
TRAFFIC TRUNK PARAMETERS FOR VOICE TRANSPORT OVER
MPLS
A. Estepa, R. Estepa and J. Vozmediano
University of Sevilla
C/ Camino de los descubrimientos s/n
Keywords:
Voice transport, MPLS Traffic Engineering, VoMPLS, VoIP.
Abstract:
Access nodes in NGN are likely to transport voice traffic using MPLS Traffic Trunks. The traffic parame-
ters describing a Traffic Trunk are basic to calculate the network resources to be allocated along the nodes
belonging to its corresponding Label-Switched-Path (LSP).
This paper provides an analytical model to estimate the lower limit of the bandwidth that needs to be allocated
to a TT loaded with a heterogeneous set of voice connections. Our model considers the effect of the Silence
Insertion Descriptor (SID) frames that a number of VoIP codecs currently use. Additionally, two transport
schemes are considered: VoIP and VoMPLS. The results, experimentally validated, quantify the benefits of
VoMPLS over VoIP.
This work was supported in part by the Spanish Secre-
tar
´
ıa de Estado de Universidades y Educaci
´
on under
the project number TIC2003-04784-C02-02
1 INTRODUCTION
Voice transport over New Generation Networks
(NGN) will likely make use of QoS-supporting
packet-switching networks. Multi-Protocol-Label
Switching (MPL, 2001)(MPLS) is a packet forward-
ing technique that facilitates the creation of Label-
Switched-Paths (LSPs) and allows the use of traffic
engineering needed to support the provision of QoS
at an optimal cost.
The traffic engineering (TE, 1999) inherent capa-
bility of MPLS allows to dynamically route a set of
forwarding equivalence classes over a so-called Traf-
fic Trunk (TT) which follows the most adequate path
according to its traffic characteristics, available re-
sources in the network and administrative criteria. For
the remainder of this paper, a TT will be used to trans-
port a set of voice streams which demand the same
QoS and follow the same LSP between two Label-
Edge Routers (LERs) as indicated in figure 1.
In order to provide a TT with traffic engineering
capabilities, the source LER needs to be aware of a
number of its characteristics. Among them, we are
interested in the traffic parameters (e.g. mean and
peak bit-rates), which can be calculated from the traf-
fic characterization of each voice stream belonging to
the TT. These traffic parameters are required to calcu-
late the capacity to be reserved for the TT in each link
of the MPLS network and to develop a faithful map
of the overall capacity remaining free in the network.
Consequently the traffic parameters are a basic input
to any constrained-routing algorithm.
MPLS
IP VoMPLS A2oMPLS
UDP
RTP
MPLS
IP VoMPLS A2oMPLS
UDP
RTP
To / From
To / From
GW
Gateway Device
Link
Label Switching router
VoATM
...
others
VoIP
Voice Networks
PTSN
PTSN
VoATM
...
others
VoIP
Voice Networks
MPLS Network
GW (LER)
GW (LER)
Label Switched Path
(Label Edge Router)
Figure 1: Sample scenario.
The methods used to calculate the optimal capacity
to be reserved are usually based in complex analyti-
cal models (R. Gu
´
erin and Naghshineh, 1991) and are
out of the scope of this paper. However, the band-
width reservation should range from the sum of the
conversation’s mean bit-rates (stability condition) to
58
Estepa A., Estepa R. and Vozmediano J. (2006).
TRAFFIC TRUNK PARAMETERS FOR VOICE TRANSPORT OVER MPLS.
In Proceedings of the International Conference on Signal Processing and Multimedia Applications, pages 58-64
DOI: 10.5220/0001572800580064
Copyright
c
SciTePress

the sum of its peak bit-rates
1
. A common and simple
approach to calculate the actual bandwidth reserva-
tion is to use the sum of the conversation’s peak bit-
rates and take this upper limit as the allocation to be
requested for the TT. This guarantees that no packet
loss occurs at the cost of some over-provisioning of
network resources. However, this conservative peak
bit-rate approach could potentially cause the rejec-
tion of a new TT in the LER’s admission procedure
(CAC,) in spite of having enough capacity.
As the number of multiplexed sources in the TT in-
creases, the traffic burstiness is smoothed and the ca-
pacity to be reserved should gradually change from
the peak bit-rate approach to the mean bit-rate ap-
proach, thus making a more effective use of the net-
work resources. However, the current calculus (B,
2002) of the mean-bit rate of the TT is inaccurate,
since it is based in the ON-OFF model which does
not consider the generation of Silence Insertion De-
scriptor (SID) frames that a number of voice codecs
generate during voice inactivity periods (Estepa et al.,
2003). These SID frames mark the end of talkspurts
and update the Comfort Noise Generation parameters
at the receiver.
Starting from the previous results in (Estepa et al.,
2003), we find a more accurate analytical expressions
for the traffic parameters of a TT (i.e. mean and peak
bit-rates) transporting a set of heterogeneous voice
sources when SID-capable codecs are used. We ap-
ply them to two possible voice transport schemes:
VoIP over MPLS and VoMPLS
2
. This would facil-
itate the use of the mean bit-rate value as a reference
for a effective resource allocation in traffic engineer-
ing. In addition, the comparison between these differ-
ent transport schemes (i.e. VoIP and VoMPLS as ob-
served in figure 1) will let us to assess the bandwidth
savings of VoMPLS over VoIP. Our results could be
also applied to optimize the off-line analysis of packet
loss and delay by using the analytical models to pro-
vide a desired QoS level as a function of both the TT
mean bit-rate and the number of sources to be multi-
plexed.
The rest of the paper is structured as follows: sec-
tion 2 sets the basic models to transport voice over
an MPLS cloud and establishes the TT model used
throughout the paper. Section 3 calculates the maxi-
mum and minimum capacity allocation for a voice TT
in a VoIP over MPLS and VoMPLS scenario. Section
4 presents the main results and finally, section 5 con-
1
Within that range, the capacity selected represents a
balance between the maximum burst size and the probabil-
ity of out-of-profile.
2
The case of A2oMPLS is not addressed in detail be-
cause the current implementation agreement does not spec-
ify the packetization scheme for the SID frames. How-
ever, the findings presented for VoMPLS are still valid for
A2oMPLS with some minimum changes
cludes the paper.
2 MODELS FOR VOICE
TRANSPORT IN MPLS
This section addresses two subjects: the characteri-
zation of a voice source traffic a in a digital environ-
ment, and the means of transporting a set of those con-
versations belonging to a TT over an MPLS network.
Conversely to previous studies, we will not use the
ON-OFF model but the more general ON-SID model
presented in (Estepa et al., 2005). The main reason for
this is the inadequacy of the ON-OFF model to cap-
ture the effect of the SID frames in the conversation’s
mean bit-rate.
2.1 Single Voice Source Model: The
ON-SID Model
Low bit-rate codecs are commonly used in the trans-
port of voice over packet-switched networks. Typi-
cally, these type of codecs analyze the speech samples
generated during a period of time T and generate a in-
formation data-unit termed frame that can be used at
the receiver to faithfully restore the original sequence
of speech samples. Low bit-rate codecs are usually
equipped with a voice activity detection (VAD) fea-
ture which pursues bandwidth savings by avoiding the
generation of frames during voice inactivity periods.
Additionally, some audio codecs like G.729,
G.723.1 or AMR are also featured with an algorithm
which allows, at the beginning of each voice inactivity
period, to send SID frames. Reception of a SID frame
after a voice frame can be interpreted as an explicit
indication of the end of the talk-spurt. In addition,
SID frames may be also transmitted at any time dur-
ing the silence interval to update comfort noise gener-
ation parameters. This allows a faithful reproduction
of the background noise at the receiver’s side, increas-
ing the quality of the conversation at the cost of some
additional bandwith (Estepa et al., 2003).
Thus, the voice traffic model to be used in the re-
mainder of this paper will not be limited to the tra-
ditional ON-OFF model, but the more general ON-
SID model. This model assumes that in the discrete
time space t
i
= i · T (where T is the codec’s frame
generation period), the codecs continuously generate
frames which can be either of type: ACT (compressed
voice), SID (background noise) or NoTX. The latter
corresponds to a zero-length frame used to model in-
stants when no frames (ACT nor SID) are being gen-
erated. ON and SID periods are exponentially distrib-
uted. During voice activity periods ACT frames are
generated every T seconds. During voice inactivity
TRAFFIC TRUNK PARAMETERS FOR VOICE TRANSPORT OVER MPLS
59
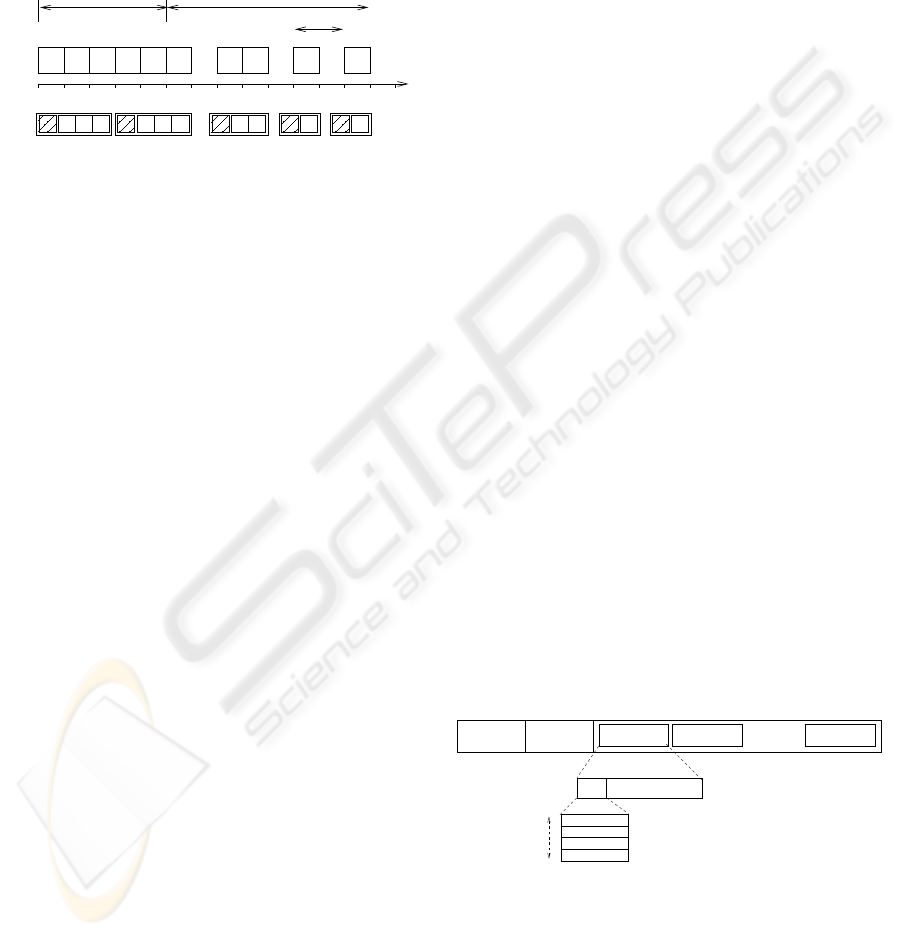
periods, SID frames are generated randomly accord-
ing to the codec’s specific algorithm and to changes in
the background-noise signal. Since SID frames gen-
eration is a random process, we can use a discrete
random variable, X, to indicate the inter-arrival time
(in number of periods T ) between SID frames as ex-
pressed in figure 2. Moreover, we assume that SID
frame generation is a renewal process.
S S S S
A A
A A
...
t
Frames
SAAAA S S S SA
A
S
ON SID
T 2T
...
Packets
X
Figure 2: ON-SID frame generation model for VoIP and
N
f pp
=3.
Additionally, we also assume that during voice ac-
tivity periods, to compensate the excess of overhead
of layer protocols (H), ACT frames are usually sent
to the network in groups of N
fpp
consecutive frames
per packet. Note that this also causes a packetiza-
tion delay that limits the maximum acceptable value
of N
fpp
.
2.1.1 Mean Bit-rate of a Single Voice Source
According to the ON-SID model, a packetized voice
stream transmitted with VAD capable codecs which
transmit SID frames exhibits a mean bit rate of:
r = ρ · p + (1 − ρ) · r
SID
(1)
where ρ is the conversation mean activity rate, p is
the peak rate and r
SID
is the mean rate during voice
inactivity periods caused by the transmission of SID
frames. For those codecs which do not generate SID
frames, obviously r
SID
= 0.
The factors of equation 1 depend on the transport
scheme used (i.e. VoIP and VoMPLS,) and will be
addressed in next subsections.
2.2 Alternatives for Voice Transport
in MPLS
This paper addresses two possible ways of voice
transport over an MPLS TT, depending on whether
the tributary conversations come from VoIP or are di-
rectly taken from the payload of the VoIP packets; that
is, the transport of codec frames directly over MPLS
or VoMPLS.
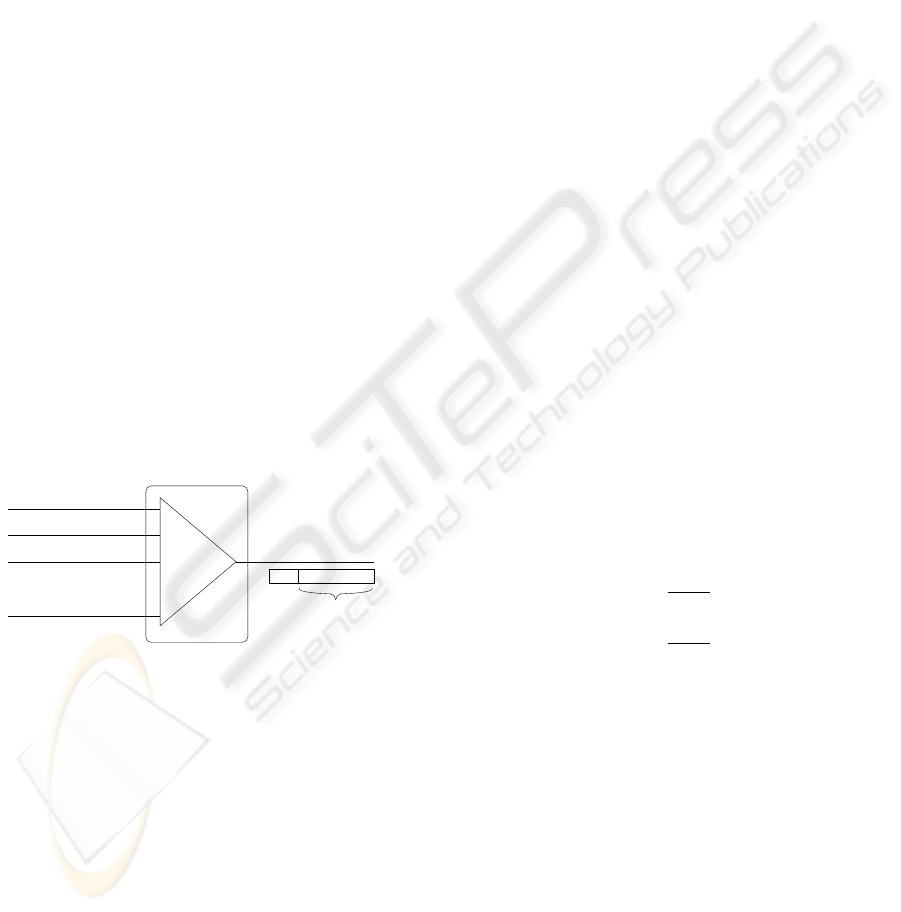
2.2.1 VoMPLS
The implementation agreement defined by the MPLS-
FrameRelay Alliance (VoM, 2001) describes how to
transport voice directly over MPLS. The method is
illustrated in figure 3 and can be summarized in the
following ideas:
• A number of voice calls may be transported over
an LSP. The multiplexing structure consists of a
mandatory Outer Label, zero or more Inner La-
bels, and one or more VoMPLS Primary Subframes
consisting of a 4-octet Header (HDR) and variable
length Primary Payload each, as shown in figure 3.
• Each Primary Subframe may be associated with a
different voice connection. A Primary Payload is
either a sequence of encoded ACT voice frame(s)
or a single SID frame.
• Within the header of a Primary Subframe, the
length field is indicated in multiples of 4 octets.
Thus, up to three padding octets may be inserted
in each subframe depending on the codec’s frame
size and the number of codec’s frames carried in
the Primary Subframe.
• A Primary Payload contains the traffic that is fun-
damental to the operation of a connection identified
by a Channel Identifier (CID). It includes ACT and
SID frames. Primary Payloads are variable-length
subframes.
• Control Subframes may be sent to support the Pri-
mary Payload (e.g., dialled digits for a primary pay-
load of encoded voice) and other control functions
(like RTP-timestamps). Control and Primary Sub-
frames are not mixed together in the same multi-
plexing frame. Thus, Control Subframes will not
be considered in the present study since they be-
long to the signalling plane.
The header’s Channel ID (CID) allows up to 248
VoMPLS calls to be multiplexed within a single LSP
so the Inner Labels will not be considered in the rest
of the paper.
CID
PayLoad Type
Lenght
Counter
Inner Label . . .
C I D = Channel ID
H D R = Header
M = Mandatory
O = Optional
HDR
Outer Label
Subframe
4 octers
Primary PayLoad
(M) (O)
Primary Primary
Subframe
Primary
Subframe
Figure 3: VoMPLS traffic trunk format.
The aforementioned implementation agreement
also establishes the maximum N
fpp
allowed value for
each codec (e.g. in VoMPLS there is a maximum
value of N
fpp
=6 for the G.729B codec, while for the
G.723.1 codec N
fpp
is forced to be 1).
SIGMAP 2006 - INTERNATIONAL CONFERENCE ON SIGNAL PROCESSING AND MULTIMEDIA
APPLICATIONS
60
2.2.2 VoIP over MPLS
The protocols involved in the transport of IP packets
are the Real Time Protocol (RTP) and the UDP pro-
tocol, resulting in a RTP/UDP/IP header of 40 octets
per each IP packet.
Packets are generated every T · N
fpp
seconds dur-
ing voice activity periods. During voice inactiv-
ity periods, SID frames are packed according to the
RFC 3551 packetization scheme, where only those
SID frames consecutively generated may be carried
in the same packet, up to the maximum of N
fpp
.
Each VoIP stream is multiplexed in a Subframe of
the MPLS TT multi-frame structure. A new TT multi-
frame is sent whenever any conversation of the TT
needs to send a new IP packet. The multi-frame has
an Outer Label as indicated in next section.
2.3 Aggregation of Heterogeneous
Voice Sources in a Traffic Trunk
For the aggregation of the voice sources in a single
TT we consider the multiplexing model illustrated in
Figure 4, where a set of K classes of m
i
homoge-
neous ON-SID sources feed a multiplexer (which can
be a LER) where a TT of real-time voice sources is
created. Each one of the m
i
voice streams belong-
ing to the same class i will have a common value of
N
fpp
and codec, and consequently, the same ON-SID
parameters; namely, the peak bit-rate (p
i
) and mean
bit-rate (r
i
).
m , r , p
1 1
m , r , p
1
2
3
m , r , p
K K KK
3 3
2 2
.
.m , r , p
.
.
MUX
L.E.R.
TT
R , P , B
TT TT
Outer
Label
VoIP or VoMPLS
scheme frames
Figure 4: Voice multiplexing model.
According to figure 4, the traffic characterization
should include the Outer Label of the TT. Therefore,
traffic parameters defining the traffic profile are:
• Traffic Trunk’s Mean Bit-rate: this parameter is the
minimum service rate that guarantees stability in
the system and thus, is the minimum capacity that
should be allocated for the TT. It includes the sum
of all the conversations mean bit-rate for the class i
plus the mean bit-rate caused by the Outer Label of
the TT (R
OL
).
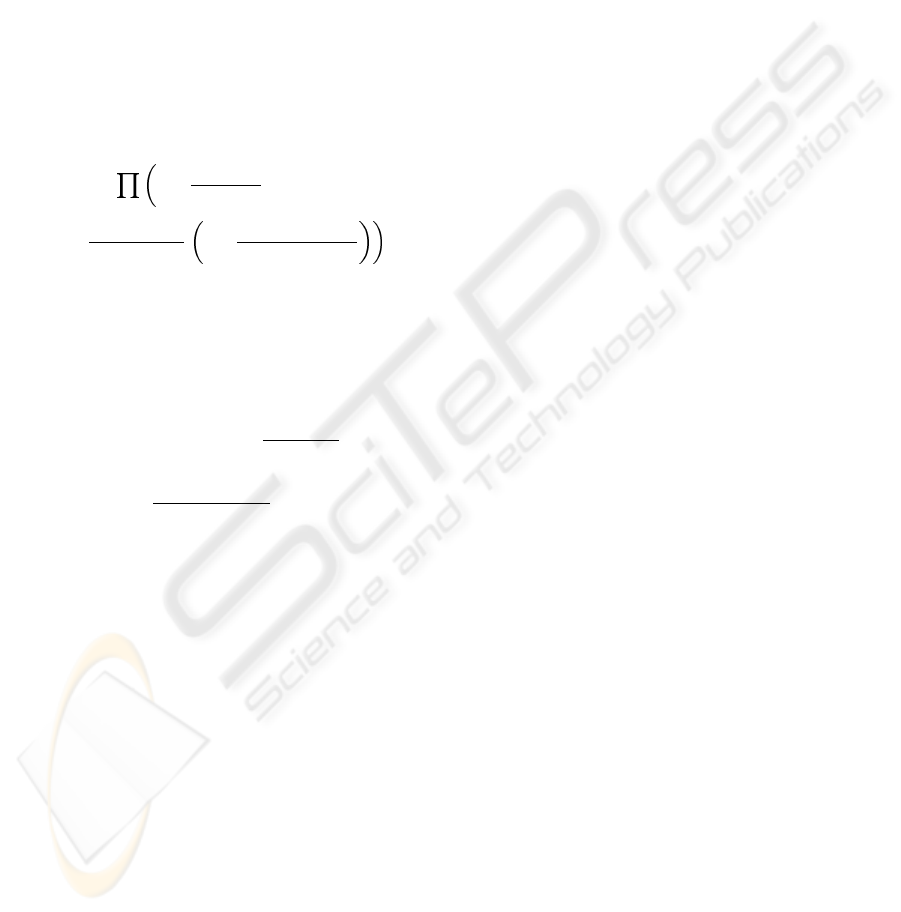
R
T T
=
K
X
i=1
m
i
· r
i
+ R
OL
(2)
• Traffic Trunk’s Peak bit-rate: is the sum of all the
peak rates plus the peak bit-rate of the Outer La-
bel of the trunk supposed that all sources are ON
(P
OL
). This is the maximum capacity that should
be allocated to the TT to avoid packet loss.
P
T T
=
K
X
i=1
m
i
· p
i
+ P
OL
(3)
• Traffic Trunk burst-size: this parameter can be con-
sidered to be free. The reason for this is that the
allocated capacity (C) for the TT must be a value
greater than R
T T
(to be stable) and smaller than
P
T T
(to take advantage of statistical multiplexing).
For C=P
T T
, the buffer size (B) needs to be only
big enough to store one voice packet from each
conversation, while for C=R
T T
, B should be large
enough in order to queue all the instant traffic in or-
der to bound the potential packet loss. An excellent
paper reviewing this tradeoff is (Procissi G, 2002).
Since the relation between B and the QoS depends
on the multiplexing analytical model used in the study
(i.e. either fluid model or MMPP), our goal is to find
the values of P
T T
and R
T T
for VoMPLS and VoIP
trunks. The next section is devoted to this task.
To account the Outer Label influence in the TT
mean bit rate, we make the following assumption: a
new MPLS frame is generated every T
min
=min{i =
1, ..k; T i} whenever there is any source generating a
new frame (i.e. voice frames or SID frames). For the
peak bit-rate calculation, we assume that a new trunk-
ing frame is generated every T
min
. Thus, the values
of P
OL
and R
OL
result as follow:
P
OL
=
H
OL
T
min
(4)
R
OL
=
H
OL
T
min
· G
T X
(5)
where G
T X
is the probability of having at least one
voice source generating a new frame at T
min
.
3 NEW VALUE OF THE TRAFFIC
PARAMETERS FOR MPLS
TRANSPORT
This section is devoted to finding out the analytical
expression for the traffic parameters as indicated in
equations 3 and 2 of previous subsection. In our ap-
proach, we first find analytical expressions for p
i
and
r
i
for both transport schemes under study: VoIP over
MPLS, and VoMPLS.
TRAFFIC TRUNK PARAMETERS FOR VOICE TRANSPORT OVER MPLS
61

Table 1: Codec characteristics.
Codec Mode L
ACT
L
SID
T (ms) E[X] P
1
G.729 - 10 2 10 7.33 0
G.723.1 6.3 24 4 30 13.05 0.27
5.3 20 4 30
AMR 4.75 12 5 20 7.47 0
12.2 31 5 29 7.47 0
3.1 Mean and Peak Bit-rate for VoIP
The peak rate of a VoIP conversation depends upon
both the codec characteristics and the number of
frames per packet (N
fpp
). Thus, it is clearly given
by:
p
i
=
H + N
fpp
L
ACT
N
fpp
T
(6)
where H is the header size of the protocol layers in-
volved in the transport service (i.e. 40 octets), L
ACT
is the voice frame size and T is the frame generation
period of a given codec. Table 1 shows the character-
istics of some VoIP codecs.
Regarding the r
SID
member of equation 1, an ana-
lytical expression for the VoIP transport may be found
in (Estepa et al., 2005). The deduction was based
in the separation of the contribution of the header
and the SID frames to the mean bit-rate so r
SID
=
R
H
+ R
fr
. The contribution of the SID frames can
be obtained by application of the Elementary Renewal
Theorem (ERT) which states that the SID frames ar-
rival long-term rate is the inverse of the expected
inter-arrival time (E[X] · T ).
R
fr
=
L
SID
T · E[X]
(7)
where L
SID
is the size of a SID frame.
In VoIP, the contribution of the packet header gen-
erated during inactive periods follows the packet gen-
eration pattern imposed by the RFC 3551, where
one packet header is sent every non-consecutive SID
frame (X = x > 1). For consecutive SID frames,
one packet header is sent every N
fpp
frames, so both
cases must be considered. Since the mean time be-
tween SID frames is given by (E[X] · T ), the header
contribution (R
H
) can be expressed as:
R
H
= P
1
·
H
N
fpp
· T · E[X]
+(1−P
1
)
H
T · E[X]
(8)
where P
1
stands for the probability of having two
time-consecutive SID frames (i.e. P (X = 1)).
Thus, for the VoIP case we have an overall mean
bit-rate of:
r
i
= ρ · p
i
+
1 − ρ
T · E[X]
·
L
SID
+ H ·
1 +
P
1
(1 − N
fpp
)
N
fpp
(9)
3.2 Mean and Peak Bit-rate for
VoMPLS
When compared to the VoIP case introduced above,
VoMPLS transportation shows three main changes:
1. The header size (H) only accounts for one HDR
header, with a size of 4 octets instead of the VoIP
header of 40 octets.
2. The padding phenomenon may add extra octets to
the packets generated during voice activity periods
or SID periods.
3. The packetization scheme forces that one primary
subframe may carry only one SID frame. This im-
plies changes in R
H
when compared to the VoIP
case.
According to the first and second items, an ex-
tra load of (N
fpp
L
ACT
) mod 4 octets needs to be
added in the ON periods. Thus, p
i
is:
p
i
=
H + N
fpp
L
ACT
+ (N
fpp
L
ACT
) mod 4
N
fpp
· T
(10)
On SID periods, an extra load of L
SID
mod 4
octets needs to be added to equation R
fr
. Apply-
ing again the renewal theorem and taking into account
that only one SID frame can travel in the subframe,
we can redefine:
R
fr
=
L
SID
+ (L
SID
mod 4)
T · E[X]
(11)
and,
R
H
=
H
T · E[X]
(12)
So the mean bit-rate for VoMPLS will be:
r
i
= ρ · p
i
+ (1 − ρ) ·
H + L
SID
+ (L
SID
mod 4)
T · E[X]
(13)
where all the information units are measured in
octets.
SIGMAP 2006 - INTERNATIONAL CONFERENCE ON SIGNAL PROCESSING AND MULTIMEDIA
APPLICATIONS
62
3.3 Traffic Trunk Parameters
According to equations 2 and 3, the lower and upper
limits of the bandwidth reservation for the TT can be
readily calculated, since p
i
and r
i
have been deduced
in sections 3.1 and 3.2 for VoMPLS and for VoIP over
MPLS respectively.
However, the traffic parameters of the TT should
also include the effect of the MPLS Outer Label in
the mean and peak bit-rates. To do this, we have to
compute the probability of having at least one voice
source generating a new frame at T
min
(G
T X
). This
can be calculated from the probability that no source
from any class generates a packet.
In the VoIP over MPLS case, and according to
equation 8, it is given by:
G
T X
= 1 −
K
i=1
1 −
ρ · T
min
N
f pp
· T
i
(14)
−
T
min
(1 − ρ)
E[X
i
] · T
i
1 +
P
1
· (1 − N
f pp
)
N
f pp
m
i
In the VoMPLS case, we should consider that pack-
etization scheme forces that one primary subframe
may only carry one SID frame. Thus, G
T X
results
into:
G
T X
= 1 −
K
Y
i=1
1 −
ρ · T
min
N
fpp
· T
i
−
(1 − ρ) · T
min
E[X
i
] · T
i
m
i
(15)
Experimental values show that, when more than 5
sources are multiplexed, G
T X
is greater than 0.95,
and for more than 10 sources, the probability in-
creases up to 0.99. Thus, we may assume G
T X
=1
for a large number of multiplexed sources (i.e. more
than 10).
4 VALIDATION AND
NUMERICAL RESULTS
This section presents the results of a comparative
study between VoIP over MPLS and VoMPLS. This
allows to quantify the benefits of VoMPLS, and vali-
dates the equations presented in the previous section.
4.1 Experiment Setup
Following the methodology found in (Estepa et al.,
2003), both edges of 14 conversations which took
place between males and females speakers, were
recorded from an ISDN line in a low-noise office en-
vironment (i.e SNR > 20dB.) The 600 minutes of
PCM audio files obtained were encoded using the
G.729B codec. This codec, highly available in any
VoIP environment, holds the capability of generating
SID frames and is widely referenced in the literature,
so it will let us to compare our results with previ-
ous studies. The output of the codec was processed
to obtain the sequence of types of frames generated
(ACT, SID or NoTXN for none.) This information
was stored in a file -ftype files- for each conversation,
and all of them were processed to experimentally find
the proper parameters to be used in the models (i.e.
activity rate ρ, E[X], P
1
.)
The ftype files were also split into 120 pieces of
five-minutes-long conversations. This database of
five-minute pieces of speech conformed a pool from
which N were randomly chosen to feed a simulator.
Each simulation was repeated 40 times to provide ac-
curate measures of the TT mean bit-rate at the output
of the LER.
The mean bit-rate obtained in our simulations is
then compared to those provided by the analytical
expressions of R
T T
, for both VoIP over MPLS and
VoMPLS, respectively.
4.2 Numerical Results
A total of N=20 homogeneous voice sources were
multiplexed following the procedure explained above.
Figure 5 plots R
T T
as obtained from simulations and
from our analytical ON-SID model for both VoIP
and MPLS TTs. Additionally, it shows R
T T
when
r
SID
=0, as is traditionally assumed by the one-source
ON-OFF model.
In the VoIP over MPLS case the differences be-
tween our analytical ON-SID model prediction and
the simulation results, measured at the LER’s output,
range between 1% (N
fpp
=1) and 4% (N
fpp
=6). For
VoMPLS those differences vary from 0%(N
fpp
=1) to
5% (N
fpp
=6). This validates the analytical results in
both cases.
When using the traditional ON-OFF model, the
VoIP over MPLS case shows differences ranging
from 11% to 31%, at the same measuring point. In
the VoMPLS case, with the same frame-generation
model, the differences range between 11% and 19%.
This means that the SID-frames effect, known to be
non-negligible in VoIP, should also be taken into ac-
count in the VoMPLS case.
Note that, due to the padding phenomenon in VoM-
PLS, at N
fpp
=2 R
T T
is smaller than at N
fpp
=3. It
also demonstrates that N
fpp
=2 is an interesting work-
ing point for the G.729 codec, achieving less delay
with lower bandwidth consumption than N
fpp
=3.
Figure 6 reveals that using VoMPLS instead of
VoIP over MPLS yields bandwidth savings ranging
TRAFFIC TRUNK PARAMETERS FOR VOICE TRANSPORT OVER MPLS
63
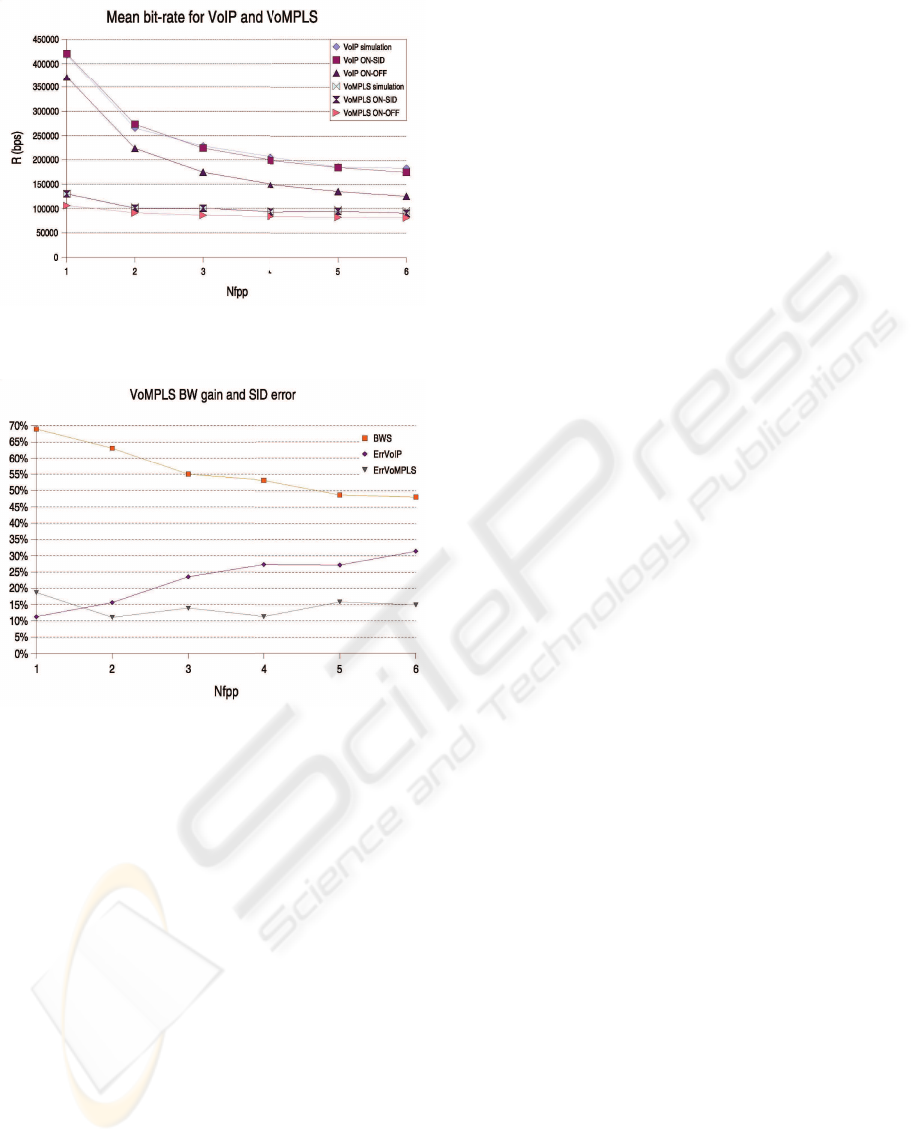
Figure 5: Experimental and analytical values of R
T T
.
Figure 6: Bandwidth saving and ON-OFF error.
from 69% (N
fpp
=1) to 48% (N
fpp
=6).
5 CONCLUSIONS
Traffic engineering needs accurate traffic parameters
in order to calculate the optimal capacity allocation
for a Traffic Trunk. We have provided analytical ex-
pressions for the mean and peak bit-rate of a Traf-
fic Trunk loaded with a mix of heterogeneous voice
sources for both the VoIP and VoMPLS transport
models. Conversely to the ON-OFF based models,
the model used for voice sources captures the effect
of the SID frames generated by a number of modern
voice codecs. We show that the SID-frames effect has
to be considered in the VoMPLS case, too. This con-
veys an improvement in the accuracy of results, which
show a quantitative gain in the bandwidth necessary
to transport voice trunks when compared to VoIP.
The calculation of required bandwidth to be allo-
cated for a voice TT with QoS commitments is in
progress at the time of writing this paper. This sub-
ject as well as the A2oMPLS transport case are left
for further study.
REFERENCES
(1999). Requirements for traffic engineering over mpls.
RFC 2702.
(2001). Multiprotocol label switching architecture. RFC
3031.
(2001). Voice over mpls- bearer transport implementation
agreement. MPLS Forum I.A.1.0.
B, G. (2002). Voice over internet protocol (voip). In Pro-
ceedings of the IEEE. IEEE Press.
Estepa, A., Estepa, R., and Vozmediano, J. (2003). Packeti-
zation and Silence Influence on VoIP Traffic Profiles.
Lecture Notes in Computer Science, 2899(1):331–
339.
Estepa, A., Estepa, R., and Vozmediano, J. (2005). Accurate
prediction of voip traffic mean bit rate. IEE Electronic
Letters, 8(10):644–647.
Procissi G, Garg A., G. M. S. M. (2002). Token bucket
characterization of long-range dependent traffic. Com-
puter Communications. Ed. Elsevier, 25:1009–1017.
R. Gu
´
erin, H. A. and Naghshineh, M. (1991). Equivalent
capacity and its application to bandwith allocation in
high-speed networks. JSAC. IEEE, 9(7).
SIGMAP 2006 - INTERNATIONAL CONFERENCE ON SIGNAL PROCESSING AND MULTIMEDIA
APPLICATIONS
64
