intra prediction is also used hierarchically
for blocks of dimensions 16×16 down to 4×4 (cor-
responding to levels 8 to 4 of the segmentation tree).
By the use of the Lagrangian RD cost function, the
encoder jointly optimises the block prediction and the
MMP residue encoding, determining the best trade-
off between the prediction accuracy and the additional
overhead introduced by the prediction data.
MMP-Intra encodes some additional information
for the block prediction, namely the used prediction
mode, m, and the block size used for the prediction
step. This information is used by the decoder to deter-
mine the same prediction block, P
l
m
, that was used in
the encoder. This block is added to the decoded resid-
ual block,
ˆ
R
l
m
, in order to reconstruct the decoded
image block, given by
ˆ
X
l
= P
l
m
+
ˆ
R
l
m
. Details about
MMP-Intra can be found in (Rodrigues et al., 2005).
3 EFFICIENT DICTIONARY
DESIGN FOR MMP-INTRA
MMP-Intra, as MMP, uses an initial dictionary con-
sisting of a few blocks with constant value. This
highly sparse initial dictionary is very inefficient, but
the updating procedure quickly adapts its blocks to
the original images’ patterns, by introducing new
blocks, S
l
new
, created by the concatenation of two
vectors of level l − 1 of the dictionary.
Experimental studies have shown that the final
number of blocks for each level of the dictionary is,
by far, much larger than the total number of blocks
that are actually used. This difference grows with the
target bit-rate, but can be observed for different im-
age types and target compression ratios. The exag-
gerate growth of the dictionary has the disadvantage
of increasing the dictionary’s indexes’ entropy, com-
promising the method’s performance.
In (Rodrigues et al., 2006), a new algorithm was
proposed to limit the dictionary growth, that intro-
duces a “minimum distance condition” between any
two vectors of each level of the dictionary. This pro-
cess avoids that new vectors, very close to those al-
ready available in the dictionary space, are used to
update the dictionary, by using a new test condition
in the dictionary update procedure. With this new al-
gorithm, a new block of level l, S
l
new
, is only used to
update the dictionary if its minimum distortion, in re-
lation to the blocks already available in the dictionary,
is not inferior to a given threshold d.
The optimum value for d is a function of the target
bit-rate and therefore of the parameter λ, and must
be carefully chosen. If this value is too small, the
aim of controlling the dictionary growth will not be
achieved, and if it is too large, the dictionary will lose
its efficiency in approximating the images’ patterns.
A simple expression for d(λ) (see eq. 1) was de-
termined by the use of a test image set, and allows
the encoder to automatically achieve a close to opti-
mum RD relation, for any given target bit-rate. Fur-
ther details on how this equation was determined can
be found in (Rodrigues et al., 2006).
d(λ) =
5 if λ ≤ 15;
10 if 15 < λ ≤ 50;
20 otherw ise.
(1)
In (Rodrigues et al., 2006), the authors also show
that the dictionary’s indexes can be more efficiently
encoded by using a context adaptive arithmetic en-
coder. The dictionary indexes are divided into groups,
according to a context criterion, that, for MMP-Intra,
is the original scale of the block. Instead of using just
one symbol to encode a dictionary index, each index
is transmitted using one context symbol followed by
an index, that chooses among the elements of the cor-
responding segment. This carefully chosen segmen-
tation criterion further explores the statistical depen-
dencies of the MMP symbols, generating gains in the
arithmetic coding module.
SIGMAP 2006 - INTERNATIONAL CONFERENCE ON SIGNAL PROCESSING AND MULTIMEDIA
APPLICATIONS
120
4 THE DEBLOCKING FILTER
The MMP-Intra algorithm uses the concatenation of
several approximations of the image blocks, at differ-
ent scales. For each approximation,
ˆ
X
l
, the RD con-
trol algorithm only controls the distortion for the im-
age block and makes no consideration regarding the
continuity in the border of the blocks. This intro-
duces blocking artifacts in the reconstructed image,
that originate from the discontinuities in the block
boundaries.
In this work we present the results of our investi-
gation in deblocking techniques that increase both the
objective as the perceptual quality of the MMP-Intra’s
reconstructed image. We use an adaptive space-
variant finite impulse response (FIR) filter to attenuate
the blocks’ borders discontinuities.
Let
ˆ
X be the reconstructed signal.
ˆ
X can be re-
garded as the concatenation of several blocks,
ˆ
X
l
k
k
,
that represent the algorithm’s approximation of the
various adjacent areas of the image. The K blocks
ˆ
X
l
k
k
, used in the approximation, have no overlapping
areas and different block sizes, given by (2
⌊
l
k
+1
2
⌋
×
2
⌊
l
k
2
⌋
). The decoded image can thus be represented
as
ˆ
X =
K−1
X
k=0
ˆ
X
l
k
k
(x − x
k
, y − y
k
). (2)
In equation 2, each block
ˆ
X
l
k
k
corresponds to a dic-
tionary block, of scale l
k
, that was created by the
MMP dictionary update process. This means that
each of these blocks can be further decomposed into
their basic components, D
0
, each belonging to the
original dictionary, i.e.
ˆ
X
l
k
k
=
J−1
X
j=0
D
0
l
j
j
. (3)
The blocks D
0
l
j
j
can be regarded as the basic
”building units” that were used by the MMP-Intra en-
coder and the l
j
values represent the scale that was
used by the encoder to represent each area of the im-
age. The border points between each of these blocks
correspond to the most probable areas for discontinu-
ities in the decoded image.
In this work we apply a running bi-dimensional
FIR filter to the reconstructed image,
ˆ
X. The fil-
ter’s kernel dimensions are successively adapted to
the scale of the original dictionary block that was used
to approximate the area of the image that is currently
being deblocked.
Blocks D
0
l
j
j
of large scales have larger support re-
gions, meaning that the corresponding area of the im-
age is smoother, while blocks with small values of
l
j
are used in more detailed image areas. The used
space-variant filter has the ability to adapt its support,
and smoothing strength, to the dimensions of each im-
age segment, D
0
l
j
j
, being considered.
l
0
l
2
l
1
l
2
l
0
l
1
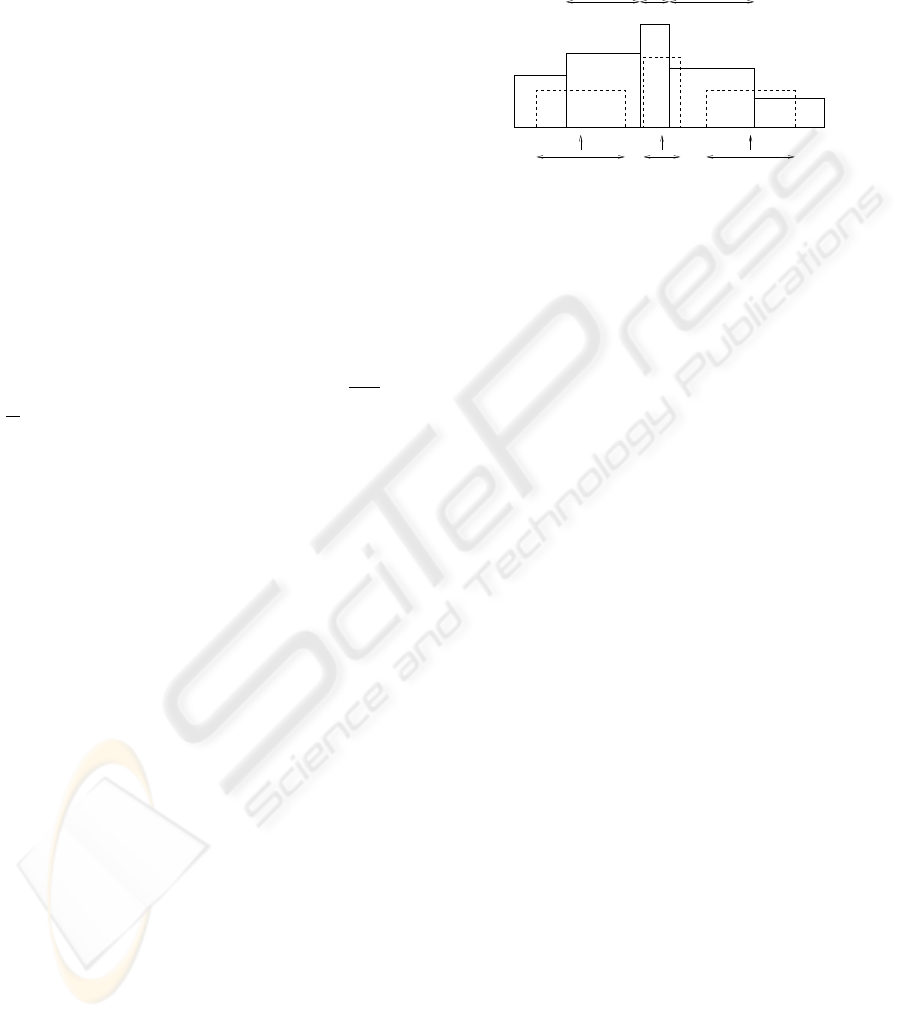
f ( ) f ( )
f ( )
Figure 2: The deblocking process uses an adaptive support
for the FIR of the filters used in the deblocking.
Figure 2 has a unidimensional representation of a
reconstructed portion of the image, that was approx-
imated by the concatenation of three basic blocks,
(D
l
0
0
D
l
1
1
D
l
2
2
), with different scales: l
0
, l
1
and l
2
.
At each filtered pixel, represented in the figure by the
arrow, the kernel support of the deblocking filter is set
according to the scale l
k
.
This process is similar to the one proposed in
(de Carvalho et al., 2000), that uses a running aver-
age filter and sets the kernel support at each point to
l
k
+ 1. This filter is known for its highly smooth-
ing effect, but the support adaptation process controls
its strength according to the detail level of the region
that is being deblocked. This prevents some of the
blurring artifacts that are usually caused by the use
of too powerful deblocking techniques, but the origi-
nal filtering process still results in a reduction in ob-
jective quality for smooth images. Another disadvan-
tage of the original process is that it introduces highly
disturbing blurring artifacts in non smooth images,
resulting in a severe decrease in the final values of
PSNR. This fact limits the applicability of this filter,
because there is no practical way of avoiding the blur-
ring of images that do not need deblocking.
In our work, we have adapted this deblocking pro-
cess to MMP-Intra and developed it. This investi-
gation resulted in a more efficient, highly adaptive,
deblocking filter, that has some important advantages
over the original method, namely:
• it uses a Gaussian kernel with optimised shape and
support for each image, that adapts the deblocking
strength to the image features resulting in percep-
tual, as well as, objective quality gains;
• the kernel shape optimisation means that the filter-
ing strength is automatically adjusted and can be
set to an arbitrarily low power. This means that,
for non low-pass images, the new process automat-
ically eliminates the highly annoying blurring ef-
fects and the corresponding PSNR losses;
IMPROVING MULTISCALE RECURRENT PATTERN IMAGE CODING WITH DEBLOCKING FILTERING
121

• the new method considers the dimensions of the
neighbouring blocks as well as those of the block
being filtered, eliminating some artifacts that were
introduced by the original method;
• the proposed algorithm monitors the differences in
the frontiers’ pixels’ intensities, in order to avoid
smoothing steep variations that were present in the
original image and do not correspond to blocking
artifacts.
4.1 Adapting Shape and Support for
the Deblocking Kernel
In our investigation we tested different kernels with
various support regions for the deblocking filter. Ex-
perimental results showed that the use of Gaussian
kernels, instead of the original rectangular filter, pro-
duces gains in the PSNR value of the decoded image,
as well as the desired effect of eliminating the block-
ing artifacts.
These tests also demonstrated that the quality of the
deblocked image strongly depends on the dimensions
of the support region of the used filter. In the original
method, this support is set to l
k
+ 1. We varied this
value and discovered that it is optimal for the running
average filter, but that this is not the case when we use
a Gaussian kernel.
Instead of adjusting the support region of the Gaus-
sian kernel, we set the filter length at the same l
k
+ 1
samples used in the original method, but adjust the
Gaussian’s variance, producing filter kernels with dif-
ferent shapes. Consider a Gaussian filter, with vari-
ance σ
2
and length L, with an impulse response (IR)
given by:
g
L
(n) = e
−
(
n−
L−1
2
)
2
2.σ
2
, (4)
with n = 0, 1, ..., L − 1. We controlled the shape of
the filter by changing a filter parameter α, that con-
trols the variance of the Gaussian, by using the ex-
pression:
g
L
(n) = e
−
(
n−
L−1
2
)
2
2.(α.L)
2
, (5)
to determine the filters’ IR.
Figure 3 represents the shape of a 17 tap filter for
the several values of parameter α represented in the
legend. This figure clearly demonstrates the explored
relation between the filters’ shape and their approxi-
mate support. By varying the value of the filter’s α pa-
rameter, one is able to efficiently adjust its IR from an
almost rectangular filter, with a support region l
k
+ 1,
to a Gaussian filter with different lengths. In the limit,
when α tends to zero, the IR of the filter becomes a
simple impulse, deactivating the deblocking effect for
those cases were it is not beneficial.
The value of the parameter α is controlled by the
MMP-Intra encoder. At the end of the encoding
0
0.05
0.1
0.15
0.2
0.25
0 2 4 6 8 10 12 14 16
Gaussian FIR of deblocking filters
alpha=0.1
alpha=0.2
alpha=0.3
alpha=0.5
Figure 3: Adaptive FIR of the filters used in the deblocking.
process, the MMP-Intra encoder tests the deblock-
ing process using different values for the α parame-
ter. It is then able to determine the value that max-
imises the PSNR of the reconstructed image. The
value of α is then appended at the end of the en-
coded bit-stream, by using a 3 bit code, that corre-
sponds respectively to the 8 possible values for α:
{0, 0.05, 0.10, 0.15, 0.20, 0.25, 0.30, 0.40}. This in-
troduces a marginal additional computational cost in
the encoder, as well as an additional rate overhead,
that is equally negligible.
4.2 Eliminating the Artifacts
Introduced by Deblocking
The original method only considers the dimensions
of the block currently being filtered to set the filter
support. In our investigation we noticed that this fact
introduces an unexpected artifact, when there exists
the concatenation of wide and short blocks, with very
different intensity values.
This case is represented in figure 4, where a wide
dark block A is concatenated with two bright blocks:
one narrow block B followed by one wide block C.
When we filter blocks A and B, a smooth transition
appears, that eliminates the blocking effect in the AB
border. When the block C is filtered, because the used
filter has a very wide support region, the pixels near
the BC border will suffer from the influence of some
of the dark pixels of block A. This causes a dark ”val-
ley” to appear in the BC border, that introduces a vis-
ible artifact in the deblocked image.
In order to avoid these artifacts, the new method
controls the filter length so that the deblocking filter
never takes in consideration pixels that are not from
the present block or its adjacent neighbours. In the
example of figure 4, the length of the filter used in
the C block’s pixels that are near the BC border is
controlled, so that the left most pixel that is used in
the deblocking is always the first (left most) pixel of
block B, eliminating the described artifact. In figure
SIGMAP 2006 - INTERNATIONAL CONFERENCE ON SIGNAL PROCESSING AND MULTIMEDIA
APPLICATIONS
122

Block BBlock A
AB BC
Block C
Figure 4: A case were the concatenation of blocks with dif-
ferent supports and pixel intensities causes the appearance
of an image artifact, after the deblocking filtering.
4, this means that the new method uses the filter rep-
resented by the solid line, instead of the original one,
represented by the dashed line.
Another artifact caused by the original method is
the introduction of smooth transitions in regions of the
image that originally have very steep transitions from
low to high pixel intensity values (or vice versa). The
proposed algorithm monitors the differences in the
frontiers’ pixels’ intensities, in order to avoid filtering
steep variations that do not correspond to blocking ar-
tifacts. This is again controlled by the encoder, using
an adaptive method.
The proposed method uses a step intensity thresh-
old, s, that corresponds to the maximum intensity dif-
ference between the two border pixels, that still allows
for the filtering to occur. This process is represented
in figure 5, where two blocks A and B with very dif-
ferent intensity values are concatenated. In this case,
the AB border is only filtered if the absolute differ-
ence between the border pixels is inferior to the de-
fined value for s, i.e., |A
k
− B
0
| < s.
A
0
A
k
B
0
B
j
Block A Block B
Figure 5: A case where a steep variation in pixel intensities
is a feature of the original image.
The value of s is again chosen in order to maximise
the PSNR value for the particular image that is be-
ing deblocked. The encoder tests a set of different
step values and transmits the code corresponding to
the chosen value. A three bit code is again used to
represent the eight possible values for s, belonging to
the set {0, 16, 32, 64, 96, 128, 192, 255}, where s = 0
corresponds to never filtering the borders and s = 255
corresponds to the case where all blocks are filtered.
5 EXPERIMENTAL RESULTS
Experimental tests were performed using the pro-
posed and original deblocking methods. Figure 6
presents a detail of image LENA 512, encoded using
the described MMP-Intra algorithm without using any
deblocking technique and compares it with the results
of using the the deblocking technique from (de Car-
valho et al., 2000), and the new deblocking technique,
proposed in this paper.
Perceptually, we can observe that the new deblock-
ing filter is able to efficiently eliminate the blocking
artifacts in Lena’s face and hat, without compromis-
ing the image quality at regions with high detail, like
Lena’s hair and her hat’s feathers. In this case, the
used filter has α = 0.10 and s = 255.
When compared with the original deblocking
method, we can observe that the smoothing effect in-
troduced by the proposed method is not as strong,
avoiding the introduction of some blurring artifacts
that are noticeable in the image of figure 6 b), spe-
cially in the areas with finer details.
In figure 6 b) we can also observe the first type
of artifacts, explained in section 4.2. They appear
in Lena’s shoulder, where the previously described
”dark valleys” are easy to observe. We can see that
the proposed method efficiently eliminates these arti-
facts.
Figure 6 b) also shows that the original method, de-
veloped originally for the MMP encoder, suffers from
a unexpectedly high performance loss, when used
with MMP-Intra. Because MMP-Intra uses predic-
tive coding, the used dictionary blocks approximate
residue patterns. In some cases, where the prediction
step is particularly efficient, some detailed areas are
approximated by large, smooth, residue blocks added
with detailed prediction blocks. In this case, the de-
blocking process uses a wide filter to deblock an im-
age area that is not necessarily smooth. When this
happens, the use of the original deblocking method
originates serious artifacts, like the one observed in
Lena’s lip. Even when this fact is not as obvious as
in the presented case, we can generally say that this
factor seriously compromises the performance of the
original method, when applied to MMP-Intra, result-
ing in a severe reduction in the PSNR results. How-
ever, due to its adaptability, the proposed method does
not seem to suffer from this disturbing factor.
Figure 7 a) shows the objective quality results for
image Lena 512, for the MMP-Intra method with no
deblocking and with the two tested deblocking tech-
niques. Figure 7 b) highlights the PSNR quality gains
introduced by the deblocking filter, that are more rel-
evant for higher compression ratios, where the block-
ing artifacts are more noticeable. These gains go
up to more than 0.3 dB, allowing for the PSNR re-
sults of MMP-Intra for image Lena to come even
IMPROVING MULTISCALE RECURRENT PATTERN IMAGE CODING WITH DEBLOCKING FILTERING
123

(a) No deblocking (30.92 dB) (b) Original deblocking (28.93 dB) (c) New deblocking (31.21 dB)
Figure 6: A detail of image Lena 512, encoded with MMP-Intra at 0.135 bpp.
closer to the ones of top state-of-the-art transform-
quantisation based encoders, like JPEG2000 (Taub-
man and Marcelin, 2001) and H.264/AVC, (Joint
Video Team (JVT), 2005), shown in figure 7 a). In
fact, we can see that, for low bit-rates, the proposed
method allows for MMP-Intra to achieve equivalent
results to those of the JPEG2000 algorithm.
We also performed experimental tests using non
smooth images, like text image PP1205 and com-
pound (text and grayscale) image PP1209. Im-
ages PP1205 and PP1209 were scanned, respec-
tively, from pages 1205 and 1209 of the IEEE
Transactions on Image Processing, volume 9, num-
ber 7, July 2000 and are available for download at
http://www.estg.ipleiria.pt/∼nuno/MMP/. These tests
showed that the proposed kernel adaptation algorithm
eliminates the highly disturbing blurring artifacts in-
troduced when the original deblocking techniques are
applied to these images. This can be confirmed in
figure 8, where the perceptual results for compound
image PP1209 are presented.
Figure 8 c) also shows that the use of the new strate-
gies as a simple post processing deblocking algo-
rithm, allows for a deblocking effect that improves the
subjective quality of the decoded image, at the cost of
a slight reduction in the PSNR value. In addition, it
shows that the second type of artifacts introduced by
the original method, that introduce a smoothing ramp
in areas of the image that originally had an abrupt
variation, is efficiently eliminated by the proposed al-
gorithm (in this example, the value of s was set to 32).
Figure 9 shows the PSNR results for compound im-
age PP1209, for the case presented in figure 8, where
the deblocking process allows for an increased per-
ceptual image quality, at the cost of a small reduc-
tion of the PSNR value. As we can see, even in
this case the objective quality achived by the MMP-
Intra encoder is still about 1 dB better than that of the
H.264/AVC encoder and 2 dB better than that of the
JPEG2000 encoder.
26
28
30
32
34
36
38
40
42
0 0.2 0.4 0.6 0.8 1 1.2 1.4
PSNR (dB)
bpp
MMP-Intra - No Deblocking
MMP-Intra - Deblocking
MMP-Intra - Original Deblocking
H.264/AVC - High
JPEG2000
(a)
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0 0.2 0.4 0.6 0.8 1 1.2 1.4
PSNR gains (dB)
bpp
(b)
Figure 7: a) Objective quality results for image Lena;
b) PSNR gains of the new method, when compared with
MMP-Intra with no deblocking, using α = 0.10, s = 255.
SIGMAP 2006 - INTERNATIONAL CONFERENCE ON SIGNAL PROCESSING AND MULTIMEDIA
APPLICATIONS
124

(a) No deblocking (32.23 dB) (b) Original deblocking (27.13 dB) (c) New deblocking (32.04 dB)
Figure 8: A detail of compound image PP1209, encoded with MMP-Intra at 0.61 bpp.
22
24
26
28
30
32
34
36
38
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6
PSNR gains (dB)
bpp
MMP-Intra - No Deblocking
MMP-Intra - Deblocking
MMP-Intra - Original Deblocking
H.264/AVC - High
JPEG2000
Figure 9: Objective quality results for image PP1209 (adap-
tive deblocking filter used α = 0.10 and s = 32).
6 CONCLUSION
In this paper we present a new adaptive deblocking
technique that allows for improvements in both per-
ceptual and objective quality, for the MMP-Intra im-
age encoding algorithm. This method uses a space-
variant FIR filter with an adaptive shape and support
Gaussian impulse response. The filter parameters are
automatically controlled in order to maximise the ob-
jective quality for smooth images and eliminate the
disturbing blurring artifacts for non smooth images,
like text and graphics.
The use of the new deblocking techniques achieves
one of the main objectives in the on going research
of multiscale recurrent pattern image encoders: find-
ing ways to improve the algorithm’s performance
for smooth images, without compromising its ex-
cellent performance for non low-pass images, like
text and graphics. Experimental results have shown
that, for smooth images, the proposed techniques al-
lows for coding gains that go up to 0.3 dB for low
bit-rates, where the blocking artifacts are more no-
ticeable, achieving the same objective quality as the
JPEG2000 algorithm. Nevertheless, for non low-pass
images, like text and graphics, the proposed method
introduces no losses, allowing MMP-Intra to maintain
its 1 to 5 db advantage over the state-of-the-art image
encoders.
REFERENCES
de Carvalho, M., da Silva, E., and Finamore, W. (2002).
Multidimensional signal compression using multi-
scale recurrent patterns. Elsevier Signal Processing,
(82):1559–1580.
de Carvalho, M., Lima, D. M., da Silva, E., and Finamore,
W. (2000). Universal multi-scale matching pursuits
algorithm with reduced blocking effect. IEEE Inter-
national Conference on Image Processing.
Joint Video Team (JVT), ISO/IEC MPEG & ITU-T VCEG,
I. J. . I.-T. S. Q. (2005). Draft of Version 4
of H.264/AVC (ITU-T Recommendation H.264 and
ISO/IEC 14496-10 (MPEG-4 part 10) Advanced
Video Coding).
Rodrigues, N. M. M., da Silva, E. A. B., de Carvalho, M. B.,
de Faria, S. M. M., and Silva, V. M. M. (2005). Uni-
versal image coding using multiscale recurrent pat-
terns and prediction. IEEE International Conference
on Image Processing.
Rodrigues, N. M. M., da Silva, E. A. B., de Carvalho, M. B.,
de Faria, S. M. M., Silva, V. M. M., and Pinag
´
e, F.
(2006). Efficient dictionary design for multiscale re-
current patterns image coding. ISCAS 2006 IEEE In-
ternational Symposium on Circuits and Systems.
Taubman, D. S. and Marcelin, M. (2001). JPEG2000: Im-
age Compression Fundamentals, Standards and Prac-
tice. Kluwer Academic Publishers.
IMPROVING MULTISCALE RECURRENT PATTERN IMAGE CODING WITH DEBLOCKING FILTERING
125
